
- 1基于STM32CUBEIDE的定时器实现微妙和毫秒延时_stm32f1 cube 延时
- 2Vue3使用Monaco-editor_vite-plugin-monaco-editor
- 3SASE (安全架构)_sase pop
- 4拟辉光管时钟“重生”记(源码)_拟辉光管时钟怎么连wifi
- 5思科交换机基本配置命令_思科交换机密码配置命令
- 6react18 函数组件 学习笔记_react18类组件
- 7【Win10安装NVIDIA驱动、CUDA、CUDNN、PyTorch】_nvidia cuda
- 8VirtualBox 安装 Ubuntu22.04 详细教程_virtualbox ubuntu
- 9卷积矩阵及其运算实例_矩阵卷积计算
- 10git如何查看密码_git 密码查看
RabbitMQ-工作模式(Topics模式&RPC模式&Publisher Confirms模式)
赞
踩

更多相关内容可查看
Topics模式
在Topics中,发送的消息不能具有任意的路由键 - 它必须是由点分隔的单词列表。这些单词可以是任何内容,但通常它们指定与消息相关联的一些特征。
- 一些有效的路由键示例包括:“stock.usd.nyse”、“nyse.vmw”、“quick.orange.rabbit”。
- 路由键中可以包含任意数量的单词,但不能超过 255 字节的限制。
绑定键也必须采用相同的形式。主题交换topics背后的逻辑与直接交换direct类似 - 使用特定路由键发送的消息将传递到所有使用匹配绑定键绑定的队列。然而,绑定键有两个重要的特殊情况:
- *(星号)可以完全代替一个单词。
- #(hash) 可以替换零个或多个单词。
在示例中解释这一点是最简单的:
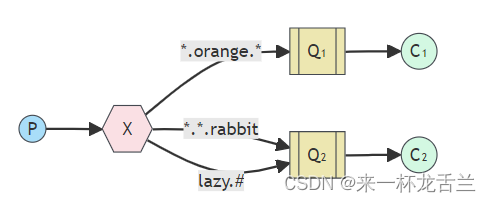
我们创建了三个绑定:Q1与绑定键“.orange.”绑定,Q2与“…rabbit”和“lazy.#”绑定。
- 使用路由键设置为
“quick.orange.rabbit”的消息将被传递到两个队列。消息“lazy.orange.elephant”也将被发送到两个队列。- 另一方面,
“quick.orange.fox”只会发送到第一个队列,“lazy.brown.fox”只会发送到第二个队列。- 尽管
“lazy.pink.rabbit”匹配两个绑定,但它将仅传递到第二个队列一次。而“quick.brown.fox”不匹配任何绑定,因此将被丢弃。- 如果我们违反合约,发送一个单词或四个单词的消息,比如“orange”或
“quick.orange.new.rabbit”会发生什么呢?好吧,这些消息不会匹配任何绑定,将会丢失。- 另一方面,
“lazy.orange.new.rabbit”虽然有四个单词,但将匹配最后一个绑定,并将传递到第二个队列。
小结
- 主题交换是强大的,它可以像其他交换一样工作。
- 当一个队列绑定了 “#”(哈希)绑定键时,它将接收所有消息,无论路由键是什么 —— 就像fount交换机一样。
- 当在绑定中没有使用特殊字符 “*”(星号)和 “#”(哈希)时,主题交换机将表现得就像直接交换机一样。
topic代码示例
生产者代码
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
public class EmitLogTopic {
private static final String EXCHANGE_NAME = "topic_logs";
public static void main(String[] argv) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
try (Connection connection = factory.newConnection();
Channel channel = connection.createChannel()) {
//指定交换机类型
channel.exchangeDeclare(EXCHANGE_NAME, "topic");
String routingKey = getRouting(argv);
String message = getMessage(argv);
channel.basicPublish(EXCHANGE_NAME, routingKey, null, message.getBytes("UTF-8"));
System.out.println(" [x] Sent '" + routingKey + "':'" + message + "'");
}
}
//..
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
消费者代码
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
import com.rabbitmq.client.DeliverCallback;
public class ReceiveLogsTopic {
private static final String EXCHANGE_NAME = "topic_logs";
public static void main(String[] argv) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
//指定交换机类型
channel.exchangeDeclare(EXCHANGE_NAME, "topic");
String queueName = channel.queueDeclare().getQueue();
if (argv.length < 1) {
System.err.println("Usage: ReceiveLogsTopic [binding_key]...");
System.exit(1);
}
//将队列绑定交换机
for (String bindingKey : argv) {
channel.queueBind(queueName, EXCHANGE_NAME, bindingKey);
}
System.out.println(" [*] Waiting for messages. To exit press CTRL+C");
DeliverCallback deliverCallback = (consumerTag, delivery) -> {
String message = new String(delivery.getBody(), "UTF-8");
System.out.println(" [x] Received '" +
delivery.getEnvelope().getRoutingKey() + "':'" + message + "'");
};
channel.basicConsume(queueName, true, deliverCallback, consumerTag -> { });
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
RPC模式
使用RabbitMQ构建一个RPC系统:一个客户端和一个可扩展的RPC服务器。由于我们没有任何值得分发的耗时任务,我们将创建一个返回斐波那契数的虚拟RPC服务。
客户端界面
为了说明如何使用RPC服务,我们将创建一个简单的客户端类。它将公开一个名为call的方法,该方法发送RPC请求并阻塞直到收到答案
FibonacciRpcClient fibonacciRpc = new FibonacciRpcClient();
String result = fibonacciRpc.call("4");
System.out.println( "fib(4) is " + result);
- 1
- 2
- 3
关于 RPC 的说明
尽管RPC在计算中是一种相当常见的模式,但它经常受到批评。问题在于程序员不清楚函数调用是本地的还是慢速的RPC。这样的混淆导致系统变得不可预测,并且增加了调试的不必要复杂性。与简化软件相反,错误使用RPC可能导致难以维护的混乱代码。
考虑到这一点,请考虑以下建议:
- 确保明确指出哪些函数调用是本地的,哪些是远程的。
- 为您的系统编写文档。清楚地说明各个组件之间的依赖关系。
- 处理错误情况。当RPC服务器长时间关闭时,客户端应该如何做出反应?
如果有疑问,应避免使用RPC。如果可以的话,您应该使用异步流水线——而不是类似RPC的阻塞,结果会异步地推送到下一个计算阶段。
回调队列
通常在RabbitMQ上进行RPC很容易。客户端发送一个请求消息,服务器用一个响应消息进行回复。为了接收响应,我们需要在请求中发送一个“回调”队列地址。我们可以使用默认队列(在Java客户端中是独占的)。让我们试试看:
callbackQueueName = channel.queueDeclare().getQueue();
BasicProperties props = new BasicProperties
.Builder()
.replyTo(callbackQueueName)
.build();
channel.basicPublish("", "rpc_queue", props, message.getBytes());
// ... then code to read a response message from the callback_queue ...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
消息属性
AMQP 0-9-1协议预定义了一组与消息一起使用的14个属性。其中常用属性有:
- deliveryMode:将消息标记为持久的(值为1)或瞬态的(任何其他值)。
- contentType:用于描述编码的MIME类型。例如,对于经常使用的JSON编码,将此属性设置为application/json是一个好的做法。
- replyTo:常用于命名回调队列。
- correlationId:用于将RPC响应与请求相关联。
关联ID
在上面提出的方法中,我们建议为每个RPC请求创建一个回调队列。这相当低效,但幸运的是有一种更好的方法——让我们为每个客户端创建一个单独的回调队列。
这引出了一个新问题,即在回调队列中收到响应时,不清楚响应属于哪个请求。这时就会用到correlationId属性。我们将为每个请求设置一个唯一的值。稍后,当我们在回调队列中接收到消息时,我们将查看这个属性,并根据它将响应与请求匹配起来。如果我们看到一个未知的值,我们可以安全地丢弃这个消息——它不属于我们的请求。
你可能会问,为什么我们应该忽略回调队列中的未知消息,而不是报错?这是由于服务器端可能发生竞态条件的可能性。虽然不太可能,但RPC服务器在发送答案后死机,但在发送请求的确认消息之前死机是可能的。如果发生这种情况,重新启动的RPC服务器将再次处理该请求。这就是为什么在客户端上我们必须优雅地处理重复的响应,并且RPC最好是幂等的。
总结

我们的RPC将按以下方式工作:
- 对于一个RPC请求,客户端发送带有两个属性的消息:replyTo,设置为专门为该请求创建的匿名独占队列;correlationId,设置为每个请求的唯一值。
- 请求被发送到一个名为 rpc_queue 的队列。
- RPC:服务器正在该队列上等待请求。当出现请求时,它执行任务并将带有结果的消息发送回客户端,使用来自replyTo字段的队列。
- 客户端在回复队列上等待数据。当出现消息时,它检查correlationId属性。如果它与请求中的值匹配,则将响应返回给应用程序。
RPC代码示例
斐波那契任务:
private static int fib(int n) {
if (n == 0) return 0;
if (n == 1) return 1;
return fib(n-1) + fib(n-2);
}
- 1
- 2
- 3
- 4
- 5
我们声明了一个斐波那契函数。它假定只有有效的正整数输入。(不要期望这个函数适用于大数,并且这可能是最慢的递归实现)。
我们的RPC服务器代码可以在RPCServer.java中找到。
服务器代码非常简单:
- 通常我们会开始建立连接、通道并声明队列。
- 我们可能想要运行多个服务器进程。为了平均分配负载到多个服务器上,我们需要在channel.basicQos.prefetchCount中设置设置。
- 我们使用basicConsumeDeliverCallback访问队列,在这里我们提供一个回调对象,该对象将执行工作并将响应发送回来。
我们的RPC客户端代码可以在RPCClient.java中找到。
客户端代码稍微复杂一些:
- 我们建立连接和通道。
- 我们的方法发起实际的RPC请求
- 在这里,我们首先生成一个唯一的数字并保存它 - 我们的消费者回调将使用这个值来匹配适当的响应。
- 然后,我们创建一个专用的独占队列用于回复并订阅它。
- 接下来,我们发布带有两个属性的请求消息:correlationId和replyTo。
- 在这一点上,我们可以坐下来等待适当的响应到达。
- 由于我们的消费者交付处理是在一个单独的线程中进行的,我们需要一些东西来在响应到达之前挂起线程。使用mainCompletableFuture是实现这一目标的一个可能的解决方案。
- 消费者做的工作非常简单,对于每个消耗的响应消息,它都会检查是否是我们正在寻找的那个。如果是,则完成correlationIdCompletableFuture。
- 同时,线程正在等待mainCompletableFuture完成。
- 最后,我们将响应返回给用户。
这里介绍的设计并不是RPC服务的唯一可能实现,但它具有一些重要的优势:
- 如果RPC服务器太慢,您可以通过运行另一个来进行扩展。尝试在新控制台中运行第二个 RPCServer。
- 在客户端,RPC只需要发送和接收一个消息。不需要像 queueDeclare 这样的同步调用。因此,对于单个RPC请求,RPC客户端只需要一个网络往返。
我们的代码仍然相当简单,没有尝试解决更复杂(但重要)的问题,比如:
- 如果没有运行服务器,客户端应该如何反应?
- 客户端是否应该为RPC设置某种超时?
- 如果服务器发生故障并引发异常,应该将其转发给客户端吗?
- 在处理之前保护无效的传入消息(例如检查边界、类型)。
Publisher Confirms模式
概述
我们将使用发布者确认来确保发布的消息已安全到达代理(broker)。我们将涵盖几种使用发布者确认的策略,并解释它们的优缺点。
在通道上启用发布者确认
发布者确认是RabbitMQ对AMQP 0.9.1协议的扩展,因此它们不是默认启用的。要在通道上启用发布者确认,可以使用confirmSelect方法。
Channel channel = connection.createChannel();
channel.confirmSelect();
- 1
- 2
这个方法必须在每个你希望使用发布者确认的通道上调用。确认应该只启用一次,而不是针对每个发布的消息都启用
单独发布消息
让我们从最简单的方法开始,使用确认进行发布, 也就是说,发布一条消息并同步等待其确认:
while (thereAreMessagesToPublish()) {
byte[] body = ...;
BasicProperties properties = ...;
channel.basicPublish(exchange, queue, properties, body);
// uses a 5 second timeout
channel.waitForConfirmsOrDie(5_000);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
发布者确认是异步的吗?
我们在开头提到,代理异步确认已发布的消息,但在第一个示例中,代码会同步等待消息确认。实际上,客户端异步接收确认,并相应地解除对waitForConfirmsOrDie的调用。可以将waitForConfirmsOrDie想象成一个同步的辅助工具,在底层依赖异步通知。
批量发布消息
为了改进之前的示例,我们可以发布一个批处理 的消息,并等待整个批次得到确认。 以下示例使用一个批次 100:
int batchSize = 100;
int outstandingMessageCount = 0;
while (thereAreMessagesToPublish()) {
byte[] body = ...;
BasicProperties properties = ...;
channel.basicPublish(exchange, queue, properties, body);
outstandingMessageCount++;
if (outstandingMessageCount == batchSize) {
channel.waitForConfirmsOrDie(5_000);
outstandingMessageCount = 0;
}
}
if (outstandingMessageCount > 0) {
channel.waitForConfirmsOrDie(5_000);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
等待一批消息被确认可以大大提高吞吐量,比起等待单个消息的确认(在远程RabbitMQ节点上,可以提高20-30倍)。一个缺点是在失败的情况下我们无法确定发生了什么,因此我们可能需要将整个批次保存在内存中以记录有意义的内容,或者重新发布这些消息。而且这个解决方案仍然是同步的,因此会阻塞消息的发布。
异步处理发布者确认
代理异步确认已发布的消息,只需在客户端注册回调以通知这些确认:
Channel channel = connection.createChannel();
channel.confirmSelect();
channel.addConfirmListener((sequenceNumber, multiple) -> {
// code when message is confirmed
}, (sequenceNumber, multiple) -> {
// code when message is nack-ed
});
- 1
- 2
- 3
- 4
- 5
- 6
- 7
有两个回调函数:一个用于已确认的消息,另一个用于NACK(代理可能认为已丢失的消息)。每个回调函数都有两个参数:
- sequence number:用于标识已确认或已NACK的消息的数字。我们很快将看到如何将其与已发布的消息相关联。
- multiple:这是一个布尔值。如果为false,则仅确认/ NACK一个消息;如果为true,则确认/
NACK所有序列号低于或等于的消息。
可以在发布之前使用Channel#getNextPublishSeqNo()获取序列号:
ConcurrentNavigableMap<Long, String> outstandingConfirms = new ConcurrentSkipListMap<>();
// ... code for confirm callbacks will come later
String body = "...";
outstandingConfirms.put(channel.getNextPublishSeqNo(), body);
channel.basicPublish(exchange, queue, properties, body.getBytes());
- 1
- 2
- 3
- 4
- 5
将消息与序列号相关联的简单方法是使用映射。假设我们想要发布字符串,因为它们很容易转换为字节数组进行发布。以下是一个使用映射将发布序列号与消息字符串体相关联的代码示例:
ConcurrentNavigableMap<Long, String> outstandingConfirms = new ConcurrentSkipListMap<>();
ConfirmCallback cleanOutstandingConfirms = (sequenceNumber, multiple) -> {
if (multiple) {
ConcurrentNavigableMap<Long, String> confirmed = outstandingConfirms.headMap(
sequenceNumber, true
);
confirmed.clear();
} else {
outstandingConfirms.remove(sequenceNumber);
}
};
channel.addConfirmListener(cleanOutstandingConfirms, (sequenceNumber, multiple) -> {
String body = outstandingConfirms.get(sequenceNumber);
System.err.format(
"Message with body %s has been nack-ed. Sequence number: %d, multiple: %b%n",
body, sequenceNumber, multiple
);
cleanOutstandingConfirms.handle(sequenceNumber, multiple);
});
// ... publishing code
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
前面的示例包含一个回调函数,当确认到达时清除映射。请注意,此回调函数处理单个和多个确认。当确认到达时(作为Channel#addConfirmListener的第一个参数),会使用此回调。对于NACK消息的回调检索消息体并发出警告。然后,它重新使用先前的回调来清除映射中的未完成确认(无论消息是否已确认或已NACK,它们在映射中的相应条目都必须被删除)。
如何跟踪未完成的确认?
我们的示例使用ConcurrentNavigableMap来跟踪未完成的确认。这种数据结构有几个方面很方便。它允许轻松将序列号与消息(无论消息数据是什么)相关联,并轻松清除到给定序列ID的条目(以处理多个确认/ NACK)。最后,它支持并发访问,因为确认回调是在客户端库拥有的线程中调用的,这应该与发布线程保持不同。
与使用复杂映射实现跟踪未完成的确认相比,还有其他跟踪未完成的确认的方法,例如使用简单的并发哈希映射和一个变量来跟踪发布序列的下限,但它们通常更复杂,并且不属于教程。
总之,异步处理发布者确认通常需要以下步骤:
- 提供一种将发布序列号与消息相关联的方法。
- 在通道上注册确认监听器,以在发布者确认NACK到达时收到通知并执行适当的操作,如记录或重新发布NACK消息。在此步骤中,序列号到消息的相关机制也可能需要一些清理。
- 在发布消息之前跟踪发布序列号。
重新发布NACK消息吗?
从相应的回调函数中重新发布NACK消息可能会很诱人,但这应该避免,因为确认回调是在 I/O 线程中分派的,在这里,通道不应执行操作。更好的解决方案是将消息排队到一个内存队列中,由发布线程轮询。像ConcurrentLinkedQueue这样的类是在确认回调和发布线程之间传递消息的好选择。
总结
确保发布的消息已经到达代理可以在某些应用程序中至关重要。发布者确认是 RabbitMQ 的一个特性,可以帮助满足这一需求。发布者确认是异步的,但也可以同步处理它们。没有一种确定的方法来实现发布者确认,这通常取决于应用程序和整个系统的约束条件。典型的技术包括:
- 单独发布消息,同步等待确认:简单,但吞吐量非常有限。
- 批量发布消息,同步等待批量确认:简单,吞吐量合理,但在出现问题时很难进行推理。
- 异步处理:性能最佳,资源利用最佳,在出现错误时具有良好的控制,但正确实现可能比较复杂。
总体代码示例
PublisherConfirms.java 类包含我们所涵盖的技术的代码。我们可以编译它,按原样执行,并查看它们的性能如何:
javac -cp $CP PublisherConfirms.java
java -cp $CP PublisherConfirms
- 1
- 2
输出将如下所示:
Published 50,000 messages individually in 5,549 ms
Published 50,000 messages in batch in 2,331 ms
Published 50,000 messages and handled confirms asynchronously in 4,054 ms
- 1
- 2
- 3
如果客户端和服务器位于同一台计算机上,您的计算机上的输出应该类似。按预期,单独发布消息的性能不佳,但与批量发布相比,异步处理的结果有些令人失望。
发布者确认非常依赖于网络,因此最好尝试使用远程节点,在生产中,客户端和服务器通常不在同一台机器上。PublisherConfirms.java 可以很容易地更改为使用非本地节点:
static Connection createConnection() throws Exception {
ConnectionFactory cf = new ConnectionFactory();
cf.setHost("remote-host");
cf.setUsername("remote-user");
cf.setPassword("remote-password");
return cf.newConnection();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
重新编译类,再次执行,然后等待结果:
Published 50,000 messages individually in 231,541 ms
Published 50,000 messages in batch in 7,232 ms
Published 50,000 messages and handled confirms asynchronously in 6,332 ms
- 1
- 2
- 3
我们看到单独发布现在性能非常糟糕。但是在客户端和服务器之间的网络的情况下,批量发布和异步处理现在性能相似,异步处理发布者确认稍微有点优势。
请记住,批量发布易于实现,但在出现负面发布者确认时,不易知道哪些消息无法到达代理。异步处理发布者确认可能稍微复杂,但在性能方面更具优势。

