
- 1代码随想录算法训练营第六天|242.有效的字母异位词、349. 两个数组的交集、202. 快乐数、1. 两数之和
- 2接口测试必备的,2种常⽤的JSON解析⽅法_测试json接口
- 3鼠标滚轮失灵怎么办?电脑用户必备教程(4个方法)_鼠标滚轮上下失灵修复小技巧
- 4解决浏览器滚动条导致的页面闪烁问题_macchrome浏览器滑动闪屏
- 5【C++风云录】进化计算框架全览:遗传算法与优化_演化算法通用框架
- 6【ChatGPT】比尔·盖茨最新分享:ChatGPT的发展,不止于此_盖茨博客 chatgpt
- 7微信营销和微博营销有什么不同_微信营销和微博营销的区别
- 8网上竞拍系统-数据库大作业_网上拍卖系统数据库设计
- 9springboot学习02-[热部署和日志]
- 10Mac OS下Docker的安装与配置_mac安装docker以及配置
数据结构-二叉树-总结_二叉树的作用
赞
踩
二叉树的作用
下文参考博客二叉树应用
常见的二叉树:二叉查找树,平衡二叉树(AVL),红黑树,字典树,满二叉树,完全二叉树,霍夫曼树,伸展树,最小堆,最大堆等,B+树,B-树则属于多路搜索树。
二叉树应用非常广泛。
在操作系统源程序中,树和森林被用来构造文件系统。我们看到的window和linux等文件管理系统都是树型结构。在编译系统中,如C编译器源代码中,二叉树的中序遍历形式被用来存放C 语言中的表达式。其次二叉树本身的应用也非常多,如哈夫曼二叉树用于JPEG编解码系统(压缩与解压缩过程)的源代码中,甚至于编写处理器的指令也可以用二叉树构成变长指令系统,另外二叉排序树被用于数据的排序和快速查找。
总的来说就是优化了时间或者空间复杂度
目录
3.1.4 二叉树最大深度-涉及两种回溯的处理模板(!!!)
3.1.5 二叉树最小深度-涉及两种回溯以及是否将递归处理nullptr
4.4.4 寻找重复子树-后序遍历+序列化(关于将参数放入递归进行处理的理解)
(缺)5.3.2 计算序列能够构建多少种搜索二叉树-动态规划添加备忘录(先写一个超时版本)
(缺) 5.3.3 计算种数并返回所有二叉树-(动态规划部分)
一、二叉树整体思路汇总(这个思路至关重要!!!!)
以上思路为递归法的思路,如果想用迭代法求解,只需要保证能够写出遍历递归后用栈或者队列(涉及层序)将其改为迭代就行
1、是否可以通过遍历一遍二叉树得到答案?
如果可以,用一个 void traverse函数配合外部变量或者内部变量来实现,这叫「遍历」的思维模式。
2、是否可以定义一个递归函数,通过子问题(子树)的答案推导出原问题的答案?
如果可以,写出这个递归函数的定义,并充分利用这个函数的返回值,这叫「分解问题」的思维模式。
这个思路是类似通解的思路,有些题存在一些比较巧妙的做法不归入其中,但绝大多数题目都能用这种思想解决
1.1 递归的要点
1.默认递归函数能够实现我们想要的功能,不去思考为什么能实现,不然会把自己绕晕
2.只思考当前处理的部分,我们把当前位置处理好了,其他位置递归函数会帮我们自动解决
3.一般递归的写法中重要的有三(分解问题有四点)点:终止条件,节点操作,递归部分,返回值(分解问题)
注:后面随着做题发现,两类做法并没有区分的很明显,很多时候要相互融会贯通才行
1.1 递归法-遍历(思路待补充)
先说结论:一般不能直接通过分解问题求解的问题就使用遍历解决
我们要找准遍历的位置是遍历法的前提,要知道在哪里遍历可以解决问题,那么我们首先需要知道每个位置遍历的差别,我们只考虑当前节点,前中后序就表示未处理子树,正在处理子树,已经处理结束子树
那么其实思路和分解子问题比较像,以不好理解的后序为例:
先在left和right中遍历了,然后将root接在遍历的后面就是后序了
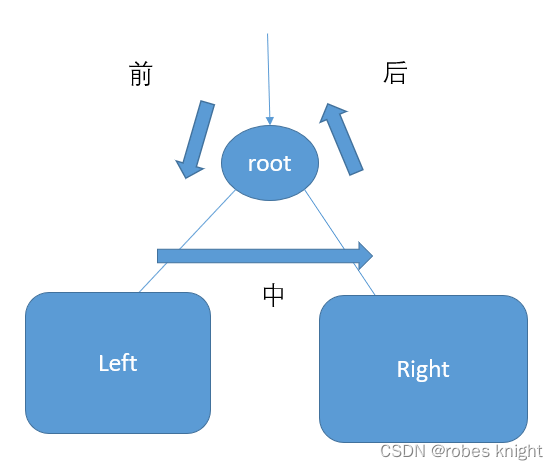
下图为个各个节点的前中后序遍历位置
1.终止条件
1.2 递归法-子问题分解
1.终止条件:
一般终止条件只需要判断当前节点是否为空即可
if(!root)return nullptr;传入的数组的话可以判断数组为空
if(nums.empty()) return nullptr;终止条件是递归的开始,必须得有终止条件
2.节点操作:
我们是否要添加额外的节点操作,取决于子函数的返回值是否够用,如果不够用需要添加额外操作
例如子函数是创建子树,那么我们需要额外定义一个root节点来接收创建的子树
- TreeNode* root = new TreeNode(*maxnum);
- vector<int> l(nums.begin(), nums.begin() + maxid);
- root->left = constructMaximumBinaryTree(l);
- vector<int> r(nums.begin() + maxid + 1, nums.end());
- root->right = constructMaximumBinaryTree(r);
当我们发现不加入节点操作,且其他部分都写完了,但是递归值在递归过程中无法发生变化时,也需要加入节点操作。
3.递归部分:
一般来说都是直接将当前节点的左右子树分别放入两个递归函数中就行(有可能会添加一些节点外的输入),左右操作是一样的且连贯
注意:由于终止条件是必须的,所以我们一般都会将nullptr放入递归函数中,不会设置if(root->left)之类的判断,这会使得终止条件很好写出。不把nullptr放入递归函数的话,终止条件就会更复杂
- TreeNode* left = invertTree(root->left);
- TreeNode* right = invertTree(root->right);
但也会存在特殊情况(很少,这种一般用遍历更好做)
如在求左叶子和的时候,我们不能对两边同时操作,需要判断左子树是不是叶子,是的话就拿到left->val,如果不是在放入递归函数中
但是由于此处判断是否为叶子时有一个if(root->left)判断,这是我们不希望对递归函数执行的操作,因此将判断放在左子树递归的后面,val可以覆盖l的值;
- l = sumOfLeftLeaves(root->left);
- if(root->left)if(!root->left->left && !root->left->right)l = root->left->val;
- r = sumOfLeftLeaves(root->right);
4.返回值:
依照后序遍历的原则,我们观察将两子树的返回值如何处理能够得到正确返回值,从而确定当前返回值
二、二叉树基础但是非常重要的操作-遍历
2.1 递归实现前中后序遍历
首先我们要知道为什么遍历有三种,这里如果直接从二叉树的形状上去理解,会陷入混乱中,为了更好的理解,我们看下面这段代码:
- void traverse(TreeNode* root) {
- if (root == nullptr) {
- return;
- }
- // 前序位置
- traverse(root->left);
- // 中序位置
- traverse(root->right);
- // 后序位置
- }
先不管所谓前中后序,单看 traverse 函数,你说它在做什么事情?我们对比链表和数组的代码:
- void traverse(vector<int>& arr) {
- for (int i = 0; i < arr.size(); i++) {
-
- }
- }
-
- //递归遍历数组
- void traverse(vector<int>& arr, int i) {
- if (i == arr.size()) {
- return;
- }
- //前序位置
- traverse(arr, i + 1);
- //后序位置
- }
-
- //迭代遍历单链表
- void traverse(ListNode* head) {
- for (ListNode* p = head; p != nullptr; p = p -> next) {
-
- }
- }
-
- //递归遍历单链表
- void traverse(ListNode* head) {
- if (head == nullptr) {
- return;
- }
- //前序位置
- traverse(head -> next);
- //后序位置
- }

可以发现,其实二叉树的递归法遍历与数组链表的递归遍历差别不大,只有二叉树有两个子节点,这为他添加了更多的可能性
因此,只要是递归形式的遍历,都可以有前序位置和后序位置,分别在递归之前和递归之后。
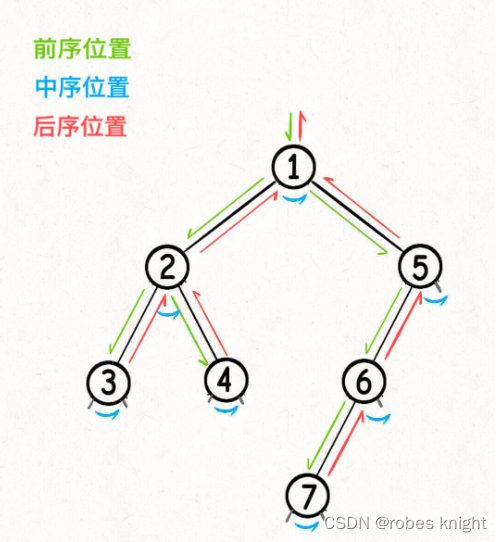
所谓前序位置,就是刚进入一个节点(元素)的时候,后序位置就是即将离开一个节点(元素)的时候,那么进一步,你把代码写在不同位置,代码执行的时机也不同:
在链表中,前后序如图:

在二叉树中,前中后序如图: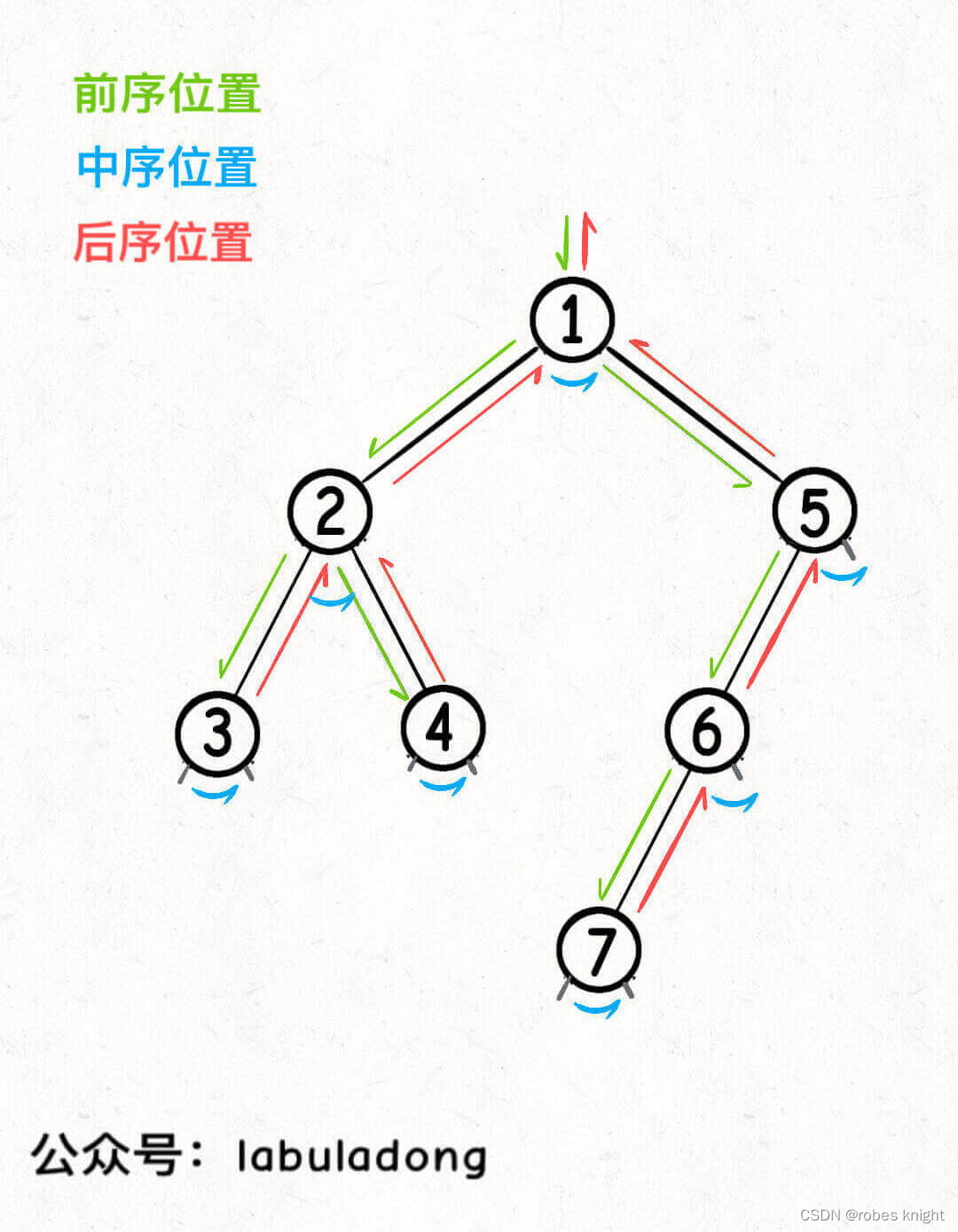
你可以发现每个节点都有「唯一」属于自己的前中后序位置,所以我说前中后序遍历是遍历二叉树过程中处理每一个节点的三个特殊时间点。
二叉树的所有问题,就是让你在前中后序位置注入巧妙的代码逻辑,去达到自己的目的,你只需要单独思考每一个节点应该做什么,其他的不用你管,抛给二叉树遍历框架,递归会在所有节点上做相同的操作。
回到我们的标题,递归实现二叉树的三种遍历方式其实就非常简单了,只要在不同位置操作当前节点即可
- void traverse(TreeNode* root) {
- if (root == nullptr) {
- return;
- }
- // print(root->val)前序遍历
- traverse(root->left);
- // print(root->val)中序遍历
- traverse(root->right);
- // print(root->val)后序遍历
- }
2.2 迭代实现前中后序遍历
没学习递归之前,我们会决定迭代比递归更好理解,但是熟悉递归后,会发现递归十分的方便,此处写迭代法是为了锻炼自己的代码能力,对栈和队列的应用更加深刻
而且我们需要知道一点,就是二叉树中但凡能够通过遍历而非分解实现的问题,都能用栈来实现迭代求解
2.2.1 前后遍历
前序遍历:
- class Solution {
- public:
- vector<int> preorderTraversal(TreeNode* root) {
- vector<int> res;
- if(!root) return res;
- stack<TreeNode*> tmp;
- tmp.push(root);
- while(!tmp.empty()){
- //处理当前节点
- TreeNode* k = tmp.top();
- tmp.pop();
- res.push_back(k->val);
- //注意栈的特点,此处要后入左节点,和递归时相反
- if(k->right)tmp.push(k->right);
- if(k->left)tmp.push(k->left);
- }
- return res;
- }
- };
后序遍历:
和前序遍历很像,只是先压入左节点后压入右节点,但是由于是中右左遍历,我们需要将结果reverse一次(为了统一格式这样书写)
- class Solution {
- public:
- vector<int> postorderTraversal(TreeNode* root) {
- vector<int> res;
- stack<TreeNode*> tmp;
- if(root == nullptr) return res;
- tmp.push(root);
- while(!tmp.empty()){
- TreeNode* k = tmp.top();
- tmp.pop();
- res.push_back(k->val);
- if(k->left)tmp.push(k->left);
- if(k->right)tmp.push(k->right);
- }
- reverse(res.begin(),res.end());
- return res;
- }
- };
2.2.2 中序遍历
中序和前后序不一样,观察之前代码可知,左右总是放在一起的,而对应中序,左右需要分开,那么不能再用之前的模板了
我们使用另一种思路:由于中序遍历需要从最左子树开始,所以我们先定位到最左子树再进行操作即可(一直往左遇到nullptr就是最左子树)

代码实现:
- class Solution {
- public:
- vector<int> inorderTraversal(TreeNode* root) {
- vector<int> res;
- stack<TreeNode*> tmp;
- TreeNode* cur = root;
- while(cur != nullptr || !tmp.empty()){
- //未找到最左节点继续找
- if(cur != nullptr){
- tmp.push(cur);
- cur = cur->left;
- }//找到了最左节点开始操作
- else{
- cur = tmp.top();
- tmp.pop();
- res.push_back(cur->val);
- //注意这里只有往右的操作
- cur = cur->right;
- }
- }
- return res;
- }
- };
2.3 广度优先(bfs)-层序遍历
2.3.1 递归法
虽然每次只能处理一个节点,但是我们把节点放到指定位置存放就能实现层序遍历了
注意这里对变量depth的处理,这是其中一种处理方法(另一种是设置外部变量,然后在后序的位置回溯),这种方法正好可以与层序结合,很巧妙。
- class Solution {
- public:
- void order(TreeNode* cur, vector<vector<int>>& result, int depth)
- {
- if (cur == nullptr) return;
- //深度满了就增加数组容量
- if (result.size() == depth) result.push_back(vector<int>());
- //每次将前序位置的数放到指定层所在的位置
- result[depth].push_back(cur->val);
- order(cur->left, result, depth + 1);
- order(cur->right, result, depth + 1);
- }
- vector<vector<int>> levelOrder(TreeNode* root) {
- vector<vector<int>> result;
- int depth = 0;
- order(root, result, depth);
- return result;
- }
- };
2.3.1 迭代法-更体现层序的思想
使用队列先入先出的特性求解
观察下列代码,我们使用一个size对当前层的节点进行计数,我们发现,队列中充满了一层的元素,其长度就是size,然后我们遍历队列,每次将队列的队头取出来的同时将子树按照左右的顺序放进去(放到了本层末尾元素的后面),当我们把本层元素全部取出后,队列中就是按照顺序放入的下一层元素,重复操作即可;
为什么队列一开始会充满本层元素,因为第一层只有根节点,随意放入队列就能充满一层
- class Solution {
- public:
- vector<vector<int>> levelOrder(TreeNode* root) {
- queue<TreeNode*> que;
- vector<vector<int>> res;
- TreeNode* cur = root;
- if(root == nullptr) return res;
- que.push(cur);
- while(!que.empty()){
- vector<int> res1;
- int size = que.size();
- while(size--){
- //处理当前节点
- cur = que.front();
- que.pop();
- res1.push_back(cur->val);
- //使用队列进行遍历
- if(cur->left)que.push(cur->left);
- if(cur->right)que.push(cur->right);
- }
- res.push_back(res1);
- }
- return res;
- }
- };
层序遍历习题:
上述模板可通杀:
- 107.二叉树层序遍历Ⅱ
- 199.二叉树右视图
- 637.二叉树的层平均值(opens new window)
- 429.N叉树的层序遍历(opens new window)
- 515.在每个树行中找最大值(opens new window)
- 116.填充每个节点的下一个右侧节点指针(opens new window)
- 117.填充每个节点的下一个右侧节点指针II(opens new window)
- 104.二叉树的最大深度(opens new window)
- 111.二叉树的最小深度
三、二叉树的基础操作
3.1 常规操作
3.1.1 对称二叉树

递归-分解子问题:
- //递归法
- class Solution {
- public:
- bool compare(TreeNode* left,TreeNode* right){
- //错误做法:没有搞清楚什么是终止,一定要到最后不能再往下走了再return,
- //这里return true里面包括了left->val==right->val,这种情况确实应该返回false,
- //但也不能返回true,要继续前进
- // if(left== nullptr && right != nullptr) return false;
- // else if(left!= nullptr && right == nullptr) return false;
- // else if(left!= nullptr && right != nullptr &&left->val != right->val)return false;
- // else return true;
- //修改后
- if(left== nullptr && right != nullptr) return false;
- else if(left!= nullptr && right == nullptr) return false;
- else if(left!= nullptr && right != nullptr &&left->val != right->val)return false;
- else if(left== nullptr && right == nullptr) return true;
- //这里不是对左右子树分别判断,是将外侧和内侧分别判断
- bool rightjudge = compare(left->left,right->right);
- bool leftjudge = compare(left->right,right->left);
- return rightjudge&&leftjudge;
- }
- bool isSymmetric(TreeNode* root) {
- bool judge = compare(root->left,root->right);
- return judge;
- }
- };
迭代法:(难理解一些,用递归更好)
- /迭代法
- class Solution {
- public:
- bool isSymmetric(TreeNode* root) {
- if(root == nullptr) return true;
- TreeNode* cur1 = root->left;
- TreeNode* cur2 = root->right;
- stack<TreeNode*> st;
- st.push(cur2);
- st.push(cur1);
- while(!st.empty()){
- cur1 = st.top();st.pop();
- cur2 = st.top();st.pop();
- if (!cur1 && !cur2) { // 左节点为空、右节点为空,此时说明是对称的
- continue;
- }
- //这一步很重要! 左右一个节点不为空,或者都不为空但数值不相同,返回false
- if ((!cur1 || !cur2 || (cur1->val != cur2->val))) {
- return false;
- }
- if(cur1->val != cur2->val)return false;
- st.push(cur2->left);
- st.push(cur1->right);
- st.push(cur2->right);
- st.push(cur1->left);
- //不能使用if判断再放入,会忽略null;
- }
- return true;
- }
- };
3.1.2 二叉树展开为链表
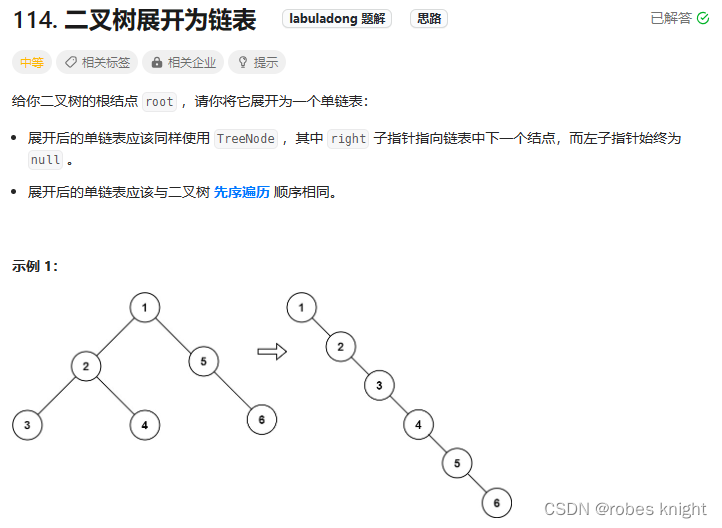
递归-遍历:
- class Solution {
- public:
- //因为最后使用的是数,所以这里用树模拟链表
- TreeNode* dummy = new TreeNode(0);
- TreeNode* cur = dummy;
- void traverse(TreeNode* root){
- if(!root) return;
- cur->right = new TreeNode(root->val);
- cur = cur->right;
- traverse(root->left);
- traverse(root->right);
- }
- void flatten(TreeNode* root) {
- if(!root)return;
- traverse(root);
- root->left = nullptr;
- root->right = dummy->right->right;
- }
- };
3.1.3 关于高度和深度的操作
- 二叉树节点的深度:指从根节点到该节点的最长简单路径边的条数。
- 二叉树节点的高度:指从该节点到叶子节点的最长简单路径边的条数。
关于高度和深度操作,注意求整颗树的最大深度和最大高度的代码一样也和求一个节点的高度的代码一样
求一个节点的深度的代码会有区别
- struct TreeNode {
- int val;
- TreeNode *left;
- TreeNode *right;
- TreeNode(int x) : val(x), left(NULL), right(NULL) {}
- };
-
- // 计算整棵树的最大深度/高度
- int maxDepth(TreeNode* root) {
- if (root == nullptr) return 0;
- return 1 + max(maxDepth(root->left), maxDepth(root->right));
- }
-
- // 计算一个节点的高度
- int height(TreeNode* node) {
- if (node == nullptr) return 0;
- return 1 + max(height(node->left), height(node->right));
- }
-
- // 计算一个节点的深度
- int depth(TreeNode* target, TreeNode* current, int currentDepth = 0) {
- if (current == nullptr) return -1;
- if (current == target) return currentDepth;
-
- int leftDepth = depth(target, current->left, currentDepth + 1);
- if (leftDepth != -1) return leftDepth;
-
- return depth(target, current->right, currentDepth + 1);
- }
-
- // 使用方法:
- // TreeNode* root = ...; // 创建或获取树的根节点
- // TreeNode* targetNode = ...; // 创建或获取目标节点
- // int treeMaxDepth = maxDepth(root);
- // int targetNodeHeight = height(targetNode);
- // int targetNodeDepth = depth(targetNode, root);
3.1.4 二叉树最大深度-涉及两种回溯的处理模板(!!!)
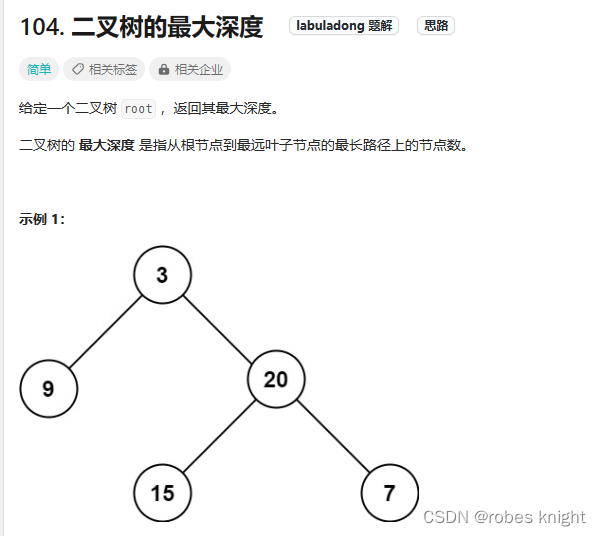
此题首先想到的就是层序,2.3 广度优先(bfs)-层序遍历中也有此题,这里贴出来层序解法,再加一个分解子问题解法
递归-遍历-回溯
这里可以理解为回溯加上后序
解法1:使用外部遍历进行回溯,要在后序位置手动回溯
- class Solution {
- public:
- int deep=0,maxdeep=0;
- void traverse(TreeNode* root){
- if(root == nullptr) return;
- deep++;
- traverse(root->left);
- traverse(root->right);
- if(!root->left &&!root->right)//这一步是不是必要,但是能够少执行几次max函数
- maxdeep = max(deep,maxdeep);//要保证在++后--前进行max处理,因为++后表示进入更深的层,--表示退出了一层,在中间时deep才是一条子路的最大深度
- deep--;//从一个节点的前序进入又从后序出去,说明这个节点进一次出一次就要加一次减一次
- //如果只从前序进入节点,就会一直++,保证了deep能够增长
- }
- int maxDepth(TreeNode* root) {
- traverse(root);
- return maxdeep;
- }
- };
解法2:使用内部遍历进行回溯,自动回溯,更好理解
- class Solution {
- public:
- int maxdeep=0;
- void traverse(TreeNode* root,int deep){
- if(root == nullptr) return;
- if(!root->left &&!root->right)
- maxdeep = max(deep,maxdeep);
- traverse(root->left,deep+1);
- traverse(root->right,deep+1);
- }
- int maxDepth(TreeNode* root) {
- int deep = 1;
- traverse(root,deep);
- return maxdeep;
- }
- };
递归-分解子问题:
- class Solution {
- public:
- int maxDepth(TreeNode* root) {
- if(root == nullptr) return 0;//对于空节点,只从这一个节点往下算,深度为0
- int l = maxDepth(root->left);
- int r = maxDepth(root->right);
- return max(l,r)+1;
- }
- };
迭代-层序遍历:
- class Solution {
- public:
- int deep=0,maxdeep=0;
- void traverse(TreeNode* root){
- if(root == nullptr) return;
- deep++;
- traverse(root->left);
- traverse(root->right);
- if(!root->left &&!root->right)//这一步是不是必要,但是能够少执行几次max函数
- maxdeep = max(deep,maxdeep);//要保证在++后--前进行max处理,因为++后表示进入更深的层,--表示退出了一层,在中间时deep才是一条子路的最大深度
- deep--;//从一个节点的前序进入又从后序出去,说明这个节点进一次出一次就要加一次减一次
- //如果只从前序进入节点,就会一直++,保证了deep能够增长
- }
- int maxDepth(TreeNode* root) {
- traverse(root);
- return maxdeep;
- }
- };
3.1.5 二叉树最小深度-涉及两种回溯以及是否将递归处理nullptr
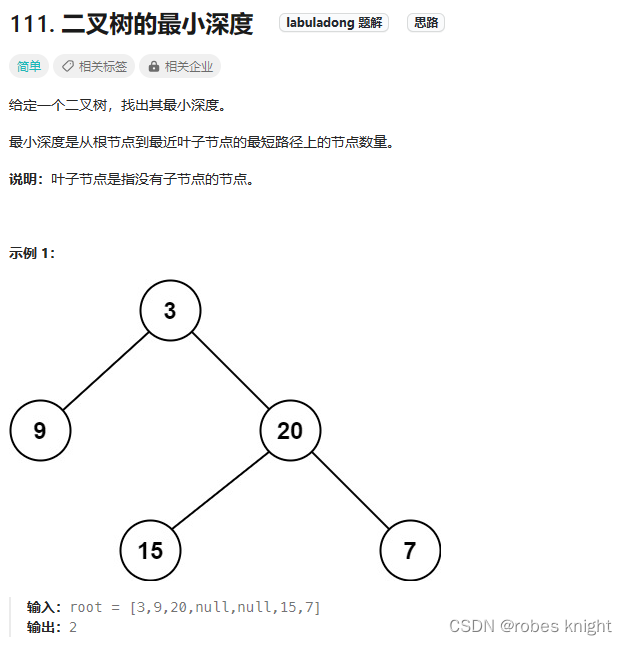
递归-遍历:
操作比较简单,但是可以通过这个题加深对于两种回溯以及nullptr的理解
解法1:将nullptr放入递归中
- class Solution {
- public:
- int deep=0,mindeep=INT_MAX;
- void traverse(TreeNode* root){
- if(root == nullptr) return;
- deep++;
- // if(root->left != nullptr)
- traverse(root->left);
- // if(root->right != nullptr)
- traverse(root->right);
- if(root->left == nullptr && root->right == nullptr)
- mindeep = min(deep,mindeep);//要保证在++后--前进行max处理,因为++后表示进入更深的层,--表示退出了一层,在中间时deep才是这个节点的深度
- deep--;//从一个节点的前序进入又从后序出去,说明这个节点进一次出一次就要加一次减一次
- //如果只从前序进入节点,就会一直++,保证了deep能够增长
- }
- int minDepth(TreeNode* root) {
- if(root == nullptr) return 0;//因为这里mindepp初值为INT_MAX所以root==nullptr时不能直接返回(和迭代中的操作没统一),要返回0
- traverse(root);
- return mindeep;
- }
- };
解法2:不将nullptr放入递归中
- class Solution {
- public:
- int deep=0,mindeep=INT_MAX;
- void traverse(TreeNode* root){
- // if(root == nullptr) return;
- deep++;
- if(root->left != nullptr)
- traverse(root->left);
- if(root->right != nullptr)
- traverse(root->right);
- if(root->left == nullptr && root->right == nullptr)
- mindeep = min(deep,mindeep);//要保证在++后--前进行max处理,因为++后表示进入更深的层,--表示退出了一层,在中间时deep才是这个节点的深度
- deep--;//从一个节点的前序进入又从后序出去,说明这个节点进一次出一次就要加一次减一次
- //如果只从前序进入节点,就会一直++,保证了deep能够增长
- }
- int minDepth(TreeNode* root) {
- if(root == nullptr) return 0;//因为这里mindepp初值为INT_MAX所以root==nullptr时不能直接返回(和迭代中的操作没统一),要返回0
- traverse(root);
- return mindeep;
- }
- };
解法3:自动回溯
- class Solution {
- public:
- int mindeep=INT_MAX;
- void traverse(TreeNode* root,int deep){
- if(root == nullptr) return;
- traverse(root->left,deep+1);
- traverse(root->right,deep+1);
- if(root->left == nullptr && root->right == nullptr)
- mindeep = min(deep,mindeep);//要保证在++后--前进行max处理,因为++后表示进入更深的层,--表示退出了一层,在中间时deep才是这个节点的深度
- }
- int minDepth(TreeNode* root) {
- if(root == nullptr) return 0;//因为这里mindepp初值为INT_MAX所以root==nullptr时不能直接返回(和迭代中的操作没统一),要返回0
- int deep=1;
- traverse(root,deep);
- return mindeep;
- }
- };
递归-分解子问题:
注意和最大深度有些区别,最大深度可以把null当作0,因为是取最大值,所以0不影响,但是这里是取最小值,0就会影响最小值,因此要把0单独处理
(如果不把nullptr放入递归函数中可以排除0的干扰,但是这样会导致终止条件和返回值变复杂,也和我们前面写的统一模板不同,因此不考虑)
- //递归法-子问题分解
- class Solution {
- public:
- int minDepth(TreeNode* root) {
- if(root == nullptr) return 0;//对于空节点,只从这一个节点往下算,深度为0
- int l = minDepth(root->left);
- int r = minDepth(root->right);
- //当左右子树为null时,会返回0,但是null不是叶子节点,所以这个0是具有误导性的所以要将其单独处理
- if(root->left != nullptr && root->right == nullptr)
- return l+1;
- if(root->right != nullptr && root->left == nullptr)
- return r+1;
- return min(l,r)+1;
- }
- };
迭代-层序遍历:
在第一个叶子节点处返回当前深度
- class Solution {
- public:
- int minDepth(TreeNode* root) {
- queue<TreeNode*> que;
- vector<int> res;
- TreeNode* cur = root;
- int deepth=1;
- if(root == nullptr) return 0;//[]的时候是0
- que.push(cur);
- while(!que.empty()){
- int size = que.size();
- while(size--){
- cur = que.front();
- que.pop();
- if(cur->left)que.push(cur->left);
- if(cur->right)que.push(cur->right);
- //遇到第一个叶子节点,就返回当前的深度
- if((!cur->left)&&(!cur->right))return deepth;
- }
- deepth++;
- }
- return deepth;
- }
- };
3.1.6 平衡二叉树-体现高度和深度的区别
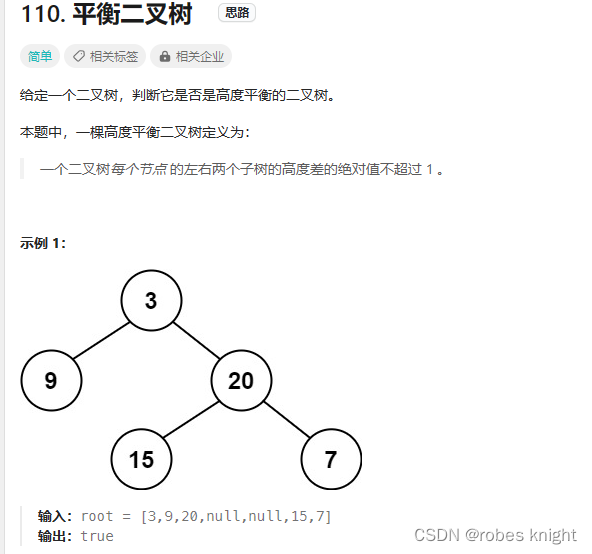
求取当前节点的高度:
- int getDepth(TreeNode* root){
- if(!root)return 0;
- int l = getDepth(root->left);
- int r = getDepth(root->right);
- return 1 + max(l , r);
- }
递归-分解子问题:
在求解高度的同时,把-1当作了表示非平衡的标签,比较巧妙
- class Solution {
- public:
- int getheight(TreeNode* root){
- if(!root)return 0;
- int l = getheight(root->left);
- if(l == -1)return -1;
- int r = getheight(root->right);
- if(r == -1)return -1;
- //-1表示非平衡,1+max(l,r)表示当前高度
- return abs(l - r) > 1 ? -1 : (1 + max(l , r));
- }
- bool isBalanced(TreeNode* root) {
- int j;
- j = getheight(root);
- if(j == -1)return false;
- else return true;
- }
- };
迭代:
此处的迭代法比较暴力,先用迭代思想求到最大高度(这一步也可以用递归求得),然后前序遍历,每次计算两个子树的最大高度
- class Solution {
- private:
- // int getDepth(TreeNode* cur) {
- // stack<TreeNode*> st;
- // if (cur != NULL) st.push(cur);
- // int depth = 0; // 记录深度
- // int result = 0;
- // while (!st.empty()) {
- // TreeNode* node = st.top();
- // if (node != NULL) {
- // st.pop();
- // st.push(node); // 中
- // st.push(NULL);
- // depth++;
- // if (node->right) st.push(node->right); // 右
- // if (node->left) st.push(node->left); // 左
-
- // } else {
- // st.pop();
- // node = st.top();
- // st.pop();
- // depth--;
- // }
- // result = result > depth ? result : depth;
- // }
- // return result;
- // }
- int getDepth(TreeNode* root){
- if(!root)return 0;
- int l = getDepth(root->left);
- int r = getDepth(root->right);
- return 1 + max(l , r);
- }
- public:
- bool isBalanced(TreeNode* root) {
- stack<TreeNode*> st;
- if (root == NULL) return true;
- st.push(root);
- while (!st.empty()) {
- TreeNode* node = st.top(); // 中
- st.pop();
- cout<<getDepth(node)<<endl;
- if (abs(getDepth(node->left) - getDepth(node->right)) > 1) {
- return false;
- }
- if (node->right) st.push(node->right); // 右(空节点不入栈)
- if (node->left) st.push(node->left); // 左(空节点不入栈)
- }
- return true;
- }
- };
3.1.7 合并二叉树
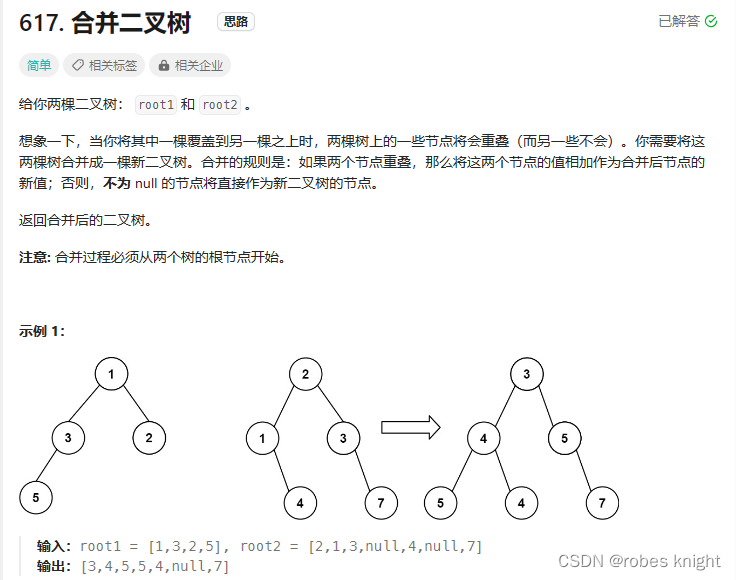
前序遍历两颗树:
- class Solution {
- public:
- TreeNode* mergeTrees(TreeNode* root1, TreeNode* root2) {
- int val;
- if(!root1 && !root2)return nullptr;
- // else if(!root1 && root2)val = root2->val;
- // else if(root1 && !root2)val = root1->val;
- else if(!root1 && root2)return root2;
- else if(root1 && !root2)return root1;
- else val = root1->val + root2->val;
- TreeNode* root = new TreeNode(val);
- root->left = mergeTrees(root1->left,root2->left);//用val的话遇到其中一个为空不会返回,然后继续执行,执行到此处会操作空指针
- root->right = mergeTrees(root1->right,root2->right);
- return root;
- }
- };
3.1.8 计算完全二叉树节点-完全二叉树性质
具体操作见下文,我们知道常规的遍历二叉树可以解决求节点,但是我们注意到满二叉树节点个数和高度有指数关系,并不需遍历所有节点,只需要知道高度即可;
完全二叉树可以利用满二叉树与普通二叉树的结合来进行优化!
如何计算完全二叉树的节点数 | labuladong 的算法笔记 (gitee.io)
四、二叉树序列化
4.1 序列化的用途
要说序列化和反序列化,得先从 JSON 数据格式说起。
JSON 的运用非常广泛,比如我们经常将变成语言中的结构体序列化成 JSON 字符串,存入缓存或者通过网络发送给远端服务,消费者接受 JSON 字符串然后进行反序列化,就可以得到原始数据了。
这就是序列化和反序列化的目的,以某种特定格式组织数据,使得数据可以独立于编程语言。
那么假设现在有一棵用 Java 实现的二叉树,我想把它通过某些方式存储下来,然后用 C++ 读取这棵并还原这棵二叉树的结构,怎么办?这就需要对二叉树进行序列化和反序列化了。
4.2 序列化的条件
谈具体的题目之前,我们先思考一个问题:什么样的序列化的数据可以反序列化出唯一的一棵二叉树?
比如说,如果给你一棵二叉树的前序遍历结果,你是否能够根据这个结果还原出这棵二叉树呢?
答案是也许可以,也许不可以,具体要看你给的前序遍历结果是否包含空指针的信息。如果包含了空指针,那么就可以唯一确定一棵二叉树,否则就不行。
举例来说,如果我给你这样一个不包含空指针的前序遍历结果 [1,2,3,4,5],那么如下两棵二叉树都是满足这个前序遍历结果的:
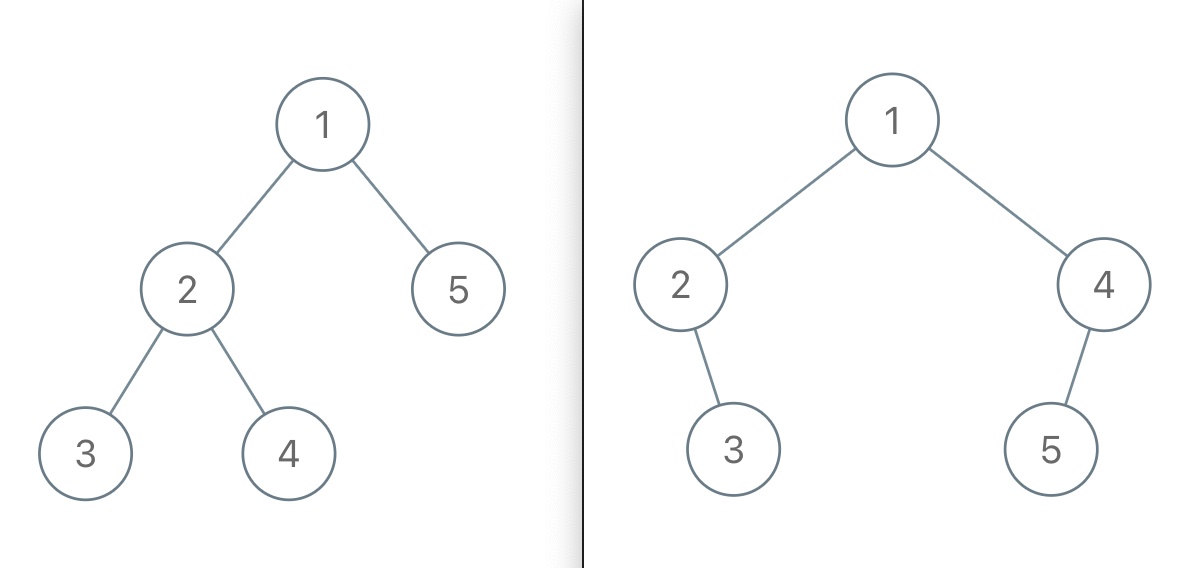
所以给定不包含空指针信息的前序遍历结果,是不能还原出唯一的一棵二叉树的。
但如果我的前序遍历结果包含空指针的信息,那么就能还原出唯一的一棵二叉树了。比如说用 # 表示空指针,上图左侧的二叉树的前序遍历结果就是 [1,2,3,#,#,4,#,#,5,#,#],上图右侧的二叉树的前序遍历结果就是 [1,2,#,3,#,#,4,5,#,#,#],它俩就区分开了。
是否只要加入空指针就能还原呢?
前后序可以,中序不行,如下图两棵二叉树显然拥有不同的结构,但它俩的中序遍历结果都是 [#,1,#,1,#],无法区分:

总结,当二叉树中节点的值不存在重复时:
-
如果你的序列化结果中不包含空指针的信息,且你只给出一种遍历顺序,那么你无法还原出唯一的一棵二叉树。
-
如果你的序列化结果中不包含空指针的信息,且你会给出两种遍历顺序,那么按照前文所说,分两种情况:
2.1. 如果你给出的是前序和中序,或者后序和中序,那么你可以还原出唯一的一棵二叉树。
2.2. 如果你给出前序和后序,那么你无法还原出唯一的一棵二叉树。
-
如果你的序列化结果中包含空指针的信息,且你只给出一种遍历顺序,也要分两种情况:
3.1. 如果你给出的是前序或者后序,那么你可以还原出唯一的一棵二叉树。
3.2. 如果你给出的是中序,那么你无法还原出唯一的一棵二叉树。
4.3 构造二叉树-不包含NULL
4.3.1 构造最大二叉树
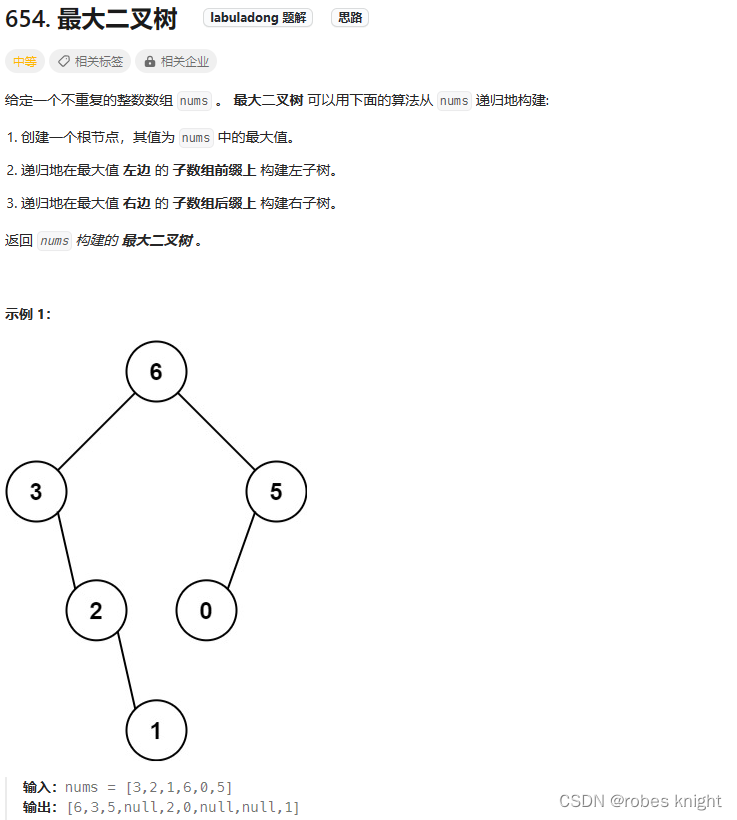
递归-分解子问题:
要注意输入是树和输入是序列的区别
注意:对数组进行操作的时候区间为左闭右开
- class Solution {
- public:
- TreeNode* constructMaximumBinaryTree(vector<int>& nums) {
- //这一步比较精妙,既是终止条件又是生成null的方法
- if(nums.empty()) return NULL;
- //获取最大值的值和id
- auto maxnum = max_element(nums.begin(), nums.end());
- int maxid = distance(nums.begin(),maxnum);
- //创建新节点接收左右子树
- TreeNode* root = new TreeNode(*maxnum);
- //进行递归,由于输入是序列,这里放入递归函数的值也要是序列,即左右序列
- //要记住这种复制数组的方法,构造中很常见
- vector<int> l(nums.begin(), nums.begin() + maxid);
- root->left = constructMaximumBinaryTree(l);
- vector<int> r(nums.begin() + maxid + 1, nums.end());
- root->right = constructMaximumBinaryTree(r);
- //返回值
- return root;
- }
- };
4.3.2 前中序遍历构造二叉树

构造思想:
找到根节点是很简单的,前序遍历的第一个值 preorder[0] 就是根节点的值。
关键在于如何通过根节点的值,将 preorder 和 inorder 数组划分成两半,构造根节点的左右子树?
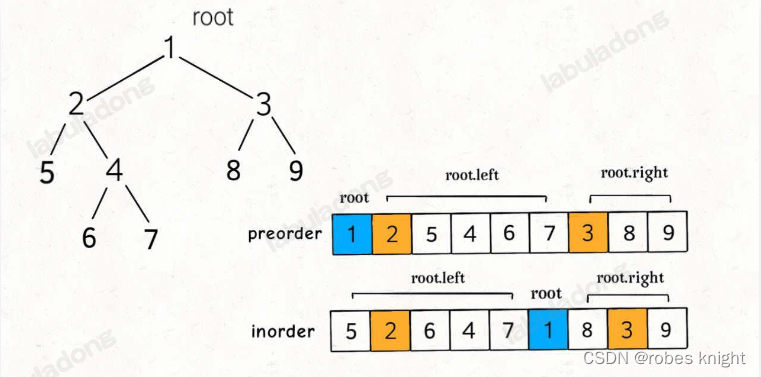
由上图可知,中序数组可以通过找到preorder[0] 的位置进行划分,但是前序数组如何划分呢
观察发现,两个数组的左右子树的size是一样大的,那么我们可以通过先判断中序的左右数组的size,然后由此在前序进行划分,如下图所示
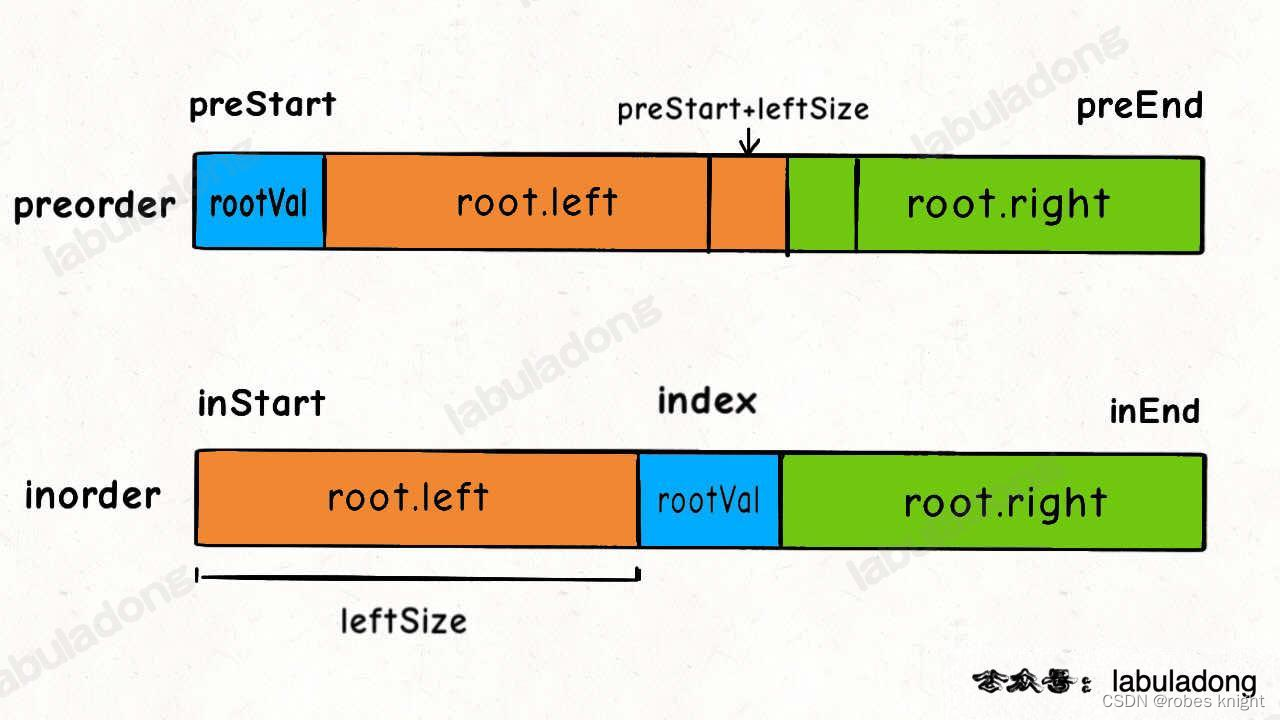
递归-分解子问题:
解法和构造最大二叉树类似
- class Solution {
- public:
- TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
- if(preorder.size() == 0)return nullptr;
- //找到根节点
- int rootval = preorder[0];
- int id;
- //找到根节点在中序数组中的id
- for(id = 0;id < inorder.size();id++){
- if(inorder[id] == rootval)break;
- }
- //创建root接收子树
- TreeNode* root = new TreeNode(rootval);
- //划分中序数组的左右部分
- vector<int> in_left(inorder.begin(),inorder.begin()+id);
- vector<int> in_right(inorder.begin()+id+1,inorder.end());
- //依照中序的size,对前序的左右数组划分
- vector<int> pre_left(preorder.begin()+1,preorder.begin()+1+in_left.size());
- vector<int> pre_right(preorder.begin()+1+in_left.size(),preorder.begin()+in_left.size()+1+in_right.size());
- //进行递归
- root->left = buildTree(pre_left,in_left);
- root->right = buildTree(pre_right,in_right);
- return root;
- }
- };
4.3.3 中后序遍历构造二叉树

中后序数组如下图,和前中序的区别在于后序是尾端为根节点其余一样

递归-分解子问题:
代码实现如下,由于和前中序极度相似,细节不多赘述
- class Solution {
- public:
- TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {
- if(postorder.size() == 0) return NULL;
-
- int rootval = postorder[postorder.size() - 1];
- int id_in;
-
- for(id_in = 0; id_in < inorder.size(); id_in++){
- if(inorder[id_in] == rootval)break;
- }
- TreeNode* root = new TreeNode(rootval);
-
- vector<int> inoder_left(inorder.begin(),inorder.begin()+id_in);
- vector<int> inoder_right(inorder.begin()+id_in+1,inorder.end());
-
- vector<int> postoder_left(postorder.begin(),postorder.begin()+inoder_left.size());
- vector<int> postoder_right(postorder.begin()+inoder_left.size(),postorder.begin()+inoder_left.size()+inoder_right.size());
-
- root->left = buildTree(inoder_left,postoder_left);
- root->right = buildTree(inoder_right,postoder_right);
- return root;
- }
- };
4.3.4 前后序构建二叉树
前后序遍历不能直接构建一个确定的二叉树,但是可以以某种规则构建一种二叉树,但结果不唯一,考虑到结果不唯一,实际应用可能比较少,不做解释
具体操作参考找到第四个前后序构造即可
4.4 序列化二叉树-包含NULL
4.4.1 string与int的转换
1:to_string函数:
to_string函数可以将数字常量转化为字符串
头文件:#include < cstring> 或 #include <string.h>
- #include <iostream>
- #include <cstring>
-
- using namespace std;
-
- int main()
- {
- int x = 566;
- string str = to_string(x);
- cout << str << endl;
- cout << str[0] << endl;
- return 0;
- }
输出:
566
5
注: 参数的类型可以是int,long, double ,long long。
2:stio函数:
将 n 进制的字符串转化为十进制
stoi(字符串,起始位置,n进制(默认10进制)),将 n 进制的字符串转化为十进制
- #include <iostream>
- #include <cstring>
-
- using namespace std;
-
- int main()
- {
- string str = "100";
- int x = stoi(str, 0, 2); //将二进制"100"转化为十进制x
- cout << x << endl;
- return 0;
- }
输出:
4
注: stoi()函数如果传入的字符串s中含有不是数字的字符,则只会识别到从开头到第一个非法字符之 前,如果第一个字符就是非法字符则会报错
4.4.2 序列化与反序列化
在序列化时涉及字符串分割操作,参考如下博客:
C++string字符串split的6种方法_c++ split_龙行天下01的博客-CSDN博客
以其中一种方法为例:
- std::vector<std::string> stringSplit(const std::string& str, char delim) {
- std::stringstream ss(str);
- std::string item;
- std::vector<std::string> elems;
- while (std::getline(ss, item, delim)) {
- if (!item.empty()) {
- elems.push_back(item);
- }
- }
- return elems;
- }
-
-
-
-
- std::stringstream ss(str);:创建一个字符串流对象 ss,并将输入字符串 str 初始化为其内容。
-
- std::string item;:创建一个空字符串 item,用于存储每个拆分后的子字符串。
-
- std::vector<std::string> elems;:创建一个空的字符串向量 elems,用于存储所有拆分后的子字符串。
-
- while (std::getline(ss, item, delim)):使用 std::getline 函数从字符串流 ss 中读取字符,直到遇到分隔符 delim 为止。每次读取到一个子字符串时,它会存储在 item 中。
-
- if (!item.empty()):检查 item 是否为空,如果不为空(即非空白字符串),则执行下面的操作。
-
- elems.push_back(item);:将非空的子字符串 item 添加到字符串向量 elems 中。
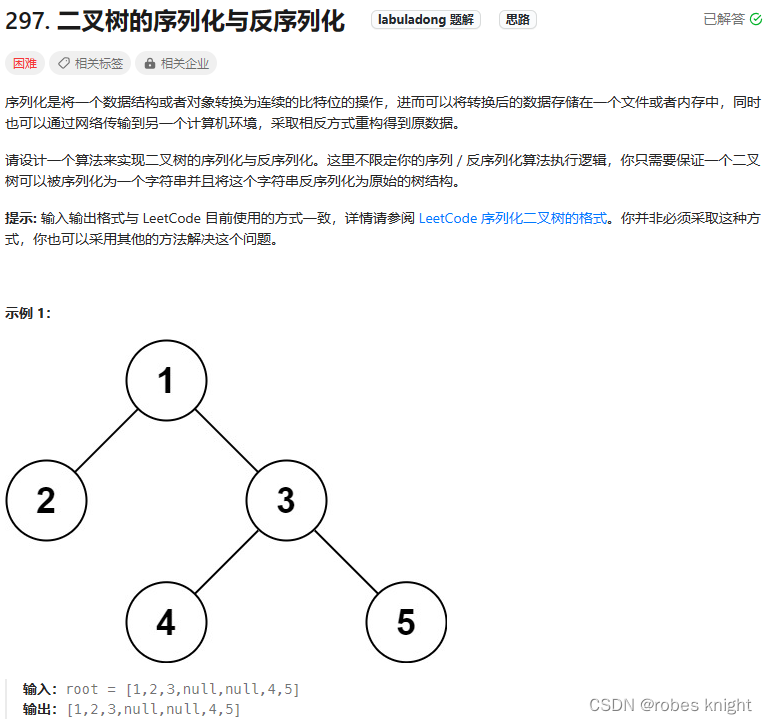
前序遍历序列化-反序列化:
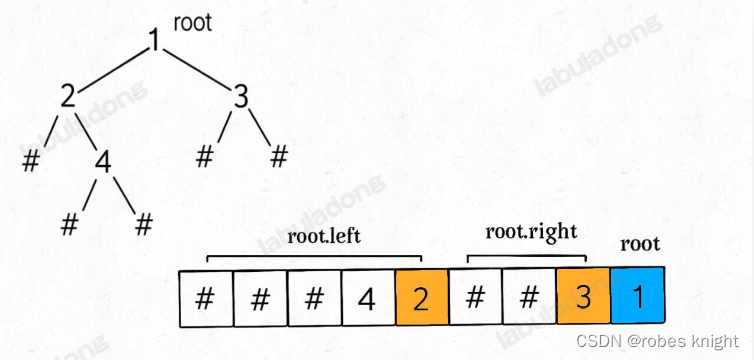
要点:
1.字符串s+操作
2.通过stringstream和geiline进行字符串分割操作
3.将分割后的字符串放入队列中(因为要弹出首元素)
4.反序列化时候的递归和二叉树递归不太相同,要多注意一下(不含null时不能这样,会导致遇不到终止条件)
- class Codec {
- public:
- //遍历-前序
- string data;
-
- void traverse(TreeNode* root,string& s){
- if(!root){
- s+="null,";
- return;
- }else s+=to_string(root->val)+",";
- traverse(root->left,s);
- traverse(root->right,s);
- }
-
- string serialize(TreeNode* root) {
- string s = "";
- traverse(root,s);
- cout<<s<<endl;
- data = s;
- return s;
- }
-
- TreeNode* build(queue<string>& s){
- string first = s.front();
- s.pop();
- if(first=="null")return nullptr;
- // cout<<std::stoi(first)<<endl;
- TreeNode* root = new TreeNode(stoi(first,0));
- root->left = build(s);
- root->right = build(s);
- return root;
- }
-
- TreeNode* deserialize(string data) {
- std::stringstream ss(data);
- std::string it;
- std::queue<std::string> res;
- while (std::getline(ss, it, ',')){
- if (!it.empty()) {
- res.push(it);
- }
- }
- return build(res);
- }
- };
后序遍历:
要点:其他步骤类似前序,但是记得对后序数组进行重构时要先重建右序列(由上图可知)
- class Codec {
- public:
- //遍历-前序
- string data;
-
- void traverse(TreeNode* root,string& s){
- if(!root){
- s+="null,";
- return;
- }
- traverse(root->left,s);
- traverse(root->right,s);
- s+=to_string(root->val)+",";
- }
-
- string serialize(TreeNode* root) {
- string s = "";
- traverse(root,s);
- cout<<s<<endl;
- data = s;
- return s;
- }
-
- TreeNode* build(vector<string>& s){
- string end = s.back();
- s.pop_back();
- if(end=="null")return nullptr;
- cout<<std::stoi(end)<<endl;
- TreeNode* root = new TreeNode(stoi(end,0));
-
- root->right = build(s);
- root->left = build(s);
- return root;
- }
-
- TreeNode* deserialize(string data) {
- std::stringstream ss(data);
- std::string it;
- std::vector<std::string> res;
- while (std::getline(ss, it, ',')){
- if (!it.empty()) {
- res.push_back(it);
- }
- }
- return build(res);
- }
- };
层序遍历实现反序列化
东哥带你刷二叉树(序列化篇) | labuladong 的算法笔记 (gitee.io)
具体操作见上文
4.4.3 求路径-序列化的一种
重点!!!!!这里能够体现递归中的另一个关键因素,将除root外的参数加入递归函数中
当作全局变量处理:所有分支都会影响值;
当作传入参数(未加引用,加上引用就和全局变量相同了)处理:每个分支会分别处理不影响(这两点对4.4.2也适用)
- class Solution {
- public:
- vector<string> res;
- void traverse(TreeNode* root,string s){
- if(!root){
- return;
- }
- s += to_string(root->val);
- if(!root->left && !root->right){
- res.push_back(s);
- return;
- }
- //注意要输出后再放->,因为最后一位是数字
- s += "->";
- traverse(root->left,s);
- traverse(root->right,s);
- }
- vector<string> binaryTreePaths(TreeNode* root) {
- string tmp;
- traverse(root,tmp);
- return res;
- }
- };
4.4.4 寻找重复子树-后序遍历+序列化(关于将参数放入递归进行处理的理解)
遇到子树相关的问题,一般都使用分解子问题进行后序求解
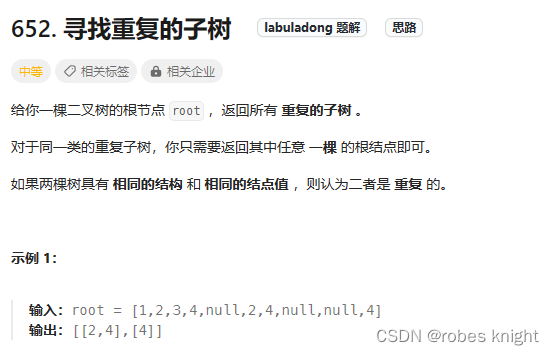
代码1(错误):尝试使用后序遍历,但是后序遍历会携带除子树以外的后序信息,具体代码如下:
- void traverse(TreeNode* root,vector<TreeNode*>& res,string& s){
- if(!root){
- s+="null";
- return;
- }
- traverse(root->left,res,s);
- traverse(root->right,res,s);
- s+= to_string(root->val);
- cout<<"test:"<<s<<endl;
- count[s]++;
- if(count[s]==2)res.push_back(root);
- }
正确做法:分解子问题:
设置外部变量:
- class Solution {
- public:
- unordered_map<string,int> count;
- vector<TreeNode*> res;
- string find(TreeNode* root){
- if(!root)return "#,";
- string mystr = find(root->left)+find(root->right)+to_string(root->val)+",";
- count[mystr]++;
- cout<<"test:"<<mystr<<endl;
- if(count[mystr]==2)res.push_back(root);
- return mystr;
- }
- vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {
- string s="";
- s = find(root);
- return res;
- }
- };
将变量放入递归中:
- class Solution {
- public:
- unordered_map<string,int> count;
- string find(TreeNode* root,vector<TreeNode*>& res){
- if(!root)return "#,";
- string mystr = find(root->left,res)+find(root->right,res)+to_string(root->val)+",";
- count[mystr]++;
- if(count[mystr]==2)res.push_back(root);
- return mystr;
- }
- vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {
- vector<TreeNode*> res;
- string s="";
- s = find(root,res);
- return res;
- }
- };
五、二叉搜索树
5.1 二叉搜索树概念及用途
5.1.1 BST特性
1、对于 BST 的每一个节点 node,左子树节点的值都比 node 的值要小,右子树节点的值都比 node 的值大。
2、对于 BST 的每一个节点 node,它的左侧子树和右侧子树都是 BST。
二叉搜索树并不算复杂,但我觉得它可以算是数据结构领域的半壁江山,直接基于 BST 的数据结构有 AVL 树,红黑树等等,拥有了自平衡性质,可以提供 logN 级别的增删查改效率;还有 B+ 树,线段树等结构都是基于 BST 的思想来设计的。
从做算法题的角度来看 BST,除了它的定义,还有一个重要的性质:BST 的中序遍历结果是有序的(升序)。
- void traverse(TreeNode* root)
- {
- if (root == nullptr)
- {
- return;
- }
- traverse(root->left);
- // 中序遍历代码位置
- print(root->val);
- traverse(root->right);
- }
5.1.2 求二叉搜索树第k小的值

中序遍历(升序输出):
- class Solution {
- public:
- void traverse(TreeNode* root,vector<int>& res){
- if(!root)return;
- traverse(root->left,res);
- res.push_back(root->val);
- traverse(root->right,res);
-
- }
- int kthSmallest(TreeNode* root, int k) {
- vector<int> res;
- traverse(root,res);
- return res[k-1];
- }
- };
5.2.3 更大和二叉树-降序排列

中序遍历:
从右往左进行中序,输出降序排列:
- class Solution {
- public:
- void traverse(TreeNode* root,int& num){
- if(!root)return;
- traverse(root->right,num);
- num += root->val;
- root->val = num;
- traverse(root->left,num);
- }
- TreeNode* bstToGst(TreeNode* root){
- int num=0;
- traverse(root,num);
- return root;
- }
- };
5.2 BST 基础操作-增删改查:
5.2.1 BST代码基础框架:
- void BST(TreeNode* root, int target) {
- if (root->val == target)
- // 找到目标,做点什么
- if (root->val < target)
- BST(root->right, target);
- if (root->val > target)
- BST(root->left, target);
- }
5.2.2 搜索二叉树的搜索
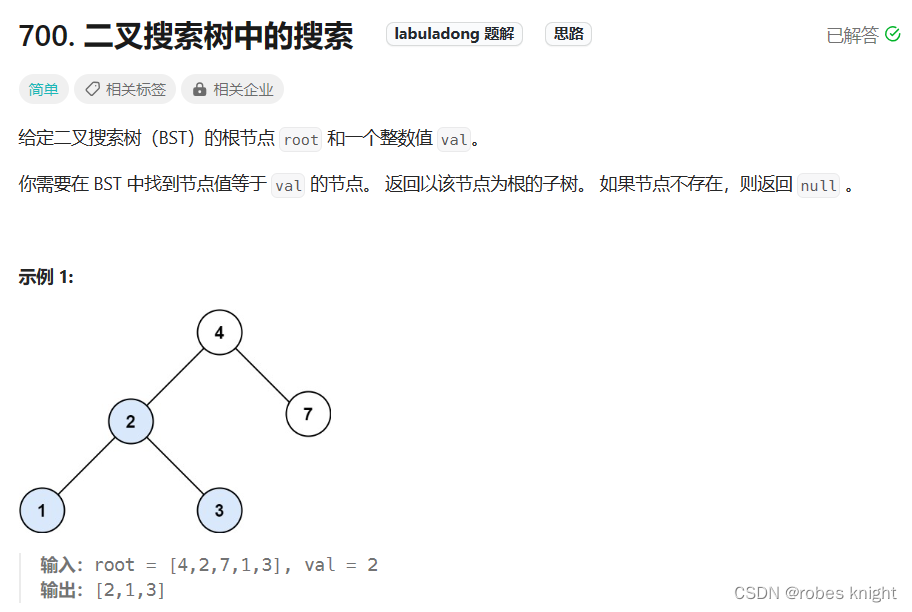
分解子问题:
- class Solution {
- public:
- TreeNode* searchBST(TreeNode* root, int val) {
- if(!root)return nullptr;
- if(root->val == val)return root;
- //错误写法
- // if(root->val > val)root->left = searchBST(root->left,val);
- // if(root->val < val)root->right = searchBST(root->right,val);
- if(root->val > val)return searchBST(root->left,val);
- if(root->val < val)return searchBST(root->right,val);
- return root;//这里返回root其实没有意义,根本走不到这一步,为了格式而已
- }
- };
5.2.3 插入节点-带返回值的遍历写法
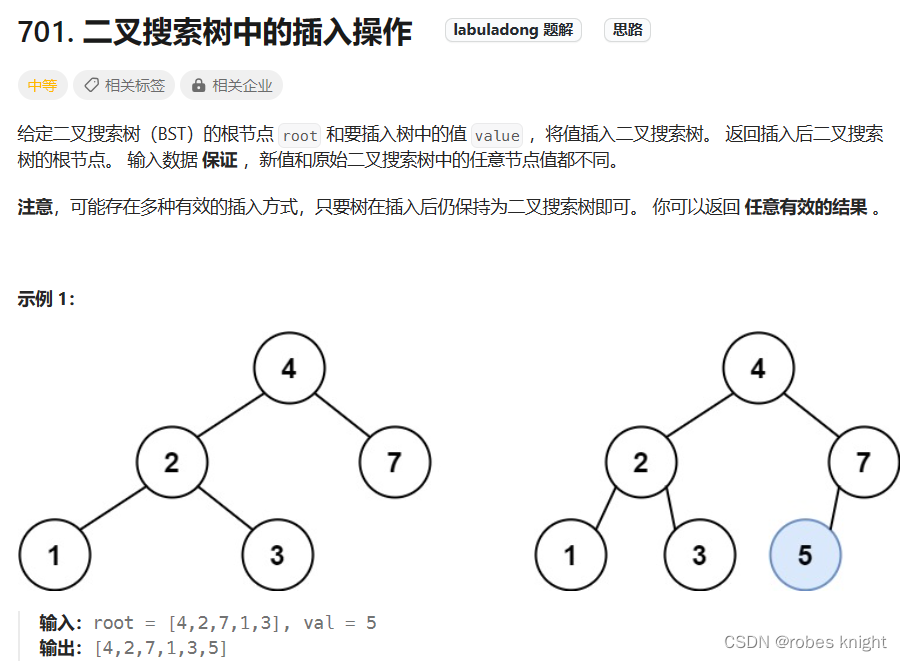
遍历:
通过判断大小进行遍历,这样能找到离val最接近的null,在此添加新节点即可
-
- class Solution {
- public:
- TreeNode* traverse(TreeNode* root,int val){
- if(!root) {
- return new TreeNode(val);
- }
- if(root->val >val)root->left = traverse(root->left,val);
- if(root->val <val)root->right = traverse(root->right,val);
- return root;
- }
- TreeNode* insertIntoBST(TreeNode* root, int val) {
- if(!root)return nullptr;
- traverse(root,val);
- return root;
- }
- };
-
-
5.2.4 删除bst中的节点

思路,分三种情况:
情况 1:A 恰好是末端节点,两个子节点都为空,那么它可以当场去世了。
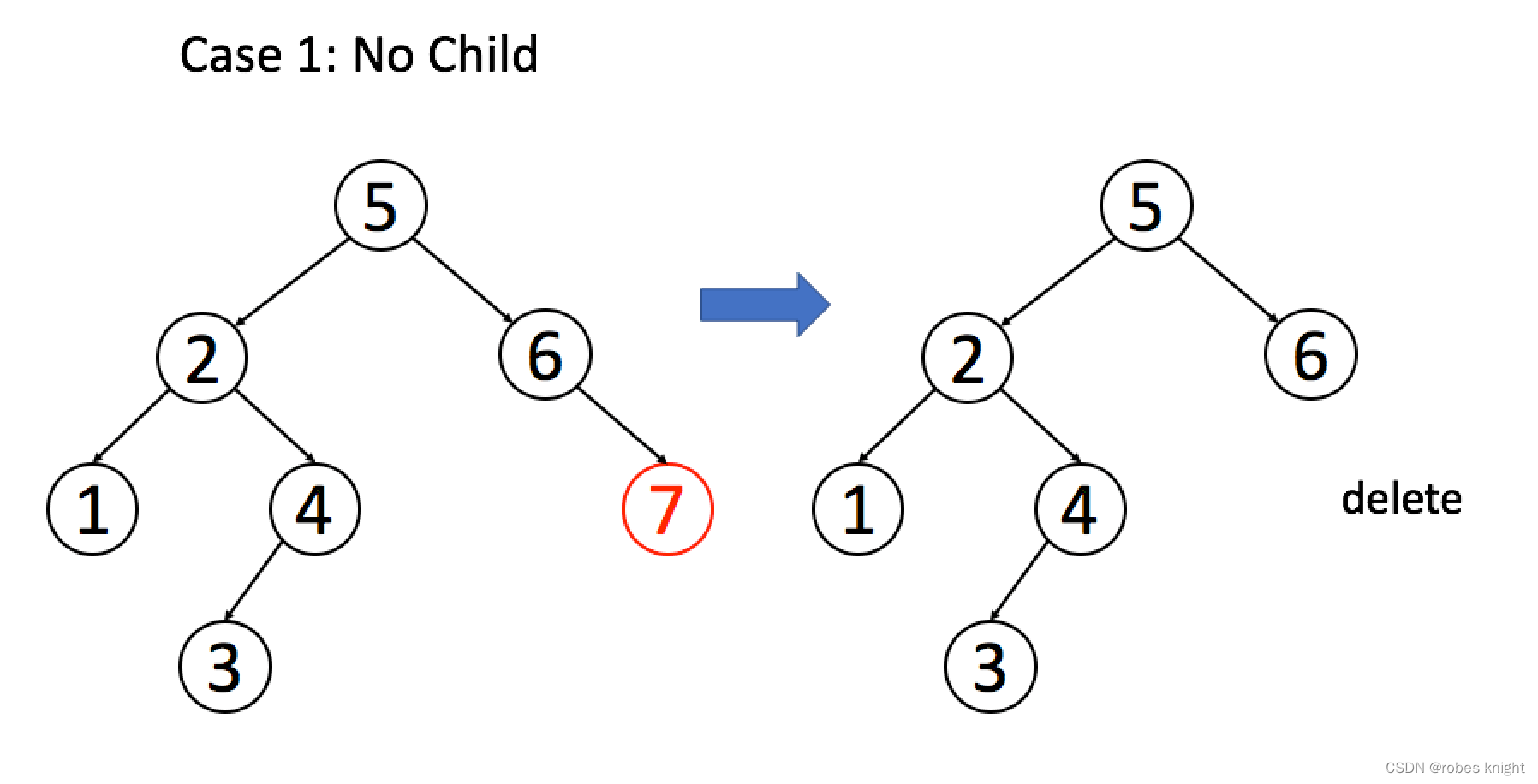
情况 2:A 只有一个非空子节点,那么它要让这个孩子接替自己的位置。
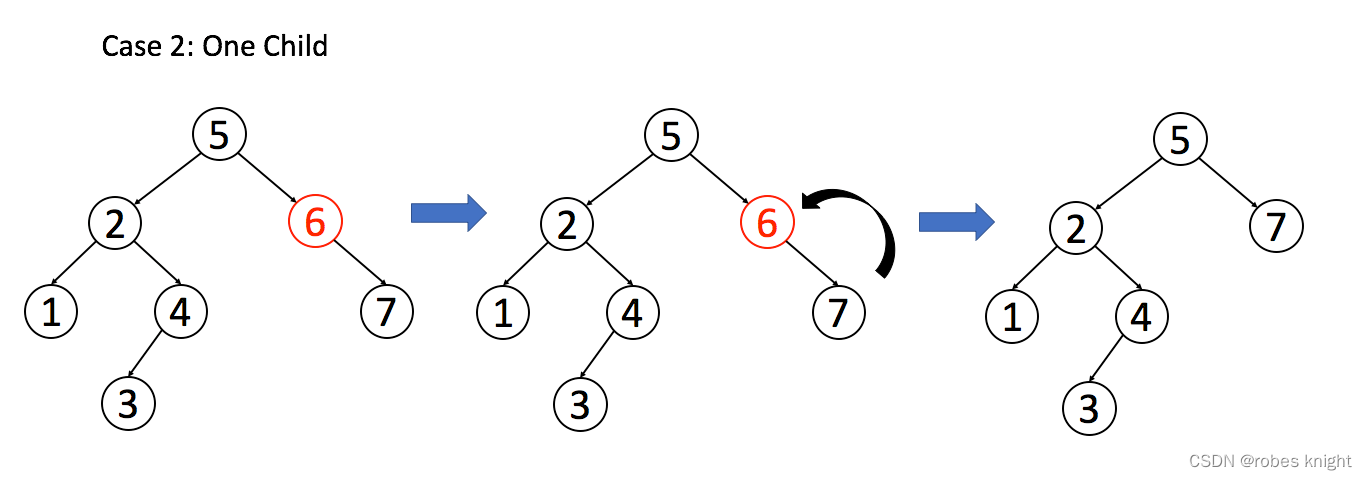
情况 3:A 有两个子节点,麻烦了,为了不破坏 BST 的性质,A 必须找到左子树中最大的那个节点,或者右子树中最小的那个节点来接替自己。我们以第二种方式讲解。
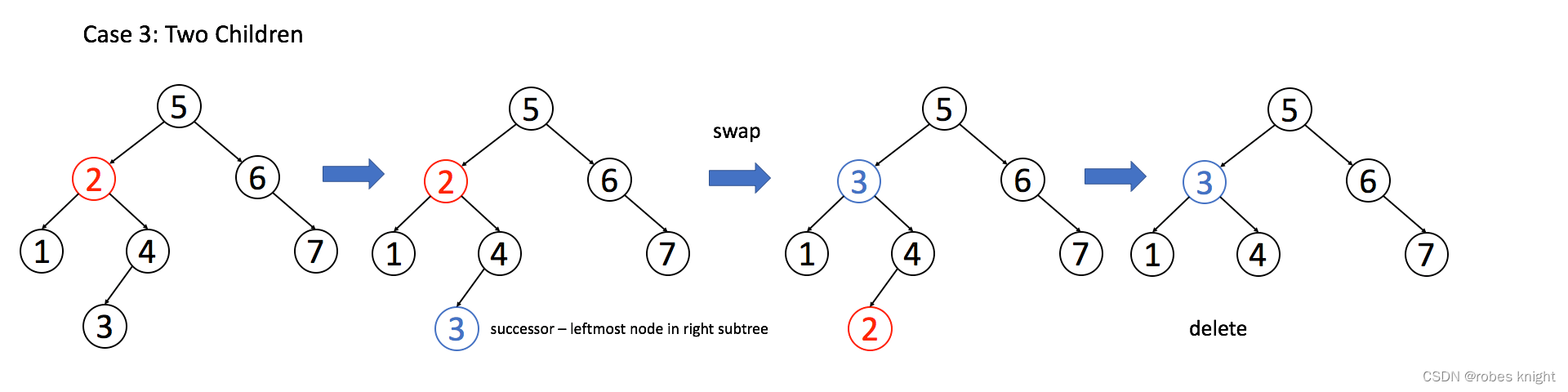
注意:如代码中备注所说,使用值交换并不安全,一般会在进行节点指针交换(直接交换连接关系)
具体操作见代码
分解子问题:
- class Solution {
- public:
- TreeNode* deleteNode(TreeNode* root, int key){
- if(!root)return nullptr;
- if(root->val == key){
- if(!root->left&&!root->right)return nullptr;
- if(!root->left) return root->right;
- if(!root->right) return root->left;
- TreeNode* cur = root->right;
- while(cur->left)cur = cur->left;
- //===通过操作val来进行替换,这样方便,但是这样操作会有风险
- // root->val = cur->val;
- // root->right = deleteNode(root->right,cur->val);
- //===通过交换节点指针
- root->right = deleteNode(root->right,cur->val);
- //只是删除了连接关系,cur还存在
- cur->left = root->left;
- cur->right = root->right;
- return cur;
- }
- if(root->val > key)root->left = deleteNode(root->left,key);
- if(root->val < key)root->right = deleteNode(root->right,key);
- return root;
- }
- };
5.2.5 二叉树裁剪-进阶删除+有返回值遍历
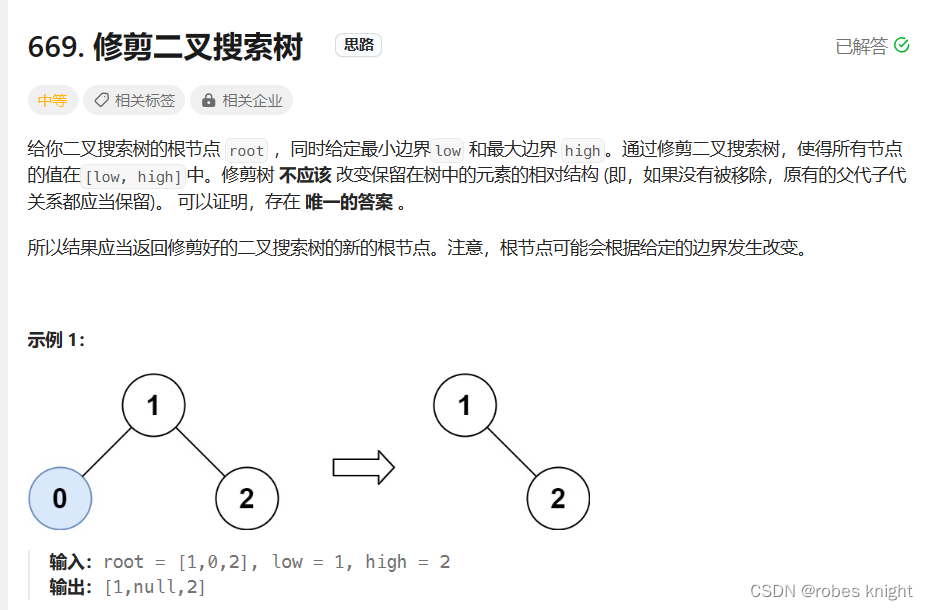
本题注意点:当前节点不满足条件((low)需要再次判断当前节点的右子树,同理如果当前节点值>high,还要再判断左子树
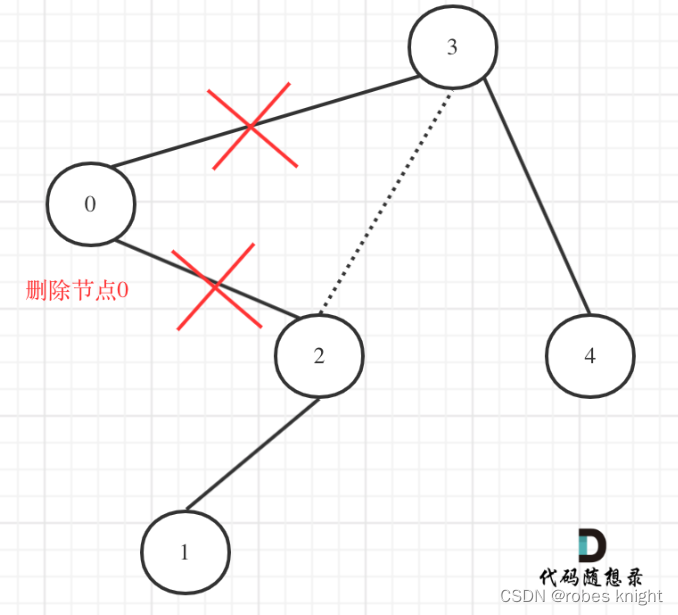
有返回值的遍历:
要体会如何利用上层来操作父节点的(第二行注释),这对理解有返回值的遍历很有用!!!
- class Solution {
- public:
- TreeNode* trimBST(TreeNode* root, int low, int high) {
- if(!root)return nullptr;
- if(root->val < low){
- //这里思路出错,想要直接找到root的父节点进行删除,但是我们没有在本层中保存父节点,想要这样操作是行不通的!!!这里还是对与有返回值的遍历理解不够深刻,我们只需要把当前节点的右子树(更新后)返回给上一层的左子树不就行了
- //root->right = trimBST(root->right,low,high);
- //这里一定要返回更新后的root->right,不要想着直接返回右子树然后在后面的递归中解决,我们必须在一次递归的函数中处理好所有问题!!!!
- //return root->right;
- TreeNode* right = trimBST(root->right,low,high);
- return right;
- }
- if(root->val > high){
- TreeNode* left = trimBST(root->left,low,high);
- return left;
- }
- root->left = trimBST(root->left,low,high);
- root->right = trimBST(root->right,low,high);
- return root;
- }
- };
5.3 构造二叉搜索树
5.3.1 构造一棵二叉搜索树
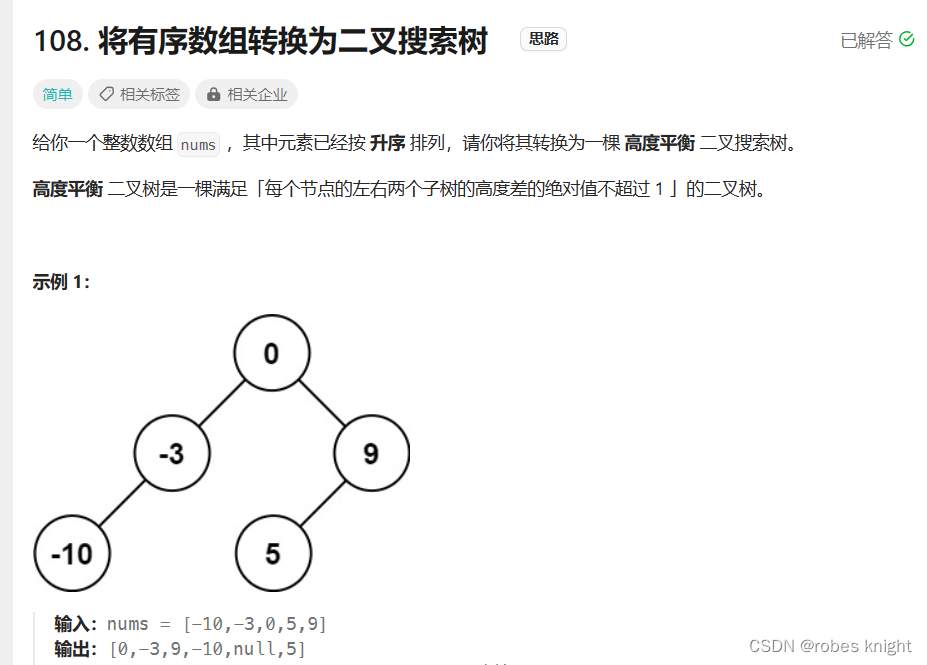
分解子问题构造:
关键在于确定根节点,在利用遍历顺序进行二叉树构造时,我们要根据具体如何遍历来确定,但是这里由于有序性,为了满足平衡二叉树条件(不要求平衡就太简单了),我只需要从中间节点遍历即可(偶数长度中间任意取一点)
- class Solution {
- public:
- TreeNode* sortedArrayToBST(vector<int>& nums) {
- if(!nums.size())return nullptr;
- int mid = nums.size()/2;
- TreeNode* root = new TreeNode(nums[mid]);
- vector<int> left(nums.begin(),nums.begin()+mid);
- vector<int> right(nums.begin()+mid+1,nums.end());
- root->left = sortedArrayToBST(left);
- root->right = sortedArrayToBST(right);
- return root;
- }
- };
(缺)5.3.2 计算序列能够构建多少种搜索二叉树-动态规划添加备忘录(先写一个超时版本)

递归实现:
我们要考虑每一个点当根情况,然后每一种的次数为左右子树次数相乘,for循环累加即可
- class Solution {
- public:
- int res=0;
- int count(int low,int high){
- if(low==high)return 1;
- if(low>high)return 1;
- int res=0;//每次只统计当前节点为根的树,因此需要把res置零
- //但也可以由此发现,冗余度很高,时间复杂度高
- for(int i=low;i<=high;i++){
- int l = count(low,i-1);
- int r = count(i+1,high);
- res+=l*r;
- }
- return res;
- }
- int numTrees(int n) {
- return count(1,n);
- }
- };
(缺) 5.3.3 计算种数并返回所有二叉树-(动态规划部分)
5.4 公共祖先
5.4.1 公共祖先的应用:
本文就用 Git 引出一个经典的算法问题:最近公共祖先(Lowest Common Ancestor,简称 LCA)。
git pull 这个命令我们经常会用,它默认是使用 merge 方式将远端别人的修改拉到本地;如果带上参数 git pull -r,就会使用 rebase 的方式将远端修改拉到本地。
这二者最直观的区别就是:merge 方式合并的分支会看到很多「分叉」,而 rebase 方式合并的分支就是一条直线。但无论哪种方式,如果存在冲突,Git 都会检测出来并让你手动解决冲突。
那么问题来了,Git 是如何检测两条分支是否存在冲突的呢?
以 rebase 命令为例,比如下图的情况,我站在 dev 分支执行 git rebase master,然后 dev 就会接到 master 分支之上:
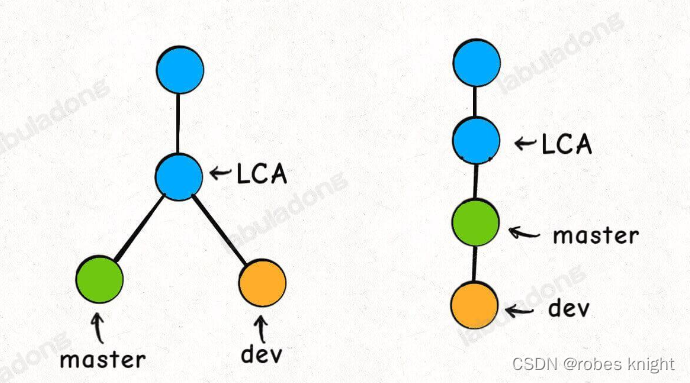
这个过程中,Git 是这么做的:
首先,找到这两条分支的最近公共祖先 LCA,然后从 master 节点开始,重演 LCA 到 dev 几个 commit 的修改,如果这些修改和 LCA 到 master 的 commit 有冲突,就会提示你手动解决冲突,最后的结果就是把 dev 的分支完全接到 master 上面。
那么,Git 是如何找到两条不同分支的最近公共祖先的呢?这就是一个经典的算法问题了,下面我来由浅入深讲一讲。
5.4.2 查询两个节点
具体细节参考:Git原理之最近公共祖先 | labuladong 的算法笔记 (gitee.io)
这里给出查看两个节点的方案,方便后面使用:
同时查找两个节点:
已经综合考虑了前后序选择的效率最高的方法
- // 定义:在以 root 为根的二叉树中寻找值为 val1 或 val2 的节点
- TreeNode* find(TreeNode* root, int val1, int val2) {
- // base case
- if (root == nullptr) {
- return nullptr;
- }
- // 前序位置,看看 root 是不是目标值
- if (root->val == val1 || root->val == val2) {
- return root;
- }
- // 去左右子树寻找
- TreeNode* left = find(root->left, val1, val2);
- TreeNode* right = find(root->right, val1, val2);
- // 后序位置,已经知道左右子树是否存在目标值
- return left != nullptr ? left : right;
- }
5.4.3 普通二叉树的公共祖先

分解子问题:
两种情况,要么
1:能够在一个一个节点的两个子树分别找到p,q,则当前节点为公共祖先
2:遇到当前节点是p或者q,由于是第一次遇到,那么这个节点就是公共祖先,另一个节点必定在他的子树里面(如果不在的话,会在前几层通过判断两边子树的方法找到)
- class Solution {
- public:
- TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
- if(!root)return nullptr;
- if(root==p || root ==q)return root;
- TreeNode* l = lowestCommonAncestor(root->left,p,q);
- TreeNode* r = lowestCommonAncestor(root->right,p,q);
- if(l&&r)return root;
- return l?l:r;
- }
- };
5.4.4 二叉搜索树的公共祖先

分解子问题:
在二叉搜索树中,当一个节点的val处于p,q之间,那么它就是最近的公共祖先,另外搜索左右子树也可以通过判断值的大小进行优化:
- class Solution {
- public:
- TreeNode* find(TreeNode* root,TreeNode* p,TreeNode* q){
- if(!root)return nullptr;
- //这一句无关紧要,因为root->val介于p,q之间时,已经包含了等于的情况了
- // if(root->val == p->val ||root->val == q->val)return root;
- if(root->val > q->val)return find(root->left,p,q);
- if(root->val < p->val)return find(root->right,p,q);
- return root;
- }
- TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
- if(p->val > q->val){
- TreeNode* tmp = p;
- p = q;
- q = tmp;
- }
- return find(root,p,q);
- }
- };
六、排序与二叉树、二叉树与动态规划结合(缺)
参考博客:
C++:to_string与stoi函数_stoi头文件-CSDN博客
- 线性表的顺序存储 ...
赞
踩

