
- 1中国跨过数据库这座大山了吗?
- 2垂直起降飞行器的设计与控制:固定翼和四旋翼整合自主飞行研究(Matlab代码实现)_vtol matlab
- 3springboot校园便利平台
- 4好程序员:学Java真的找不到工作吗?2023年Java就业情况如何?_java还能找到工作吗
- 5python中tkinter使用text组件添加多行文本并自动换行、添加多行文字、添加按钮、添加图片_tkinter 文本框添加按钮
- 6RocketMQ消息发送常见错误与解决方案_defaultmqproducer send exception
- 7Java使用POI导出Excel_java poi导出excel
- 8在无字体时使用word样式,并设置字体样式_xwpfstyles
- 9苹果iOS设备解锁软件:iToolab UnlockGo_强制解除苹果监管锁的软件
- 107 年+积累、 Elastic 创始人Shay Banon 等 15 位专家推荐的 Elasticsearch 8.X新书已上线...
(四)预测模型——时间序列模型_时间序列预测模型
赞
踩
目录
一、算法概念
时间序列模型简单来说就是数据随时间会发生变化,而我们可以根据时间序列进行预测后续的变化。
1.变动形态
时间序列模型要考虑很多情况,在变动形态上,一般分为四种:长期趋势变动,季节变动,循环变动,不规则变动。(而一个时间序列往往是上面四个形态的叠加)
(1)长期趋势变动:趋势是数据在一段时间的逐渐向上或向下的移动。
(2)季节变动:季节是数据自身经过一定周期的天数,周数,月数或季数(此即季节性叫法由来,即季节分为秋、冬、春、夏)不断重复的性质。
(3)循环变动:周期为数据每隔几年重复发生的时间序列形式。它们一般与经济周期有关,并对短期经营分析与计划起重要作用。
(4)不规则变动:随机波动是由偶然、非经常性原因引起的数据变动。它们没有可识别的形式。
统计学上,时间序列有两种一般形式:乘法模式和加法模式。
如果四种变动相互独立,则用乘法模式:需求=趋势*季节*周期*随机波动。
如果四种变动相互关联,则用加法模式:需求=趋势+季节+周期+随机波动。
2.常见模型类别
而时间序列分析常见的模型又分为以下几种,其中每个模型都有自己适合的方面,这里我们主要讲ARIMA模型。
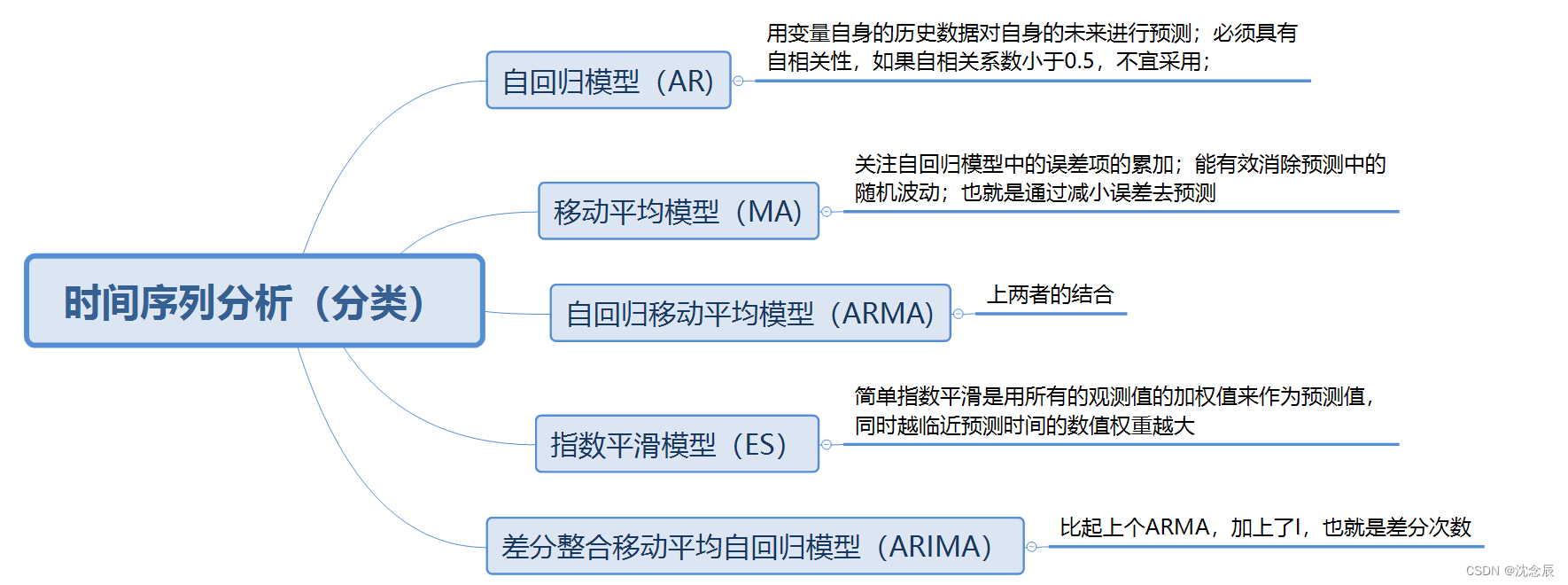
注:当数据没有明显趋势或者周期和季节模式时,可以考虑选择ES模型。
当然:如果导致非平稳的原因确定:ES、MA、AR、ARMA;如果是平稳序列:ARIMA
如果我们发现时间序列有季节性,而且很强,那建议使用SARIMA,具体可以看下文:
3.ARIMA概念介绍
下面我们来说一下ARIMA
ARIMA(p,d,q)中,AR是“自回归”,p为自回归项数;MA为滑动平均,q为滑动平均项数,d为使之成为平稳序列所做差分次数(阶数)。
二、算法流程
1. 检查时间序列的平稳性
使用ARIMA有一个大前提,那就是数据要平稳,不然结果会不准确,那所以第一步往往就需要先去验明一下平稳性了,这时就引出了平稳性检验:
(1)什么是平稳序列?
如果时间序列在某一常数附近波动且波动范围有限,均值、方差和自相关性,在时间上是稳定的,则称该序列为平稳序列。
(2)怎么检验平稳呢?
①单位根检验
不存在单位根即是平稳序列。(直接在MATLAB中使用adftest(data)对数据进行检测,如果返回结果为0,说明不平稳,返回结果为1,说明平稳)
②使用KPSS进行检验
方法是一样的,可以直接在MATLAB中使用kpsstest(data),但需注意(kpss的结果与ADF刚好相反,kpss返回结果为0,说明平稳)
那问题也就随之出现了,如果不平稳该怎么办呢,由此我们引出第二步。
2. 差分操作
如果平稳性检测结果表明原始时间序列不平稳,那就需要此时对原始数据取差分,再进行检验。先 进行一阶差分,结果平稳就结束差分过程。如果依旧不平稳的话,就二次差分,直至通过检验。
差分操作是通过计算当前观测值与前一个观测值之间的差异来消除非平稳性。(以物理学中来理解,一阶导数表示速度,二阶差分表示速度的导数加速度。同样的,在时间序列模型中,一阶差分表示相邻时间的数据的变化情况,二阶差分就表示这种变化的变化强弱。)
当然,差分的操作在代码中是可以直接使用diff这个函数来解决的,很方便!
3. 模型选择
根据差分操作后的时间序列,可以确定ARIMA模型的参数。ARIMA模型由3个参数表示:自回归阶数(p)、差分阶数(d)和移动平均阶数(q)。可以使用自相关函数(ACF)和偏自相关函数(PACF)的图形,以及信息准则(如AIC、BIC等)等指标来选择合适的模型参数。
在MATLAB中使用autocorr和parcorr这两个函数,可以得到数据的自相关函数和偏自相关函数的图形,然后根据图形的截尾或者拖尾去判断使用什么预测模型。
当然需要提一下这里概念的意思:
拖尾:相关系数单调递减至0
截尾:相关系数在某个位置突然变成0 (两条蓝色虚线之间可以视作0)
比如下图就是拖尾


4. 模型拟合
使用确定的ARIMA模型参数,对差分后的时间序列进行模型拟合。算法会估计模型的未知参数,以最小化预测误差。
下面就我们通过AIC与BIC准则确定pq取值,拟合ARIMA模型,使用极大似然估计,最后得到模型的AIC值,AIC值是判断模型拟合好坏的标准,越小越好。
5. 模型诊断
对拟合的ARIMA模型进行诊断,以验证模型的适用性。可以检查残差序列是否满足白噪声假设,即不存在自相关性,那么什么是白噪声检验:
(1)什么是白噪声?
白噪声即纯随机序列,自相关系数为零(理论)或接近于零 (实际)。(就是对结果没有用的杂项,理解为杂音)白噪声检验也称为纯随机性检验,当数据是纯随机数据时,再对数据进行分析就没有任何意义了,所以拿到数据后最好对数据进行一个纯随机性检验。(所以本代码中并没有白噪声检验)
(2)检验纯随机性
①图检验
自相关图检验:自相关系数为零或接近于零
②DW检验或LB统计量检验
6. 模型预测
使用训练好的ARIMA模型对未来的时间序列进行预测。其中,差分操作后的预测结果需要通过逆差分操作恢复到原始时间序列空间。(在代码中对模型进行估计时,需要对数据矩阵进行取转置,也就是A ',具体原因还在研究)
三、算法应用
除了时间序列预测模型,还有很多预测类模型,这里可以简单说下他们各自更加适合的应用场景。
①时间序列预测:
适用场景:气象降雨,交通流量,金融,商业公司的销售经营,医学上的药物反应,各类系统的运作负荷,国民经济市场潜量预测、农作物病虫灾害预报、环境污染控制、天文学和海洋学等方面(个人感觉更适合低维小样本的情况)。
②神经网络预测:一种非线性模型
适用于大样本的预测问题(小样本情况,无论是低维还是高维,不如SVM和贝叶斯模型;大样本量,在低维数据中,不如各种ensemble类算法)
③回归分析预测:
适用场景:样本数量较少,自变量与因变量间的变化具有明显的逻辑关系
④马尔科夫预测:
适用场景:主要用于语音识别、股票预测、环境 质量、文字信息、信息安全等方面,也可以用于市场占有率的预测和销售期望利润的预测以及其他商业领域的预测等
四、算法优缺点
1.优点
①根据过去的变化趋势,通过统计学的方式预测未来,通常符合事物发展的规律;
②在考虑发展趋势的同时,注重季节性和周期性变化对具体时间点的影响,更加准确;
③承认随机变量可能对最终结果造成的影响。
2.缺点
①仅使用时间作为分析因子,未考虑其他因素的影响,分析仍有些片面;
②仅按照历史数据进行预测,未考虑周围因素变化的可能性。
③ARIMA模型对于长期依赖性的时间序列可能表现较差,因此在实际应用中,可能需要结合其他方法,如神经网络或其他时间序列模型,来提高预测性能。
五、算法代码
- clear all
- clc
- data=[10930,10318,10595,10972,7706,6756,9092,10551,9722,10913,11151,8186,6422 ...
- 6337,11649,11652,10310,12043,7937,6476,9662,9570,9981,9331,9449,6773,6304,9355 ...
- 10477,10148,10395,11261,8713,7299,10424,10795,11069,11602,11427,9095,7707,10767 ...
- 12136,12812,12006,12528,10329,7818,11719,11683,12603,11495,13670,11337,10232 ...
- 13261,13230,15535,16837,19598,14823,11622,19391,18177,19994,14723,15694,13248 ...
- 9543,12872,13101,15053,12619,13749,10228,9725,14729,12518,14564,15085,14722 ...
- 11999,9390,13481,14795,15845,15271,14686,11054,10395];
-
- figure %可以用subplot(m,n,p) 将当前图窗划分为 m×n 网格,并在 p 指定的位置创建坐标区(相当于把一页图分成三份,下面的plot占第一份)
- %但是我感觉不如直接用figure,让每个图单独在一页
- plot(data,'b-','LineWidth',1)%画数据,用蓝色的-,且线的宽度为1。
- xlabel('time')
- ylabel('data')
- set(gca,'fontsize',15)%gac返回当前图窗中的当前坐标区,fontsize是设置字体大小(也就是给当前坐标更改字体大小)
-
- figure
- ddata = diff(data);%diff即为差分(对数据进行一阶差分)
- plot(ddata,'b-','LineWidth',1)
- xlabel('time')
- ylabel('data的一阶差分')
- set(gca,'fontsize',15)
-
- figure
- dddata = diff(data,2);%diff即为差分(对数据进行二阶差分),diff(X,2) 与 diff(diff(X)) 相同。
- plot(dddata,'b-','LineWidth',1)
- xlabel('time')
- ylabel('data的二阶差分')
- set(gca,'fontsize',15)
-
- % 数据平稳性测试
- adf=adftest(data)
- %adftest指的是ADF检验,通常在使用时间序列模型(如ARMA,ARIMA)的时候用于检验时间序列数据的平稳性。
- %他主要通过检验数据是否有单位根判断序列是否平稳。(如果返回结果为0,说明不平稳,返回结果为1.说明平稳)
- kpss=kpsstest(data)%同理,这是kpss检验,也是用来检验数据平稳性的。(kpss的结果与ADF刚好相反,kpss返回结果为0,说明平稳)
-
- % 一阶差分并平稳性检验
- ddata = diff(data);
- d1_adf = adftest(ddata)
- d1_kpss = kpsstest(ddata)%返回结果d1_adf为1,d1_kpss为0,则双重验证了数据在一阶差分后,数据变得平稳了,可以进行后续操作
-
-
- % 绘制自相关与偏自相关图
- % 这里要用一阶差分之后的数据绘图(一定要用平稳后的数据)
- figure%subplot(2,1,1),如果想让自相关与偏自相关图在一页图上,就用这个函数。
- autocorr(ddata,40)%第二个参数是表示需要计算的ACF的时间滞后步长(lag)。如果该参数缺省,则取20;如果样本长度小于20,则T取样本长度减1。
- ylabel('ACF')
- set(gca,'fontsize',15)
-
- figure%subplot(2,1,2)
- parcorr(ddata,40)
- ylabel('PACF')
- set(gca,'fontsize',15)
-
- %% 计算pdq取值
- pmax = 4;
- qmax = 4;
- d = 1;
- [p q ]=findPQ(data,pmax,qmax,d);%通过自定函数的不断寻找, 最终找到最为合适的pq值,这里p=3,q=4
-
- %% 构建模型
- Mdl = arima(p, 1, q); %第二个变量值为1,即一阶差分
- EstMdl = estimate(Mdl,data');%estimate函数可以用于参数估计,其中第一个参数是指定的模型,第二个参数是数据样本
- %% 模型预测
- step = 10;%预测接下面的数据个数,一般选10刚好
- [forData,YMSE] = forecast(EstMdl,step,'Y0',data');
- %第一个参数是模型,第二个是预测长度,第三个参数是初始化(固定的),第四个参数是样本数据 ,而返回值中YMSE是预测观测值的误差方差
- %matlab2018及以下版本写为Predict_Y(i+1) = forecast(EstMdl,1,'Y0',Y(1:i));
- lower = forData - 1.96*sqrt(YMSE); %95置信区间下限
- upper = forData + 1.96*sqrt(YMSE); %95置信区间上限
- figure
- plot(1:length(data),data)
- hold on
- plot((length(data)+1):length(data)+step,forData)%数据长度需要加一后再开始预测,不然预测图出不来
- hold on
- plot((length(data)+1):length(data)+step,lower)%在区间内去预测可能出现在上面和下面的情况
- plot((length(data)+1):length(data)+step,upper)%可以再最后一个参数后面加线的颜色和类型,如'r--'。
-
- function [p q] = findPQ(data,pmax,qmax,d)%这是一个用于找pq值的自定函数,用极大似然函数去估计,找出AIC的值,越小说明拟合的越好
- data = reshape(data,length(data),1);
- LOGL=zeros(pmax+1,qmax+1);
- PQ=zeros(pmax+1,qmax+1);
- for p=0:pmax
- for q=0:qmax
- model=arima(p,d,q);
- [fit,~,logL]=estimate(model,data); %指定模型的结构
- LOGL(p+1,q+1)=logL;
- PQ(p+1,q+1)=p+q; %计算拟合参数的个数
- end
- end
- LOGL=reshape(LOGL,(pmax+1)*(qmax+1),1);
- PQ=reshape(PQ,(pmax+1)*(qmax+1),1);
- m2 = length(data);
- [aic,bic]=aicbic(LOGL,PQ+1,m2);
- aic0 = reshape(aic,(pmax+1),(qmax+1));
- bic0= reshape(bic,(pmax+1),(qmax+1));
-
- aic1 = min(aic0(:));
- index = aic1==aic0;
- [pp qq] = meshgrid(0:pmax,0:qmax);
- p0 = pp(index);
- q0 = qq(index);
-
- aic2 = min(bic0(:));
- index = aic2==bic0;
- [pp qq] = meshgrid(0:pmax,0:qmax);
- p1 = pp(index);
- q1 = qq(index);
-
- if p0^2+q0^2> p1^2+q1^2
- p = p1;
- q = q1;
- else
- p = p0;
- q = q0;
- end
-
- end

还有一个用PYTHON的例子:理论加实践,终于把时间序列预测ARIMA模型讲明白了

