
超全Java集合框架讲解(建议收藏)
赞
踩
超全Java集合框架讲解
集合在我们日常开发使用的次数数不胜数,ArrayList/LinkedList/HashMap/HashSet······信手拈来,抬手就拿来用,在 IDE 上龙飞凤舞,但是作为一名合格的优雅的程序猿,仅仅了解怎么使用API是远远不够的,如果在调用API时,知道它内部发生了什么事情,就像开了透视外挂一样,洞穿一切,这种感觉才真的爽,而且这样就不是集合提供什么功能给我们使用,而是我们选择使用它的什么功能了。
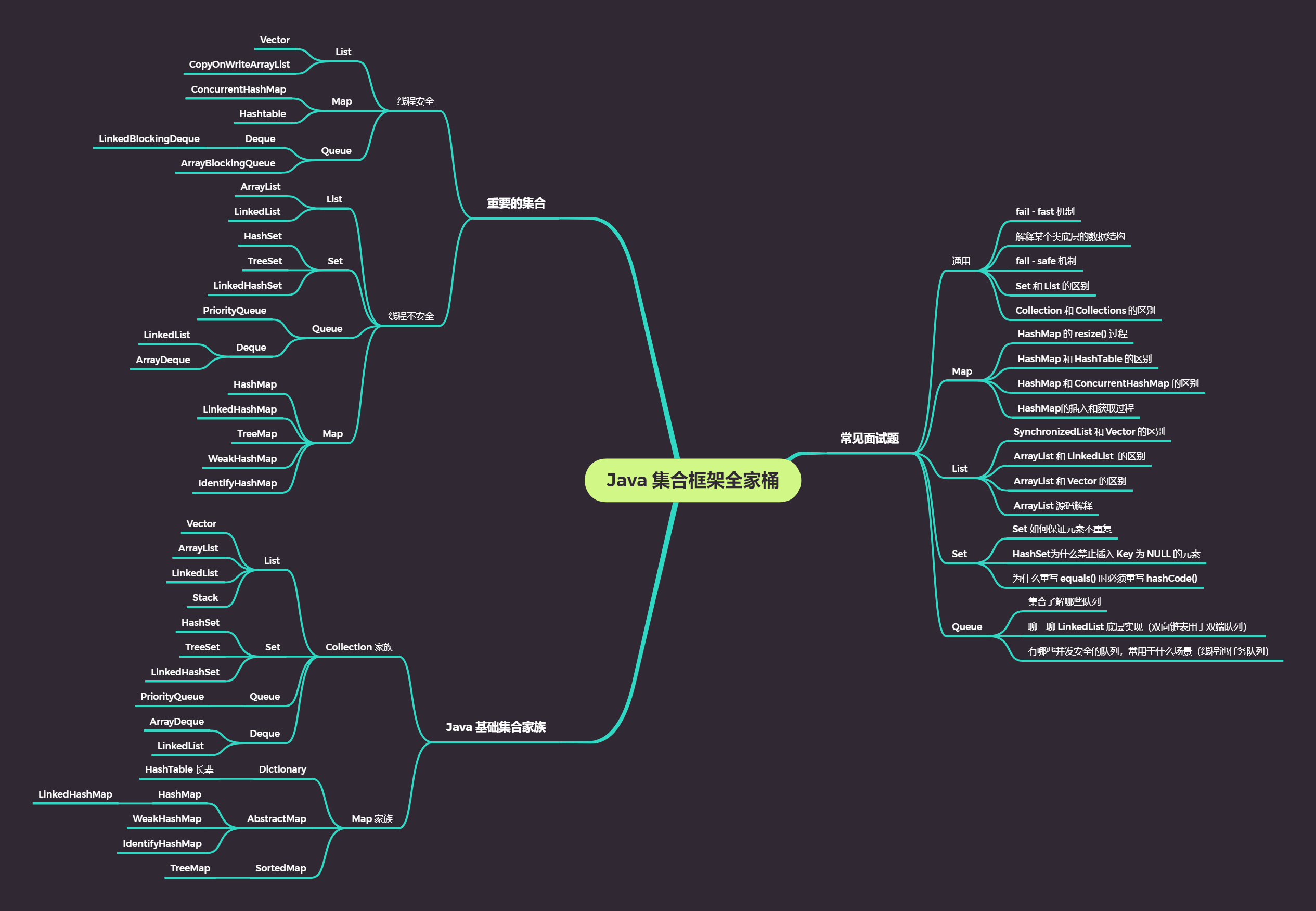
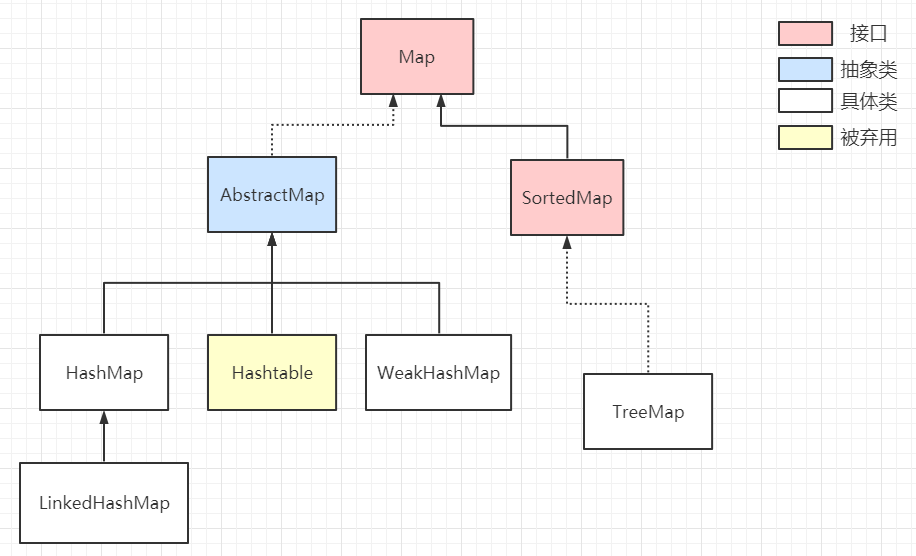
集合框架总览
下图堪称集合框架的上帝视角,讲到集合框架不得不看的就是这幅图,当然,你会觉得眼花缭乱,不知如何看起,这篇文章带你一步一步地秒杀上面的每一个接口、抽象类和具体类。我们将会从最顶层的接口开始讲起,一步一步往下深入,帮助你把对集合的认知构建起一个知识网络。
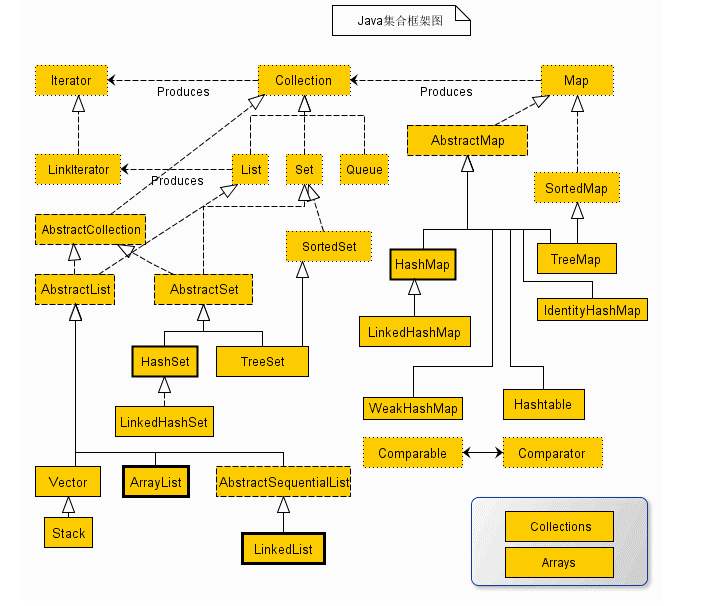
工欲善其事必先利其器,让我们先来过一遍整个集合框架的组成部分:
- 集合框架提供了两个遍历接口:
Iterator和ListIterator,其中后者是前者的优化版,支持在任意一个位置进行前后双向遍历。注意图中的Collection应当继承的是Iterable而不是Iterator,后面会解释Iterable和Iterator的区别 - 整个集合框架分为两个门派(类型):
Collection和Map,前者是一个容器,存储一系列的对象;后者是键值对<key, value>,存储一系列的键值对 - 在集合框架体系下,衍生出四种具体的集合类型:
Map、Set、List、Queue Map存储<key,value>键值对,查找元素时通过key查找valueSet内部存储一系列不可重复的对象,且是一个无序集合,对象排列顺序不一List内部存储一系列可重复的对象,是一个有序集合,对象按插入顺序排列Queue是一个队列容器,其特性与List相同,但只能从队头和队尾操作元素- JDK 为集合的各种操作提供了两个工具类
Collections和Arrays,之后会讲解工具类的常用方法 - 四种抽象集合类型内部也会衍生出许多具有不同特性的集合类,不同场景下择优使用,没有最佳的集合
上面了解了整个集合框架体系的组成部分,接下来的章节会严格按照上面罗列的顺序进行讲解,每一步都会有承上启下的作用
学习
Set前,最好最好要先学习Map,因为Set的操作本质上是对Map的操作,往下看准没错
Iterator Iterable ListIterator
在第一次看这两个接口,真以为是一模一样的,没发现里面有啥不同,存在即合理,它们两个还是有本质上的区别的。
首先来看Iterator接口:
public interface Iterator<E> {
boolean hasNext();
E next();
void remove();
}
- 1
- 2
- 3
- 4
- 5
提供的API接口含义如下:
hasNext():判断集合中是否存在下一个对象next():返回集合中的下一个对象,并将访问指针移动一位remove():删除集合中调用next()方法返回的对象
在早期,遍历集合的方式只有一种,通过Iterator迭代器操作
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
Iterator iter = list.iterator();
while (iter.hasNext()) {
Integer next = iter.next();
System.out.println(next);
if (next == 2) { iter.remove(); }
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
再来看Iterable接口:
public interface Iterable<T> {
Iterator<T> iterator();
// JDK 1.8
default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action);
for (T t : this) {
action.accept(t);
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
可以看到Iterable接口里面提供了Iterator接口,所以实现了Iterable接口的集合依旧可以使用迭代器遍历和操作集合中的对象;
而在 JDK 1.8中,Iterable提供了一个新的方法forEach(),它允许使用增强 for 循环遍历对象。
List<Integer> list = new ArrayList<>();
for (Integer num : list) {
System.out.println(num);
}
- 1
- 2
- 3
- 4
我们通过命令:javap -c反编译上面的这段代码后,发现它只是 Java 中的一个语法糖,本质上还是调用Iterator去遍历。
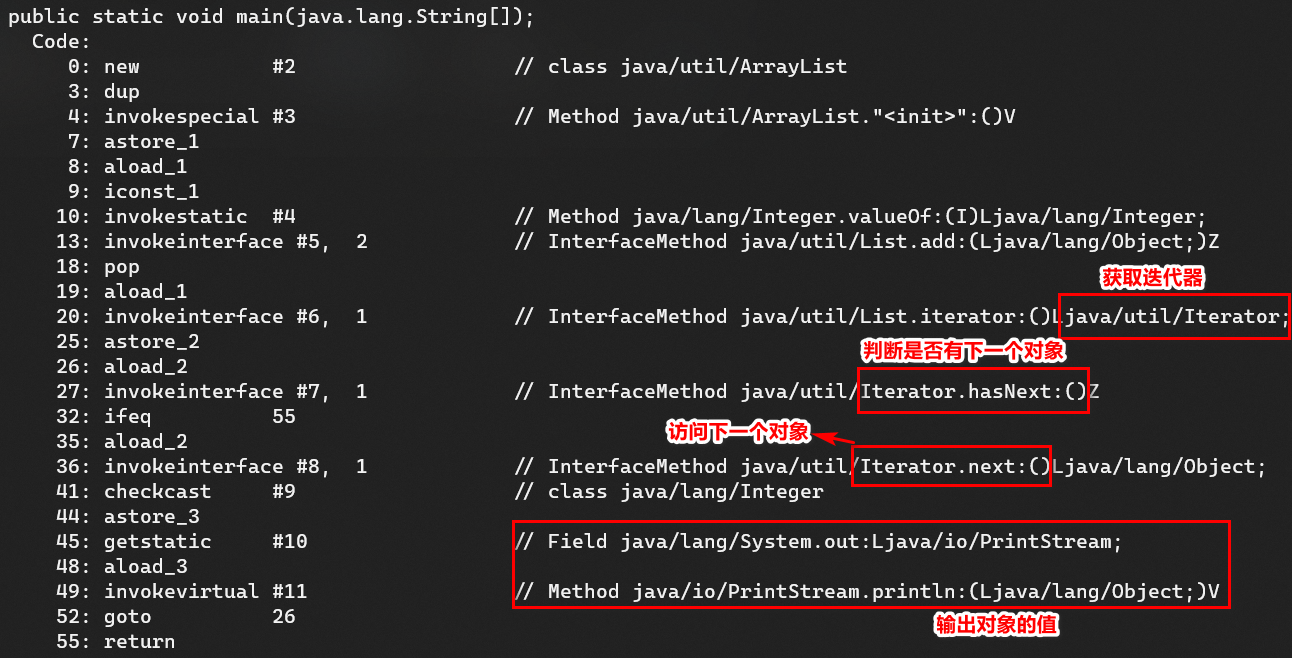
翻译成代码,就和一开始的Iterator迭代器遍历方式基本相同了。
Iterator iter = list.iterator();
while (iter.hasNext()) {
Integer num = iter.next();
System.out.println(num);
}
- 1
- 2
- 3
- 4
- 5
还有更深层次的探讨:为什么要设计两个接口
Iterable和Iterator,而不是保留其中一个就可以了。简单讲解:
Iterator的保留可以让子类去实现自己的迭代器,而Iterable接口更加关注于for-each的增强语法。具体可参考:Java中的Iterable与Iterator详解
关于Iterator和Iterable的讲解告一段落,下面来总结一下它们的重点:
Iterator是提供集合操作内部对象的一个迭代器,它可以遍历、移除对象,且只能够单向移动Iterable是对Iterator的封装,在JDK 1.8时,实现了Iterable接口的集合可以使用增强 for 循环遍历集合对象,我们通过反编译后发现底层还是使用Iterator迭代器进行遍历
等等,这一章还没完,还有一个ListIterator。它继承 Iterator 接口,在遍历List集合时可以从任意索引下标开始遍历,而且支持双向遍历。
ListIterator 存在于 List 集合之中,通过调用方法可以返回起始下标为 index的迭代器
List<Integer> list = new ArrayList<>();
// 返回下标为0的迭代器
ListIterator<Integer> listIter1 = list.listIterator();
// 返回下标为5的迭代器
ListIterator<Integer> listIter2 = list.listIterator(5);
- 1
- 2
- 3
- 4
- 5
ListIterator 中有几个重要方法,大多数方法与 Iterator 中定义的含义相同,但是比 Iterator 强大的地方是可以在任意一个下标位置返回该迭代器,且可以实现双向遍历。
public interface ListIterator<E> extends Iterator<E> {
boolean hasNext();
E next();
boolean hasPrevious();
E previous();
int nextIndex();
int previousIndex();
void remove();
// 替换当前下标的元素,即访问过的最后一个元素
void set(E e);
void add(E e);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
Map 和 Collection 接口
Map 接口和 Collection 接口是集合框架体系的两大门派,Collection 是存储元素本身,而 Map 是存储<key, value>键值对,在 Collection 门派下有一小部分弟子去偷师,利用 Map 门派下的弟子来修炼自己。
是不是听的一头雾水哈哈哈,举个例子你就懂了:HashSet底层利用了HashMap,TreeSet底层用了TreeMap,LinkedHashSet底层用了LinkedHashMap。
下面我会详细讲到各个具体集合类哦,所以在这里,我们先从整体上了解这两个门派的特点和区别。
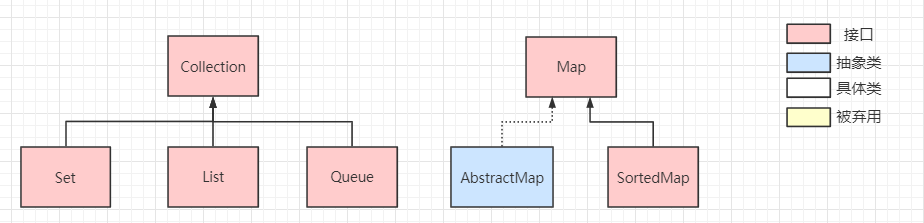
Map接口定义了存储的数据结构是<key, value>形式,根据 key 映射到 value,一个 key 对应一个 value ,所以key不可重复,而value可重复。
在Map接口下会将存储的方式细分为不同的种类:
SortedMap接口:该类映射可以对<key, value>按照自己的规则进行排序,具体实现有 TreeMapAbsractMap:它为子类提供好一些通用的API实现,所有的具体Map如HashMap都会继承它
而Collection接口提供了所有集合的通用方法(注意这里不包括Map):
- 添加方法:
add(E e)/addAll(Collection<? extends E> var1) - 删除方法:
remove(Object var1)/removeAll(Collection<?> var1) - 查找方法:
contains(Object var1)/containsAll(Collection<?> var1); - 查询集合自身信息:
size()/isEmpty() - ···
在Collection接口下,同样会将集合细分为不同的种类:
Set接口:一个不允许存储重复元素的无序集合,具体实现有HashSet/TreeSet···List接口:一个可存储重复元素的有序集合,具体实现有ArrayList/LinkedList···Queue接口:一个可存储重复元素的队列,具体实现有PriorityQueue/ArrayDeque···
Map 集合体系详解
Map接口是由<key, value>组成的集合,由key映射到唯一的value,所以Map不能包含重复的key,每个键至多映射一个值。下图是整个 Map 集合体系的主要组成部分,我将会按照日常使用频率从高到低一一讲解。
不得不提的是 Map 的设计理念:定位元素的时间复杂度优化到 O(1)
Map 体系下主要分为 AbstractMap 和 SortedMap两类集合
AbstractMap是对 Map 接口的扩展,它定义了普通的 Map 集合具有的通用行为,可以避免子类重复编写大量相同的代码,子类继承 AbstractMap 后可以重写它的方法,实现额外的逻辑,对外提供更多的功能。
SortedMap 定义了该类 Map 具有 排序行为,同时它在内部定义好有关排序的抽象方法,当子类实现它时,必须重写所有方法,对外提供排序功能。
HashMap
HashMap 是一个最通用的利用哈希表存储元素的集合,将元素放入 HashMap 时,将key的哈希值转换为数组的索引下标确定存放位置,查找时,根据key的哈希地址转换成数组的索引下标确定查找位置。
HashMap 底层是用数组 + 链表 + 红黑树这三种数据结构实现,它是非线程安全的集合。
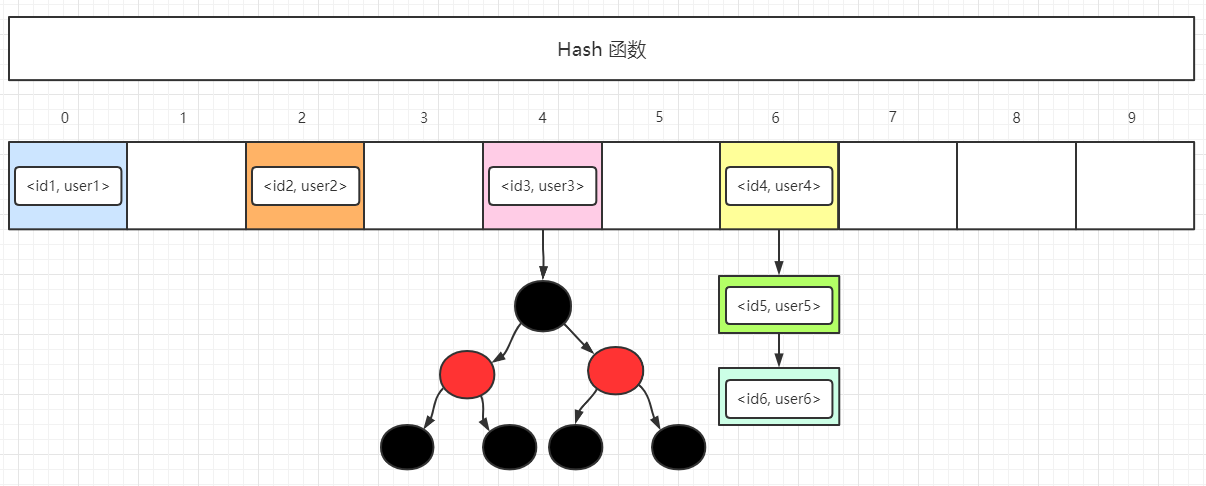
发送哈希冲突时,HashMap 的解决方法是将相同映射地址的元素连成一条链表,如果链表的长度大于8时,且数组的长度大于64则会转换成红黑树数据结构。
关于 HashMap 的简要总结:
- 它是集合中最常用的
Map集合类型,底层由数组 + 链表 + 红黑树组成 - HashMap不是线程安全的
- 插入元素时,通过计算元素的
哈希值,通过哈希映射函数转换为数组下标;查找元素时,同样通过哈希映射函数得到数组下标定位元素的位置
LinkedHashMap
LinkedHashMap 可以看作是 HashMap 和 LinkedList 的结合:它在 HashMap 的基础上添加了一条双向链表,默认存储各个元素的插入顺序,但由于这条双向链表,使得 LinkedHashMap 可以实现 LRU缓存淘汰策略,因为我们可以设置这条双向链表按照元素的访问次序进行排序
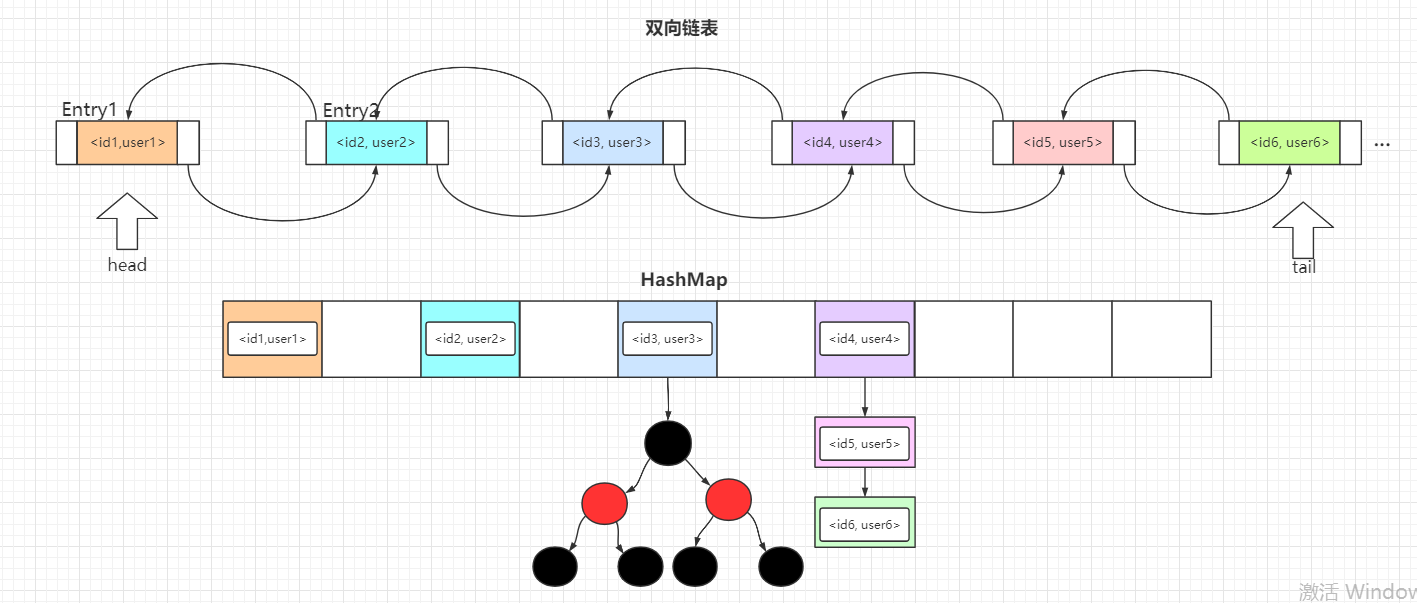
LinkedHashMap 是 HashMap 的子类,所以它具备 HashMap 的所有特点,其次,它在 HashMap 的基础上维护了一条双向链表,该链表存储了所有元素,默认元素的顺序与插入顺序一致。若accessOrder属性为true,则遍历顺序按元素的访问次序进行排序。
// 头节点
transient LinkedHashMap.Entry<K, V> head;
// 尾结点
transient LinkedHashMap.Entry<K, V> tail;
- 1
- 2
- 3
- 4
利用 LinkedHashMap 可以实现 LRU 缓存淘汰策略,因为它提供了一个方法:
protected boolean removeEldestEntry(java.util.Map.Entry<K, V> eldest) {
return false;
}
- 1
- 2
- 3
该方法可以移除最靠近链表头部的一个节点,而在get()方法中可以看到下面这段代码,其作用是挪动结点的位置:
if (this.accessOrder) {
this.afterNodeAccess(e);
}
- 1
- 2
- 3
只要调用了get()且accessOrder = true,则会将该节点更新到链表尾部,具体的逻辑在afterNodeAccess()中,感兴趣的可翻看源码,篇幅原因这里不再展开。
现在如果要实现一个LRU缓存策略,则需要做两件事情:
- 指定
accessOrder = true可以设定链表按照访问顺序排列,通过提供的构造器可以设定accessOrder
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
- 1
- 2
- 3
- 4
- 重写
removeEldestEntry()方法,内部定义逻辑,通常是判断容量是否达到上限,若是则执行淘汰。
关于 LinkedHashMap 主要介绍两点:
- 它底层维护了一条
双向链表,因为继承了 HashMap,所以它也不是线程安全的 - LinkedHashMap 可实现
LRU缓存淘汰策略,其原理是通过设置accessOrder为true并重写removeEldestEntry方法定义淘汰元素时需满足的条件
TreeMap
TreeMap 是 SortedMap 的子类,所以它具有排序功能。它是基于红黑树数据结构实现的,每一个键值对<key, value>都是一个结点,默认情况下按照key自然排序,另一种是可以通过传入定制的Comparator进行自定义规则排序。
// 按照 key 自然排序,Integer 的自然排序是升序
TreeMap<Integer, Object> naturalSort = new TreeMap<>();
// 定制排序,按照 key 降序排序
TreeMap<Integer, Object> customSort = new TreeMap<>((o1, o2) -> Integer.compare(o2, o1));
- 1
- 2
- 3
- 4
TreeMap 底层使用了数组+红黑树实现,所以里面的存储结构可以理解成下面这幅图哦。
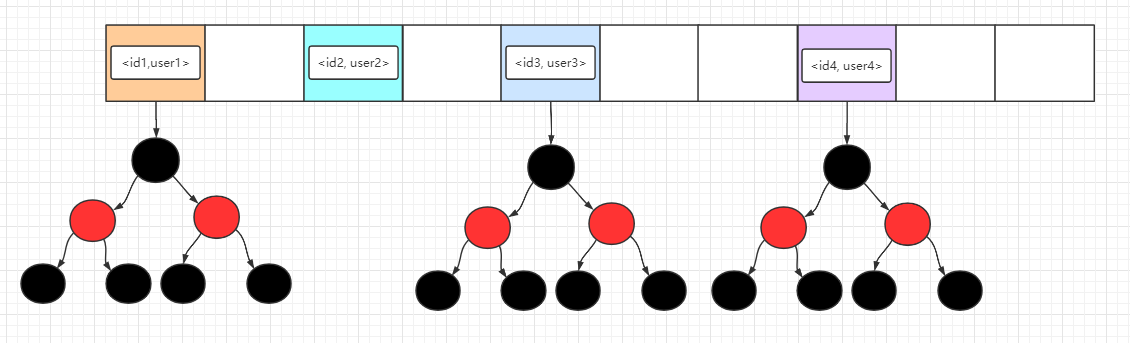
图中红黑树的每一个节点都是一个Entry,在这里为了图片的简洁性,就不标明 key 和 value 了,注意这些元素都是已经按照key排好序了,整个数据结构都是保持着有序 的状态!
关于自然排序与定制排序:
- 自然排序:要求
key必须实现Comparable接口。
由于Integer类实现了 Comparable 接口,按照自然排序规则是按照key从小到大排序。
TreeMap<Integer, String> treeMap = new TreeMap<>();
treeMap.put(2, "TWO");
treeMap.put(1, "ONE");
System.out.print(treeMap);
// {1=ONE, 2=TWO}
- 1
- 2
- 3
- 4
- 5
- 定制排序:在初始化 TreeMap 时传入新的
Comparator,不要求key实现 Comparable 接口
TreeMap<Integer, String> treeMap = new TreeMap<>((o1, o2) -> Integer.compare(o2, o1));
treeMap.put(1, "ONE");
treeMap.put(2, "TWO");
treeMap.put(4, "FOUR");
treeMap.put(3, "THREE");
System.out.println(treeMap);
// {4=FOUR, 3=THREE, 2=TWO, 1=ONE}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
通过传入新的Comparator比较器,可以覆盖默认的排序规则,上面的代码按照key降序排序,在实际应用中还可以按照其它规则自定义排序。
compare()方法的返回值有三种,分别是:0,-1,+1
(1)如果返回0,代表两个元素相等,不需要调换顺序
(2)如果返回+1,代表前面的元素需要与后面的元素调换位置
(3)如果返回-1,代表前面的元素不需要与后面的元素调换位置
而何时返回+1和-1,则由我们自己去定义,JDK默认是按照自然排序,而我们可以根据key的不同去定义降序还是升序排序。
关于 TreeMap 主要介绍了两点:
- 它底层是由
红黑树这种数据结构实现的,所以操作的时间复杂度恒为O(logN) - TreeMap 可以对
key进行自然排序或者自定义排序,自定义排序时需要传入Comparator,而自然排序要求key实现了Comparable接口 - TreeMap 不是线程安全的。
WeakHashMap
WeakHashMap 日常开发中比较少见,它是基于普通的Map实现的,而里面Entry中的键在每一次的垃圾回收都会被清除掉,所以非常适合用于短暂访问、仅访问一次的元素,缓存在WeakHashMap中,并尽早地把它回收掉。
当Entry被GC时,WeakHashMap 是如何感知到某个元素被回收的呢?
在 WeakHashMap 内部维护了一个引用队列queue
private final ReferenceQueue<Object> queue = new ReferenceQueue<>();
- 1
这个 queue 里包含了所有被GC掉的键,当JVM开启GC后,如果回收掉 WeakHashMap 中的 key,会将 key 放入queue 中,在expungeStaleEntries()中遍历 queue,把 queue 中的所有key拿出来,并在 WeakHashMap 中删除掉,以达到同步。
private void expungeStaleEntries() {
for (Object x; (x = queue.poll()) != null; ) {
synchronized (queue) {
// 去 WeakHashMap 中删除该键值对
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
再者,需要注意 WeakHashMap 底层存储的元素的数据结构是数组 + 链表,没有红黑树哦,可以换一个角度想,如果还有红黑树,那干脆直接继承 HashMap ,然后再扩展就完事了嘛,然而它并没有这样做:
public class WeakHashMap<K, V> extends AbstractMap<K, V> implements Map<K, V> {
}
- 1
- 2
- 3
所以,WeakHashMap 的数据结构图我也为你准备好啦。
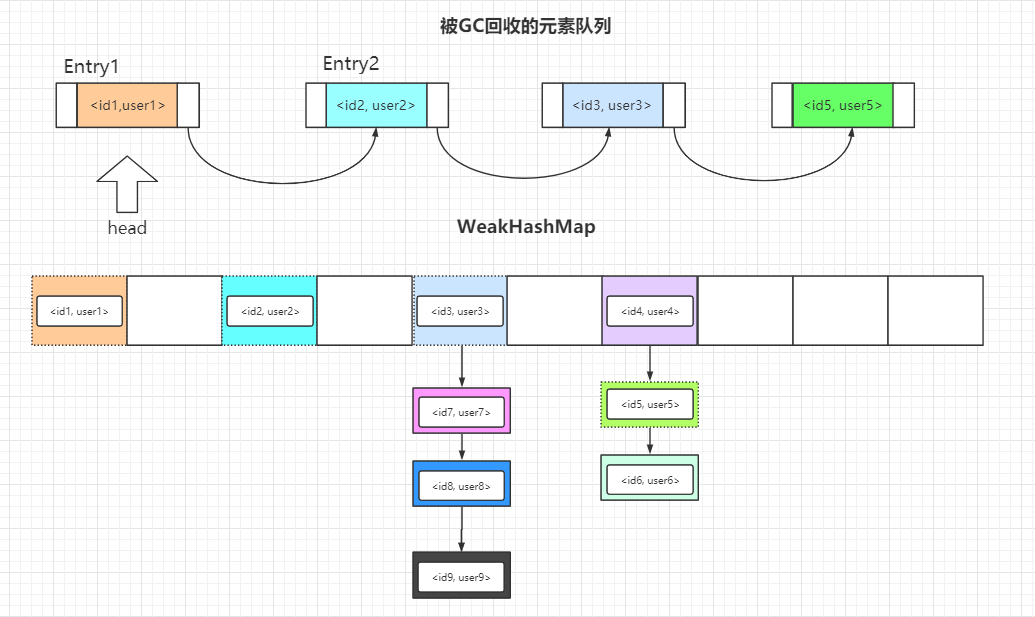
图中被虚线标识的元素将会在下一次访问 WeakHashMap 时被删除掉,WeakHashMap 内部会做好一系列的调整工作,所以记住队列的作用就是标志那些已经被GC回收掉的元素。
关于 WeakHashMap 需要注意两点:
- 它的键是一种弱键,放入 WeakHashMap 时,随时会被回收掉,所以不能确保某次访问元素一定存在
- 它依赖普通的
Map进行实现,是一个非线程安全的集合 - WeakHashMap 通常作为缓存使用,适合存储那些只需访问一次、或只需保存短暂时间的键值对
Hashtable
Hashtable 底层的存储结构是数组 + 链表,而它是一个线程安全的集合,但是因为这个线程安全,它就被淘汰掉了。
下面是Hashtable存储元素时的数据结构图,它只会存在数组+链表,当链表过长时,查询的效率过低,而且会长时间锁住 Hashtable。
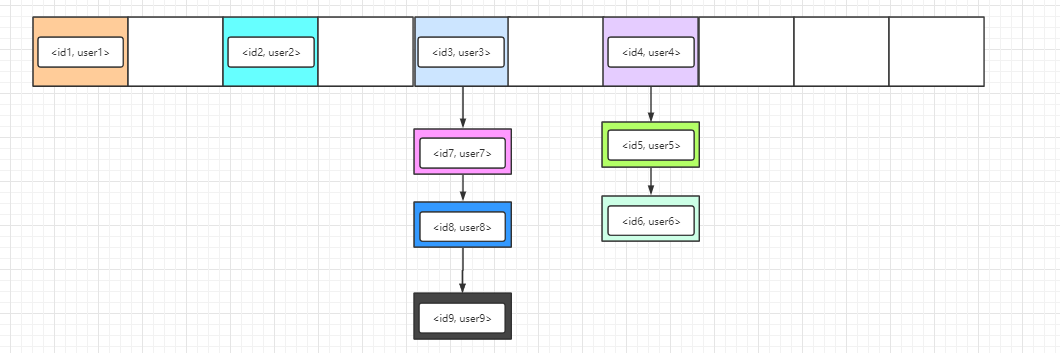
这幅图是否有点眼熟哈哈哈哈,本质上就是 WeakHashMap 的底层存储结构了。你千万别问为什么 WeakHashMap 不继承 Hashtable 哦,Hashtable 的
性能在并发环境下非常差,在非并发环境下可以用HashMap更优。
HashTable 本质上是 HashMap 的前辈,它被淘汰的原因也主要因为两个字:性能
HashTable 是一个 线程安全 的 Map,它所有的方法都被加上了 synchronized 关键字,也是因为这个关键字,它注定成为了时代的弃儿。
HashTable 底层采用 数组+链表 存储键值对,由于被弃用,后人也没有对它进行任何改进
HashTable 默认长度为 11,负载因子为 0.75F,即元素个数达到数组长度的 75% 时,会进行一次扩容,每次扩容为原来数组长度的 2 倍
HashTable 所有的操作都是线程安全的。
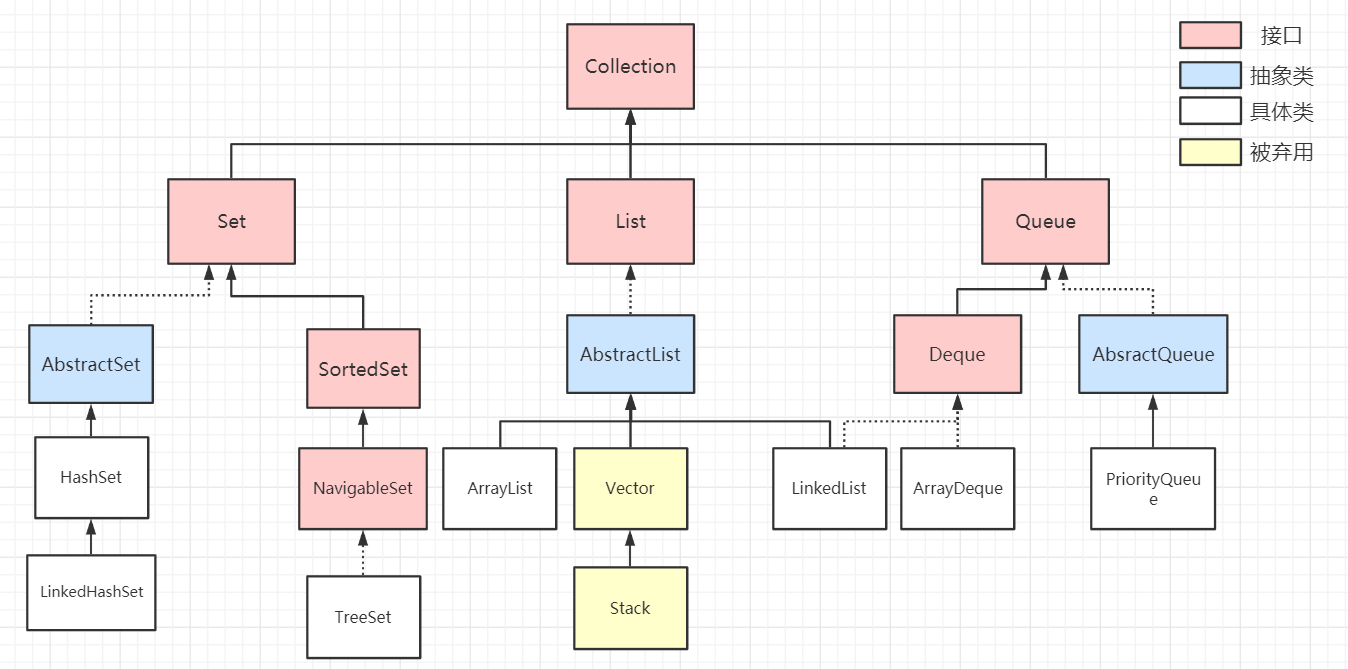
Collection 集合体系详解
Collection 集合体系的顶层接口就是Collection,它规定了该集合下的一系列行为约定。
该集合下可以分为三大类集合:List,Set和Queue
Set接口定义了该类集合不允许存储重复的元素,且任何操作时均需要通过哈希函数映射到集合内部定位元素,集合内部的元素默认是无序的。
List接口定义了该类集合允许存储重复的元素,且集合内部的元素按照元素插入的顺序有序排列,可以通过索引访问元素。
Queue接口定义了该类集合是以队列作为存储结构,所以集合内部的元素有序排列,仅可以操作头结点元素,无法访问队列中间的元素。
上面三个接口是最普通,最抽象的实现,而在各个集合接口内部,还会有更加具体的表现,衍生出各种不同的额外功能,使开发者能够对比各个集合的优势,择优使用。
Set 接口
Set接口继承了Collection接口,是一个不包括重复元素的集合,更确切地说,Set 中任意两个元素不会出现 o1.equals(o2),而且 Set 至多只能存储一个 NULL 值元素,Set 集合的组成部分可以用下面这张图概括:
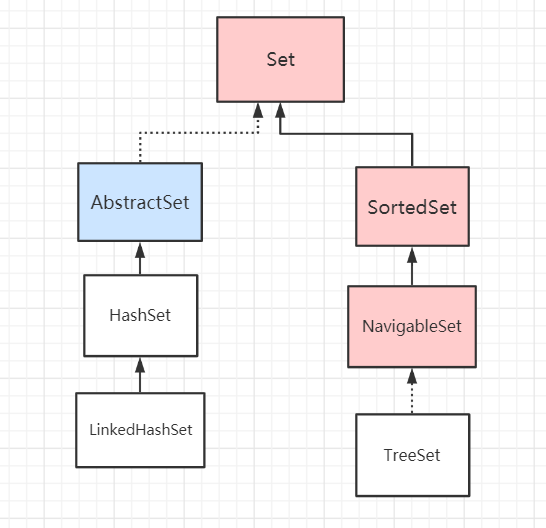
在 Set 集合体系中,我们需要着重关注两点:
-
存入可变元素时,必须非常小心,因为任意时候元素状态的改变都有可能使得 Set 内部出现两个相等的元素,即
o1.equals(o2) = true,所以一般不要更改存入 Set 中的元素,否则将会破坏了equals()的作用! -
Set 的最大作用就是判重,在项目中最大的作用也是判重!
接下来我们去看它的实现类和子类: AbstractSet 和 SortedSet
AbstractSet 抽象类
AbstractSet 是一个实现 Set 的一个抽象类,定义在这里可以将所有具体 Set 集合的相同行为在这里实现,避免子类包含大量的重复代码
所有的 Set 也应该要有相同的 hashCode() 和 equals() 方法,所以使用抽象类把该方法重写后,子类无需关心这两个方法。
public abstract class AbstractSet<E> implements Set<E> { // 判断两个 set 是否相等 public boolean equals(Object o) { if (o == this) { // 集合本身 return true; } else if (!(o instanceof Set)) { // 集合不是 set return false; } else { // 比较两个集合的元素是否全部相同 } } // 计算所有元素的 hashcode 总和 public int hashCode() { int h = 0; Iterator i = this.iterator(); while(i.hasNext()) { E obj = i.next(); if (obj != null) { h += obj.hashCode(); } } return h; } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
SortedSet 接口
SortedSet 是一个接口,它在 Set 的基础上扩展了排序的行为,所以所有实现它的子类都会拥有排序功能。
public interface SortedSet<E> extends Set<E> {
// 元素的比较器,决定元素的排列顺序
Comparator<? super E> comparator();
// 获取 [var1, var2] 之间的 set
SortedSet<E> subSet(E var1, E var2);
// 获取以 var1 开头的 Set
SortedSet<E> headSet(E var1);
// 获取以 var1 结尾的 Set
SortedSet<E> tailSet(E var1);
// 获取首个元素
E first();
// 获取最后一个元素
E last();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
HashSet
HashSet 底层借助 HashMap 实现,我们可以观察它的多个构造方法,本质上都是 new 一个 HashMap
这也是这篇文章为什么先讲解 Map 再讲解 Set 的原因!先学习 Map,有助于理解 Set
public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, Serializable {
public HashSet() {
this.map = new HashMap();
}
public HashSet(int initialCapacity, float loadFactor) {
this.map = new HashMap(initialCapacity, loadFactor);
}
public HashSet(int initialCapacity) {
this.map = new HashMap(initialCapacity);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
我们可以观察 add() 方法和remove()方法是如何将 HashSet 的操作嫁接到 HashMap 的。
private static final Object PRESENT = new Object();
public boolean add(E e) {
return this.map.put(e, PRESENT) == null;
}
public boolean remove(Object o) {
return this.map.remove(o) == PRESENT;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
我们看到 PRESENT 就是一个静态常量:使用 PRESENT 作为 HashMap 的 value 值,使用HashSet的开发者只需关注于需要插入的 key,屏蔽了 HashMap 的 value
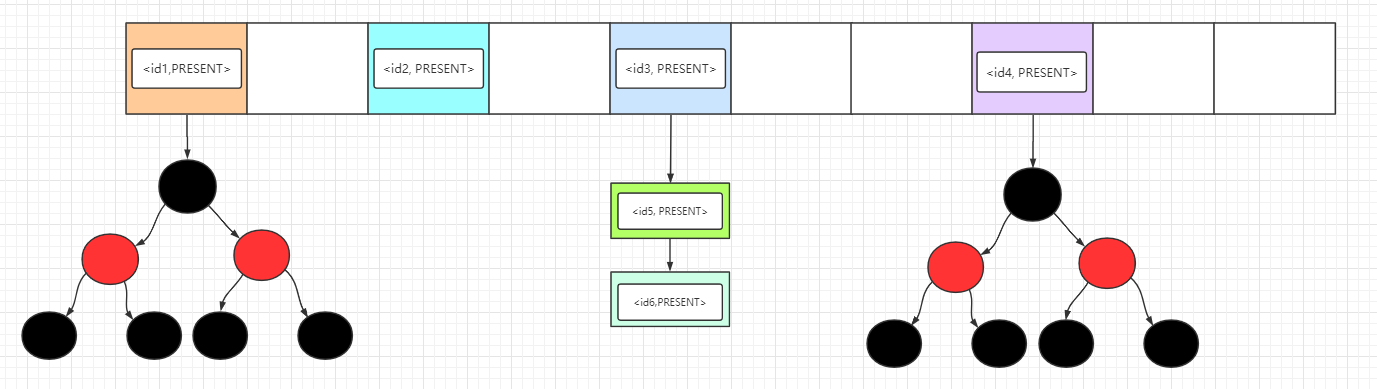
上图可以观察到每个Entry的value都是 PRESENT 空对象,我们就不用再理会它了。
HashSet 在 HashMap 基础上实现,所以很多地方可以联系到 HashMap:
- 底层数据结构:HashSet 也是采用
数组 + 链表 + 红黑树实现 - 线程安全性:由于采用 HashMap 实现,而 HashMap 本身线程不安全,在HashSet 中没有添加额外的同步策略,所以 HashSet 也线程不安全
- 存入 HashSet 的对象的状态最好不要发生变化,因为有可能改变状态后,在集合内部出现两个元素
o1.equals(o2),破坏了equals()的语义。
LinkedHashSet
LinkedHashSet 的代码少的可怜,不信我给你我粘出来
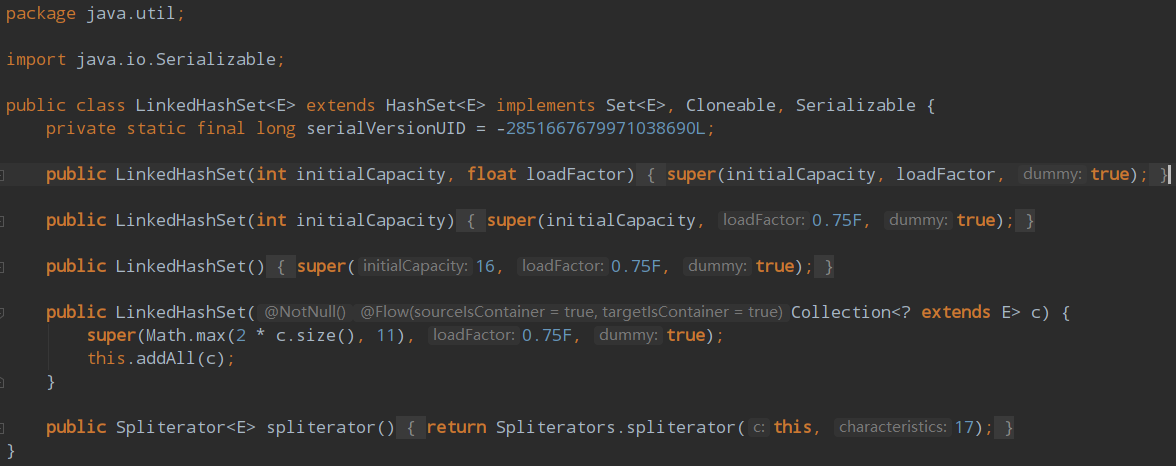
少归少,还是不能闹,LinkedHashSet继承了HashSet,我们跟随到父类 HashSet 的构造方法看看
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
this.map = new LinkedHashMap(initialCapacity, loadFactor);
}
- 1
- 2
- 3
发现父类中 map 的实现采用LinkedHashMap,这里注意不是HashMap,而 LinkedHashMap 底层又采用 HashMap + 双向链表 实现的,所以本质上 LinkedHashSet 还是使用 HashMap 实现的。
LinkedHashSet -> LinkedHashMap -> HashMap + 双向链表
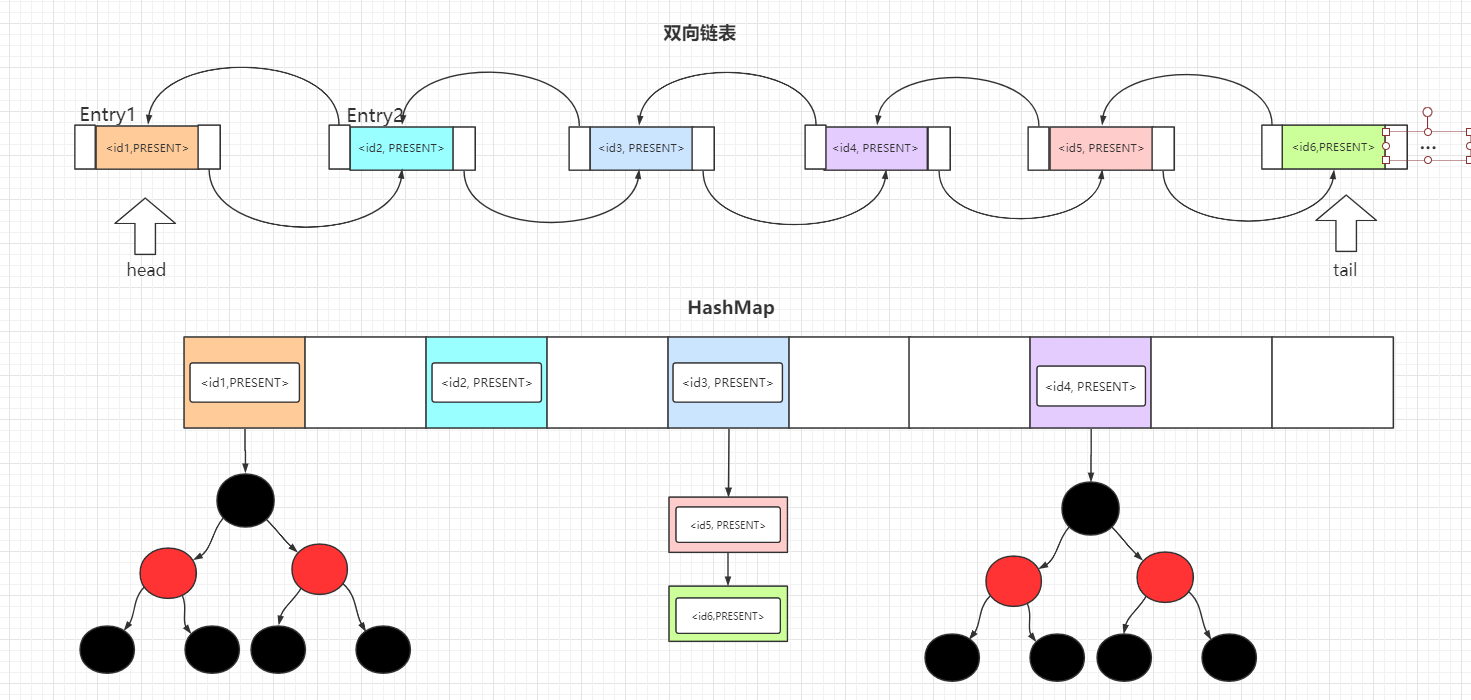
而 LinkedHashMap 是采用 HashMap和双向链表实现的,这条双向链表中保存了元素的插入顺序。所以 LinkedHashSet 可以按照元素的插入顺序遍历元素,如果你熟悉LinkedHashMap,那 LinkedHashSet 也就更不在话下了。
关于 LinkedHashSet 需要注意几个地方:
- 它继承了
HashSet,而 HashSet 默认是采用 HashMap 存储数据的,但是 LinkedHashSet 调用父类构造方法初始化 map 时是 LinkedHashMap 而不是 HashMap,这个要额外注意一下 - 由于 LinkedHashMap 不是线程安全的,且在 LinkedHashSet 中没有添加额外的同步策略,所以 LinkedHashSet 集合也不是线程安全的
TreeSet
TreeSet 是基于 TreeMap 的实现,所以存储的元素是有序的,底层的数据结构是数组 + 红黑树。
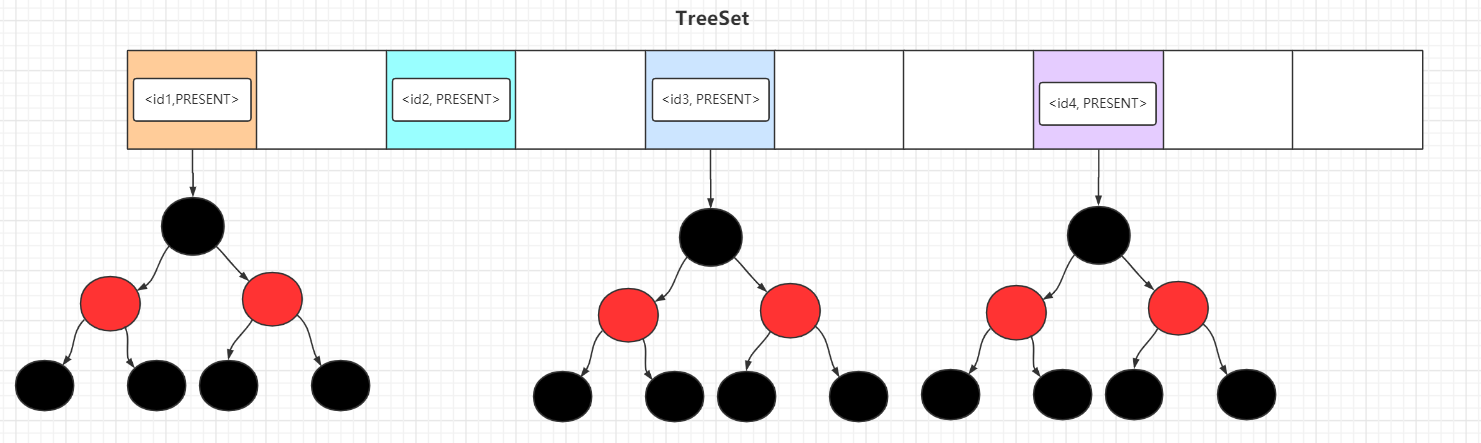
而元素的排列顺序有2种,和 TreeMap 相同:自然排序和定制排序,常用的构造方法已经在下面展示出来了,TreeSet 默认按照自然排序,如果需要定制排序,需要传入Comparator。
public TreeSet() {
this(new TreeMap<E,Object>());
}
public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<>(comparator));
}
- 1
- 2
- 3
- 4
- 5
- 6
TreeSet 应用场景有很多,像在游戏里的玩家战斗力排行榜
public class Player implements Comparable<Integer> { public String name; public int score; @Override public int compareTo(Student o) { return Integer.compareTo(this.score, o.score); } } public static void main(String[] args) { Player s1 = new Player("张三", 100); Player s2 = new Player("李四", 90); Player s3 = new Player("王五", 80); TreeSet<Player> set = new TreeSet(); set.add(s2); set.add(s1); set.add(s3); System.out.println(set); } // [Student{name='王五', score=80}, Student{name='李四', score=90}, Student{name='张三', score=100}]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
对 TreeSet 介绍了它的主要实现方式和应用场景,有几个值得注意的点。
- TreeSet 的所有操作都会转换为对 TreeMap 的操作,TreeMap 采用红黑树实现,任意操作的平均时间复杂度为
O(logN) - TreeSet 是一个线程不安全的集合
- TreeSet 常应用于对不重复的元素定制排序,例如玩家战力排行榜
注意:TreeSet判断元素是否重复的方法是判断compareTo()方法是否返回0,而不是调用 hashcode() 和 equals() 方法,如果返回 0 则认为集合内已经存在相同的元素,不会再加入到集合当中。
List 接口
List 接口和 Set 接口齐头并进,是我们日常开发中接触的很多的一种集合类型了。整个 List 集合的组成部分如下图
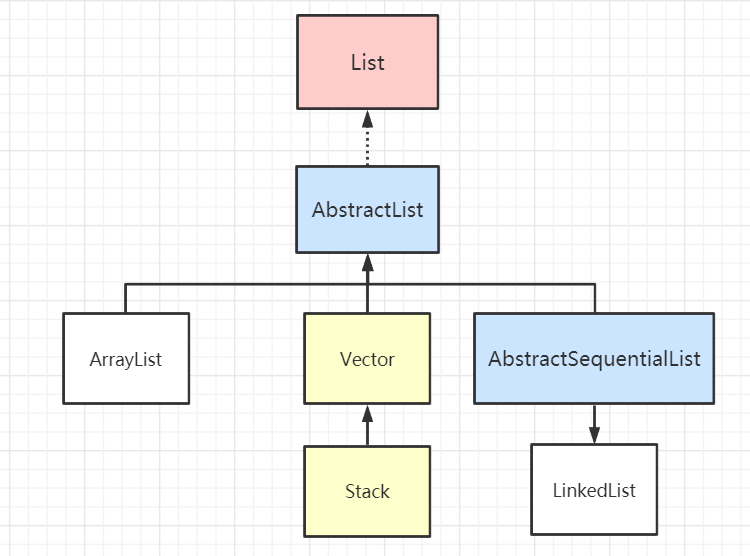
List 接口直接继承 Collection 接口,它定义为可以存储重复元素的集合,并且元素按照插入顺序有序排列,且可以通过索引访问指定位置的元素。常见的实现有:ArrayList、LinkedList、Vector和Stack
AbstractList 和 AbstractSequentialList
AbstractList 抽象类实现了 List 接口,其内部实现了所有的 List 都需具备的功能,子类可以专注于实现自己具体的操作逻辑。
// 查找元素 o 第一次出现的索引位置
public int indexOf(Object o)
// 查找元素 o 最后一次出现的索引位置
public int lastIndexOf(Object o)
//···
- 1
- 2
- 3
- 4
- 5
AbstractSequentialList 抽象类继承了 AbstractList,在原基础上限制了访问元素的顺序只能够按照顺序访问,而不支持随机访问,如果需要满足随机访问的特性,则继承 AbstractList。子类 LinkedList 使用链表实现,所以仅能支持顺序访问,顾继承了 AbstractSequentialList而不是 AbstractList。
Vector
Vector 在现在已经是一种过时的集合了,包括继承它的 Stack 集合也如此,它们被淘汰的原因都是因为性能低下。
JDK 1.0 时代,ArrayList 还没诞生,大家都是使用 Vector 集合,但由于 Vector 的每个操作都被 synchronized 关键字修饰,即使在线程安全的情况下,仍然进行无意义的加锁与释放锁,造成额外的性能开销,做了无用功。
public synchronized boolean add(E e);
public synchronized E get(int index);
- 1
- 2
在 JDK 1.2 时,Collection 家族出现了,它提供了大量高性能、适用於不同场合的集合,而 Vector 也是其中一员,但由于 Vector 在每个方法上都加了锁,由于需要兼容许多老的项目,很难在此基础上优化Vector了,所以渐渐地也就被历史淘汰了。
现在,在线程安全的情况下,不需要选用 Vector 集合,取而代之的是 ArrayList 集合;在并发环境下,出现了 CopyOnWriteArrayList,Vector 完全被弃用了。
Stack
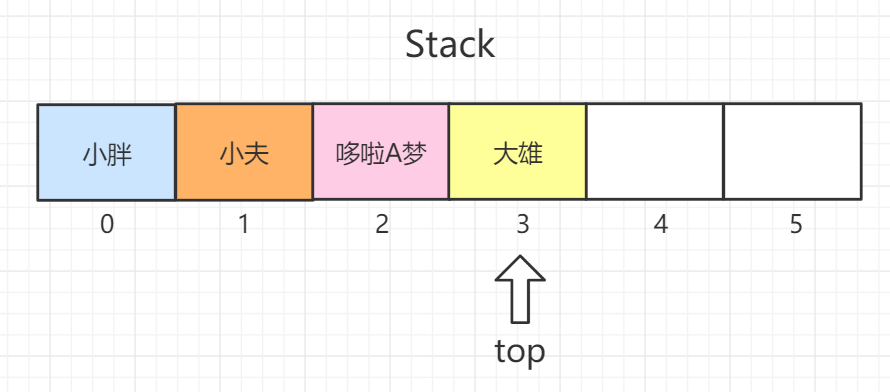
Stack是一种后入先出(LIFO)型的集合容器,如图中所示,大雄是最后一个进入容器的,top指针指向大雄,那么弹出元素时,大雄也是第一个被弹出去的。
Stack 继承了 Vector 类,提供了栈顶的压入元素操作(push)和弹出元素操作(pop),以及查看栈顶元素的方法(peek)等等,但由于继承了 Vector,正所谓跟错老大没福报,Stack 也渐渐被淘汰了。
取而代之的是后起之秀 Deque接口,其实现有 ArrayDeque,该数据结构更加完善、可靠性更好,依靠队列也可以实现LIFO的栈操作,所以优先选择 ArrayDeque 实现栈。
Deque<Integer> stack = new ArrayDeque<Integer>();
- 1
ArrayDeque 的数据结构是:数组,并提供头尾指针下标对数组元素进行操作。本文也会讲到哦,客官请继续往下看,莫着急!
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

