
- 1【JavaSE】接口 详解(下)
- 2iOS及Mac开源项目和学习资料【超级全面】_gooey发行时间
- 3面试必问:四种经典限流算法_限流算法 滑动窗口
- 4从零开始学习Python爬虫:详细指南,阿里p7面试经验
- 5【Doris】Doris 最佳实践-Compaction调优(3)_doris中如何查看哪个表的版本有堆积?
- 6教你成为机房最靓的仔——伪装黑客_如何伪装黑客
- 7Docker安装Rabbitmq并挂载宿主机数据目录_docker rabbitmq 数据目录
- 8第一章第一节计算机语言C语言基础教程
- 9Android Studio新建项目缓慢解决方案_android studio创建项目很慢
- 10Python后端---使用Django+Mysql搭建一个简单的网站_django pymysql
爬虫scrapy_scrapy爬虫
赞
踩

零, scrapy框架必读
学习scrapy前, 我们需要看懂下图
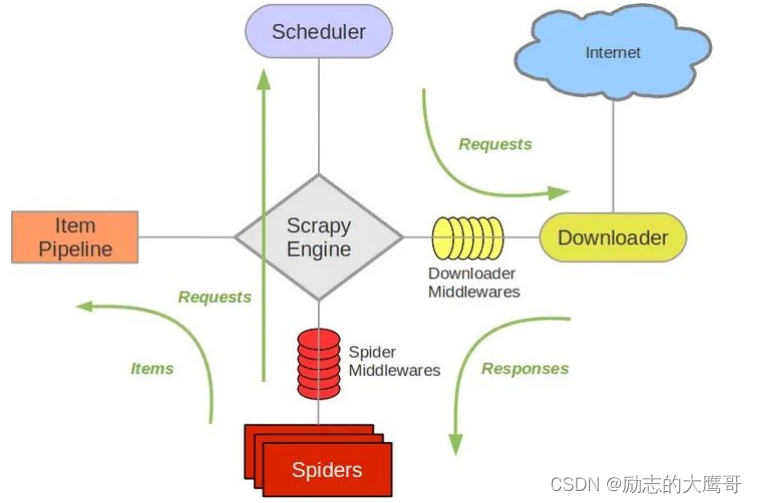
请务必仔细阅读并理解该流程:
0- spider优先提供一个起始url(start_url)和想要爬取的域名, 发送给引擎。
1- scrapy框架核心为引擎(ScrapyEngine)。启动scrapy时。引擎会读取spiders中由start_url构建出的request请求。
2- Engine 将封装好的request推送到 Scheduler调度器中 。调度器使用过滤器读取setting中的配置构成请求队列返回给引擎。
3- 引擎按照 Scheduler中的安排下发任务给 Downloader下载器 下载器请求Internet去获取相应的响应
4- 其中Requests和Response都会经过DownloadMiddlerwares,一些特殊请求或响应可以在中间件中构建或处理完成 。
5- 引擎获取到Downloader中返回的Response后,将response传递给spider。 spider通过parse方法对response进行解析
6- 获取到解析数据后,spider将数据返回给引擎。 如果还有回调函数。spider将url重新封装成Request再次返回给引擎
7- 引擎将所有的Request调用完毕, 结束流程
总结
scrapy是一个自动化的框架, 它给我们提供了 Spiders, Engine, Scheduler, Downloader,
Pipelines 以及 Middleware功能。-其中我们只用编写或修改部分功能。 如
1- Spiders功能中, 我们需要编写 【提取和构建 requests & Response 数据处理 】
2- setting中配置Scheduler需要的参数
3- DownloaderMiddleware中构建请求的特殊参数。 如(UA, IP池等)
4- Pipline中做结果处理操作。如(数据入库)
note: 我们所有的步骤全部又Engine调度
一, 环境准备
1- python 解释器
2- pycharm 编辑工具
3- scarpy 安装scrapy包
note: 这里有个坑。 我们正常安装的的scrapy版本与scrappy-redis可能会有冲突。所以我们通常会固定scrapy版本。如果以后要使用scrapy-redis的话, 建议按照如下操作更新scrapy。
执行一下步骤:
pip uninstall scrapy 输入:y确认卸载
pip install scrapy2.5.1 安装指定的scrapy版本
scrapy version --verbose 查看scrapy中各个工具的版本。
pip uninstall cryptography 如果cryptography版本不在 1.. 则卸载 cryptography
pip install cryptography36.0.2 固定版本36.0.2
至此。 scrapy版本即固定成功
一切准备就绪,我们开始创建自己的第一个scrapy爬虫
二, 创建一个最简单的爬虫项目
1- 选择要存放scrapy的目录, 进入cmd目录地址, 使用该命令创建scrapy项目
scrapy startproject ant_spider
- 1
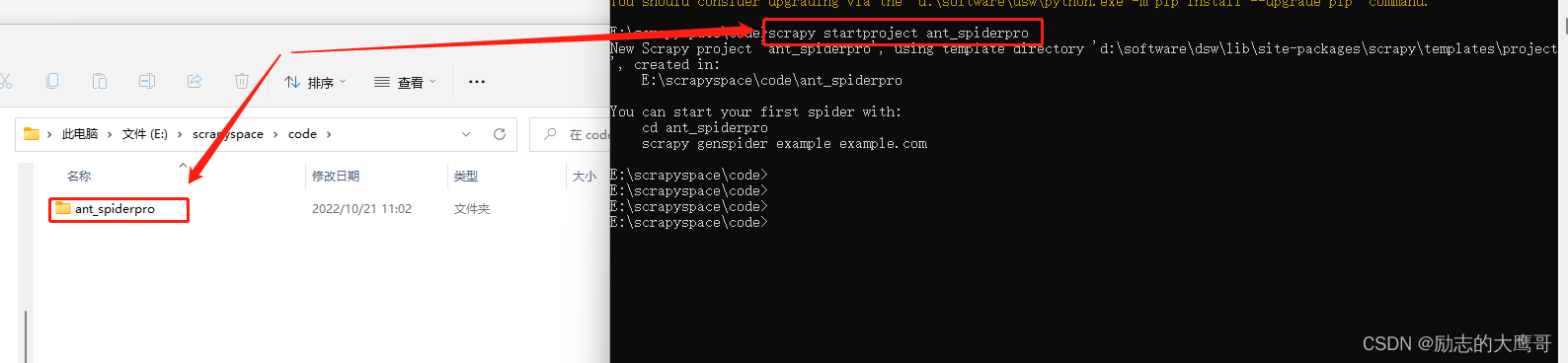
2- cd进入scrapy项目中, 并指定我们要爬取的网站。
cd ant_spider
scrapy genspider yanzhaopro https://yz.chsi.com.cn
此时我们指定了要爬取 https://yz.chsi.com.cn 下的内容

- 1
- 2
- 3
- 4
此时我们的scrapy项目创建成功
3- scrapy配置
1, scrapy是一个爬虫框架, 即我们只需要做出相应的配置, 它就能按照指定的步骤去执行爬虫步骤。
首先我们看下setting中的配置:
1- 我们当然不应该遵守 Robots 协议 ROBOTSTXT_OBEY = False note: 如果不清楚robots协议还是要去百度一下, 简单来说就是互联网中的君子协议。 如果遵守就没必要学习爬虫了。 2- 请求并发量 CONCURRENT_REQUESTS = 32 note: 如果目标网站数据不敏感当然可以高一点(可以达到200。其实可以更高, 鉴于数据不敏感的网站服务器一般不会太牛, 200差不多了, 再高可能会影响爬虫的成功率)。 但是目标网站过于敏感还是建议使用低并发处理(50以下) 3- 下载延时 DOWNLOAD_DELAY = 3 note: 这个参数可以高一点。 我们请求成功就行, 如果因为下载太多频繁导致成功率太低得不偿失(3-10之间都可以) 4- 域名和ip的并发量 CONCURRENT_REQUESTS_PER_DOMAIN = 16 CONCURRENT_REQUESTS_PER_IP = 16 note: 这两个是配套使用, 具体用法可以百度。 参数调节一般二者选一个就行。值尽量在20-50之间 5- cookie的使用 COOKIES_ENABLED = False note: 这里其实也是大有学问, 本质就是是否使用scrapy配置的cookie, 或者手动添加cookie。 值为False: 不会自动添加cookie, 如果需要用cookie,则手动添加 值不为False(为True或者注释掉): 自动添加cookie 6- 开启控制台调试打印 TELNETCONSOLE_ENABLED = True 7- 给定默认请求头 DEFAULT_REQUEST_HEADERS = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'en', } 8- 开启middleware SPIDER_MIDDLEWARES = { 'ant_spiderpro.middlewares.AntSpiderproSpiderMiddleware': 543, } DOWNLOADER_MIDDLEWARES = { 'ant_spiderpro.middlewares.AntSpiderproDownloaderMiddleware': 543, } 9- item操作 ITEM_PIPELINES = { 'ant_spiderpro.pipelines.AntSpiderproPipeline': 300, } 10- 设置日志等级 LOG_LEVEL = "WARNING"

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
4- 正式编写一个scrapy项目
到这一步我们就可以正式编写一个scrapy了
还记得第一步吗, spider中构建一个request请求。
找到spider
编写spider代码如下
import scrapy from scrapy.http import Request class YanzhaoproSpider(scrapy.Spider): name = 'yanzhaopro' def __init__(self): # 需要爬取的页面, 这里可以添加url池 self.start_urls = ['http://yz.chsi.com.cn/'] def start_requests(self): if not hasattr(self, 'start_urls'): self.start_urls = [] for url in self.start_urls: print("我们开始构建请求") yield Request(url, dont_filter=True) def parse(self, response): print("我们对response进行处理") print(response.text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
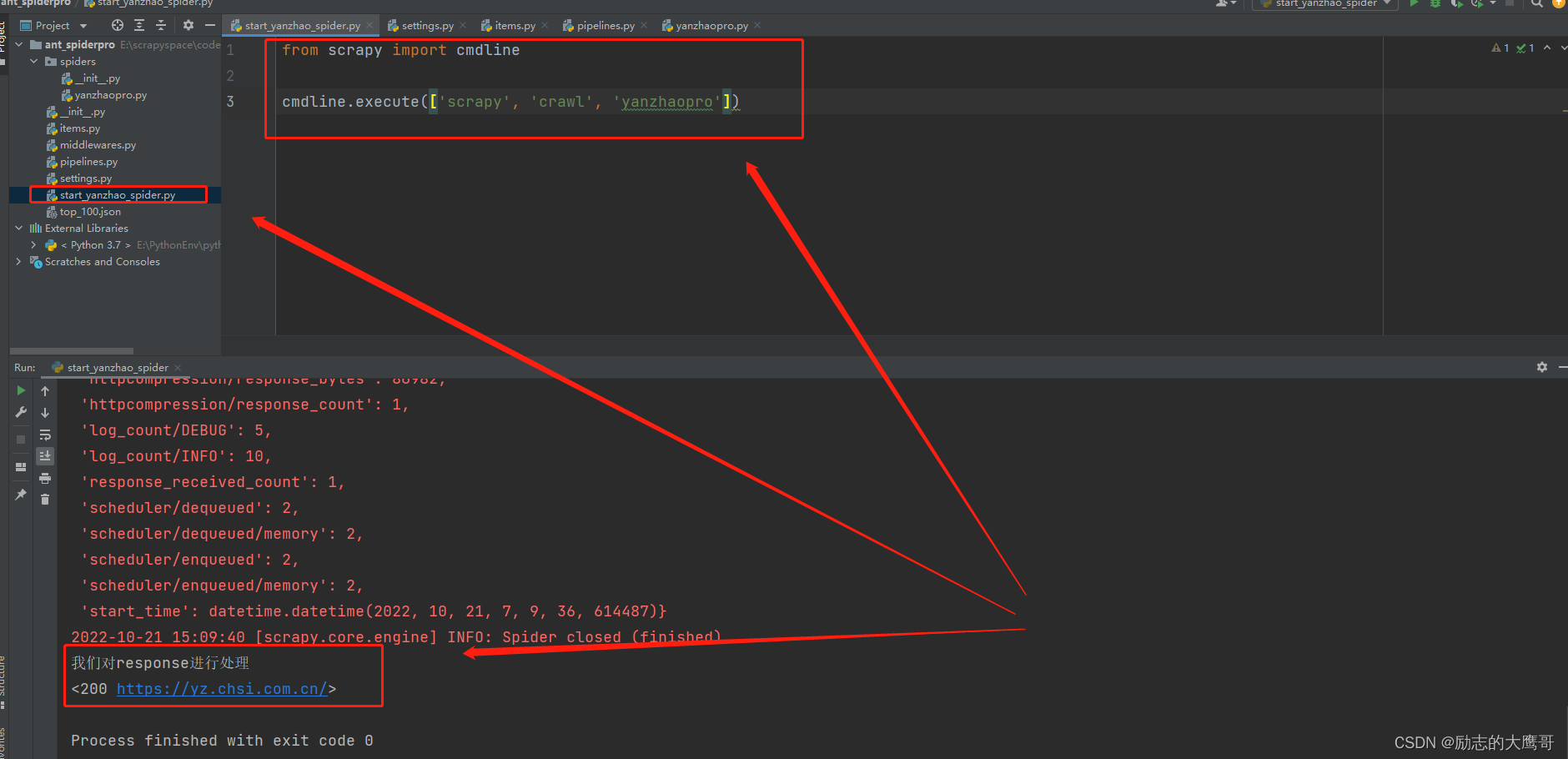
5- 启动爬虫
此时有几种方式启动spider, 我这里只说一种。
在项目中创建一个 start_spider 的py文件
from scrapy import cmdline
cmdline.execute(['scrapy', 'crawl', 'yanzhaopro'])
- 1
- 2
- 3
执行既能启动
三,案例一 ==> 单页面爬取
1- setting中的初级配置
BOT_NAME = 'firstcrawl' SPIDER_MODULES = ['firstcrawl.spiders'] NEWSPIDER_MODULE = 'firstcrawl.spiders' # 设置日志等级 LOG_LEVEL = "WARNING" # Crawl responsibly by identifying yourself (and your website) on the user-agent USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36' # Obey robots.txt rules ROBOTSTXT_OBEY = False # Configure maximum concurrent requests performed by Scrapy (default: 16) # scrapy默认是协程任务 CONCURRENT_REQUESTS = 32 # Configure item pipelines # See https://docs.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { # 管道: 优先级 'firstcrawl.pipelines.FirstcrawlPipeline': 300, }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
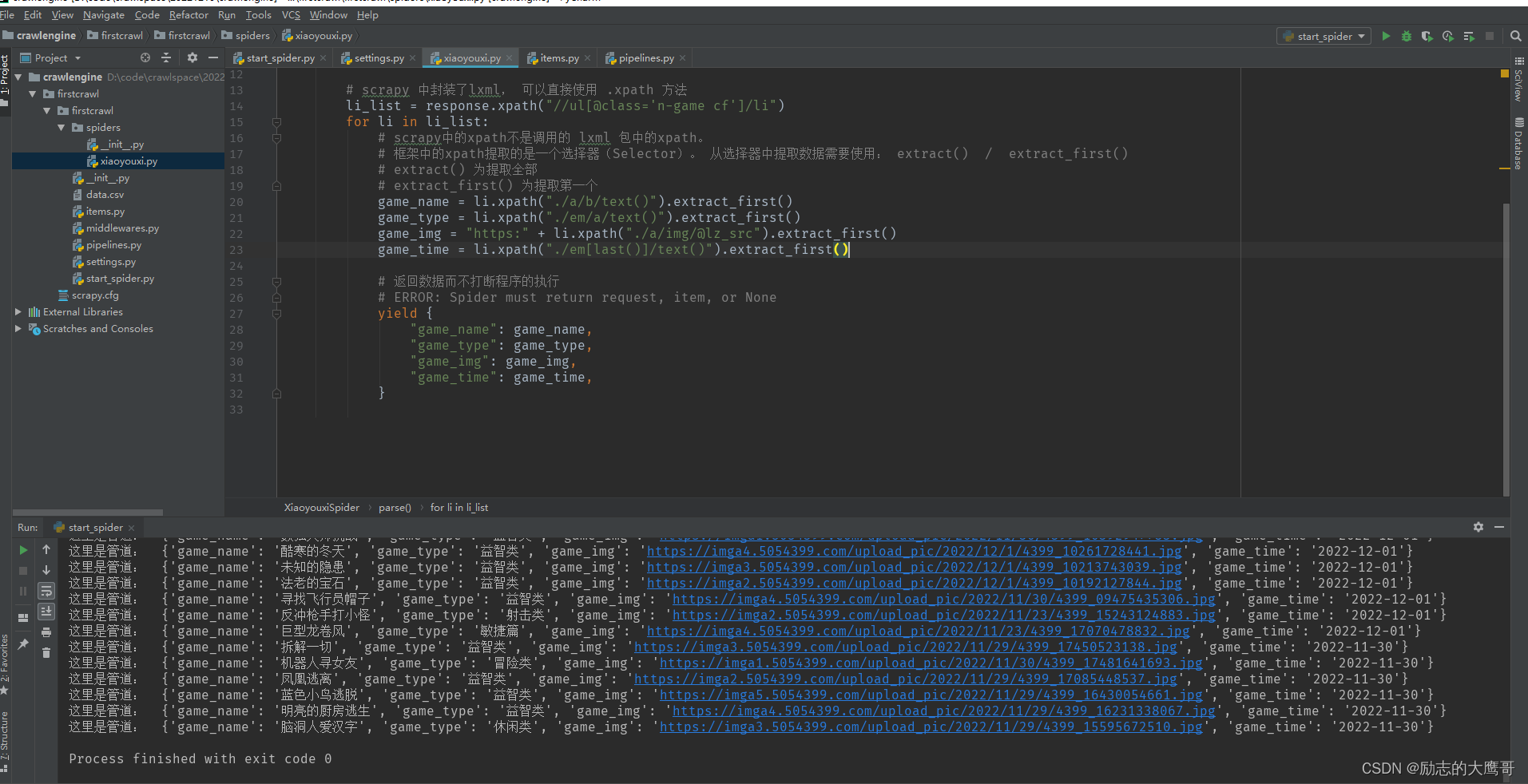
2- spider中的代码
import scrapy class XiaoyouxiSpider(scrapy.Spider): name = 'xiaoyouxi' # 爬虫的名字 allowed_domains = ['4399.com'] # 爬虫允许访问的域名是什么 start_urls = ['https://www.4399.com/flash/'] # 起始 url def parse(self, response): print(response.text) print("================================================================") # scrapy 中封装了lxml, 可以直接使用 .xpath 方法 li_list = response.xpath("//ul[@class='n-game cf']/li") for li in li_list: # scrapy中的xpath不是调用的 lxml 包中的xpath。 # 框架中的xpath提取的是一个选择器(Selector)。 从选择器中提取数据需要使用: extract() / extract_first() # extract() 为提取全部 # extract_first() 为提取第一个 game_name = li.xpath("./a/b/text()").extract_first() game_type = li.xpath("./em/a/text()").extract_first() game_img = "https:" + li.xpath("./a/img/@lz_src").extract_first() game_time = li.xpath("./em[last()]/text()").extract_first() # 返回数据而不打断程序的执行 # ERROR: Spider must return request, item, or None yield { "game_name": game_name, "game_type": game_type, "game_img": game_img, "game_time": game_time, }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
note:其中特别说明的是 scrapy 中使用xpath不是基于 lxml 库。 所以用法上有点区别
为了解决xpath提取文本时以索引获取数据可能报错的问题
如果使用[0]索引取值。 页面中没有该值则会报错【li.xpath(“./a/b/text()”)[0]】
scrapy将xpath提取数据封装成了selector选择器, 当xpath中的对象不存在时。 返回为None, 避免流程无故中断
而从选择器中取值提供了两个方法: 【extract_first()】取第一个值。 【extract()】 提取全部值
3- pipline中的代码
# 管道使用。必须在settings中开启
class FirstcrawlPipeline:
# item 数据
# process 处理
def process_item(self, item, spider):
print("这里是管道: ", item)
with open("data.csv", mode="a", encoding="utf-8") as f:
f.write(f"{item['game_name']}, {item['game_type']}, {item['game_img']}, {item['game_time']}\n")
return item
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
返回结果如下
四, 案例二 ==> 多次请求和下载图片
以该url: 【https://desk.zol.com.cn/dongman/】 为例。 我们需要获取页面上的img详情链接, 请求详情链接中的图片进行下载
此时步骤为:
…1- 第一次请求获取页面上的img_url的详情地址。
…2- 第二次请求从详情页面中获取多个图片地址。
…3-最后针对每个url进行下载
1- setting.py中的代码
BOT_NAME = 'tupian' SPIDER_MODULES = ['tupian.spiders'] NEWSPIDER_MODULE = 'tupian.spiders' USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36' ROBOTSTXT_OBEY = False LOG_LEVEL = "WARNING" ITEM_PIPELINES = { 'tupian.pipelines.DetailTupianPipeline': 301, } IMAGES_STORE = "./jia" MEDIA_ALLOW_REDIRECTS = True
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
2- spider中的代码
import scrapy from scrapy.http import Request class JiaSpider(scrapy.Spider): name = 'jia' allowed_domains = ['zol.com.cn'] start_urls = ['https://desk.zol.com.cn/dongman/'] def parse(self, response, **kwargs): print(response.url) print("====================================================") hrefs = response.xpath("//ul[@class='pic-list2 clearfix']/li/a/@href").extract() for href in hrefs: # 屏蔽无用链接 if href.endswith(".exe"): continue # 拼接出完整的路径 """ response路径: https://desk.zol.com.cn/dongman/ 如果抓取路径以“/”开头, 则需要与域名拼接成完整路径: https://desk.zol.com.cn/dongman/ /bizhi/9109_111583_2.html ===》 https://desk.zol.com.cn/bizhi/9109_111583_2.html 如果抓取路径不是以“/”开头, 则需要与response中抓取的同级目录进行拼接: https://desk.zol.com.cn/dongman/zhoujielun bizhi/9109_111583_2.html ===》 https://desk.zol.com.cn/dongman/bizhi/9109_111583_2.html """ download_url = response.urljoin(href) print(download_url) yield Request(download_url, callback=self.detail_parse) def detail_parse(self, detail_response, **kwargs): img_url = detail_response.xpath("//img[@id='bigImg']/@src").extract_first() print(img_url) yield { "img_url": img_url }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
3- pipline中的代码
from itemadapter import ItemAdapter from scrapy.pipelines.images import ImagesPipeline from scrapy.pipelines.files import FilesPipeline from scrapy import Request class TupianPipeline: def process_item(self, item, spider): return item class DetailTupianPipeline(ImagesPipeline): # 发送下载请求 def get_media_requests(self, item, info): img_url = item['img_url'] print("来", img_url) # 请求对象船只的最佳方案: meta yield Request(img_url, meta={"img_path": img_url}) def file_path(self, request, response=None, info=None, *, item=None): # 需要返回文件路径 img_path = request.meta["img_path"] img_name = img_path.split("/")[-1] return f"save_img/{img_name}" def item_completed(self, results, item, info): # 对下载结果(results)进行判断, 选择操作 return item
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
结果展示
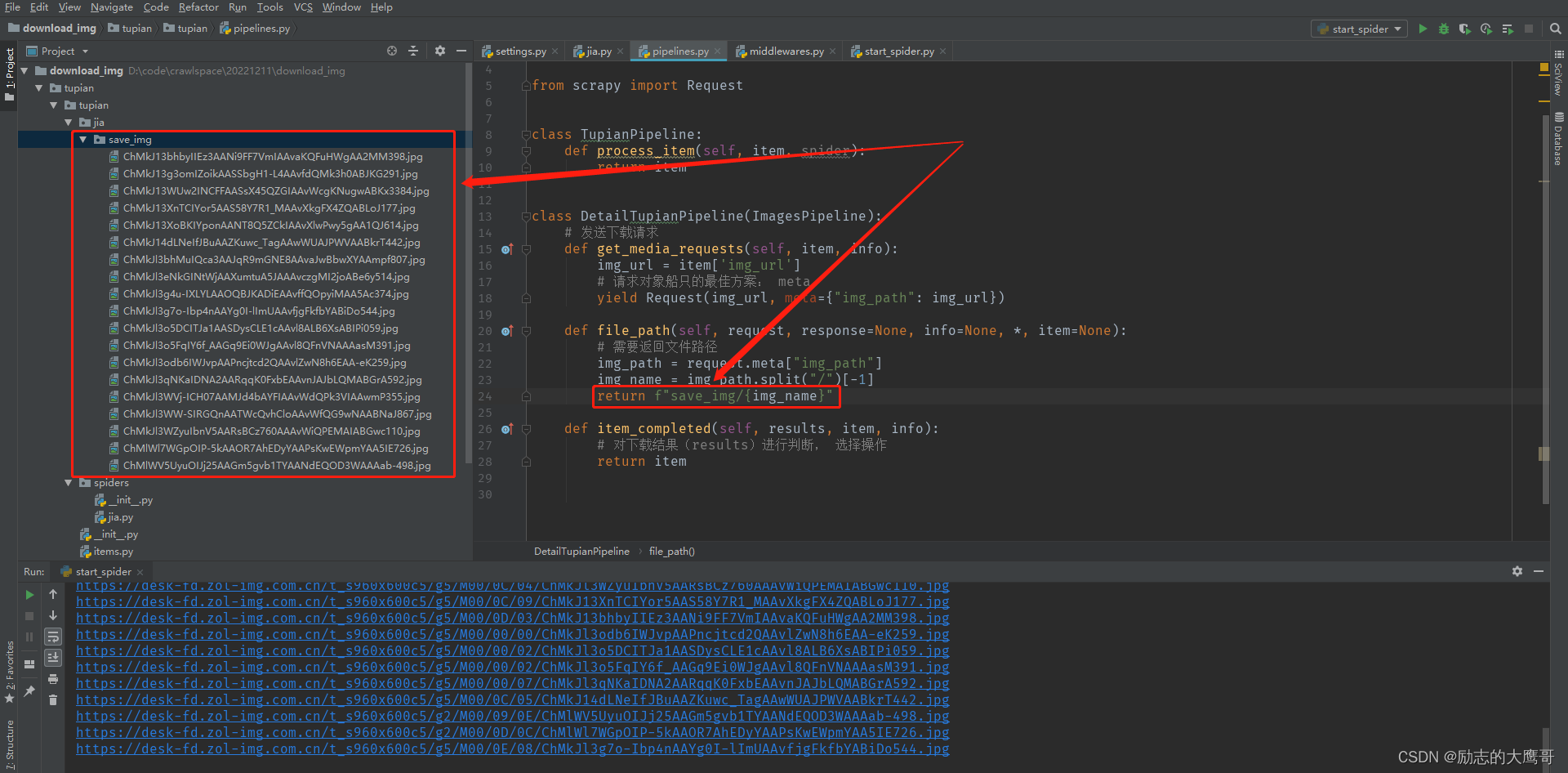
步骤说明:
1- spider构建出Request后, 获取response响应。
2- spider中的parse方法解析response后提取出img_url详情页面。 构建出二次请求的Request并回调到 detail_parse 进行解析
【yield Request(download_url, callback=self.detail_parse)】
3- detail_parse 解析出详情页中的img图片, 在管道中进行下载
4- 管道的图片下载有三个函数, 分别是【构建下载请求】 【下载路径处理】 【下载结果逻辑】
图片下载完成
五, 案例三 ==> 请求翻页
1- 只有spider中的代码需要改动
import scrapy from scrapy import Request class FenleiSpider(scrapy.Spider): name = 'fenlei' allowed_domains = ['17k.com'] start_urls = ['https://www.17k.com/all/book/2_0_0_0_0_0_0_0_1.html'] def parse(self, response, **kwargs): book_list = response.xpath("//table/tbody/tr[contains(@class, 'bg')]") for book in book_list: book_type = book.xpath("./td[@class='td2']/a/text()").extract_first() book_name = book.xpath("./td[@class='td3']//a/text()").extract_first() book_chapters = book.xpath("./td[@class='td4']/a/text()").extract_first() book_author = book.xpath("./td[@class='td6']/a/text()").extract_first() yield { "book_type": book_type, "book_name": book_name, "book_chapters": book_chapters, "book_author": book_author } hrefs = response.xpath("//div[@class='page']/a/@href").extract() for href in hrefs: if href.startswith('javascript'): continue next_url = response.urljoin(href) yield Request(next_url, callback=self.parse)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
六, 案例四 ==> 常规登录案例
1- setting中代码
BOT_NAME = 'loginpro' SPIDER_MODULES = ['loginpro.spiders'] NEWSPIDER_MODULE = 'loginpro.spiders' USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36' ROBOTSTXT_OBEY = False LOG_LEVEL = "WARNING" COOKIES_ENABLED = False DEFAULT_REQUEST_HEADERS = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'en', # 这里的cookie不可以直接使用, 因为scrapy中有个cookie的中间件会刷新这里的cookie "Cookie": 'GUID=c2a0dd44-3d59-4b1c-a17f-5f4f1c0e33bf; c_channel=0; c_csc=web; accessToken=avatarUrl%3Dhttps%253A%252F%252Fcdn.static.17k.com%252Fuser%252Favatar%252F09%252F49%252F49%252F99704949.jpg-88x88%253Fv%253D1670250949000%26id%3D99704949%26nickname%3DMrxiong1223%26e%3D1685804209%26s%3D1ed4b1d810f2a640; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2299704949%22%2C%22%24device_id%22%3A%22184e2b4d45529f-056b1f117d50f2-58412b14-2073600-184e2b4d456d6a%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%2C%22first_id%22%3A%22c2a0dd44-3d59-4b1c-a17f-5f4f1c0e33bf%22%7D; Hm_lvt_9793f42b498361373512340937deb2a0=1670250813,1670720818; __bid_n=184feb8ad3b63e15874207; FEID=v10-7dfe2cb3a52c946f7bbaf83b0d75a37cdf23252d; __xaf_fpstarttimer__=1670720826804; __xaf_ths__={"data":{"0":1,"1":86400,"2":60},"id":"2601b593-4337-4646-99ed-4cf75e8c080c"}; __xaf_thstime__=1670720826807; FPTOKEN=hhpJOar3Pm4F2QF3tBjIjCg9lkLA2F9Mm71+WEXfUwZ1N+pR9tHaRmQnQVmQ2NgQa0bZb2Ntpxuhtqg4Mg0IBjfB07vqq4z/gzR+++P0jmy/02QTrdlsdljF+AU5emWnGGTdobRj0/9YagyuEdK1sY42ZQiSZYCzOjiYxeoCMEaalSB6k2eyTmgIYlGE4IOeq5DjWK4PYfHProC3piqDWRtApvDQzUmJBySmkFyFQgibQ6YgVht01ZpX+1mGa5o2E1I9uASyQZOeUNMHBiRg097fF05z+chXLoTyaC3rxUmCW55cLXooXV1o1rlzDGDw9Br+6eW+Ha3pMBmOS+Xq3aSNqmnldT1z3pQv9YCl0l5dnhqJeeSceqsYElJG9ACppLEYwiQ2EWxmFBI3wo3ZPQ==|UJQeL0Hjl5mZHzA4CKG3sKH7UoEiBkRXqz3XxPbtPcw=|10|195946289e4b100f86abdbadf9399cd6; __xaf_fptokentimer__=1670720826905; Hm_lpvt_9793f42b498361373512340937deb2a0=1670730045' }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
或者也可以使用下面的方式将cookie传入request
import scrapy from scrapy import Request class MyloginSpider(scrapy.Spider): name = 'mylogin' allowed_domains = ['17k.com'] start_urls = ['https://user.17k.com/www/bookshelf/'] def start_requests(self): cookie = 'GUID=c2a0dd44-3d59-4b1c-a17f-5f4f1c0e33bf; c_channel=0; c_csc=web; accessToken=avatarUrl%3Dhttps%253A%252F%252Fcdn.static.17k.com%252Fuser%252Favatar%252F09%252F49%252F49%252F99704949.jpg-88x88%253Fv%253D1670250949000%26id%3D99704949%26nickname%3DMrxiong1223%26e%3D1685804209%26s%3D1ed4b1d810f2a640; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2299704949%22%2C%22%24device_id%22%3A%22184e2b4d45529f-056b1f117d50f2-58412b14-2073600-184e2b4d456d6a%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%2C%22first_id%22%3A%22c2a0dd44-3d59-4b1c-a17f-5f4f1c0e33bf%22%7D; Hm_lvt_9793f42b498361373512340937deb2a0=1670250813,1670720818; __bid_n=184feb8ad3b63e15874207; FEID=v10-7dfe2cb3a52c946f7bbaf83b0d75a37cdf23252d; __xaf_fpstarttimer__=1670720826804; __xaf_ths__={"data":{"0":1,"1":86400,"2":60},"id":"2601b593-4337-4646-99ed-4cf75e8c080c"}; __xaf_thstime__=1670720826807; FPTOKEN=hhpJOar3Pm4F2QF3tBjIjCg9lkLA2F9Mm71+WEXfUwZ1N+pR9tHaRmQnQVmQ2NgQa0bZb2Ntpxuhtqg4Mg0IBjfB07vqq4z/gzR+++P0jmy/02QTrdlsdljF+AU5emWnGGTdobRj0/9YagyuEdK1sY42ZQiSZYCzOjiYxeoCMEaalSB6k2eyTmgIYlGE4IOeq5DjWK4PYfHProC3piqDWRtApvDQzUmJBySmkFyFQgibQ6YgVht01ZpX+1mGa5o2E1I9uASyQZOeUNMHBiRg097fF05z+chXLoTyaC3rxUmCW55cLXooXV1o1rlzDGDw9Br+6eW+Ha3pMBmOS+Xq3aSNqmnldT1z3pQv9YCl0l5dnhqJeeSceqsYElJG9ACppLEYwiQ2EWxmFBI3wo3ZPQ==|UJQeL0Hjl5mZHzA4CKG3sKH7UoEiBkRXqz3XxPbtPcw=|10|195946289e4b100f86abdbadf9399cd6; __xaf_fptokentimer__=1670720826905; Hm_lpvt_9793f42b498361373512340937deb2a0=1670730045' item_dict = {} for item in cookie.split(";"): item = item.strip() k, v = item.split("=", 1) item_dict[k] = v yield Request(self.start_urls[0], cookies=item_dict) def parse(self, response, **kwargs): print(response.text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
将cookie信息更新在setting中, 并关闭cookie中间件中的覆盖。则request会携带cookie请求页面
七,案例五 ==> 跳转登录页面进行模拟登录
1- start_spider
from scrapy import cmdline
cmdline.execute("spider crawl novel_17K".split())
- 1
- 2
- 3
- 4
2- setting
BOT_NAME = 'mylogin'
SPIDER_MODULES = ['mylogin.spiders']
NEWSPIDER_MODULE = 'mylogin.spiders'
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36'
ROBOTSTXT_OBEY = False
LOG_LEVEL = "WARNING"
DOWNLOAD_DELAY = 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
3- novel_17k
import scrapy from scrapy import Request class Novel17kSpider(scrapy.Spider): name = 'novel_17K' allowed_domains = ['17k.com'] start_urls = ['https://user.17k.com/ck/author/shelf?page=1&appKey=2406394919'] def start_requests(self): login_url = 'https://passport.17k.com/ck/user/login' params = { "loginName": "13059155810", "password": "123456" } """ params_str = "" for k, v in params.items(): params_str += k+"="+v+"&" params_str = params_str[:-1] """ from urllib.parse import urlencode params_str = urlencode(params) yield Request(login_url, method='POST', body=params_str, callback=self.login_success) def login_success(self, response, **kwargs): print(response.text) print("登录成功") yield Request(self.start_urls[0], callback=self.parse) def parse(self, response, **kwargs): print("进入解析页面") print(response.text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35

