
热门标签
热门文章
- 1我的书签菜单_聚bt网址
- 2SLA(服务等级协议)_服务可用性sla
- 3Baidu Comate——基于AI的智能代码生成让你的编码更快、更好、更简单!_指新用户在ide中安装comate插件,并在问答区有技术类的提问,或者在编码区有采纳行
- 4Java|IDEA 运行和打包报错解决_java: java.lang.nosuchfielderror: class com.sun.to
- 5Github 2024-05-21 开源项目日报 Top10
- 6Android Studio Gradle
- 7Openlayers的交互功能(六)——编辑图斑_openlayer modify
- 8CSDN上传付费资源需要创作者等级Lv3,我的升级之路_csdn 的 综合贡献分
- 9Endnote 保姆级攻略:参考文献插入与删除、Style修改、文档格式转化(转载)_endnote插入引文 参考文献格式
- 10人工智能 ai java_人工智能需要java吗
当前位置: article > 正文
spark3.3.1通过hbase-connectors连接CDH6.3.2自带hbase_apache hbase spark connector
作者:菜鸟追梦旅行 | 2024-05-26 06:06:54
赞
踩
apache hbase spark connector
补充编译
hbase-connectors-master
源码下载
wget https://github.com/apache/hbase-connectors
- 1
mvn --settings /Users/admin/Documents/softwares/repository-zi/settings-aliyun.xml -Dspark.version=3.3.1 -Dscala.version=2.12.10 -Dscala.binary.version=2.12 -Dhbase.version=2.4.9 -Dhadoop-three.version=3.2.0 -DskipTests clean package
- 1
pom.xml添加配置
<repositories>
<repository>
<id>central</id>
<name>Maven Repository</name>
<url>https://repo.maven.apache.org/maven2</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
1、导出对应的jar包
cp /opt/cloudera/parcels/CDH/lib/hbase/hbase-shaded-netty-2.2.1.jar /opt/cloudera/parcels/CDH/lib/spark3/jars/
cp /opt/cloudera/parcels/CDH/lib/hbase/hbase-shaded-protobuf-2.2.1.jar /opt/cloudera/parcels/CDH/lib/spark3/jars/
cp /opt/cloudera/parcels/CDH/lib/hbase/hbase-protocol-shaded-2.1.0-cdh6.3.2.jar /opt/cloudera/parcels/CDH/lib/spark3/jars/
cp /opt/cloudera/parcels/CDH/lib/hbase/hbase-shaded-miscellaneous-2.2.1.jar /opt/cloudera/parcels/CDH/lib/spark3/jars/
cp hbase-spark-1.0.1-SNAPSHOT.jar /opt/cloudera/parcels/CDH/lib/spark3/jars/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2、scala脚本测试
spark-shell -c spark.ui.port=11111
- 1
import org.apache.hadoop.hbase.spark.HBaseContext
import org.apache.hadoop.hbase.HBaseConfiguration
val conf = HBaseConfiguration.create()
conf.set("hbase.zookeeper.quorum", "hadoop103:2181")
new HBaseContext(spark.sparkContext, conf)
val hbaseDF = (spark.read.format("org.apache.hadoop.hbase.spark")
.option("hbase.columns.mapping",
"empno STRING :key,ename STRING info:ename, job STRING info:job"
).option("hbase.table", "hive_hbase_emp_table")
).load()
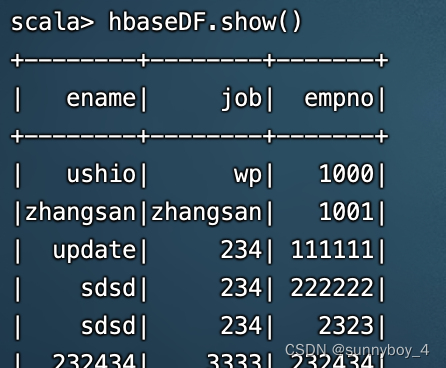
hbaseDF.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
3、pyspark脚本测试hbase-connectors
import findspark
findspark.init(spark_home='/opt/cloudera/parcels/CDH/lib/spark3',python_path='/opt/cloudera/anaconda3/bin/python')
from pyspark.sql import SparkSession
spark = SparkSession.Builder().appName("Demo_spark_conn").getOrCreate()
df = spark.read.format("org.apache.hadoop.hbase.spark").option("hbase.zookeeper.quorum","hadoop103:2181").option("hbase.columns.mapping","empno STRING :key, ename STRING info:ename,job STRING info:job").option("hbase.table", "hive_hbase_emp_table").option("hbase.spark.use.hbasecontext", False).load()
df.show(10)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/菜鸟追梦旅行/article/detail/625492
推荐阅读
相关标签

