
- 1Leecode刷题总结
- 218k+ start开源项目管理工具Focalboard centos部署教程_focalboard在linux运行
- 3SuperSet 安装配置(Win10、python3.9)踩坑无数版_superset windows
- 4MAC 忘记Homebrew安装的mysql密码_mac brew 安装的mysql 忘记初始密码
- 5【大数据】HDFS启动报错无法解决,需要重新格式化namenode_hdfs进程无法启动
- 6使用直方图均衡方法对图像进行白平衡_白平衡直方图
- 7MATLAB图像处理:图像分割、特征提取和目标识别的应用和优化_基于matlab目标识别
- 8支持多平台,无需GPU!仅需8G内存即可部署运行大模型_ollama需要显卡吗
- 9智能家居—ESP32开发环境搭建
- 10怎样创建vue脚手架并写一个简单的页面_vue项目搭建好之后如何写页面
如何学习分布式系统?一文全Get!_分布式系统学习
赞
踩
分布式系统在互联网公司中的应用已经非常普遍,开源软件层出不穷。hadoop生态系统,从hdfs到hbase,从mapreduce到spark,从storm到spark streaming, heron, flink等等,如何在开源的汪洋中不会迷失自己?本文将从基本概念、架构并结合自己学习工作中的感悟,阐述如何学习分布式系统。由于分布式系统理论体系非常庞大,知识面非常广博,笔者能力有限,不足之处,欢迎讨论交流。
常见的分布式系统分为数据存储系统如hdfs,hbase;数据处理计算系统如storm、spark、flink;数据存储兼分析混合系统,这类系统在数据存储的基础上提供了复杂的数据搜索查询功能,如elastic search、druid。对于存储兼计算的系统,我们仍然可以分开分析,所以本文会从数据存储和计算两种系统来论述。
文章的大致结构:第一部分,分布式系统的基本概念;第二、三部分分别详细论述数据存储和数据计算系统;最后一部分总结。
概念
分布式系统:每个人都在提分布式系统,那么什么是分布式系统?其基本概念就是组件分布在网络计算机上,组件之间仅仅通过消息传递来通信并协调行动。
A distributed system is one in which components located at networked computers communicate and coordinate their actions only by passing messages. (摘自分布式系统概念和设计)
节点:节点可以理解为上述概念提到的组件,其实完成一组完整逻辑的程序个体,对应于server上的一个独立进程。一提到节点,就会考虑节点是有状态还是无状态的?判断标准很简单,该独立节点是否维护着本地存储的一些状态信息,或者节点是不是可以随时迁移到其他server上而保持节点的行为和以前一致,如果是的话,则该节点是无状态,否则是有状态的。
异常:异常处理可以说是分布式系统的核心问题,那么分布式异常处理相对于单机来说,有什么不同呢?在单机系统中,对于程序的处理结果是可以预知的,要么成功,要么失败,结果很明确。可在分布式环境中,处理结果除了明确返回成功或失败,还有另外一种状态:超时,那超时意味着处理结果完全不确定,有可能成功执行,也有可能执行失败,也有可能根本没执行,这给系统开发带来了很大的难度。其实各种各样的分布式协议就是保证系统在各种异常情形下仍能正常的工作,所以在学习分布式系统时,要着重看一下文档异常处理fault-tolerance章节。
CAP理论:学习分布式系统中需要重要理解的理论,同时在架构设计中也可以用到这个理论,例如在一些情形下我们可以通过降低一致性来提高系统的可用性,将数据的每次数据库更新操作变成批量操作就是典型的例子。
CAP理论,三个字母代表了系统中三个相互矛盾的属性:
C(Consistency):强一致性,保证数据中的数据完全一致;
A(Available):在系统异常时,仍然可以提供服务,注:这儿的可用性,一方面要求系统可以正常的运行返回结果,另一方面同样对响应速度有一定的保障;
P(Tolerance to the partition of network ):既然是分布式系统,很多组件都是部署在不同的server中,通过网络通信协调工作,这就要求在某些节点服发生网络分区异常,系统仍然可以正常工作。
CAP 理论指出,无法设计一种分布式协议同时完全具备CAP属性。
从以上CAP的概念我们得出一个结论,在技术选型时,根据你的需求来判断是需要AP高可用性的系统(容忍返回不一致的数据)还是CP强一致性的系统,或者根据系统提供的参数在AC之间权衡。(可能会有读者会问,为什么一定需要P呢?既然是分布式系统,在网络分区异常情况下仍然正常提供服务是必须的。)
数据存储系统
当数据量太大以及已经超过单机所能处理的极限时,就需要使用到数据存储分布式系统。无论是选择开源系统还是自己设计,第一个要考虑的问题就是数据如何分布式化。
数据分布方式
哈希方式:哈希方式是最常见的数据分布方式。可以简单想象有一个大的hash表,其中每个桶对应的一台存储服务器,每条数据通过某种方式计算出其hash值分配到对应的桶中。 int serverId = data.hashcode % serverTotalNum 上面只是一个简单的计算公式示例,通过这种方式就可以将数据分配到不同的服务器上。
优点:不需要存储数据和server映射关系的meta信息,只需记录serverId和server ip映射关系即可。
缺点:可扩展性不高,当集群规模需要扩展时,集群中所有的数据需要迁移,即使在最优情况下——集群规模成倍扩展,仍然需要迁移集群一半的数据(这个问题有时间可以考虑一下,为啥只需要迁移一半?);另一个问题:数据通过某种hash计算后都落在某台服务器上,造成数据倾斜(data skew)问题。
应用例子:ElasticSearch数据分布就是hash方式,根据routingId取模映射到对应到不同node上。
数据范围分布:将数据的某个特征值按照值域分为不同区间。比如按时间、区间分割,不同时间范围划分到不同server上。
优点:数据区间可以自由分割,当出现数据倾斜时,即某一个区间的数据量非常大,则可以将该区间split然后将数据进行重分配;集群方便扩展,当添加新的节点,只需将数据量多的节点数据迁移到新节点即可。
缺点:需要存储大量的元信息(数据区间和server的对应关系)。
应用例子:Hbase的数据分布则是利用data的rowkey进行区间划分到不同的region server,而且支持region的split。
数据量分布:按数据量分布,可以考虑一个简单例子:当使用log文件记录一些系统运行的日志信息时,当日志文件达到一定大小,就会生成新的文件开始记录后续的日志信息。这样的存储方式和数据的特征类型没有关系,可以理解成将一个大的文件分成固定大小的多个block。
优点:不会有数据倾斜的问题,而且数据迁移时速度非常快(因为一个文件由多个block组成,block在不同的server上,迁移一个文件可以多个server并行复制这些block)。
缺点: 需要存储大量的meta信息(文件和block的对应关系,block和server的对应关系)。
应用例子:Hdfs的文件存储按数据量block分布。
一致性哈希:前文刚提到的哈希方式,当添加删除节点时候,所有节点都会参与到数据的迁移,整个集群都会受到影响。那么一致性哈希可以很好的解决这个问题。一致性哈希和哈希的数据分布方式大概一致,唯一不同的是一致性哈希hash的值域是个环。
优点:集群可扩展性好,当增加删除节点,只影响相邻的数据节点。
缺点:上面的优点同时也是缺点,当一个节点挂掉时,将压力全部转移到相邻节点,有可能将相邻节点压垮。
应用例子:Cassandra数据分布使用的是一致性hash,只不过使用的是一致性hash改良版:虚拟节点的一致性hash(有兴趣的可以研究下)。
讨论完数据分布问题,接下来该考虑如何解决当某个节点服务不可达的时候系统仍然可以正常工作(分布式系统CAP中网络分区异常问题)?这个问题的解决方案说起来很简单,就是将数据的存储增加多个副本,而且分布在不同的节点上,当某个节点挂掉的时候,可以从其他数据副本读取。
引入多个副本后,引来了一系列问题:多个副本之间,读取时以哪个副本的数据为准呢,更新时什么才算更新成功,是所有副本都更新成功还是部分副本更新成功即可认为更新成功?这些问题其实就是CAP理论中可用性和一致性的问题。其中primary-secondary副本控制模型则是解决这类问题行之有效的方法。
primary-secondary控制模型
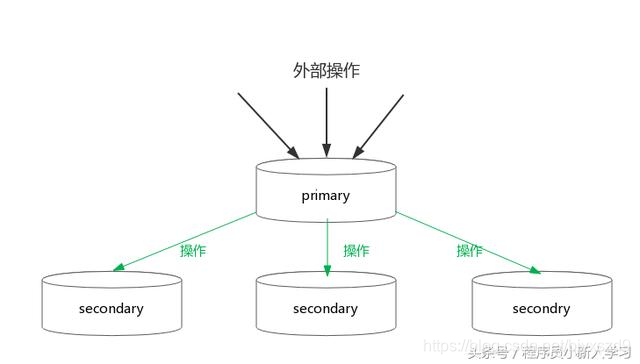
主从(primary-secondary )模型是一种常见的副本更新读取模型,这种模型相对来说简单,所有的副本相关控制都由中心节点控制,数据的并发修改同样都由主节点控制,这样问题就可以简化成单机问题,极大的简化系统复杂性。
注:常用的副本更新读取架构有两种:主从(primary-secondary)和去中心化(decentralized)结构,其中主从结构较为常见,而去中心化结构常采用paxos、raft、vector time等协议,这里由于本人能力有限,就不再这儿叙述了,有兴趣可以自己学习,欢迎补充。
其中涉及到主从副本操作有以下几种:
副本的更新
副本更新基本流程:数据更新操作发到primary节点,由primary将数据更新操作同步到其他secondary副本,根据其他副本的同步结果返回客户端响应。各类数据存储分布式系统的副本更新操作流程大体是一样的,唯一不同的是primary副本更新操作完成后响应客户端时机的不同,这与系统可用性和一致性要求密切相关。
以mysql的master slave简单说明下,通常情况下,mysql的更新只需要master更新成功即可响应客户端,slave可以通过binlog慢慢同步,这种情形读取slave会有一定的延迟,一致性相对较弱,但是系统的可用性有了保证;另一种slave更新策略,数据的更新操作不仅要求master更新成功,同时要求slave也要更新成功,primary和secondray数据保持同步,系统保证强一致性,但可用性相对较差,响应时间变长。
上述的例子只有两个副本,如果要求强一致性,所有副本都更新完成才认为更新成功,响应时间相对来说也可以接受,但是如果副本数更多,有没有什么方法在保证一定一致性同时满足一定的可用性呢?这时就需要考虑Quorum协议,其理论可以用一个简单的数学问题来说明:
有N个副本,其中在更新时有W个副本更新成功,那我们读取R个副本,W、R在满足什么条件下保证我们读取的R个副本一定有一个副本是最新数据(假设副本都有一个版本号,版本号大的即为最新数据)?
问题的答案是:W+R > N (有兴趣的可以思考下)
通过quorum协议,在保证一定的可用性同时又保证一定的一致性的情形下,设置副本更新成功数为总副本数的一半(即N/2+1)性价比最高。(看到这儿有没有想明白为什么zookeeper server数最好为基数个?)
副本的读取
副本的读取策略和一致性的选择有关,如果需要强一致性,我们可以只从primary副本读取,如果需要最终一致性,可以从secondary副本读取结果,如果需要读取最新数据,则按照quorum协议要求,读取相应的副本数。
副本的切换
当系统中某个副本不可用时,需要从剩余的副本之中选取一个作为primary副本来保证后续系统的正常执行。这儿涉及到两个问题:
副本状态的确定以及防止brain split问题:一般方法是利用zookeeper中的sesstion以及临时节点,其基本原理则是lease协议和定期heartbeat。Lease协议可以简单理解成参与双方达成一个承诺,针对zookeeper,这个承诺就是在session有效时间内,我认为你的节点状态是活的是可用的,如果发生session timeout,认为副本所在的服务已经不可用,无论误判还是服务真的宕掉了,通过这种机制可以防止脑裂的发生。但这样会引起另外一个问题:当在session timeout期间,primary 副本服务挂掉了,这样会造成一段时间内的服务不可用。
primary副本的确定:这个问题和副本读取最新数据其实是一个问题,可以利用quoram以及全局版本号确定primary副本。zookeeper在leader选举的过程中其实利用了quoram以及全局事务id——zxid确定primary副本。
存储架构模型
关于数据的分布和副本的模型这些细节问题已经详细叙述,那么从系统整体架构来看,数据存储的一般流程和主要模块都有哪些呢?从元数据存储以及节点之间的membership管理方面来看,主要分以下两类:
中心化的节点membership管理架构
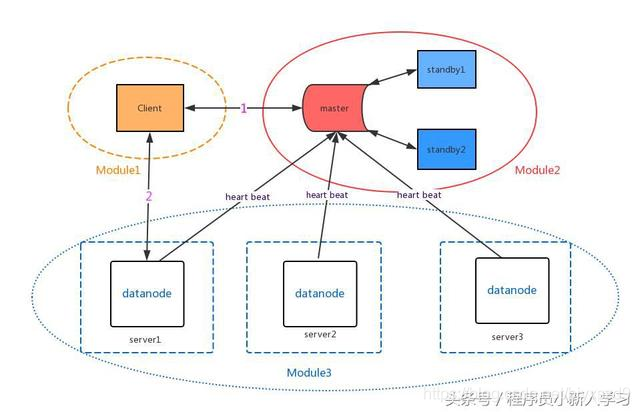
这类系统主要分为三个模块:client模块,负责用户和系统内部模块的通信;master节点模块,负责元数据的存储以及节点健康状态的管理;data节点模块,用于数据的存储和数据查询返回。
数据的查询流程通常分两步:1. 向master节点查询数据对应的节点信息;2. 根据返回的节点信息连接对应节点,返回相应的数据。
分析一下目前常见的数据存储系统,从hdfs,hbase再到Elastic Search,通过与上述通用系统对比,发现:master节点模块具体对应hdfs的namenode、hbase的hMaster、Elastic Search的master节点;data节点对应hdfs的datanode、hbase的region server、Elastic Search的data node。
去中心化的节点membership管理架构
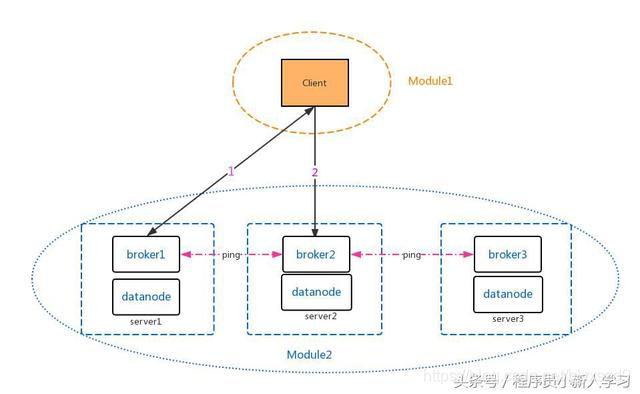
与上一模型比较,其最大的变化就是该架构中不存在任何master节点,系统中的每个节点可以做类似master的任务:存储系统元信息以及管理集群节点。
数据的查询方式也有所不同,client可以访问系统中的任意节点,而不再局限于master节点,具体查询流程如下:1. 查询系统中任意节点,如果该数据在此节点上则返回相应的数据,如果不在该节点,则返回对应数据的节点地址,执行第二步;2. 获得数据对应的地址后向相关请求数据。
节点之间共享状态信息是如何做到的呢?常用的方法是使用如gossip的协议以及在此基础之上开发的serf框架,感兴趣的话可以参考redis cluster 和 consul实现。
数据计算处理系统
常用的数据计算主要分为离线批量计算,可以是实时计算,也可以是准实时mini-batch计算,虽然开源的系统很多,且每个系统都有其侧重点,但有些问题却是共性相通的。
数据投递策略
在数据处理中首先要考虑一个问题,我们的数据记录在系统中会被处理几次(包括正常情形和异常情形):
at most once:数据处理最多一次,这种语义在异常情况下会有数据丢失;
at least once:数据处理最少一次,这种语义会造成数据的重复;
exactly once:数据只处理一次,这种语义支持是最复杂的,要想完成这一目标需要在数据处理的各个环节做到保障。
如何做到exactly once, 需要在数据处理各个阶段做些保证:
数据接收:由不同的数据源保证。
数据传输:数据传输可以保证exactly once。
数据输出:根据数据输出的类型确定,如果数据的输出操作对于同样的数据输入保证幂等性,这样就很简单(比如可以把kafka的offset作为输出mysql的id),如果不是,要提供额外的分布式事务机制如两阶段提交等等。
异常任务的处理
异常处理相对数据存储系统来说简单很多,因为数据计算的节点都是无状态的,只要启动任务副本即可。
注意:异常任务除了那些失败、超时的任务,还有一类特殊任务——straggler(拖后腿)任务,一个大的Job会分成多个小task并发执行,发现某一个任务比同类型的其他任务执行要慢很多(忽略数据倾斜导致执行速度慢的因素)。
其中任务恢复策略有以下几种:
简单暴力,重启任务重新计算相关数据,典型应用:storm,当某个数据执行超时或失败,则将该数据从源头开始在拓扑中重新计算。
根据checkpoint重试出错的任务,典型应用:mapreduce,一个完整的数据处理是分多个阶段完成的,每个阶段(map 或者reduce)的输出结果都会保存到相应的存储中,只要重启任务重新读取上一阶段的输出结果即可继续开始运行,不必从开始重新执行该任务。
背压——Backpressure
在数据处理中,经常会担心这样一个问题:数据处理的上游消费数据速度太快,会不会压垮下游数据输出端如mysql等。 通常的解决方案:上线前期我们会做详细的测试,评估数据下游系统承受的最大压力,然后对数据上游进行限流的配置,比如限制每秒最多消费多少数据。其实这是一个常见的问题,现在各个实时数据处理系统都提供了背压的功能,包括spark streaming、storm等,当下游的数据处理速度过慢,系统会自动降低上游数据的消费速度。
对背压感兴趣朋友们,或者有想法自己实现一套数据处理系统,可以参考Reactive Stream,该项目对通用数据处理提供了一种规范,采用这种规范比较有名的是akka。
数据处理通用架构
数据处理的架构大抵是相似的,通常包含以下几个模块:
client: 负责计算任务的提交。
scheduler : 计算任务的生成和计算资源的调度,同时还包含计算任务运行状况的监控和异常任务的重启。
worker:计算任务会分成很多小的task, worker负责这些小task的执行同时向scheduler汇报当前node可用资源及task的执行状况。
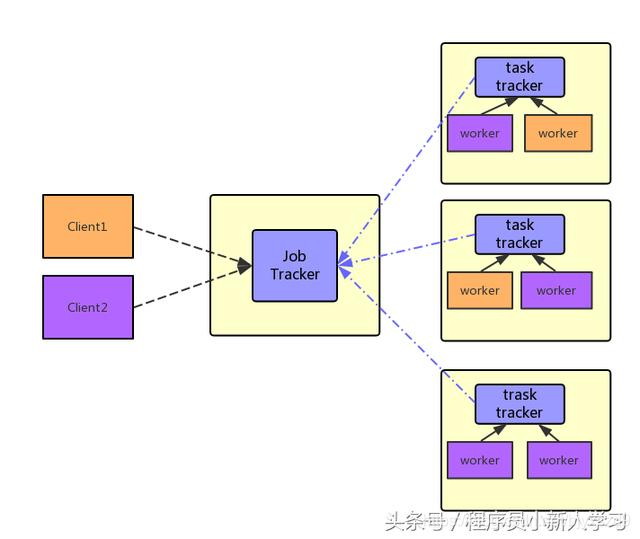
上图是通用的架构模型图,有些人会问这是hadoop v1版本的mapreduce计算框架图,现在都已经yarn模式的新的计算框架图,谁还用这种模式?哈哈,说的对,但是现在仍然有些处理框架就是这种模型————storm。
不妨把图上的一些概念和storm的概念映射起来:Job tracker 对应于 nimbus,task tracker 对应于 supervisor,每台supervisor 同样要配置worker slot,worker对应于storm中的worker。 这样一对比,是不是就觉得一样了?
这种框架模型有它的问题,责任不明确,每个模块干着多样工作。例如Job tracker不仅要监控任务的执行状态,还要负责任务的调度。TaskTracker也同样,不仅要监控task的状态、执行,同样还要监控节点资源的使用。
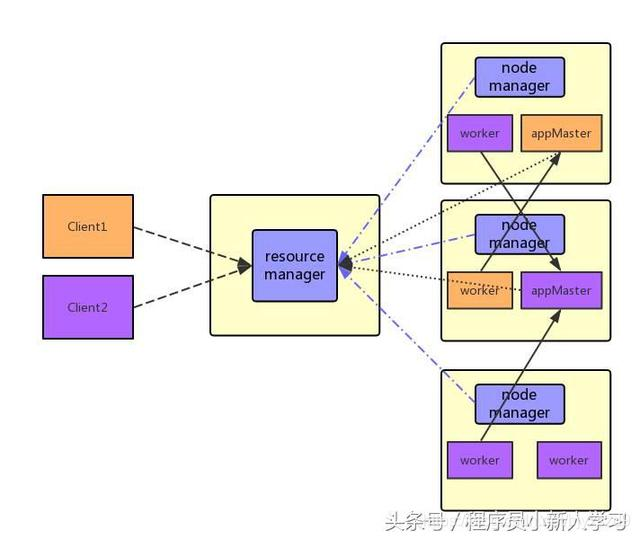
针对以上问题,基于yarn模式的新的处理架构模型,将任务执行状态的监控和任务资源的调度分开。原来的Job tracker分为resource manger 负责资源的调度,任务执行的监控则交给每个appMaster来负责,原来的task tracker,变为了node manager,负责资源的监控和task的启动,而task的执行状态和异常处理则交给appMaster处理。
同样的,twitter 根据storm架构方面的一些问题,推出了新的处理框架heron,其解决的问题也是将任务的调度和任务的执行状态监控责任分离,引入了新的概念Topology Master,类似于这儿的appMaster。
总结
分布式系统涵盖的内容非常多,本篇文章主要从整体架构以及概念上介绍如何入门,学习过程有一些共性的问题,在这儿总结一下:
先分析该系统是数据存储还是计算系统。
如果是数据存储系统,从数据分布和副本策略开始入手;如果是数据处理问题,从数据投递策略入手。
读对应系统架构图,对应着常用的架构模型,每个组件和已有的系统进行类比,想一下这个组件类似于hdfs的namenode等等,最后在脑海里梳理下数据流的整个流程。
在了解了系统的大概,着重看下文档中fault tolerence章节,看系统如何容错,或者自己可以预先问些问题,比如如果一个节点挂了、一个任务挂了系统是如何处理这些异常的,带着问题看文档。
文档详细读了一遍,就可以按照官方文档写些hello world的例子了,详细查看下系统配置项,随着工作的深入就可以看些系统的细节和关键源码了。

