
PySpark数据分析基础:PySpark基础功能及DataFrame操作基础语法详解_pyspark rdd_spark dataframe基本语法
赞
踩
DataFrame.show()
使用格式:
df.show(<int>)
- 1
df.show(1)
- 1
+---+---+-------+----------+-------------------+
| a| b| c| d| e|
+---+---+-------+----------+-------------------+
| 1|2.0|string1|2000-01-01|2000-01-01 12:00:00|
+---+---+-------+----------+-------------------+
only showing top 1 row
- 1
- 2
- 3
- 4
- 5
- 6
- 7
spark.sql.repl.eagerEval.enabled
spark.sql.repl.eagerEval.enabled用于在notebooks(如Jupyter)中快速生成PySpark DataFrame的配置。控制行数可以使用spark.sql.repl.eagerEval.maxNumRows。
spark.conf.set('spark.sql.repl.eagerEval.enabled', True)
df
- 1
- 2
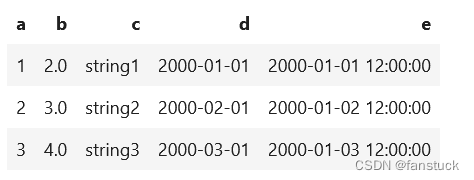
spark.conf.set('spark.sql.repl.eagerEval.maxNumRows',1)
df
- 1
- 2

纵向显示
行也可以垂直显示。当行太长而无法水平显示时,纵向显示就很明显。
df.show(1, vertical=True)
- 1
-RECORD 0------------------
a | 1
b | 2.0
c | string1
d | 2000-01-01
e | 2000-01-01 12:00:00
only showing top 1 row
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
查看DataFrame格式和列名
df.columns
- 1
['a', 'b', 'c', 'd', 'e']
- 1
df.printSchema()
- 1
root
|-- a: long (nullable = true)
|-- b: double (nullable = true)
|-- c: string (nullable = true)
|-- d: date (nullable = true)
|-- e: timestamp (nullable = true)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
查看统计描述信息
df.select("a", "b", "c").describe().show()
- 1
+-------+---+---+-------+
|summary| a| b| c|
+-------+---+---+-------+
| count| 3| 3| 3|
| mean|2.0|3.0| null|
| stddev|1.0|1.0| null|
| min| 1|2.0|string1|
| max| 3|4.0|string3|
+-------+---+---+-------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
DataFrame.collect()将分布式数据收集到驱动程序端,作为Python中的本地数据。请注意,当数据集太大而无法容纳在驱动端时,这可能会引发内存不足错误,因为它将所有数据从执行器收集到驱动端。
df.collect()
- 1
[Row(a=1, b=2.0, c='string1', d=datetime.date(2000, 1, 1), e=datetime.datetime(2000, 1, 1, 12, 0)),
Row(a=2, b=3.0, c='string2', d=datetime.date(2000, 2, 1), e=datetime.datetime(2000, 1, 2, 12, 0)),
Row(a=3, b=4.0, c='string3', d=datetime.date(2000, 3, 1), e=datetime.datetime(2000, 1, 3, 12, 0))]
- 1
- 2
- 3
为了避免引发内存不足异常可以使用DataFrame.take()或者是DataFrame.tail():
df.take(1)
- 1
[Row(a=1, b=2.0, c='string1', d=datetime.date(2000, 1, 1), e=datetime.datetime(2000, 1, 1, 12, 0))]
- 1
df.tail(1)
- 1
[Row(a=3, b=4.0, c='string3', d=datetime.date(2000, 3, 1), e=datetime.datetime(2000, 1, 3, 12, 0))]
- 1
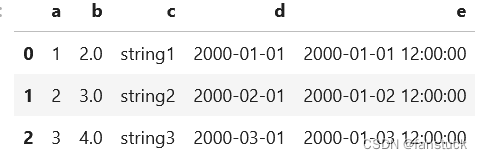
PySpark DataFrame转换为Pandas DataFrame
PySpark DataFrame还提供了到pandas DataFrame的转换,以利用pandas API。注意,toPandas还将所有数据收集到driver端,当数据太大而无法放入driver端时,很容易导致内存不足错误。
df.toPandas()
- 1
3.查询
PySpark DataFrame是惰性计算的,仅选择一列不会触发计算,但它会返回一个列实例:
df.a
- 1
Column<'a'>
- 1
大多数按列操作都返回列:
from pyspark.sql import Column
from pyspark.sql.functions import upper
type(df.c) == type(upper(df.c)) == type(df.c.isNull())
- 1
- 2
- 3
- 4
True
- 1
上述生成的Column可用于从DataFrame中选择列。例如,DataFrame.select()获取返回另一个DataFrame的列实例:
df.select(df.c).show()
- 1
+-------+
| c|
+-------+
|string1|
|string2|
|string3|
+-------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
添加新列实例:
df.withColumn('upper_c', upper(df.c)).show()
- 1
+---+---+-------+----------+-------------------+-------+
| a| b| c| d| e|upper_c|
+---+---+-------+----------+-------------------+-------+
| 1|2.0|string1|2000-01-01|2000-01-01 12:00:00|STRING1|
| 2|3.0|string2|2000-02-01|2000-01-02 12:00:00|STRING2|
| 3|4.0|string3|2000-03-01|2000-01-03 12:00:00|STRING3|
+---+---+-------+----------+-------------------+-------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
条件查询DataFrame.filter()
df.filter(df.a == 1).show()
- 1
+---+---+-------+----------+-------------------+
| a| b| c| d| e|
+---+---+-------+----------+-------------------+
| 1|2.0|string1|2000-01-01|2000-01-01 12:00:00|
+---+---+-------+----------+-------------------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
4.运算
Pandas_udf
PySpark支持各种UDF和API,允许用户执行Python本机函数。另请参阅最新的Pandas UDF( Pandas UDFs)和Pandas Function API( Pandas Function APIs)。例如,下面的示例允许用户在Python本机函数中直接使用pandas Series中的API。
import pandas as pd
from pyspark.sql.functions import pandas_udf
@pandas_udf('long')
def pandas_plus_one(series: pd.Series) -> pd.Series:
# Simply plus one by using pandas Series.
return series + 1
df.select(pandas_plus_one(df.a)).show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
+------------------+
|pandas_plus_one(a)|
+------------------+
| 2|
| 3|
| 4|
+------------------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
DataFrame.mapInPandas
DataFrame.mapInPandas允许用户在pandas DataFrame中直接使用API,而不受结果长度等任何限制。
def pandas_filter_func(iterator):
for pandas_df in iterator:
yield pandas_df[pandas_df.a == 1]
df.mapInPandas(pandas_filter_func, schema=df.schema).show()
- 1
- 2
- 3
- 4
- 5
+---+---+-------+----------+-------------------+
| a| b| c| d| e|
+---+---+-------+----------+-------------------+
| 1|2.0|string1|2000-01-01|2000-01-01 12:00:00|
+---+---+-------+----------+-------------------+
- 1
- 2
- 3
- 4
- 5
5.分组
PySpark DataFrame还提供了一种使用常见方法,即拆分-应用-合并策略来处理分组数据的方法。它根据特定条件对数据进行分组,对每个组应用一个函数,然后将它们组合回DataFrame。
df = spark.createDataFrame([
['red', 'banana', 1, 10], ['blue', 'banana', 2, 20], ['red', 'carrot', 3, 30],
['blue', 'grape', 4, 40], ['red', 'carrot', 5, 50], ['black', 'carrot', 6, 60],
['red', 'banana', 7, 70], ['red', 'grape', 8, 80]], schema=['color', 'fruit', 'v1', 'v2'])
df.show()
- 1
- 2
- 3
- 4
- 5
+-----+------+---+---+
|color| fruit| v1| v2|
+-----+------+---+---+
| red|banana| 1| 10|
| blue|banana| 2| 20|
| red|carrot| 3| 30|
| blue| grape| 4| 40|
| red|carrot| 5| 50|
|black|carrot| 6| 60|
| red|banana| 7| 70|
| red| grape| 8| 80|
+-----+------+---+---+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
分组,然后将avg()函数应用于结果组。
df.groupby('color').avg().show()
- 1
+-----+-------+-------+
|color|avg(v1)|avg(v2)|
+-----+-------+-------+
| red| 4.8| 48.0|
| blue| 3.0| 30.0|
|black| 6.0| 60.0|
+-----+-------+-------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
还可以使用pandas API对每个组应用Python自定义函数。
def plus_mean(pandas_df):
return pandas_df.assign(v1=pandas_df.v1 - pandas_df.v1.mean())
df.groupby('color').applyInPandas(plus_mean, schema=df.schema).show()
- 1
- 2
- 3
- 4
+-----+------+---+---+
|color| fruit| v1| v2|
+-----+------+---+---+
|black|carrot| 0| 60|
| blue|banana| -1| 20|
| blue| grape| 1| 40|
| red|banana| -3| 10|
| red|carrot| -1| 30|
| red|carrot| 0| 50|
| red|banana| 2| 70|
| red| grape| 3| 80|
+-----+------+---+---+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
联合分组和应用函数
df1 = spark.createDataFrame(
[(20000101, 1, 1.0), (20000101, 2, 2.0), (20000102, 1, 3.0), (20000102, 2, 4.0)],
('time', 'id', 'v1'))
df2 = spark.createDataFrame(
[(20000101, 1, 'x'), (20000101, 2, 'y')],
('time', 'id', 'v2'))
def asof_join(l, r):
return pd.merge_asof(l, r, on='time', by='id')
df1.groupby('id').cogroup(df2.groupby('id')).applyInPandas(
asof_join, schema='time int, id int, v1 double, v2 string').show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
+--------+---+---+---+
| time| id| v1| v2|
+--------+---+---+---+
|20000101| 1|1.0| x|
|20000102| 1|3.0| x|
|20000101| 2|2.0| y|
|20000102| 2|4.0| y|
+--------+---+---+---+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
6.获取数据输入/输出
CSV简单易用。Parquet和ORC是高效紧凑的文件格式,读写速度更快。
PySpark中还有许多其他可用的数据源,如JDBC、text、binaryFile、Avro等。另请参阅Apache Spark文档中最新的Spark SQL、DataFrames和Datasets指南。Spark SQL, DataFrames and Datasets Guide
CSV
df.write.csv('foo.csv', header=True)
spark.read.csv('foo.csv', header=True).show()
- 1
- 2
这里记录一个报错:
java.lang.UnsatisfiedLinkError:org.apache.hadoop.io.nativeio.NativeIO$Windows.access0
- 1
将Hadoop安装目录下的 bin 文件夹中的 hadoop.dll 和 winutils.exe 这两个文件拷贝到 C:\Windows\System32 下,问题解决。
+---+---+-------+----------+--------------------+
| a| b| c| d| e|
+---+---+-------+----------+--------------------+
| 1|2.0|string1|2000-01-01|2000-01-01T12:00:...|
| 2|3.0|string2|2000-02-01|2000-01-02T12:00:...|
| 3|4.0|string3|2000-03-01|2000-01-03T12:00:...|
+---+---+-------+----------+--------------------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
Parquet
df.write.parquet('bar.parquet')
spark.read.parquet('bar.parquet').show()
- 1
- 2
+-----+------+---+---+
|color| fruit| v1| v2|
+-----+------+---+---+
|black|carrot| 6| 60|
| blue|banana| 2| 20|
| blue| grape| 4| 40|
| red|carrot| 5| 50|
| red|banana| 7| 70|
| red|banana| 1| 10|
| red|carrot| 3| 30|
| red| grape| 8| 80|
+-----+------+---+---+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
ORC
df.write.orc('zoo.orc')
spark.read.orc('zoo.orc').show()
- 1
- 2
+-----+------+---+---+
|color| fruit| v1| v2|
+-----+------+---+---+
| red|banana| 7| 70|
| red| grape| 8| 80|
|black|carrot| 6| 60|
| blue|banana| 2| 20|
| red|banana| 1| 10|
| red|carrot| 5| 50|
| red|carrot| 3| 30|
| blue| grape| 4| 40|
+-----+------+---+---+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
四、结合Spark SQL
DataFrame和Spark SQL共享同一个执行引擎,因此可以无缝地互换使用。例如,可以将数据帧注册为表,并按如下方式轻松运行SQL:
df.createOrReplaceTempView("tableA")
spark.sql("SELECT count(*) from tableA").show()
- 1
- 2
+--------+
|count(1)|
+--------+
| 8|
+--------+
- 1
- 2
- 3
- 4
- 5
- 6
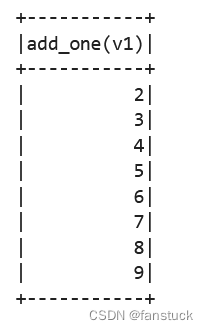
此外UDF也可在现成的SQL中注册和调用
@pandas_udf("integer")
def add_one(s: pd.Series) -> pd.Series:
return s + 1
spark.udf.register("add_one", add_one)
spark.sql("SELECT add_one(v1) FROM tableA").show()
- 1
- 2
- 3
- 4
- 5
- 6
这些SQL表达式可以直接混合并用作PySpark列。
from pyspark.sql.functions import expr   **网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。** **[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)** **一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!** turn s + 1 spark.udf.register("add_one", add_one) spark.sql("SELECT add_one(v1) FROM tableA").show()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
这些SQL表达式可以直接混合并用作PySpark列。
from pyspark.sql.functions import expr
[外链图片转存中...(img-YaCO0Yl5-1714159286719)]
[外链图片转存中...(img-iDk4owcI-1714159286719)]
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14

