
- 1linux服务器配置conda和torch环境踩坑记录
- 2css的背景
- 319套STM32开发板资料共享
- 4DevOps已死?2024年的DevOps将如何发展
- 5Git基础全套完整版教程(快速上手,一套搞定)_蛙课网 git零基础入门到实战教程 文档
- 6maven project facet dynamic web module错误解决方案_determined from the dynamic web module facet vers
- 7大学生蓝桥杯比赛时间2020_注意!第十一届蓝桥杯大赛青少年创意编程组比赛开始报名啦!...
- 8zustand状态库在react类组件中使用
- 9初涉后端--为什么postman能够成功获取后端数据,前端项目却不能获取后端数据(已解决)_postman可以请求成功,前端就不能请求成功
- 10Java后端四面字节跳动,唬住面试官你也能拿30K+;附面经+面试题
K-MEANS聚类——Python实现_kmeans聚类算法python代码
赞
踩
一、概述
(1)物以类聚,人以群分,聚类分析是一种重要的多变量统计方法,但记住其实它是一种数据分析方法,不能进行统计推断的。当然,聚类分析主要应用在市场细分等领域,也经常采用聚类分析技术来实现对抽样框的分层。它和分类不同,它属于无监督问题。一个好的聚类方法要能产生高质量的聚类结果,则需要聚类的簇要具备:高的簇内相似性,低的簇间相似性。
(2)常用聚类方法:K-means聚类、DBSCAN密度聚类方法
(3)基本聚类方法的概述
1.划分方法
给定一个n个对象或元组的数据库,一个划分方法构建数据的k个划分,每个划分表示一个簇,并且 k<=n。每个组至少包含一个对象,每个对象属于且仅 属于一个组。
2.层次方法
自底向上方法(凝聚):开始将每个对象作为单独的一个组,然后相继的合并相近的对象或组,直到所有的组合并为一个,或者达到一个终止条件。
自顶向下方法(分裂):开始将所有的对象置于一个簇中,在迭代的每一步,一个簇被分裂为多个更小的簇,直到最终每个对象在一个单独的簇中, 或达到一个终止条件。
缺点:合并或分裂的步骤不能被撤销。
3.密度方法
基于距离的聚类方法的缺点:只能发现球状的簇, 难以发现任意形状的簇。
基于密度的聚类:只要临近区域的密度(对象或数据 点的数目)超过某个临界值,就继续聚类。
优点:可以过滤掉“噪声”和“离群点”发现任意形状的簇。
4.基于网格的方法
把对象空间量化为有限数目的单元,形成一个网格结构。所有的聚类都在这个网格结构上进行。 优点:处理数度快(因为处理时间独立于数据对象数 目,只与量化空间中每一维的单元数目有关)
总结:

二、K-MEANS算法
基本概念:
- 要得到簇的个数,需要指定k值
- 质心:均值,即向量各维取平均即可。
- 距离的度量:常用欧式距离(先标准化)
- 优化目标:
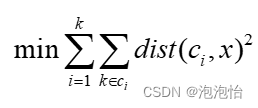
三、工作流程
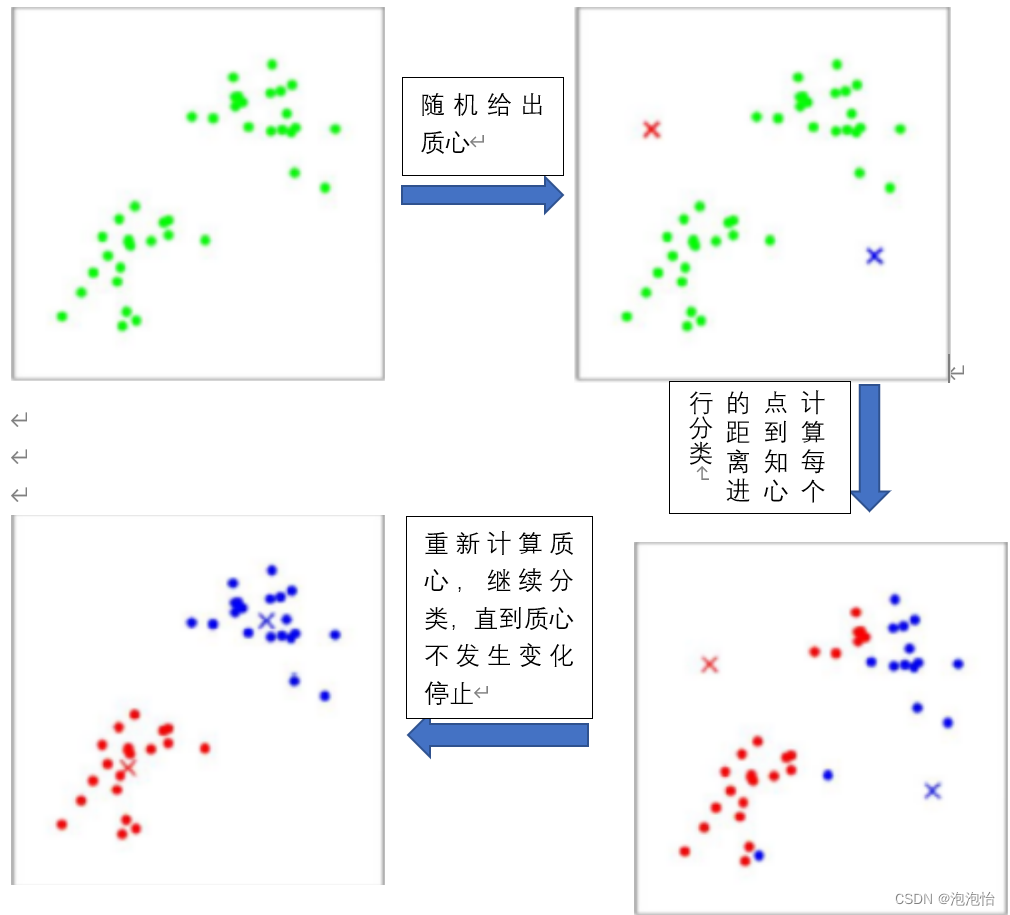
四、优缺点:
优点:操作简单,快速,适合常规数据集
缺点:
- k值很难确定
- 复杂度与样本呈线性关系
- 很难发现任意形状的簇
五、代码实现
1.导包
- %matplotlib inline
- import numpy as np
- import matplotlib.pyplot as plt
- from sklearn.cluster import KMeans
- from sklearn.preprocessing import StandardScaler
- from sklearn.datasets import make_blobs #生成数据函数
- from sklearn import metrics
2.生成平面数据点+标准化
- n_samples = 1500
- X,y = make_blobs(n_samples=n_samples,centers=4,random_state=170)
- X = StandardScaler().fit_transform(X) #标准化
3.调用kmeans包
- Kmeans=KMeans(n_clusters=4,random_state=170)
- Kmeans.fit(X)
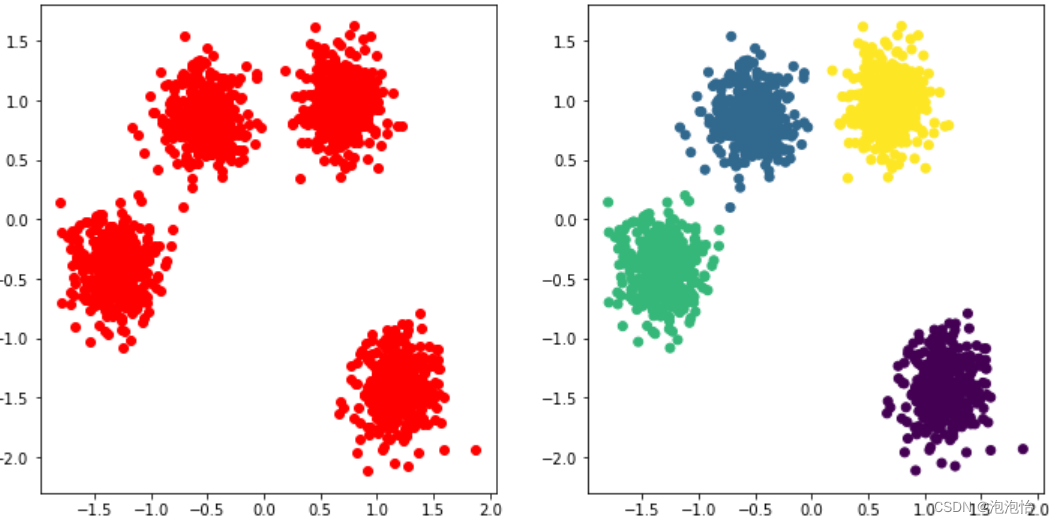
4.可视化效果
- plt.figure(figsize=(12,6))
- plt.subplot(121)
- plt.scatter(X[:,0],X[:,1],c='r')
- plt.title("聚类前数据图")
- plt.subplot(122)
- plt.scatter(X[:,0],X[:,1],c=Kmeans.labels_)
- plt.title("聚类后数据图")
- plt.show()
结果如图:
六、K-MEANS算法程序,代码如下:
- class KMEANS:
- def_init_(self,data,num_clustres):
- self.data=data
- self.num_clustres=num_clustres
- def train(self,max_iterations):
- #1.先随机选择k个中心点
- centroids=KMEANS.centroids_init(self.data,self.num_clustres)
- #2.开始训练
- num_exxamples=self.data.shape[0]
- closest_ centroids_ids=np.empty((num_examples,1))
- for _ in range(max_iterations):
- #3得到当前每个样本到k个中心点的距离,找最近的
-
- closest_centroids_ids=KMEANS.centroids_find_closest(self.data,centroids)
- #进行中心点位置更新
- centroids=KMEANS.centroids_compute(self.data,closest_centroids_ids,self.num_clustres)
- return centroids,closest_ centroids_ids
接下来是三个方法:
- def centroids_init(self,data,num_clustres):
- num_examples=data.shape[0]
- random_ids=np.random.permutation(num_examples)
- centroids=data[random_ids[:num__clustres],:]
- return centroids
- def centroids_find_closest(self,data,centroids ) :
- num_examples = self.data.shape[0]
- num_centroids = centroids.shape[0]
- closest_centroids_ids = np.zeros((num_examples,1))
- for example_index in range( num_examples) :
- distance = np.zeros( num_centroids,1)
- for centroid_index in range(num_centroids) :
- distance_diff = data[example_index, : ] - centroids[centroid_index,distance[centroid_index]
- = np.sum(distance_diff**2)
- closest_centroids_ids[example_index] = np.argmin(distance)
- return closest_centroids_ids
- def centroids_compute(self ,data,closest_centroids_ids,num_clustres):
- num_features = data.shape[0]
- centroids = np.zeros((num_ciustres,num_features))
- for centnoid_id in range(num_clustres) :
- closest_ids = closest_centroids_ids == centroid_id
- centroids[closest_ids] = np.mean( aareturn centroids.flatten(),:],axis=0)
- return centroids
七、模型评估(轮廓系数)
轮廓系数意义:
轮廓系数(Silhouette Coefficient)是为每个样本定义的,由两个得分组成:
a: 某个样本与同一类别中所有其他点之间的平均距离。
b: 该样本与下一个距离最近的簇中的所有其他点之间的平均距离。
单个样本的轮廓系数(Silhouette Coefficient)为: s=(b−a)/max(a,b)
一组样本的轮廓系数(Silhouette Coefficient)为:每个样本的 Silhouette 系数的平均值
- #反映同类样本类内平均距离尽可能小,类间距离尽可能大的指标。取值范围在[-1,1]之间,越大越好
- labels = Kmeans.labels_
- pgjg1=metrics.silhouette_score(X, labels, metric='euclidean') #轮廓系数
- print('聚类结果的轮廓系数=',pgjg1)
结果:
![]()
三、数据挖掘考试复习题



