
热门标签
热门文章
- 1Facebook如何引流独立站,有哪些策略?
- 2粉丝投稿,分享自己的哔哩哔哩四面总结,以及个人总结的一些面试真题。_b站4面
- 3什么是VRRP?_vrrp是什么
- 4在 VS Code 中使用版本控制_vscode merge changes
- 5主流开源 BI 产品对比---------2020开源BI工具都有哪些,哪个好用_开源bi有哪些
- 6R语言中使用colSums函数对矩阵或数据框的列进行求和
- 7基于模板匹配的手写字体数字识别-含Matlab代码_基于模板的手写数字识别
- 8postman 测试接口报错401_postman 401
- 9ubuntu+docker+pycharm环境深度学习远程炼丹使用教程_pycharm使用docker ubuntu配置python环境
- 10头歌python实训通关四——循环结构_头歌课程怎么样算通关
当前位置: article > 正文
第三章 Flink基础理论之内存管理初步介绍_flink内存管理
作者:菜鸟追梦旅行 | 2024-06-09 23:56:32
赞
踩
flink内存管理
1、引入
- Flink内存管理:自己管理自己内存的
基于JVM的数据分析引擎都需要面对将大量数据存到内存中,不得不面对JVM存在的几个问题
- Java 对象存储密度低。一个只包含 boolean 属性的对象占用了16个字节内存:对象头占了8个,boolean 属性占了1个,对齐填充占了7个。而实际上只需要一个bit(1/8字节)就够了。
- Full GC 会极大地影响性能,尤其是为了处理更大数据而开了很大内存空间的JVM来说,GC 会达到秒级甚至分钟级。
- OOM 问题影响稳定性。OutOfMemoryError是分布式计算框架经常会遇到的问题,当JVM中所有对象大小超过分配给JVM的内存大小时,就会发生OutOfMemoryError错误,导致JVM崩溃,分布式框架的健壮性和性能都会受到影响。
2、内存管理概述
- Flink 并不是将大量对象存在堆上,而是将对象都序列化到一个预分配的内存块(MemorySegment),也是Flink中的最小内存分配单元
MemorySegment ≈ Flink 定制的 java.nio.ByteBuffer。
它的底层可以是一个普通的 Java 字节数组(byte[]),也可以是一个申请在堆外的 ByteBuffer。
每条记录都会以序列化的形式存储在一个或多个MemorySegment中。
- 1
- 2
- 3
- Flink 中的 Worker 名叫 TaskManager,是用来运行用户代码的 JVM 进程,
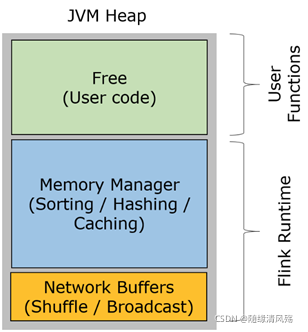
- TaskManager 的堆内存主要被分成了三个部分
1、Network Buffers: 一定数量的32KB大小的 buffer,主要用于数据的网络传输。
在 TaskManager 启动的时候就会分配。默认数量是 2048 个,
可以通过 taskmanager.network.numberOfBuffers 来配置。
- 1
- 2
2、Memory Manager Pool: 这是一个由 MemoryManager 管理的,由众多MemorySegment组成的超大集合
Flink 中的算法(如 sort/shuffle/join)会向这个内存池申请 MemorySegment,
将序列化后的数据存于其中,使用完后释放回内存池。
默认情况下,池子占了堆内存的 70% 的大小。
- 1
- 2
- 3
注意:只能用于批计算,不能用于流计算,所以在流式计算代码会占用此部分内存
3、Remaining (Free) Heap: 这部分的内存是留给用户代码以及 TaskManager 的数据结构使用的
这些数据结构一般都很小,所以基本上这些内存都是给用户代码使用的。
从GC的角度来看,可以把这里看成的新生代,也就是说这里主要都是由用户代码生成的短期对象。
- 1
- 2
3、序列化方法
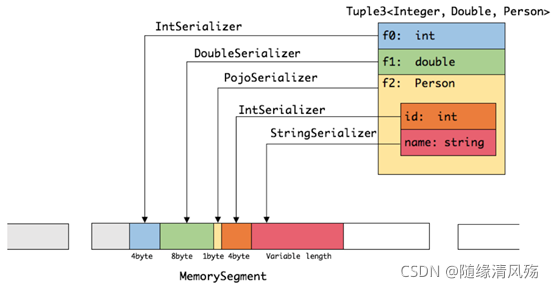
- Flink操作数据:直接操作二进制数据,从而使序列化/反序列化带来的开销达到最小
Flink处理的数据超出了内存限制,则会将部分数据存储到硬盘上,下图展示了Flink处理数据时的存储过程
1、减少GC压力,
有常驻型数据都以二进制的形式存在 Flink 的MemoryManager中,不会被回收,
其他的数据对象是由用户代码生成的短生命周期对象,可以被GC快速回收,从而有效降低了垃圾回收的压力。
2、避免了OOM
所有运行时数据结构与算法只能向内存池申请,其内存大小是固定的,不会运行时因数据结构/算法发生OOM
在内存吃紧的情况下算法会高效的将内存块写到磁盘,之后在处理的时候读取回来。
3、节省内存空间
对象只存实际数据的二进制内容,可以避免这部分消耗
4、高效的二进制操作 & 缓存友好的计算
二进制数据以定义好的格式存储,可以高效地比较与操作;
该二进制形式可以把相关的值,以及hash值,键值和指针等相邻地放进内存中,使数据结构更为友好。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
4、数据类型
1、以直接通过偏移量,只是反序列化特定的对象成员变量。
2、如果对象的成员变量较多时,能够大大减少Java对象的创建开销,以及内存数据的拷贝大小。
- 1
- 2
- BasicTypeInfo: 任意Java 基本类型(装箱的)或 String 类型。
- BasicArrayTypeInfo: 任意Java基本类型数组(装箱的)或 String 数组。
- WritableTypeInfo: 任意 Hadoop Writable 接口的实现类。
- TupleTypeInfo: 任意的 Flink Tuple 类型(支持Tuple1 to Tuple25)。Flink tuples 是固定长度固定类型的Java Tuple实现。
- CaseClassTypeInfo: 任意的 Scala CaseClass(包括 Scala tuples)。
- PojoTypeInfo: 任意的 POJO (Java or Scala),例如,Java对象的所有成员变量,要么是 public 修饰符定义,要么有 getter/setter 方法。
- GenericTypeInfo: 任意无法匹配之前几种类型的类。
针对前六种类型数据集,Flink皆可以自动生成对应的TypeSerializer,能非常高效地对数据集进行序列化和反序列化。
对于最后一种数据类型,Flink会使用Kryo进行序列化和反序列化。
- 1
- 2
5、排序
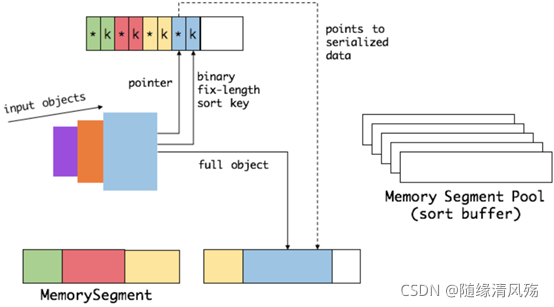
当一个对象要加到 sort buffer 中时,
它的二进制数据会被加到第一个区域,
指针(可能还有key)会被加到第二个区域。
- 1
- 2
- 3
- sort buffer 分成两块区域。
- 一个区域:是用来存放所有对象完整的二进制数据
- 一个区域:用来存放指向完整二进制数据的指针以及定长的序列化后的key(key+pointer)。
排序操作相关
关键操作:比大小&交换
1、会先用 key 比大小,这样就可以直接用二进制的key比较而不需要反序列化出整个对象;
2、key相同(或者没有提供二进制key),那就必须将真实的二进制数据反序列化出来,然后再做比较。
- 1
- 2
- 3
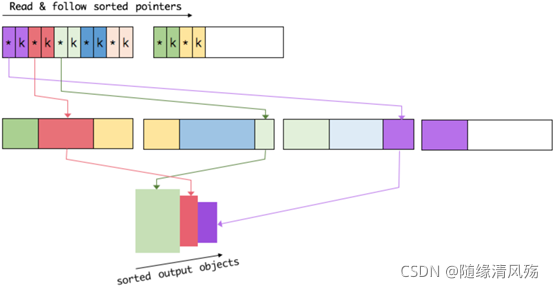
3、访问排序后的数据,可以沿着排好序的key+pointer区域顺序访问,
通过pointer找到对应的真实数据,并写到内存或外部
- 1
- 2
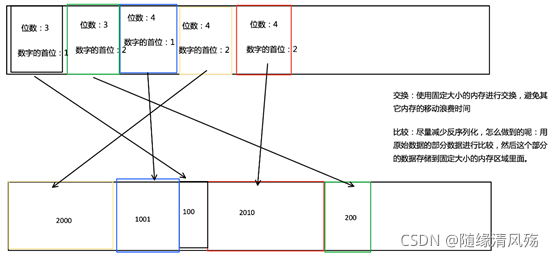
- 实际的数据和指针加定长key分开存放好处
- 第一,交换定长块(key+pointer)更高效,不用交换真实的数据也不用移动其他key和pointer。
- 第二,这样做是缓存友好的,因为key都是连续存储在内存中的,这大大提高了缓存命中率。
6、堆外内存
待续
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/菜鸟追梦旅行/article/detail/696305
推荐阅读
org.apache.flink [详细] 赞
踩
相关标签

