
热门标签
热门文章
- 1Android输入法IME(三)之 管理端(IMMS)启动流程
- 2HBase高可用集群踩坑总结以及hbase-site.xml配置文件分享_配置hbase-site.xml出现的问题
- 3数据结构~~排序
- 4从零开始学习CANoe(一)—— 新建工程_canoe新建工程
- 5【计算机视觉 | 图像分割】arxiv 计算机视觉关于图像分割的学术速递(7 月 4 日论文合集)_hrsegnet
- 6FPGA - 4位数值比较器电路
- 7Python 一步一步教你用pyglet制作汉诺塔游戏(终篇)_python汉诺塔
- 8输入十个姓名,按首字母的大小排列顺序!_c 语言 人名按字母排序
- 9毕业设计:基于python动漫数据分析推荐系统+可视化+协同过滤推荐算法 Django框架(源码)✅
- 10前端大文件分片下载解决方案,没用你来砍我
当前位置: article > 正文
vue源码之mustache模板引擎_模板引擎底层
作者:菜鸟追梦旅行 | 2024-05-23 01:30:06
赞
踩
模板引擎底层
vue源码之mustache模板引擎
什么是模板引擎
模板引擎是将数据变为视图的解决方案;
1、纯DOM法;
2、数据join法(字符串);
3、es6的反引号法;
4、模板引擎;
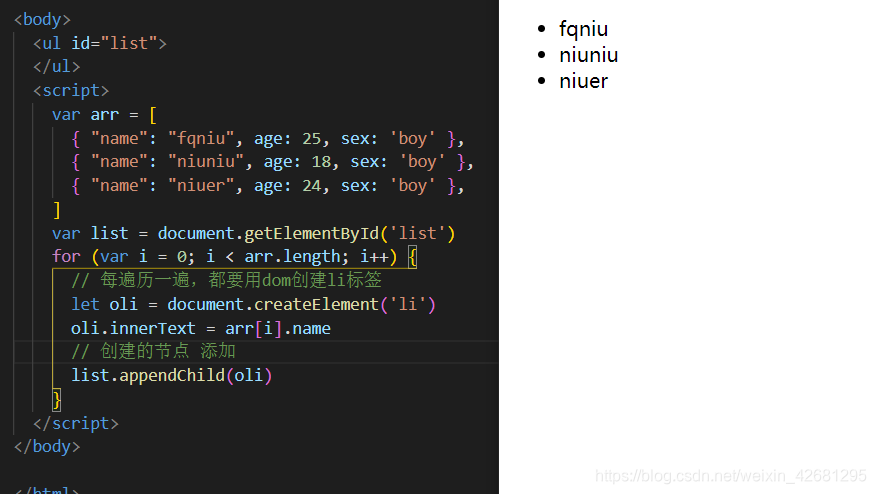
<body> <ul id="list"></ul> <script> var str = ['a', 'b', 'c', 'd'].join('') var str = [ 'a', 'b', 'c', 'd' ].join('') console.log(str); // abcd var html = [ '<ul>', '<li>姓名:</li>', '<li>年龄:</li>', '<li>性别:</li>', '</ul>' ].join('') console.log(html); var arr = [ { "name": "fqniu", age: 25, sex: 'boy' }, { "name": "niuniu", age: 18, sex: 'boy' }, { "name": "niuer", age: 24, sex: 'boy' }, ] var list = document.getElementById('list') // 遍历arr数组,每遍历一项,就以字符串的视角将HTML字符串添加到list中 for(let i=0;i<arr.length;i++){ list.innerHTML += [ '<ul>', '<li>姓名:'+arr[i].name+'</li>', '<li>年龄:'+arr[i].age+'</li>', '<li>性别:'+arr[i].sex+'</li>', '</ul>' ].join('') } // 反引号写法 for(let i=0;i<arr.length;i++){ list.innerHTML += ` <ul> <li>姓名:${arr[i].name}</li> <li>年龄:${arr[i].age}</li> <li>性别:${arr[i].sex}</li> </ul> ` } </script> </body>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
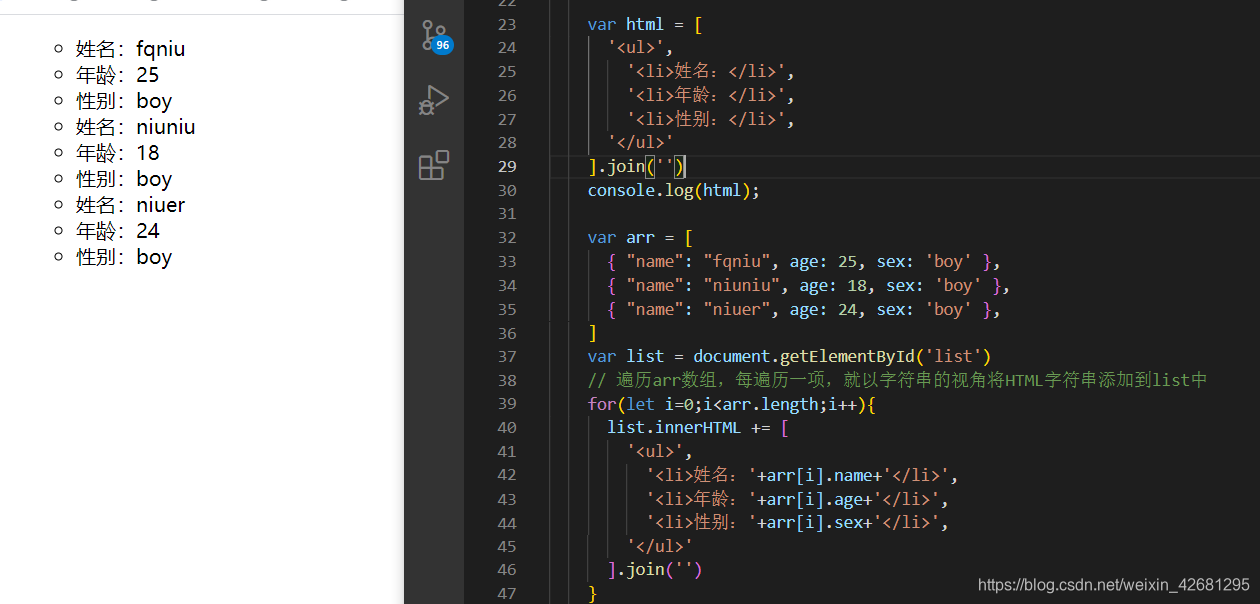

mustache 基本使用
mustache是最早的模板引擎库;引入mustache库,可以在bootcdn.com上找到;
mustache的模板语法比较简单,如下:
<div id="wrapper"></div> // 引入 mustache 文件 <script src="./mustache.js"></script> <script> console.log(Mustache); // # 代表循环开始 /代表循环结束 var templateStr = ` <ul> {{#arr}} <li> <div>姓名:{{name}}</div> <div>年龄:{{age}}</div> <div>性别:{{sex}}</div> </li> {{/arr}} </ul> `; var data ={ arr:[ { "name": "fqniu", age: 25, sex: 'boy' }, { "name": "niuniu", age: 18, sex: 'boy' }, { "name": "niuer", age: 24, sex: 'boy' }, ] }; var domStr = Mustache.render(templateStr,data) console.log(domStr); var wrapper = document.getElementById('wrapper') wrapper.innerHTML = domStr </script>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29

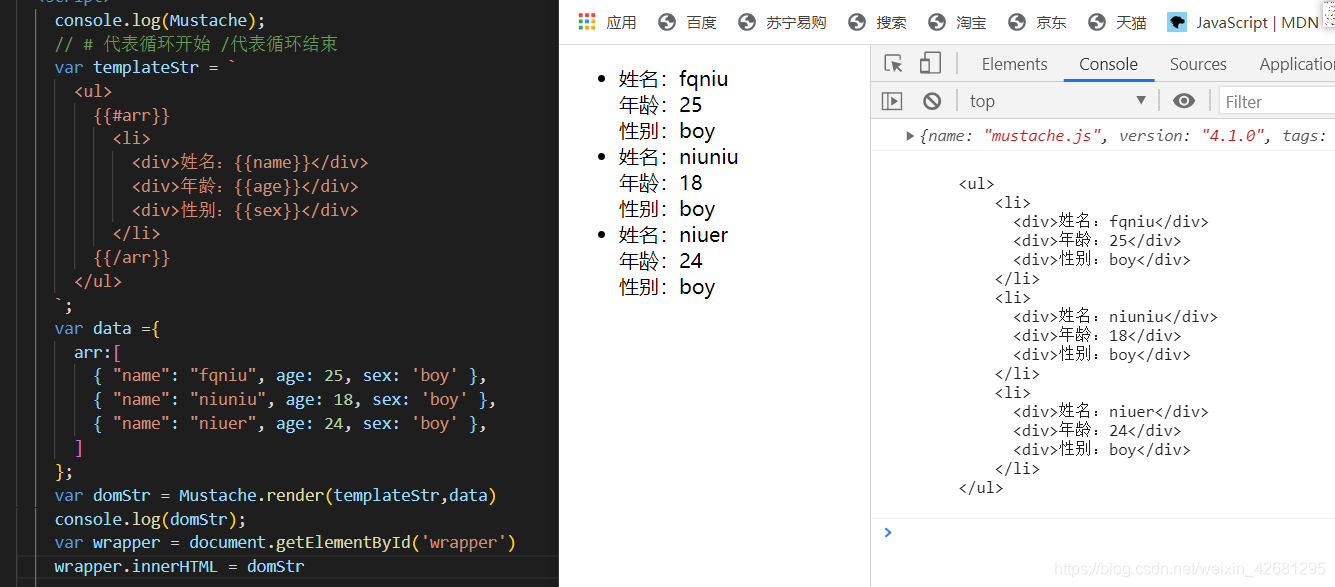

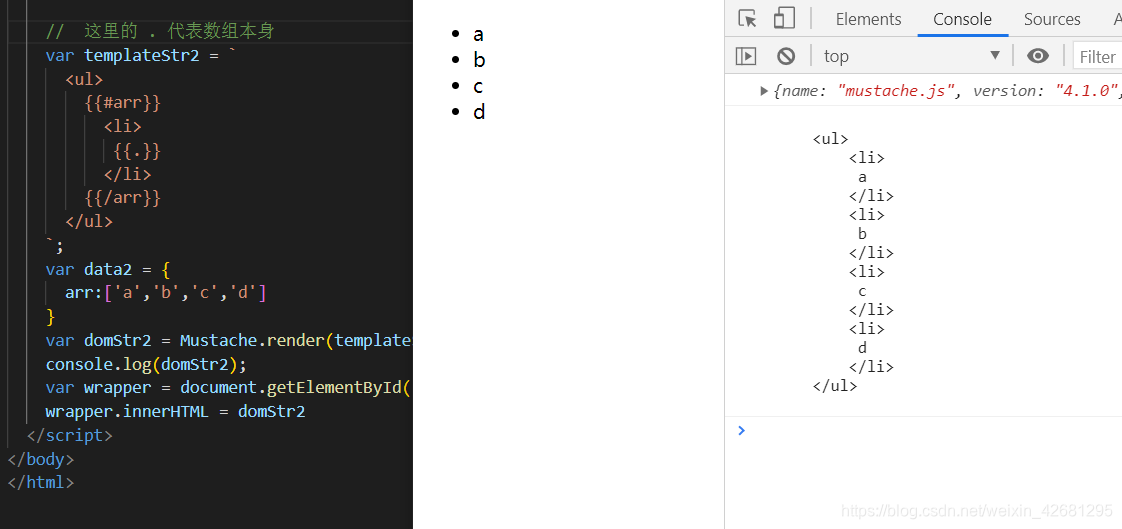
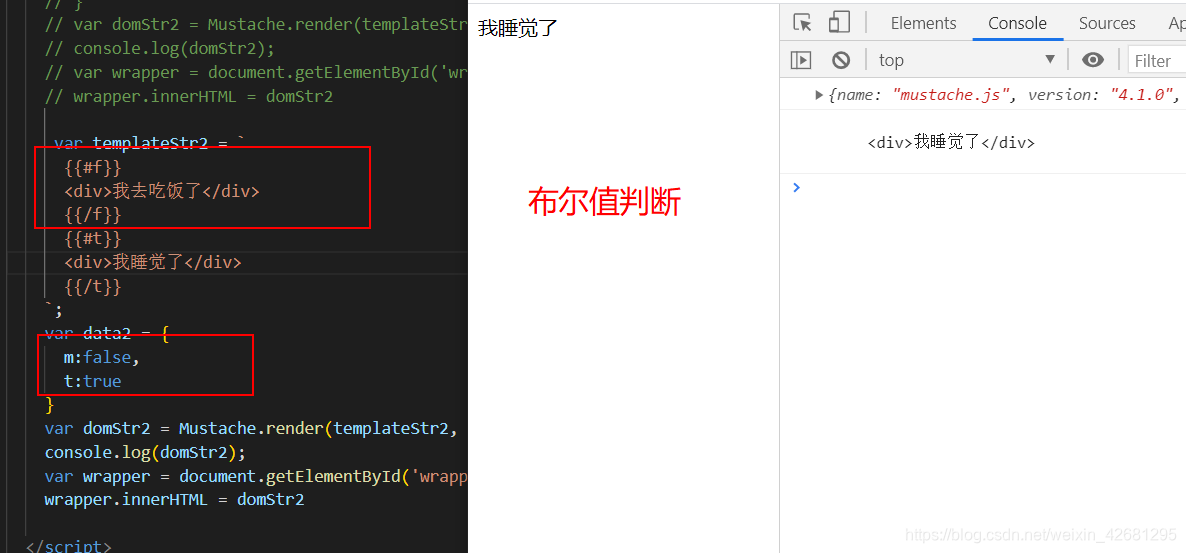
mustache 底层核心机理


// 简单的模板引擎实现机理。利用的是正则表达式中的replace方法
// replace() 的第二个参数可以是一个函数,函数提供捕获的东西参数,就是captureStr,最后结合data对象,进行智能的替换
function render(templateStr, data) {
return templateStr.replace(/\{\{(\w+)\}\}/g, function (findStr, captureStr) {
return data[captureStr]
})
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
tokens是一个js的嵌套数组,就是模板字符串的JS表示;
它是 “抽象语法书” 、“虚拟节点”;


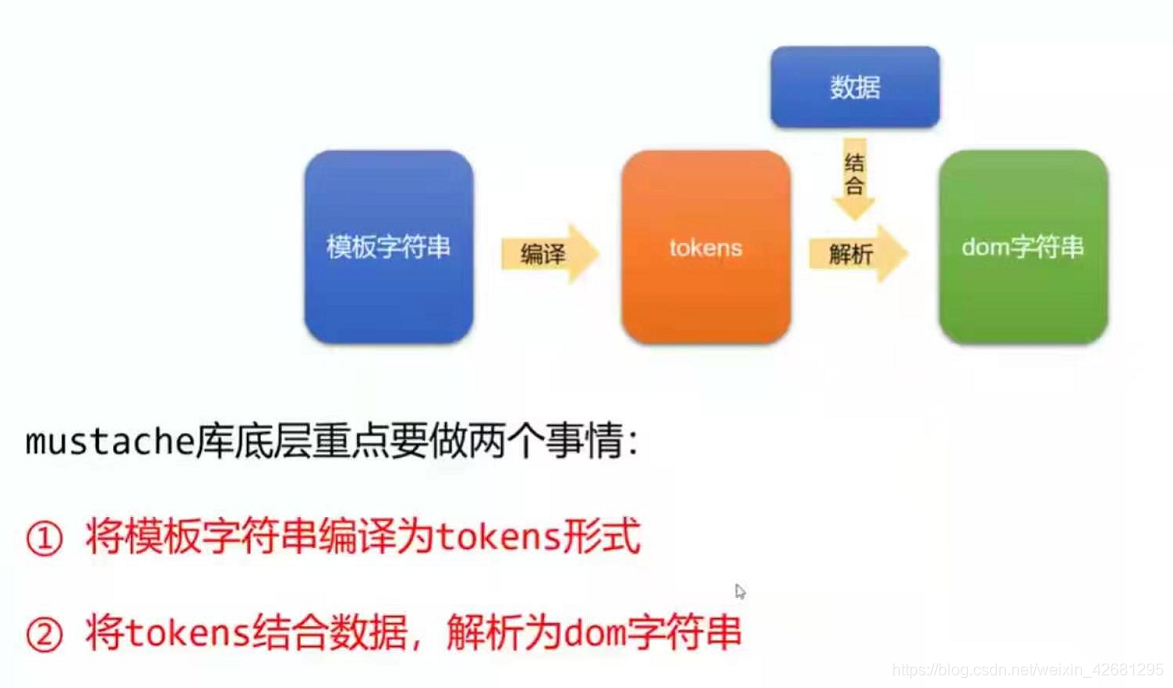
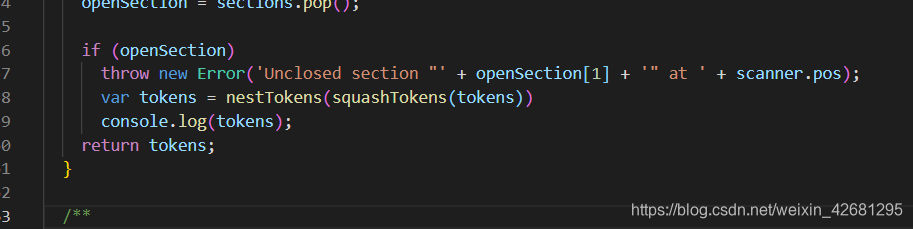

手写实现mustache库
mustache.js中的scan

mustache库之scanner
/** * 扫描器类 * */ export default class Scanner { constructor(templateStr) { console.log('我是scanner=', templateStr); // 将模板字符串写到实例中 this.templateStr = templateStr // 指针 this.pos = 0 // 尾巴 一开始就是模板字符串的原文 this.tail = templateStr } // 功能弱,就是走过指定内容 ,没有返回值 scan(tag) { if (this.tail.indexOf(tag) == 0) { // tag有多长,比如{{长度为2,就让指针后移多少位 this.pos += tag.length; // 尾巴也要变, 改变尾巴,从当前指针这个字符开始,到最后全部字符 this.tail = this.templateStr.substring(this.pos) } } // 让指针进行扫描,直到遇见内容结束,并且能够返回结束之前路过的文字 scanUntil(stopTag) { // 记录一下执行方法的时候pos值 const pos_backup = this.pos; // 当尾巴不是stopTag的时候,就说明还没有扫描到stopTag // 这里的&& 防止找不到那么寻找到最后也要停止下来,死循环 while (!this.eos() && this.tail.indexOf(stopTag) !== 0) { this.pos++; // 改变尾巴,从当前指针这个字符开始,到最后全部字符 this.tail = this.templateStr.substring(this.pos) } return this.templateStr.substring(pos_backup, this.pos) } // eos 指针是否已经到头,返回布尔值 end of string eos(){ return this.pos >= this.templateStr.length } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
index.js
import Scanner from './Scanner' window.mt_templateEngine = { render(templateStr,data){ console.log('render函数被调用了'); // 实例化一个扫描器,构造时候提供一个参数,这个参数就是模板字符串 // 可以说扫描器就是针对这个字符串工作的 var scanner = new Scanner(templateStr) var word; // 当 scanner 没有到头 // while(scanner.pos !== templateStr.length){ while(!scanner.eos()){ word = scanner.scanUntil("{{") console.log(word); scanner.scan("{{") word = scanner.scanUntil("}}") console.log(word); scanner.scan("}}") } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
mustache库之token
import Scanner from './Scanner' /** * 将模板字符串变为tokens数组 */ export default function parseTemplateToToken(templateStr) { var tokens = [] // 创建扫描器 var scanner = new Scanner(templateStr) var words // 扫描器工作 while(!scanner.eos()){ // 收集开始标记出现之前的文字 words = scanner.scanUntil('{{') // 判断是否为空的情况 if(words !==''){ // 这个words就是{{}}中间的东西,判断一下首字符 if(words[0] == '#'){ // 存起来,从下标为1的开始存,因为下标为0的是 # tokens.push(['#',words.substring(1)]) } else if (words[0] == '/'){ // 存起来,从下标为1的开始存,因为下标为0的是 / tokens.push(['/',words.substring(1)]) } else { // 存起来 tokens.push(['text',words]) } } // // 判断是否为空的情况 // if(words !==''){ // // 存起来 // tokens.push(['name',words]) // } // 过双大括号 scanner.scan('{{') // 收集开始标记出现之前的文字 words = scanner.scanUntil('}}') // 判断是否为空的情况 if(words !==''){ // 这个words就是{{}}中间的东西,判断一下首字符 if(words[0] == '#'){ // 存起来,从下标为1的开始存,因为下标为0的是 # tokens.push(['#',words.substring(1)]) } else if (words[0] == '/'){ // 存起来,从下标为1的开始存,因为下标为0的是 / tokens.push(['/',words.substring(1)]) } else { // 存起来 tokens.push(['text',words]) } } // 过双大括号 scanner.scan('}}') } return tokens }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57

将零散的tokens嵌套起来
这里的结构为 栈 (first in last out):FILO 先进后出;
遇见 # 就进栈,遇见 / 就出栈



根据源码引出如下
/** * nestTokens 函数是用于折叠tokens * 将 # 和 / 之间的tokens整合起来,作为下标为3的项 * */ export default function nestTokens(tokens) { // 结果数组 var nestedTokens = []; // 栈结构 存放小tokens ,栈顶(靠近端口的,最新进入的) 的tokens数组中当前操作的这个tokens小数组 var sections = [] // console.log(tokens); // 收集器 天生指向 nestedTokens结果数组,引用类型值,指向同一个数组 // 注意 收集器指向会变化 当遇见 # 收集器会指向这个token下标为2的新数组 var collector = nestedTokens for (let i = 0; i < tokens.length; i++) { let token = tokens[i]; switch (token[0]) { case '#': // // 给这个tokens下标为2的项创建一个数组,以收集子元素 // token[2] = [] // // 压栈 (入栈) // sections.push(token) // // console.log(token[1],'进栈'); // nestedTokens.push(token) // 收集器中放入token collector.push(token) // (入栈) sections.push(token) // 收集器换人, 给这个token添加下标为2的项,并且让收集器指向他 collector = token[2] = [] break; case '/': // // 弹栈 出栈 pop() 会返回弹出的项 // let section_pop = sections.pop() // // console.log(section[1],'出栈'); // // 刚刚弹出的项还没有加入到结果数组中 // nestedTokens.push(section_pop) // 出栈 pop() 会返回刚刚弹出的项 let section_pop = sections.pop() // 改变收集器为栈结构队尾(队尾是栈顶) 那项下标为2的数组 collector = sections.length > 0 ? sections[sections.length - 1][2] : nestedTokens break; default: // // 判断。栈队列当前情况 // if(sections.length == 0){ // nestedTokens.push(token) // }else{ // sections[sections.length -1][2].push(token) // } collector.push(token) } } return nestedTokens; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
编写renderTemplate 函数让tokens 变为dom字符串
先写一种较为简单的形式但是不全面的函数
/** * 函数的功能是让tokens 数组变为dom字符串 * */ export default function renderTempla(tokens, data) { console.log(tokens, data); // 结果字符串 var resultStr = '' // 循环tokens for (let i = 0; i < tokens.length; i++) { let token = tokens[i] // 看类型 if (token[0] == 'text') { // 拼起来 resultStr += token[1] } else if (token[0] == 'name') { resultStr += data[token[1]] } } console.log(resultStr); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
index.js
import Scanner from './Scanner';
import parseTemplateToToken from './parseTemplateToToken';
import renderTemplate from './renderTemplate'
window.mt_templateEngine = {
render(templateStr, data){
// 调用 parseTemplateToToken 让模板字符串变为tokens数组
var tokens = parseTemplateToToken(templateStr)
// 调用renderTemplate 函数,让token数组变为dom字符串
var domStr = renderTemplate(tokens, data)
console.log(tokens);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title> </head> <body> <div>我是index.html</div> <script src="/xuni/bundle.js"></script> <script> var templateStr = '我爱{{things}},{{things}}也好吃!'; var data = { things:'做饭' } mt_templateEngine.render(templateStr,data) </script> </body> </html>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
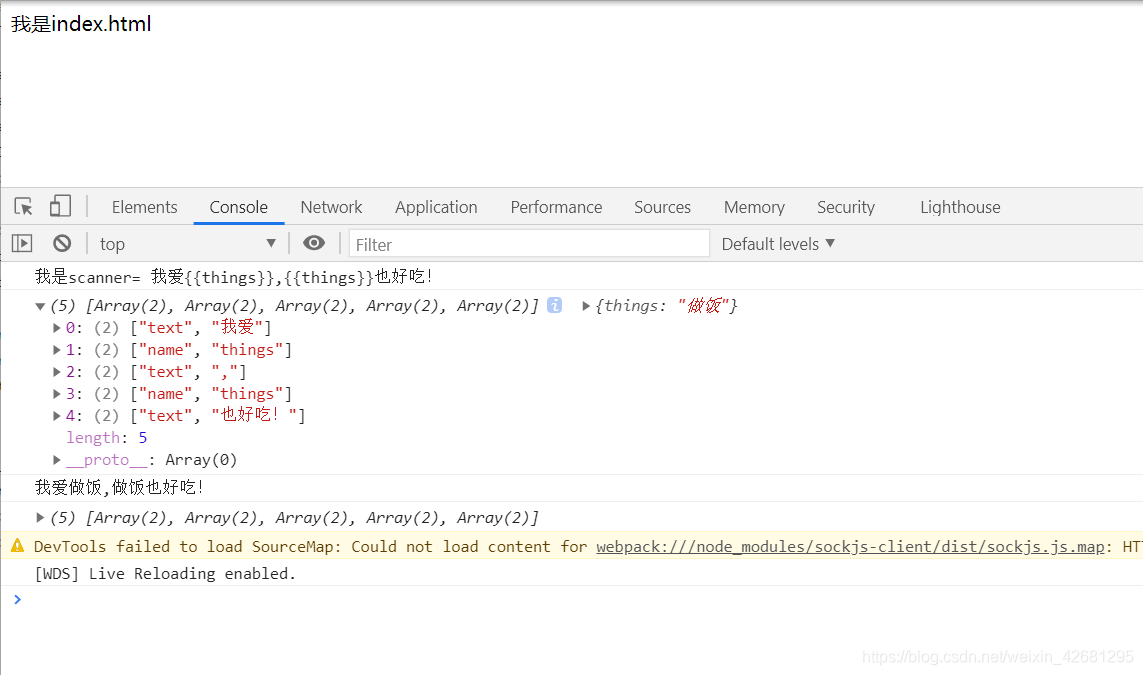
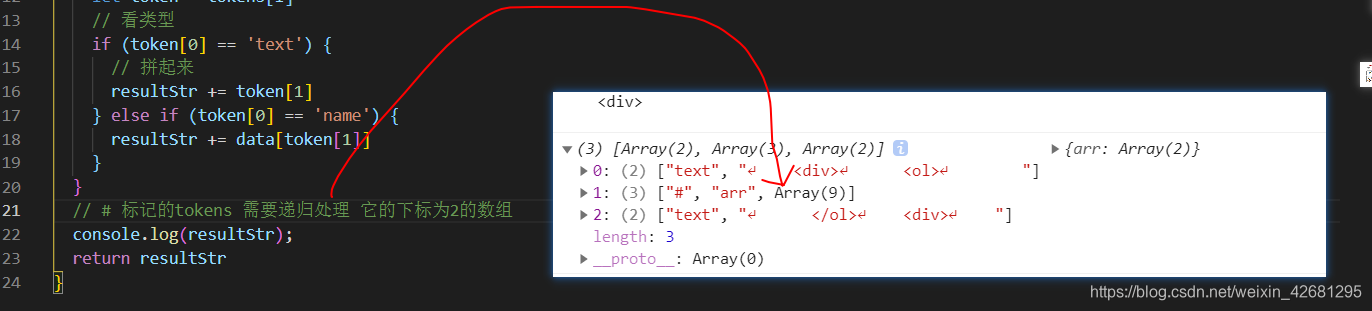
注意: # 标记的tokens 需要递归处理 它的下标为2的数组
遇见问题:不认识 . 符号 例如 a.b.c

lookup.js 在dataObj对象中,寻找用连续点符号的keyname属性
/** * * 功能是可以在dataObj对象中,寻找用连续点符号的keyname属性 * 比如 obj.a.b.c * { * a: { * b: { * c:100 * } * } * } * * 那么lookup (dataObj, 'a.b.c') 结果是100 * */ export default function lookup(dataObj, keyname) { console.log(dataObj, keyname); // 看看keyname 有没有点符号 但是不能是 . 本身 if (keyname.indexOf('.') !== -1 && keyname !== '.') { var keys = keyname.split('.') // 用这个temp变量作为中间值 临时变量 用于周转 , 一层一层去找 var temp = dataObj; // 每找一层设置为新的临时变量 for (let i = 0; i < keys.length; i++) { temp = temp[keys[i]]; } return temp } // 如果这里没有点符号 return dataObj[keyname]; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
parseArray.js 处理数组,结合renderTemplate实现递归
/** * * 处理数组,结合renderTemplate实现递归 * 注意 函数接收的是 token 而不是tokens * token 就是简单的 ['#', 'xxx',[]] * 这个函数要递归调用renderTemplate 函数 调用多少次 取决于 data 决定 * { arr:[ {name:'fqniu',age:'25',sex:'boy',hobbise:['游泳','健身']}, {name:'fqniu',age:'25',sex:'boy',hobbise:['游泳','健身']}, ] } 那么parseArray 函数就要调用renderTemplate 函数 2次 因为data数组长度为 2 * */ import lookup from './lookup' import renderTemplate from './renderTemplate'; export default function parseArray(token, data) { // console.log(token, data); // 得到整体数据中这个数组要使用的部分 var v = lookup(data, token[1]) // console.log('v=',v); var resultStr = '' // 遍历v数组,v 一定是数组 // 注意这个循环 是最难想到的 是遍历数据,不是遍历tokens, 数组中的数据有几个,就是遍历几条 for (let i = 0; i < v.length; i++) { // 这里要补充一个 . 的 属性 先添加一个. 属性 然后再展开 resultStr += renderTemplate(token[2], { ...v[i], '.':v[i], }) } return resultStr }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title> </head> <body> <div>我是index.html</div> <script src="/xuni/bundle.js"></script> <script> // var templateStr = `<h1>我今天很{{mood}},明天也一样{{mood}}</h1>` var templateStr = ` <div> <ol> {{#arr}} <li> <div>姓名:{{name}}</div> <div>年龄:{{age}}</div> <div>性别:{{sex}}</div> <ol> {{#hobbies}} <li>{{.}}</li> {{/hobbies}} </ol> </li> {{/arr}} </ol> <div> ` var data = { arr:[ {name:'fqniu',age:'25',sex:'boy',hobbies:['游泳','健身']}, {name:'niuniu',age:'19',sex:'boy1',hobbies:['游泳1','健身1']}, ] } var domStr = mt_templateEngine.render(templateStr,data) console.log(domStr); </script> </body> </html>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43

总结如下代码内容
/** * 扫描器类 * */ export default class Scanner { constructor(templateStr) { console.log('我是scanner=', templateStr); // 将模板字符串写到实例中 this.templateStr = templateStr // 指针 this.pos = 0 // 尾巴 一开始就是模板字符串的原文 this.tail = templateStr } // 功能弱,就是走过指定内容 ,没有返回值 scan(tag) { if (this.tail.indexOf(tag) == 0) { // tag有多长,比如{{长度为2,就让指针后移多少位 this.pos += tag.length; // 尾巴也要变, 改变尾巴,从当前指针这个字符开始,到最后全部字符 this.tail = this.templateStr.substring(this.pos) } } // 让指针进行扫描,直到遇见内容结束,并且能够返回结束之前路过的文字 scanUntil(stopTag) { // 记录一下执行方法的时候pos值 const pos_backup = this.pos; // 当尾巴不是stopTag的时候,就说明还没有扫描到stopTag // 这里的&& 防止找不到那么寻找到最后也要停止下来,死循环 while (!this.eos() && this.tail.indexOf(stopTag) !== 0) { this.pos++; // 改变尾巴,从当前指针这个字符开始,到最后全部字符 this.tail = this.templateStr.substring(this.pos) } return this.templateStr.substring(pos_backup, this.pos) } // eos 指针是否已经到头,返回布尔值 end of string eos(){ return this.pos >= this.templateStr.length } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
/** * nestTokens 函数是用于折叠tokens * 将 # 和 / 之间的tokens整合起来,作为下标为3的项 * */ export default function nestTokens(tokens) { // 结果数组 var nestedTokens = []; // 栈结构 存放小tokens ,栈顶(靠近端口的,最新进入的) 的tokens数组中当前操作的这个tokens小数组 var sections = [] // console.log(tokens); // 收集器 天生指向 nestedTokens结果数组,引用类型值,指向同一个数组 // 注意 收集器指向会变化 当遇见 # 收集器会指向这个token下标为2的新数组 var collector = nestedTokens for (let i = 0; i < tokens.length; i++) { let token = tokens[i]; switch (token[0]) { case '#': // // 给这个tokens下标为2的项创建一个数组,以收集子元素 // token[2] = [] // // 压栈 (入栈) // sections.push(token) // // console.log(token[1],'进栈'); // nestedTokens.push(token) // 收集器中放入token collector.push(token) // (入栈) sections.push(token) // 收集器换人, 给这个token添加下标为2的项,并且让收集器指向他 collector = token[2] = [] break; case '/': // // 弹栈 出栈 pop() 会返回弹出的项 // let section_pop = sections.pop() // // console.log(section[1],'出栈'); // // 刚刚弹出的项还没有加入到结果数组中 // nestedTokens.push(section_pop) // 出栈 pop() 会返回刚刚弹出的项 sections.pop() // 改变收集器为栈结构队尾(队尾是栈顶) 那项下标为2的数组 collector = sections.length > 0 ? sections[sections.length - 1][2] : nestedTokens break; default: // // 判断。栈队列当前情况 // if(sections.length == 0){ // nestedTokens.push(token) // }else{ // sections[sections.length -1][2].push(token) // } collector.push(token) } } return nestedTokens; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
import Scanner from './Scanner' import nestTokens from './nestTokens' /** * 将模板字符串变为tokens数组 */ export default function parseTemplateToToken(templateStr) { var tokens = [] // 创建扫描器 var scanner = new Scanner(templateStr) var words // 扫描器工作 while (!scanner.eos()) { // 收集开始标记出现之前的文字 words = scanner.scanUntil('{{') // 判断是否为空的情况 if (words !== '') { // 尝试写一下去掉空格,智能判断是普通文字的空格,还是标签中的空格 // 标签中的空格不能去掉,比如<div class="xxx"></div>中的空格不能去掉 // 是否是尖角号 let isInjjh = false; // 空白字符串 let _words = ''; for (let i = 0; i < words.length; i++) { // 判断是否在标签内 if (words[i] == '<') { isInjjh = true; } else if (words[i] == '>') { isInjjh = false; } // 如果不是空格,拼接上 if (!/\s/.test(words[i])) { _words += words[i]; } else { // 如果是空格,只有当他的标签内的时候,才拼接上 if (isInjjh) { _words += ' '; } } } // 存起来 去掉空格 tokens.push(['text', _words]) } // 过双大括号 scanner.scan('{{') // 收集开始标记出现之前的文字 words = scanner.scanUntil('}}') // 判断是否为空的情况 if (words !== '') { // 这个words就是{{}}中间的东西,判断一下首字符 if (words[0] == '#') { // 存起来,从下标为1的开始存,因为下标为0的是 # tokens.push(['#', words.substring(1)]) } else if (words[0] == '/') { // 存起来,从下标为1的开始存,因为下标为0的是 / tokens.push(['/', words.substring(1)]) } else { // 存起来 tokens.push(['name', words]) } } // 过双大括号 scanner.scan('}}') } // 返回折叠后的tokens return nestTokens(tokens) }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
/** * * 处理数组,结合renderTemplate实现递归 * 注意 函数接收的是 token 而不是tokens * token 就是简单的 ['#', 'xxx',[]] * 这个函数要递归调用renderTemplate 函数 调用多少次 取决于 data 决定 * { arr:[ {name:'fqniu',age:'25',sex:'boy',hobbise:['游泳','健身']}, {name:'fqniu',age:'25',sex:'boy',hobbise:['游泳','健身']}, ] } 那么parseArray 函数就要调用renderTemplate 函数 2次 因为data数组长度为 2 * */ import lookup from './lookup' import renderTemplate from './renderTemplate'; export default function parseArray(token, data) { // console.log(token, data); // 得到整体数据中这个数组要使用的部分 var v = lookup(data, token[1]) // console.log('v=',v); var resultStr = '' // 遍历v数组,v 一定是数组 // 注意这个循环 是最难想到的 是遍历数据,不是遍历tokens, 数组中的数据有几个,就是遍历几条 for (let i = 0; i < v.length; i++) { // 这里要补充一个 . 的 属性 先添加一个. 属性 然后再展开 resultStr += renderTemplate(token[2], { ...v[i], '.':v[i], }) } return resultStr }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
/** * * 功能是可以在dataObj对象中,寻找用连续点符号的keyname属性 * 比如 obj.a.b.c * { * a: { * b: { * c:100 * } * } * } * * 那么lookup (dataObj, 'a.b.c') 结果是100 * */ export default function lookup(dataObj, keyname) { // console.log(dataObj, keyname); // 看看keyname 有没有点符号 但是不能是 . 本身 if (keyname.indexOf('.') !== -1 && keyname !== '.') { var keys = keyname.split('.') // 用这个temp变量作为中间值 临时变量 用于周转 , 一层一层去找 var temp = dataObj; // 每找一层设置为新的临时变量 for (let i = 0; i < keys.length; i++) { temp = temp[keys[i]]; } return temp } // 如果这里没有点符号 return dataObj[keyname]; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
/** * 函数的功能是让tokens 数组变为dom字符串 * */ import lookup from './lookup' import parseArray from './parseArray' export default function renderTemplate(tokens, data) { // console.log(tokens, data); // 结果字符串 var resultStr = '' // 循环tokens for (let i = 0; i < tokens.length; i++) { let token = tokens[i] // 看类型 if (token[0] == 'text') { // 拼起来 resultStr += token[1] } else if (token[0] == 'name') { // 如果是name 类型 直接使用它的值 当然要用lookup函数 防止a.b.c形式取值为 undefined resultStr += lookup(data, token[1]) }else if (token[0] == '#') { // # 标记的tokens 需要递归处理 它的下标为2的数组 resultStr += parseArray(token, data) } } return resultStr; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title> </head> <body> <div>我是index.html</div> <script src="/xuni/bundle.js"></script> <script> var templateStr = ` <div> <ol> {{#arr}} <li class="item"> <div>姓名:{{name}}</div> <div>年龄:{{age}}</div> <div>性别:{{sex}}</div> <ol> {{#hobbies}} <li>{{.}}</li> {{/hobbies}} </ol> </li> {{/arr}} </ol> <div> ` var data = { arr:[ {name:'fqniu',age:'25',sex:'boy',hobbies:['游泳','健身']}, {name:'niuniu',age:'19',sex:'boy1',hobbies:['游泳1','健身1']}, ] } var domStr = mt_templateEngine.render(templateStr,data) console.log(domStr); </script> </body> </html>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
具体的可百度 mustache相关认识点 或 查看mustache 源码写法mustache.js
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/菜鸟追梦旅行/article/detail/610750
推荐阅读
相关标签

