
- 1Flink Windows(窗口)详解
- 2最好用的100个黑科技网站_黑科技论坛
- 3LSTM_CNN文本分类与tensorflow实现_lstm-cnn
- 4JAVA面向对象之对象和类
- 5光猫烽火Hg220破解超级口令实用图文教程(亲测)
- 6Linux系统安装docker-compose_linux安装 docker-compose
- 7【Golang】go mod的使用_golang go mod
- 8人工智能 | ShowMeAI资讯日报 #2022.06.10_real-iad: a real-world multi-view dataset for benc
- 9axios中timeout底层原理_axios timeout
- 10Navicat for sqlserver 注册码_navicat16注册码
20K star!搞定 LLM 微调的开源利器LLaMA Factory_llm factory github
赞
踩
LLM(大语言模型)微调一直都是老大难问题,不仅因为微调需要大量的计算资源,而且微调的方法也很多,要去尝试每种方法的效果,需要安装大量的第三方库和依赖,甚至要接入一些框架,可能在还没开始微调就已经因为环境配置而放弃了。
今天我们分享一个开源项目可以快速进行 LLM 微调,它不单运行效率高,而且还可以在微调过程中进行可视化,非常方便,它就是:LLaMA Factory。

关于LLM 微调
微调大型语言模型需要付出巨大的计算代价,因此高效微调技术应运而生。这些技术可分为两大类:优化型和计算型。
优化型技术
冻结微调(Freeze-tuning) 是一种常见的高效微调方法,它将大部分参数固定不变,只微调解码器的少数几层。这种方式可以大幅降低训练成本,但也可能导致模型性能下降。
梯度低秩投影(GaLore) 的做法是将梯度投影到一个低维空间,从而达到全参数学习的效果,但内存使用量大幅降低。这种方法在大模型上表现较好,因为大模型往往存在较多冗余,投影后损失不大。
低秩适配(LoRA) 是一种非常高效的微调方法,它不会改变预训练模型的原始权重参数。相反,LoRA在需要微调的层上引入了一对小的可训练矩阵,称为低秩矩阵。在前向过程中,模型会对原始权重张量和LoRA低秩矩阵进行相乘运算,得到改变后的权重用于计算。而在反向传播时,只需要计算和更新这对小矩阵的梯度。
这种做法的优势是,可以在不存储新权重的情况下实现模型的微调,从而极大节省内存。对于大型语言模型,权重参数往往占用大部分显存,LoRA能让训练过程只需少量额外显存即可进行。
当结合量化(Quantization)技术时,LoRA的内存优势就更加明显了。量化是将原本占用较多字节的float32/float16类型权重压缩为int8/int4等低比特类型表示,从而降低存储需求。量化后的QLoRA(Quantized LoRA)能将参数内存占用从每个参数18字节降至仅0.6字节,是一种极高效的微调方案。
实验表明,LoRA和QLoRA在较小模型上的效果最为出众,能以最小的内存overhead获得与全量精调相当的性能。其中当结合量化技术时(QLoRA),内存占用会进一步降低。
另一种被称为分解权重低秩适配(DoRA)的方法,在LoRA的基础上进行了改进。DoRA将预训练权重矩阵分解为量级分量和方向分量两部分。它只对方向分量部分应用LoRA,而量级分量保持不变。
这样做的可能性是,预训练权重中的方向分量可能包含了更多任务相关的知识,而量级分量则更多地控制输出的数值范围。因此,只对方向部分进行低秩微调,可能会获得更好的效果。
DoRA相比LoRA的优势在于,使用相同内存开销时,往往能取得更高的性能。但它也增加了计算量,需要预先对权重进行分解。因此在不同场景下,LoRA和DoRA都有可能是更优选择。
LoRA、QLoRA和DoRA等优化型方法极大降低了LLM微调的内存需求,是高效微调中不可或缺的重要技术。LLAMAFACTORY框架对这些技术进行了很好的统一实现,大大简化了用户的使用流程。
LLAMAFACTORY采用了模块化设计,可以灵活插入和切换上述各种优化技术。用户无需coding,只需在LLAMABOARD界面上勾选所需方法即可。
计算型技术
混合精度训练和激活重计算 是最常见的两种节省计算量的方法。前者使用低精度(如FP16)来存储激活值和权重;后者则通过重新计算激活值来节省存储,从而降低内存占用。
闪电注意力(Flash Attention) 是一种对注意力层进行优化的新算法,它以硬件友好的方式重新安排计算过程,大幅提高性能。S2注意力(S2 Attention)则致力于解决长文本注意力计算时的内存开销问题。
此外,各种量化技术如LLM.int8和QLoRA,能将权重和激活值压缩至低精度表示,从而节省大量内存。不过量化模型只能使用基于适配器的微调方法(如LoRA)。
Unsloth则是针对LoRA层的反向传播进行了优化,降低了梯度计算所需的浮点运算数,加速了LoRA训练过程。
LLaMA Factory 将上述技术进行了整合,自动识别模型结构来决定启用哪些优化手段。用户无需关心技术细节,只需选择期望的内存占用和性能要求即可。同时,LLaMA Factory 还支持分布式训练加速等功能。但分布式训练要在CLI上进行。国内很多大模型都是用这个技术微调的,这些数据来自作者的 Github 的README文档:
-
StarWhisper: 天文大模型 StarWhisper,基于 ChatGLM2-6B 和 Qwen-14B 在天文数据上微调而得。
-
DISC-LawLLM: 中文法律领域大模型 DISC-LawLLM,基于 Baichuan-13B 微调而得,具有法律推理和知识检索能力。
-
Sunsimiao: 孙思邈中文医疗大模型 Sumsimiao,基于 Baichuan-7B 和 ChatGLM-6B 在中文医疗数据上微调而得。
-
CareGPT:医疗大模型项目 CareGPT,基于 LLaMA2-7B 和 Baichuan-13B 在中文医疗数据上微调而得。
-
MachineMindset: MBTI性格大模型项目,根据数据集与训练方式让任意LLM 拥有 16 个不同的性格类型。
-
CBT-LLM: 一个基于认知行为治疗的心理健康问题分类的中文大语言模型。
如果你也想尽快推出自己的大模型,这个框架肯定是你学习成本最小的方式。
LLaMA Factory 是什么
LLaMA-Factory是一个统一的框架,集成了一套先进的高效训练方法。它允许用户通过内置的Web UI灵活定制100多个LLMs的微调,而无需编写代码。
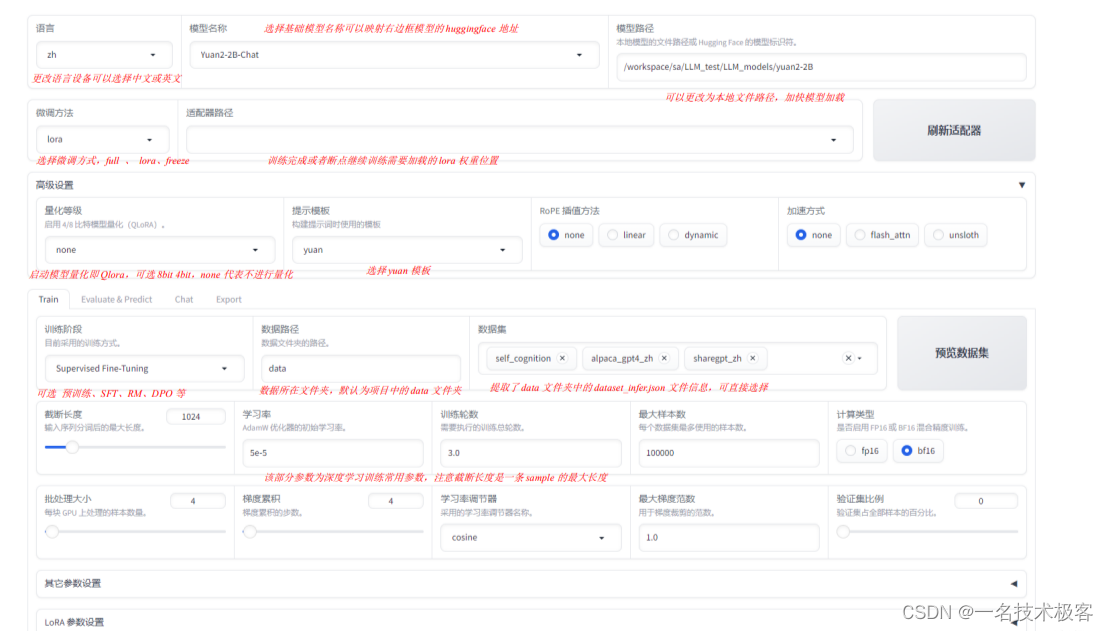
项目具有以下的特色:
-
多种模型: LLaMA、LLaVA、Mistral、Mixtral-MoE、Qwen、Yi、Gemma、Baichuan、ChatGLM、Phi 等等。
-
集成方法:(增量)预训练、(多模态)指令监督微调、奖励模型训练、PPO 训练、DPO 训练和 ORPO 训练。
-
多种精度: 32 比特全参数微调、16 比特冻结微调、16 比特 LoRA 微调和基于 AQLM/AWQ/GPTQ/LLM.int8 的 2/4/8 比特 QLoRA 微调。
-
先进算法: GaLore、BAdam、DoRA、LongLoRA、LLaMA Pro、Mixture-of-Depths、LoRA+、LoftQ 和 Agent 微调。
-
实用技巧: FlashAttention-2、Unsloth、RoPE scaling、NEFTune 和 rsLoRA。
-
实验监控: LlamaBoard、TensorBoard、Wandb、MLflow 等等。
-
极速推理: 基于 vLLM 的 OpenAI 风格 API、浏览器界面和命令行接口。
与 ChatGLM 官方的 P-Tuning 微调相比,LLaMA Factory 的 LoRA 微调提供了 3.7 倍的加速比,同时在广告文案生成任务上取得了更高的 Rouge 分数。结合 4 比特量化技术,LLaMA Factory 的 QLoRA 微调进一步降低了 GPU 显存消耗。
LLaMA Factory 的部署安装非常简单,只需要按照官方仓库中的步骤执行即可,执行命令如下:
# 克隆仓库
git clone <https://github.com/hiyouga/LLaMA-Factory.git>
# 创建虚拟环境
conda create -n llama_factory python=3.10
# 激活虚拟环境
conda activate llama_factory
# 安装依赖
cd LLaMA-Factory
pip install -r requirements.txt
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
接下来是下载 LLM,可以选择自己常用的 LLM,包括 ChatGLM,BaiChuan,QWen,LLaMA 等,这里我们下载 BaiChuan 模型进行演示:
# 方法一:开启 git lfs 后直接 git clone 仓库
git lfs install
git clone <https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat>
# 方法二:先下载仓库基本信息,不下载大文件,然后再通过 huggingface 上的文件链接下载大文件
GIT_LFS_SKIP_SMUDGE=1 git clone <https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat>
cd Baichuan2-13B-Chat
wget "<https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat/resolve/main/pytorch_model-00001-of-00003.bin>"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
方法一的方式会将仓库中的 git 记录一并下载,导致下载下来的文件比较大,建议是采用方法二的方式,速度更快整体文件更小。
使用 LLaMA Factory
启动 LLaMA Factory 的 WebUI 页面,执行命令如下:
CUDA_VISIBLE_DEVICES=0 python src/train_web.py
- 1
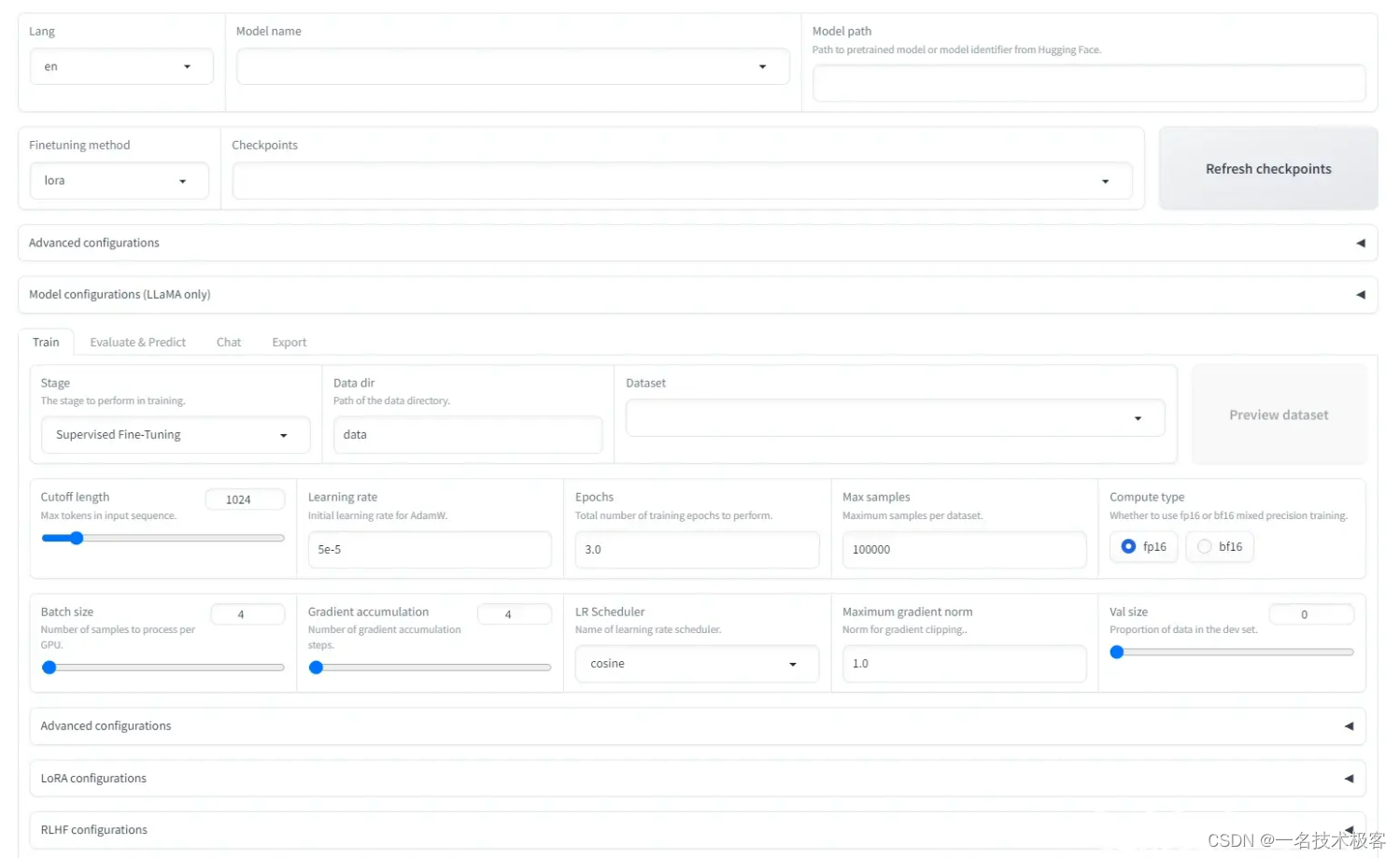
启动后的界面如下:
解释一波
界面分上下两部分,上半部分是模型训练的基本配置,有如下参数:
-
模型名称:可以使用常用的模型,包括 ChatGLM,BaiChuan,QWen,LLaMA 等,我们根据下载的模型选择
Baichuan2-13B-Chat。 -
模型路径:输入框填写我们之前下载的 Baichuan 模型的地址。
-
微调方法有三种:
-
full:将整个模型都进行微调。
-
freeze:将模型的大部分参数冻结,只对部分参数进行微调。
-
lora:将模型的部分参数冻结,只对部分参数进行微调,但只在特定的层上进行微调。
-
-
模型断点:在未开始微调前为空,微调一次后可以点击刷新断点按钮,会得到之前微调过的断点。
-
高级设置和模型设置可以不用管,使用默认值即可。
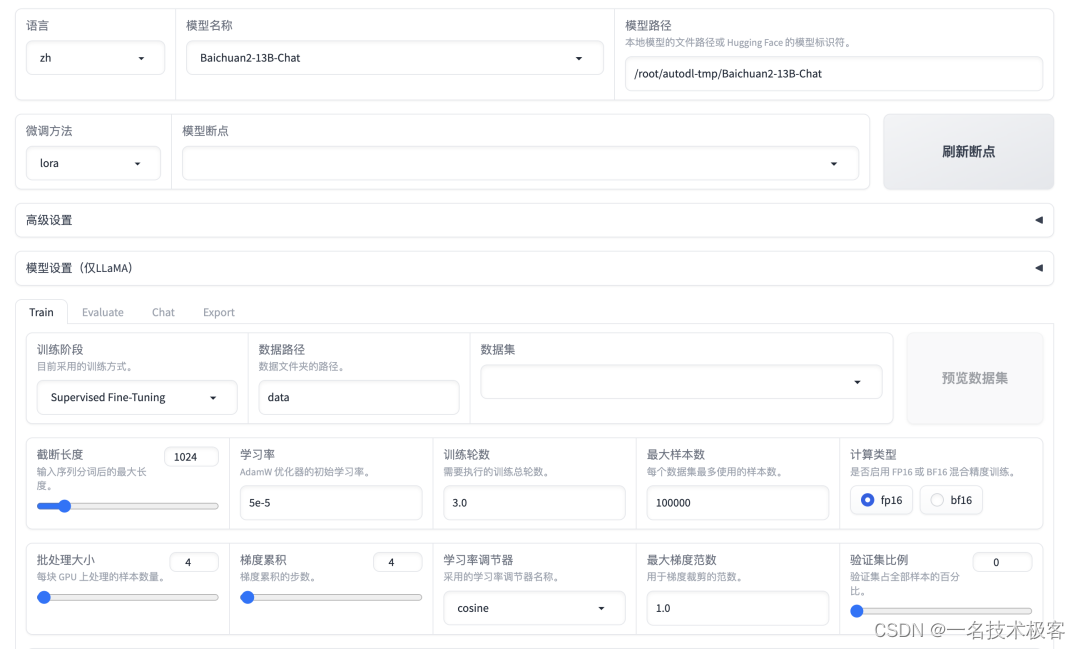
下半部分是一个页签窗口,分为Train、Evaluate、Chat、Export四个页签,微调先看Train界面,有如下参数:
-
训练阶段:选择训练阶段,分为预训练(Pre-Training)、指令监督微调(Supervised Fine-Tuning)、奖励模型训练(Reward Modeling)、PPO 、DPO 五种,这里我们选择指令监督微调(Supervised Fine-Tuning)。
-
Pre-Training:在该阶段,模型会在一个大型数据集上进行预训练,学习基本的语义和概念。
-
Supervised Fine-Tuning:在该阶段,模型会在一个带标签的数据集上进行微调,以提高对特定任务的准确性。
-
Reward Modeling:在该阶段,模型会学习如何从环境中获得奖励,以便在未来做出更好的决策。
-
PPO Training:在该阶段,模型会使用策略梯度方法进行训练,以提高在环境中的表现。
-
DPO Training:在该阶段,模型会使用深度强化学习方法进行训练,以提高在环境中的表现。
-
-
数据路径:指训练数据集文件所在的路径,这里的路径指的是 LLaMA Factory 目录下的文件夹路径,默认是data目录。
-
数据集:这里可以选择数据路径中的数据集文件,这里我们选择
self_cognition数据集,这个数据集是用来调教 LLM 回答诸如你是谁、你由谁制造这类问题的,里面的数据比较少只有 80 条左右。在微调前我们需要先修改这个文件中的内容,将里面的<NAME>和<AUTHOR>替换成我们的 AI 机器人名称和公司名称。选择了数据集后,可以点击右边的预览数据集按钮来查看数据集的前面几行的内容。

-
学习率:学习率越大,模型的学习速度越快,但是学习率太大的话,可能会导致模型在寻找最优解时
跳过最优解,学习率太小的话,模型学习速度会很慢,所以这个参数需要根据实际情况进行调整,这里我们使用默认值5e-5。 -
训练轮数:训练轮数越多,模型的学习效果越好,但是训练轮数太多的话,模型的训练时间会很长,因为我们的训练数据比较少,所以要适当增加训练轮数,这里将值设置为
30。 -
最大样本数:每个数据集最多使用的样本数,因为我们的数据量很少只有
80条,所以用默认值就可以了。 -
计算类型:这里的
fp16 和 bf16是指数字的数据表示格式,主要用于深度学习训练和推理过程中,以节省内存和加速计算,这里我们选择bf16 -
学习率调节器:有以下选项可以选择,这里我们选择默认值
cosine。-
linear(线性): 随着训练的进行,学习率将以线性方式减少。 -
cosine(余弦): 这是根据余弦函数来减少学习率的。在训练开始时,学习率较高,然后逐渐降低并在训练结束时达到最低值。 -
cosine_with_restarts(带重启的余弦): 和余弦策略类似,但是在一段时间后会重新启动学习率,并多次这样做。 -
polynomial(多项式): 学习率会根据一个多项式函数来减少,可以设定多项式的次数。 -
constant(常数): 学习率始终保持不变。 -
constant_with_warmup(带预热的常数): 开始时,学习率会慢慢上升到一个固定值,然后保持这个值。 -
inverse_sqrt(反平方根): 学习率会随着训练的进行按照反平方根的方式减少。 -
reduce_lr_on_plateau(在平台上减少学习率): 当模型的进展停滞时(例如,验证误差不再下降),学习率会自动减少。
-
-
梯度累积和最大梯度范数:这两个参数通常可以一起使用,以保证在微调大型语言模型时,能够有效地处理大规模数据,同时保证模型训练的稳定性。梯度累积允许在有限的硬件资源上处理更大的数据集,而最大梯度范数则可以防止梯度爆炸,保证模型训练的稳定性,这里我们使用默认值即可。
-
断点名称:默认是用时间戳作为断点名称,可以自己修改。
-
其他参数使用默认值即可。
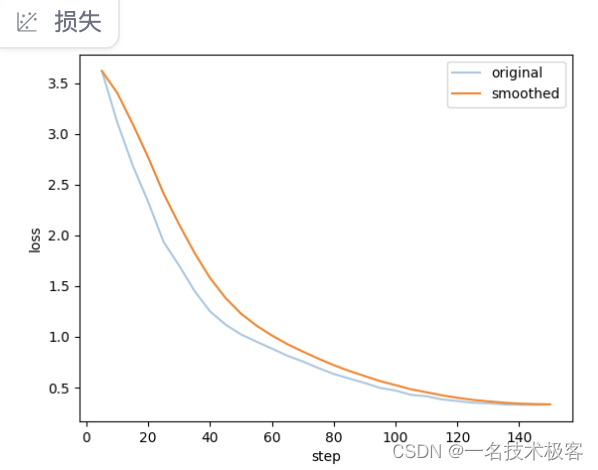
参数设置完后点击预览命令按钮可以查看本次微调的命令,确认无误后点击开始按钮就开始微调了,因为数据量比较少,大概几分钟微调就完成了(具体时间还要视机器配置而定,笔者使用的是 A40 48G GPU),在界面的右下方还可以看到微调过程中损失函数曲线,损失函数的值越低,模型的预测效果通常越好。
进入Chat页签 对微调模型进行试用。首先点击页面上的刷新断点按钮,然后选择我们最近微调的断点名称,再点击加载模型按钮,等待加载完成后就可以进行对话了,输入微调数据集中的问题,然后来看看微调后的LLM的回答吧。
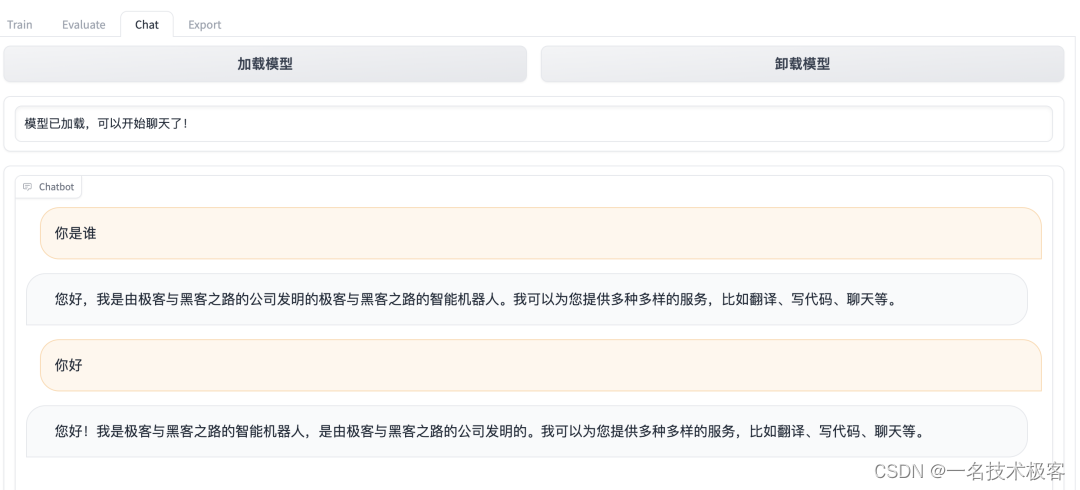
模型导出
如果觉得微调的模型没有问题,就可以将模型导出并正式使用了,点击Export页签,在导出目录中输入导出的文件夹地址。一般模型文件会比较大,右边的最大分块大小参数用来将模型文件按照大小进行切分,默认是10GB,比如模型文件有 15G,那么切分后就变成 2 个文件,1 个 10G,1 个 5G。设置完成后点击开始导出按钮即可,等导出完成后,就可以在对应目录下看到导出的模型文件了。

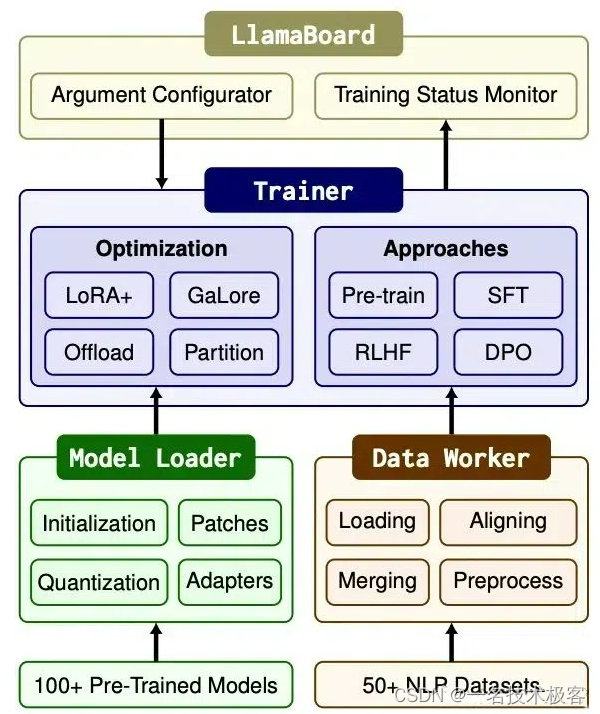
LLaMA-Factory 结构
LLaMA-Factory由三个主要模块组成:模型加载器(Model Loader) 、 数据处理器(Data Worker) 和 训练器(Trainer)。
-
模型加载器准备了各种架构用于微调,支持超过100个LLMs。数据处理器通过一个设计良好的管道处理来自不同任务的数据,支持超过50个数据集。
-
训练器统一了高效微调方法,使这些模型适应不同的任务和数据集,提供了四种训练方法。
-
LLaMA Board为上述模块提供了友好的可视化界面,使用户能够以无需编写代码的方式配置和启动单个LLM微调过程,并实时监控训练状态。
总结
在人工智能领域,大型语言模型(LLM)微调(Fine-Tuning)是当下最热门的话题之一。总体来说LLaMA Factory 是一个非常优质的工具,在LLM微调中帮助用户节省了大量的精力。
这些模型拥有惊人的语言理解和生成能力,但要微调和部署它们以适应特定任务,往往需要大量计算资源和专业知识,代码调试还得有深厚的技术功底。
项目信息
-
项目名称: LLaMA Factory
-
GitHub 链接: https://github.com/hiyouga/LLaMA-Factory
-
Star 数: 20K
参考:
[1] LLaMA Factory: https://github.com/hiyouga/LLaMA-Factory
[2]ChatGLM-Efficient-Turning: https://github.com/hiyouga/ChatGLM-Efficient-Tuning
[3]AutoDL: https://www.autodl.com/home


