
- 1景联文科技:用高质量数据采集标注赋能无人机技术,引领无人机迈入新纪元!
- 2AI赋能分层模式,解构未来,智领风潮
- 3huggingface-cli: command not found
- 4git基本操作命令整理。
- 5KAN网络技术最全解析—最热KAN能否干掉MLP和Transformer?(收录于GPT-4/ChatGPT技术与产业分析)
- 6实习记录小程序|基于SSM的实习记录小程序设计与实现(源码+数据库+文档)_实习日记生成器小程序
- 7spark 连接 mysql 出现 No suitable driver_no suitable driver spark
- 8MybatisPlus报错Error querying database. Cause: java.lang.IndexOutOfBoundsException: Index: 3, Size: 3_mybatisplus报错indexoutofbounds
- 9【通过EM算法实现GMM学习的3D可视化】三维数据的高斯混合模型的 3D 可视化研究(Matlab代码实现)_三维 高斯分布
- 10测绘院、国土局如何提升GIS系统数据的安全性?
hadoop -- Yarn资源管理_yarn资源管理器
赞
踩
Yarn
YARN被设计用以解决以往架构的需求和缺陷的资源管理和调度软件。
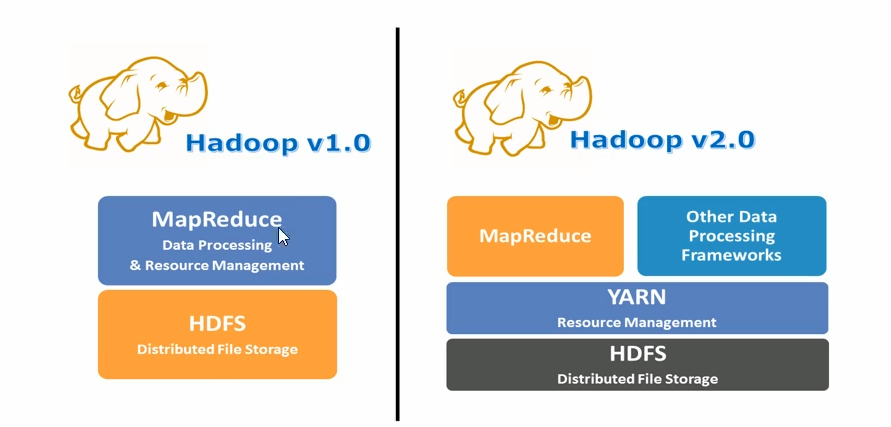
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统和调度平台,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
资源管理系统:集群的硬件资源,和程序运行相关,比如内存,CPU等
调度平台:多个程序同时申请计算资源如何分配,调度的规则(算法)。
通用∶不仅仅支持MapReduce程序,理论上支持各种计算程序。YARN不关心你干什么,只关心你要资源,在有的情况下给你,用完之后还我。
可以把Hadoop YARN理解为相当于一个分布式的操作系统平台,而MapReduce等计算程序则相当于运行于操作系统之上的应用程序,YARN为这些程序提供运算所需的资源(内存、CPU等)。
Yarn架构体系
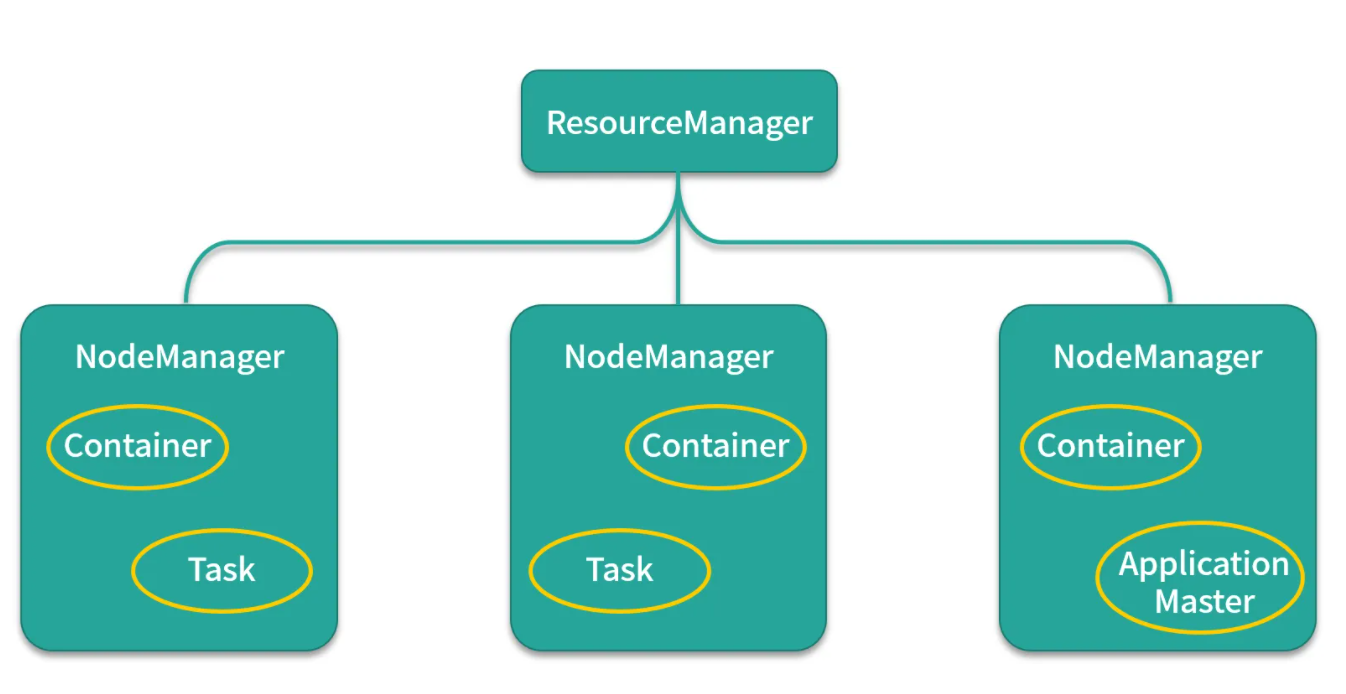
主从架构
也是采用 master(Resource Manager)- slave (Node Manager)架构,Resource Manager 整个集群只有一个,一个可靠的节点。
1、 每个节点上可以负责该节点上的资源管理以及任务调度,Node Manager 会定时向Resource Manager汇报本节点上 的资源使用情况和任务运行状态,
2、 Resource Manager会通过心跳应答的机制向Node Manager下达命令或者分发新的任务,
3、 Yarn 将某一资源分配给该应用程序后,应用程序会启动一个Application Master,
4、 Application Master为应用程序负责向Resource Manager申请资源,申请资源之后,再和申请到的节点进行通信,运行内部任务。
Resource Manager
RM是一个全局的资源管理器,负责整个系统的资源管理和分配。它主要由两个组件构成:调度器(Scheduler)和应用程序管理器(Applications Manager,ASM)。
Schedule 资源调度器是一个可插拔的组件,用户可根据自己需要设计资新的源调度器,YARN提供多个可直接使用的资源调度器。资源调度器将系统中的资源分配给正在运行的程序,不负责监控或跟踪应用的执行状态,不负责重启失败的任务。
Applications Manager 应用程序管理器负责管理整个系统中所有应用程序,包括应用程序提交、与调度器协商资源以启动ApplicationMaster、监控ApplicationMaster运行状态并在失败时重新启动它等。
Node Manager
NM是每个节点上的资源和任务管理器,一方面,它会定时地向RM汇报本节点上的资源使用情况和各个Container的运行状态;另一方面,它接收并处理来自AM的Container启动/停止等各种请求。
ApplicationMaster
用户提交的每个应用程序均包含一个AM,主要功能包括:
1.与RM调度器协商以获取资源(用Container表示);
2.将得到的任务进一步分配给内部的任务
3.与NM通信以启动/停止任务;
4.监控所有任务运行状态,并在任务运行失败时重新为任务申请资源以重启任务。
注:RM只负责监控AM,在AM运行失败时候启动它,RM并不负责AM内部任务的容错,这由AM来完成。
Container
Container是YARN中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等,当AM向RM申请资源时,RM为AM返回的资源便是用Container表示。YARN会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源。yarn的container容器是yarn虚拟出来的一个东西,属于虚拟化的,它是由memory+vcore组成,是专门用来运行任务的
安装
etc/hadoop/目录下 yarn-site.xml文件
- cd /opt/apps/hadoop-3.1.1/etc/hadoop/
- vi yarn-site.xml
-
- <!-- resource,manager主节点所在机器 -->
- <property>
- <name>yarn.resourcemanager.hostname</name>
- <value>linux01</value>
- </property>
-
- <!-- 为mr程序提供shuffle服务 -->
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
-
- <!-- 一台NodeManager的总可用内存资源 -->
- <property>
- <name>yarn.nodemanager.resource.memory-mb</name>
- <value>4096</value>
- </property>
- <!-- 一台NodeManager的总可用(逻辑)cpu核数 -->
- <property>
- <name>yarn.nodemanager.resource.cpu-vcores</name>
- <value>4</value>
- </property>
-
- <!-- 是否检查容器的虚拟内存使用超标情况
- vmem为true 指的是默认检查虚拟内存,容器使用的虚拟内存不能超过我们设置的虚拟内存大小
- -->
- <property>
- <name>yarn.nodemanager.vmem-check-enabled</name>
- <value>false</value>
- </property>
-
- <!-- 容器的虚拟内存使用上限:与物理内存的比率 -->
- <property>
- <name>yarn.nodemanager.vmem-pmem-ratio</name>
- <value>2.1</value>
- </property>
-
-
- 将 yarn-site.xml 同步给其他Linux
- scp yarn-site.xml linux02:$PWD
- scp yarn-site.xml linux03:$PWD

配置一键启停
- cd /opt/apps/hadoop-3.1.1/sbin
- vi start-yarn.sh
- vi stop-yarn.sh
-
- YARN_RESOURCEMANAGER_USER=root
- HADOOP_SECURE_DN_USER=yarn
- YARN_NODEMANAGER_USER=root
-
- start-yarn.sh 一键启动
-
- 启动后可以访问 http://linux01:8088 查看页面
-
-
- 解决linux连接不上 可能网卡出现问题
- systemctl stop NetworkManager
- systemctl diable NetworkManager
- systemctl restart network
-
MR程序提交到Yarn
使用idea提交程序
配置mapred-site.xml文件 添加到resources目录下
- <?xml version="1.0"?>
- <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
-
- <configuration>
- <property>
- <name>yarn.app.mapreduce.am.env</name>
- <value>HADOOP_MAPRED_HOME=/opt/apps/hadoop-3.1.1</value>
- </property>
- <property>
- <name>mapreduce.map.env</name>
- <value>HADOOP_MAPRED_HOME=/opt/apps/hadoop-3.1.1</value>
- </property>
- <property>
- <name>mapreduce.reduce.env</name>
- <value>HADOOP_MAPRED_HOME=/opt/apps/hadoop-3.1.1</value>
- </property>
-
- </configuration>
-
- day05.com.doit.demo06;
修改提交任务的代码 maven打jar包的命令为 package
- public class Test02 {
- public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
- System.setProperty("HADOOP_USER_NAME", "root");
- Configuration conf = new Configuration();
- //操作HDFS数据
- conf.set("fs.defaultFS", "hdfs://linux01:8020");
- //设置运行模式
- conf.set("mapreduce.framework.name", "yarn");
- //设置ResourceManager位置
- conf.set("yarn.resourcemanager.hostname", "linux01");
- // 设置MapReduce程序运行在windows上的跨平台参数
- conf.set("mapreduce.app-submission.cross-platform","true");
-
- Job job = Job.getInstance(conf, "WordCount");
-
- //设置jar包路径
- job.setJar("D:\\IdeaProjects\\hadoop\\target\\test_yarn.jar");
-
- job.setMapperClass(WordCountMapper.class);
- job.setReducerClass(WordCountReduce.class);
-
- job.setMapOutputKeyClass(Text.class);
- job.setMapOutputValueClass(IntWritable.class);
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(IntWritable.class);
-
- //设置路径为HDFS路径
- FileInputFormat.setInputPaths(job,new Path("/wc/input/word.txt"));
- FileOutputFormat.setOutputPath(job,new Path("/wc/out4"));
-
- job.waitForCompletion(true);
- }
- }
在linux上直接提交jar包
- public class Test02 {
- public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
- Configuration conf = new Configuration();
-
- //设置运行模式
- conf.set("mapreduce.framework.name", "yarn");
- //设置ResourceManager位置
- conf.set("yarn.resourcemanager.hostname", "linux01");
- // 设置MapReduce程序运行在windows上的跨平台参数
- conf.set("mapreduce.app-submission.cross-platform","true");
-
- Job job = Job.getInstance(conf, "WordCount");
-
- //设置jar包路径
- //job.setJar("D:\\IdeaProjects\\hadoop\\target\\test_yarn.jar");
-
- job.setJarByClass(Test02.class);
-
- job.setMapperClass(WordCountMapper.class);
- job.setReducerClass(WordCountReduce.class);
-
- job.setMapOutputKeyClass(Text.class);
- job.setMapOutputValueClass(IntWritable.class);
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(IntWritable.class);
-
- //设置路径为HDFS路径
- FileInputFormat.setInputPaths(job,new Path("/wc/input/word.txt"));
- FileOutputFormat.setOutputPath(job,new Path("/wc/out5"));
-
- job.waitForCompletion(true);
- }
- }
- 打成jar包后
- linux上使用
- 需要查看 mapred-site.xml 如果没有配置 需要配置一下
-
- hadoop jar jar包名 运行的类
- hadoop jar test_yarn.jar day03.com.doit.demo02.Test02
Map Join
Map端join是指数据达到map处理函数之前进行合并的,效率要远远高于Reduce端join,因为Reduce端join是把所有的数据都经过Shuffle,非常消耗资源。
- order.txt
- order011 u001
- order012 u001
- order033 u005
- order034 u002
- order055 u003
- order066 u004
- order077 u010
-
- user.txt
- u001,hangge,18,male,angelababy
- u002,huihui,58,female,ruhua
- u003,guanyu,16,male,chunge
- u004,laoduan,38,male,angelababy
- u005,nana,24,femal,huangbo
- u006,xingge,18,male,laoduan
-
-
- 最终结果
- u001,hangge,18,male,angelababy,order012
- u001,hangge,18,male,angelababy,order011
- u002,huihui,58,female,ruhua,order034
- u003,guanyu,16,male,chunge,order055
- u004,laoduan,38,male,angelababy,order066
- u005,nana,24,femal,huangbo,order033
- null,order077
一个用户可能会产生多个订单,可能user.txt中的用户非常少,但是订单数据又非常非常多,这时我们可以考虑使用Map端join.一个小文件,一个大文件时,可以使用Map端join,说的简单一些,就是不走reduce,通过Map直接得出结果.
原理:将小文件上传到分布式缓存,保证每个map都可以访问完整的小文件的数据,然后与大文件切分后的数据进行连接,得出最终结果.

- package hadoop06.com.doit.demo;
-
- import hadoop03.com.doit.demo02.WordCountMapper;
- import hadoop03.com.doit.demo02.WordCountReducer;
- import hadoop05.com.doit.demo05.Test;
- import org.apache.commons.lang.ObjectUtils;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.IntWritable;
- import org.apache.hadoop.io.LongWritable;
- import org.apache.hadoop.io.NullWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.Mapper;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
-
- import java.io.BufferedReader;
- import java.io.FileReader;
- import java.io.IOException;
- import java.net.URI;
- import java.net.URISyntaxException;
- import java.util.HashMap;
- import java.util.Map;
-
- public class MapJoinDemo {
-
- public static class JoinMapper extends Mapper<LongWritable,Text,Text, NullWritable>{
-
- //定义集合用来存储user.txt的数据 键是uid 值是这一行记录
- private Map<String,String> userMap = new HashMap<>();
-
- private Text k2 = new Text();
- @Override
- protected void setup(Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {
- //读取本地user.txt文件 由于user.txt添加到了分布式缓存中,会将这个文件 缓存到执行maptask的计算机上
- //由于这个文件和class文件放在一起 可以直接读取
- BufferedReader br = new BufferedReader(new FileReader("user.txt"));
- String line = null;
- while((line = br.readLine())!=null){
- //System.out.println(line);
- String uid = line.split(",")[0];
- //将uid 和 user的一行记录放入到map中
- userMap.put(uid,line);
- }
- }
-
- @Override
- protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {
- //得到order的一条记录
- String line = value.toString();
- //获取order的 uid
- String uid = line.split("\\s+")[1];// u001
- //获取map中 当前uid的 用户信息
- String userInfo = userMap.get(uid);
-
- //拼接字符串写出
- k2.set(userInfo+","+line.split("\\s+")[0]);
-
- context.write(k2, NullWritable.get());
- }
- }
-
- public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException, URISyntaxException {
-
- System.setProperty("HADOOP_USER_NAME", "root");
- Configuration con = new Configuration();
-
- //配置到yarn上执行
- con.set("mapreduce.framework.name", "yarn");
- //配置操作HDFS数据
- con.set("fs.defaultFS", "hdfs://linux01:8020");
- //配置resourceManager位置
- con.set("yarn.resourcemanager.hostname", "linux01");
- //配置mr程序运行在windows上的跨平台参数
- con.set("mapreduce.app-submission.cross-platform","true");
-
- Job job = Job.getInstance(con,"wordcount");
-
- //分布式缓存user.txt文件
- job.addCacheFile(new URI("hdfs://linux01:8020/user.txt"));
-
- //设置jar包的路径
- job.setJar("D:\\IdeaProjects\\test_hadoop\\target\\test_hadoop-1.0-SNAPSHOT.jar");
-
- //设置Mapper
- job.setMapperClass(JoinMapper.class);
-
- //设置最后结果的输出类型
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(NullWritable.class);
-
- //设置读取HDFS上的文件 的路径
- //设置读取文件的位置 可以是文件 也可以是文件夹
- FileInputFormat.setInputPaths(job,new Path("/join/order.txt"));
- //设置输出文件的位置 指定一个文件夹 文件夹不已存在 会报错
- FileOutputFormat.setOutputPath(job,new Path("/join/out"));
-
- //提交任务 并等待任务结束
- job.waitForCompletion(true);
-
- }
-
- }
-
MR程序提交到Yarn上流程


