
- 1jsp连接各种数据库的代码_jsp链接数据库的各种方式以及实现代码
- 2界面开发(3)--- PyQt5用户登录界面连接数据库_pyqt页面制作登录界面并连接数据库
- 3jsp 连接 mysql 方法_jsp连接数据库的几种方式
- 4asp.net------C# MVC之接口返回json数据_asp.net返回json嵌套
- 5vue+element项目中过滤输入框特殊字符防止xss攻击_vue对输入框内容做过滤
- 6综述向:强化学习经典方法梳理_强化学习综述
- 7什么是软件安全性测试?如何进行安全测试?
- 8Python是什么?Python人才需求现状?如何学习编程?_爬虫需要人才码
- 9维修上门预约小程序源码系统 附带完整的搭建教程_上门维修小程序源码
- 10【Navicat】Navicat实现自动备份数据库_navicat自动备份
SQLAlchemy
赞
踩
一 概述
SQLAlchemy是 SQL工具包和对象关系映射器用于使用 数据库和 Python。它有几个不同的区域 ,可单独使用或组合使用。其主要组成部分如下所示, 将组件依赖项组织成层:
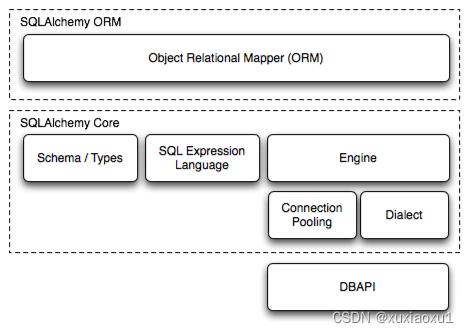
上面两个最重要的部分 SQLAlchemy是对象关系映射器(ORM)和Core。
Core包含SQLAlchemy的SQL和数据库的广度集成和描述服务,其中最突出的部分是SQL 表达式语言。
SQL表达式语言是一个独立的工具包,独立于ORM 包,它提供了一个构造 SQL 表达式的系统,表示为 可组合对象,然后可以针对目标数据库“执行” 在特定事务的范围内,返回结果集。 插入、更新和删除(即 DML)是通过传递来实现的 表示这些语句以及字典的 SQL 表达式对象 表示要与每个语句一起使用的参数。
ORM建立在Core之上,提供了一种处理域对象的方法 映射到数据库架构的模型。使用 ORM 时,SQL 语句是 构造方式与使用 Core 时大致相同,但是 DML 的任务, 这里指的是数据库中业务对象的持久性,是 使用称为工作单元的模式自动转换更改 在状态中针对可变对象进入插入、更新和删除构造 然后根据这些对象调用它们。选择语句也是 通过特定于 ORM 的自动化和以对象为中心的查询功能进行增强。
而使用 Core 和 SQL 表达式语言则呈现 以架构为中心的数据库视图,以及 ORM以不变性为导向,在此基础上构建了以域为中心的 具有更明确的编程范例的数据库视图 面向对象,依赖于可变性。由于关系数据库是 本身是一个可变服务,区别在于核心/SQL表达式语言 是面向命令的,而ORM是面向状态的。
安装:
pip install SQLAlchemy
- 1
二 使用
任何 SQLAlchemy 应用程序的启动都是一个名为 Engine 的对象。此对象充当连接的中央源 到特定数据库,同时提供工厂和控股 为这些数据库调用连接池的空间 连接。引擎通常是仅创建的全局对象 一次用于特定数据库服务器,并使用 URL 字符串进行配置 这将描述它应该如何连接到数据库主机或后端。
MySQL-Python
mysql+mysqldb://<user>:<password>@<host>[:<port>]/<dbname>
pymysql
mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>]
MySQL-Connector
mysql+mysqlconnector://<user>:<password>@<host>[:<port>]/<dbname>
cx_Oracle
oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...]
更多:http://docs.sqlalchemy.org/en/latest/dialects/index.html
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
2.1 执行原生SQL
from sqlalchemy import create_engine engine = create_engine( "mysql+pymysql://root:123@127.0.0.1:3306/tutorial?charset=utf8mb4", max_overflow=0, # 超过连接池大小外最多创建的连接 pool_size=5, # 连接池大小 pool_timeout=30, # 池中没有,线程最多等待的时间,否则报错 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) ) # engine = create_engine("sqlite+pysqlite:///:memory:", echo=True, future=True) # 通过engine从链接池中拿到一个链接对象 conn = engine.raw_connection() # 生成游标 cursor = conn.cursor() # 执行sql语句 cursor.execute('select `article_title` from article') res = cursor.fetchall() print(res)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
2.2 orm创建删除表
from sqlalchemy import create_engine, Column, Integer, String, DateTime, Text, Index, UniqueConstraint from sqlalchemy.orm import declarative_base import datetime Base = declarative_base() def get_engine(): engine = create_engine( "mysql+pymysql://root:123@127.0.0.1:3306/sqlalchemy?charset=utf8mb4", max_overflow=0, # 超过连接池大小外最多创建的连接 pool_size=5, # 连接池大小 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) ) return engine class Users(Base): __tablename__ = 'users' # 数据库表名称 id = Column(Integer, primary_key=True) # id 主键 name = Column(String(32), index=True, nullable=False) # name列,索引,不可为空 email = Column(String(32), unique=True) # datetime.datetime.now不能加括号,加了括号,以后永远是当前时间 ctime = Column(DateTime, default=datetime.datetime.now) extra = Column(Text, nullable=True) __table_args__ = ( UniqueConstraint('id', 'name', name='uix_id_name'), # 联合唯一 Index('ix_id_name', 'name', 'email'), # 索引 ) def init_db(): """ 根据类创建数据库表 :return: """ engine = get_engine() Base.metadata.create_all(engine) def drop_db(): """ 根据类删除数据库表 :return: """ engine = get_engine() Base.metadata.drop_all(engine) if __name__ == '__main__': init_db() # drop_db()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
三 一对多关系
class Publish(Base):
__tablename__ = 'publish'
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(32), nullable=False)
class Book(Base):
__tablename__ = 'book'
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(32), nullable=False)
publish_id = Column(Integer, ForeignKey('publish.id'))
# 跟数据库无关,不会新增字段,只用于快速链表操作
# 类名,backref用于反向查询
publish = relationship('Publish', backref='books')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
四 多对多关系
class Book(Base): __tablename__ = 'book' id = Column(Integer, primary_key=True, autoincrement=True) name = Column(String(32), nullable=False) publish_id = Column(Integer, ForeignKey('publish.id')) # 跟数据库无关,不会新增字段,只用于快速链表操作 # 类名,backref用于反向查询 publish = relationship('Publish', backref='books') class Author(Base): __tablename__ = 'author' id = Column(Integer, primary_key=True, autoincrement=True) name = Column(String(32), nullable=True) # 与生成表结构无关,仅用于查询方便,放在哪个单表中都可以 book = relationship('Book', secondary='book2author', backref='books') class BookToAuthor(Base): __tablename__ = 'book2author' id = Column(Integer, primary_key=True, autoincrement=True) book_id = Column(Integer, ForeignKey('book.id')) author_id = Column(Integer, ForeignKey('author.id'))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
五 操作数据表
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from models import Users
engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/sqlalchemy?charset=utf8mb4")
Session = sessionmaker(bind=engine)
session = Session()
user_obj = Users(name='xuxiaoxu', email='xxx@163.com')
session.add(user_obj)
session.commit()
session.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
六 基于scoped_session实现线程安全
scoped_session中有原来Session中的以下方法:
methods=[ "__contains__", "__iter__", "add", "add_all", "begin", "begin_nested", "close", "commit", "connection", "delete", "execute", "expire", "expire_all", "expunge", "expunge_all", "flush", "get", "get_bind", "is_modified", "bulk_save_objects", "bulk_insert_mappings", "bulk_update_mappings", "merge", "query", "refresh", "rollback", "scalar", "scalars", ]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from sqlalchemy.orm import scoped_session
from models import Users
engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/sqlalchemy?charset=utf8mb4")
Session = sessionmaker(engine)
session = scoped_session(Session)
user_obj = Users(name='jasper', email='yyy@qq.com', extra='handsome')
session.add(user_obj)
session.commit()
session.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
七 基本增删查改
from sqlalchemy import create_engine, text from sqlalchemy.orm import sessionmaker, scoped_session from models import Users engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/sqlalchemy?charset=utf8mb4") Session = sessionmaker(bind=engine) session = scoped_session(Session) ############## 查询 ############### # 查询所有 # res = session.query(Users).all() # 查询name字段和extra字段,并给name字段起别名xx # res = session.query(Users.name.label('xx'), Users.extra).all() # filter传的是表达式 # res = session.query(Users).filter(Users.name == 'xuxiaoxu').all() # filter_by传的是参数 # res = session.query(Users).filter_by(id=2).all() # :id 和:name 相当于占位符,用params传参数 # res = session.query(Users).filter(text('id<:id and name=:name')).params(id=2, name='xuxiaoxu').all() # 自定义查询sql # res = session.query(Users).from_statement(text('select * from users')).all() ################ 增 ############### # 增加一条 # user_obj = Users(name='张三') # session.add(user_obj) # 增加多条 # session.add_all([ # Users(name='李四'), # Users(name='王五'), # ]) ################ 删除 ############### # obj = session.query(Users).filter_by(name='王五').first() # session.delete(obj) ################ 更新 ############### # 传字典 # session.query(Users).filter(Users.id > 0).update({"extra": "update"}) # 类似于django的F查询 session.query(Users).filter(Users.id > 0).update({Users.name: Users.name + "_handsome"}, synchronize_session=False) # 数字需指定synchronize_session="evaluate" session.query(Users).filter(Users.id > 0).update({"age": Users.age + 1}, synchronize_session="evaluate") # 增删改都需要commit session.commit() session.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
八 常用操作
from sqlalchemy import create_engine from sqlalchemy.orm import sessionmaker, scoped_session from models import Users, Publish, Book engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/sqlalchemy?charset=utf8mb4") Session = sessionmaker(engine) session = scoped_session(Session) # 按条件查 # res = session.query(Users).filter_by(id=90).all() # 按表达式 # res = session.query(Users.age).filter(Users.id > 80, Users.age < 100).all() # res = session.query(Users).filter(Users.id.between(1, 3)).all() # in # res = session.query(Users).filter(Users.id.in_([1, 2])).all() # ~ 非 # res = session.query(Users).filter(~Users.age.in_([1, 2])).all() # 二次筛选 # res = session.query(Users).filter(Users.id < (session.query(Users.id).filter(Users.age > 100).first()[0])) from sqlalchemy import and_, or_ # or_包裹的都是or条件,and_包裹的都是and条件 # res = session.query(Users).filter(and_(Users.id > 3, Users.name == 'x10')).all() # res = session.query(Users).filter(or_(Users.id < 2, Users.name == 'x10')).all() # res = session.query(Users).filter( # or_( # Users.id < 2, # and_(Users.name == 'x10', Users.id > 3), # Users.extra != "" # )).all() # 通配符,以e开头,不以e开头 # res = session.query(Users).filter(Users.name.like('e%')).all() # res = session.query(Users).filter(~Users.name.like('e%')).all() # 限制,用于分页,区间 # res = session.query(Users).all()[1:10] # 排序,根据name降序排列(从大到小) # res = session.query(Users).order_by(Users.name.desc()).all() # 升序 # res = session.query(Users).order_by(Users.name.asc()).all() # 第一个条件重复后,再按第二个条件升序排 # res = session.query(Users).order_by(Users.name.desc(), Users.id.asc()).all() # 分组 from sqlalchemy import func # res = session.query(Users.extra).group_by(Users.extra).all() # 分组之后取最大id,id之和,最小id,统计个数 # res = session.query( # func.max(Users.id), # func.sum(Users.id), # func.min(Users.id), # func.count(Users.id), # ).group_by(Users.extra).all() # having筛选 # res = session.query( # func.max(Users.id), # func.sum(Users.id), # func.min(Users.id), # func.count(Users.id), # ).group_by(Users.extra).having(func.min(Users.id > 2)).all() # 连表(默认用ForeignKey关联) # res = session.query(Publish, Book).filter(Publish.id == Book.id).all() # join表,默认是inner join # SELECT publish.id AS publish_id, publish.name AS publish_name # FROM publish INNER JOIN book ON publish.id = book.publish_id # res = session.query(Publish, Book).join(Book).all() # isouter=True 外连,表示Person left join Favor,没有右连接,反过来即可 # res = session.query(Publish, Book).join(Book, isouter=True) # res = session.query(Publish, Book).join(Publish, isouter=True) # 自己指定on条件(连表条件),第二个参数,支持on多个条件,用and_,同上 # res = session.query(Publish, Book).join(Book, Publish.id == Book.id, isouter=True).all() # 组合UNION 操作符用于合并两个或多个 SELECT 语句的结果集 # union和union all的区别? # union: 对两个结果集进行并集操作, 不包括重复行,相当于distinct, 同时进行默认规则的排序; # union all: 对两个结果集进行并集操作, 包括重复行, 即所有的结果全部显示, 不管是不是重复; # q1 = session.query(Users.name).filter(Users.id > 90) # q2 = session.query(Users.name).filter(Users.id <= 100) # res = q1.union(q2).all() q1 = session.query(Users.name).filter(Users.id > 90) q2 = session.query(Users.name).filter(Users.id <= 100) res = q1.union_all(q2).all() print(res)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
九 一对多新增和基于对象的查询
from sqlalchemy import create_engine from sqlalchemy.orm import sessionmaker, scoped_session from models import Publish, Book engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/sqlalchemy?charset=utf8mb4") Session = sessionmaker(engine) session = scoped_session(Session) # 指定外键字段id号 # book_obj = Book(name='安徒生童话', publish_id=2) # 通过外键字段对象创建 # publish_obj = session.query(Publish).filter_by(name='东方出版社').first() # book_obj = Book(name='三毛流浪记', publish=publish_obj) # session.add(book_obj) # 正向查询 # book_obj = session.query(Book).filter_by(id=1).first() # res = book_obj.publish # print(res.name) # print(res.id) # 反向查询 # 方式一:使用relationship的参数backref反向查询 # publish_obj = session.query(Publish).filter_by(id=1).first() # res = publish_obj.books # print(res) # for i in res: # print(i.name, i.id) # 方式二:join链表 book_list = session.query(Book, Publish).join(Publish).filter(Publish.id == 1).all() print(book_list) for i in book_list: print(i[0].name, i[0].id) session.commit() session.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
十 多对多新增和基于对象的跨表查询
from sqlalchemy import create_engine from sqlalchemy.orm import sessionmaker, scoped_session from models import Book, Author, BookToAuthor engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/sqlalchemy?charset=utf8mb4") Session = sessionmaker(engine) session = scoped_session(Session) # 添加 # 方式一:手动操作第三张表的方式 # author_obj1 = Author(name='张三') # author_obj2 = Author(name='李四') # author_obj3 = Author(name='王二') # # session.add_all([author_obj1, author_obj2, author_obj3]) # # mid_obj1 = BookToAuthor(book_id=1, author_id=1) # mid_obj2 = BookToAuthor(book_id=1, author_id=2) # mid_obj3 = BookToAuthor(book_id=1, author_id=3) # mid_obj4 = BookToAuthor(book_id=2, author_id=2) # mid_obj5 = BookToAuthor(book_id=2, author_id=3) # mid_obj6 = BookToAuthor(book_id=3, author_id=3) # # session.add_all([mid_obj1, mid_obj2, mid_obj3, mid_obj4, mid_obj5, mid_obj6]) # 方式二:通过关联关系 # book_obj1 = Book(name='语文', publish_id=1) # book_obj2 = Book(name='数学', publish_id=1) # book_obj3 = Book(name='英语', publish_id=1) # # author_obj = Author(name='小红', book=[book_obj1, book_obj2, book_obj3]) # session.add(author_obj) # 基于对象的跨表查 # 正向 # author_obj = session.query(Author).filter_by(id=7).first() # # 通过author_obj拿到所有的book # print(author_obj.book) # for i in author_obj.book: # print(i.name, i.id) # 反向 book_obj = session.query(Book).filter_by(id=1).first() print(book_obj.books) session.commit() session.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
十一 flask-sqlalchemy和flask-migrate使用
安装
pip install flask-sqlalchemy
pip install flask-migrate==2.7.0
- 1
- 2
init.py
from flask import Flask from flask_sqlalchemy import SQLAlchemy # 第一步:类实例化得到对象 db = SQLAlchemy() from .views import bp from app.models import * def create_app(): app = Flask(__name__) app.config.from_object('settings.DevelopmentConfig') # 第二步: 将db注册到app中 db.init_app(app) # 注册蓝图 app.register_blueprint(bp) return app
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
views.py
from flask import Blueprint, jsonify from . import db from . import models bp = Blueprint('view', __name__) @bp.route('/') def login(): res = db.session.query(models.User).all() data = [] for i in res: data.append({ 'name': i.username, 'email': i.email, }) return jsonify(data)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
manage.py
from app import create_app from flask_script import Manager from flask_migrate import Migrate, MigrateCommand from app import db """ python3 manage.py db init python3 manage.py db migrate python3 manage.py db upgrade """ app = create_app() # flask-script的使用 # 第一步:初始化出flask_script的manage manager = Manager(app) # 第二步:使用flask_migrate的Migrate 包裹一下app和db(sqlalchemy对象) Migrate(app, db) # 第三步:把命令增加到flask-script中去 manager.add_command('db', MigrateCommand) if __name__ == '__main__': manager.run()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
settings.py
class BaseConfig(object): SQLALCHEMY_DATABASE_URI = "mysql+pymysql://root:123@127.0.0.1:3306/1215?charset=utf8mb4" SQLALCHEMY_POOL_SIZE = 5 SQLALCHEMY_POOL_TIMEOUT = 30 SQLALCHEMY_POOL_RECYCLE = -1 # 追踪对象的修改并且发送信号 SQLALCHEMY_TRACK_MODIFICATIONS = False class ProductionConfig(BaseConfig): pass class DevelopmentConfig(BaseConfig): pass class TestingConfig(BaseConfig): pass
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21

