
- 1隧道技术的三种应用场景(IPv6,多播,VPN)_ipv6的过渡技术ipv6 over ipv4 isatap隧道,能够支持哪些场景?
- 2研发岗-面临统信UOS系统配置总结
- 3阿里云推出“ModelScopeGPT”大模型调用工具,再添新贵_大模型调试工具
- 4HCIA-HarmonyOS应用开发工程师 V2.0 模拟考试_某开发者自定义了test1组件
- 5区块链安全之DDoS防护的重要性及其实施策略
- 6Flutter build-runner工具简单使用_flutter build_runner
- 7stable-diffusion-webui [Centos]安装记录_loading weights [dcd690123c] from e:\sd\stable-dif
- 8【多尺度混合注意力Transformer:Pansharpening】_多尺度全局注意力机制
- 9uniapp使用本地存储(app)_uniapp本地数据库
- 10MySql锁机制(全网最全、最详细、最清晰)
[论文阅读] RT-1: ROBOTICS TRANSFORMER FOR REAL-WORLD CONTROL AT SCALE
赞
踩
1、RT-1: ROBOTICS TRANSFORMER FOR REAL-WORLD CONTROL AT SCALE
时间:2022/12/13
团队:robotics at google
会议:RSS2
摘要
通过从大型、多样化的任务识别数据集转移知识,现代机器学习模型可以解决特定的下游任务,无论是零样本还是使用小型任务特定数据集,都可以达到高性能水平 。zero-shot or with small task-specific datasets to a high level of performance
虽然这种能力已经在计算机视觉、自然语言处理或语音识别等其他领域得到了证明,但它仍有待于机器人领域的展示,因为难以收集真实世界的机器人数据,因此模型的泛化能力尤其关键 the generalization capabilities of the models are particularly critical。
我们认为,这种通用机器人模型成功的关键之一在于开放式任务无关训练,以及能够吸收所有不同机器人数据的高容量架构。
我们提出了一个模型类,称为Robotics Transformer,它具有很好的可扩展模型特性。
我们在一项研究中验证了我们的结论,研究了不同的模型类别,以及它们作为数据大小、模型大小和数据多样性的函数的泛化能力,该研究基于执行现实世界任务的真实机器人的大规模数据收集。
思路
这种模型(NLP等领域)成功的关键在于开放式的任务不可知训练,结合可以吸收大规模数据集中所有知识的高容量架构。如果一个模型可以“吸收”经验来学习语言或感知的一般模式,那么它就可以更有效地将它们用于单个任务。
The keys to the success of such models lie with open-ended task-agnostic training, combined with high-capacity architectures that can absorb all of the knowledge present in large-scale datasets. If a model can "sponge up" experience to learn general patterns in language or perception, then it can bring them to bear on individual tasks more efficiently.
旨在训练一种可以用在各类机器人任务上的通用模型:a single, capable, large multi-task backbone model on data consisting of a wide variety of robotic tasks
这样的模型是否享有在其他领域观察到的好处,表现出对新任务、环境和对象的零概率泛化 zero-shot generalization?
当前大型多任务机器人policies存在的问题:
- have limited breadth of real-world tasks
- focus on training tasks rather than generalization to new tasks,as with recent instruction following methods
- attain comparatively lower performance on new tasks
two main challenges:
- assembling the right dataset
- 我们使用了一个数据集,该数据集是我们在17个月的时间里收集的,由13个机器人组成,包含约130k次发作和700多个任务
- 良好的泛化需要结合规模和广度的数据集,涵盖各种任务和设置
- the tasks in the dataset should be sufficiently well-connected to enable generalization
- designing the right model
- transformer模型在高容量方面突出
- 我们设计了RT-1的架构,高维输入camera images, instructions and motor commands转变为transformer所用的compact token representations
- 高效推理实现实时控制
研究结果:
- RT-1可以以97%的成功率执行700多个训练指令,并且可以推广到新任务、干扰源和背景
- RT-1可以结合来自模拟甚至其他机器人类型的数据,保留原始任务的性能并提高对新场景的泛化
We aim to learn robot policies to solve language-conditioned tasks from vision.
方法
硬件:We use mobile manipulators from Everyday Robots, which have a 7 degree-of-freedom arm, a two-fingered gripper, and a mobile base
environments:use three kitchen-based environments,一个训练厨房环境,两个真实厨房环境
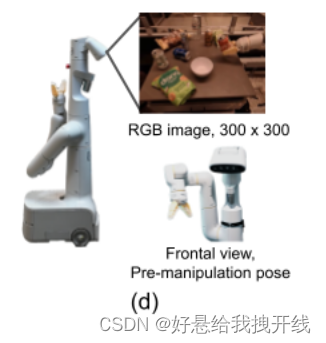
训练数据:由人类提供的演示组成并对每个episode用机器人执行指令的文本描述进行标注;指令instruction包含一个动词和多个名词;最大的数据集包含超过130k个单独的演示,包括使用各种各样的对象的700多个不同的任务指令
RT-1:
- 输入:一个简短的图像序列和一个自然语言指令
- 输出:在每个时间步为机器人动作
- 架构
- 图像:an ImageNet pretrained convolutional network conditioned on a pretrained embedding of the instruction via FiLM
- text:Token Learner (Ryoo et al., 2021) to compute a compact set of tokens
- 最后Transformer (Vaswani et al., 2017)来处理这些tokens并生成离散的动作tokens
- action组成
- seven dimensions for the arm movement (x, y, z, roll, pitch, yaw, opening of the gripper)
- three dimensions for base movement (x, y, yaw)
- a discrete dimension to switch between three modes: controlling the arm, the base, or terminating the episode.
RT-1执行闭环控制,并以3hz的频率命令动作
模型结构

整体结构
图像处理 image tokenization
- a history of 6 images
- an ImageNet pretrained EfficientNet-B3 model
- outputs a spatial feature map of shape 9 × 9 × 512
- flatten the output feature map from the EfficientNet into 81 visual tokens
文本信息
- condition the image tokenizer on the natural language instruction in the form of a pretrained language embedding
- first embedded via Universal Sentence Encoder
- This embedding is then used as input to identity-initialized FiLM layers (Perez et al., 2018) added to the pretrained EfficientNet
RT-1's image and instruction tokenization via FiLM EfficientNet-B3 is a total of 16M parameters, with 26 layers of MBConv blocks and FiLM layers, which output 81 vision-language tokens.
TokenLearner
TokenLearner将从预训练的film - effentnet层中产生的81个视觉标记子采样到仅8个最终标记,然后传递到我们的Transformer层
Transformer
与历史张图连接形成48个tokens输入RT-1的Transformer主干
Transformer是一个只有解码器的序列模型,具有8个自self-attention层和19M参数,可输出action tokens
Action tokenization
Loss
standard categorical cross-entropy entropy objective
causal masking in prior Transformer-based controllers
Inference speed
at least 3Hz control frequency
the resulting inference time budget for the model to be less than 100ms
实验
性能评价说明:
- Seen task performance:evaluate performance on instructions sampled from the training set
- Unseen tasks generalization:object and skill会以新的方式组合进行测试
- Robustness:30 real-world tasks for distractor robustness and 22 tasks for background robustness.
- Long-horizon scenarios:多步骤指令,通过 SayCan系统从更高级别的指令自动获得
列出实验结果:






局限
- 它是一种模仿学习方法,它继承了这类方法的局限,例如它可能无法超越演示者的表现
- 对新指令的泛化仅限于以前见过的概念的组合,不能泛化到以前从未见过的全新运动
- 方法使用在一个大但不是很灵巧的操作任务集中,计划扩展指令集解决
2、Robot Learning from Demonstration: A Review of Recent Advances
刊物:Annual Review of Control, Robotics, and Autonomous Systems
Annual Review of Control, Robotics, and Autonomous Systems - 知乎 (zhihu.com)
日期:2020/5/3
关键词
- Keywordslearning from demonstration
- imitation learning
- programming by demonstration
- robot learning
摘要
从演示中学习 learning from demonstrations (LfD)是机器人通过学习模仿专家来获取新技能的范式。当ideal behavior 既不能像传统机器人编程那样轻松编写脚本,也不能轻松定义为优化问题,但可以演示时,选择LfD而不是其他机器人学习方法是compelling的。本调查旨在概述用于使机器人能够向老师学习和模仿的机器学习方法。我们专注于该领域的最新进展,以及现有方法的更新分类和表征 an updated taxonomy and characterization 。我们还讨论了LfD的成熟和新兴应用领域,并强调了在理论和实践中仍需克服的重大挑战。
内容
INTRODUCTION
- 传统方法需要专业编程知识与大量时间投入、明确执行动作与运动顺序
- 运动规划可以减轻一些负担,但需要制定更高级的动作,对环境变化敏感
- LFD从演示中隐式地学习任务约束和需求,从而做出自适应行为,摆脱在受限环境中重复简单的预先指定的行为
- 在不增加负担的情况下学习在非结构化环境中采取最佳行动
- 降低机器人操作专业性门槛
- 在过去的十年里,对机器人教学的研究兴趣一直在稳步增长
- Imitation learning, programming by demonstration, and behavioral cloning为相关关键词
- 只从演示中学习确实会将LfD技术的表现限制在教师的能力范围内
- 为了解决这个问题,LfD方法可以与基于探索的方法相结合 exploration-based methods。
- lfd面临挑战
- 来自机器学习技术方面的挑战:the curse of dimensionality, learning from very large or very sparse datasets, incremental learning, and learning from noisy data.
- 控制理论的挑战:predictability of the response of the system under external disturbances, ensuring stability when in contact, and convergence guarantees.
- 人机交互中的挑战:LfD is not only sensitive to who teaches the robot, but it is also still quite dependent on the platform (robot + interface) used
CATEGORIZATION BASED ON DEMONSTRATIONS
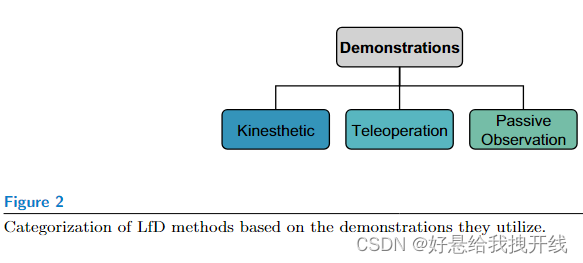
一般来说,演示方法分为三类:
- kinesthetic
- teleoperation
- passive observation

Kinesthetic Teaching
- 应用于操作平台
- 用户物理移动机器人进行所需的运动来进行演示,直观的方法和最低的用户培训要求
- 通过其机载传感器(例如,关节角度、扭矩)记录产生机器学习模型的训练数据
- 在轻型工业机器人在内的机械手中很受欢迎
- 在机器人上记录演示消除了correspondence problem简化了机器学习过程
局限性
- 演示的质量取决于人类用户的灵活性和流畅性,即使是专家数据也往往需要平滑或其他后处理技术
- 因为直观对机械手来说是最有效的,但适用性在其他平台上受到限制,如腿式机器人或机械手
Teleoperation
- 应用于轨迹学习、任务学习、抓握和高级任务
- 已经探索了广泛的接口,包括触觉设备和VR接口
- 遥操作可以应用于更复杂的系统
- 远程操作可以很容易地与模拟相结合,以进一步促进大规模的数据收集和实验,这在强化学习(RL)框架中是经常需要的。
Passive Observations
- 用户使用自己的身体执行任务,有时由额外的传感器检测以促进跟踪
- 机器人不参与任务的执行,充当被动观察者。这种类型的学习,通常称为模仿学习 imitation learning
- 对演示者来说特别容易,适合应用于动觉教学困难的高自由度或非拟人化机器人
- 由于需要学习从人类动作到机器人可执行动作的映射而变得复杂
- 遮挡、快速运动和传感器噪声对这类任务演示提出了额外的挑战
- 成功应用于各种任务,例如协同家具组装、自动驾驶、桌面动作和打结
Active and Interactive Demonstrations
CATEGORIZATION BASED ON LEARNING OUTCOME

- LfD方法的学习结果取决于对感兴趣的问题选择合适的抽象级别
- 选择要追求的学习成果取决于任务和相关的限制
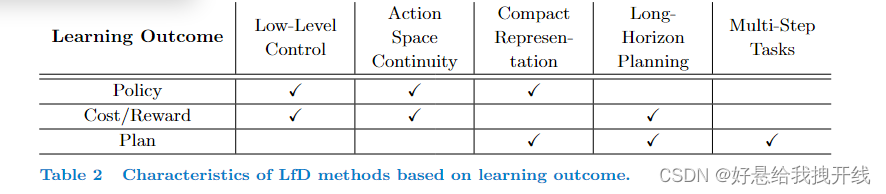
Learning Policies from Demonstrations
- 该方法假设存在一个direct and learnable的function(即policy)来产生期望的行为
- 将策略定义为将可用信息映射到适当操作空间 an appropriate action space 的函数
- 表示为
- 目标是学习一个策略π(·),该策略生成的状态轨迹{x(t)}与专家演示的状态轨迹相似
- 对抗性学习adversarial learning 和逆强化学习 (IRL) 之间的联系被用来提出生成对抗性模仿学习 generative adversarial imitation learning (GAIL)
- GAIL 不能归类为 IRL 算法,因为它不学习奖励函数。GAIL 可以被认为是一种策略学习算法,因为它直接从演示中学习策略。
Policy learning methods分类:
Policy input
输入必须充分捕捉生成最佳操作所需的信息


time
- 将时间映射到适当的动作空间,这种方法的演示由时间-动作对组成
- 基本假设:可以主要基于初始条件和当前时间采取最佳行动,而不依赖于额外的反馈
- 基于时间的策略类似于开环控制器,因为它们不依赖于来自策略的输出或状态的反馈
- 已被证明能够识别和捕捉锚定在时间中的重要特征
- 时间为主要输入可以利用异方差随机过程 heteroscedastic stochastic processes 或几何结构geometric structures 来确定重要的时间约束
- 有助于推广到涉及不同初始、最终和通过点的新场景
- 被用来编码多个模态之间的相关性
- 显著限制是对扰动缺乏鲁棒性,仅限于由时间驱动且系统不会受到意外扰动的情况
State
- 状态的各种选择:末端执行器位置,速度,方向,力,关节角度和扭矩
- 基本思想:在任何给定时刻,状态都是关于机器人的反馈,有时是关于任务的反馈,对应于闭环控制器
- 需要由状态-动作对组成的演示
- 状态信息可以隐式地或显式地包括时间
- 构成状态的内容通常是手动指定的
- 当一个合适的状态空间不是先验已知的时通过无监督或有监督的方式对合适的状态空间进行学习
- 将状态空间直接映射到适当的动作空间来为各种技能提供紧凑的表示
- 基于状态的策略可能取决于高维输入空间更复杂
- 稳定性比基于时间的系统更难证明和实现
Raw observations
- 将原始观察映射到动作,不依赖于简洁的输入表示,通常称为端到端方法
- 需要可以近似复杂关系的函数,需要大量的计算资源。
- 当学习简洁的输入表示未知或不存在的任务时,这种方法特别有用
- 需要大量的数据和计算资源才能进行训练
- 理论保证的推导非常具有挑战性,阻碍了端到端方法在安全关键应用程序中的使用
- 在难以获取标记数据的情况下受限
Policy output

Trajectory learning
- 从演示中提取模式patterns 来编码感兴趣的某些变量的轨迹
- 例如末端执行器位置、末端执行器位姿、末端执行器力和关节状态。
- 再现技能根据初始状态和某些情况下的当前状态生成轨迹
- 轨迹学习方法
- dynamical systems:假设所演示的轨迹是动力系统的解
- probabilistic inference:假设所演示的轨迹表示底层随机过程的样本,通过在可能以初始、通过和最终点为条件的轨迹中的已学习到的分布进行采样来获得再现
- 依靠低级控制器来执行生成的参考轨迹,适合于过度驱动的系统,如冗余机械手,其运动学可行性相对容易实现
- 不需要机器人动力学知识,也不需要重复的数据收集
- 可以在关节空间和操作空间中实现
- 关节空间中,学习到的策略取决于机器人的运动链,不能直接转移到其他机器人系统
- 在操作空间中的学习不能保证生成的运动是可行的,并且不能保证避免奇点
Learning low-level actions
- 直接生成适当的低级别控制信号(如关节转矩)
- 映射到机器人动作空间action space的方法的一种常见做法是从LFD策略推导出速度/加速度,通过逆动力学模型将它们转换为关节力矩等命令
- 另一种方法是直接学习每个状态下必要的关节力矩/力,这也允许调整阻抗参数,从而产生柔顺控制
- 研究集中在学习产生柔顺运动所需的扭矩和刚度参数
- 难以获得准确的力和扭矩演示、确定柔顺轴和估计机器人的物理属性
- 模型依赖于机器人的物理特性,由于任务中的磨损变化,物理特性很可能会发生变化
Policy class
根据策略所属的数学函数类型来分类


Deterministic vs stochastic policies 确定性策略和随机策略
- 选择依据:给定一个特定的上下文,演示代表
- i) 单一或绝对理想行为,或
- ii) 来自理想行为分布的样本
- 确定性策略假设每种情况下都存在单一的最优操作,并试图从演示中学习此类最优操作
- 这些策略产生可预测或可重复的行为,为性能提供了强有力的理论保证
- 例如全局渐近收敛 global asymptotic convergence
- 随机策略在每次执行期间从学习到的行为分布中对行为进行采样
- 符号表示:
,P表示条件概率
- 优点是能够捕捉内在的不确定性
- 例如,当绕过障碍物时,停留在障碍物的右侧或左侧可能同样是最佳的
- 确定性策略不能捕获不确定性并且必须解决看似冲突的路径
- 确定性策略可能会导致不安全的行为,例如遍历平均路径,这将导致碰撞
- 最近提出了随机策略的理论保证,例如概率收敛
Time-dependent vs invariant policies 时间相关策略与不变策略
- 可以根据策略的平稳性 the stationarity 对策略类进行细分
- 与时间相关的政策除了任何其他形式的反馈还依赖于时间
- 能够捕获随时间变化的策略
- 例如,与时间相关的策略确保复制的行为与速度和持续时间方面的演示一致
- 时不变策略能够捕获独立于时间的一般策略,对间歇性时空扰动更加稳健
- 例如,在再现到达运动时,时不变方法对运动中的中断更加稳健,因为它们不必依赖于内部“时钟”并且可以依赖于状态反馈
- 某些时不变策略,如DMP(100),对时间有隐含的依赖性
- 可以使用相位变量来捕捉行为的顺序相关信息
- 而相位变量不需要与实际演示时间同步
3.2. Learning Cost and Reward Functions from Demonstrations
- 这一类的方法假定理想行为源于一个优化隐藏函数,即成本函数或奖励函数
- 目标是从可用的演示中提取隐藏函数
- 随后,机器人通过优化已识别的函数来复制学习到的行为
- 学习成本或奖励函数需要对任务和环境做出某些假设

3.2.1. Trajectory optimization
- 假设专家在展示技能时最小化隐藏成本函数,演示被视为最优解用于推断潜在的成本函数
- 实现这种推断,通常的做法是假设隐藏成本函数采用某种参数形式,其参数是从演示中学习的
- 形式的选择基于与任务相关的假设
- 例如,演示和复制可以被视为最小化希尔伯特范数
- 形式的选择基于与任务相关的假设
3.2.2. Inverse reinforcement learning
- 假设演示者优化未知的奖励函数,学习隐藏的奖励函数,然后使用经典的强化学习方法来计算最优行动
- 其中最优控制的隐藏目标函数是根据演示估计的
- 非常类似于逆最优控制(IOC)
- 可能有多个奖励函数可以最佳地解释可用的演示,因此IRL被称为“不适定” "ill-posed" 问题
- 为了获得唯一的奖励函数,IRL方法考虑不同的附加优化目标,例如最大裕度 maximum margin 和最大熵 maximum entropy
- 基于最大裕度的IRL中,通过最大化最佳策略与所有其他策略之间的差异来识别奖励函数
- 基于最大熵的IRL识别了一种分布,该分布在约束下最大化熵,并关于特征期望匹配,以确保再现与演示相似
- 为了获得唯一的奖励函数,IRL方法考虑不同的附加优化目标,例如最大裕度 maximum margin 和最大熵 maximum entropy
- 根据假设的先验知识,IRL的机器人学习方法可以进一步分为基于模型的方法和无模型的方法
- 基于模型的IRL方法利用转移概率(即系统模型)来确保奖励函数和策略被准确更新。
- However, the system model might not always be available.
- 无模型IRLZ方法利用基于采样的方法来恢复奖励函数
- 具体技术包括最小化基线策略 baseline policy 和学习策略的状态-动作轨迹分布之间的相对熵 relative entropy,直接搜索策略;在奖励和策略之间交替优化
- 比较表明基于模型的方法具有许多计算优势
- 基于模型的IRL方法利用转移概率(即系统模型)来确保奖励函数和策略被准确更新。
3.2.3. Limitations.
- 学习成本或奖励函数可能对次优演示很敏感
- 函数的结构选择显著影响性能,这种选择往往取决于感兴趣的任务
- 继承了学习来的函数的局限性,例如需要大量episodes才能收敛 (127) 和难以推导出的转换模型的存在
3.3. Learning Plans from Demonstrations
- 假设感兴趣的任务是根据由几个子任务或原始动作(即任务计划)组成的结构化计划执行
- 任务计划编码子任务中的模式和约束,将机器人从初始状态带到目标状态。给定任务的当前状态,任务计划在一组有限的子任务中提供最合适的子任务来执行下一个
- 复杂的任务连续演示,包含相互依赖和约束的子任务
- 因此,分割在任务计划学习中起着至关重要的作用
- 基于组件子任务的相似性
- 基于指示事件的出现
- 任务计划通常包括每个子任务的前置条件和后置条件
- 包括前置和后置条件的任务计划用于生成每个子任务的操作
- 从演示中学习任务计划的方法可以学习基元序列 primitive sequence or a primitive hierarchy
- 基序列表示任务中涉及步骤的简单排序和相关约束
- primitive hierarchy结合了高级结构化指令,并提供了一个可以捕获变量排序 variable sequencing 和非确定性的计划
- 例如层次 hierarchy 结构可用于捕捉某些子任务可以按任何顺序执行的事实
3.4. Pursuing Multiple Learning Outcomes Simultaneously
追求多种学习结果可以在多个抽象层次上学习复杂行为。
一些研究所采用的方法
4. APPLICATIONS OF LFD
4.1. Manipulators
Manipulators are perhaps the most popular application platform for LfD methods.、
Manufacturing
- 自80年代以来,LfD已被研究用于教授机械手与制造相关的各种技能。
- 在制造应用中引入演示的最常见方法是通过动觉教学 kinesthetic teaching
- 学习目标是低水平轨迹的情况下,使用policy learning方法
- 学习高级动作序列(如装配任务中涉及的步骤)的情况下,可以从演示中学习plan
- 当预计会出现干扰时使用基于状态的策略
- 当任务涉及时间敏感约束时使用基于时间的策略
Assisting and Healthcare Robotics
提出了对安全运行的要求,可以通过提供学习策略的收敛性和稳定性保证来满足这一要求
Human-Robot Interaction (HRI)
- 有效的协作需要产生所需的机器人运动,这些运动与人类的运动互补
- 通过观察人与人之间的互动来教导manipulators如何与人类伙伴合作,从而提高合作的流畅性和安全性
- 此类应用需要能够补偿机器人操作期间发生的扰动的LfD方法
- 最常见方法是通过学习一个策略函数,其输入是机器人的状态
- HRI应用还提出了对柔性机械手的需求,通常学习适当的关节扭矩、刚度和阻尼参数
4.2. Mobile Robots
Ground Vehicles
此类平台的演示通常通过小型车辆的操纵杆远程操作提供。动觉教学可以应用于大型交通工具,如汽车,其中人类坐在驾驶员座位上,并通过驾驶表现出期望的行为
Aerial Vehicles
LfD已被证明在教导飞行器在混乱环境中导航方面是有效的
训练飞行机器人的演示通常通过远程操作来完成。因此,训练主要用于教授所需的轨迹,而机器人的稳定性则由传统的控制方法来处理。
Bipedal and Quadrupedal Robots
LfD方法已成功用于两足机器人学习行走和步态优化
训练两足机器人的演示可以通过远程操作或观察引入,其中人类演示者的步态可以通过适当的传感器捕获,并通过导出对应映射传递到机器人
Underwater Vehicles
5. STRENGTHS AND LIMITATIONS OF LFD
5.1. Strengths of LfD
不同类型的LfD算法提供了不同的好处,使其适用于不同的场景和问题
Non-expert robot programming
- LfD已经成功地解决了optimal behavior can be demonstrated的问题
- 不一定要以数学形式(例如,奖励函数)简洁地指定
- 使机器人的编程变得更容易
Data efficiency
- 许多LfD方法通常从少量的专家演示中学习
- 轨迹学习方法通常使用少于10个演示来学习新技能
- 高水平任务学习已被证明只需一个演示即可实现
- 由于RL方法采用“试错” trial-and-error 方法来发现最优策略,因此它们的效率往往明显低于利用专家演示的LfD方法
- LfD的这一性质有助于解决高维状态空间中的问题
- LfD可以与强化学习相结合,以提高样本效率
Safe Learning
- 专家演示可以更好地激励机器人呆在状态空间的安全或相关区域内
- 演示提供了一种评估与状态空间区域相关的安全性或风险的方法
- 几种LfD方法用与状态空间的不同部分相关联的不确定性度量向用户传达系统的置信度
- 学习如何与人类用户交互
Performance guarantees
可以通过为算法一致且成功地执行任务的能力提供理论保证
例如,许多基于动力学系统的轨迹学习方法提供了强大的收敛保证
Platform independence
利用专家演示学习与平台无关的策略、成本函数和计划
例如,dynamical movement primitives(DMP)算法已被用于各种平台,包括机械手、机械手、类人机器人和飞行器
5.2. Limitations of LfD
Demonstrating complex behaviors
需要这些空间之间存在映射,但由于两个系统在运动约束和维度方面的差异,这可能很难实现
捕捉演示的感知系统继承了与计算机视觉相关的局限性,如遮挡、姿态估计和噪声
Reliance on labeled data
Sub-optimal and inappropriate demonstrators
6. CHALLENGES AND FUTURE DIRECTIONS
由于演示很少涵盖问题空间的所有部分,机器人可能会发现输入与演示场景不同。这导致了一种被称为变量偏移 covariate shift 或误差复合的现象compounding of error
一种避免错误复合的解决方案利用与用户的交互来获得纠正演示
我们需要能够将所获得的信息外推到新场景的学习方法,更重要的是,估计所学习的Policy对新场景的适用性
与泛化相关的另一个关键挑战涉及the selection of the hypothesis class(the set of all possible functions that we consider when learning)的
目前尚不清楚如何系统地选择给定技能或一组技能的假设类别以帮助有效解决偏差-方差权衡问题bias-variance trade-off
Hyper-parameter selection
建模高度非线性的关系可能需要大量的隐藏单元,而不太复杂的关系需要更少的单元
基于DMP的方法的一个重要超参数是径向基函数(RBF)的数量。高度非线性的运动需要对更多的RBF进行建模。然而,如果演示的运动并不复杂但使用了相对大量的RBF,那么模型也会捕获演示中引入的噪声,从而导致过度拟合
状态-动作表示通常被建模为高斯混合模型(GMM)。在GMM中,与上述情况类似,高斯分量数量的选择会影响估计函数的复杂性
Evaluation and Benchmarking
Other Challenges
- Appropriate distance metric to minimize during reproduction
- 所有方法,无论以何种方式,都旨在最大限度地减少机器人行为与演示者行为之间的距离
- 选择用于计算距离的度量至关重要。最广泛使用的距离度量是欧几里得距离。然而,可能存在其他更适合给定任务的距离广义定义
- Simultaneous learning of low- and high-level behaviors.
- 设计用于学习高级任务计划的方法通常假设低级基元是先验已知的并且是固定的
- 而原始的学习方法忽视了高级任务目标的存在
- Learning from multi-modal demonstrations.
- 当我们向他人学习时,我们会利用各种多模态信息,包括语言和非语言线索
- 当前的多模态LfD方法仅限于从少量预先指定的模态中学习
- Learning from multiple demonstrators and cloud robotics.
- 大多数算法都假设有一个最优函数,但在有多个演示者的情况下,这种假设并不成立。不同的演示者往往有不同的优先级和最佳行为的定义
- 重要的是要将技能的重要组成部分与演示者的特质区分开来
- 这在云机器人的环境(多个演示者可以提供相同技能的演示)很重要
- 研究表明,与向单个演示者或具有类似专业知识的演示者学习相比,从不同专业知识水平的演示中学习可以暴露出更丰富的奖励功能和结构
- 大多数算法都假设有一个最优函数,但在有多个演示者的情况下,这种假设并不成立。不同的演示者往往有不同的优先级和最佳行为的定义

