
- 1YOLOV7学习记录之模型推理_yolov7推理
- 2CSS3 立体 3D 变换
- 3详解YOLOv5网络结构/数据集获取/环境搭建/训练/推理/验证/导出/部署_yolov5如何配置结构
- 4Android Studio 搭建离线开发环境_androidstudio离线配置环境
- 53ds Max2024安装包(亲测可用)
- 6MindManager2023中文版本思维导图_mindmanager 2023 license key
- 7Android MTK 设置默认启动 Launcher,字节跳动学习笔记_pm.gethomeactivities
- 8php、redis实现分布式锁的正确写法(原子操作 通用类 加讲解)_php使用redisson
- 9字典树&&AC自动机---看完应该会...了...吧_字典树和ac自动机
- 10现在互联网都在裁员,2023届的计算机毕业生秋招还有戏吗?_如今还有工作机会吗?大厂们都纷纷裁员了
异步联邦学习-能耗:Energy-Efficient Dynamic Asynchronous Federated Learning in Mobile Edge Computing Networks
赞
踩
异步联邦学习
Energy-Efficient Dynamic Asynchronous Federated Learning in Mobile Edge Computing Networks
移动边缘计算网络中具有节能特性的动态异步联邦学习
会议:2023 IEEE International Conference on Communications (ICC): Green Communication Systems and Networks Symposium
原文链接:https://ieeexplore.ieee.org/document/10278887
一、摘要
为了打破数据孤岛并解决绿色通信的挑战,联邦学习(FL)被广泛应用于移动边缘计算(MEC)网络中,用于在网络边缘训练深度学习模型。然而,许多现有的FL算法并未充分考虑动态环境,导致模型收敛较慢且训练能耗较大。在本文中,我们设计了一个动态异步联邦学习(DAFL)模型,以提高MEC网络中FL的效率。具体而言,我们根据它们的到达顺序动态选择一定数量的移动设备(MDs)参与每个时期的全局聚合。与此同时,我们分析了本地更新和上传更新的能耗模型,并将问题制定为一个NP-hard的动态顺序决策问题,以最小化能耗。为了解决这个问题,我们提出了一种基于深度强化学习的能效算法,命名为DDAFL,根据每个时期MEC网络的状态智能地确定参与全局聚合的MDs的数量。与基准方案相比,所提出的算法可以显著降低能耗并加速模型收敛。
二、文章贡献
1.具体使用场景
大背景是在移动边缘计算场景。
2.贡献
主要有两个贡献:
- 本文在移动边缘计算网络中设计了一个DAFL模型,并分别对本地更新和上传更新的每个阶段进行能耗分析,以有效提高FL的效率,以期迎接未来绿色MEC网络。【基于FedAsync设计DAFL模型的启发,以适应MEC网络的动态环境。与FedAsync不同,DAFL能够有效解决模型收敛的困难】
- 本文提出了一种能效强化学习(DRL)算法DDAFL,智能地根据MEC网络在每个时期的状态确定参与全局更新的MDs数量,以显著降低能耗。【提出了一种节点选择策略】
三、系统模型和优化问题
1、文中图1是系统模型,包含A,B,C,D四个常规步骤:

2、动态异步联邦学习模型
(1)该模型考虑了由于设备计算资源的差异,不同的移动设备对全局更新的贡献也不同,具有强大计算能力和低能耗的MD应更频繁地参与全局更新。【这在联邦平均算法中也是常规的考量】参数聚合公式:

(2)此外,在MEC网络中存在其他不稳定因素(如网络拥塞和设备离线),本文需要根据网络状态动态调整ES执行全局更新的策略。【设定了固定更新时间】

3、能源消耗模型
能源消耗分为本地能源消耗、传输能源消耗
(1)本地能源消耗:移动设备的计算能力可以用每秒CPU周期数来衡量,原文:


(2)传输能源消耗:

四、提出一种算法设计
1、深度强化学习的制定
为了节约训练过程中的能源消耗,本文使用深度强化学习(Deep Reinforcement Learning, DRL)来决定nt的值,即需要上传的客户端数量。图三展示了DRL的结构,其中代理(agent)从环境中感知状态,然后输出相应状态下每个动作的值。根据策略 π,代理选择一个具有最大值的动作 a_t 进行执行,并接收奖励 r_t。

原文解释:

译文:

解读:当d=0时,代表了不带折扣因子的即时奖励,后续奖励都带有折扣因子。这里我还有不太理解的地方,即后续奖励是如何计算的
DRL算法详解:

由于缺少深度强化学习知识,我对这波解释没看懂,qaq
2、本文所提算法的训练,DDAFL
本文使用深度 Q 网络(DQN)对强化学习代理进行训练。本文使用深度 Q 网络(DQN)对深度强化学习代理进行训练,其中深度神经网络(DNNs)被设计用于估计值函数的近似值 Q(s_t, a;θ),其中θ是神经网络的参数。实际上,DNNs 可以被看作是一个策略 π(s_t | a;θ) = max_a Q(s_t, a;θ)。策略 π 被持续更新,以便代理可以在状态 s_t 中采取更有价值的动作 a_t。这一部分着重讲了各模块是如何互相配合运行的。【有点没理解透,回头补习补习深度强化学习方面的知识】
五、实验
实验基于TensorFlow进行
基本设置
考虑了四个方面的设置:评估设置、数据集和模型、性能指标、基准比较。在基准模型的比较重,引入了两个基准模型,FedAvg和FedAsync。
1、收敛性
本文首先考虑训练代理的收敛性能,该训练在7个移动设备(MDs)上进行,共进行了200个episode。图四左图是损失函数值曲线,右图是奖励曲线。图五左图是损失值函数曲线,右图是准确率曲线。从下图中,文章得出结论,所提出的DAFL可以加速联邦学习模型训练的收敛。
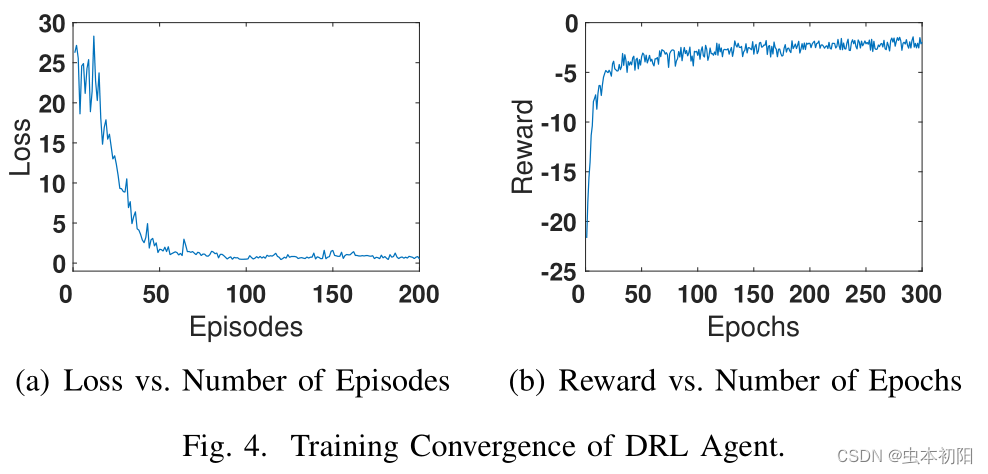
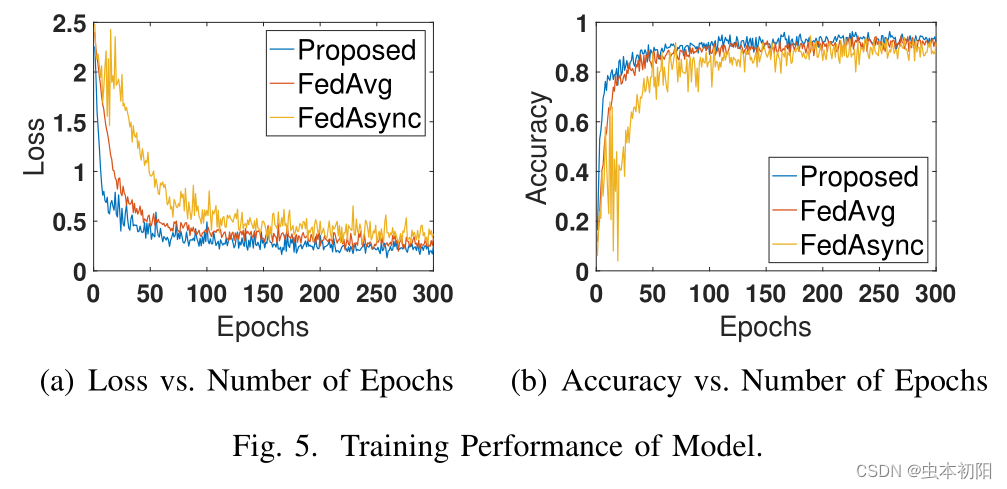
2、能耗
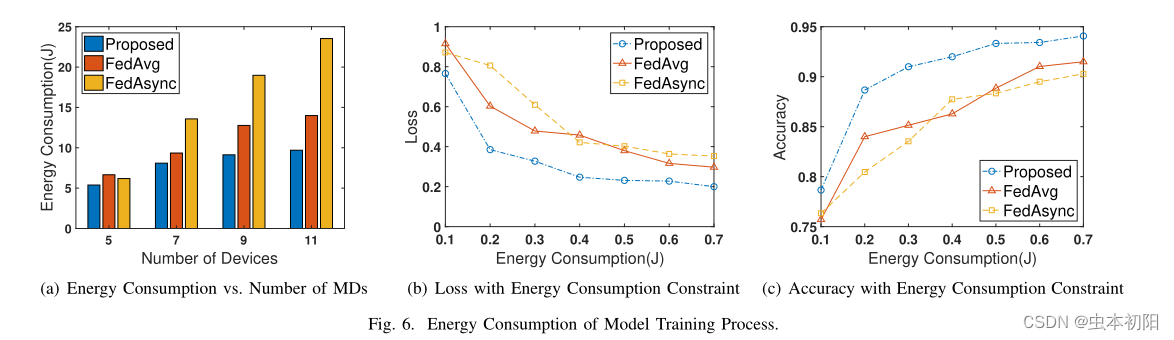
下图展示了能耗相关的数据。不仅与其他两种基准方案作比较,还比较了自身能耗随着设备数量变化的情况。
六、总结
译文:在本文中,我们设计了一种在MEC网络中有效提高联邦学习(FL)效率的DAFL模型。具体而言,我们从本地更新和上传更新的角度分析了能量消耗,并将优化问题制定为一个动态顺序决策问题,以最小化能量消耗。为了解决制定的问题,我们进一步提出了一种基于能效的强化学习算法DDAFL,根据MEC网络在每个时期的状态智能地确定参与全局聚合的移动设备(MDs)数量。模拟结果表明,与考虑的基准方案相比,所提出的算法可以显著减少能量消耗并加速MEC网络中的FL模型收敛。在未来,我们将进一步研究MEC网络中的层次聚合问题。

