
- 1中国人情世故的63个定律 。_达人归纳的63则中国人情世故的定律
- 2python 连接clickhouse数据库及简单操作
- 3安装visio2019Pro提示报错“0xC004F017“具体解决办法
- 4KubeEdge安装加入边缘节点报错: error unmarshaling JSON: while decoding JSON: json: cannot unmarshal number into_error decoding json: json: cannot unmarshal number
- 5深度解析Kafka中的消息奥秘
- 6HarmonyOS RUST 应用开发指导_deveco reload rust project
- 7Flask表单详解
- 8自学Python做兼职月入过万,用Python做项目有多赚钱?_python副业可以赚多少钱
- 9Nacos下载配置启动
- 10单片机:STC89C52的最小单元_单片机52最小系统显示屏元器件名称
【论文解读】GFPGAN:基于生成式面部先验的真实世界盲脸修复_gfp-gan
赞
踩
论文地址:https://arxiv.org/pdf/2101.04061.pdf
代码地址:https://github.com/TencentARC/GFPGAN

图片解释: 与最先进的面部修复方法的比较:HiFaceGAN [67]、DFDNet [44]、Wan 等人。[61] 和 PULSE [52] 在真实世界的低质量图像上。虽然以前的方法难以恢复忠实的面部细节或保留面部特征,但我们提出的GFP-GAN在真实性和保真度之间取得了良好的平衡,伪影要少得多。此外,强大的生成面部先验使我们能够联合进行修复和色彩增强。
0 摘要
盲脸修复通常依赖于面部先验,例如面部几何先验或参考先验,以恢复逼真和可信的细节。 然而,非常低质量的输入无法提供准确的几何先验,而高质量的参考则无法获得,从而限制了在实际场景中的适用性。 在这项工作中,我们提出了GFP-GAN,它利用封装在预训练人脸GAN中的丰富多样的先验进行盲人脸恢复。这种生成面部先验(GFP)通过空间特征变换层被整合到面部恢复过程中,这使得我们的方法能够实现真实性和保真度的良好平衡。 得益于强大的生成面部先验和精致的设计,我们的GFP-GAN只需一次前向传递即可共同还原面部细节并增强色彩,而GAN反演方法则需要在推理时进行特定于图像的优化。大量的实验表明,我们的方法在合成和真实世界的数据集上都取得了优于现有技术的性能。
1 引言
盲脸修复旨在从遭受未知退化的低质量对应物中恢复高质量的人脸,例如低分辨率 [13, 48, 9]、噪点 [71]、模糊 [39, 58]、压缩伪影 [12] 等。当应用于现实世界的场景时,由于更复杂的退化、多样化的姿势和表情,它变得更具挑战性。以前的工作[9,69,6]通常利用面部特定的先验来修复面部,例如面部特征[9],解析图[6,9],面部组件热图[69],并表明这些几何面部先验对于恢复准确的脸部形状和细节至关重要。然而,这些先验通常是根据输入图像估计的,并且在现实世界中不可避免地会随着输入质量非常低而降级。此外,尽管有语义指导,但上述先验包含用于恢复面部细节(例如,眼睛瞳孔)的纹理信息有限。
另一类参考先验的方法,例如,高质量的引导面部 [46, 45, 11],或面部成分词典[44],以产生真实的结果并减轻对降级输入的依赖。然而,高分辨率参考的不可获取限制了其实际适用性,而词典的有限容量限制了其面部细节的多样性和丰富性。
在这项研究中,我们利用生成面部先验(GFP)进行真实世界的盲人面部恢复,即隐式封装在预训练的人脸生成对抗网络(GAN)[18]模型中,如StyleGAN [35,36]。这些面部GAN能够生成具有高度可变性的可信的人脸,从而提供丰富多样的先验,如几何形状、面部纹理和颜色,从而可以共同还原面部细节和增强颜色(图1)。然而,将这种生成先验纳入恢复过程具有挑战性。以前的尝试通常使用GAN反转[19,54,52]。他们首先将退化的图像“反转”回预训练GAN的潜在代码,然后进行昂贵的图像特定优化来重建图像。尽管输出具有视觉逼真感,但它们通常会产生低保真度的图像,因为低维潜在代码不足以指导准确的修复。
为了应对这些挑战,我们提出了具有精致设计的GFP-GAN,以在一次前向传递中实现真实性和保真度的良好平衡。 具体来说,GFPGAN由降解去除模块和预训练的人脸GAN作为人脸先验组成。它们通过直接潜在编码映射和多个通道拆分空间特征变换 (CS-SFT) 层以从粗到细的方式连接起来。所提出的CS-SFT层对分割的特征进行空间调制,并让左侧特征直接通过,以便更好地保存信息,使我们的方法在重新训练高保真度的同时有效地结合生成先验。此外,我们引入了具有局部判别器的面部成分损失函数,以进一步增强感知面部细节,同时采用身份保留损失函数来进一步提高保真度。
我们总结如下贡献。 (1)我们利用丰富多样的生成面部先验进行盲脸修复。这些先验包含足够的面部纹理和颜色信息,使我们能够共同进行面部修复和颜色增强。 (2)我们提出了GFP-GAN框架,该框架具有精细的架构和损失设计,以纳入生成面部先验。我们带有 CS-SFT 层的 GFP-GAN 在一次前向传递中实现了保真度和纹理保真度的良好平衡。 (3)大量实验表明,我们的方法在合成和现实世界数据集上都取得了优于现有技术的性能。
2 相关工作
图像修复通常包括超分辨率[13,48,60,49,74,68,22,50],去噪[71,42,26],去模糊[65,39,58]和压缩去除[12,21]。为了获得视觉上令人愉悦的结果,生成对抗网络[18]通常被用作损失监督,以推动解决方案更接近自然流形[41,57,64,7,14],而我们的工作则试图利用预训练的人脸GAN作为生成面部先验(GFP)。
面部修复。 基于一般人脸幻觉[5,30,66,70],两个典型的人脸特定先验:几何先验和参考先验,以进一步提高性能。几何先验包括面部特征点[9,37,77],面部解析图[58,6,9]和面部组件热图[69]。然而,1)这些先验需要从低质量的输入中进行估计,并且在实际场景中不可避免地会退化。 2)它们主要关注几何约束,可能不包含足够的修复细节。 取而代之的是,我们采用的GFP不涉及从降级图像中显式的几何估计,并且在其预训练网络中包含足够的纹理。
参考先验[46,45,11]通常依赖于相同身份的参考图像。为了克服这个问题,DFDNet[44]建议构建每个组件(例如,眼睛、嘴巴)的人脸字典,并具有CNN特征来指导修复。然而,DFDNet主要关注字典中的成分,因此在字典范围之外的区域(例如,头发,耳朵和面部轮廓)会降解,相反,我们的GFP-GAN可以将面部视为一个整体进行恢复。此外,字典的有限大小限制了其多样性和丰富性,而GFP可以提供丰富多样的先验,包括几何、纹理和颜色。
生成先验 [34, 35, 36, 3] 以前被 GAN 反演 [1, 76, 54, 19] 利用,其主要目的是在给定输入图像的情况下找到最接近的潜在代码。PULSE [52] 迭代优化 StyleGAN [35] 的潜在代码,直到输出和输入之间的距离低于阈值。mGANprior[19]试图通过优化多个代码来提高重构质量。 然而,这些方法通常会产生低保真度的图像,因为低维潜码不足以指导修复。相比之下,我们提出的CS-SFT调制层能够预先合并多分辨率空间特征,以实现高保真度。此外,在推理过程中,我们的GFP-GAN不需要昂贵的迭代优化。
通道拆分操作通常用于设计紧凑的模型,提高模型的表示能力。MobileNet [28] 提出了深度卷积,GhostNet [23] 将卷积层分成两部分,并使用更少的过滤器来生成内在特征图。DPN [8] 中的双路径架构支持对每条路径进行特征复用和新特征探索,从而提高其表示能力。在超分辨率中也采用了类似的想法[75]。我们的 CS-SFT 层具有相似的精神,但具有不同的操作和目的。我们采用空间特征变换 [63, 55] 在一个部分上和将左边的分裂保留为身份,以实现真实性和保真度的良好平衡。
局部组件鉴别器。 局部判别器关注局部斑块分布[32,47,62]。当应用于人脸时,这些判别性损失被施加在单独的语义人脸区域[43,20]。我们引入的面部成分损失也采用了这样的设计,但基于学习的判别特征进行了进一步的风格监督。
3 方法论
3.1 GFP-GAN概述
我们在本节中描述了GFP-GAN框架。给定输入的面部图像 x 遭受未知退化,盲人面部修复的目的是估计高质量的图像 ,在真实度和保真度方面尽可能与真值图像 y 相似。
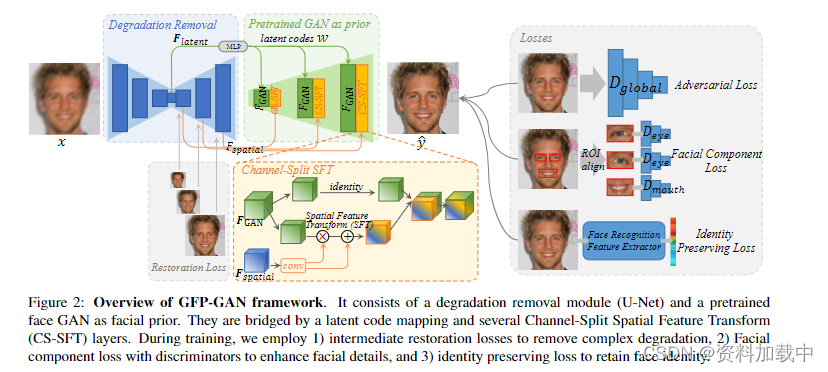
图片解释: GFP-GAN 框架概述。 它由一个退化去除模块(U-Net)和一个预训练的人脸GAN网络作为面部先验信息。它们由潜在代码映射和多个通道拆分空间特征转换 (CS-SFT) 层桥接。在训练过程中,我们采用 1) 中间恢复损失来消除复杂的退化,2) 使用鉴别器的面部成分损失来增强面部细节,以及 3) 身份保留损失来保留面部身份。
GFP-GAN的整体框架如图2所示。GFP-GAN由降解去除模块(U-Net)和预训练人脸GAN(如StyleGAN2 [36])组成。 它们由潜在代码映射和多个通道拆分空间特征转换 (CS-SFT) 层桥接。 具体而言,所述降解去除模块设计用于去除复杂的降解,并提取两种特征,即.1)潜在特征将输入图像映射到StyleGAN2中最接近的潜在编码。以及 2) 多分辨率空间特征
用于调制StyleGAN2特征。
紧接着,通过几个线性层映射到中间潜在编码 W。鉴于与输入图像的潜伏代码接近,StyleGAN2 可以生成中间卷积特征,用
表示。这些特征提供了在预训练 GAN 的权重中捕获的丰富面部细节。多分辨率特征
习惯于使用所提出的CS-SFT层以从粗到细的方式对面部GAN特征
进行空间调制,在保持高保真度的同时实现逼真的效果。在训练过程中,除了全局判别损失外,我们还引入了带有判别器的面部成分损失,以增强感知上显着的面部成分,即眼睛和嘴巴。为了重新训练身份,我们还采用了身份保留指导。
3.2 退化去除模块
真实世界的盲脸修复面部具有复杂和严重的退化,通常是低分辨率、模糊、噪点和JPEG伪影的混合体。退化去除模块旨在显式去除上述退化并提取“干净”特征和
,减轻了后续模块的负担。我们采用U-Net [56]结构作为退化去除模块,因为它可以1)增加感受野以消除大模糊,以及2)生成多分辨率特征。其公式如下:
潜空间特征用于将输入图像映射到离StyleGAN2中最近的潜在编码(Sec.3.3)。
多分辨率特征用于调制StyleGAN2特征(Sec.3.4)。
为了对消除退化进行中间监督,我们在训练的早期阶段在每个分辨率尺度中使用了 L1 恢复损失。具体来说,我们还输出UNet解码器的每个分辨率比例的图像,然后将这些输出限制为接近真实目标图像的金字塔。
3.3 生成面部先验和潜在编码映射
预先训练的人脸GAN在其卷积的倾斜权重中捕获人脸的分布,即生成先验[19,54]。我们利用这种预训练的面部GAN为我们的任务提供多样化和丰富的面部细节。部署生成先验的典型方法是将输入图像映射到其最接近的潜在代码 Z ,然后通过预训练的 GAN [1, 76, 54, 19] 生成相应的输出。但是,这些方法通常需要耗时的迭代优化来保持保真度。我们不是直接生成最终图像,而是生成最接近的人脸的中间卷积特征,因为它包含更多细节,并且可以通过输入特征进一步调制以获得更好的保真度(参见第 3.4 节)。
特别的,给定输入图像的编码向量(由公式1中的UNet产生),我们首先将其映射到中间潜在代码W,以更好地保留语义属性,即从Z转换的中间空间与多个多层感知层(MLP)[76]。然后,潜在代码 W 穿过预训练 GAN 中的每个卷积层,并为每个分辨率尺度生成 GAN 特征。
讨论:关节修复和色彩增强。生成模型除了逼真的细节和生动的纹理之外,还可以捕获各种丰富先验的内容。例如,它们还封装了颜色先验,可用于我们的联合面部修复和颜色增强任务。真实世界的人脸图像,例如老照片,通常有黑白、复古黄色或暗淡的颜色。生成面部先验中的活泼色彩先验允许我们进行颜色增强,包括着色[72]。 我们认为生成面部先验还结合了传统的几何先验[9,69],3D先验[16]等。用于恢复和操作。
3.4 通道分割空间特征变换
为了更好地保持保真度,我们进一步使用输入的空间特征(由式1中UNet产生)来调制方程式2中的GAN特征
。从输入保留空间信息对于面部修复式至关重要的,因此通常需要局部特征的真实保留。我们提出了空间转换模块(SFT)[63],生成用于空间特征调制的仿射变换参数,并显示了其在图像恢复[63,64]和图像生成[55]结合其他条件的有效性。
特别的,在每一个分辨率尺度上,我们通过经过少数卷积层的输入特征生成一对仿射变换参数(
)。在那之后,通过缩放和移动GAN特征
来完成调制:
为了更好地实现真实感和保真度的平衡,我们进一步提出了通道分割空间特征变换(CSSFT)层,该层通过输入特征对部分GAN特征进行空间调制(有助于保真度),并留下左侧的GAN特征(有助于真实性)直接通过,如图2所示:
是从
在通道维度上切分出去的特征,Concat[.,.]表示堆叠操作。
因此,CS-SFT具有直接结合先验信息和输入图像有效调制的优势,从而在纹理保真度和保真度之间实现了良好的平衡。此外,CS-SFT还可以降低复杂性,因为它需要更少的调制通道,类似于GhostNet [23]。
我们在每个分辨率尺度上进行通道分割SFT层,最后生成恢复的人脸。
3.5 模型目标
训练 GFP-GAN 的学习目标包括:1)约束输出接近真实目标y的重建损失;2) 用于恢复逼真纹理的对抗性损失;3) 提出面部成分损失以进一步增强面部细节;4) 身份保留损失。
重建损失。我们采用广泛使用的L1损失和知觉损失[33,41]作为我们的重建损失L,定义如下:
其中 φ 是预训练的 VGG-19 网络 [59],我们在激活前使用 {conv1, · · · , conv5} 特征图[64],分别表示权重L1损失和感知损失。
对抗性损失。 我们采用对抗性损失来鼓励GFP-GAN支持自然图像流形中的解并生成逼真的纹理。与StyleGAN2 [36]类似,采用逻辑损失[18]:
其中 D 表示判别器,表示对抗损失权重。
面部成分损失。 为了进一步增强具有感知意义的面部成分,我们引入了具有局部判别器的左眼、右眼和嘴的面部成分损失,由图2展示。我们首先使用 ROI 对齐 [24] 裁剪感兴趣的区域。对于每个区域,我们训练单独的小型局部判别器来区分恢复斑块是否真实,从而将斑块推近自然面部成分分布。
受[62]的启发,我们进一步纳入了基于学习鉴别器的特征风格损失。 与以往具有空间约束的特征匹配损失[62]不同,我们的特征风格损失尝试匹配真实和恢复补丁的Gram矩阵统计量[15]。Gram矩阵计算特征相关性,通常有效地捕获纹理信息[17]。 我们从学习到的局部判别器的多层中提取特征,并学习匹配来自真实和恢复补丁的中间表示的这些 Gram 统计量。根据经验,我们发现特征风格损失在生成逼真的面部细节和减少令人不快的伪影方面比以前的特征匹配损失表现更好。
面部成分损失定义如下。第一项是判别损失 [18],第二项是特征样式损失:
其中 ROI 是组件集合 {左眼、右眼、嘴巴 } 中的感兴趣区域。D 是每个区域的局部判别器。 ψ表示来自学习鉴别器的多分辨率特征。分别表示局部判别性损失和特征样式损失的损失权重。
身份保留丢失。 我们从[31]中汲取灵感,并在我们的模型中应用身份保留损失。与感知损失 [33] 类似,我们根据输入人脸的特征嵌入来定义损失。 具体来说,我们采用了预训练的人脸识别ArcFace[10]模型,该模型捕获了身份识别最突出的特征。恒等式保留损失强制恢复的结果在紧凑的深度特征空间中与真实值有很小的距离:
其中η表示人脸特征提取器,即 .ArcFace [10] 在我们的实现中。 表示身份保留丢失的权重。
模型的总体目标是上述损失的组合:
损失超参数设置如下:= 0.1,
,和
。
4 实验
4.1 数据集和实现
训练数据集。 我们在FFHQ数据集[35]上训练我们的GFP-GAN,该数据集由70,000张高质量图像组成。在训练期间,我们将所有图像的大小调整为 512。我们的 GFP-GAN 是在合成数据上训练的,这些合成数据近似于真实的低质量图像,并在推理过程中泛化到真实世界的图像。 我们遵循 [46, 44] 中的实践,采用以下降解模型来合成训练数据:

首先对高质量图像 y 进行高斯模糊核卷积,然后使用比例因子 r 进行下采样操作。之后,将加性高斯白噪声n添加到图像中,最后通过JPEG压缩,品质因子为q。与 [44] 类似,对于每个训练对,我们分别从 { 0 .2 : 10}、{1 : 8} 、 {0 : 15} 、 {60 : 100} 中随机抽取 σ 、 r 、 δ 和 q。我们还在训练期间添加了色彩抖动,以增强色彩。
测试数据集。 我们构建了一个合成数据集和三个具有不同来源的不同真实数据集。所有这些数据集都与我们的训练数据集没有重叠。我们在这里提供简要介绍。
CelebA-Test 是一个合成数据集,其中包含来自其测试分区的 3,000 张 CelebA-HQ 图像 [51]。生成方式与训练期间的生成方式相同。
LFW-测试。 LFW [29] 包含低质量野外图像。我们将验证分区中每个标识的所有第一个映像分组,形成 1711 个测试映像。
CelebChild-Test包含从互联网上收集的180张名人的童脸。它们质量低下,其中许多是黑白老照片。
WebPhoto-测试。在现实生活的互联网中,我们抓取了 188 张低质量照片,提取 407 张人脸来构建 WebPhoto 测试数据集。这些照片具有多种多样且复杂的退化。 其中一些是老照片,在细节和颜色上都有非常严重的退化。
实现。我们采用具有 512 个输出的预训练 StyleGAN2 [36] 作为我们的生成面部先验。StyleGAN2 的通道倍增器设置为 1,以实现紧凑的模型大小。用于降解去除的UNet由7个下采样和7个上采样组成,每个下采样都有一个残余块[25]。对于每个CS-SFT层,我们使用两个卷积层分别生成仿射参数α和β。
训练小批量大小设置为 12。 我们通过水平翻转和颜色抖动来增强训练数据。我们考虑三个组成部分:左眼、右眼、嘴巴,因为它们在感知上很重要。每个组件都通过ROI与原始训练数据集中的脸部关键点对齐[24]然后进行裁剪。

图片解释:每个组件都通过ROI对齐[24]与面部进行裁剪 图3:用于盲面修复的CelebA-Test的定性比较。我们的GFP-GAN在眼睛、嘴巴和头发上产生可信的细节。

图片解释:CelebA-Test 对 × 4 人脸超分辨率的比较。我们的GFP-GAN可恢复逼真的牙齿和忠实的眼睛注视方向。 我们使用 Adam 优化器 [38] 训练模型,总共进行了 800 k 次迭代。 学习率设置为,然后在第 700 k次、第 750 k次迭代时衰减 2 倍。我们使用 PyTorch 框架实现模型,并使用四个 NVIDIA Tesla P40 GPU 对其进行训练。
4.2 sota方法对比
我们将GFP-GAN与几种最先进的面部修复方法进行了比较:HiFaceGAN [67]、DFDNet [44]、PSFRGAN [6]、Super-FAN [4] 和 Wan et al. [61]。用于面部修复的GAN反转方法:PULSE [52]和mGANprior [19]也包括在内进行比较。我们还将我们的GFP-GAN与图像恢复方法进行了比较:RCAN [74]、ESRGAN [64]和DeblurGANv2 [40],并在我们的面部训练集上对它们进行了微调,以便进行公平的比较。我们采用他们的官方代码,但 Super-FAN 除外,我们对此使用了重新实现。
在评估中,我们采用了广泛使用的非参考感知指标:FID [27] 和 NIQE [53]。我们还采用像素级指标(PSNR 和 SSIM)和感知指标 (LPIPS [73]) 进行 CelebA-Test with Ground-Truth (GT)。我们在 ArcFace [10] 特征嵌入中测量基于角度的身份距离,其中较小的值表示更接近 GT。
合成 CelebA-Test。 比较是在两种设置下进行的:1)输入和输出具有相同分辨率的盲脸修复。 2) 4 ×面超分辨率图像作为面部超分辨率的输入。
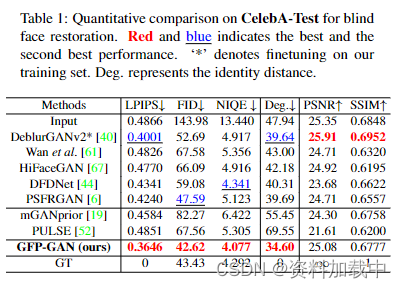
图表解释:基于CelebA-Test盲脸恢复的定量比较。红色和蓝色表示最佳和次优性能。 “*”表示对训练集的微调。Deg表示标识距离。
每个设置的定量结果如表1和表2所示.。在这两种设置下,GFP-GAN都实现了最低的LPIPS,表明我们的结果在感知上接近真实值。GFP-GAN还获得了最低的FID和NIQE,表明输出分别与真实人脸分布和自然图像分布有很近的距离。除了感知性能外,我们的方法还保留了更好的识别性,表现为面部特征嵌入的最小程度。请注意,1)我们的方法比GT低的FID和NIQE并不表明我们的性能优于GT,因为这些“感知”指标在粗略尺度上与人类意见得分密切相关,但在更精细的尺度上并不总是很好地相关[2];2)像素指标PSNR和SSIM与人类观察者的主观评价相关性不高[2,41],我们的模型在这两个指标上表现不佳。
定性结果如图3和图4所示。1)由于强大的生成面部先验,我们的GFPGAN可以恢复眼睛(瞳孔和睫毛),牙齿等的可信细节。2)我们的方法在修复中将面部视为整体,也可以生成逼真的头发,而以前依赖于组件字典(DFDNet)或解析图(PSFRGAN)的方法无法产生可信的头发纹理(第二行,图3)。 3)GFP-GAN能够保持保真度,例如,它产生自然的闭口没有像 PSFRGAN 那样强制添加牙齿(第 2 行,图 3)。在图4中,GFP-GAN也恢复了合理的眼睛注视方向。

图象解释:三个真实数据集的量化比较。
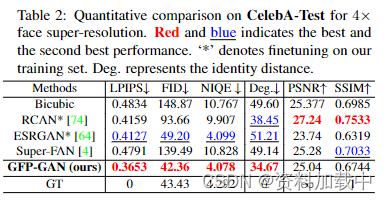
图表解释: CelebA-Test 对 4 ×面部超分辨率的定量比较。 红色和蓝色表示最佳和次优性能。“*”表示对训练集的微调。Deg表示标识距离。
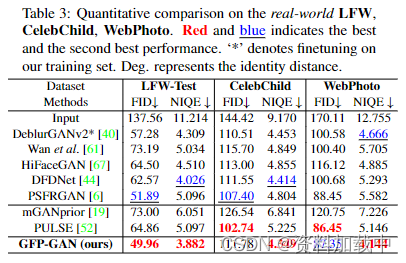
真实世界LFW的,CelebChild , WebPhoto 数据集定量比较. 红色和蓝色表示最佳和次优性能。“*”表示对训练集的微调。Deg表示标识距离。
真实世界的 LFW、CelebChild 和 WedPhoto-Test。 为了测试泛化能力,我们在三个不同的真实数据集上评估了我们的模型。 定量结果如表所示。3. 我们的GFP-GAN在所有三个真实数据集上都取得了卓越的性能,显示出其卓越的泛化能力。尽管PULSE [52]也可以获得较高的感知质量(较低的FID评分),如图5所示。
定性比较如图5所示。GFPGAN可以利用强大的生成先验技术,对现实生活中的照片进行面部修复和色彩增强。我们的方法可以在复杂的现实世界退化上产生合理和逼真的面部,而其他方法无法恢复可信的面部细节或产生伪影(特别是在图 5 的 WebPhoto-Test 中)。除了眼睛和牙齿等常见的面部成分外,GFP-GAN在头发和耳朵中的表现也更好,因为GFP先验考虑了整个面部而不是单独的部分。借助 SC-SFT 层,我们的模型能够实现高保真度。如图 5 的最后一行所示,以前的大多数方法都无法恢复闭合的眼睛,而我们的方法可以用更少的伪影成功恢复它们。
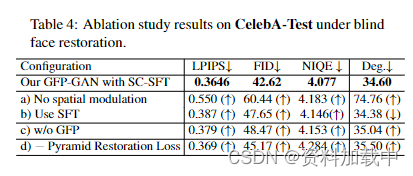
图表解释:CelebA-Test数据集上盲面恢复的消融结果。

图6 CS-SFT层的消融研究,GFP先验和金字塔恢复损失。
图7 面部成分损失的消融研究,D,fm,fs表示成分判别器,特征。
图8 黑色皮肤面部上的修复结果。
图9 该模型的局限性,PSFRGAN[6]的结果也在里面。
4.3 消融研究
CS-SFT 层。 如表所示。如图4[构型a)]和图6所示,当我们去除空间调制层时,即只保留潜在代码映射而没有空间信息时,即使存在身份保留损失(高LIPS分数和大度),恢复的人脸也无法保留人脸身份。因此,CS-SFT 图层中使用的多分辨率空间特征对于保持保真度至关重要。当我们将 CS-SFT 层切换到表中的简单 SFT 层 [配置 b) 时。4],我们观察到 1) 感知质量在所有指标上都下降了,2) 它保留了更强的同一性(更小的度),因为输入图像特征对所有调制特征施加影响,输出偏向于降级的输入,从而导致感知质量降低。相比之下,CSSFT 图层通过调节特征分割来提供真实性和保真度的良好平衡。
预训练 GAN 作为 GFP。 预训练的GAN提供了丰富多样的恢复功能。 如果我们不使用生成面部先验,则观察到性能下降,如表所示。4 [配置 c)] 和图 6。
金字塔修复损失。 在退化去除模块中采用金字塔恢复损失,增强了现实世界中复杂退化的恢复能力。如果没有这种中间监督,后续调制的多分辨率空间特征仍可能退化,导致性能较差,如表所示。4 [构型 d]和图 6。
面部成分损失。 我们比较了以下结果:1)去除所有面部成分损失,2)仅保留成分判别器,3)增加额外的特征匹配损失,如[62],以及4)采用基于Gram统计的额外特征样式损失[15]。如图 7 所示,具有特征风格损失的分量判别器可以更好地捕获眼图分布并恢复合理的细节。
4.4 讨论和局限性
训练偏差。我们的方法在大多数深色皮肤的人脸和各种人群中表现良好(图 8),因为我们的方法使用预训练的 GAN 和输入图像特征进行调制。此外,我们采用重建损失和身份保留损失来限制输出,以保持输入的保真度。但是,当输入图像为灰度图像时,由于输入的图像不包含足够的颜色信息,因此面部颜色可能会有偏差(图8中的最后一个示例)。因此,需要一个多样化和平衡的数据集。
局限性。 如图9所示,当真实图像的退化严重时,GFPGAN恢复的面部细节会因伪影而扭曲。我们的方法还为非常大的姿势产生了不自然的结果。这是因为合成降解和训练数据分布与现实世界不同。一种可能的方法是从真实数据中学习这些分布,而不是仅仅使用合成数据,这将留作未来的工作。

