
- 1离线程序激活功能实现思路第二版(ts实现)_离线激活原理
- 2CSDN可以修改发帖内容吗_csdn 发布文章后没办法修改嘛
- 3Flutter run卡在Running Gradle task assembleDebug_running gradle task 'assembledebug'... 大约 多长时间
- 4【Python学习】常用函数(更新中……)
- 5大模型llm:Ollama部署llama3学习入门llm_ollama 3模型
- 6MATLAB知识点:矩阵的重构和重新排列_matlab reshape
- 7用于高质量目标检测的 Rank-DETR
- 8基于HTML+CSS+JavaScript制作学生网页——外卖服务平台10页带js 带购物车_外卖网站制作
- 9Mysql分库分表方案_mysql subpartition by hash
- 10IDEA—右边maven模块不见了_项目中没有pom文件
AIGC应用:Stable diffusion webui基本使用技巧_stable diffusion webui 采样方法 (sampler)
赞
踩
前言
Stable diffusion相信很多技术爱好者都了解,并且也尝试用过,目前在各路开源大佬的支持下,Stable diffusion的生图piepline越来越成熟,同时在各种新技术的加持下,可玩性越来越高。相比我以往的理论性文章,该系列文章主要讲解一下SD web ui的具体使用,以及一些拓展功能的使用,同时对自己应用SD有一个记录。
一、Stable Diffusion Web UI 安装
github:https://github.com/AUTOMATIC1111/stable-diffusion-webui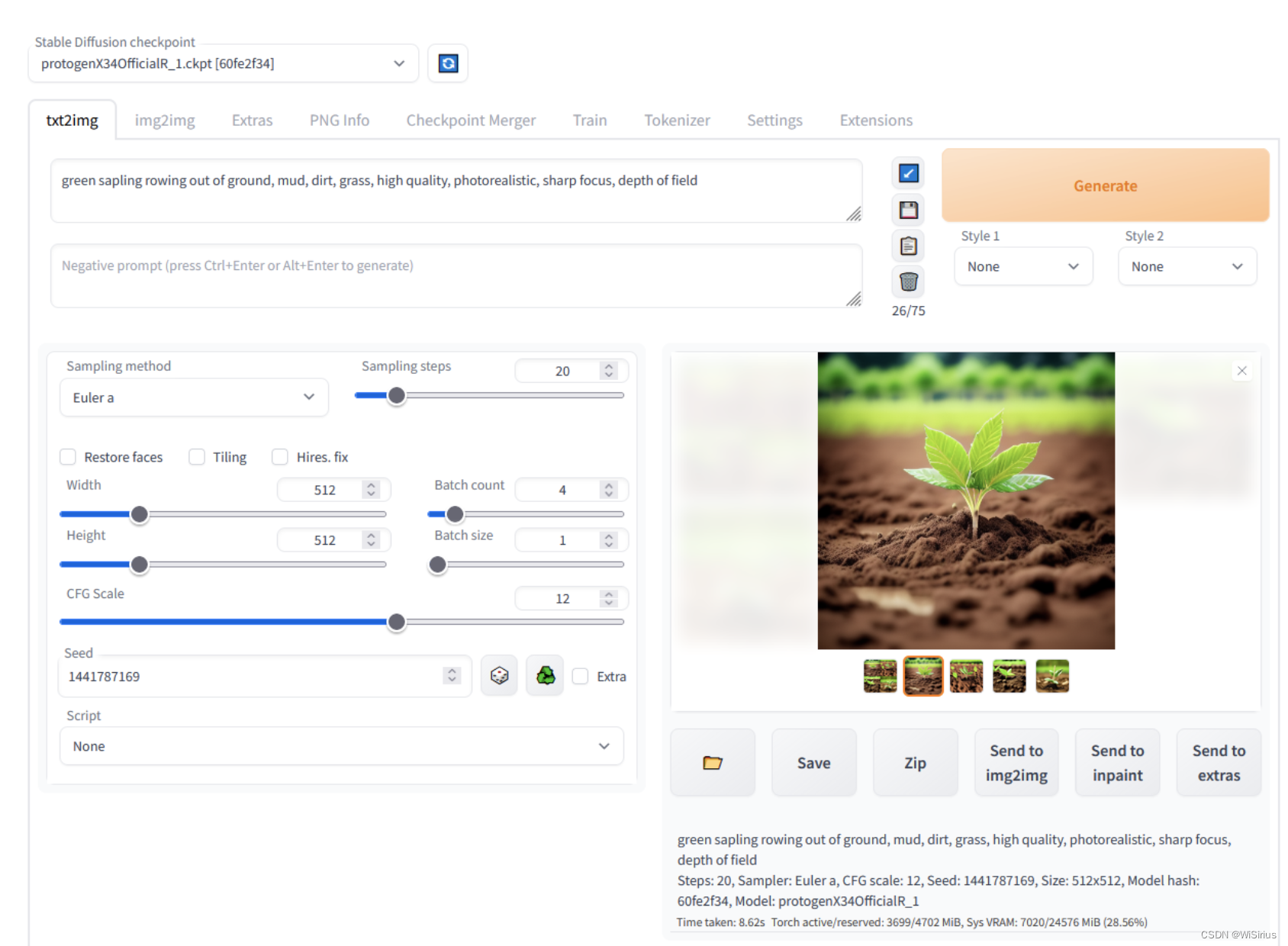
相信很多技术人应该不用我去教如何在终端搭建这个环境,为了避免安装中途出现错误可以科学上网。
对于一些计小白,可以安装一些大佬们封装好的安装包,直接使用即可(可以去b站上搜一下Stable diffusion安装教程,一般会有大佬发一些安装包链接,下载安装即可,主要注意一下模型存放目录位置就好了,能启动就ok)
二、泡泡玛特(prompt)
提示词直接决定了文本编码,文本编码直接影响了生成图像的质量,对于没有什么灵感的新手,可以参考civitai网站的一些提示词编排和对应生成的图像。
也可以去看一下词缀表获得灵感,**SD的文本编码使用的是CLIP,一般每个独立的diffusion模型有经过微调的专用CLIP模型权重,因此每个diffusion模型有些其独特的词汇,但是对于通用词汇差别不大。同样的,对于一些lora模型可能也包含了CLIP的权重,需要输入特定的词汇才能触发lora效果。**下面列出了一些词缀表网站:
prompt tool:https://prompttool.com/home/NovelAI
tag大全:https://www.wujieai.com/tag-generator/tags
另外,这里推荐一个tag自动补齐插件(教学视频):
https://www.bilibili.com/video/BV14Y4y1D7vR/?vd_source=97898b168f3bb650e9d9bf8c75304b94
以下是一些常用的提示词:
1)提升图像质量的正向提示词:

2)艺术风格相关提示词:

3)反向提示词:

这里列举了一些常用提示词,其它提示词还需要各位自己挖掘!!!
三、txt输入规则
若是想突出生成图像的某个特点,应当使其生成步骤向前,生成步骤数加大,词缀排序向前,权重提高。画面质量 → 主要元素 → 细节
若是想明确风格,则风格词缀应当优于内容词缀画面质量 → 风格 → 元素 → 细节
对于人物细节来说,尽量从上到下依次描述,比如优先描述面部特征,发色等,再描述身体状态,衣服,最后描述衣服等特征,避免有些词汇会污染人物特征(怀疑训练数据的prompt是这样子描述的)。
逗号:分割词缀,有一定权重排序功能,逗号前权重高,逗号后权重低,因而建议排序:
综述(图像质量+画风+镜头效果+光照效果+主题+构图)
主体(人物&对象+姿势+服装+道具)(姿势和服装可以自己订哪个优先)
细节(场景+环境+饰品+特征)
1)词汇权重:(girl:0.75) 表示对girl编码进行0.75倍加权; (girl) 表示对girl编码进行1.1倍加权—一组括号提升0.1倍;{girl} 表示对girl编码进行1.05倍加权—一组中括号提升0.05倍
词汇权重技巧:先把要描述的画面写下生成一次,根据生成结果边试边改不满意或遗漏的描述,要强调的概念用 (xxx: 1.x ) 语法形式来提升权重,其中 xxx 是你要强调的词,1.x 代表要提升的比例,如 1.5 就是提升 150% 的权重。权重取值范围 0.4-1.6,权重太小容易被忽视,太大容易拟合图像出错。
2)连接符:
and: bird and dog and pig ; bird:1.5 and dog:1.2 and pig:0.8
加号➕:(red hair:1.1)+(yellow hair:1.25)+(green hair:1.4)
竖线|;下划线 _ ; 逗号 ,
这些符号都可以用来作为连接符,常用的就是逗号
这些规则对于句子同样有效!
举个例子:
8k portrait of beautiful cyborg with brown hair, intricate, elegant, highly detailed, majestic, digital photography, art by artgerm and ruan jia and greg rutkowski surreal painting gold butterfly filigree, broken glass, (masterpiece, sidelighting, finely detailed beautiful eyes: 1.2), hdr, (detailed background window to a new dimension, plants and flowers:0.7) , infinity, infinite symbol,

四、交替渲染
[] 方括号中使用:、| 等符号,则可实现交替渲染的效果。
(PS 交替渲染仅在某些checkpoint有作用,有些SD模型没有效果)
1、[A:B:step][元素1:元素2:步骤比例] :渲染元素1到多少进度后开始渲染元素2,实现元素1与元素2的互相叠加,比如渲染蓝色到40%进度后,开始渲染红色[blue:red:0.4],或者前12步渲染蓝色后,开始渲染红色[blue:red:12]
2、[A:step][元素1:步骤比例]:表示从多少进度开始渲染元素1,同样可使用上面的比例或者步数来表示。
3、[A::step][元素1::步骤比例]:渲染到多少进度的时候停止元素1的渲染
4、[A|B][元素1|元素2]:元素1和元素2的交替混合渲染;比如 [blue|red] 可融合蓝色和红色,[cat|dog] 可生成猫和狗的融合生物。可融合多个元素[xx|xx|xx|…]。
5、[A|B]C[元素1|元素2]元素3:括号外加词缀意味着融合过程中的共享元素。
五、Lora模型调用
使用lora模型前,首先确保lora模型存在于stable-diffusion-webui/stable-diffusion-webui/models/Lora文件夹中,可以在页面中查看。
输入:lora:filename:multiplier 即可调取相应模型。
六、Hypernetwork & Embeding
Hypernetwork 和 embedding 和 Lora 模型一样,也属于一种模型微调技术(关于Lora是如何微调模型的,感兴趣的同学可以参考我之前的博客 —— 图像生成:SD LoRA模型详解)。
这里简单说一下超网的原理,如下图,它是一个附加到Stable Diffusion模型的小型神经网络,用于修改其风格,通过插入两个小网络来转换键向量和查询向量:
嵌入(Embeding)是一种称为文本反转的微调方法的结果。与超网络一样,文本反演不会改变模型。它只是定义新的关键字来实现某些样式。文本反演和超网络适用于稳定扩散模型的不同部分。文本反转在文本编码器中创建新的嵌入。超网络将一个小型网络插入噪声预测器的交叉注意模块中。根据经验,嵌入比超网络稍微强大一些。
Hypernetwork & Embeding使用方式和lora的使用一样,与lora的区别在于,lora实际上是改变了原本SD模型的权重,而这两种没有,只是在原模型基础上插入了新的模块。
七、采样器(sampler)选择
webui中集成了多种采样器,采样器是生成模型中最重要的部分,也是SD中理论性最强的一部分,涉及到的数学运算最多,这里不做详细描述,只是简单介绍一下不同采样器的特点。
1)经典ODE求解器
Euler:欧拉采样方法,简单快速。
Heun:欧拉方法的改进版本,更准确但稍慢。
LMS:线性多步法,速度与欧拉相近但更准确。
2)祖先采样器
这类采样器会在每个步骤中添加噪声,具有一定随机性。如Euler a ;DPM2 a ; DPM++2S a
3)DDIM和PLMS(已过时)
DDIM:去噪扩散隐式模型的采样器。
PLMS:DDIM的更快速替代品。
4)DPM和DPM++系列
DPM:自适应调整步长,速度可能较慢,对Tag的利用率高。
DPM++:二阶方法,结果更准确但较慢。
5)UniPC采样器
2023年发布,速度快,可在5-10步内生成高质量图像。
6)K-diffusion采样器
大部分采样器来自K-diffusion,具有较高的准确性和速度平衡。
7)LCM采样器
前段时间大火的超快出图的采样器,需要配合对应SD的lora使用。
下面对部分采样器进行详细介绍:
Euler a:在每个步骤中减去更多的噪声,具有一定的随机性。
Euler:简单的采样器,通过噪声计划减少噪声。
LMS:标准的线性多步法,速度与欧拉相近。
Heun:Euler的改进版本,更精确但较慢。
DPM2:采用DPM-Solver-2算法,速度受参数影响。
DPM2 a:祖先采样器,使用DPM2方法,受参数影响。
DPM++2S a:随机采样器,二阶方法,受参数影响。
DPM++2M:K-diffusion中的多步方法,速度与质量平衡。
DPM++SDE:DPM++的SDE版本,受参数影响。
DPM fast:固定步长的采样器,用于步数较少情况。
DPM adaptive:自适应步长的采样器,受参数影响。
Karras字样的6种采样器:基于Karras噪声时间表的版本。
DDIM:使用去噪后的图像近似最终图像,速度较快。
PLMS:DDIM的新版且更快速的替代品。
UniPC:最新采样器,快速生成高质量图像。
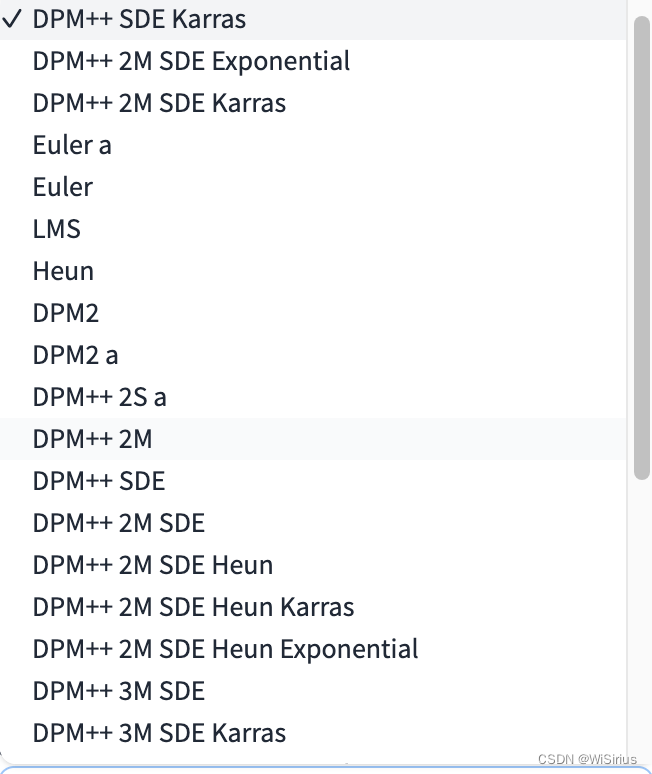
根据不同的需求和优先考虑因素,可以选择不同的采样方法:
快速生成质量不错的图片:选择DPM++ 2M Karras(20-30步)或UNIPC(15-25步)。
追求高质量图像:选择DPM++ SDE Karras(10-15步,较慢)或DDIM(10-15步,较快)。
希望生成简单图像:选择Euler、Heun(可以减少步骤以节省时间)。
追求稳定可重现的图像:避免选择祖先采样器。
追求变化多样的图像:选择不收敛的祖先采样器。
下面两张图分别是用DPM++ 和 Eluer 采样器生成的图像,可以发现DPM++的生成的细节更丰富,Euler生成的图像更简洁。


对于civitai中一些checkpoint可以看一下作者选用的什么采样器,选择相同采样器即可。
八、CFG scale
CFG Scale用来衡量提示词对生成结果的影响程度。 在图像生成过程中,模型会根据给定的提示词来生成相应的图像。 CFG Scale的值越高,提示词对最终生成结果的影响就越大,也就是说生成的图像更加符合提示词的要求。一般情况下默认0.7就好(太大大小都有可能会崩坏)。
九、上采样模型
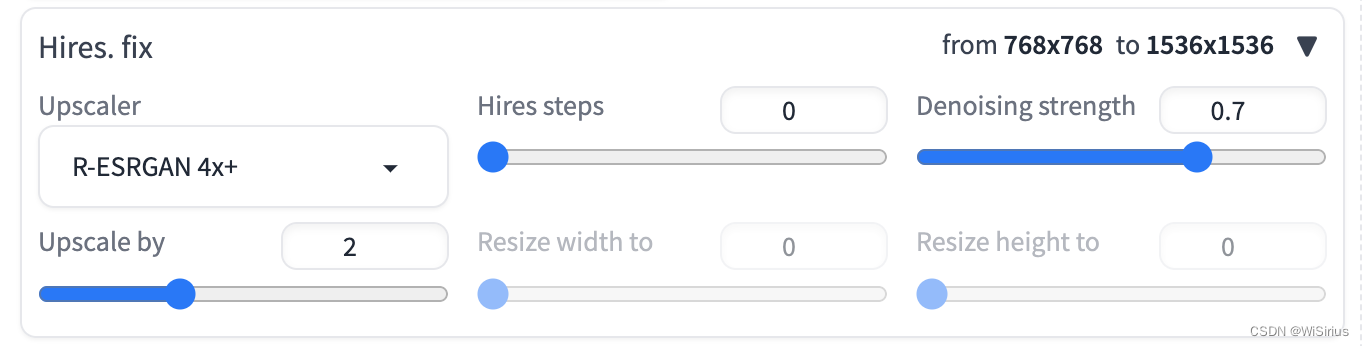
webui中有一项hires. fix 选项,这部分主要是上采样操作(超分辨率),因为SD由于模型本身较大,生成的图像通常分辨率不大,可以通过上采样器进行分辨率提升,这些上采样器都是近几年比较有名的超分恢复模型,使用前需要把模型文件下载好,然后放在对应文件夹中。
十、SD缺点
SD的主要缺点在于其对于图像中的高频信息很难生成,主要情况如下:
1、仅用文字描述同一场景多人物,很难成功生图
2、对于全身图来说,面部容易出现崩坏
3、手部 腿部 脚部等细节无法很好生成
4、文字生成效果差
总结
这部分内容主要是使用SD的一些基础技巧。
SD webui目前的插件越来越多,玩法也越来越多,后面我会继续更新相关使用技巧和内容。

