
- 1Android精美登录界面设计
- 2使用 Calendar 计算时间_calendar 时间计算
- 3redis在linux的安装及redis常用指令的使用_linux 通过命令增加redis内存
- 4rabbitMQ知识概括_rabbitmq 端口
- 5模仿dcloudio/uni-preset-vue 自定义基于uni-app的小程序框架
- 6python断言assert实例求素数_Python单元测试框架之pytest -- 断言
- 7数字图像处理、计算机图形学相关的名词解释和解答题(二)
- 8使用vscode进行rebase拉取_vscode rebase
- 9翻译:Face-Sensitive Image-to-Emotional-Text Cross-modal Translation for Multimodal Aspect-based Sentim
- 10为什么java会发生溢出,java – 为什么这个乘法整数溢出导致零?
YOLO系列详细解读:YOLO V3_yolov3
赞
踩
YOLOv3没有太多的创新,主要是借鉴一些好的方案融合到YOLO里面。不过效果还是不错的,在保持速度优势的前提下,提升了预测精度,尤其是加强了对小物体的识别能力。
yolo_v3对之前的算法既有保留又有改进。先分析一下yolo_v3上保留的东西:
- “分而治之”,从yolo_v1开始,yolo算法就是通过划分单元格来做检测,只是划分的数量不一样。
- 采用"leaky ReLU"作为激活函数。
- 端到端进行训练。一个loss function搞定训练,只需关注输入端和输出端。
- 从yolo_v2开始,yolo就用batch normalization作为正则化、加速收敛和避免过拟合的方法,把BN层和leaky relu层接到每一层卷积层之后。
- 多尺度训练。在速度和准确率之间tradeoff。想速度快点,可以牺牲准确率;想准确率高点儿,可以牺牲一点速度。
YOLO3主要的改进有:
- 调整了网络结构;
- 利用多尺度特征进行对象检测;
- 对象分类用Logistic取代了softmax。
yolo每一代的提升很大一部分决定于backbone网络的提升,从v2的darknet-19到v3的darknet-53。yolo_v3还提供替换backbone——tiny darknet。要想性能牛叉,backbone可以用Darknet-53,要想轻量高速,可以用tiny-darknet。总之,yolo就是天生“灵活”,所以特别适合作为工程算法。
新的网络结构Darknet-53
在基本的图像特征提取方面,YOLO3采用了称之为Darknet-53的网络结构(含有53个卷积层),它借鉴了残差网络residual network的做法,在一些层之间设置了快捷链路(shortcut connections)。
上图的Darknet-53网络采用256*256*3作为输入,最左侧那一列的1、2、8等数字表示多少个重复的残差组件。每个残差组件有两个卷积层和一个快捷链路,示意图如下:
YOLO v3
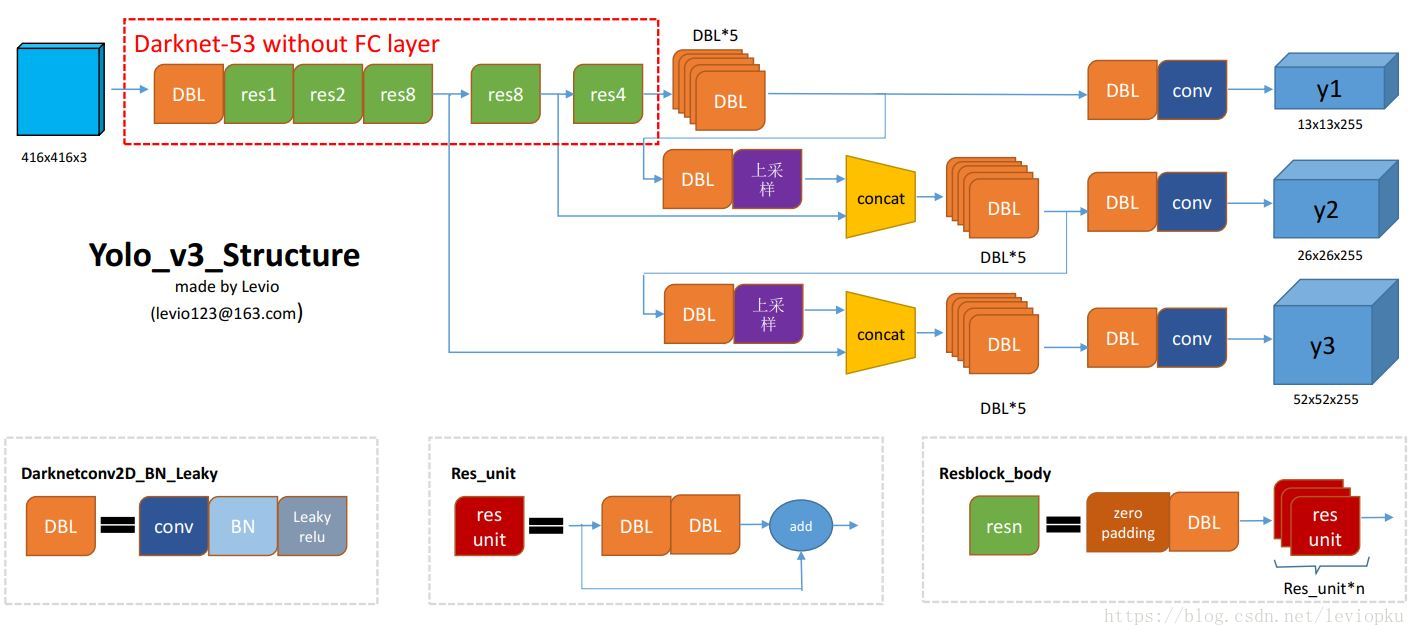
上图表示了yolo_v3整个yolo_body的结构,没有包括把输出解析整理成咱要的[box, class, score]。
对于把输出张量包装成[box, class, score]那种形式,还需要写一些脚本,但这已经在神经网络结构之外了(我后面会详细解释这波操作)。
为了让yolo_v3结构图更好理解,我对图1做一些补充解释:
DBL: 如图1左下角所示,也就是代码中的Darknetconv2d_BN_Leaky,是yolo_v3的基本组件。就是卷积+BN+Leaky relu。对于v3来说,BN和leaky relu已经是和卷积层不可分离的部分了(最后一层卷积除外),共同构成了最小组件。
resn:n代表数字,有res1,res2, … ,res8等等,表示这个res_block里含有多少个res_unit。这是yolo_v3的大组件,yolo_v3开始借鉴了ResNet的残差结构,使用这种结构可以让网络结构更深(从v2的darknet-19上升到v3的darknet-53,前者没有残差结构)。对于res_block的解释,可以在图1的右下角直观看到,其基本组件也是DBL。
concat:张量拼接。将darknet中间层和后面的某一层的上采样进行拼接。拼接的操作和残差层add的操作是不一样的,拼接会扩充张量的维度,而add只是直接相加不会导致张量维度的改变。
我们可以借鉴netron来分析网络层,整个yolo_v3_body包含252层,组成如下:
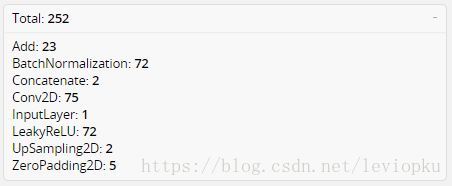
对于代码层面的layers数量一共有252层,包括add层23层(主要用于res_block的构成,每个res_unit需要一个add层,一共有1+2+8+8+4=23层)。除此之外,BN层和LeakyReLU层数量完全一样(72层),在网络结构中的表现为:每一层BN后面都会接一层LeakyReLU。卷积层一共有75层,其中有72层后面都会接BN+LeakyReLU的组合构成基本组件DBL。看结构图,可以发现上采样和concat都有2次,和表格分析中对应上。每个res_block都会用上一个zero padding,一共有5个res_block。
1. backbone
整个v3结构里面,是没有池化层和全连接层的。前向传播过程中,张量的尺寸变换是通过改变卷积核的步长来实现的,比如stride=(2, 2),这就等于将图像边长缩小了一半(即面积缩小到原来的1/4)。在yolo_v2中,要经历5次缩小,会将特征图缩小到原输入尺寸的1/25
1/25,即1/32。输入为416x416,则输出为13x13(416/32=13)。
yolo_v3也和v2一样,backbone都会将输出特征图缩小到输入的1/32。所以,通常都要求输入图片是32的倍数。可以对比v2和v3的backbone看看:(DarkNet-19 与 DarkNet-53)
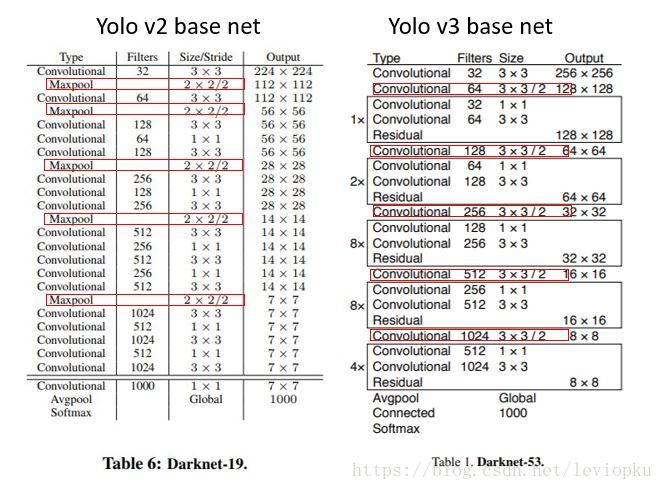
yolo_v2中对于前向过程中张量尺寸变换,都是通过最大池化来进行,一共有5次。而v3是通过卷积核增大步长来进行,也是5次。(darknet-53最后面有一个全局平均池化,在yolo-v3里面没有这一层,所以张量维度变化只考虑前面那5次)。
这也是416x416输入得到13x13输出的原因。可以看出,darknet-19是不存在残差结构(resblock,从resnet上借鉴过来)的,和VGG是同类型的backbone(属于上一代CNN结构),而darknet-53是可以和resnet-152正面刚的backbone,看下表:
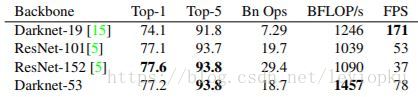
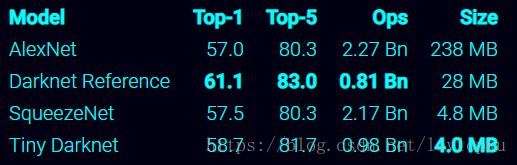
从上表也可以看出,darknet-19在速度上仍然占据很大的优势。其实在其他细节也可以看出(比如bounding box prior采用k=9),yolo_v3并没有那么追求速度,而是在保证实时性(fps>36)的基础上追求performance。不过前面也说了,你要想更快,还有一个tiny-darknet作为backbone可以替代darknet-53,在官方代码里用一行代码就可以实现切换backbone。搭用tiny-darknet的yolo,也就是tiny-yolo在轻量和高速两个特点上,显然是state of the art级别,tiny-darknet是和squeezeNet正面刚的网络,详情可以看下表:
所以,有了yolo v3,就真的用不着yolo v2了,更用不着yolo v1了。这也是[yolo官方网站](https://pjreddie.com/darknet/),在v3出来以后,就没提供v1和v2代码下载链接的原因了。
2. Output
更值得关注的是输出张量:
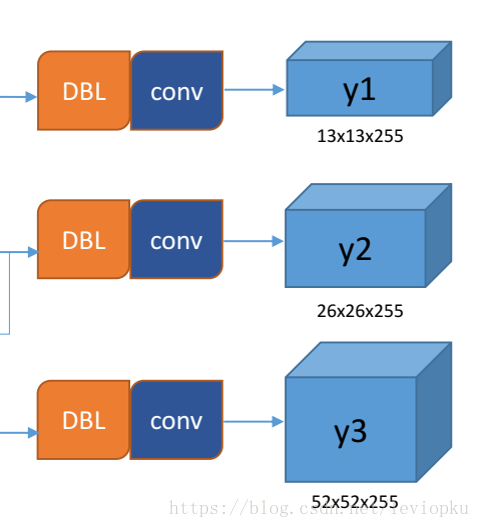
yolo v3输出了3个不同尺度的feature map,如上图所示的y1, y2, y3。这也是v3论文中提到的为数不多的改进点:predictions across scales
这个借鉴了FPN(feature pyramid networks),采用多尺度来对不同size的目标进行检测,越精细的grid cell就可以检测出越精细的物体。
y1,y2和y3的深度都是255,边长的规律是13:26:52
对于COCO类别而言,有80个种类,所以每个box应该对每个种类都输出一个概率。
yolo v3设定的是每个网格单元预测3个box,所以每个box需要有(x, y, w, h, confidence)五个基本参数,然后还要有80个类别的概率。所以3*(5 + 80) = 255。这个255就是这么来的。
v3用上采样的方法来实现这种多尺度的feature map,可以结合图1和图2右边来看,图1中concat连接的两个张量是具有一样尺度的(两处拼接分别是26x26尺度拼接和52x52尺度拼接,通过(2, 2)上采样来保证concat拼接的张量尺度相同)。作者并没有像SSD那样直接采用backbone中间层的处理结果作为feature map的输出,而是和后面网络层的上采样结果进行一个拼接之后的处理结果作为feature map。为什么这么做呢? 我感觉是有点玄学在里面,一方面避免和其他算法做法重合,另一方面这也许是试验之后并且结果证明更好的选择,再者有可能就是因为这么做比较节省模型size的。这点的数学原理不用去管,知道作者是这么做的就对了。
3. some tricks
上文把yolo_v3的结构讨论了一下,下文将对yolo v3的若干细节进行剖析。
Bounding Box Prediction
b-box预测手段是v3论文中提到的又一个亮点。先回忆一下v2的b-box预测:想借鉴faster R-CNN RPN中的anchor机制,但不屑于手动设定anchor prior(模板框),于是用维度聚类的方法来确定anchor box prior(模板框),最后发现聚类之后确定的prior在k=5也能够又不错的表现,于是就选用k=5。后来呢,v2又嫌弃anchor机制线性回归的不稳定性(因为回归的offset可以使box偏移到图片的任何地方),所以v2最后选用了自己的方法:直接预测相对位置。预测出b-box中心点相对于网格单元左上角的相对坐标。
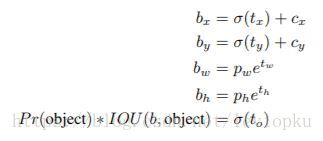
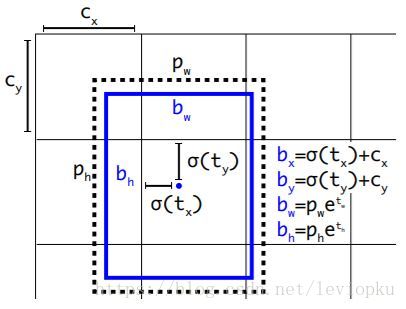
yolo v2直接predict出(tx, ty, tw, th, to),并不像RPN中anchor机制那样去遍历每一个pixel。可以从上面的公式看出,b-box的位置大小和confidence都可以通过(txtx, tyty, twtw, thth, toto)计算得来,v2相当直接predict出了b-box的位置大小和confidence。box宽和高的预测是受prior影响的,对于v2而言,b-box prior数为5,在论文中并没有说明抛弃anchor机制之后是否抛弃了聚类得到的prior(没看代码,所以我不能确定),如果prior数继续为5,那么v2需要对不同prior预测出tw和th。
对于v3而言,在prior这里的处理有明确解释:选用的b-box priors 的k=9,对于tiny-yolo的话,k=6。priors都是在数据集上聚类得来的,有确定的数值,如下:
10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
分配上,在最小的13*13特征图上(有最大的感受野)应用较大的先验框(116x90),(156x198),(373x326),适合检测较大的对象。中等的26*26特征图上(中等感受野)应用中等的先验框(30x61),(62x45),(59x119),适合检测中等大小的对象。较大的52*52特征图上(较小的感受野)应用较小的先验框(10x13),(16x30),(33x23),适合检测较小的对象。
感受一下9种先验框的尺寸,下图中蓝色框为聚类得到的先验框。黄色框式ground truth,红框是对象中心点所在的网格。
每个anchor prior(名字叫anchor prior,但并不是用anchor机制)就是两个数字组成的,一个代表高度另一个代表宽度。
v3对b-box进行预测的时候,采用了logistic regression。这样能够支持多标签对象(比如一个人有Woman 和 Person两个标签)。v3每次对b-box进行predict时,输出和v2一样都是(tx, ty, tw, th, to),然后通过公式计算出绝对的(x, y, w, h, c)。还需要乘以特征图的采样率,得到真实的检测框x,y。
logistic回归用于对anchor包围的部分进行一个目标性评分(objectness score),即这块位置是目标的可能性有多大。这一步是在predict之前进行的,可以去掉不必要anchor,可以减少计算量。作者在论文种的描述如下:
If the bounding box prior is not the best but does overlap a ground truth object by more than some threshold we ignore the prediction, following[17]. We use the threshold of 0.5. Unlike [17] our system only assigns one bounding box prior for each ground truth object.
如果模板框不是最佳的,即使它超过我们设定的阈值,我们还是不会对它进行predict。
不同于faster R-CNN的是,yolo_v3只会对1个prior进行操作,也就是那个最佳prior。从9个anchor priors中找到objectness score(目标存在可能性得分)最高的那一个,由sigmoid函数解码即可,解码之后数值区间在[0,1]中。
疑问解答和说明:
-
- 第一点, 9个anchor会被三个输出张量平分的。根据大中小三种size各自取自己的anchor。
-
- 第二点,每个输出y在每个自己的网格都会输出3个预测框,这3个框是9除以3得到的,这是作者设置
- 的,我们可以从输出张量的维度来看,13x13x255。255是怎么来的呢,3*(5+80)。80表示80个种类,5表
- 示位置信息和置信度,3表示要输出3个prediction。在代码上来看,3*(5+80)中的3是直接由
- num_anchors//3得到的。
-
- 第三点,作者使用了logistic回归来对每个anchor包围的内容进行了一个目标性评分(objectness score)。
- 根据目标性评分来选择anchor prior进行predict,而不是所有anchor prior都会有输出。
-
- 第四点:类别解码
-
- COCO数据集有80个类别,所以类别数在85维输出中占了80维,每一维独立代表一个类别的置信度。使用sigmoid激活函数替代了Yolov2中的softmax,取消了类别之间的互斥,可以使网络更加灵活。
-
- 三个特征图一共可以解码出 8 × 8 × 3 + 16 × 16 × 3 + 32 × 32 × 3 = 4032 个box以及相应的类别、置信度。这4032个box,在训练和推理时,使用方法不一样:
- 训练时4032个box全部送入打标签函数,进行后一步的标签以及损失函数的计算。
- 推理时,选取一个置信度阈值,过滤掉低阈值box,再经过nms(非极大值抑制),就可以输出整个网络的预测结果了。
-
- 第五点:ground truth为什么不按照中心点分配对应的预测box?
-
- (1)在Yolov3的训练策略中,不再像Yolov1那样,每个cell负责中心落在该cell中的ground truth。原因是Yolov3一共产生3个特征图,3个特征图上的cell,中心是有重合的。训练时,可能最契合的是特征图1的第3个box,但是推理的时候特征图2的第1个box置信度最高。所以Yolov3的训练,不再按照ground truth中心点,严格分配指定cell,而是根据预测值寻找IOU最大的预测框作为正例。
-
- (2)笔者实验结果:第一种,ground truth先从9个先验框中确定最接近的先验框,这样可以确定ground
- truth所属第几个特征图以及第几个box位置,之后根据中心点进一步分配。第二种,全部4032个输出框直接和
- ground truth计算IOU,取IOU最高的cell分配ground truth。第二种计算方式的IOU数值,往往都比第一种
- 要高,这样wh与xy的loss较小,网络可以更加关注类别和置信度的学习;其次,在推理时,是按照置信度排
- 序,再进行nms筛选,第二种训练方式,每次给ground truth分配的box都是最契合的box,给这样的box置信
- 度打1的标签,更加合理,最接近的box,在推理时更容易被发现。

训练策略
YOLOv3 predicts an objectness score for each bounding box using logistic regression. This should be 1 if the bounding box prior overlaps a ground truth object by more than any other bounding box prior. If the bounding box prior is not the best but does overlap a ground truth object by more than some threshold we ignore the prediction, following [17]. We use the threshold of .5. Unlike [17] our system only assigns one bounding box prior for each ground truth object. If a bounding box prior is not assigned to a ground truth object it incurs no loss for coordinate or class predictions, only objectness.
以上是Yolov3论文中的训练策略。说实话,最后一句“一个没有被分配ground truth的预测框,只产生置信度loss“,有一定的歧义。深刻理解Yolov3之后,训练策略总结如下:
- 预测框一共分为三种情况:正例(positive)、负例(negative)、忽略样例(ignore)。
- 正例:任取一个ground truth,与4032个框全部计算IOU,IOU最大的预测框,即为正例。并且一个预测框,只能分配给一个ground truth。例如第一个ground truth已经匹配了一个正例检测框,那么下一个ground truth,就在余下的4031个检测框中,寻找IOU最大的检测框作为正例。ground truth的先后顺序可忽略。正例产生置信度loss、检测框loss、类别loss。
- 忽略样例:正例除外,与任意一个ground truth的IOU大于阈值(论文中使用0.5),则为忽略样例。忽略样例不产生任何loss。
- 负例:正例除外(与ground truth计算后IOU最大的检测框,但是IOU小于阈值,仍为正例),与全部ground truth的IOU都小于阈值(0.5),则为负例。负例只有置信度产生loss,置信度标签为0。
- 为什么有忽略样例?
(1)忽略样例是Yolov3中的点睛之笔。由于Yolov3使用了多尺度特征图,不同尺度的特征图之间会有重合检测部分。比如有一个真实物体,在训练时被分配到的检测框是特征图1的第三个box,IOU达0.98,此时恰好特征图2的第一个box与该ground truth的IOU达0.95,也检测到了该ground truth,如果此时给其置信度强行打0的标签,网络学习效果会不理想。
详情:https://zhuanlan.zhihu.com/p/76802514
- Yolov1中的置信度标签,就是预测框与真实框的IOU,Yolov3为什么是1?
(1)置信度意味着该预测框是或者不是一个真实物体,是一个二分类,所以标签是1、0更加合理。
(2)实验结果:第一种:置信度标签取预测框与真实框的IOU;第二种:置信度标签取1。第一种的结果是,在训练时,有些预测框与真实框的IOU极限值就是0.7左右,置信度以0.7作为标签,置信度学习有一些偏差,最后学到的数值是0.5,0.6,那么假设推理时的激活阈值为0.7,这个检测框就被过滤掉了。但是IOU为0.7的预测框,其实已经是比较好的学习样例了。尤其是coco中的小像素物体,几个像素就可能很大程度影响IOU,所以第一种训练方法中,置信度的标签始终很小,无法有效学习,导致检测召回率不高。而检测框趋于收敛,IOU收敛至1,置信度就可以学习到1,这样的设想太过理想化。而使用第二种方法,召回率明显提升了很高。
loss function
对掌握Yolo来讲,loss function不可谓不重要。在v3的论文里没有明确提所用的损失函数,确切地说,yolo系列论文里面只有yolo v1明确提了损失函数的公式。对于yolo这样一种讨喜的目标检测算法,就连损失函数都非常讨喜。在v1中使用了一种叫sum-square error的损失计算方法,就是简单的差方相加而已。想详细了解的可以看我关于v1解释的博文。我们知道,在目标检测任务里,有几个关键信息是需要确定的:(x,y),(w,h),class,confidence
根据关键信息的特点可以分为上述四类,损失函数应该由各自特点确定。最后加到一起就可以组成最终的loss_function了,也就是一个loss_function搞定端到端的训练。可以从代码分析出v3的损失函数,同样也是对以上四类:

总结
v3毫无疑问现在成为了工程界首选的检测算法之一了,结构清晰,实时性好。这是我十分安利的目标检测算法,更值得赞扬的是,yolo_v3给了近乎白痴的复现教程,这种气量在顶层算法研究者中并不常见。你可以很快的用上v3,但你不能很快地懂v3,我花了近一个月的时间才对v3有一个清晰的了解(可能是我悟性不够哈哈哈)。在算法学习的过程中,去一些浮躁,好好理解算法比只会用算法难得很多。
参考
https://zhuanlan.zhihu.com/p/76802514
https://blog.csdn.net/leviopku/article/details/82660381

