
- 1分享32个高质量的自学网站_oeasy自学网
- 2Java 栈的实现-使用链表_java 链表方式实现栈
- 3详解Python基本数据类型_python中汉字用哪个数据类型
- 4程序员刚毕业,去大厂好还是小厂好,送给刚毕业的你_程序员去大厂还是小厂好
- 5关于layui 的一个报错_uncaught referenceerror: util is not
- 6(21)维度表和事实表_维度,事实,码值,临时
- 7【论文写作】PPT绘图并另存为高清图片_论文ppt作图怎么导出
- 8未来十年人工智能有哪些新的方向_十年后 ai
- 9git push 总是需要输入密码或者个人访问令牌personal access token解决方案_为什么gitcode需要访问令牌
- 101688按关键词搜索示例
全新剪枝框架 | YOLOv5模型缩减4倍,推理速度提升2倍
赞
踩
作者 | 小书童 编辑 | 集智书童
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【目标检测】技术交流群
后台回复【2D检测综述】获取鱼眼检测、实时检测、通用2D检测等近5年内所有综述!

自动驾驶车辆中使用的目标检测器可能具有较高的内存和计算开销。在本文中介绍了一种新的半结构化剪枝框架R-TOSS,它克服了现有模型剪枝技术的缺点。
JetsonTX2上的实验结果表明,R-TOSS在YOLOv5目标检测器上的压缩率为4.4倍,推理时间加快了2.15倍,能耗降低了57.01%。
R-TOSS还可以在RetinaNet上实现2.89倍的压缩,推理时间加快1.86倍,能耗降低56.31%。与各种最先进的剪枝技术相比R-TOSS展示了显著的改进。
1、简介
近年来,自动驾驶汽车(AVs)因其提高驾驶舒适性和减少车辆碰撞伤害的潜力而受到极大关注。美国国家公路交通安全管理局(NHTSA)的一份报告显示,2021年美国公路上发生了31720多起致命事故。这些事故被发现主要是由司机分心造成的。AVs可以借助其感知系统帮助减轻人为错误并避免此类事故。感知系统通过一系列传感器(包括激光雷达、雷达和摄像头)帮助AVs了解周围环境。目标检测是此类感知系统的重要组成部分。
飞行器必须实时处理大量数据,以向车辆控制器提供精确的修正,以保持其航向、速度和方向。为了协助车辆路径规划和控制,AVs依靠目标检测器来提供有关其周围障碍物的信息。这些目标检测器必须满足两个重要条件:
保持高精度
提供实时推断(几十毫秒)
近年来,研究人员已经能够设计用于高精度目标检测的机器学习模型,但这些模型通常非常计算密集,并且经常与传感器融合任务相结合,这有助于通过组合来自各种传感器的数据来向这些模型提供输入。除了这些目标检测器外,Avs还必须处理大量数据,作为高级驾驶员辅助系统(ADAS)的一部分,以实现操作安全和安保,例如车内通信和车对x(V2X)协议,这会增加计算成本和电力使用。这是一个挑战,因为AVs中的机载计算机资源有限,功耗和计算能力受到严格限制。
目标检测是一项涉及分类和回归的计算和内存密集型任务。通常,所有基于机器学习的对象检测器可以分为两种类型:
1)两阶段检测器
2)单阶段检测器
两阶段检测器由两个检测过程组成,包括区域建议阶段和随后的目标分类细化阶段。区域建议阶段通常由区域建议网络(RPN)组成,该网络在输入图像(例如,来自AV中的相机传感器)中建议多个感兴趣区域(ROI)。这些ROI用于对其中的目标进行分类。然后,目标被边界框包围以定位它们。两阶段检测器的示例包括R-CNN、Fast R-CNN和Faster R-CNN。
与两阶段检测器不同,单阶段检测器使用单一前馈网络,该网络包括分类和回归,以创建边界框来定位目标。单阶段目标检测器重量轻,比两阶段检测器更快。单阶段检测器的一些经典的方法有YOLOv5、RetinaNet、YOLOR和YOLOX等等。不幸的是,即使是单阶段检测器也是计算和内存密集型的,因此在AV中的嵌入式和物联网板上部署和执行它们仍然是一个瓶颈。
为了解决这一瓶颈,近年来提出了许多技术,例如剪枝、量化和知识蒸馏,以压缩和优化目标检测器的推理过程,重点是在保持模型精度的同时提高推理时间。特别是,通过仔细去除不影响总体精度的冗余权重,剪枝技术已被证明在增加目标检测器模型的稀疏性方面非常有效。这样的稀疏模型需要更少的计算,并且可以被压缩以减少延迟、内存和能源成本。
在本文中介绍了R-TOSS目标检测器修剪框架,以实现AVs中使用的目标检测器的有效剪枝。与通常可分类为结构化剪枝或非结构化剪枝的传统修剪算法不同,作者使用了一种涉及半结构化剪枝的方法。本文的方法涉及应用特定的kernel模式来修剪卷积kernel和相关的连接性。
提出的目标检测器修剪框架的贡献如下:
通过使用深度优先搜索来生成要一起修剪的父子核计算图来降低迭代修剪的计算成本的方法;
提出一种剪枝技术用于修剪1×1核权重,以增加模型稀疏性;
提出一种在不进行连通性修剪的情况下实现kernel修剪,以保留kernel信息用于推断,这有助于保持模型的准确性;
与多种最先进的修剪方法进行详细比较,以展示本文新框架在mAP、延迟、能耗和实现的稀疏性方面的有效性。
2、相关工作
修剪目标检测模型旨在通过使用某些标准从模型中移除权重参数来减少模型大小和计算复杂性。考虑具有个层的深度学习模型。深度学习模型最复杂的操作是卷积(Conv)层。如果每个Conv层具有个kernel和个非零权重,则在推断过程中,模型的计算成本是的函数。
随着所涉及参数的增加,计算成本急剧增加,这是现代深度学习模型的趋势。通过执行参数修剪,可以在模型中引入稀疏性,这将减少中的参数,通过kernel修剪,还可以减少。这降低了总体计算成本。新兴计算平台提供了软件压缩技术,该技术可以响应于零值(删减)参数的存在来压缩输入矩阵和权重矩阵,从而在模型执行期间完全skipping它们。skipping操作也可以可选地由具有专门设计的硬件的硬件执行。
先前工作中的修剪方法可分为3大类:
非结构化剪枝
结构化剪枝
半结构化剪枝或基于模式的剪枝
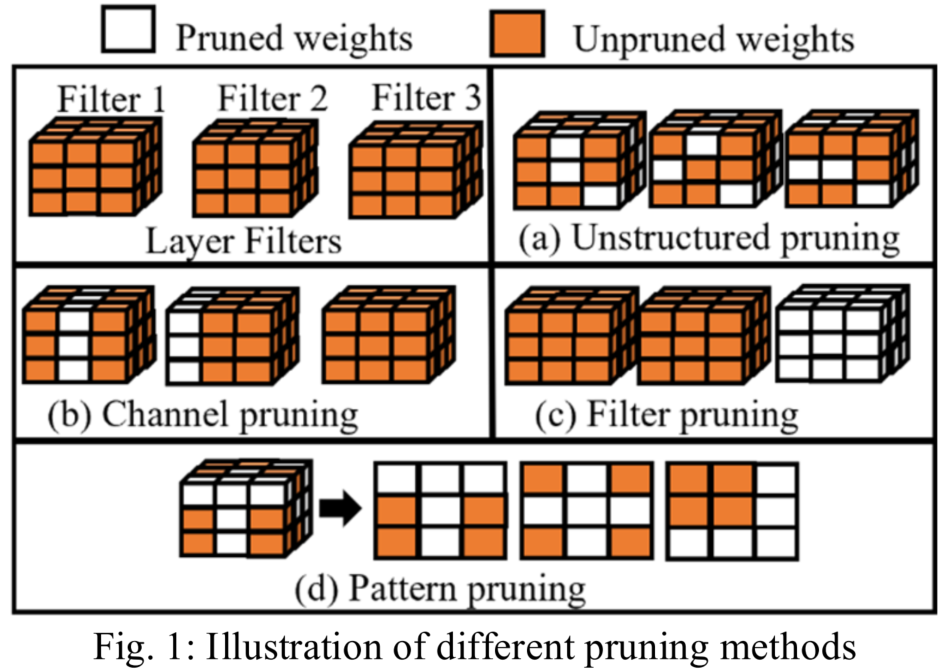
2.1、非结构化剪枝
在非结构化修剪中,多余的权重(图1(a))被随机地修剪,同时将损失保持在最小,这有助于保持模型的准确性。
已经提出了几种非结构化的修剪方案,例如:
weight magnitude pruning,其重点是将一组低于预定义阈值的权重替换为零;
gradient magnitude pruning,其修剪梯度低于预定义阈值的一组权重;
synaptic flow pruning,这是一种迭代修剪技术,使用全局评分方案并修剪一组权重,直到全局评分降至阈值以下;
以及second order derivative pruning,其通过将一组权重替换为零并保持网络的损失接近原始损失来计算权重的二阶导数。
由于来自不同权重矩阵的不同稀疏度导致的负载失衡,这些方法对线程级并行性产生了负面影响。不规则的稀疏性也会影响内存性能,因为它会在数据访问位置中产生变化,从而降低跨各种平台(GPU、CPU、TPU)缓存的性能。
2.2、结构化剪枝
在结构化修剪中,对整个滤波器(图1(c))或连续通道(图1)(b))进行修剪,以增加模型的稀疏性。滤波器/通道修剪提供了更均匀的权重矩阵,并减小了模型的大小。与非结构化修剪相比,简化的矩阵有助于减少乘法和累加(MAC)操作的数量。
然而,结构化修剪也会降低模型的准确性,因为可以有助于模型整体准确性的权重也将与冗余权重一起被修剪。结构化修剪也可以与TensorRT等加速算法一起使用。
与非结构化修剪不同,由于权重矩阵的统一性质,结构化修剪可以更好地利用各种平台在内存和带宽方面提供的硬件加速。
2.3、半结构化剪枝
半结构化剪枝,也称为模式剪枝,是结构化剪枝和非结构化剪枝方案的组合(图1(d))。这种类型的剪枝利用了可以用作kernel掩码的kernel模式。掩码防止其覆盖的权重被修剪,从而导致kernel中的部分稀疏。通过评估修剪kernel的有效性,例如利用范数,可以在推理过程中识别和部署最有效的模式掩码。由于kernel模式只能修剪kernel内固定数量的权重,因此它们将比其对应的稀疏性更少。
为了克服这个问题,模式剪枝与连接剪枝一起应用,连接修剪会完全剪枝一些kernel。然而,大多数现代目标检测器都有大量的1×1卷积核,这些核包含在这个过程中不被修剪的冗余权重。这是因为,模式修剪技术通常侧重于大小为3×3或更大的卷积核,这些卷积核具有更多的候选权重用于修剪。
连接修剪也会降低模型的准确性,因为在这个过程中,特定卷积核中的几个重要权重也会被移除。然而,由于其半结构化性质,kernel模式修剪仍然可以利用硬件并行性来减少模型的推理时间。
3、本文动机
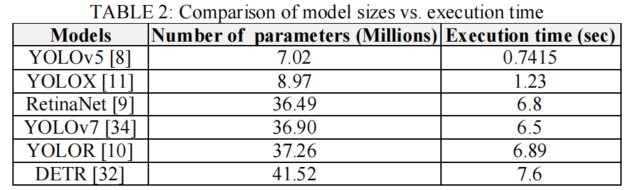
设计用于AVs的目标检测器需要高精度,但因此这些模型也有开销,如大内存占用和更高的推理时间。为了克服这些问题,需要提出一个能够实现高精度的轻量级模型。YOLOv5、RetinaNet、Detection Transformer(DETR)和YOLOR等检测器是实现实时检测目标的良好起点,但这些模型仍具有较高的内存占用量,可能会降低模型性能。表2总结了Jetson TX2上随着目标检测器模型的大小增加的推断时间。
为了减少操作延迟,同时保持模型精度,可以采用剪枝技术。在剪枝技术中,基于模式的半结构化剪枝可以提供比非结构化剪枝更好的稀疏性,同时确保比结构化剪枝技术更好的准确性。
半结构化剪枝还允许更规则的权重矩阵形状,从而允许硬件更好地加速模型推断。同时,与结构化剪枝不同,它不会剪枝整个卷积核权重,从而保留更多信息,从而确保更好的准确性。因此,理想情况下,基于模式的剪枝技术可以生成具有高稀疏性和高精度的模型。
然而,基于模式的剪枝的一个警告是,当前的技术主要集中在3×3卷积核上,这限制了可实现的稀疏性,因此限制了推理加速的好处。大多数最先进的模型,如YOLOv5、RetinaNet和DETR,分别由68.42%、56.14%和63.46%的1×1小卷积核组成。因此,为了增加此类模型的稀疏性,基于模式的剪枝技术有时会在这3×3个卷积核上使用连通性修剪。但是,连接剪枝中使用的“每层最后一个内核”标准会导致重要信息的丢失,从而影响模型的准确性。因此,作者选择在剪枝框架中避免连接剪枝。
此外,如上所述,该技术仍然没有处理1×1卷积核,这是卷积核的重要组成部分。
为了解决这些缺点,作者提出了一种三步剪枝方法来剪枝1×1卷积核:
将1×1个卷积核组成3×3个临时权重矩阵;
对这些权重矩阵应用kernel模式修剪;
将临时权重矩阵分解为1×1卷积核,并重新分配给它们的原始层。
因此,本文的方法增加了模型的稀疏性,同时保留了有助于模型准确性的重要信息。
4、R-TOSS剪枝框架
在本节中,我们描述了我们的新型R-TOSS修剪框架,并详细介绍了我们如何在YOLOv5和RetinaNet对象检测器上实现了前面提到的对内核修剪技术的改进。在保持模型大部分原始性能的同时,一种简单的修剪方法是采用迭代修剪方法。但这是一种幼稚的方法,因为随着模型大小的增加,迭代方法在计算成本和时间要求方面会很快变得笨拙。如第III.C节所述,现代物体探测器的模型尺寸正在增加,但对于许多使用它们的应用领域,如AVs,其精度不能降低。我们的R-TOSS框架(图2)采用了迭代修剪方案,并进行了若干优化,以减少计算成本和时间开销。我们首先使用深度优先搜索(DFS)算法,该算法用于查找模型中的父子层耦合。由此获得的父子图用于减少修剪的计算要求。当父层的修剪反映在图中的子层中时,计算成本会降低。我们跟踪DFS,识别子图中的3×3和1×1内核,并对其应用内核大小特定的修剪。这些算法将在以下小节中详细讨论。
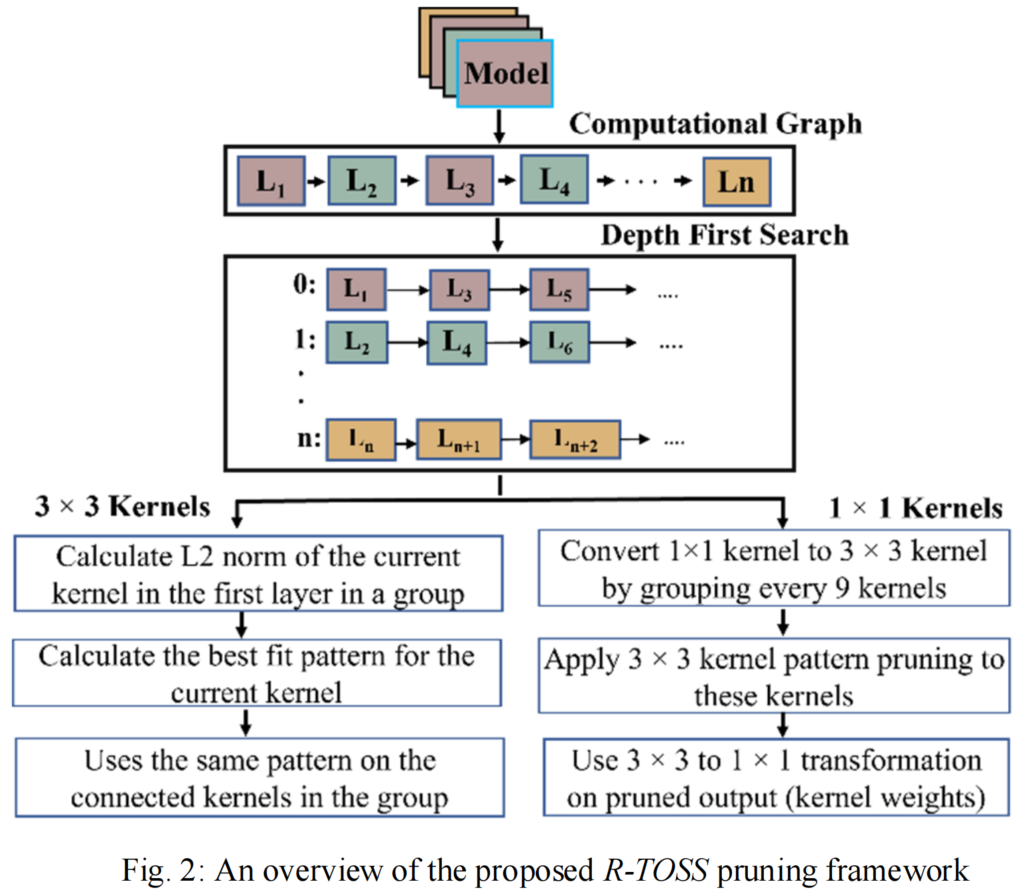
4.1、DFS算法
算法1显示DFS算法的伪代码。
使用预训练的模型作为输入,使用从反向传播获得的梯度来计算计算图(G)。初始化一个空列表(group_list)(第2行)以存储父子图层组。然后遍历模型层(),并在计算图G上应用DFS搜索以识别该层的父层。
如果一个层没有任何父层,那么将该层指定为它自己的父层()(第7-9行),这将成为一个组。
如果一个层被标识为group_list(第5行)中任何层的子层(),则该层现在成为子层()的父层()并添加到该组(第5-6行)。每个父层()可以有多个子层(),但每个子层只能有一个父层()。
此过程将继续,直到所有图层都指定给一个组。由于每个组中的层都有耦合通道,因此它们也共享其kernel weight,因此可以共享相同的kernel模式。

4.2、选择kernel模式
通过标准组合法在所有可能的组合中生成模式掩模,使用以下公式:
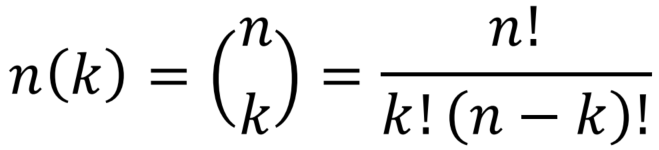
其中,是矩阵的大小,k是图案掩模的大小。然后,使用以下两个标准来减少使用的内核模式的数量:
丢弃所有没有相邻非零权重的模式;这样做是为了保持kernel模式的半结构化性质;
通过使用范围[-1,1]内的随机初始化计算kernel的范数来选择最常用的kernel模式。的值可以从1到8,这可以生成8种不同类型的图案组。
为了增加模型的稀疏度,模式中非零权重的数量应该更低。先前关于kernel模式修剪的工作使用了由kernel中的4个非零权重组成的4项模式。但这导致模型具有相对较低的稀疏性,为了克服这一问题,这些工作的作者利用了连通性修剪。
由于第二节中讨论的连接修剪的缺点,作者建议在R-TOSS框架中使用3入口模式(3EP)和2入口模式(2EP)kernel模式,它们分别使用3个和2个非零权重。
4.3、3×3 kernel修剪
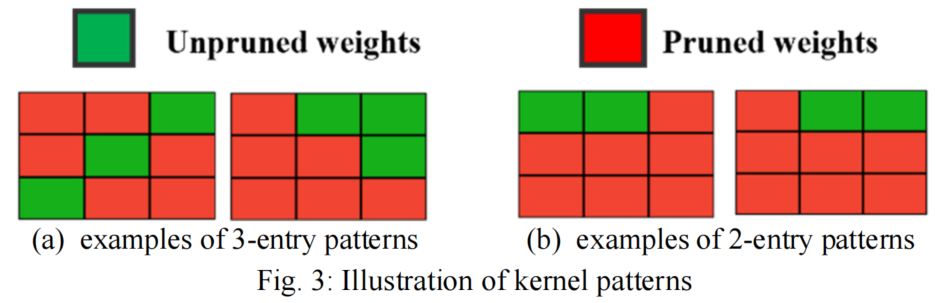
算法2显示了使用所提出的内核模式进行3×3 kernel模式修剪的伪代码,其示例如图3所示。

首先使用来自算法1的3×3父核权重(KW)作为输入,并初始化一个变量(形状)以存储核权重的形状(第1行)。还创建了一个由3EP(图3(a))和2EP(图2(b))模式组成的模式字典(kernel_patterns_dict)(第3行)。然后遍历3×3 kernel,并将当前3×3 kernel的权重矩阵存储在层中作为temp_kernel(第5行)。然后,初始化一个空列表(L2_dict),在应用模式字典中的kernel模式后,该列表可以存储temp_kernel的范数。
然后,遍历kernel_patterns_dict中的kernel模式,并在应用kernel模式后计算kernel的L2norm。该L2norm与来自kernel_patterns_dict的当前模式的key一起存储在L2_dict列表中(第7-10行)。然后,使用L2_dict中的L2norm值找到temp_kernel的最佳kernel模式,并将kernel模式的索引存储在最佳拟合变量中(第11行)。
来自bestfit的索引现在被用作kernel的kernel模式,并更新为其原始权重矩阵(第12-14行)。然后,遍历父层中的所有kernel,并将其存储为算法1中父层组(lP)中其余3×3 kernel的 kernel 掩码。一旦找到适合于父kernel的模式,这些模式也将通过利用卷积映射应用于相应的子kernel。
还通过执行1×1到3×3 kernel转换,将这种模式匹配方法应用于1×1 kernel。由于将相同的kernel掩码应用于特定组中的所有kernel,因此可以减少框架修剪整个模型所需的时间。
通过实验,将所需的图案总数减少到21个。由于在推理时只有21个预定义的kernel模式,因此具有类似模式的kernel被分组在一起,这可以降低总体计算成本并加快推理。
4.3、1×1 kernel修剪
通过执行1×1到3×3变换,从内核修剪中删除了连接性修剪。这可以确保能够保持模型的准确性,并减轻连接修剪带来的损失。
1×1 kernel剪枝还可以通过将相似的kernel模式分组在一起来加速推理。算法3显示了执行1×1内核修剪的伪代码。

首先使用来自算法1(group_list)的父层的1×1 kernel权重作为输入。然后,初始化一个列表FL,该列表用于存储(第1-2行)中扁平的1×1 kernel权重。随后,初始化用于存储临时权重矩阵的temp_array。我们遍历展平数组FL,并将列表中的每9个权重分组为3×3个临时权重矩阵,这些矩阵存储在temp_array中(第5-11行)。这个过程一直持续到列表末尾,或者如果值小于9。此时,剩余的权重被视为零权重并被修剪(第13行)。然后,使用算法2对temp_array中的临时3×3权重矩阵执行3×3 kernel修剪(第14行)。
算法2的输出矩阵被存储回temp_array中,temp_arra被转换回1×1 kernel,并附加回原始的1×1 kernel权重(第15-16行)。
5、实验
5.1、精度对比

5.2、速度对比
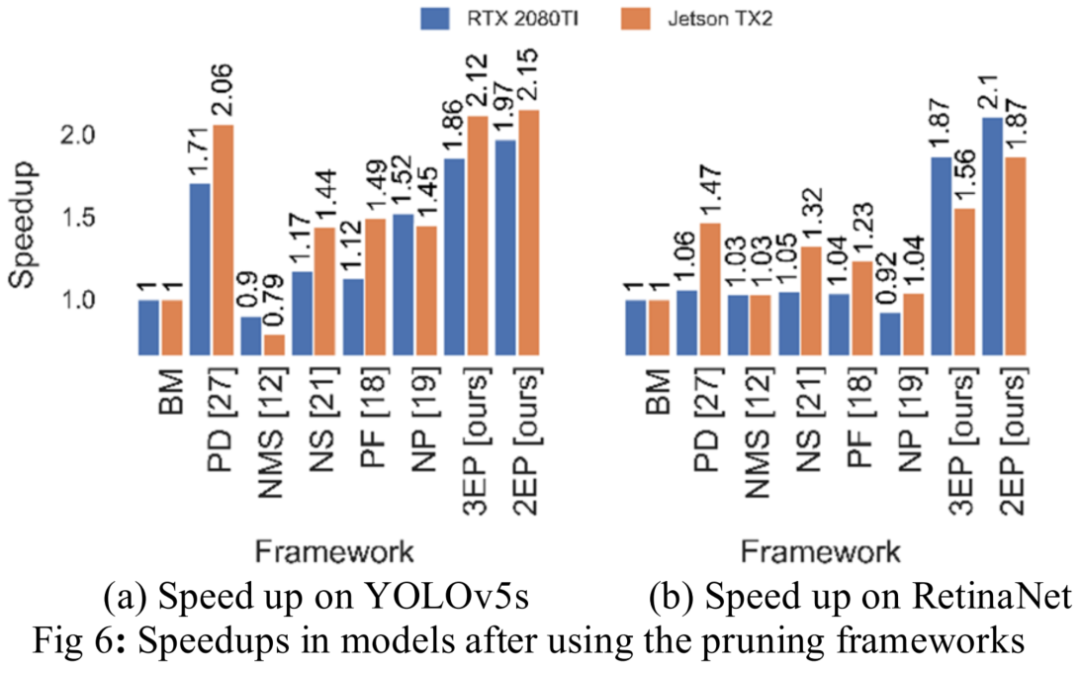
在图6中的推断时间结果表明,在RTX 2080 Ti上,R-TOS-3EP和R-TOS-2EP能够实现YOLOv5s的1.86倍和1.97倍的执行时间加速,与BM相比,在RetinaNet上实现1.87倍和2.1倍的速度加速。
优于目前性能最佳的现有工作框架(PD),YOLOv5s分别为8%和13.3%,分别地类似地,与BM相比,在Jetson TX2上,R-TOSS-3EP和R-TOSS-2EP能够在YOLOv5s模型上实现2.12倍和2.15倍的推理时间加速,在RetinaNet上实现1.56倍和1.87倍的加速。
R-TOS-3EP和R-TOS-2EP也优于PD,在YOLOV5上执行时间分别快2.6%和4.27%,在Retina Net上执行时间快5.94%和21.62%。
5.3、可视化结果

图8说明了不同框架在KITTI数据集测试用例上的性能。从结果中可以观察到,R-TOS-2EP特别保留了检测微小目标(本例中的汽车)的能力,以及比NP和PD更好的置信度分数。由于AVs依靠快速准确的推断来做出时间关键的驾驶决策,R-TOSS可以帮助实现速度和精度,同时保持比所比较的其他最先进修剪技术更低的能耗。
6、参考
[1].R-TOSS: A Framework for Real-Time Object Detection using Semi-Structured Pruning.

国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称

