
- 1IDEA 中使用Git创建新分支,合并代码_idea git合并代码
- 2文件上传--Upload-labs--Pass12--(POST)00绕过_upload files pass-12
- 3最后十天!奖金31万等你来挑战!
- 4LeetCode 232.用栈实现队列(详解) (๑•̌.•๑)
- 5VScode保存时右下角出现的提示弹窗,保存速度变慢,如何解决_vscode saving time is too long
- 6【已解决】535 Login Fail. Please enter your authorization code to login. More information in http---servi
- 7【看表情包学Linux】(9) 缓冲区的概念 Git 三板斧 实现简易进度条_git缓冲区大小是什么(1)
- 8从“神经网络之父”到“人工智能教父”|Geoffrey Hinton的传奇人生 那才叫精彩...
- 9Access、SQLite,我该如何选择?_sqlite access
- 10iptables 添加,删除,查看,修改,及docker运行时修改端口_iptables 添加端口
JVM内存泄漏问题分析处理实战_dump分析内存泄露
赞
踩
一、背景
文章开头,先分享一张大部分Java开发同学都记在心里的一张图。

没错,就是Spring Bean生命周期图。就因为这张图不熟悉,导致线上环境出现内存泄漏问题,系统频繁FullGC,服务无法响应。
1、第一次报错系统监控现象


2、关键时间节点:
14:16 机器发布新代码
15:35 机器开始出现fullGC
15:50 机器fullGC耗时上升
17:48 对JVM进行dump操作,然后进行机器置换
由图可知,在14:16发布完成后,系统正常运行了一段时间,期间内存、线程等均未出现异常,不过当系统运行了一段时间后,通过监控可以明显发现内存使用量和线程数都在持续上升,那这样问题就很明确了:
1.有大量阻塞线程
2.存在内存泄露问题
二、 排查过程
分析线程Dump文件
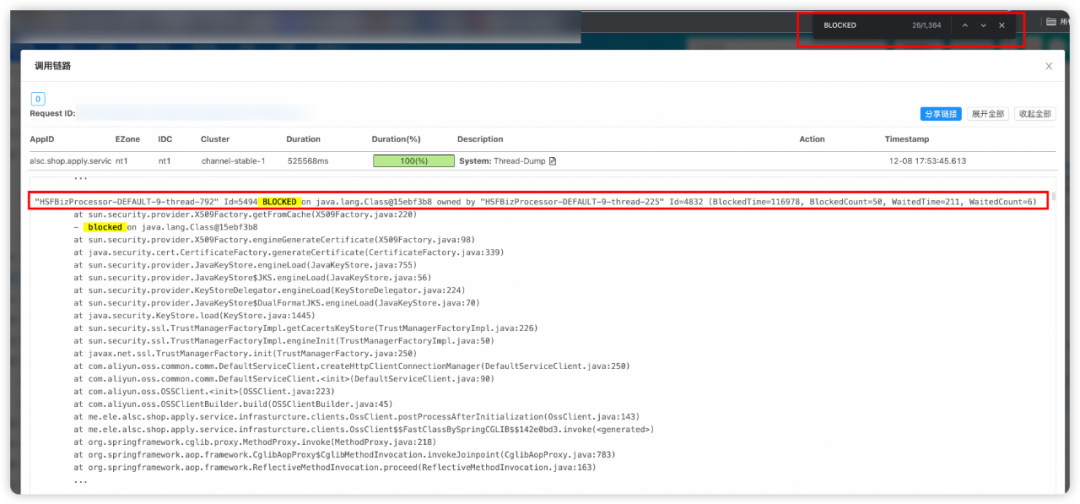
Dump文件记录
通过截图中Dump文件内容可知,HSFBizProcessor-DEFAULT-9-thread-792 这个线程已经阻塞了116s,并且的阻塞线程共有682个。
三、 问题分析原因
根据线程堆栈信息,查到了线程是阻塞在下面这段代码:
@Componentpublic class OssClient implements BeanPostProcessor {private OSS ossClient = null;/** * 初始化OSS客户端 **/@Overridepublic Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {// 省略代码……// 以下是阻塞代码行 ossClient = new OSSClientBuilder().build(ossProperty.getString("endpoint"), ossProperty.getString("accessKeyId"), ossProperty.getString("accessKeySecret"), configuration);// 省略代码……return bean; }}这段代码本意是在应用启动时,通过动态配置文件来配置OSS客户端。
但是线程阻塞在了这行,首先我想到可能是由于OSS客户端初始化需要发起网络请求,因为饿了么有张北和南通机房且一般情况下跨机房无法访问,所以第一时间检查了一下配置,果不其然,南通机房配置了张北的OSS。
登录上南通机房的机器,尝试PING张北的OSS域名,发现无法PING通,验证了我的猜测。

四、 第一次问题解决
Get到了报错原因,就方便解决了;通过修改配置,将OSS机房配置正确后,重启机器即可。
1、第二次报错系统监控现象
本来以为万事大吉,在观察了30分钟,确认系统无BLOCKED线程后,就认为该问题已经解决。
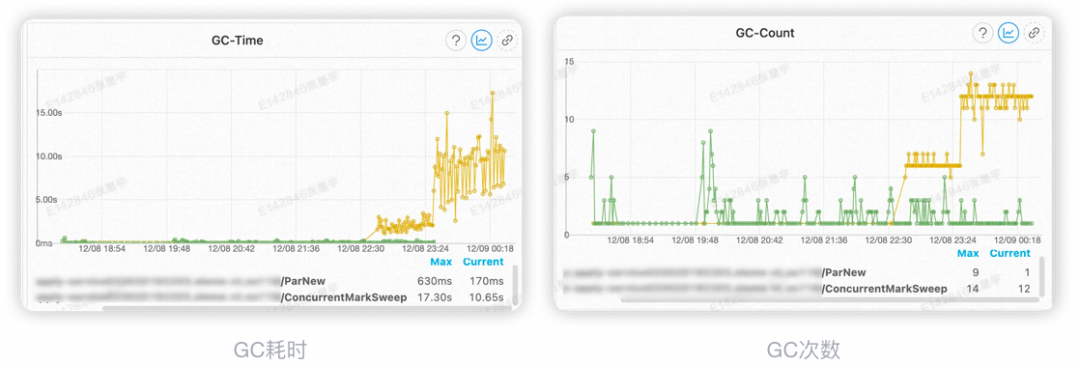
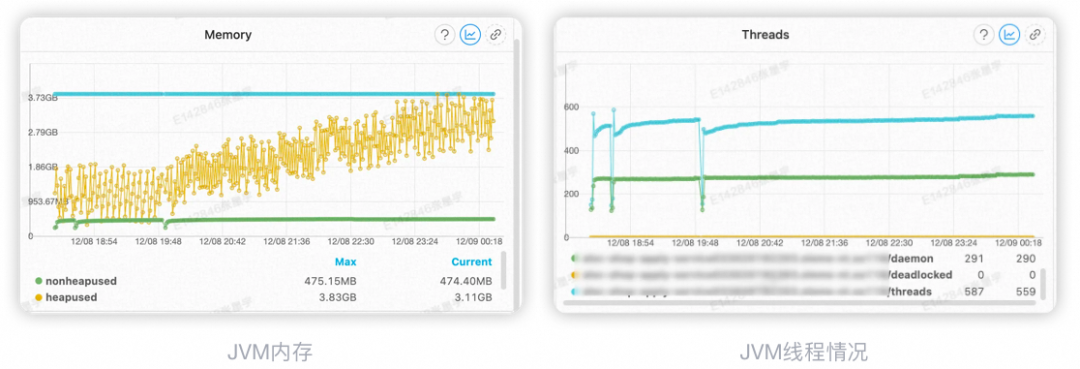
2、关键时间节点:
19:48 机器发布新代码
22:30 机器开始出现fullGC
23:30 机器fullGC耗时上升
00:30 对JVM进行dump操作,然后进行机器置换
然而,在发布后3个小时以后,系统又开始报错,同样是fullGC,只不过这次fullGC耗时没有之前那么长了。
3、分析线程Dump文件
因为有了前车之鉴,所以第一步想到的就是上一步的问题没有解决,线程仍然阻塞在刚才的代码处。

不过,这次并没有查询到阻塞线程。这至少证明:
1.阻塞线程确实是由于OSS跨单元拒绝访问导致的
2.还有其他问题导致了内存泄漏
4、分析GC Dump文件
首先,通过集团Grace工具,发现有严重的内存泄漏问题。
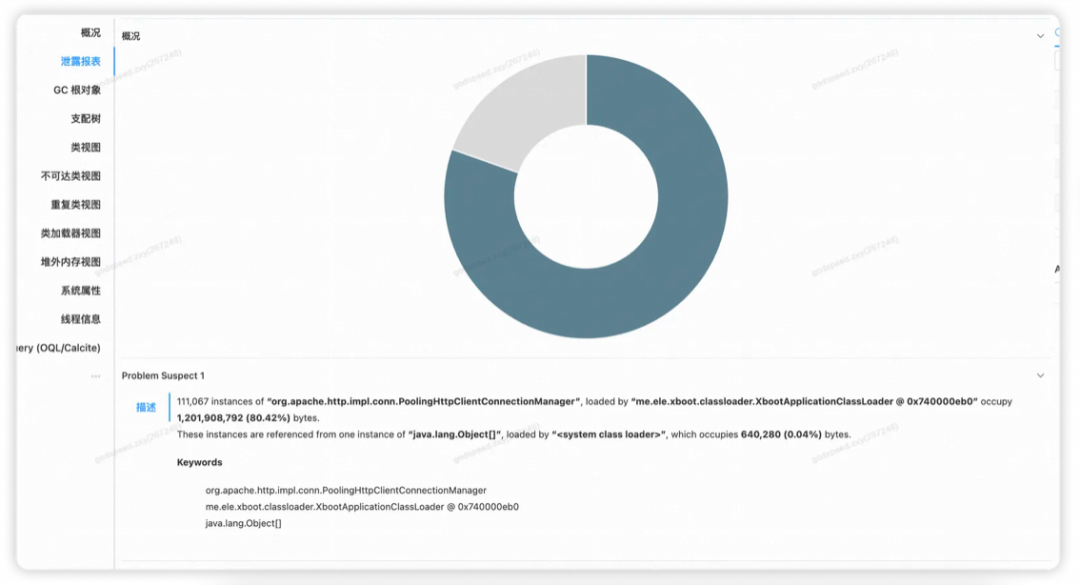
这里显示有11万个org.apache.http.impl.conn.PoolingHttpClientConnectionManager实例,占用了80.42%的堆内存,但是这个类并不是我直接引入的,那么一定是有间接依赖,生成了大量该类对象。
另外,通过类名,能判断这个对象是和网络请求有关系,而我这个应用上需要网络请求的地方有几处:
1.访问DB
2.访问Redis
3.访问OSS
4.进行HSF调用
继续通过对对象依赖进行分析,发现了一个重要信息:

org.apache.http.impl.conn.PoolingHttpClientConnectionManager这个类由OSS间接依赖进来的,确定了引起内存泄漏的罪魁祸首。
虽然定位到了是由于OSS建议依赖进来,但是看代码仍然不能解释为什么会产生内存泄漏。
@Componentpublic class OssClient implements BeanPostProcessor {private OSS ossClient = null;/** * 初始化OSS客户端 **/@Overridepublic Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {// 省略代码……// 一下是阻塞代码行 ossClient = new OSSClientBuilder().build(ossProperty.getString("endpoint"), ossProperty.getString("accessKeyId"), ossProperty.getString("accessKeySecret"), configuration);// 省略代码……return bean; }}排查原因过程中,有一篇文章给了我答案,下面是这篇文章给的OOM原因的解释:
每次new OSSClient的时候,都会往List中放入HttpClientConnectionManager,但是没有主动调用OSSClient的shutdown的方法,所以List只会增大不会变小。反观我们的代码,每次接口调用都会创建一个OSSClient对象,但却在使用完之后,没有调用OSSClient的shutdown方法,导致未调用IdleConnectionReaper的removeConnectionManager方法,使得IdleConnectionReaper中静态列表存储的PoolingHttpClientConnectionManager实例数据一直会增长,一直都不会被回收,最终带来的结果就是OOM。
其实通过代码能够看出,我的初衷是在OssClient这个Bean初始化的时候执行一下初始化逻辑,在我查到导致内存泄漏的原因后,我仍然对一个问题很是不解:为什么OSS初始化的代码会被多次执行?
回到文章标题和开头,为什么这篇文章标题叫“一次由于八股文引起的内存泄漏”,以及为什么文章开头会引入下面这张图?
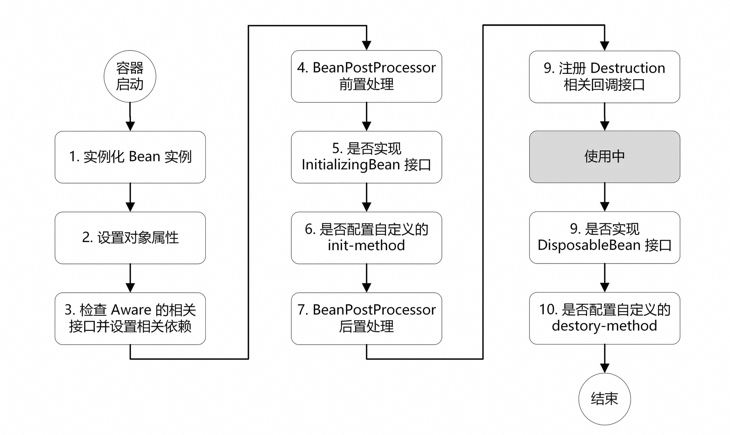
实际上,是由于实现错了接口导致的OSS初始化代码被重复调用,最终导致系统OOM。
五、 最终问题解决
改变一下实现接口,使代码逻辑符合我预期效果即可,当然这个解决方式有多种多样,下面只是我的一种解决方案。
@Componentpublic class OssClient implements InitializingBean {
private OSS ossClient = null;
/** * 初始化OSS客户端 **/ @Override public void afterPropertiesSet() throws Exception { // 省略代码…… // 以下是阻塞代码行 ossClient = new OSSClientBuilder().build(ossProperty.getString("endpoint"), ossProperty.getString("accessKeyId"), ossProperty.getString("accessKeySecret"), configuration); // 省略代码…… }
}总结
圈内常有声音抱怨,“面试好比是造火箭,而工作不过是拧螺丝”,尤其对于Java开发岗位面试中的常规知识题目持有轻蔑态度。然而,这些被称作“八股文”的知识,实际上是每位开发工程师技术根基的核心。坚实的基础才能确保构建在其之上的高楼大厦能够屹立不倒,历经岁月的洗礼。

