
- 1一级造价工程师(安装)- 案例笔记_不平衡报价一定要控制在合理幅度内,为避免引起业主反对,一般可在()以内
- 2SpringBoot 解决跨域问题的 5 种方案!_springboot跨域配置
- 3RtspServer实现及使用_rtsp server
- 4Hive on Spark环境搭建_hive on spark配置
- 5Kubernetes学习之路(十)之资源清单定义_matchexpressions
- 6最全python+django飞机航班查询推荐订票系统,2024年最新Python面试题生命周期
- 7使用MinIO S3存储桶备份Weaviate_weaviate 内存管理
- 8JavaEE--------MyBatis框架_javamybatis框架
- 9五万字总结,深度学习基础。,2024年阿里Python岗面试必问_深度学习面试
- 10【中文Llama-3】Chinese-LLaMA-Alpaca-3开源大模型项目正式发布
mmap内核实现及物理内存组织结构_mmap在哪个内核文件实现
赞
踩
主要参考了《深入linux内核》和《Linux内核深度解析》,另外简单浅析了一下相关内容
mmap内核实现及物理内存组织结构
虚拟内存区域使用起始地址和结束地址描述,链表按起始地址递增排序。两系统调用区别: mmap指定的偏移的单位是字节,而mmap2指定的偏移的单位是页。ARM64架构实现系统调用mmap。
系统调用mmap
系统调用mmap用来创建内存映射,把创建内存映射主要工作委托给do_mmap函数,内核源码文件处理:
mm/mmap.c
#define SYSCALL_DEFINE1(name, …) SYSCALL_DEFINEx(1, _##name, VA_ARGS)
#define SYSCALL_DEFINE2(name, …) SYSCALL_DEFINEx(2, _##name, VA_ARGS)
#define SYSCALL_DEFINE3(name, …) SYSCALL_DEFINEx(3, _##name, VA_ARGS)
#define SYSCALL_DEFINE4(name, …) SYSCALL_DEFINEx(4, _##name, VA_ARGS)
#define SYSCALL_DEFINE5(name, …) SYSCALL_DEFINEx(5, _##name, VA_ARGS)
#define SYSCALL_DEFINE6(name, …) SYSCALL_DEFINEx(6, _##name, VA_ARGS)
#define SYSCALL_DEFINEx(x, sname, …) \
SYSCALL_METADATA(sname, x, VA_ARGS) \
__SYSCALL_DEFINEx(x, sname, VA_ARGS)
sys_mmap
SYSCALL_DEFINE1(old_mmap, struct mmap_arg_struct __user *, arg)
{
struct mmap_arg_struct a;
if (copy_from_user(&a, arg, sizeof(a)))
return -EFAULT;
if (offset_in_page(a.offset)) // 检查是不是整数倍
return -EINVAL;
return sys_mmap_pgoff(a.addr, a.len, a.prot, a.flags, a.fd,
a.offset >> PAGE_SHIFT);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
sys_mmap_pgoff
SYSCALL_DEFINE6(mmap_pgoff, unsigned long, addr, unsigned long, len, unsigned long, prot, unsigned long, flags, unsigned long, fd, unsigned long, pgoff) { struct file *file = NULL; unsigned long retval; if (!(flags & MAP_ANONYMOUS)) { audit_mmap_fd(fd, flags); file = fget(fd); if (!file) return -EBADF; if (is_file_hugepages(file)) len = ALIGN(len, huge_page_size(hstate_file(file))); retval = -EINVAL; if (unlikely(flags & MAP_HUGETLB && !is_file_hugepages(file))) goto out_fput; } else if (flags & MAP_HUGETLB) { struct user_struct *user = NULL; struct hstate *hs; hs = hstate_sizelog((flags >> MAP_HUGE_SHIFT) & MAP_HUGE_MASK); if (!hs) return -EINVAL; len = ALIGN(len, huge_page_size(hs)); /* * VM_NORESERVE is used because the reservations will be * taken when vm_ops->mmap() is called * A dummy user value is used because we are not locking * memory so no accounting is necessary */ file = hugetlb_file_setup(HUGETLB_ANON_FILE, len, VM_NORESERVE, &user, HUGETLB_ANONHUGE_INODE, (flags >> MAP_HUGE_SHIFT) & MAP_HUGE_MASK); if (IS_ERR(file)) return PTR_ERR(file); } flags &= ~(MAP_EXECUTABLE | MAP_DENYWRITE); retval = vm_mmap_pgoff(file, addr, len, prot, flags, pgoff); out_fput: if (file) fput(file); return retval; }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48

系统调用munmap
系统调用munmap用来删除 内存映射,它有两个参数:起始地址 和长度即可。它的主要工作委托给内 核源码文件处理“mm/mmap.c”当 中的函数do_munmap。

如上图的9个项
1、vma = find_vma(mm, start); //根据起始地址找到要删除的第一个虚拟内存区域vma
2、如果只删除虚拟内存区域vma的部分,那么分裂虚拟内存区域vma
3、根据结束地址找到要删除的最后一个虚拟内存区域vma
4、如果只删除虚拟内存区域last的一部分,那么分裂虚拟内存区域vma
5、针对所有删除目标,如果虚拟内存区域被锁定在内存中(不允许换出到交换区 (swap) ),同用函数解除锁定。
6、调用此函数,把所有删除目标从进程虚拟内存区域链表和树中删除,单独组成一条临时的链表。
7、调用此函数,针对所有删除目标,在进程的页表中删除映射,并且从处理器的页表缓存(tlb_gather_mmu)中删除映射。
8、调用此函数执行处理器架构特定的处理操作。
9、调用此函数,删除所有目标。
/* Munmap is split into 2 main parts -- this part which finds * what needs doing, and the areas themselves, which do the * work. This now handles partial unmappings. * Jeremy Fitzhardinge <jeremy@goop.org> */ int do_munmap(struct mm_struct *mm, unsigned long start, size_t len, struct list_head *uf) { unsigned long end; struct vm_area_struct *vma, *prev, *last; if ((offset_in_page(start)) || start > TASK_SIZE || len > TASK_SIZE-start) return -EINVAL; len = PAGE_ALIGN(len); if (len == 0) return -EINVAL; /* Find the first overlapping VMA */ vma = find_vma(mm, start); if (!vma) return 0; prev = vma->vm_prev; /* we have start < vma->vm_end */ /* if it doesn't overlap, we have nothing.. */ end = start + len; if (vma->vm_start >= end) return 0; if (uf) { int error = userfaultfd_unmap_prep(vma, start, end, uf); if (error) return error; } /* * If we need to split any vma, do it now to save pain later. * * Note: mremap's move_vma VM_ACCOUNT handling assumes a partially * unmapped vm_area_struct will remain in use: so lower split_vma * places tmp vma above, and higher split_vma places tmp vma below. */ if (start > vma->vm_start) { int error; /* * Make sure that map_count on return from munmap() will * not exceed its limit; but let map_count go just above * its limit temporarily, to help free resources as expected. */ if (end < vma->vm_end && mm->map_count >= sysctl_max_map_count) return -ENOMEM; error = __split_vma(mm, vma, start, 0); if (error) return error; prev = vma; } /* Does it split the last one? */ last = find_vma(mm, end); if (last && end > last->vm_start) { int error = __split_vma(mm, last, end, 1); if (error) return error; } vma = prev ? prev->vm_next : mm->mmap; /* * unlock any mlock()ed ranges before detaching vmas */ if (mm->locked_vm) { struct vm_area_struct *tmp = vma; while (tmp && tmp->vm_start < end) { if (tmp->vm_flags & VM_LOCKED) { mm->locked_vm -= vma_pages(tmp); munlock_vma_pages_all(tmp); } tmp = tmp->vm_next; } } /* * Remove the vma's, and unmap the actual pages */ detach_vmas_to_be_unmapped(mm, vma, prev, end); unmap_region(mm, vma, prev, start, end); arch_unmap(mm, vma, start, end); /* Fix up all other VM information */ remove_vma_list(mm, vma); return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
/* * Get rid of page table information in the indicated region. * * Called with the mm semaphore held. */ static void unmap_region(struct mm_struct *mm, struct vm_area_struct *vma, struct vm_area_struct *prev, unsigned long start, unsigned long end) { struct vm_area_struct *next = prev ? prev->vm_next : mm->mmap; struct mmu_gather tlb; lru_add_drain(); tlb_gather_mmu(&tlb, mm, start, end); update_hiwater_rss(mm); unmap_vmas(&tlb, vma, start, end); free_pgtables(&tlb, vma, prev ? prev->vm_end : FIRST_USER_ADDRESS, next ? next->vm_start : USER_PGTABLES_CEILING); tlb_finish_mmu(&tlb, start, end); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
物理内存组织结构
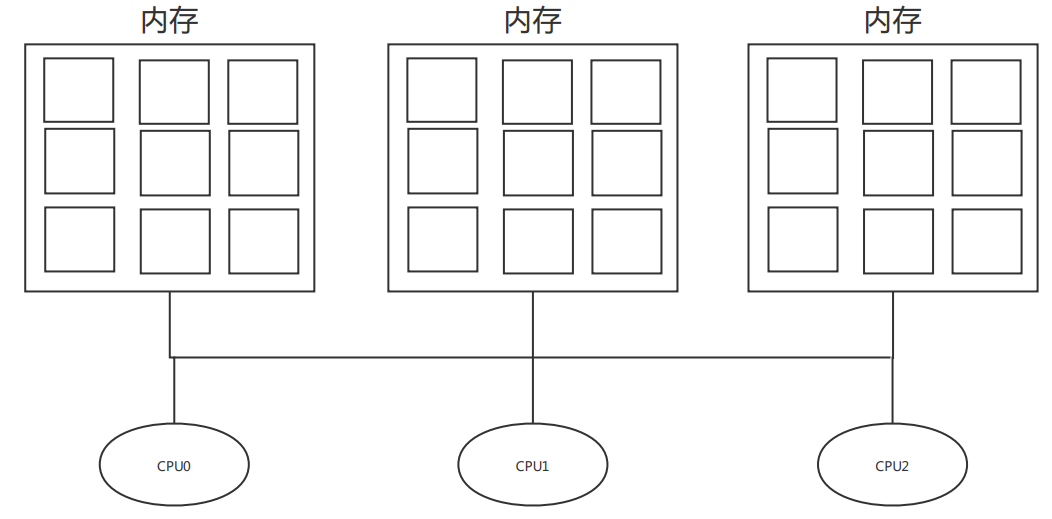
体系结构 NUMA / UMA
目前多处理器系统有两种体系结构:
1)非一致内存访问(Non-Unit Memory Access,NUMA):指内存被划分成多个内存节点的多处理器系统。访问一个内存节点花费的时间取决于处理器和内存节点的距离。
NUMA系统 每个CPU都有本地内存,可支持特别快速的访问。各个CPU之间通过总结连接起 来,以支持对其他CPU的本地内存访问,当然比访问本地内存要慢一点。
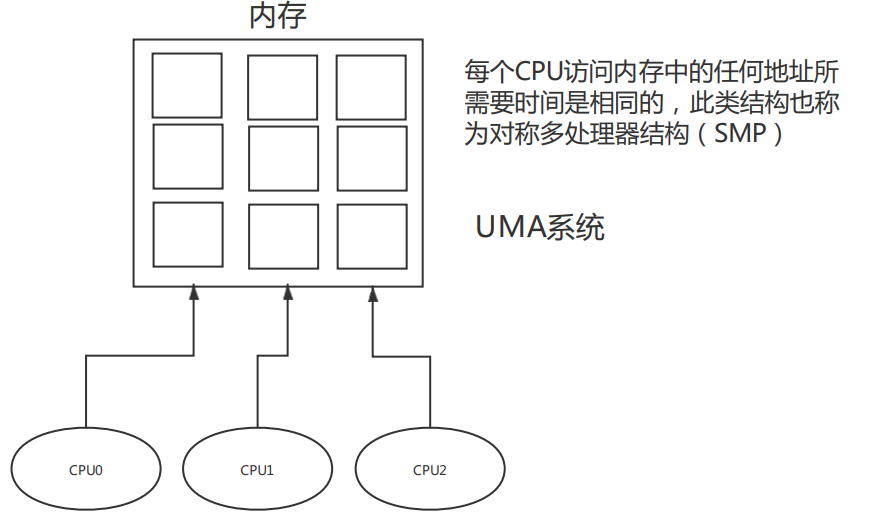
2)对称多处理器(Symmetric Multi-Processor,SMP):即一致内存访问(Uniform Memory Access,UMA),所有处理器访问内存花费的时间是相同。
内存模型(物理内存分布)
内存模型是从处理器角度看到的物理内存分布,内核管理不同内存模型的方式存差异。
内存管理子系统支持3种内存模型:
1)平坦内存(Flat Memory):内存的物理地址空间是连续的,没有空洞。
2)不连续内存(Discontiguous Memory):内存的物理地址空间存在空洞,这种模型可以高效地处理空洞。
3)稀疏内存(Space Memory):内存的物理地址空间存在空洞,如果要支持内存热插拔,只能选择稀疏内存模型。
什么情况会出现内存的物理地址空间存在空洞?
- 系统包含多块物理内存,两块内存的物理地址空间之间存在空洞。一块内存的物理地址空间也可能存在空洞,可以查看处理器的参考手册获取分配给内存的物理地址空间。
如果内存的物理地址空间是连续的,不连续内存模型会产生额外的开销,降低性能,所以平坦内存模型是更好的选择。如果内存的物理地址空间存在空洞,应该选择哪种内存模型?
- 平坦内存模型会为空洞分配page结构体,浪费内存;而不连续内存模型对空洞做了优化处理,不会为空洞分配page结构体。和平坦内存模型相比,不连续内存模型是更好的选择。
稀疏内存模型是实验性的,尽量不要选择稀疏内存模型,除非内存的物理地址空间很稀疏,或者要支持内存热插拔。其他情况应该选择不连续内存模型。
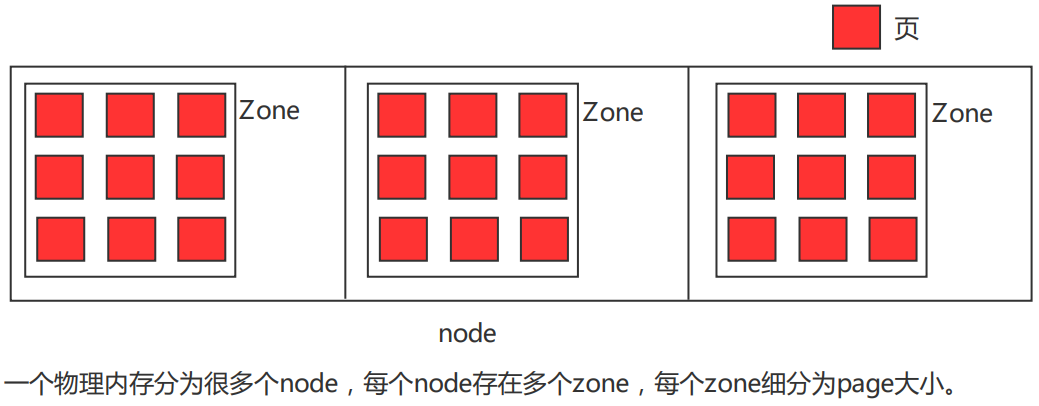
三级结构(物理内存划分)
内存管理子系统使用节点(node)、区域(zone)和页(page)三级结构描述物理内存。
一个物理内存分为很多个node,每个node存在多个zone,每个zone细分为page大小。
内存节点 struct pglist_data
内存节点分为两种情况:
(1)NUMA体系的内存节点,根据处理器和内存的距离划分内存节点;
(2)在具有不连续内存的UMA系统中,表示比区域的级别更高的内存区域,根据物理地址是否连续划分,每块物理地址连续的内存是一个内存节点。
include/linux/mmzone.h
- node_mem_map此成员指向页描述符数组,每个物理页对应一个页描述符。
- Node是内存管理最顶层的结构,在NUMA架构下,CPU平均划分为多个Node,每个Node有自己的内存控制器及内存插槽。
- CPU访问自己Node上内存速度快,而访问其他CPU所关联Node的内存速度慢。UMA被当做只一个Node的NUMA系统。
typedef struct pglist_data { struct zone node_zones[MAX_NR_ZONES]; // 内存区域数组 struct zonelist node_zonelists[MAX_ZONELISTS]; // 备用区域列表 int nr_zones; // 该节点包含的内存区域数量 #ifdef CONFIG_FLAT_NODE_MEM_MAP /* means !SPARSEMEM */ struct page *node_mem_map; // 页描述符数组 #ifdef CONFIG_PAGE_EXTENSION struct page_ext *node_page_ext; // 页的扩展属性 #endif #endif ... unsigned long node_start_pfn; // 该节点的起始物理页号 unsigned long node_present_pages; /// 物理页的总数 unsigned long node_spanned_pages; // 物理页的总长度,包括空洞 int node_id; // 节点标识符 ... } pg_data_t;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
内存区域 struct zone
内存节点被划分为内存区域
include/linux/mmzone.h
内核定义的区域类型
enum zone_type { #ifdef CONFIG_ZONE_DMA ZONE_DMA, #endif #ifdef CONFIG_ZONE_DMA32 ZONE_DMA32, #endif ZONE_NORMAL, #ifdef CONFIG_HIGHMEM ZONE_HIGHMEM, #endif ZONE_MOVABLE, #ifdef CONFIG_ZONE_DEVICE ZONE_DEVICE, #endif __MAX_NR_ZONES };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- DMA区域(ZONE_DMA):DMA是“Direct Memory Access”的缩写,意思是直接内存访问。如果有些设备不能直接访问所有内存,需要使用DMA区域。
例如旧的工业标准体系结构(Industry Standard Architecture,ISA)总线只能直接访问16MB以下的内存。 - DMA32区域(ZONE_DMA32):64位系统,如果既要支持只能直接访问16MB以下内存的设备,又要支持只能直接访问4GB以下内存的32位设备,
那么必须使用DMA32区域。 - 普通区域(ZONE_NORMAL):直接映射到内核虚拟地址空间的内存区域,直译为“普通区域”,意译为“直接映射区域”或“线性映射区域”。
内核虚拟地址和物理地址是线性映射的关系,即虚拟地址 =(物理地址 + 常量)。是否需要使用页表映射?不同处理器的实现不同,例如ARM处理器
需要使用页表映射,而MIPS处理器不需要使用页表映射。 - 高端内存区域(ZONE_HIGHMEM):这是32位时代的产物,内核和用户地址空间按1 : 3划分,内核地址空间只有1GB,不能把1GB以上的内存直接
映射到内核地址空间,把不能直接映射的内存划分到高端内存区域。通常把DMA区域、DMA32区域和普通区域统称为低端内存区域。64位系统的内核
虚拟地址空间非常大,不再需要高端内存区域。 - 可移动区域(ZONE_MOVABLE):它是一个伪内存区域,用来防止内存碎片,后面讲反碎片技术的时候具体描述。
- 设备区域(ZONE_DEVICE):为支持持久内存(persistent memory)热插拔增加的内存区域。
每个内存区域使用一个zone结构体描述,如下为主要成员
struct zone { /* Read-mostly fields */ /* zone watermarks, access with *_wmark_pages(zone) macros */ unsigned long watermark[NR_WMARK]; // 页分配器使用的水线 unsigned long nr_reserved_highatomic; long lowmem_reserve[MAX_NR_ZONES]; // 页分配器使用,当前区域保留多少页不能借给高的区域类型 #ifdef CONFIG_NUMA int node; #endif struct pglist_data *zone_pgdat; // 指向内存节点的pglist_data实例 struct per_cpu_pageset __percpu *pageset; // 每个处理器页集合 #ifndef CONFIG_SPARSEMEM /* * Flags for a pageblock_nr_pages block. See pageblock-flags.h. * In SPARSEMEM, this map is stored in struct mem_section */ unsigned long *pageblock_flags; // 当前区域的起始物理页号 #endif /* CONFIG_SPARSEMEM */ /* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT */ unsigned long zone_start_pfn; unsigned long managed_pages; // 伙伴分配器管理的物理页的数量 unsigned long spanned_pages; // 当前区域跨越的总页数,包括空洞 unsigned long present_pages; // 当前区域存在的物理页的数量,不包括空洞 const char *name; // 区域名称 #ifdef CONFIG_MEMORY_ISOLATION /* * Number of isolated pageblock. It is used to solve incorrect * freepage counting problem due to racy retrieving migratetype * of pageblock. Protected by zone->lock. */ unsigned long nr_isolate_pageblock; #endif #ifdef CONFIG_MEMORY_HOTPLUG /* see spanned/present_pages for more description */ seqlock_t span_seqlock; #endif int initialized; /* Write-intensive fields used from the page allocator */ ZONE_PADDING(_pad1_) /* free areas of different sizes */ struct free_area free_area[MAX_ORDER]; // 不同长度的空闲区域 ...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
物理页 struct page
每个物理页对应一个page结构体,称为页描述符,内存节点的pglist_data实例的成员node_mem_map指向该内存节点包含的所有物理页的页描述符组成的数组。
-
页是内存管理当中的最小单位,页面中的内存其物理地址是连续的,每个物理页由struct page描述。为了节省内存,struct page 是个联合体(共用体)。
-
页,又称为页帧,在内核当中,内存管理单元MMU(负责虚拟地址和物理地址转换的硬件)是把物理页page作为内存管理的基本单位。体系结构不同,支持的页大小也相同。
32位体系结构支持4kb的页
64位体系结构支持8kb的页
MIPS64架构体系支持16kb的页
include/linux/mm_types.h
struct page {
/* First double word block */
unsigned long flags; /* Atomic flags, some possibly
* updated asynchronously */
- 1
- 2
- 3
- 4
结构体page的成员flags的布局如下
- 其中,SECTION是稀疏内存模型中的段编号,NODE是节点编号,ZONE是区域类型,FLAGS是标志位。
因为物理页的数量很大,所以在page结构体中增加1个成员,可能导致所有page实例占用的内存大幅增加。为了减少内存消耗,内核努力使page结构体尽可能小,对于不会同时生效的成员,使用联合体,这种做法带来的负面影响是page结构体的可读性差。

