
- 1方法的继承,重写和重载_子类继承父类方法重载
- 2OpenAI API-KEY 余额如何查询?如何在线购买卡密自助发货网址?_openai账户余额
- 3Nginx实际问题解决——如何指定地址访问指定页面_nginx跳转到指定html页面
- 4关于近端梯度下降法你不知道的事_加速近端梯度法
- 5SpringBoot-07-集成mybatis-plus_mybatis-plus springboot 2.7
- 6Python使用defaultdict设置自己的默认值_defaultdict如何设置默认值
- 7Ubuntu 24.04 代号敲定为“Noble Numbat”
- 8ubuntu环境下安装Hive_ubtuntu上安装hive
- 92023华为od机试【矩阵元素的边界值】Java_给定一个n*m矩阵,请先找出m个该矩阵中每列元素的最大值,然后输出这m个值中的最小
- 10ThingsBoard开源物联网平台介绍_thingsbord
每日一题——力扣206. 反转链表(举一反三、思想解读)
赞
踩

一个认为一切根源都是“自己不够强”的INTJ
![]() 个人主页:用哲学编程-CSDN博客
个人主页:用哲学编程-CSDN博客![]() 专栏:每日一题——举一反三
专栏:每日一题——举一反三
题目链接
目录
菜鸡写法
- // 定义了一个用于反转单链表的函数。接受一个指向链表头节点的指针。
- struct ListNode* reverseList(struct ListNode* head) {
- // 如果链表为空或只有一个节点,直接返回头指针,因为无需反转。
- if(head==NULL||head->next==NULL)
- return head;
-
-
- // 定义三个指针用于遍历链表和反转操作。
- struct ListNode* tmp1=NULL;
- struct ListNode* tmp2=NULL;
- struct ListNode* newHead;
-
-
- // 查找链表的尾节点,将其作为新的头节点(但这个过程实际上并不改变链表结构)。
- for(newHead=head;newHead->next!=NULL;newHead=newHead->next) {
- // 空循环体,仅用于遍历到链表末尾。
- }
-
-
- // 开始反转链表的过程。
- for(tmp1=head,tmp2=newHead;tmp2->next!=head;) {
- // 查找倒数第二个节点。
- for(tmp1=head;tmp1->next->next!=NULL;tmp1=tmp1->next) {
- // 空循环体,仅用于遍历。
- }
-
-
- // 再次遍历到链表末尾的节点,这一步似乎是多余的,因为tmp2已经是最后一个节点。
- for(tmp2=newHead;tmp2->next!=NULL;tmp2=tmp2->next) {
- // 空循环体。
- }
-
-
- // 将倒数第二个节点连接到最后一个节点。
- tmp2->next = tmp1;
- // 并将倒数第二个节点的next设置为NULL,断开与前一个节点的连接。
- tmp1->next = NULL;
- }
- // 返回新的头节点,即原链表的尾节点。
- return newHead;
- }
-

代码点评
这段代码的目标是反转一个单链表。然而,它采用了一种非常不典型且低效的方法来实现这一目标。让我们从几个方面来进行分析。
代码分析
首先,代码的基本逻辑是试图通过找到链表的最后一个节点来开始反转过程,然后逐步将每个节点移动到这个位置。这种方法虽然在逻辑上可行,但远非最优解。
时间复杂度
时间复杂度是衡量算法运行时间长短的一个指标。对于这段代码,我们注意到它包含多层嵌套循环。最外层循环的目的是为了重复反转操作,而内层的两个循环则是寻找链表的倒数第二个节点(tmp1)和最后一个节点(tmp2)。这种多层嵌套循环的使用导致了非常高的时间复杂度。
- 对于一个包含 n 个节点的链表,最外层循环需要执行 n 次,因为每次循环只能将一个节点移动到正确的位置。
- 内层循环每次都会遍历整个链表来查找倒数第二个节点,因此,它们的时间复杂度也是 O(n)。
因此,总的时间复杂度为 O(n^2),这是因为对于每个节点,算法都需要遍历整个链表来找到它应该在反转后的位置。这种方法显然不是反转链表的最佳方案。
空间复杂度
空间复杂度衡量的是算法在执行过程中需要的额外空间。这段代码的空间复杂度相对较低,为 O(1)。这是因为无论链表的大小如何,它只需要维护几个额外的指针(tmp1、tmp2 和 newHead),这些指针的数量不随链表大小变化而变化。
专业点评
从专业角度来看,这段代码虽然能够实现链表反转的功能,但其方法过于复杂且效率低下。在实际应用中,我们通常采用更高效且更直观的算法,例如迭代法或递归法,这些方法的时间复杂度为 O(n),空间复杂度为 O(1)(迭代法)或 O(n)(递归法,因为递归调用栈的使用)。
迭代法通过遍历链表一次,逐个调整节点的指向,就可以完成链表的反转,而无需如此复杂的多次遍历和无效操作。因此,尽管这段代码在逻辑上是正确的,它并不是解决问题的最佳方案。在编写代码时,寻找更高效的算法总是非常重要的,这不仅可以提升代码的运行速度,还可以提高代码的可读性和可维护性。
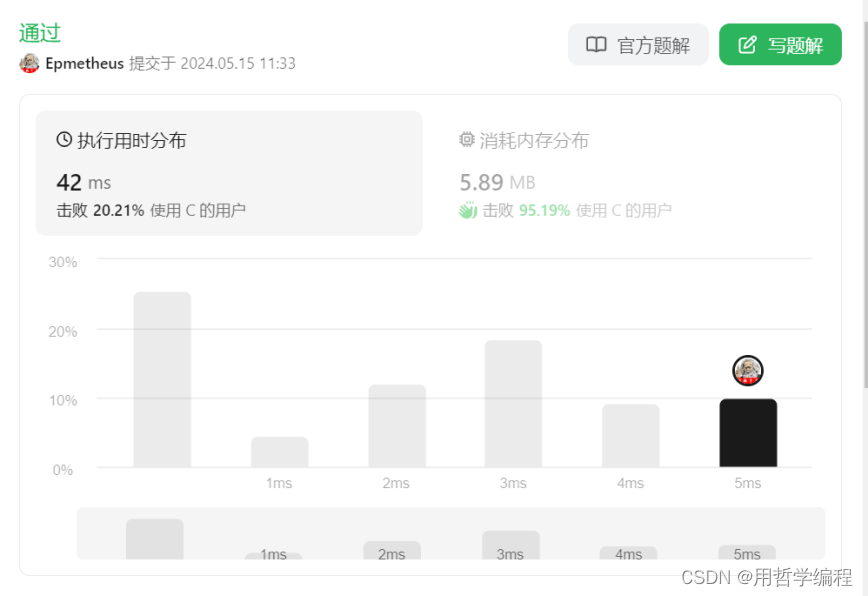
另一种方法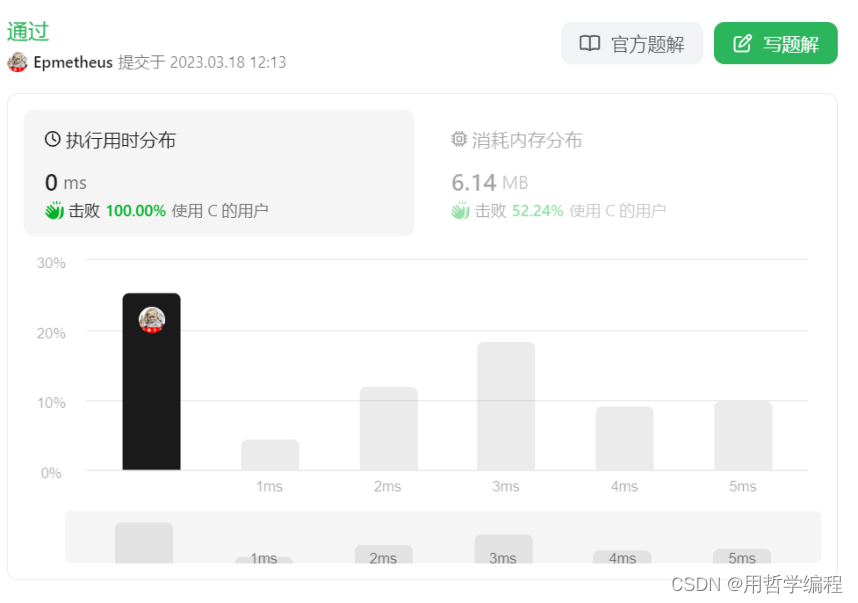
- /**
- * Definition for singly-linked list.
- * struct ListNode {
- * int val;
- * struct ListNode *next;
- * };
- */
-
-
- struct ListNode* reverseList(struct ListNode* head){
- int arr[5001]={0},i;
- struct ListNode* cur=head;
- for(i=0;cur;cur=cur->next,i++)
- {
- arr[i]=cur->val;
- }
- i--;
- for(cur=head;cur;cur=cur->next,i--)
- {
- cur->val=arr[i];
- }
- return head;
- }
代码点评
这段代码提供了一种通过使用数组作为中介来反转单链表的方法。整体上,这种方法虽然相对直观,但并不是最优解。下面是对这段代码的专业点评,包括时间复杂度和空间复杂度的分析。
代码逻辑
- **遍历链表并存储值:**初始遍历链表,将每个节点的值存储到一个固定大小的数组arr中。数组大小被设定为5001,这意味着代码假设链表的最大长度不会超过5000个节点。
- **反向赋值:**第二次遍历链表时,按反向顺序从数组arr中读取值,并重新赋值给各个链表节点。
时间复杂度
- 第一次遍历链表有一个时间复杂度为O(n),其中n是链表中的节点数量,因为它需要遍历整个链表一次。
- 第二次遍历同样有一个时间复杂度为O(n),因为它再次遍历整个链表来重新赋值。
- 因此,总体时间复杂度为O(n) + O(n) = O(2n),简化后为O(n)。
空间复杂度
- 数组arr的空间复杂度为O(m),其中m是数组的固定大小,这里是5001。尽管这个空间用于存储链表的值,但由于其大小固定,我们可以认为这里的空间复杂度是O(1),意味着与链表的长度无关。
- 没有使用递归调用或动态分配额外的数据结构,所以除了数组arr以外,没有使用额外的空间。
专业点评
- 假定限制:使用固定大小的数组(5001个元素)来存储链表的值是这段代码的一个主要限制。这意味着它只能正确处理最多5000个节点的链表。对于更大的链表,这段代码将无法工作。
- 效率和优化:虽然这种方法的时间复杂度为O(n),与一些更直接的链表反转方法相同,但它通过增加一个额外的数组来存储链表的值,这增加了额外的空间复杂度。更优的链表反转方法(例如迭代或递归反转)可以直接在链表上操作,而无需额外的存储空间。
- 实用性:这段代码在实际应用中的实用性受到限制,因为它假设了链表的最大长度。在处理未知长度的链表时,更灵活的方法是直接操作链表的指针。
总的来说,这段代码为链表反转问题提供了一个有趣的解决方案,但它不是最优的。对于实际应用,推荐使用直接在链表上操作的方法,这样可以避免固定长度数组带来的限制,并且减少空间复杂度。
我要更强
- struct ListNode* reverseList(struct ListNode* head) {
- struct ListNode* prev = NULL;
- struct ListNode* curr = head;
- while (curr) {
- struct ListNode* next = curr->next;
- curr->next = prev;
- prev = curr;
- curr = next;
- }
- return prev;
- }
代码点评
这段代码是一个用来反转单链表的经典迭代方法。它通过重新指定节点间的链接关系来实现链表的反向,不需要额外的数组或数据结构来存储链表的节点值。下面是对这段代码的专业点评,包括时间复杂度和空间复杂度的分析。
代码逻辑
- **初始化指针:**使用三个指针prev、current和next来跟踪链表的节点。prev初始化为NULL,因为反转后的链表的第一个节点将指向NULL。
- **遍历链表:**遍历整个链表,对于每个节点,暂时保存它的下一个节点(next),然后将它的next指针指向prev节点,从而实现反转。之后,prev和current都向前移动一个节点。
- **更新头指针:**遍历完成后,prev将指向原链表的最后一个节点,这时候它成了反转后的链表的头节点。更新head指针指向prev。
时间复杂度
时间复杂度是O(n),其中n是链表中的节点数。这是因为代码需要遍历链表一次,每个节点仅被访问一次。
空间复杂度
空间复杂度是O(1),因为反转过程中仅使用了有限的几个指针变量(prev、current和next),并且这个额外空间的需求不随输入链表的大小变化而变化。
点评
这种迭代方法是反转单链表的一种非常高效且空间节省的方法。与使用数组或其他数据结构存储节点值相比,这种直接操作链表指针的方法不仅节省了空间,而且简化了逻辑,提高了效率。由于它的时间复杂度是线性的,且空间复杂度是常数级别的,这使得它在实际应用中非常受欢迎,尤其是在空间资源受限的环境中。
此外,这种方法的优点还包括其简洁性和直观性,使得它容易理解和实现。不依赖于链表的大小或是其他外部数据结构,使得它在多种编程语境中都非常适用。因此,这是一种在实际编程工作中推荐使用的链表反转技术。
这种方法用到哪些哲学和编程思想
反转链表的迭代方法体现了几个重要的哲学和编程思想:
1. 迭代思想
迭代是一种通过重复执行一系列步骤直到满足某个条件来解决问题的方法。在这个链表反转的例子中,迭代思想体现在使用一个循环(while循环)来遍历链表,直到所有节点都被处理完毕。
2. 逐步构建
这种方法通过逐步改变链表节点的next指针来构建反转后的链表。这种逐步构建的思想是编程中解决复杂问题的一种常见策略,它将一个复杂的问题分解成一系列简单的步骤,每一步都依赖于前一步的结果。
3. 指针操作
链表反转方法的核心在于对指针的精确操作。指针是编程中用来直接访问和操作内存中数据的重要工具。在这个例子中,通过改变节点的next指针,实现了链表结构的改变。
4. 空间效率
这种方法的空间复杂度是O(1),意味着它只使用了常数级别的额外空间。这与许多算法和数据结构中追求空间效率的哲学相一致,特别是在资源受限的环境中,如嵌入式系统或高性能计算。
5. 不变性和可变性
在编程中,不变性指的是对象在创建后其状态不能被改变,而可变性则允许对象的状态在创建后被改变。在这个链表反转的例子中,我们利用了链表的可变性,通过改变节点的next指针来反转链表。
6. 递归与迭代的对比
虽然这个例子使用的是迭代方法,但反转链表也可以使用递归方法来实现。递归和迭代是解决问题的两种不同方法,它们各自有优缺点。在这个例子中,迭代方法避免了递归可能带来的栈溢出风险,同时也减少了额外的空间使用。
7. 抽象和具体化
链表反转的迭代方法体现了从抽象到具体化的过程。首先,我们有一个抽象的问题:反转链表。然后,我们通过具体的代码实现来解决这个问题。这种从抽象到具体的过程是编程中的一个核心思想,它帮助我们将复杂的问题分解成可管理的代码块。
总的来说,链表反转的迭代方法是一个很好的例子,展示了如何将编程思想和哲学应用于解决实际问题。它强调了迭代、逐步构建、指针操作、空间效率、不变性与可变性、递归与迭代的对比,以及抽象和具体化的重要性。
举一反三
基于单链表反转的迭代方法,以下是一些编程技巧和原则,你可以举一反三地应用到其他编程任务中:
1. 理解数据结构的性质
在反转链表之前,了解链表的性质是至关重要的。同样地,在处理任何数据结构时,首先要深入理解它的性质和运作方式。例如,数组支持随机访问,而链表支持高效的元素插入和删除。这种理解会帮助你选择正确的算法和编程策略。
2. 分步骤解决问题
反转链表的过程是一步一步完成的,每次迭代只处理一个节点。类似地,面对复杂问题时,将其拆分成一系列小任务,并逐个解决。这样可以简化问题,并保持代码的清晰和可管理性。
3. 空间复杂度意识
使用有限的几个指针变量就完成了链表的反转,这展示了在可能的情况下应该优化空间使用的重要性。在其他算法设计中,同样要考虑如何使用最小的额外空间,特别是对于大数据量或内存限制的应用场景。
4. 循环和迭代
迭代是解决问题的核心工具,不仅适用于链表操作,也适用于数组处理、树遍历等。熟练使用for和while循环可以帮助你编写出处理各种数据结构的有效算法。
5. 修改现有结构 vs 新建结构
在链表反转案例中,我们通过修改现有的链表结构来实现目标,而没有新建一个链表。当需要优化性能时,考虑直接修改现有结构而不是创建新的数据结构可以节省空间和时间。
6. 不变量的使用
在反转链表的过程中,我们维护了节点之间的连接关系,即使是在修改指针时。在其他问题中,识别和保持不变量可以帮助你在变化的过程中保持数据完整性和一致性。
7. 对可变性的控制
在修改数据时,要小心对数据结构中的元素进行操作,确保不会不小心破坏结构。在编程中,正确管理可变状态和不变状态对于预防错误和保证程序的可靠性至关重要。
8. 边界案例和错误处理
当你反转链表时,需要考虑空链表或只有一个节点的链表等边界情况。同样地,在设计算法和编写代码时,总是要考虑和处理边界情况和可能的错误,确保代码的健壮性。
将这些技巧和原则应用到其他编程任务中,可以帮助你更有效地解决问题,写出更清晰、更高效、更健壮的代码。
以上是本节全部内容,感谢阅读!!!


