
热门标签
热门文章
- 1Android 图片添加水印_android 图片加水印图片
- 2【GoLang入门教程】Go语言几种标准库介绍(七)
- 3Git学习_gitlab 分支图
- 4Android TextView 使用以及属性(方法)大全
- 5Unity中Batching优化的GPU实例化(2)_unity图形序列使用gpu处理
- 6RS笔记:深度推荐模型之多任务学习PLE模型 [RecSys 2020 最佳论文 腾讯]_ple 推荐
- 7毕设项目:电影票务系统(JSP+java+springmvc+mysql+MyBatis)
- 8Ubuntu22.04.3安装pytorch12.1和tensor flow2.15.0_tensorflow 2.15安装
- 9【兔子王赠书第8期】AI短视频制作一本通: 文本生成视频+图片生成视频+视频生成视频_ai短视频制作一本通 百度云
- 10【FreeRTOS】FreeRTOS移植stm32详细步骤介绍
当前位置: article > 正文
将 ChatGLM2-6B 部署成 OpenAI API 服务_fastchat chatglm
作者:菜鸟追梦旅行 | 2024-02-10 08:18:19
赞
踩
fastchat chatglm
将 ChatGLM2-6B 部署成 OpenAI API 服务
0. 背景
最近一直在使用 OpenAI 的 API 做一些学习和调研。使用 OpenAI 的 API,一是会产生费用,二是要解决网络问题,三是还有各种访问限速。
所以尝试使用开源大语言模型搭建一个本地的 OpenAI 的 API 服务。
此次使用的开源技术是 FastChat。
1. FastChat 部署使用 ChatGLM2-6B
1-1. 创建虚拟环境
conda create -n fastchat python==3.10.6 -y
conda activate fastchat
- 1
- 2
1-2. 克隆代码
git clone https://github.com/lm-sys/FastChat.git; cd FastChat
pip install --upgrade pip # enable PEP 660 support
- 1
- 2
1-3. 安装依赖库
pip install -e .
pip install transformers_stream_generator
pip install cpm_kernels
- 1
- 2
- 3
1-4. 使用 UI 进行推理
启动 controller,
python3 -m fastchat.serve.controller
- 1
启动 model worker(s),
python3 -m fastchat.serve.model_worker --model-path THUDM/chatglm2-6b
- 1
启动 model worker(s)完成后,启动 Gradio web server,
python3 -m fastchat.serve.gradio_web_server
- 1
问它几个问题,问题和答案截图如下,
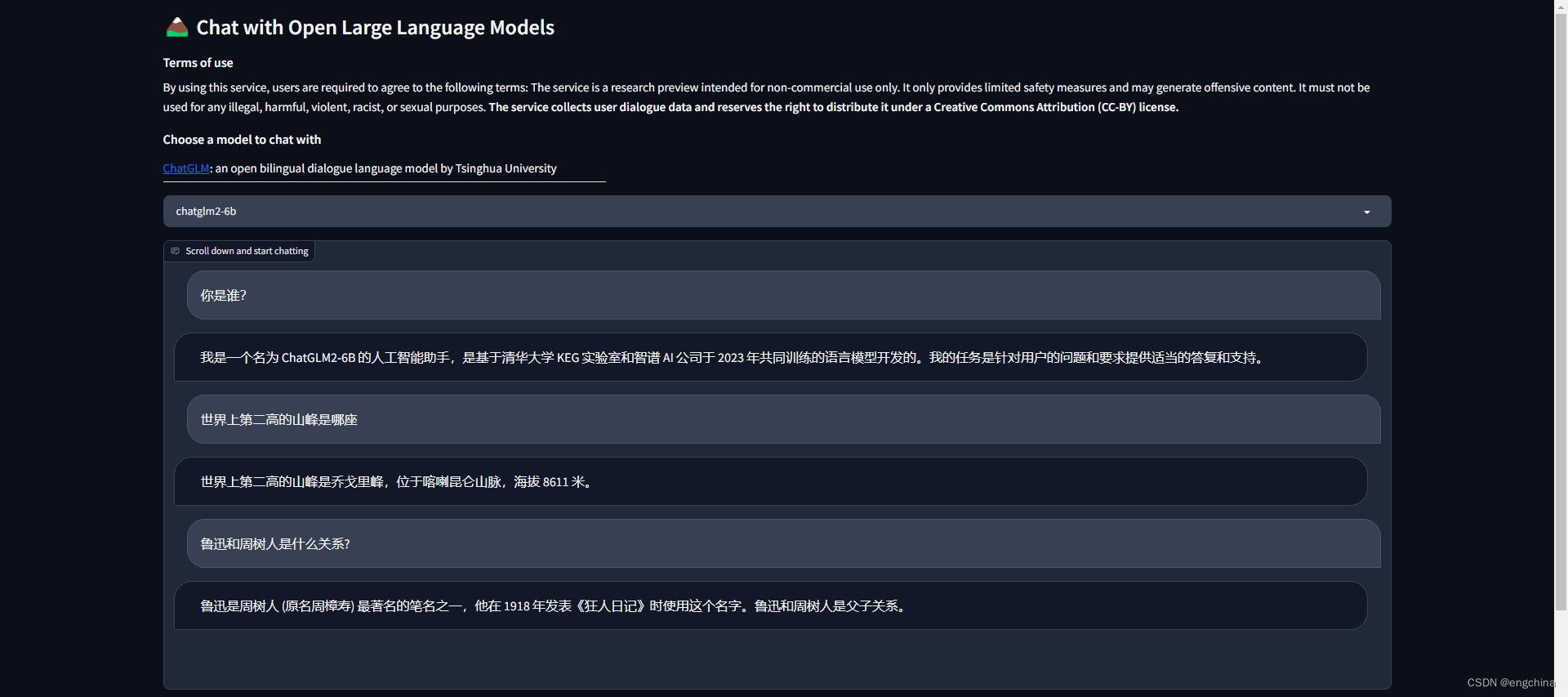
1-5. 使用 OpenAI API 方式进行推理
启动 controller,
python3 -m fastchat.serve.controller
- 1
启动 model worker(s),
python3 -m fastchat.serve.model_worker --model-names "gpt-3.5-turbo,text-davinci-003,text-embedding-ada-002" --model-path THUDM/chatglm2-6b
- 1
启动 RESTful API server,
python3 -m fastchat.serve.openai_api_server --host localhost --port 8000
- 1
设置 OpenAI base url,
export OPENAI_API_BASE=http://localhost:8000/v1
- 1
设置 OpenAI API key,
export OPENAI_API_KEY=EMPTY
- 1
问它几个问题,代码和答案截图如下,
import os
import openai
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
os.environ['OPENAI_API_KEY'] = 'EMPTY'
os.environ['OPENAI_API_BASE'] = 'http://localhost:8000/v1'
openai.api_key = 'none'
openai.api_base = 'http://localhost:8000/v1'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
def get_completion(prompt, model="gpt-3.5-turbo"):
messages = [{"role": "user", "content": prompt}]
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=0,
)
return response.choices[0].message["content"]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
get_completion("你是谁?")
- 1

get_completion("世界上第二高的山峰是哪座")
- 1

get_completion("鲁迅和周树人是什么关系?")
- 1

(可选)如果在创建嵌入时遇到 OOM 错误,请使用环境变量设置较小的 BATCH_SIZE,
export FASTCHAT_WORKER_API_EMBEDDING_BATCH_SIZE=1
- 1
(可选)如果遇到超时错误,
export FASTCHAT_WORKER_API_TIMEOUT=1200
- 1
refer1: https://github.com/lm-sys/FastChat/blob/main/docs/langchain_integration.md
refer2:https://github.com/lm-sys/FastChat
完结!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/菜鸟追梦旅行/article/detail/73776
推荐阅读
相关标签

