
- 1比 Elasticsearch 更快, RediSearch + RedisJSON = 王炸~_redisearch和elasticsearch
- 2在Android中使用WebSocket_android websocket
- 3【华为鸿蒙系统学习】- 如何利用鸿蒙系统进行App项目开发 自学篇_鸿蒙app开发(1)_鸿蒙系统虚拟机app
- 4FAST-LIVO论文翻译_fast livo
- 5区块链的典型应用场景与落地应用案例_可落地的典型应用案例,形成明确可落地的推广计划 区块链 nft
- 6【DevOps】Elasticsearch 数据跨集群同步方案_elasticsearch ccr 开源方案
- 7vscode 仓库,拉取代码时出现 “在签出前请先清理仓库工作树”_vscode在签出前,请清理存储库工作树
- 8隐私计算技术|深度解读可信隐私计算框架“隐语”_隐语secretflow
- 9gitSource 自定义脚本
- 10Python的登录注册界面跳转汽车主页面_python登录后跳转到主界面
DeepSpeed介绍_deepseed zero
赞
踩
1. 概览
1.1 背景(Why)
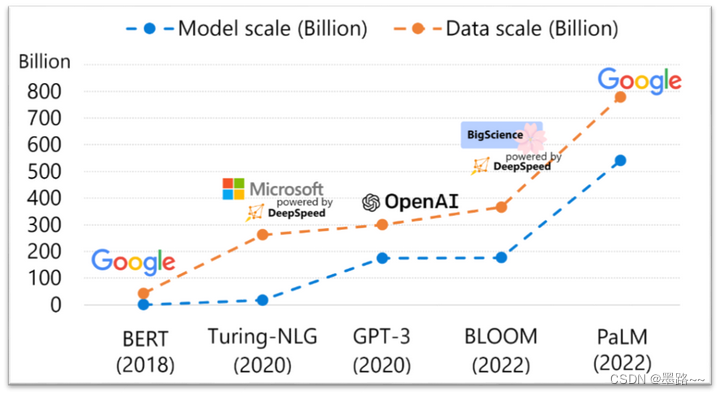
近些年,chatGPT及类似模型引发了人工智能领域的风潮,大小公司想要更轻松、快速、经济的训练和部署自己的类chatGPT模型,但是随着模型越来越大,训练数据规模也越来越大,训练成本随之增加。训练这样的大模型,需要昂贵的多卡多节点GPU集群,硬件资源昂贵。即使拥有了GPU集群,现有的开源系统训练效率对机器利用率低。通常也达不到机器所能达到的最大效率的50%,也就是说更好的资源不代表更高的吞吐量,系统有更好的吞吐量也不一定训练的模型精准率更高,收敛更快,更不能说明这样的开源软件更好用。基于这样的现状,希望拥有一个高效、有效且易于使用的开源系统,帮助开发提高生产力。微软开发的deepspeed框架进入我们的视野。
所谓的高效性、有效性且易于使用指的是:
- 高效性。能够充分利用硬件资源实现高吞吐和可扩展性;
- 有效性。高精度、快速收敛、低成本
- 易于使用。提高开发生产力;
1.2 简介(what)
DeepSpeed是一个由微软开发的开源深度学习优化库,旨在提高大规模模型训练的效率和可扩展性。它通过多种技术手段来加速训练,包括模型并行化、梯度累积、动态精度缩放、本地模式混合精度等。DeepSpeed还提供了一些辅助工具,如分布式训练管理、内存优化和模型压缩等,以帮助开发者更好地管理和优化大规模深度学习训练任务。此外,deepspeed基于pytorch构建,只需要简单修改即可迁移。DeepSpeed已经在许多大规模深度学习项目中得到了应用,包括语言模型、图像分类、目标检测等等。
deepspeed在深度学习模型软件体系架构中所处的位置是?

deepspeed作为一个大模型训练加速库,位于模型训练框架和模型之间,用来提升训练、推理等。
1.3 软件架构
deepspeed主要包含三部分:
Apis。提供易用的api接口,训练模型、推理模型只需要简单调用几个接口即可。其中最重要的是initialize接口,用来初始化引擎,参数中配置训练参数及优化技术等。配置参数一般保存在config.json文件中。
runtime。运行时组件,是deepspeed管理、执行和性能优化的核心组件。如部署训练任务到分布式设备、数据分区、模型分区、系统优化、微调、故障检测、checkpoints保存和加载等。该组件使用python语言实现。
ops。用c++和cuda实现底层内核,优化计算和通信,例如ultrafast transformer kernels, fuse LAN kernels, customary deals等。
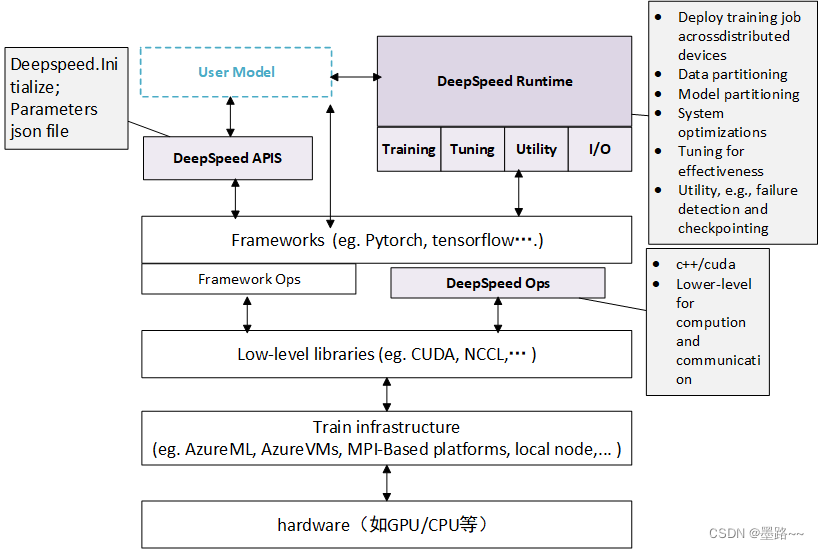 deepspeed 软件架构图
deepspeed 软件架构图
为什么使用这种架构?——架构设计的好处
可以在训练框架上进行两部分(训练和推理分开)优化;
与紧密耦合的结构比,该结构可以更好的利用整个生态,且与深度集成相比,更容易维护;
与基础设置无关,用户可以选择喜欢的平台,如Azure ML、Azure VMs等
2. 核心技术
下面介绍deepspeed的一些核心技术,阐述它如何实现高效性、有效性。
2.1 ZeRO(零冗余优化器)
零冗余优化器(Zero Redundancy Optimizer,缩写为Zero)是一种用于大规模分布式深度学习的新型内存优化技术。ZeRO可以在当前一代GPU集群上以当前最佳系统吞吐量的三到五倍的速度训练具有1000亿个参数的深度学习模型。它还为训练具有数万亿参数的模型提供了一条清晰的道路,展示了深度学习系统技术的前所未有的飞跃。ZeRO作为DeepSpeed的一部分,用于提高显存效率和计算效率。
ZeRO可以克服数据并行和模型并行的局限性,同时实现两者的优点。通过在数据并行进程之间划分模型状态参数、梯度和优化器状态来消除数据并行进程中的内存冗余,而不是复制它们。在训练期间使用动态通信调度来在分布式设备之间共享必要的状态,以保持数据并行的计算粒度和通信量。
ZeRO的三个阶段以及对应功能。
ZeRO有三个主要的优化阶段(如下图所示),它们对应于优化器状态、梯度和参数的划分。
- Optimizer State Partitioning(Pos):减少4倍内存,通信量与数据并行性相同
- 添加梯度分区(Pos+g):减少8倍内存,通信量与数据并行性相同
- 添加参数分区(Pos+g+p):内存减少与数据并行度Nd呈线性关系。例如,在64个GPU(Nd=64)之间进行拆分将产生64倍的内存缩减。通信量有50%的适度增长。
ZeRO消除了内存冗余,并使集群的全部聚合内存容量可用。在启用所有三个阶段的情况下,ZeRO可以在1024个NVIDIA GPU上训练万亿参数模型。像Adam这样具有16位精度的优化器的万亿参数模型需要大约16 TB的内存来保存优化器的状态、梯度和参数。16TB除以1024是16GB,这对于GPU来说是在合理的范围内的。
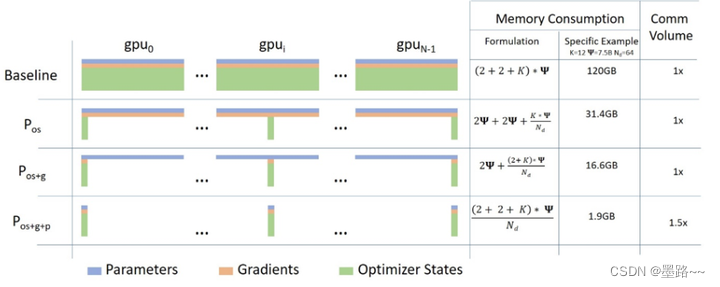 Memory savings and communication volume for the three stages of ZeRO compared with standard data parallel baseline. In the memory consumption formula, Ψ refers to the number of parameters in a model and K is the optimizer specific constant term. As a specific example, we show the
Memory savings and communication volume for the three stages of ZeRO compared with standard data parallel baseline. In the memory consumption formula, Ψ refers to the number of parameters in a model and K is the optimizer specific constant term. As a specific example, we show the
优化1: ZeRO2
它扩展了ZeRO-1,包括减少梯度内存占用,同时还添加了针对激活内存和碎片内存的优化。与ZeRO-1相比,ZeRO-2将DeepSpeed可以训练的模型大小增加了一倍,同时显著提高了训练效率。使用ZeRO-2,1000亿参数模型的训练速度可以比仅基于模型并行性的现有技术快10倍。
优化2:Zero-3 offload
ZeRO-3 offload是ZeRO Stage 3和ZeRO offload相结合的一种高效且易于使用的实施方式,旨在通过向每个人提供高效的大规模深度学习训练来实现人工智能民主化的持续目标。ZeRO-3 offload的主要好处是:
极高的内存效率,可以在有限的GPU资源上运行非常大的模型-例如,在单个GPU上具有超过40B的参数,在512个GPU上具有2万亿的参数的微调模型。
极易使用
扩展到超过一万亿个参数,而不需要以复杂的方式组合多种并行技术。
对于现有的DeepSpeed用户,只需在DeepSpeedConfig文件中使用几个标志即可打开ZeRO-3卸载。
每个GPU的高性能吞吐量和跨GPU的超线性可扩展性,用于分布式训练。
使用1万亿参数,ZeRO-3 Offload在512个NVIDIA V100 GPU上的计算性能可维持25 PetaFlops,实现49 TFlop/GPU。
与ZeRO相比,单个GPU上,ZeRO offload吞吐量增加2倍。
2.2 基于ZeRO的3D并行化实现万亿参数模型训练
DeepSpeed实现了零冗余优化器( Zero Redundancy Optimizer,简称ZeRO)支持的数据并行、流水线并行和张量切片模型并行,并可以灵活组合使用。解决显存效率和计算效率。
数据并行。当模型参数和都较少时,可以在一个CPU上加载所有的数据和模型,但是大模型训练需要大规模的数据集,一张GPU无法存储足够的数据,此时,需要对数据进行分块,放到不同的GPU上进行处理,反向传播后,再通过通信归约梯度,保证优化器在各个机器进行相同的更新。这种方法就是数据并行。该方法的优势是,计算效率高。数据并行的 batch 大小,随 worker 数量提高,但是往往无法在不影响收敛性的情况下,一直增加 batch 大小。
模型并行。数据并行时,每个GPU会加载完整的模型结构,但是如果一个模型参数非常多,一个GPU无法加载所有的参数时,需要对模型进行分层,每个GPU处理一层,该方法就是模型并行。模型并行性的计算和通信因模型结构而异。DeepSpeed借用了英伟达的 Megatron-LM,基于 Transformer 提供大规模模型并行功能。模型并行根据 worker 数量,成比例地减少显存使用量,也是这三种并行度中显存效率最高的。代价是计算效率最低。
流水线并行。流水线并行将模型的各层划分,可以并行处理。当完成一个 micro-batch 的正向传递时,激活内存将被通信至流水线的下一个阶段。当下一阶段完成反向传播时,将通过管道反向通信梯度。必须同时计算多个 micro-batch,确保流水线的各个阶段能并行计算。已经开发出了几种用于权衡内存和计算效率收敛行为的方法,例如 PipeDream。DeepSpeed通过梯度累积来实现并行,保持与传统数据并行和模型并行训练,在相同的总 batch 大小下收敛。
数据并行和模型并行时,会保存模型运行时的全部状态,造成大量的内存冗余,而deepspeed采用的基于ZeRO的3D并行,会极大的优化显存利用效率和计算效率。
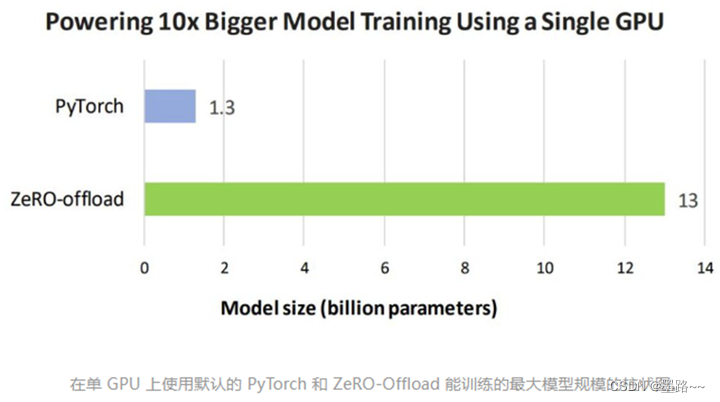
2.3 ZeRO-Offload 使 GPU 单卡,能够训练 10 倍大的模型
ZeRO-Offload能够同时利用 CPU 和 GPU 内存来训练大型模型。核心是将优化器状态和梯度卸到CPU内存中。用户在使用带有单张英伟达 V100 GPU 的机器时,可以在不耗尽显存的情况下,运行多达 130 亿个参数的模型,模型规模扩展至现有方法的10倍,保持有竞争力的吞吐量。此功能使数十亿参数的模型训练,更加大众化。
2.4 通过 DeepSpeed Sparse Attention,用6倍速度执行10倍长的序列
基于注意力的深度学习模型(如transformer)能很好的捕捉输入序列token之间的关系,即使是长距离的。因此,它们与基于文本、图像和声音的输入一起使用,其中序列长度可以以数千个token为单位。然而,实践中,它们在长序列输入中的应用受到注意力计算的计算和内存资源的限制,这些需求随着序列长度n二次增长,即O(n^2)。
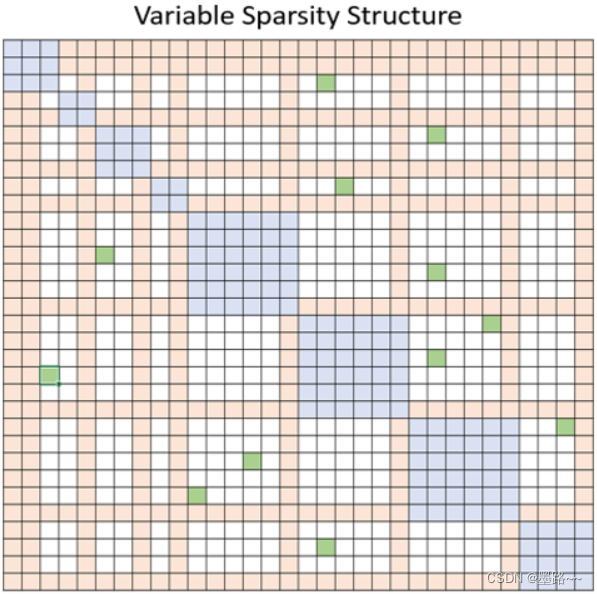
为了解决这一限制,DeepSpeed提供了一套稀疏注意力核(sparse attention kernel),这是一种工具技术,可以通过块稀疏计算将注意力计算的计算和内存需求降低几个数量级。该方法不仅缓解了注意力计算的内存瓶颈,而且可以有效地执行稀疏计算。它的API允许与任何基于transformer的模型进行方便集成。除了提供广泛的稀疏性结构外,它还具有处理任何用户定义的块稀疏结构的灵活性。具体地说,稀疏注意力(SA)可以计算相邻token之间的局部注意力,再通过用局部注意力计算的摘要token来计算全局注意力。此外,SA还可以允许随机注意力,或局部、全局和随机注意力的任何组合,如下图中分别用蓝色、橙色和绿色块所示。因此,SA将内存占用减少到O(wn),其中1<w<n是一个参数,其值取决于注意力结构。
2.5 1 比特 Adam 减少 5 倍通信量,提升 3.4倍的训练速度
Adam 是一个在大规模深度学习模型训练场景下的,有效的(也许是最广为应用的)优化器。与通信效率优化算法往往不兼容。在跨设备进行分布式扩展时,通信开销可能成为瓶颈。推出了一种 1 比特 Adam 新算法,高效实现。该算法最多可减少 5 倍通信量,实现了与Adam相似的收敛率。在通信受限的场景下,观察到分布式训练速度,提升了 3.5 倍,这使得该算法,可以扩展到不同类型的 GPU 群集和网络环境。
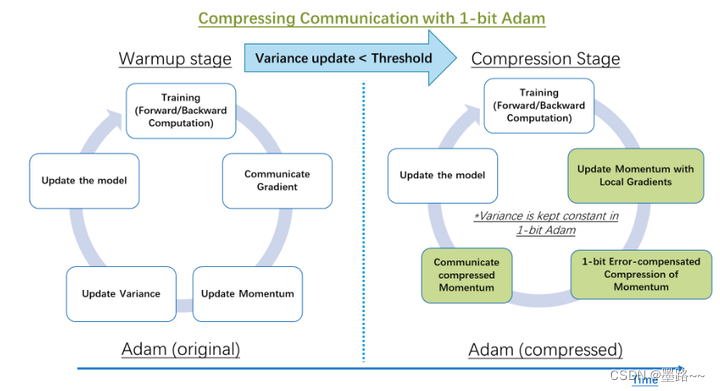 Comparison of distributed training steps in classic Adam and the proposed 1-bit compressed Adam algorithm
Comparison of distributed training steps in classic Adam and the proposed 1-bit compressed Adam algorithm
3 如何使用
3.1 安装前须知
在安装DeepSpeed之前之前必须安装pytorch(推荐使用版本>=1.9)
需要CUDA或ROCm编译器,如nvcc或hipcc,用于编译C++ / CUDA / HIP扩展。
DeepSpeed最完整的测试在以下GPU上进行:NVIDIA:Pascal、Volta、Ampere和Hopper架构,AMD:MI100和MI200
3.2 安装
pip install deepspeed
安装完成后,可以通过DeepSpeed环境报告验证安装并查看计算机与哪些扩展/操作兼容
ds_report
3.3 模型训练
1.初始化引擎。初始化分布式环境、分布式数据并行、混合精度训练设置等。可以根据配置文件参数构建和管理训练优化器、数据加载器和学习率调度器

2. 训练。引擎初始化后,即可通过3个api训练模型,用于前向传播、后向传播和权重更新。
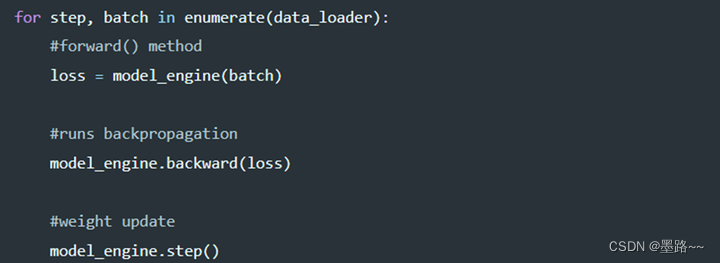 deepspeed训练模型代码简单实现
deepspeed训练模型代码简单实现
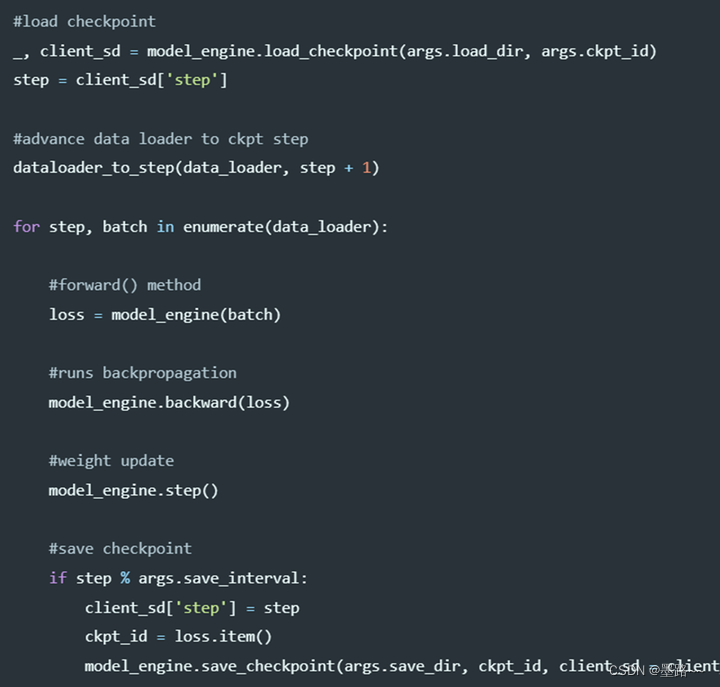
训练中,模型保存和加载训练状态checkpoints通过save_checkpoint和load_checkpoint函数。函数主要涉及两个参数:
•ckpt_dir: checkpoints保存的文件;
•ckpt_id:唯一标识checkpoints的标识符。代码中以loss值作为ckpt_id
DeepSpeed可以自动保存和恢复模型、优化器和学习率调度器状态。用户如果想要保存模型训练的其他数据,客户端状态字典client_sd进行保存。
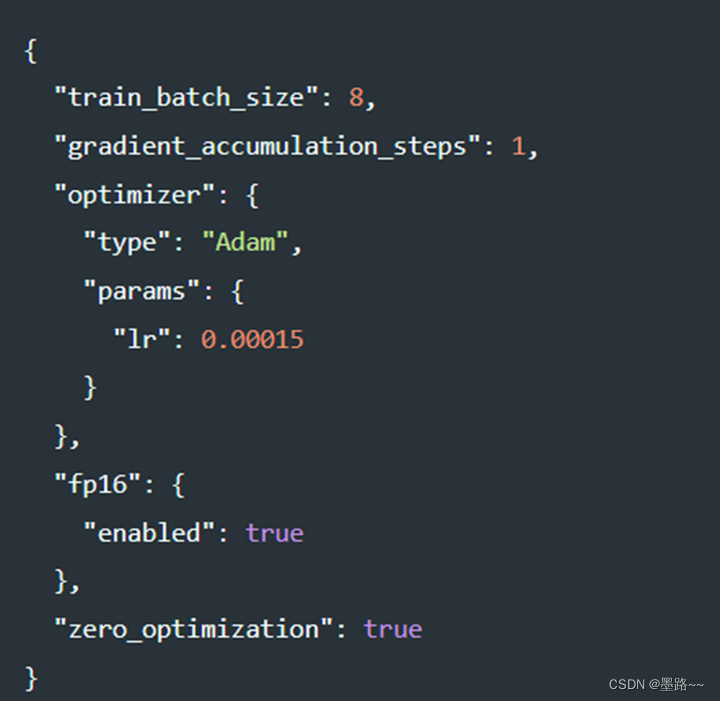
对于训练过程中的配置参数,可以通过配置文件configjson文件决定某个功能是否启用,如下图中,设置batch_size大校,梯度累积的步数、优化器类型、学习率、训练精度、是否使用零冗余优化等。
3. 启动训练程序
对于多机环境,DeepSpeed使用hostfile配置多节点计算资源。hostfile是主机名(或SSH别名)列表,这些机器可以通过无密码SSH访问,以及槽计数,指定系统上可用的GPU数量。
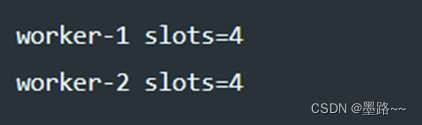 指定名为worker-1和worker-2的两台机器各有四个GPU可用于训练。
指定名为worker-1和worker-2的两台机器各有四个GPU可用于训练。
使用以下命令启动模型训练。在myhostfile中指定的所有可用节点和GPU上启动PyTorch训练 。

其中,client_entry.py是模型的入口脚本,client_args是argparse命令行参数 ,ds_config.json是DeepSpeed的配置文件。
对于多节点环境,跨多个节点进行训练时,支持用户定义的环境变量。默认情况下,DeepSpeed将传播所有已设置的NCCL和PYTHON相关环境变量。如果要传播其他变量,则可以在.deepspeed_env文件中指定(key=value)。如下图中设置NCCL_IB_DISABLE设置为1,NCCL_SOCKET_IFNAME = eth0

对于单节点环境,仅在一个节点(一个或多个 GPU)运行时,不需要添加hostfile ,自动查询本地计算机上的GPU数量和可用槽数。用户需要把“localhost”指定为主机名。注意: CUDA_VISIBLE_DEVICES不能与DeepSpeed一起使用以控制应使用哪些设备。
例如,只使用当前节点的gpu1,用以下命令启动:
deepspeed –include localhost:1 client_entry.py
也可以使用以下命令,指定GPU为worker-2, 0和1卡,

3.4 模型推理
(1)使用init_inference API来加载模型进行推理。
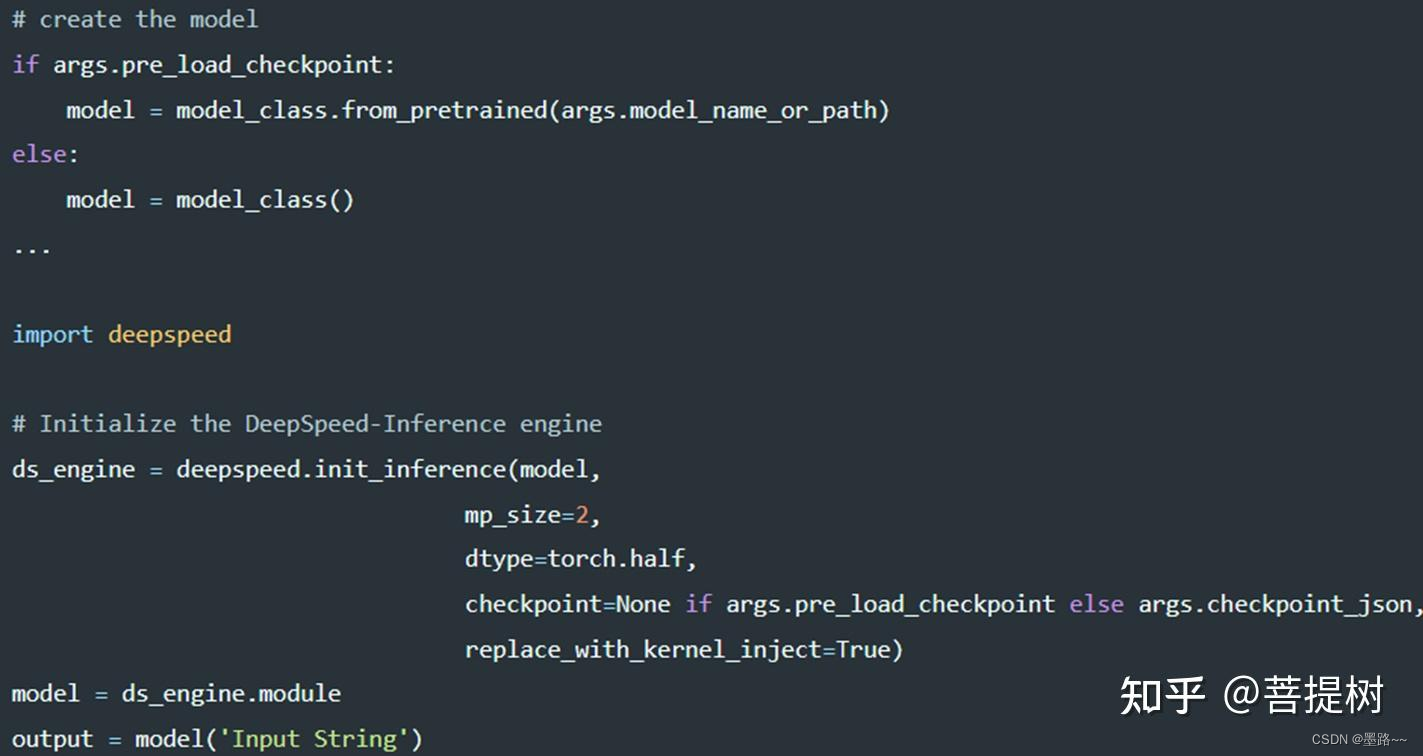 deepspeed进行模型推理实现
deepspeed进行模型推理实现
推理时,可以在初始化接口参数中,(1)指定MP度,(2)如果模型没有使用检查点加载,也可以使用json文件或检查点路径提供检查点描述,(3)注入高性能内核,设置replace_with_kernel_inject=True(兼容模型)等。
此处,对于能够用deepspeed训练的模型【Megatron-Turing NLG (530B)、Jurassic-1 (178B)、BLOOM (176B)、GLM (130B)、YaLM (100B)、GPT-NeoX (20B)、AlexaTM (20B)、Turing NLG (17B)、METRO-LM (5.4B)】才能用replace_with_kernel_inject=True设置注入高性能内核加速推理。对于deepspeed目前不支持的模型,用户可以提交一个PR,定义一个在replace_policy类中指定层的不同参数(例如注意力和前馈部分)的新策略。通过注入策略实现不支持的模型加速推理。以下展示了如何使用T5模型与deepspeed-inference:
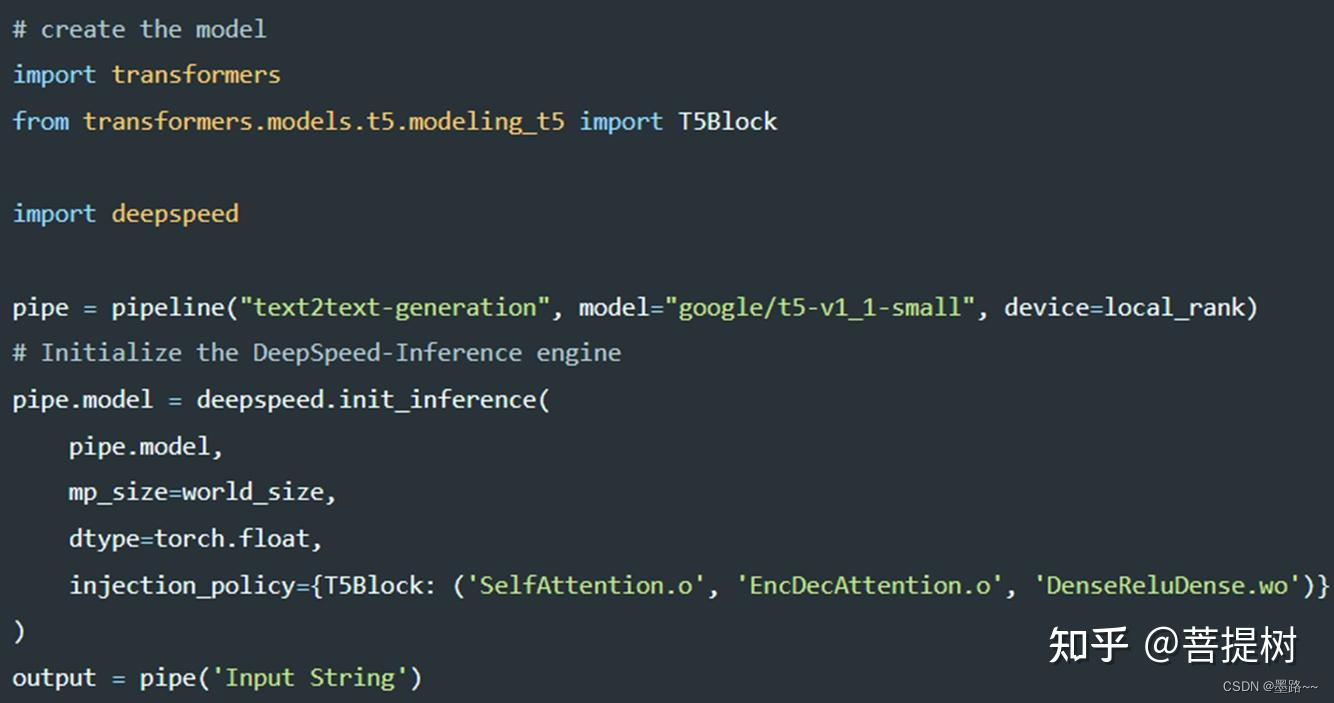
使用deepspeed推理T5模型实现文本生成任务
对于HuggingFace训练的模型,可以用from_pretrained API预加载模型checkpoints。对于使用模型并行训练的Megatron-LM模型,我们需要在JSON模型并行检查点的列表。配置中需要传递所有的checkpoints.
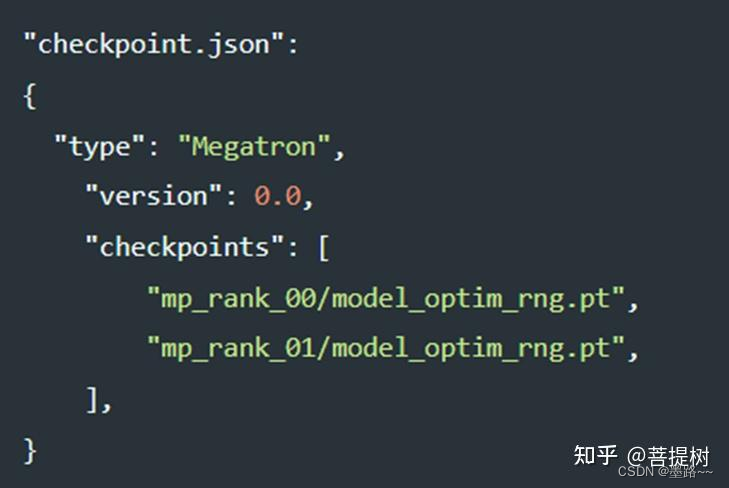
加载MP=2训练的Megatron-LM checkpoint
对于DeepSpeed训练的模型,checkpoint.json只要求提供checkpoint保存路径,见下图:
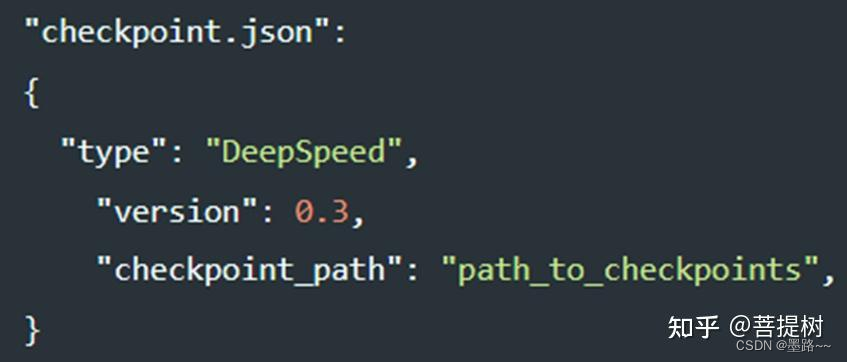
添加图片注释,不超过 140 字(可选)
(2)启动推理模型:

推理代码启动脚本
3.5 DeepSpeed与Huggingface结合使用
pytorch训练的模型也可以使用deepspeed加速推理。将DeepSpeed推理与HuggingFace pipeline结合使用,给出GPT-NEO-2.7B模型生成文本的端到端客户端代码:
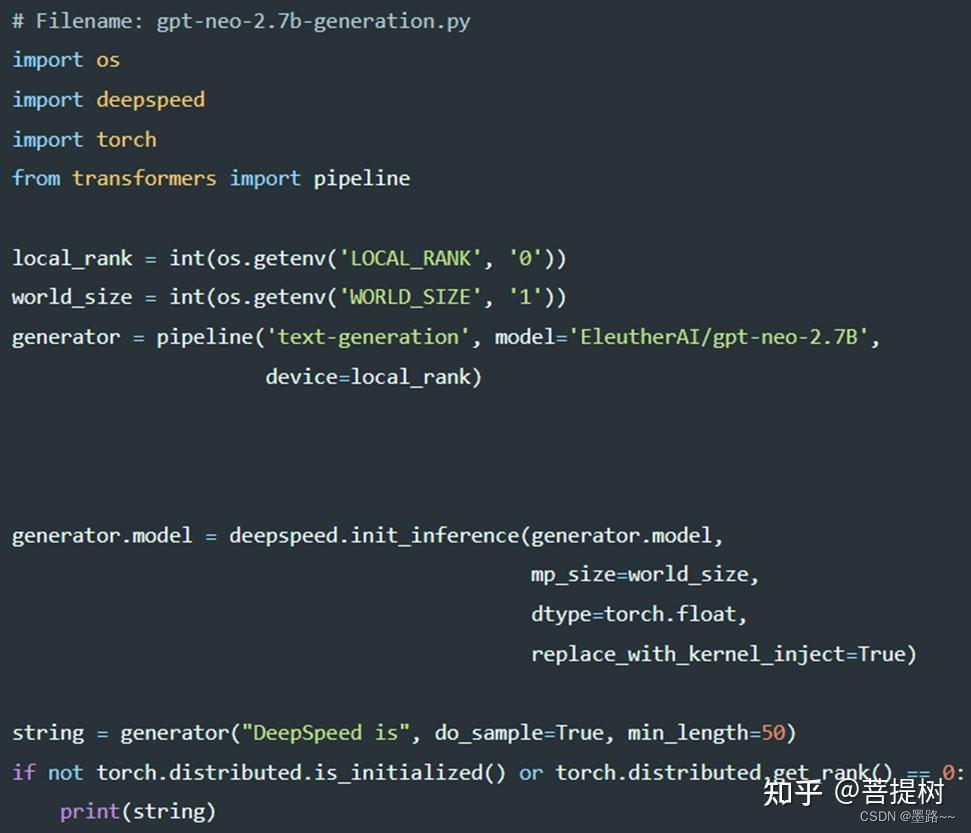 deepspeed与pytorch联合使用实现过程
deepspeed与pytorch联合使用实现过程
运行脚本:

输出结果:

结果展示
3.6 实例:基于pytorch和DeepSpeed实现bert和GPT对比
3.6.1 DeepSpeed Models: BERT
之前使用pytorch训练深度学习模型bert时的伪代码:
#Construct distributed model model= BertMultiTask() model = DistributedDataParallel(mode1) ….. # Construct FP16 optimizer optimizer = FusedAdam(mode1_parameters,…) optimizer = FP16_Optimizer(optimizer,...) # Forward pass loss = model(batch) # Backward pass Optimizer.backward(loss) # Parameter update optimizer.step() 使用pytorch训练深度学习模型bert时的伪代码: #Construct distributed model model= BertMultiTask() ….. # Construct FP16 optimizer model, optimizer, _ ,_=deepspeed.initialize( args=args, model=model, model_parameters=model_parameters) # Forward pass loss = model(batch) # Backward pass model.backward(loss) # Parameter update model.step()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
3.6.2 DeepSpeed Models: GPT2
之前使用pytorch训练深度学习模型GPT2时的伪代码:
#Construct distributed model model = GPT2Model(num_layers=args.num_ayers,...) model=FP16_Module(model) model = DistributedDataParalle(model,...) ... # Construct FP16 optimizer optimizer = FusedAdam(mode1_parameters,…) optimizer = FP16_Optimizer(optimizer,...) # Forward pass loss = model(batch) # Backward pass Optimizer.backward(loss) # Parameter update optimizer.step() 使用pytorch训练深度学习模型bert时的伪代码: #Construct gpt model model= GPT2Mode1(num_layers=args ,num_ayers,...) ... # Construct Adam optimizer optimizer = Adam(param_groups,..) # wrap mode1, optimizer , and 1r model,optimizer,r_scheduler,- = deepspeed.initialize( args=args,model=model,optimizer=optimizer, Ir_scheduler=Ir_scheduler,mpu=mpu) # Forward pass output = model(tokens,...) # Backward pass model.backward(loss) # Parameter update model.step()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
4. 性能分析
(1)模型规模
从模型规模看,使用了Zero-offload技术的deepspeed库可以训练10倍大的模型。用户在使用带有单张英伟达 V100 GPU 的机器时,可以在不耗尽显存的情况下,运行多达 130 亿个参数的模型,模型规模扩展至现有方法的10倍,保持有竞争力的吞吐量。此功能使数十亿参数的模型训练,更加大众化。
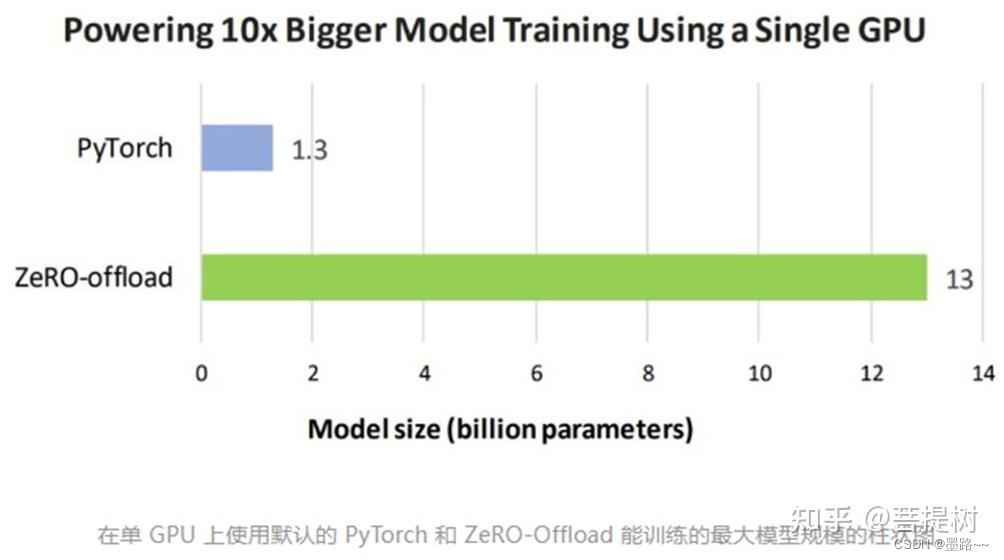
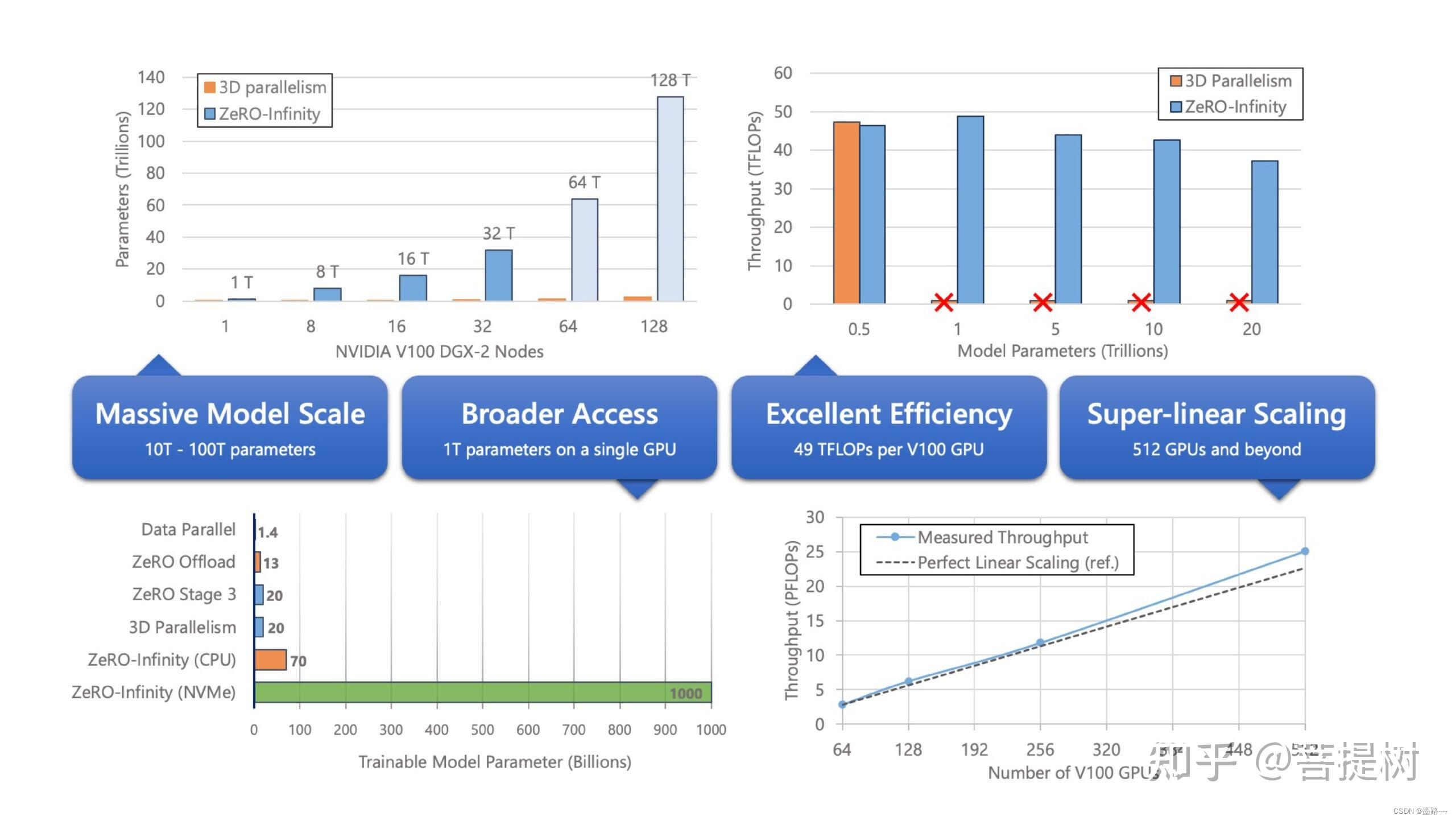
图片来源:https://www.microsoft.com/en-us/research/uploads/prod/2021/04/1400x788_deepspeed_update_figure_nologo_Still-1-scaled.jpg
根据上图可以看出,(左上图)NVIDIA V100 GDX-2卡的节点上,不同数量的节点,与3D并行相比,使用ZeRO-Infinity能够支持的模型参数量更大,且随着节点数增加,差距越明显。(右上图)展示了ZeRO Infinity在512个NVIDIA V100 GPU上为数十亿和数万亿参数模型提供了超过25 PB的持续性能,具有卓越的训练效率。模型size为500B时的效率可与最先进的3D并行相媲美。与ZeRO Infinity不同,由于GPU内存限制,3D并行无法扩展到具有数万亿参数的模型,超过1T的模型就会内存溢出,而ZeRO-Infinity能够支持模型参数量到20T。(左下图)同样显示使用deepspeed中不同优化库技术时,可支持的训练的模型参数量。(右下图)显示,随着GPU集群规模的扩展,deepspeed在吞吐量上实现了近线性扩展。
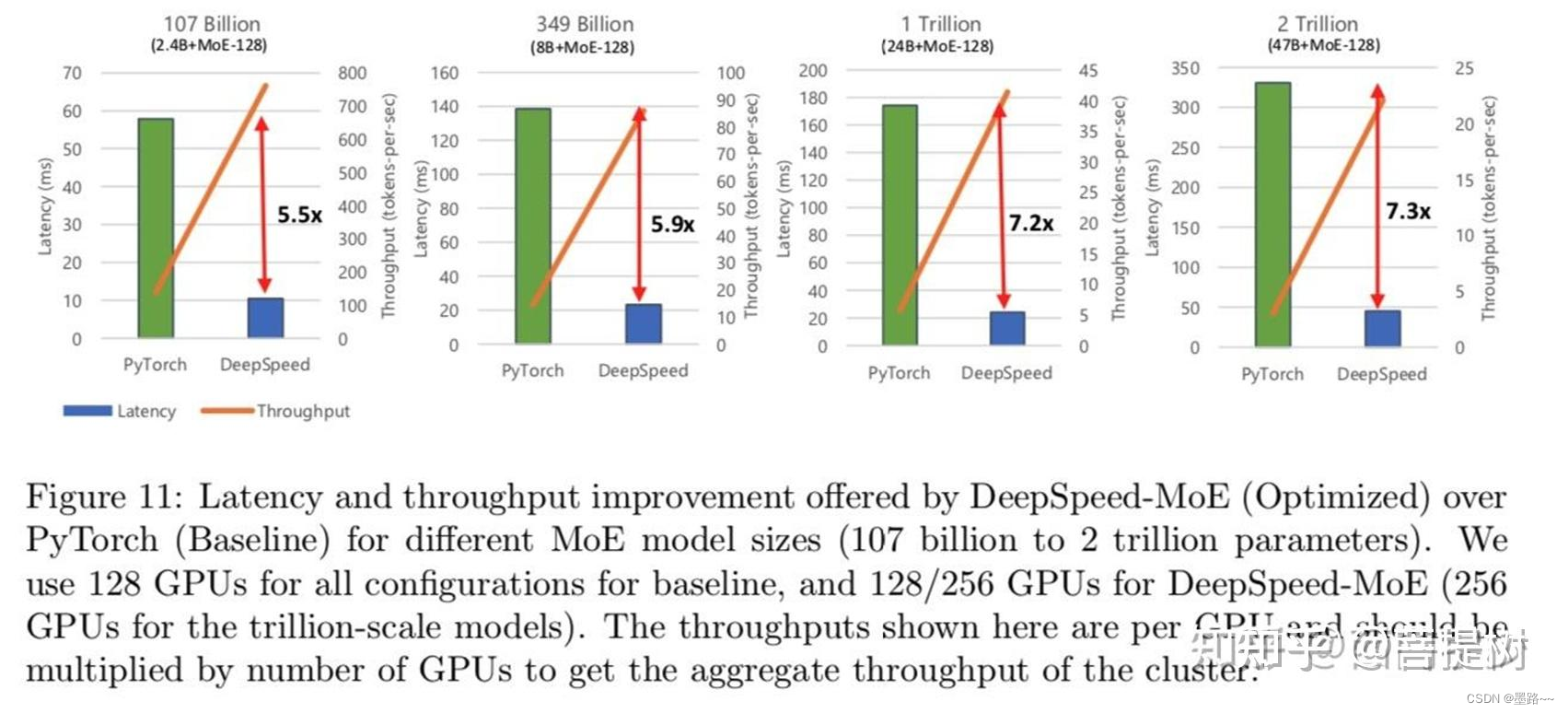
图片来源网络,侵删
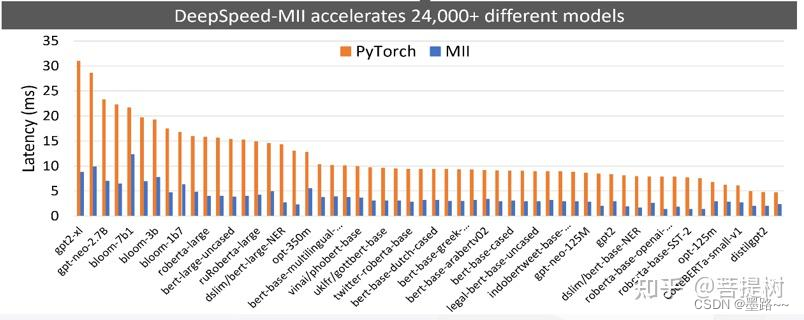
上图中,同样也可以看出,与pytorch相比,deepspeed推理延迟加快了约6倍(前2图),吞吐量增加7x+。
(2)速度
从速度看,在GPT家族中的选择40B-170B参数的大模型,超过25B参数的大模型,DeepSpeed比baseline加速了10x多。
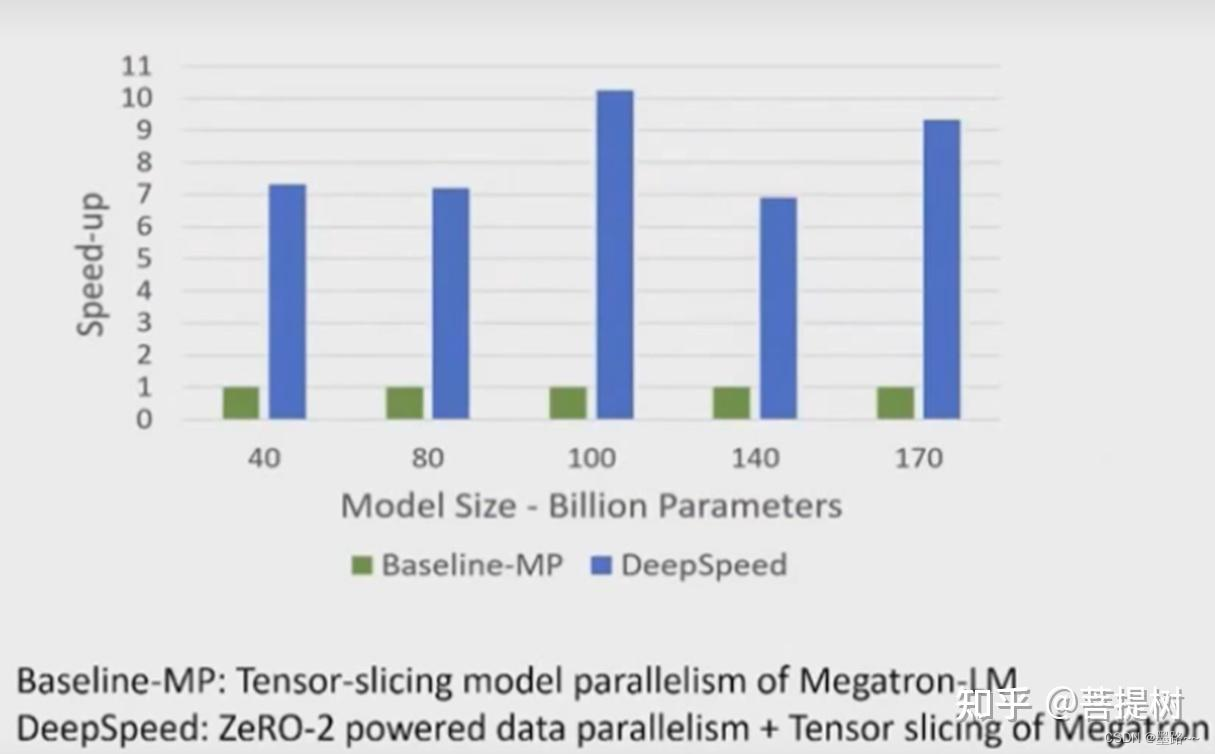
(3)扩展性
扩展性角度看,小规模上实现了超线性扩展,在较大规模时实现了近线性或次线性扩展。因为,内存可用性和最大全局batch大小之间的相互作用。从下图可以看出,在小规模
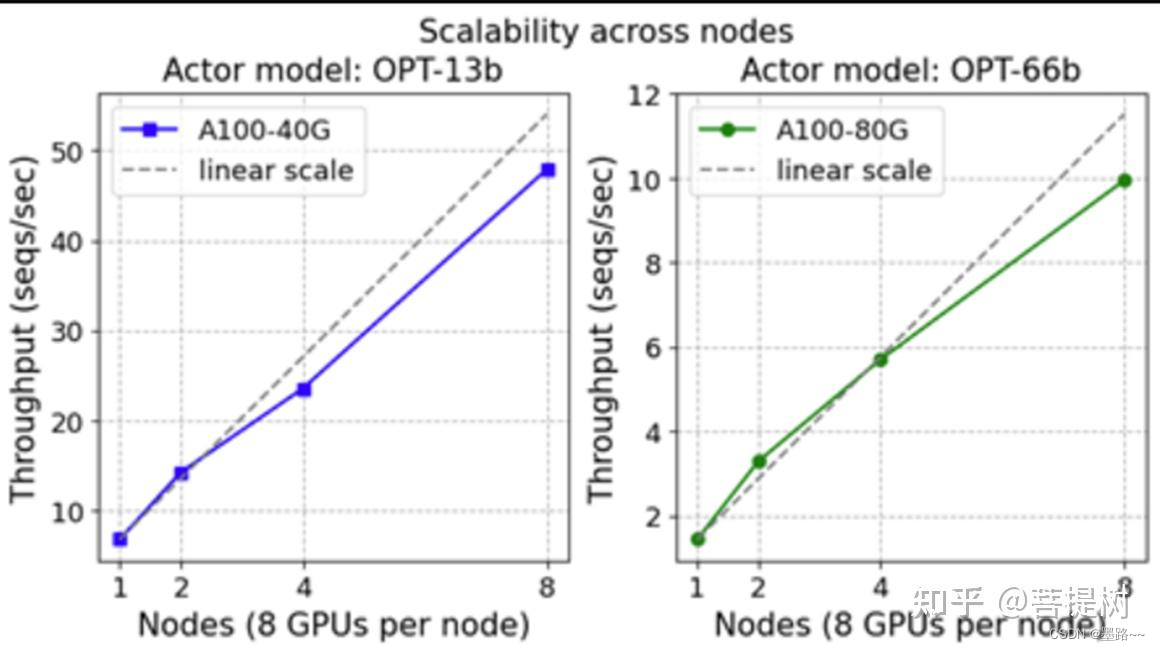
在不同数量的DGX (A100-40/80G GPU) 节点上,进行13B(左)和66B(右)actor 模型 和 350M reward 模型的可扩展性训练
上图显示 DeepSeed-RLHF 在多达 64 个 GPU的集群 上实现了良好的整体扩展。然而,如果我们仔细观察,可以发现 DeepSpeed-RLHF 训练在小规模时实现了超线性扩展,随后在较大规模时实现了接近线性或次线性扩展。这是由于内存可用性和最大全局批量大小之间的相互作用。
DeepSpeed-HE 的核心技术基于 ZeRO,用于训练过程中将模型状态分割到每个GPU上。这意味着随着 GPU 数量的增加,每个 GPU 的内存消耗会减少,使得 DeepSpeed-HE 能够在每个 GPU 上支持更大的批量,从而实现超线性扩展。然而,在大规模情况下,尽管可用内存持续增加,但最大全局批量大小仍然限制了每个 GPU 的批量大小,导致接近线性或次线性扩展。因此,在给定的最大全局批量大小(例如,我们设置为 1024 个句子,每个句子长度为 512)下,DeepSpeed-HE 在超线性和次线性可扩展性之间实现了最佳的吞吐量和成本效益。具体的平衡点主要取决于每个 GPU 上可运行的最大批量大小,而这又受到可用内存和全局批量大小的函数所决定。
(4)吞吐量
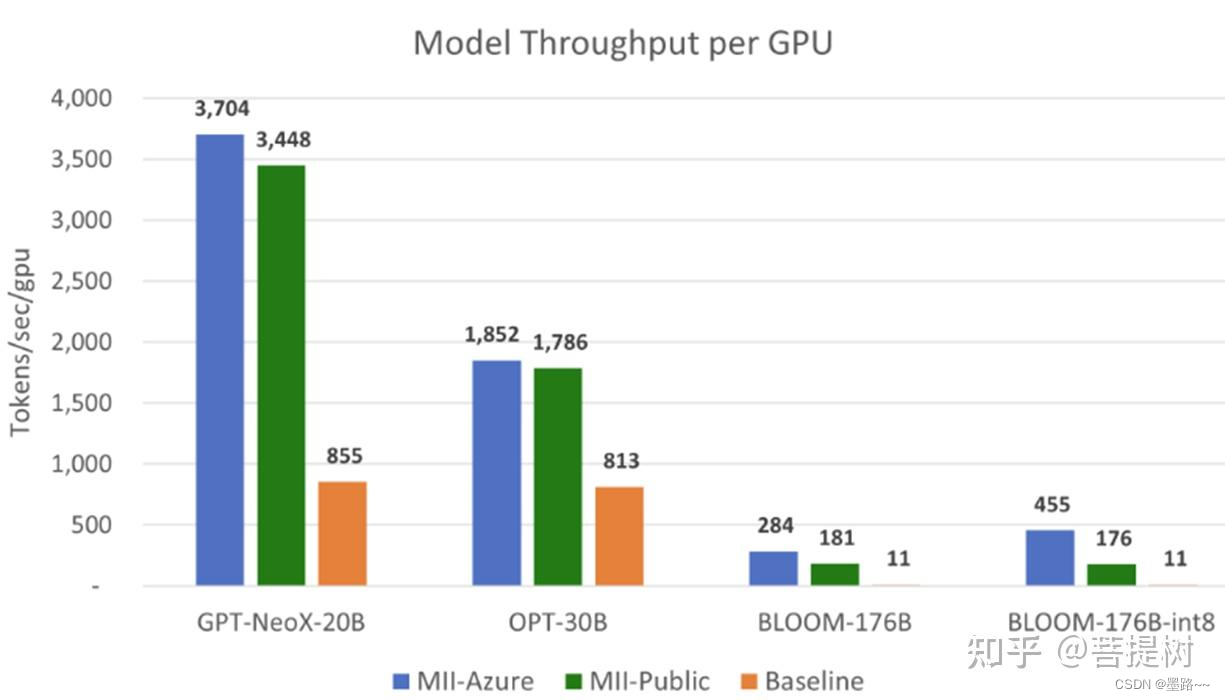
Throughput comparison per A100-80GB GPU for large models. MII-Public offers over 15x throughput improvement while MII-Azure offers over 40x throughput improvement
与baseline相比,MII-Public分别提供了超过15倍的吞吐量提高,MII-Azure提供了超过30倍的吞吐量。
(5)推理延迟
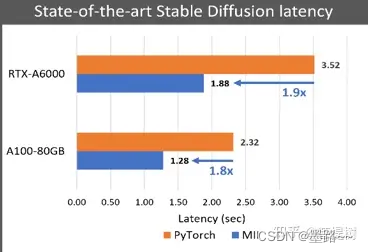
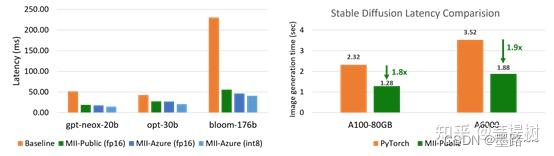 (left) Best achievable latency for large models. MII-Azure (int8) offers 5.7X lower latency compared to Baseline for Bloom-176B. (right) Stable Diffusion text to image generation latency comparison
(left) Best achievable latency for large models. MII-Azure (int8) offers 5.7X lower latency compared to Baseline for Bloom-176B. (right) Stable Diffusion text to image generation latency comparison
(图左)使用如Bloom、 OPT和NeoX等庞大模型进行文本生成时,多GPU推断延迟降低高5.7倍,(图右)使用Stable Diffusion的图像生成任务,模型生成时间延迟降低约1.9倍。
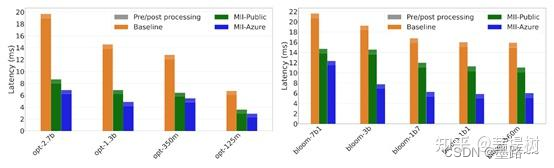
编辑
Latency comparison for OPT and BLOOM models. MII-Azure is up to 2.8x faster than baseline.
基于OPT、BLOOM和GPT架构的相对较小的文本生成模型(7B参数),在单个GPU上运行时延迟降低高达3倍
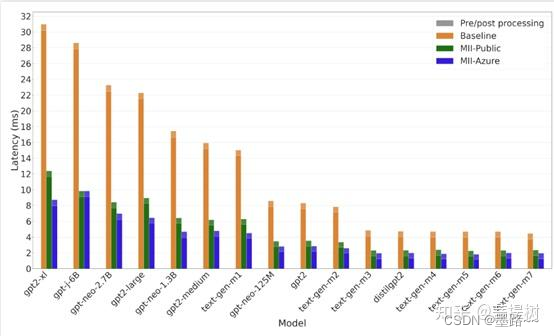
Latency comparison for GPT models. MII-Azure is up to 3x faster than baseline.
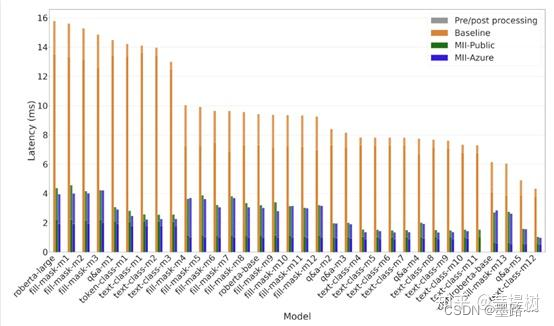 Latency comparison for RoBERTa models. MII offers up to 9x lower model latency and up to 3x lower end-to-end latency than baseline on several tasks and RoBERTa variants 1
Latency comparison for RoBERTa models. MII offers up to 9x lower model latency and up to 3x lower end-to-end latency than baseline on several tasks and RoBERTa variants 1
使用基于RoBERTa和BERT的模型进行各种文本表示任务,如填充掩码、文本分类、问答和标记分类,延迟降低高达9倍(见上2张图)。
(6)成本
在Azure上使用MII生成1Mtokens成本降低40倍。MII(Model Implementations for Inference)是DeepSpeed的一个新的开源Python库,旨在使大模型的低延迟、低成本推断不仅可行而且易于访问。

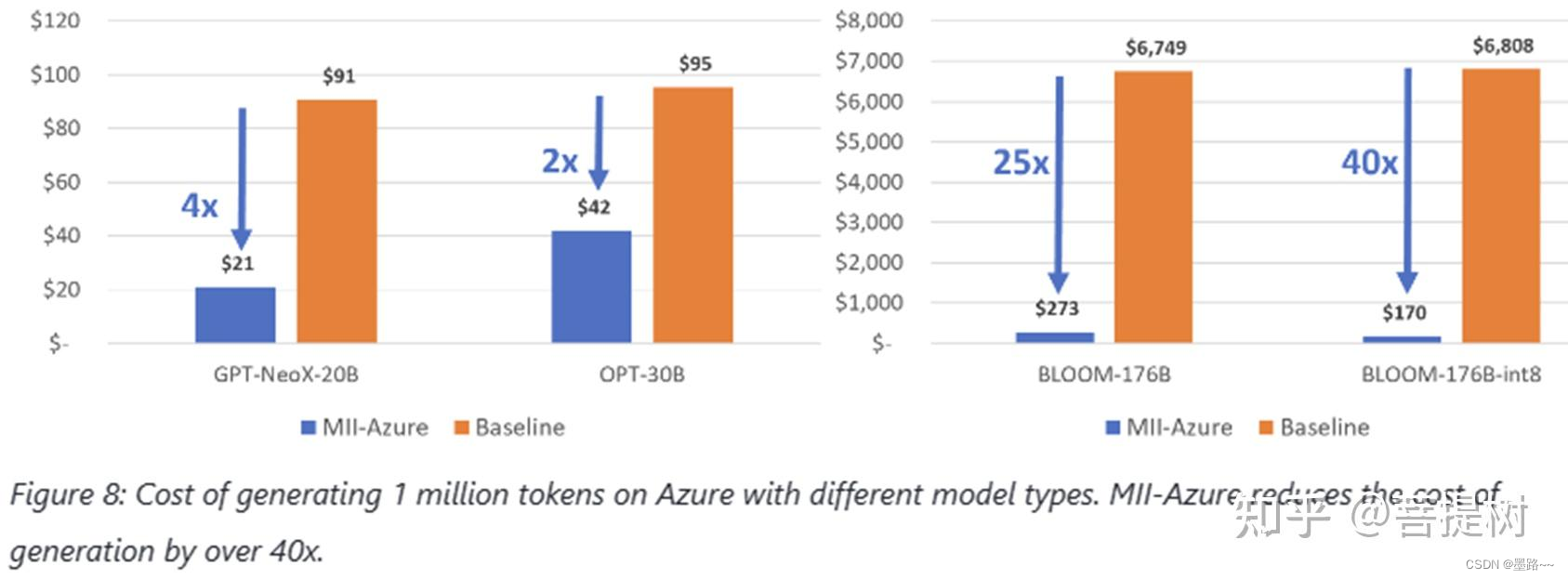
与baseline相比,MII-Azure推理GPT-nex和bloom降低了超过40倍的成本
(7)模型压缩
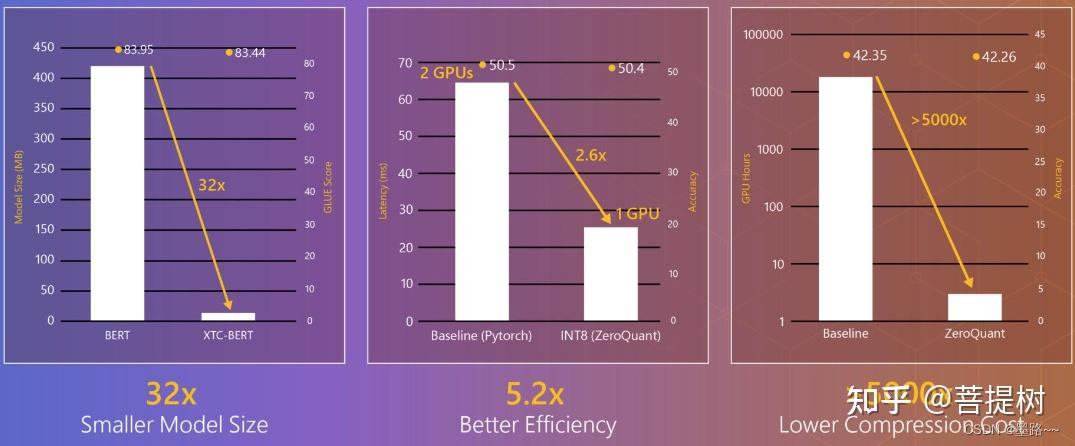 https://www.microsoft.com/en-us/research/blog/deepspeed-compression-a-composable-library-for-extreme-compression-and-zero-cost-quantization/
https://www.microsoft.com/en-us/research/blog/deepspeed-compression-a-composable-library-for-extreme-compression-and-zero-cost-quantization/
从上图可以看出,DeepSpeed通过提供的先进压缩技术,XTC可以将模型尺寸缩小32倍,ZeROQuant可以将压缩成本降低5000倍,单个GPU平均提升2倍效率。
5. 优势/特点
存储效率。提供一种称为Zero Redundancy Optimizer(ZeRO)的新型解决方案来减少训练内存占用, ZeRO与基本的数据并行不同,其中内存状态在数据并行进程之间复制,ZeRO将模型状态和梯度进行分区以节省大量内存。此外,它还减少了激活内存和碎片内存。当前的实现(ZeRO-2)相对于现有技术可将内存减少多达8倍。ZeRO-Offload:利用CPU和GPU内存来训练大型模型,使用一台单个GPU的机器,可以运行>130亿参数的模型,而不会耗尽内存,比现有方法大10倍,同时有很好的吞吐量。
可扩展性。 DeepSpeed支持高效的数据并行、模型并行、管道并行及它们的组合,我们称之为3D并行。
通信效率。pipline并行减少了分布式训练期间的通信量,使用户可以在网络带宽有限的集群上以2-7倍的速度训练数十亿参数的模型。1-bit Adam、0/1 Adam和1-bit LAMB可将通信量减少多达26倍,同时实现与Adam相似的收敛效率,使其能够扩展到不同类型的GPU集群和网络。
数据效率。通过课程学习提供高效的数据采样,通过随机分层令牌丢弃提供高效的数据路由。这种组合的解决方案可以在GPT-3/BERT预训练和GPT/ViT微调期间节省2倍的数据和时间,或在相同的数据/时间下进一步提高模型质量。
支持长序列 。提供一种稀疏注意力内核技术,与经典稠密的Transformer相比 ,可以支持长达一个数量级的输入序列,速度快6倍,准确度与原来相当。它还优于最先进的稀疏实现,执行速度提升1.5-3倍。
快速收敛以提高效率。支持先进的超参数调整和大批量大小优化器,如LAMB,以提高模更快型训练的效果,并减少达到所需精度所需的样本数量。
**易用性。**仅需要修改几行代码即可使PyTorch模型使用DeepSpeed和ZeRO。
6. 参考文献
[1] microsoft/DeepSpeed
[2] DeepSpeed-MII: instant speedup on 24,000+ open-source DL models with up to 40x cheaper inference
[3]ZeRO & Fastest BERT: Increasing the scale and speed of deep learning training in DeepSpeed
[4]ZeRO-Inference: Democratizing massive model inference
[5][译] DeepSpeed:所有人都能用的超大规模模型训练工具
[6] ZeRO & DeepSpeed: New system optimizations enable training models with over 100 billion parameters

