
- 1今天给大家分享几款非常好用的下载工具
- 2YOLOv5改进系列目录
- 3Datasophon升级doris版本为2.0.1_please set the maximum number of open file descrip
- 4如何编写一个易于维护的考试系统源码_云帆考试源码
- 5iOS最新外部符号加载
- 6MPU6050 获取角度理论推导(三)---9轴融合算法
- 7【AI视野·今日NLP 自然语言处理论文速览 第七十五期】Thu, 11 Jan 2024_can chatgpt rival neural machine translation? a co
- 8基于Git与Tortoisegit的Gitee(码云)手把手入门教学_giteee
- 9推荐一个优质Linux技术公众号-作者都是一线Linux代码贡献者们哦
- 10《数据仓库快速入门》_数据仓库 入门教程
追赶ChatGPT的难点与平替
赞
踩
卷友们好,我是rumor。
最近ChatGPT真的太火爆了,让人很难静下心。一方面是对它的能力感到不安,以后各个NLP子任务可能就统一起来了,范式也会变成预训练+Prompt,不需要那么多精调模型的算法了。另一方面是对国内复现ChatGPT感到悲观,那么大的模型,真的需要很强的决心,投入足够的人力、财力和时间才能做出来。
调整了几周,终于回归开卷的心态,捋了一遍我认为复现ChatGPT的难点与平替方案。由于个人精力有限,以下调研肯定存在纰漏,欢迎大家一起讨论补全。
难点1:高效率的算法框架
大模型的训练并不如想象那样容易,需要一个强大的工程框架进行支持。参数量上去之后,需要把模型和数据分散放到多个GPU卡,卡之间如何通信、调度,进行高效的反向传播,都有很多坑等着大家去踩。就像前几年,即使阿里的技术那么强,双十一流量上来了也得崩一会。而且算法框架一旦出现bug,模型可能都收敛不了,或者效果上不去。同时,训练效率非常重要,可以极大地降低试错成本。
知道了训练框架的重要性后,我们再来看OpenAI做到什么地步:
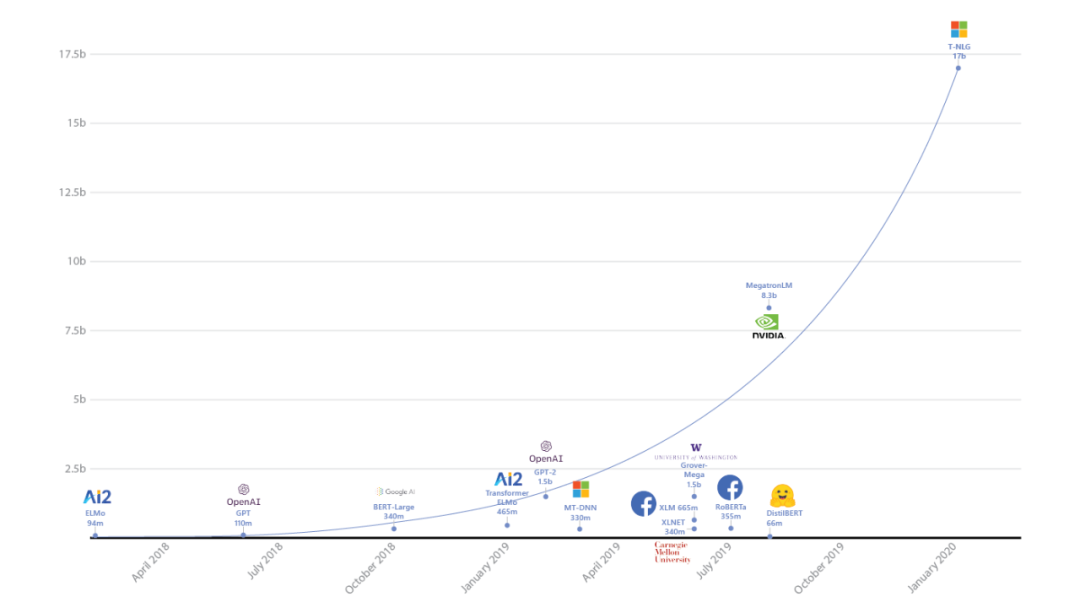
早期的从业者一定对这张图有印象,当时Megatron-LM和DeepSpeed已经把模型提到了一个我们不敢想的尺寸(普通算法团队人均2张V100就很幸福了),结果20年中OpenAI一下发布了175B的GPT-3。从那时起,OpenAI算法框架的容量就领先了一到两个数量级。
好在大厂们在近两年的大模型竞赛中都迭代出了自己的框架,不过这次,强化学习范式RLHF的加入又给训练框架带来了新的挑战。我去年大概花了4个月的业余时间去做强化学习项目和打比赛,有两点让我十分痛苦:
动不动就训崩了,在奖励很稀疏或者自己魔改奖励的情况下,模型往往走捷径往意想不到的地方发展。
不同的框架往往给出不一样的结果,开源框架百花齐放且不一定靠谱,我自己就前后换了3个。跟业内三个RL同学交流下来他们公司都选择了自研而不是用开源的,不像NLP一样大家都用transformers。
好在这次的奖励是连续的,损失函数也明确给出来了,而且基础PPO的复现门槛也没有那么高。
更好的消息是,最近已经出了一个平替方案ColossalAI[1],由国人打造,从一些介绍来看效率是超过Megatron-LM和DeepSpeed的,而且已经做了ChatGPT的部分实现(还不支持PPO-ptx),接下来就看大家使用的效果了。
难点2:先追上GPT3
从符尧大佬对于ChatGPT能力起源的追溯来看,一个好的预训练模型会涌现出诸多能力:
上下文学习能力(In-Context Learning):可以不经过精调直接理解输入的指令和示例
长距离理解能力:是之后多轮对话的基础
具有常识知识、并可以进行推理
跨语言能力
代码生成能力
而且从符尧另一篇对大模型能力的研究看来,至少要62B以上的模型才能有一定少样本效果。真的追上这些能力需要耗费很大财力、人力和时间,估计现在各个厂都在批发A100了,起码千张,预算上亿。
好在也有一些平替方案,支持中文的有mT5(176B)、GLM(130B)和BLOOM(176B),但其中只有BLOOM是GPT架构。另外还有mT0和BLOOMZ,是Instruction tuning后的版本。
难点3:获取真实的用户输入
从GPT3到ChatGPT,主要是基于用户的真实输入进行标注,再对模型进行精调,从而拟合了人的偏好(称为Alignment)。
所以前段时间让我最焦虑的就是它的马太效应,或者数据飞轮,它效果越好,用的人越多,从而不断帮它提升拟合效果。技术问题都有平替,但我们去哪儿找上亿的用户来源源不断的输送Prompt呢?
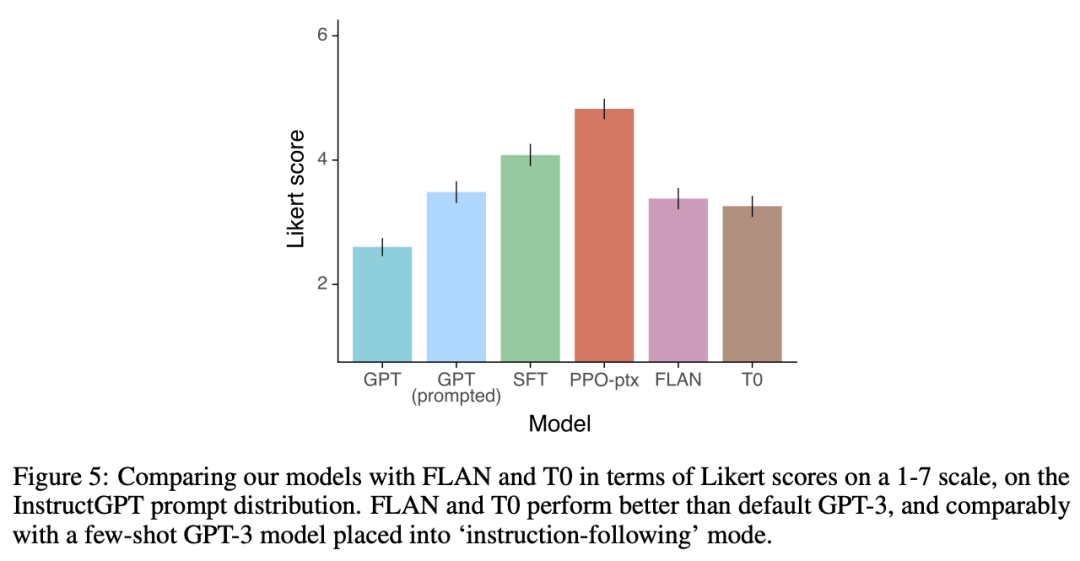
第一个平替方案,是借鉴Instruction tuning的论文,用各种NLP数据集构造Prompt。但这并不是最优解,因为InstructGPT也做过这个实验,用FLAN和T0的数据进行精调,效果如下:
如果要做通用模型,最好还是符合用户的分布,可以看到InstructGPT的分布统计:
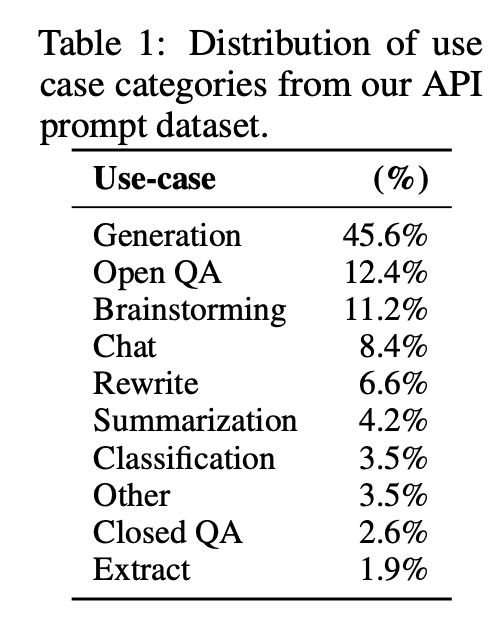
看到真实分布后,我的焦虑缓解了一些,感觉还是可以找到冷启动平替的。首先占比最高的生成任务,很多预训练模型都可以做,比如写诗写故事,大家之前应该见过很多了,刚开始不一定需要特别去优化。其次就是OpenQA,这个有不少数据可以爬,比如百度百科、知乎。头脑风暴可以通过关键词在爬到的问答数据中筛选。剩下几个任务有些是传统NLP任务,也有开源数据集。
难点4:趟过精调的坑
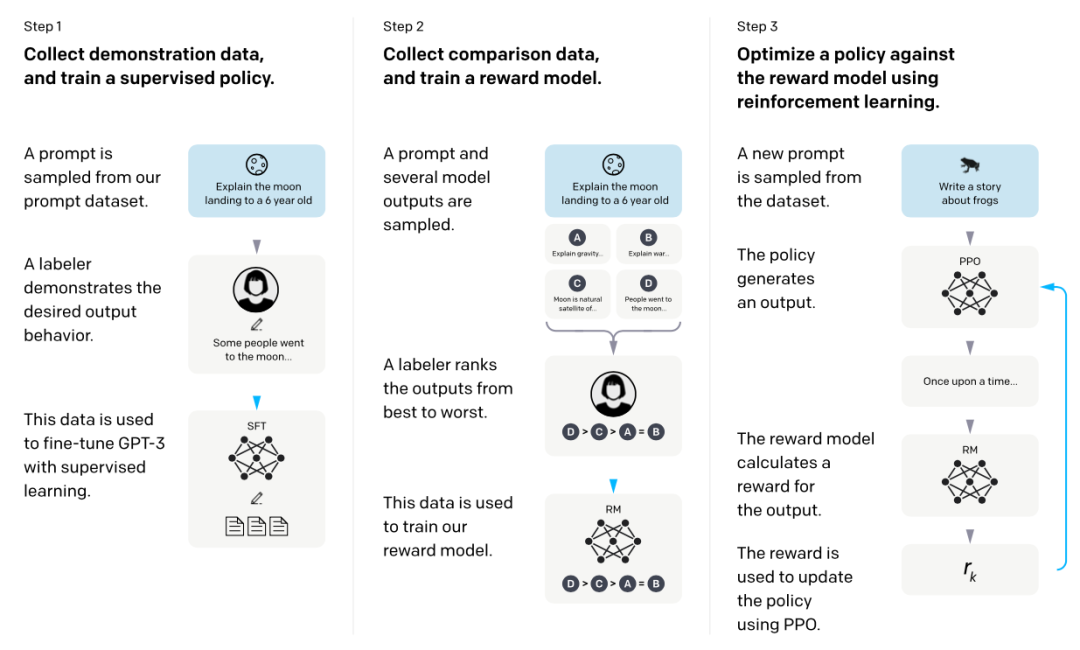
对于精调,OpenAI分了两个步骤:有监督精调(SFT,下图step1)、强化学习训练(RLHF,下图step2+3)。
虽然有看到一些观点,认为不用RL,有更好的监督数据也可以做ChatGPT,甚至RL+NLP近年来一直不被看好[2],但最近回顾了OpenAI在20年和22年的两篇RLHF文章之后,个人认为ChatGPT精调的重点在于RLHF阶段。
举个不一定恰当的栗子,假设我们把训模型当作带孩子:
Pretrain:在孩子0-3岁的时候,我们没法讲太多道理,他也听不懂,更多的是让他自己观察这个世界,自由学习。
Instruction Tuning:孩子学会说话了,也对世界有了基本认知,我们就可以开始通过示范教他一些东西,比如怎么穿衣服、怎么刷牙。
RLHF:等孩子再大点,很多事情都会了,便不会再完全模仿父母,而是有自己不一样的行为,这时候父母就需要对这些不可预料的行为给出反馈,在他取得好成绩时奖励,在做坏事后惩罚。
再回到生成任务本身,长久以来NLP里的范式都是以最大似然为目标,用teacher forcing的方式拟合标注同学写出的句子。那万一标注同学偷懒呢?
对于「到底什么是好的回复」这个问题,每个人都有不同的答案,但必须定义好目标,才知道模型应该往哪里优化。谷歌训LaMDA对话模型时就给出了5个维度的定义,再朝着这5个方向拟合,而人类语言博大精深,5个维度真能评价一段话的好坏吗?
RLHF范式的关键就在于,它能真正让模型去拟合人的偏好,同时给予模型一定的自由度,这样才能让模型先模仿再超越,而不是重复Instruction tuning中的一些pattern。
上述的说法可能比较主观,接下来让我们看OpenAI官方给的实验数据:
在摘要生成任务中,RLHF精调后的模型大幅超越SFT的效果。另外论文中的其他实验也证实了RLHF模型具备更好的跨领域泛化能力:
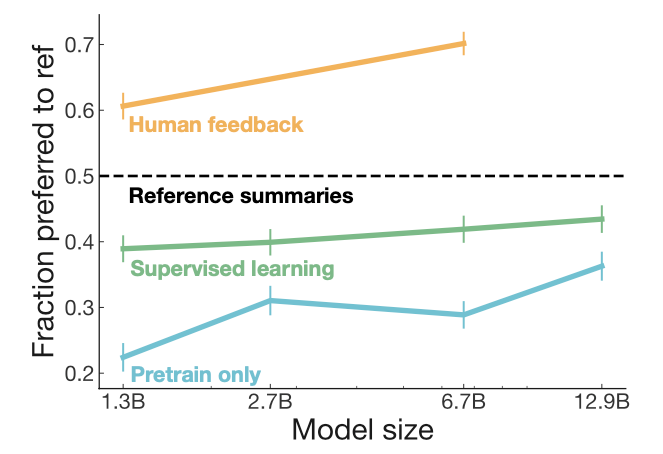
在InstructGPT论文中,1.3B经过RLHF的模型可以超过175B模型SFT的效果:
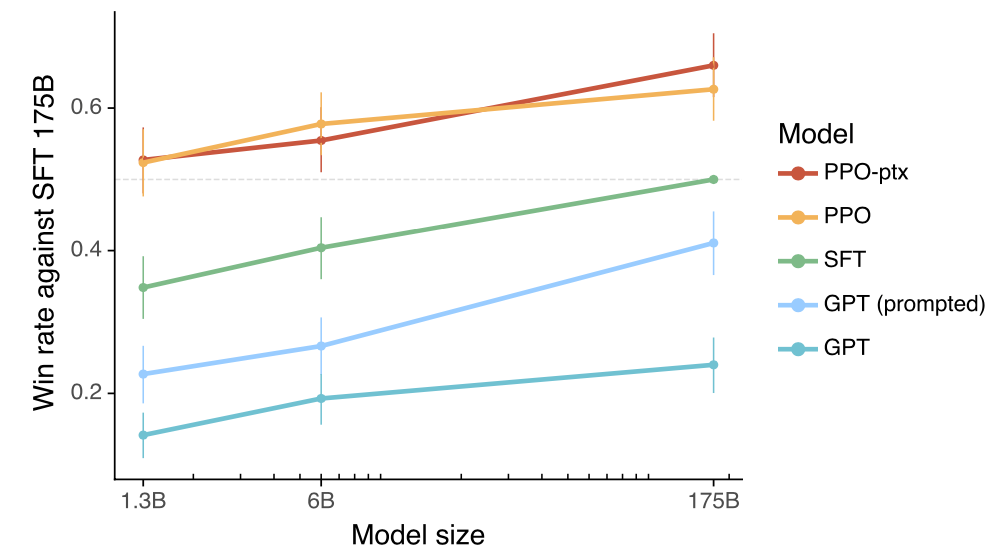
从上述结果可以猜测,在人力、算力、时间有限的情况下,效率最优的路径是直接在1.3B模型上迭代,大概10万标注数据,复现一个低配小型ChatGPT,验证整个流程的有效性,再去做175B的模型。
遗憾的是目前RLHF这个部分趟过坑的人太少,没法找到平替,我只想到了用小模型快速迭代的方案,接下来的踩坑就看大家了。
另外,关于为什么以前一些RLHF工作不work,我认为关键的点是:
这篇工作[3]的标注同学更倾向抽取式答案,模型学偏了,而OpenAI这次在标注上下了狠功夫。另外该工作是用人作为RM,效率较低。
DeepMind Sparrow[4]其实只在某个对话数据集上进行了训练,和真实分布不一样,另外它加入的Rule Reward可能也有影响。目前我觉得核心还是没在数据上下狠功夫,就是简单follow了一下OpenAI。但该论文有70多页,我实在读不动了,之后会不时重读刷新认知。
总结
在上文中,我列了4条我认为复现ChatGPT的难点,与一些替代方案,如果每个方案都打个折,确实是复现到60%的程度,和业内乐观的预测一样。
另外,我其实一直没提标注数据的重要性,因为标注数据的平替非常容易,直接跟老板要预算去调OpenAI接口吧。不过OpenAI论文里有一句话我特别喜欢,希望自己在以后做模型的时候谨记:
We train all labelers to ensure high agreement with our judgments, and continuously monitor labeler-researcher agreement over the course of the project.
得先训练好标注同学,才能训好模型,请所有人跟我默念三遍(狗头。
最后,和大家分享使我焦虑下降的两个点:
OpenAI最新一篇博文显示[5],他们后续的方向之一是在通用模型上做定制化模型,我估计不会失业了,又可以洗数据了。
自从发现1.3B的模型+RLHF就可以很强之后,我觉得在真正的落地中,训一个for单一生成任务的定制化ChatGPT不再那么遥不可及,一两张A100和十万级别的数据就可以了(可能过于乐观,但我就是经常在热血和焦虑之间横跳)。
参考资料
[1]
ColossalAI: https://github.com/hpcaitech/ColossalAI
[2]知乎:当前(2020年)机器学习中有哪些研究方向特别的坑?: https://www.zhihu.com/question/299068775/answer/647698748
[3]Fine-tuning language models from human preferences: https://arxiv.org/abs/1909.08593
[4]Sparrow: https://www.deepmind.com/blog/building-safer-dialogue-agents
[5]How should AI systems behave, and who should decide?: https://openai.com/blog/how-should-ai-systems-behave/

我是朋克又极客的AI算法小姐姐rumor
北航本硕,NLP算法工程师,谷歌开发者专家
欢迎关注我,带你学习带你肝
一起在人工智能时代旋转跳跃眨巴眼
「另外,你的点赞也可以缓解我的焦虑」


