
- 1react项目总结_react项目经验
- 2如何在不支持TPM.2 的电脑安装win11_不支持tpm2.0升级windows11甲乙
- 3python安装插件方法
- 4Jenkins项目实战之-xcode+jenkins自动化打iOS包_jenkins xcode
- 5使用Docker安装Jenkins,并能够在该Jenkins中使用Docker
- 6[一维前缀和]leetcode303:区域和检索 - 数组不可变(easy)_leetcode 一维前缀和
- 7WindowsServer 离线安装Docker&端口映射_windows离线安装docker
- 8steam换头像出现服务器错误_steam测试中国版 单机游戏强制防沉迷
- 9【正点原子STM32】STM32时钟系统(时钟树、时钟源、分频器和倍频系数、锁相环、STM32CubeMX时钟树、系统时钟配置步骤)
- 10Python实现PDF文件转表格_python plumber table
ChatGPT和Bard太贵,介绍8个免费开源的大模型解决方案!_常用的开源大数据模型
赞
踩
8个开源的ChatGPT和Bard的替代方案,带你发现更多广泛使用的开源框架和模型。
微信搜索关注《Python学研大本营》,加入读者群,分享更多精彩

1.LLaMA
LLaMA项目包含了一组基础语言模型,其规模从70亿到650亿个参数不等。这些模型在数以百万计的token上进行训练,而且它完全在公开的数据集上进行训练。结果,LLaMA-13B超过了GPT-3(175B),而LLaMA-65B的表现与Chinchilla-70B和PaLM-540B等最佳模型相似。
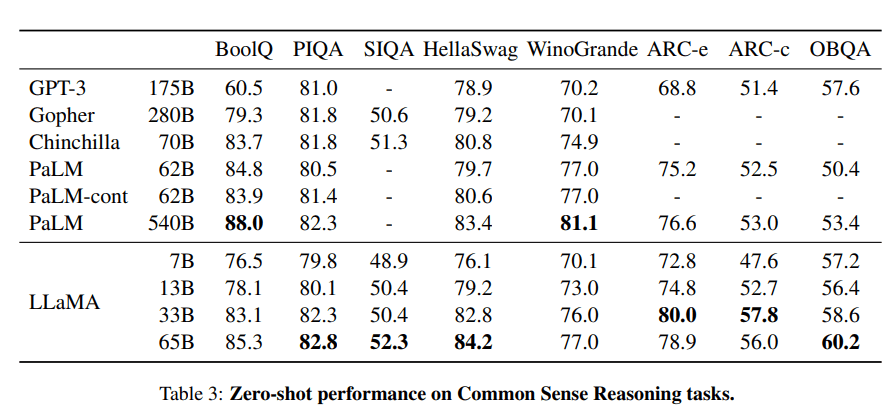
图片来自LLaMA
资源:
-
研究论文:“LLaMA: Open and Efficient Foundation Language Models (arxiv.org)” [https://arxiv.org/abs/2302.13971]
-
GitHub:facebookresearch/llama [https://github.com/facebookresearch/llama]
-
演示:Baize Lora 7B [https://huggingface.co/spaces/project-baize/Baize-7B]
2.Alpaca
斯坦福大学的Alpaca声称它可以与ChatGPT竞争,任何人都可以在不到600美元的情况下复制它。Alpaca 7B是在52K指令遵循的示范上从LLaMA 7B模型中进行微调。

训练内容|图片来自斯坦福大学CRFM
资源:
-
博客:斯坦福大学CRFM。[https://crfm.stanford.edu/2023/03/13/alpaca.html]
-
GitHub:tatsu-lab/stanford_alpaca [https://github.com/tatsu-lab/stanford_alpaca]
-
演示:Alpaca-LoRA (官方演示已经丢失,这是Alpaca模型的再现) [https://huggingface.co/spaces/tloen/alpaca-lora]
3.Vicuna
Vicuna是在从ShareGPT收集到的用户共享对话上的LLaMA模型基础上进行微调。Vicuna-13B模型已经达到了OpenAI ChatGPT和Google Bard的90%以上的质量。它还在90%的情况下超过了LLaMA和斯坦福大学Alpaca模型。训练Vicuna的成本约为300美元。
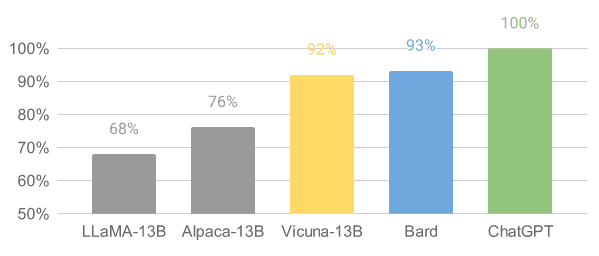
图片来自Vicuna
资源:
-
博客文章:“Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality” [https://vicuna.lmsys.org/]
-
GitHub:lm-sys/FastChat [https://github.com/lm-sys/FastChat#fine-tuning]
-
演示:FastChat (lmsys.org) [https://chat.lmsys.org/]
4.OpenChatKit
OpenChatKit:开源的ChatGPT替代方案,是一个用于创建聊天机器人的完整工具包。它提供了用于训练用户自己的指令调整的大型语言模型、微调模型、用于更新机器人响应的可扩展检索系统以及用于过滤问题的机器人审核的指令。

图片来自TOGETHER
可以看到,GPT-NeoXT-Chat-Base-20B模型在问答、提取和分类任务上的表现优于基础模式GPT-NoeX。
资源:
-
博客文章:“Announcing OpenChatKit”—TOGETHER [https://www.together.xyz/blog/openchatkit]
-
GitHub: togethercomputer/OpenChatKit [https://github.com/togethercomputer/OpenChatKit]
-
演示:OpenChatKit [https://huggingface.co/spaces/togethercomputer/OpenChatKit]
-
模型卡:togethercomputer/GPT-NeoXT-Chat-Base-20B [https://huggingface.co/togethercomputer/GPT-NeoXT-Chat-Base-20B]
5.GPT4ALL
GPT4ALL是一个社区驱动的项目,并在一个大规模的辅助交互语料库上进行训练,包括代码、故事、描述和多轮对话。该团队提供了数据集、模型权重、数据管理过程和训练代码以促进开源。此外,他们还发布了模型的量化4位版本,可以在笔记本电脑上运行。甚至可以使用Python客户端来运行模型推理。

图片来自GPT4ALL
资源:
-
技术报告:GPT4All [https://s3.amazonaws.com/static.nomic.ai/gpt4all/2023_GPT4All_Technical_Report.pdf]
-
GitHub: nomic-ai/gpt4al [https://github.com/nomic-ai/gpt4all]
-
演示:GPT4All(非官方)。[https://huggingface.co/spaces/rishiraj/GPT4All]
-
模型卡:nomic-ai/gpt4all-lora · Hugging Face [https://huggingface.co/nomic-ai/gpt4all-lora]
6.Raven RWKV
Raven RWKV 7B是一个开源的聊天机器人,它由RWKV语言模型驱动,生成的结果与ChatGPT相似。该模型使用RNN,可以在质量和伸缩性方面与transformer相匹配,同时速度更快,节省VRAM。Raven在斯坦福大学Alpaca、code-alpaca和更多的数据集上进行了微调。

图片来自Raven RWKV 7B
资源:
-
GitHub:BlinkDL/ChatRWKV [https://github.com/BlinkDL/ChatRWKV]
-
演示:Raven RWKV 7B [https://huggingface.co/spaces/BlinkDL/Raven-RWKV-7B]
-
模型卡:BlinkDL/rwkv-4-raven [https://huggingface.co/BlinkDL/rwkv-4-raven]
7.OPT
OPT:Open Pre-trained Transformer语言模型并不像ChatGPT那样强大,但它在零样本和少样本学习以及刻板偏见分析方面表现出卓越的能力。还可以将它与Alpa、Colossal-AI、CTranslate2和FasterTransformer集成以获得更好的结果。注意:它上榜的原因是它的受欢迎程度,因为它在文本生成类别中每月有624,710次下载。
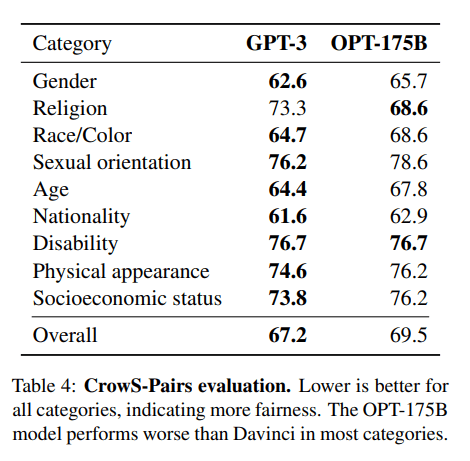
图片来自(arxiv.org)
资源:
-
研究论文:“OPT: Open Pre-trained Transformer Language Models (arxiv.org)” [https://arxiv.org/abs/2205.01068]
-
GitHub: facebookresearch/metaseq [https://github.com/facebookresearch/metaseq]
-
演示:A Watermark for LLMs [https://huggingface.co/spaces/tomg-group-umd/lm-watermarking]
-
模型卡:facebook/opt-1.3b [https://huggingface.co/facebook/opt-1.3b]
8.Flan-T5-XXL
Flan-T5-XXL在以指令形式表述的数据集上微调了T5模型。指令的微调极大地提高了各种模型类别的性能,如PaLM、T5和U-PaLM。Flan-T5-XXL模型在1000多个额外的任务上进行了微调,涵盖了更多语言。
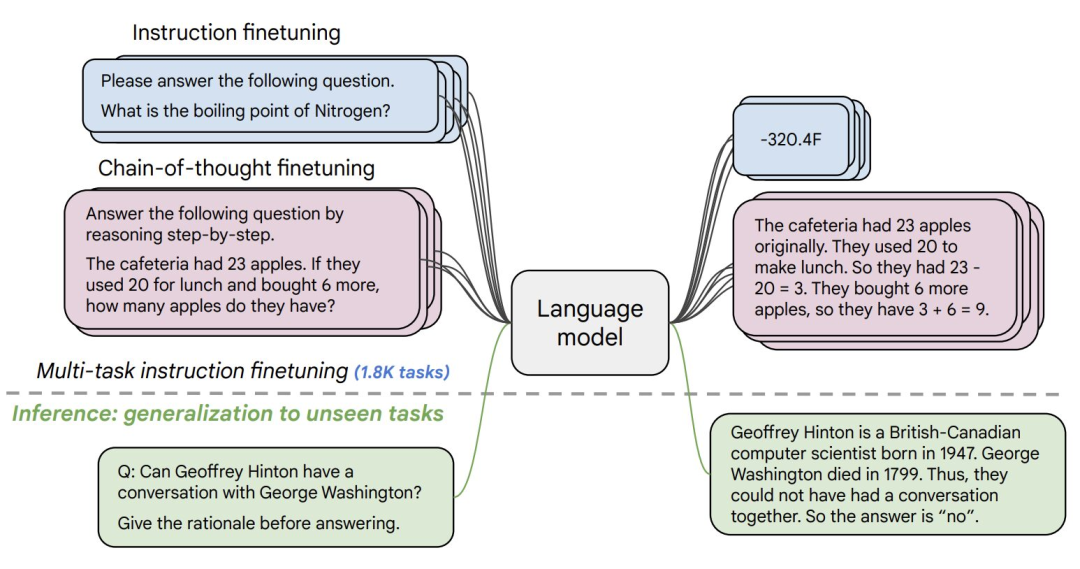
图片来自Flan-T5-XXL
资源:
-
研究论文:“Scaling Instruction-Fine Tuned Language Models” [https://arxiv.org/pdf/2210.11416.pdf]
-
GitHub: google-research/t5x [https://github.com/google-research/t5x]
-
演示:Chat Llm Streaming [https://huggingface.co/spaces/olivierdehaene/chat-llm-streaming]
-
模型卡:google/flan-t5-xxl [https://huggingface.co/google/flan-t5-xxl?text=Q%3A+%28+False+or+not+False+or+False+%29+is%3F+A%3A+Let%27s+think+step+by+step]
总结
现在有很多开源的可供选择的大模型,本文涉及到其中比较流行的8个大模型。
推荐书单
《Python人工智能》
本书系统地介绍了基于Python平台的人工智能的原理及实现过程,全书共7章。第1章“从这里开始认识Python”,介绍人工智能及Python 基础知识;第2章“Python 语法基础”,通过生动有趣的实验实例介绍Python编程语法知识;第3章“Python 程序设计”,以实例为基础,介绍Python 的编程方法;第4 章“数据结构”,通过范例介绍列表、元组、字典、集合、函数等数据结构的使用方法;第5章“数据库及应用”,主要介绍Python数据库应用及Web应用开发技术,通过实例讲解Python数据库应用;第6章“大数据应用”,基于实例,主要介绍网络爬虫、Excel数据爬取及分析处理等技术,了解数据挖掘分析处理等大数据应用技术的一般设计流程;第7 章“人工智能”,以具体实例讲解照片人脸识别、图像识别、视频人脸识别、聊天机器人、微信语音聊天机器人、图文识别、语音识别及花朵识别等人工智能深度学习技术。
本书图文并茂,示例丰富,讲解细致透彻,介绍深入浅出,章后练习精广,具有很强的实用性和可操作性,适合初学或自学Python的学生,可作为中小学STEM 教育或培训机构的人工智能课程教材,也可作为大中专院校人工智能、软件工程、计算机等专业以及相关课程的教材或参考书,还可以当作全国计算机二级(Python)考试的教材使用。

精彩回顾
《大模型技术的根基,解读注意力机制论文《Attention Is All You Need》和代码实现(下)》
《大模型技术的根基,解读注意力机制论文《Attention Is All You Need》和代码实现(上)》
微信搜索关注《Python学研大本营》,加入读者群
访问【IT今日热榜】,发现每日技术热点

