
- 1已解决(pymysqL连接数据库报错)pymysqL.err.ProgrammingError: (1146,“Table ‘test.students‘ doesn‘t exist“)_raise errorclass(errno, errval) pymysql.err.progra
- 2vue 报错this.$Api.sendEmail is not a function 和TypeError: Cannot set property 'pageCode' of undefined_vue this.$api.不存在
- 3自用的8款AI工具!提升学习/工作/赚钱效率,轻松超过99%的人!
- 4数据结构与算法——归并排序_数据结构归并排序
- 5使用 Xcode 运行 python等脚本语言(perl, ruby)_伊织code
- 6深入理解Elasticsearch的索引映射(mapping)_elasticsearch 类型 映射
- 7三分钟掌握PHP操作数据库_php数据库
- 8远程仓库——GitHub
- 9Hadoop之HBase基本简介_hadoop hbase
- 10[深度学习]yolov8+pyqt5搭建精美界面GUI设计源码实现一_yolo pyqt界面设计代码
Apache Seata基于改良版雪花算法的分布式UUID生成器分析2
赞
踩
title: 关于新版雪花算法的答疑
author: selfishlover
keywords: [Seata, snowflake, UUID, page split]
date: 2021/06/21
本文来自 Apache Seata官方文档,欢迎访问官网,查看更多深度文章。
关于新版雪花算法的答疑
在上一篇关于新版雪花算法的解析中,我们提到新版算法所做出的2点改变:
- 时间戳不再时刻追随系统时钟。
- 节点ID和时间戳互换位置。由原版的:

改成:
有细心的同学提出了一个问题:新版算法在单节点内部确实是单调递增的,但是在多实例部署时,它就不再是全局单调递增了啊!因为显而易见,节点ID排在高位,那么节点ID大的,生成的ID一定大于节点ID小的,不管时间上谁先谁后。而原版算法,时间戳在高位,并且始终追随系统时钟,可以保证早生成的ID小于晚生成的ID,只有当2个节点恰好在同一时间戳生成ID时,2个ID的大小才由节点ID决定。这样看来,新版算法是不是错的?
这是一个很好的问题!能提出这个问题的同学,说明已经深入思考了标准版雪花算法和新版雪花算法的本质区别,这点值得鼓励!在这里,我们先说结论:新版算法的确不具备全局的单调递增性,但这不影响我们的初衷(减少数据库的页分裂)。这个结论看起来有点违反直觉,但可以被证明。
在证明之前,我们先简单回顾一下数据库关于页分裂的知识。以经典的mysql innodb为例,innodb使用B+树索引,其中,主键索引的叶子节点还保存了数据行的完整记录,叶子节点之间以双向链表的形式串联起来。叶子节点的物理存储形式为数据页,一个数据页内最多可以存储N条行记录(N与行的大小成反比)。如图所示:
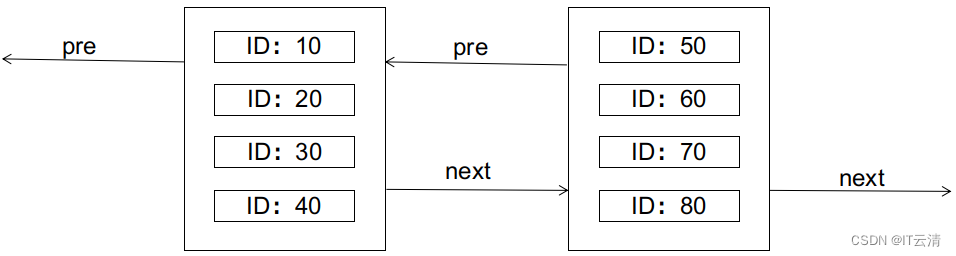
B+树的特性要求,左边的节点应小于右边的节点。如果此时要插入一条ID为25的记录,会怎样呢(假设每个数据页只够存放4条记录)?答案是会引起页分裂,如图:
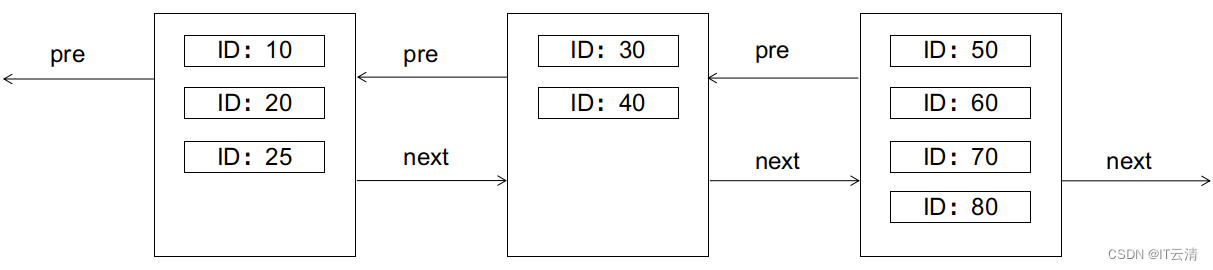
页分裂是IO不友好的,需要新建数据页,拷贝转移旧数据页的部分记录等,我们应尽量避免。
理想的情况下,主键ID最好是顺序递增的(例如把主键设置为auto_increment),这样就只会在当前数据页放满了的时候,才需要新建下一页,双向链表永远是顺序尾部增长的,不会有中间的节点发生分裂的情况。
最糟糕的情况下,主键ID是随机无序生成的(例如java中一个UUID字符串),这种情况下,新插入的记录会随机分配到任何一个数据页,如果该页已满,就会触发页分裂。
如果主键ID由标准版雪花算法生成,最好的情况下,是每个时间戳内只有一个节点在生成ID,这时候算法的效果等同于理想情况的顺序递增,即跟auto_increment无差。最坏的情况下,是每个时间戳内所有节点都在生成ID,这时候算法的效果接近于无序(但仍比UUID的完全无序要好得多,因为workerId只有10位决定了最多只有1024个节点)。实际生产中,算法的效果取决于业务流量,并发度越低,算法越接近理想情况。
那么,换成新版算法又会如何呢?
新版算法从全局角度来看,ID是无序的,但对于每一个workerId,它生成的ID都是严格单调递增的,又因为workerId是有限的,所以最多可划分出1024个子序列,每个子序列都是单调递增的。
对于数据库而言,也许它初期接收的ID都是无序的,来自各个子序列的ID都混在一起,就像这样:
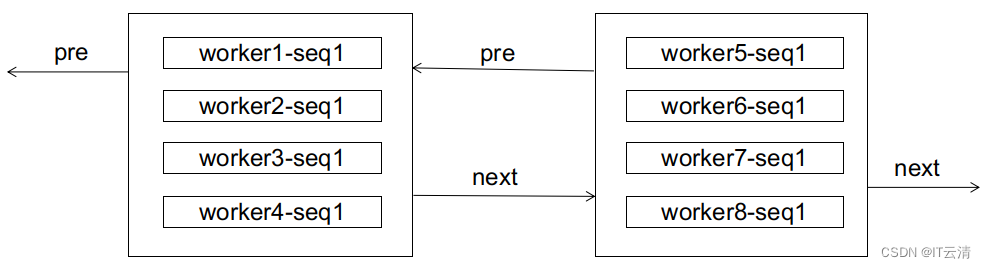
如果这时候来了个worker1-seq2,显然会造成页分裂:

但分裂之后,有趣的事情发生了,对于worker1而言,后续的seq3,seq4不会再造成页分裂(因为还装得下),seq5也只需要像顺序增长那样新建页进行链接(区别是这个新页不是在双向链表的尾部)。注意,worker1的后续ID,不会排到worker2及之后的任意节点(因而不会造成后边节点的页分裂),因为它们总比worker2的ID小;也不会排到worker1当前节点的前边(因而不会造成前边节点的页分裂),因为worker1的子序列总是单调递增的。在这里,我们称worker1这样的子序列达到了稳态,意为这条子序列已经"稳定"了,它的后续增长只会出现在子序列的尾部,而不会造成其它节点的页分裂。
同样的事情,可以推广到各个子序列上。无论前期数据库接收到的ID有多乱,经过有限次的页分裂后,双向链表总能达到这样一个稳定的终态:
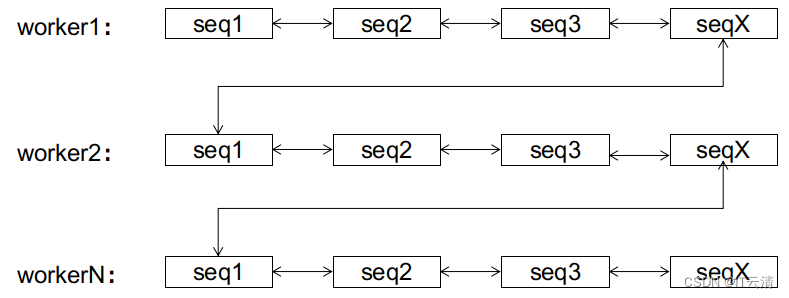
到达终态后,后续的ID只会在该ID所属的子序列上进行顺序增长,而不会造成页分裂。该状态下的顺序增长与auto_increment的顺序增长的区别是,前者有1024个增长位点(各个子序列的尾部),后者只有尾部一个。
到这里,我们可以回答开头所提出的问题了:新算法从全局来看的确不是全局递增的,但该算法是收敛的,达到稳态后,新算法同样能达成像全局顺序递增一样的效果。
扩展思考
以上只提到了序列不停增长的情况,而实践生产中,不光有新数据的插入,也有旧数据的删除。而数据的删除有可能会导致页合并(innodb若发现相邻2个数据页的空间利用率都不到50%,就会把它俩合并),这对新算法的影响如何呢?
经过上面的流程,我们可以发现,新算法的本质是利用前期的页分裂,把不同的子序列逐渐分离开来,让算法不断收敛到稳态。而页合并则恰好相反,它有可能会把不同的子序列又合并回同一个数据页里,妨碍算法的收敛。尤其是在收敛的前期,频繁的页合并甚至可以让算法永远无法收敛(你刚分离出来我就又把它们合并回去,一夜回到解放前~)!但在收敛之后,只有在各个子序列的尾节点进行的页合并,才有可能破坏稳态(一个子序列的尾节点和下一个子序列的头节点进行合并)。而在子序列其余节点上的页合并,不影响稳态,因为子序列仍然是有序的,只不过长度变短了而已。
以seata的服务端为例,服务端那3张表的数据的生命周期都是比较短的,一个全局事务结束之后,它们就会被清除了,这对于新算法是不友好的,没有给时间它进行收敛。不过已经有延迟删除的PR在review中,搭配这个PR,效果会好很多。比如定期每周清理一次,前期就有足够的时间给算法进行收敛,其余的大部分时间,数据库就能从中受益了。到期清理时,最坏的结果也不过是表被清空,算法从头再来。
如果您希望把新算法应用到业务系统当中,请务必确保算法有时间进行收敛。比如用户表之类的,数据本就打算长期保存的,算法可以自然收敛。或者也做了延迟删除的机制,给算法足够的时间进行收敛。
如果您有更好的意见和建议,也欢迎跟seata社区联系!

