
- 1python中异常值的检测和处理_python查找异常值和处理
- 2表格el-table多出一条横线,怎么解决(el-table表格下方多一条线的问题)_el-table表头有根线
- 3【STM32】DMA—直接存储器存取(原理篇)
- 4flyway快速入门基础教程_flyway使用教程
- 5C++小程序:同一路由器下两台计算机简单通信(1/2)——服务器端_c++ socket服务器
- 6FPGA集创赛、研电赛、FPGA创新设计竞赛国奖经验交流分享_电赛华中赛区证书
- 7通义千问模型使用text-generation-webui搭建webui页面
- 8FPGA图像处理基本技巧_连通域检测 fpga
- 9ts笔记 —— 函数_ts函数参数默认值
- 10openlayers浅入(了解框架逻辑以及简单使用)
音源分离|MUSIC SOURCE SEPARATION BASED ON A LIGHTWEIGHT DEEP LEARNING FRAMEWORK
赞
踩
一、文章摘要
音源分离(Music source separation ,MSS)旨在从一段混合音乐中提取“人声”,“鼓”,“贝斯”和“其他”音轨。虽然深度学习方法已经显示出令人印象深刻的结果,且有一个趋势是使用更大的模型去实现音源分离。但在本文中,介绍了一种新的轻量级架构DTTNet,它基于双路径模块和时频卷积时间分布全连接UNet(TFC-TDF UNet)。与Bandsplit RNN(BSRNN)相比,DTTNet在“人声”上实现了10.12 dB的cSDR,而BSRNN为10.01 dB,但参数数量减少了86.7%。我们还评估了特定模式的性能和模型对复杂音频模式的泛化能力。
二、本文方法
2.1 背景
目前用于分离MSS问题中“人声”音轨的最先进模型是Band-split Recurrent Neural Network (BSRNN)[12]和Time-Frequency ConvolutionsTime-Distributed Fully-connected UNet (TFC-TDF UNet)v3[13]。
BSRNN在谱图上预测一个复值的掩模,并使用全连接层(FC)和多层感知器(MLP)对特征进行编码和解码。编码后的特征通过12个双路径rnn进一步处理,以捕获子带间和子带内的依赖关系。然而,FC层和MLP层引入了大量冗余参数,并且12层双路径rnn需要增加训练时间。
FC-TDF UNet v3使用残差卷积块。此外,TFC-TDF UNet v3没有引入显式时间建模,因此当模型参数急剧增加时,性能增益不太突出。
本工作的贡献如下:1。如图1所示,通过集成和优化来自TFC-TDF UNet v3的编码器和解码器以及来自BSRNN的潜在双路径模块,我们减少了冗余参数。
2. 如图2(b)所示,我们在改进的双径模块内划分通道C,从而减少了推理时间。
3. 我们优化了DTTNet内部的超参数,提高了与BSRNN[12]和TFC-TDF UNet v3[13]相当的信失真比(SDR),如表3所示。
4. 我们使用复杂的音频模式对DTTNet进行测试,这些模式通常被许多在MUSDB18-HQ数据集上训练的模型错误分类。
2.2 本文方法

本文框架由三部分组成:编码器、解码器和潜在部分。
2.2.1 Encoder
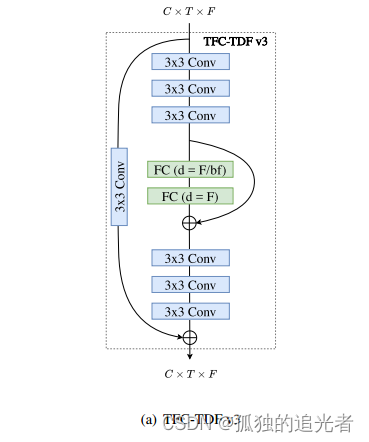
在编码器中使用TFC-TDF v3模块。
2.2.2 Improved Dual-Path Module

在潜在部分使用改进的双路径模块。改进双路径模块(Improved Dual-Path Module, IDPM)的结构与BSRNN中的Band and Sequence Module相似[12]。为了在保持高输入维数C的同时减少推理时间,我们首先将输入通道C分成H个头。然后,首先沿着第一个RNN块中的时间轴处理H头,然后沿着第二个RNN块中的频率轴处理H头。在IDPM结束时,应用相反的过程将H头合并到C通道中。
2.2.3 Decoder
解码器中同样使用TFC-TDF v3模块。
三、实验结果
3.1 数据集
MUSDB18-HQ。
3.2 实验设置
学习率为2 × 10−4,AdamW optimizer,L1损失函数,Batch_Size=8,模型训练300个epoch,STFT窗口大小为6144,hop length为1024。
3.3 推理结果
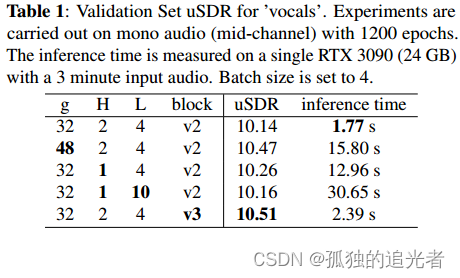

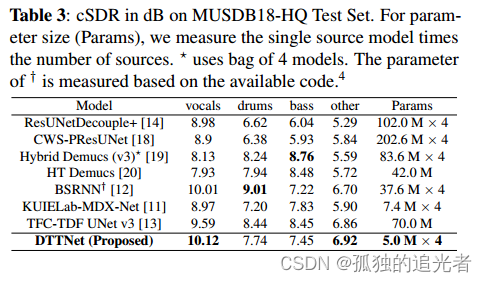
【文章链接】:https://arxiv.org/pdf/2309.08684v2.pdf
【源码链接】:https://github.com/junyuchen-cjy/dttnet-pytorch
【参考文献】:
[12] Yi Luo and Jianwei Yu, “Music source separation with band-split rnn,” IEEE/ACM Transactions on Audio,Speech, and Language Processing, vol. 31, pp. 1893–1901, 2023.
[13] Minseok Kim, Jun Hyung Lee, and Soonyoung Jung,“Sound Demixing Challenge 2023 Music Demixing TrackTechnical Report: TFC-TDF-UNet v3,” arXiv preprint:arXiv:2306.09382, 2023.

