
- 1Mac 外接显示器色彩不正常解决方案_mac外接显示器颜色变紫
- 2NPDP证书值得考吗?_一、npdp到底值不值得考?有用吗? 想要回答上面的问题,我们先要了解一下以下问题!
- 3Linux搭建DNS服务_linux搭建dns服务器
- 4flink三种部署模式_flink三种部署方案
- 5Android系统启动源码分析
- 6计算机毕业设计ssm宠物托管系统设计与实现is2039(附源码)新手必备
- 7Android手势滑动(左滑和右滑)_android开发界面左滑右滑
- 8搜索引擎爬虫_sogou web spider
- 9如何用Python获取微信好友信息,让你更加了解你的朋友_微信好友详情接口
- 102021年安全员-B证报名考试及安全员-B证考试技巧_安全b证考试技巧
揭秘AI大模型:推理过程优化如何影响未来智能世界?
赞
踩
AI大模型推理过程和优化技术
一 推理过程
主流大模型均根植于Transformer架构,其核心精髓在于注意力机制。简而言之,该机制通过计算softmax(qk^T)*v,精准捕捉数据间的关联,从而实现高效信息处理。
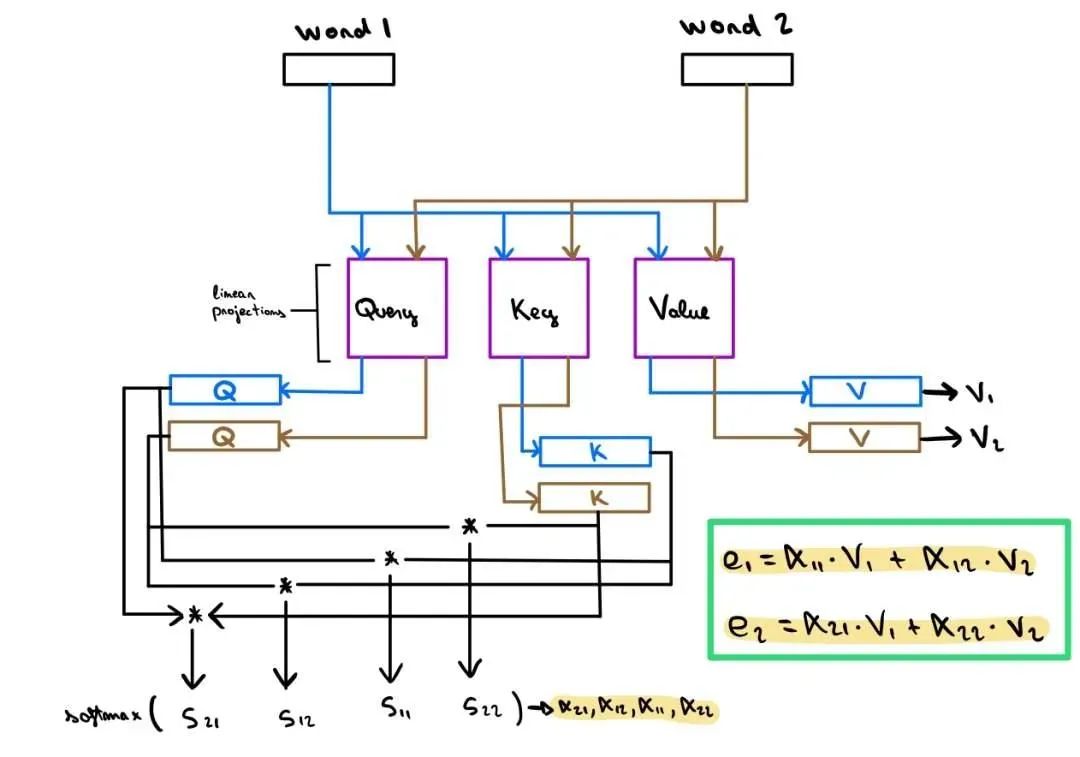
计算softmax(qk^T)*v
推理会分成 prefill 和 decoding 两个阶段。每一个请求发起后产生的推理过程都会先经历一个 Prefill 过程,prefill 过程会计算用户所有的输入,并生成对应的 KV 缓存,再经历若干个 decoding 过程,每一个 decoding 过程服务器都会生成一个字符,并将其放入到 KV 缓存当中,推理出来的预测结果又放入输入中,如此循环往复,直到推理出最终结果。
新的请求进来在进行完 prefill 之后会不断迭代进行 decoding,每一个 decoding 阶段结束之后都会将结果当场返回给客户。这样的生成过程称为流式传输。
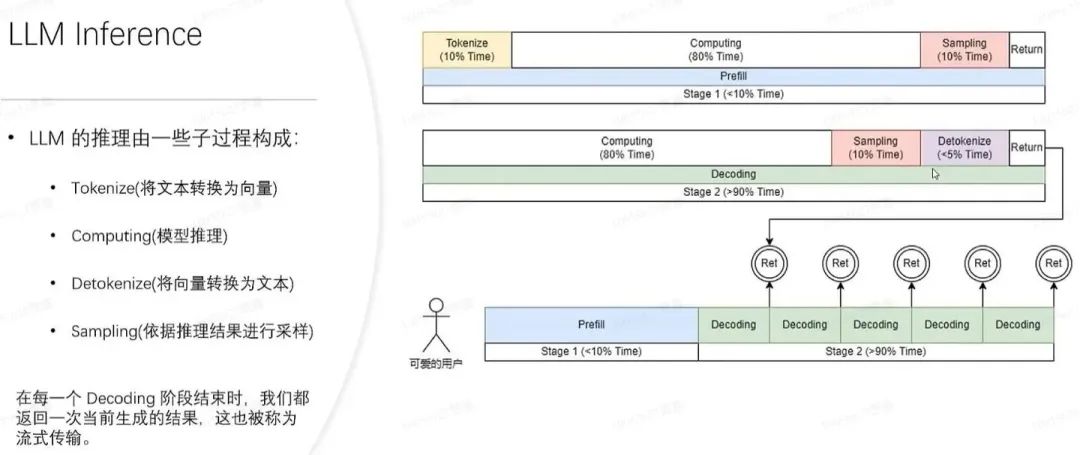
LLM 推理过程
1.Prefill(输入理解与初始化)阶段
需要计算整个prompt的自注意力。Embedding 曾将用户提问构建 Word Embedding Matrix,之后会被分成 Q、K、V,其中 Q 在经过 Rotary Embedding 之后直接进入后续 Attention 计算,而 K 在经过 Rotary Embedding 之后会和先前的 V 一同进入 KV cache 之中,以待后续计算。随后进入 Attention 的计算,先前处理完成之后的 Q、K、V 会计算得出 self-attention。具体如下:
用户输入向量化是关键步骤,其中tokenize过程将文本转为向量,尽管仅占据整体prefill阶段的10%时间,但其重要性不容忽视,这一过程虽然有所代价,却是后续处理的基础与核心。
2.进行真正的 prefill 计算,这一过程会占掉大概 80% 的时间。
在Pytorch中,sampling环节常涉及sample、top p方法,而在大语言模型推理时则常用argmax。此过程旨在基于模型结果生成最终词汇,尽管仅占总体时间的10%,却至关重要,对模型输出的精准度具有决定性影响。
最后,我们迅速将refill的结果反馈给客户,此环节耗时极短,仅占整体流程2%至5%的时间,高效便捷。
2.Decoding(递归推理与解码输出)阶段
每生成一个token就要计算一次。模型理解了初始序列之后便会开始逐词预测后续文本,每次预测时模型都会基于已知的输入序列和上一步预测出来的词计算出下一个最可能的词汇的概率分布,输入过后,执行和 Prefill 前期一样的操作,随后计算 Attention,此时的 Q 就只是一行向量了(因为只有一个词作为输入),K,V 则依旧是矩阵(新输入的 Embedding 生成的 K,V 向量嵌入 KV cache 原本有的矩阵中,和隐状态融合),一样的计算过程可以得出下一步的输出。这个预测过程会一直持续到达到预设的终止条件,例如生成特定长度的文本、遇到终止符,或是满足某种逻辑条件为止。
在Decoding阶段,无需进行tokenize操作,每次解码均直接从计算起步。整个解码流程耗费了高达80%的时间,紧接着的采样生成词过程也占据了10%的时间。然而,还有一项关键步骤——detokenize,即在生成词向量后需将其解码为文本形式,此过程约占5%的时间。最终,将生成的词精准地呈现给用户,确保信息的完整性与准确性。这一优化流程不仅提升了效率,更确保了用户体验的流畅与舒适。
Decoder中的Multi-Head Self-Attention结构运算量庞大,模型宽度与Layer数量倍增后,参数量急剧增长,导致推理速度缓慢且资源消耗巨大。优化此结构,提升效率,成为当前研究的迫切需求。
二 推理性能的评价指标
在大模型推理中

