
- 1编程学习中的挫折与克服:点亮希望之光
- 22024-HW最新漏洞整理及相应解决方案(一)_cve-2024-23321
- 3git分支规范
- 4BurpSuite_v2.0.05下载与注册(包含注册机)_burpsuite官网
- 5Datawhale AI夏令营第四期魔搭- AIGC方向 task01笔记_metadata.jsonl
- 6linux protobuf安装_linux protocol buffers安装最新版本
- 7深度学习入门必读 | 深度学习算法技术原理和发展_深度学习算法原理
- 8CMS简介_cms 简介
- 9中科天目智能合同管理平台与生态构建
- 10flink中maven项目报错:java: 程序包org.apache.flink.api.java不存在
Llama 4B剪枝蒸馏实战
赞
踩
大型语言模型 (LLM) 因其有效性和多功能性,如今已成为自然语言处理和理解领域的主导力量。LLM(例如 Llama 3.1 405B 和 NVIDIA Nemotron-4 340B)在许多具有挑战性的任务中表现出色,包括编码、推理和数学。然而,它们的部署需要大量资源。因此,业界还有另一种趋势,即开发小型语言模型 (SLM),这种模型在许多语言任务中足够熟练,但部署到大众中却便宜得多。
最近,NVIDIA 研究人员表明,结构化权重修剪(structured weight pruning)与知识提炼(knowledge distillation)相结合形成了一种有效且高效的策略,可以从最初的较大兄弟模型中逐渐获得较小的语言模型。NVIDIA Minitron 8B 和 4B 就是这样的小型模型,它们通过修剪和提炼 NVIDIA Nemotron 系列中较大的 15B 兄弟模型而获得。
修剪和提炼可带来多种好处:
- 与从头开始训练相比,MMLU 分数提高了 16%。
- 每个附加模型所需的训练 token 更少,约 100B 个 token,最多可减少 40 倍。
- 与从头开始训练所有模型相比,训练一系列模型的计算成本最多可节省 1.8 倍。
- 性能可与 Mistral 7B、Gemma 7B 和 Llama-3 8B 相媲美,训练的 token 数量更多,最多可达 15T。
本文还介绍了一套实用有效的 LLM 结构化压缩最佳实践,将深度、宽度、注意力和 MLP 修剪与基于知识蒸馏的再训练相结合。
在这篇文章中,我们首先讨论这些最佳实践,然后展示它们应用于 Llama 3.1 8B 模型以获得 Llama-3.1-Minitron 4B 模型时的有效性。 Llama-3.1-Minitron 4B 的表现优于 Minitron 4B、Phi-2 2.7B、Gemma2 2.6B 和 Qwen2-1.5B 等类似规模的先进开源模型。Llama-3.1-Minitron 4B 即将发布到 NVIDIA HuggingFace 系列,等待批准。

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
1、修剪和提炼
修剪是使模型更小更精简的过程,可以通过删除层(深度修剪)或删除神经元和注意力头并嵌入通道(宽度修剪)来实现。修剪通常伴随着一定程度的再训练以恢复准确性。
模型提炼是一种用于将知识从大型复杂模型(通常称为教师模型)转移到较小、更简单的学生模型的技术。目标是创建一个更高效的模型,该模型保留了原始大型模型的大部分预测能力,同时运行速度更快、资源消耗更少。
有两种主要的提炼方式:
- SDG 微调:从较大的教师模型生成的合成数据用于进一步微调较小的、经过预训练的学生模型。在这里,学生仅模仿老师预测的最终标记。Azure AI Studio 中的 Llama 3.1 Azure 提炼和 AWS 使用 Llama 3.1 405B 进行合成数据生成和提炼以微调较小模型教程就是一个例子。
- 经典知识提炼:学生模仿训练数据集上的老师的 logit 和其他中间状态,而不仅仅是学习必须预测的标记。这可以被视为提供更好的标签(与一次性标签相比的分布)。即使使用相同的数据,梯度也包含更丰富的反馈,从而提高训练准确性和效率。但是,由于 logit 太大而无法存储,因此必须有训练框架支持这种提炼方式。
这两种提炼方式是相辅相成的,而不是互相排斥的。这篇文章主要关注经典的知识提炼方法。
2、修剪和提炼程序
我们提出将修剪与经典知识提炼相结合,作为一种资源高效的再训练技术(图 1)。
- 我们从 15B 模型开始。我们估计了每个组件(层、神经元、头部和嵌入通道)的重要性,然后对模型进行排序和修剪,使其达到目标大小:8B 模型。
- 我们使用模型提炼执行了轻度再训练程序,以原始模型为老师,修剪后的模型为学生。
- 训练后,小模型(8B)作为起点,修剪和提炼为更小的 4B 模型。

图 1. 迭代模型修剪和提炼过程
图 1 显示了单个模型的修剪和提炼过程(顶部)以及模型修剪和提炼链(底部)。在后者中,前一阶段的输出模型用作下一阶段的输入模型。
2.1 重要性分析
要修剪模型,了解模型的哪些部分很重要至关重要。我们建议使用纯基于激活的重要性估计策略,该策略使用小型(1024 个样本)校准数据集和仅前向传播传递同时计算所有考虑的轴(深度、神经元、头部和嵌入通道)的敏感度信息。与依赖梯度信息并需要后向传播传递的策略相比,此策略更直接且更具成本效益。
在修剪时,你可以迭代地在给定轴或轴组合的修剪和重要性估计之间交替。但是,我们的实证工作表明,使用单次重要性估计就足够了,迭代估计没有任何好处。
2.2 使用经典知识蒸馏进行再训练
图 2 显示了蒸馏过程,其中 N 层学生模型(修剪模型)是从 M 层教师模型(原始未修剪模型)蒸馏而来。学生通过最小化嵌入输出损失、logit 损失和映射到学生块 S 和教师块 T 的 transformer 编码器特定损失的组合来学习。
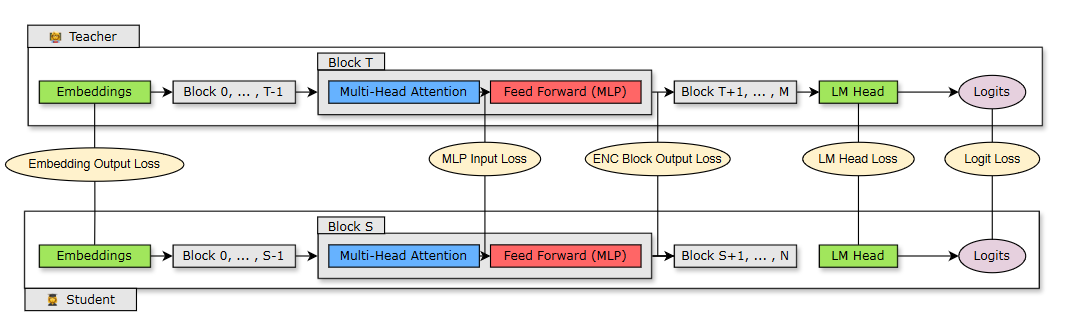
图 2. 蒸馏训练损失
3、修剪和蒸馏最佳实践
基于通过修剪和知识蒸馏在紧凑语言模型中进行的广泛消融研究,我们将我们的学习总结为几个结构化压缩最佳实践:
调整大小:
- 要训练一个 LLM 系列,首先训练最大的一个,然后迭代修剪和蒸馏以获得较小的 LLM。
- 如果使用多阶段训练策略训练最大的模型,最好修剪和重新训练从训练的最后阶段获得的模型。
- 修剪最接近目标大小的可用源模型。
修剪:
- 优先考虑宽度而不是深度修剪。这对于考虑的模型规模(≤ 15B)效果很好。
- 使用单次重要性估计。迭代重要性估计没有任何好处。
再训练:
- 仅使用蒸馏损失而不是常规训练进行再训练。
- 当深度显着减少时,使用 logit 加中间状态加嵌入蒸馏。
- 当深度没有显著减少时,使用仅对 logit 进行提炼。
4、Llama-3.1-Minitron:将最佳实践付诸实践
Meta 最近推出了功能强大的 Llama 3.1 模型系列,这是第一批开源模型,在许多基准测试中可与闭源模型相媲美。Llama 3.1 的范围从巨大的 405B 模型到 70B 和 8B。
凭借 Nemotron 提炼的经验,我们着手将 Llama 3.1 8B 模型提炼为更小、更高效的 4B 兄弟模型:
- 教师微调
- 仅深度修剪
- 仅宽度修剪
- 准确度基准
- 性能基准
4.1 教师微调
为了纠正模型训练所用的原始数据集上的分布偏移,我们首先在我们的数据集(94B 个标记)上微调了未修剪的 8B 模型。实验表明,如果不纠正分布偏移,教师在提炼时会提供次优的数据集指导。
4.2 仅深度修剪
为了从 8B 变为 4B,我们修剪了 16 层(50%)。我们首先通过从模型中删除每个层或连续的层子组并观察下游任务的 LM 损失增加或准确度降低来评估它们的重要性。
图 5 显示了删除 1、2、8 或 16 层后验证集上的 LM 损失值。例如,第 16 层的红色图表示如果我们删除前 16 层,则 LM 损失。如果我们保留第一层并删除第 2 至第 17 层,第 17 层表示 LM 损失。我们观察到开始和结束的层是最重要的。
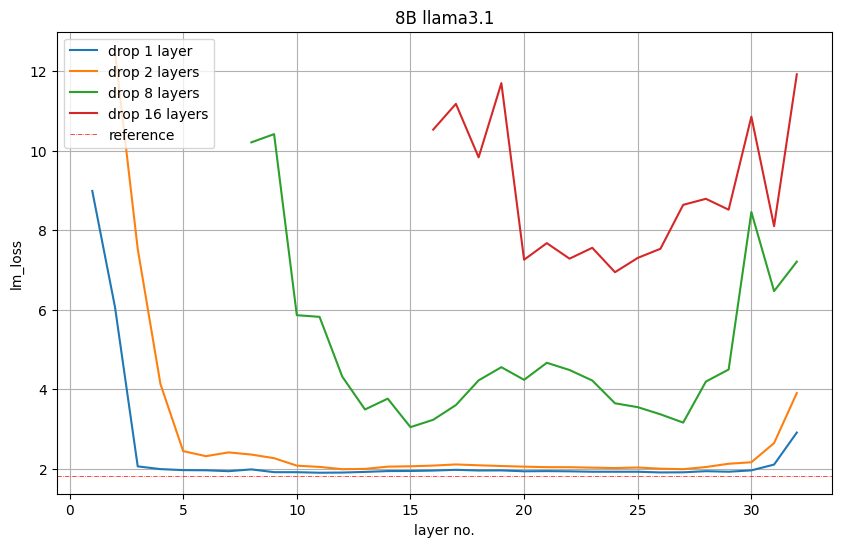
图 5. 仅深度剪枝中的层重要性
然而,我们观察到这种 LM 损失不一定与下游性能直接相关。
图 6 显示了每个剪枝模型的 Winogrande 准确率。它表明最好删除第 16 至第 31 层,其中第 31 层是倒数第二层,剪枝模型的 5 次准确率明显高于随机准确率 (0.5)。我们采纳了这一见解并删除了第 16 至第 31 层。
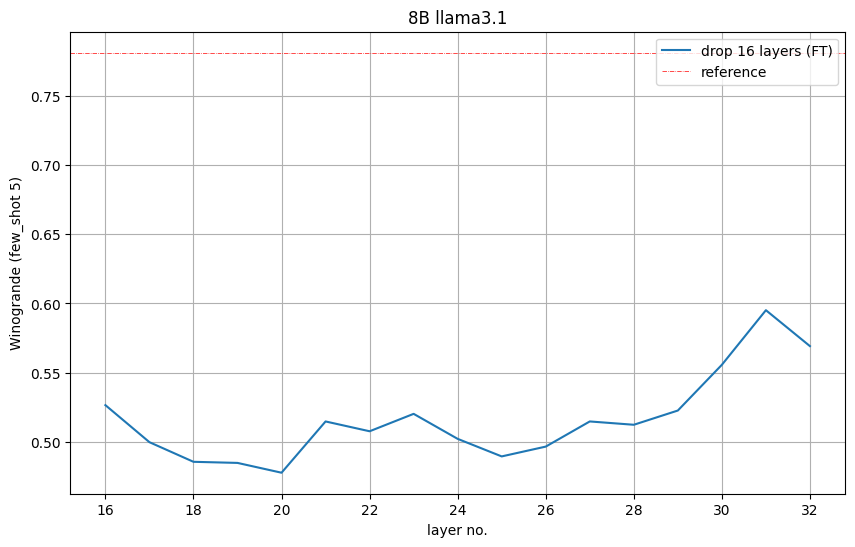
图 6. 删除 16 个层时 Winogrande 任务的准确率
4.3 仅宽度修剪
我们沿宽度轴修剪了嵌入(隐藏)和 MLP 中间维度,以压缩 Llama 3.1 8B。具体来说,我们使用前面描述的基于激活的策略计算了每个注意头、嵌入通道和 MLP 隐藏维度的重要性分数。在重要性估计之后,我们:
- 将 MLP 中间维度从 14336 修剪为 9216。
- 将隐藏大小从 4096 修剪为 3072。
- 重新训练注意头数量和层数。
值得一提的是,在一次性修剪之后,宽度修剪的 LM 损失高于深度修剪。然而经过短暂的重新训练后,趋势发生了逆转。
4.4 准确度基准
我们用以下参数提炼了模型:
- 峰值学习率=1e-4
- 最小学习率=1e-5
- 40 步线性预热
- 余弦衰减时间表
- 全局批量大小=1152
表 1 显示了 Llama-3.1-Minitron 4B 模型变体(宽度剪枝和深度剪枝)与原始 Llama 3.1 8B 模型和其他类似大小的模型在跨多个领域的基准测试中的比较性能。
总体而言,我们再次证实了与遵循最佳实践的深度剪枝相比,宽度剪枝策略的有效性。
| Benchmark | No. of shots | Metric | Llama-3.1 8B | Minitron 4B | Llama-3.1-Minitron 4B | Phi-2 2.7B | Gemma2 2.6B† | Qwen2-1.5B† | |
| Width-pruned | Depth-pruned | Width-pruned | |||||||
| winogrande | 5 | acc | 0.7727 | 0.7403* | 0.7214 | 0.7348 | 0.7400** | 0.709 | 0.662 |
| arc_challenge | 25 | acc_norm | 0.5794 | 0.5085 | 0.5256 | 0.5555** | 0.6100* | 0.554 | 0.439 |
| MMLU | 5 | acc | 0.6528 | 0.5860** | 0.5871 | 0.6053* | 0.5749 | 0.513 | 0.565 |
| hellaswag | 10 | acc_norm | 0.8180 | 0.7496 | 0.7321 | 0.7606* | 0.7524** | 0.73 | 0.666 |
| gsm8k | 5 | acc | 0.4860 | 0.2411 | 0.1676 | 0.4124 | 0.5500** | 0.239 | 0.585* |
| truthfulqa | 0 | mc2 | 0.4506 | 0.4288 | 0.3817 | 0.4289 | 0.4400** | – | 0.459* |
| XLSum en (20%) | 3 | rougeL | 0.3005 | 0.2954* | 0.2722 | 0.2867** | 0.0100 | – | – |
| MBPP | 0 | pass@1 | 0.4227 | 0.2817 | 0.3067 | 0.324 | 0.4700* | 0.29 | 0.374** |
| Training Tokens | 15T | 94B | 1.4T | 3T | 7T | ||||
表 1. Minitron 4B 基础模型与类似大小的基础社区模型的准确度比
- *最佳模型
- ** 次优模型
- – 不可用结果
- † 结果如模型发布者在模型报告中所述。
为了验证提炼后的模型是否可以成为强大的指导模型,我们使用 NeMo-Aligner 对 Llama-3.1-Minitron 4B 模型进行了微调。我们使用了用于 Nemotron-4 340B 的训练数据,并在 IFEval、MT-Bench、ChatRAG-Bench 和 Berkeley Function Calling Leaderboard (BFCL) 上评估了模型,以测试指令遵循、角色扮演、RAG 和函数调用功能。我们确认 Llama-3.1-Minitron 4B 模型可以成为可靠的指导模型,其表现优于其他基线 SLM(表 2)。
| Minitron 4B | Llama-3.1-Minitron 4B | Gemma 2B | Phi-2 2.7B | Gemma2 2.6B | Qwen2-1.5B | ||
| Benchmark | Width-pruned | Depth-pruned | Width-pruned | ||||
| IFEval | 0.4484 | 0.4257 | 0.5239** | 0.4050 | 0.4400 | 0.6451* | 0.3981 |
| MT-Bench | 5.61 | 5.64 | 6.34** | 5.19 | 4.29 | 7.73* | 5.22 |
| ChatRAG† | 0.4111** | 0.4013 | 0.4399* | 0.3331 | 0.3760 | 0.3745 | 0.2908 |
| BFCL | 0.6423 | 0.6680* | 0.6493** | 0.4700 | 0.2305 | 0.3562 | 0.3275 |
| Training Tokens | 94B | 3T | 1.4T | 2T | 7T | ||
表 2. 对齐的 Minitron 4B 基础模型与类似大小的对齐社区模型的准确性比较
- *最佳模型
- ** 第二佳模型
- † 基于 ChatRAG 的代表性子集,而不是整个基准。
4.5 性能基准
我们使用 NVIDIA TensorRT-LLM (一种用于优化 LLM 推理的开源工具包)优化了 Llama 3.1 8B 和 Llama-3.1-Minitron 4B 模型。
图 7 和图 8 显示了不同模型在不同用例下以 FP8 和 FP16 精度每秒的吞吐量请求,表示为 8B 模型的批大小为 32 的输入序列长度/输出序列长度 (ISL/OSL) 组合以及 4B 模型的批大小为 64 的输入序列长度/输出序列长度 (ISL/OSL) 组合,这要归功于较小的权重允许较大的批大小,在一个 NVIDIA H100 80GB GPU 上。
Llama-3.1-Minitron-4B-Depth-Base 变体是最快的,平均吞吐量约为 Llama 3.1 8B 的 2.7 倍,而 Llama-3.1-Minitron-4B-Width-Base 变体的平均吞吐量约为 Llama 3.1 8B 的 1.8 倍。与 BF16 相比,在 FP8 中部署还可使这三种型号的性能提高约 1.3 倍。
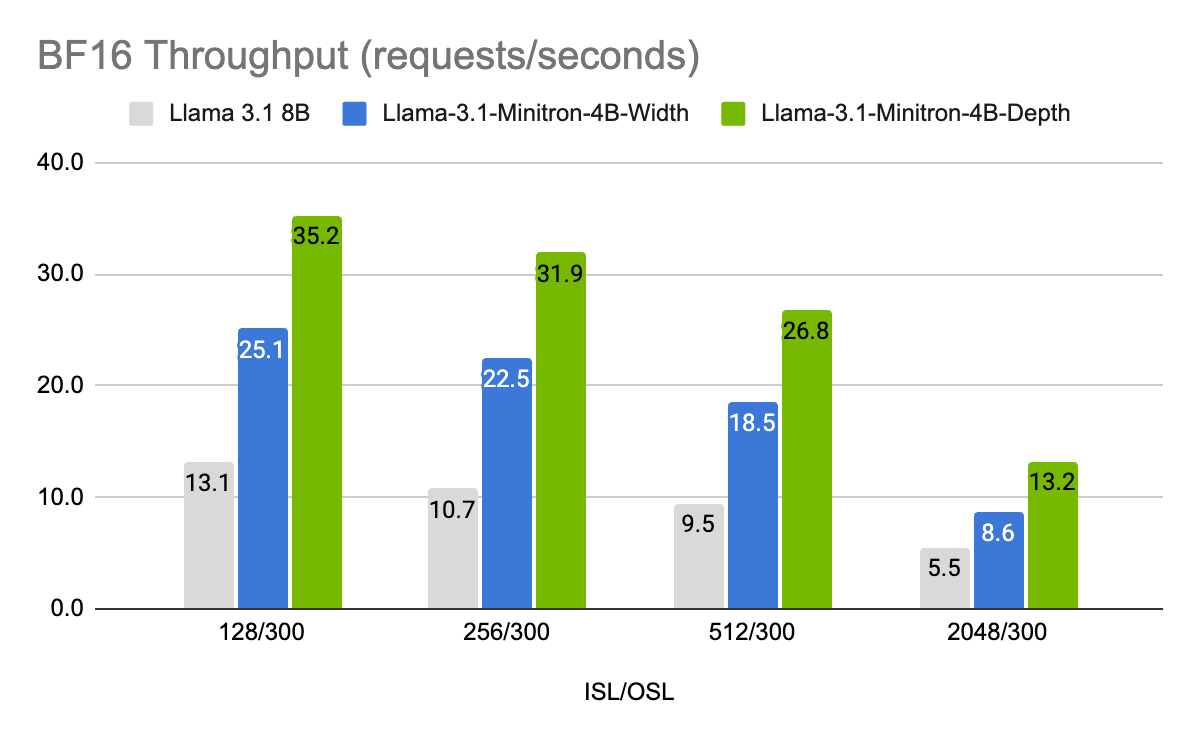
图 7. 不同输入/输出长度组合下的请求 BF16 吞吐量性能基准
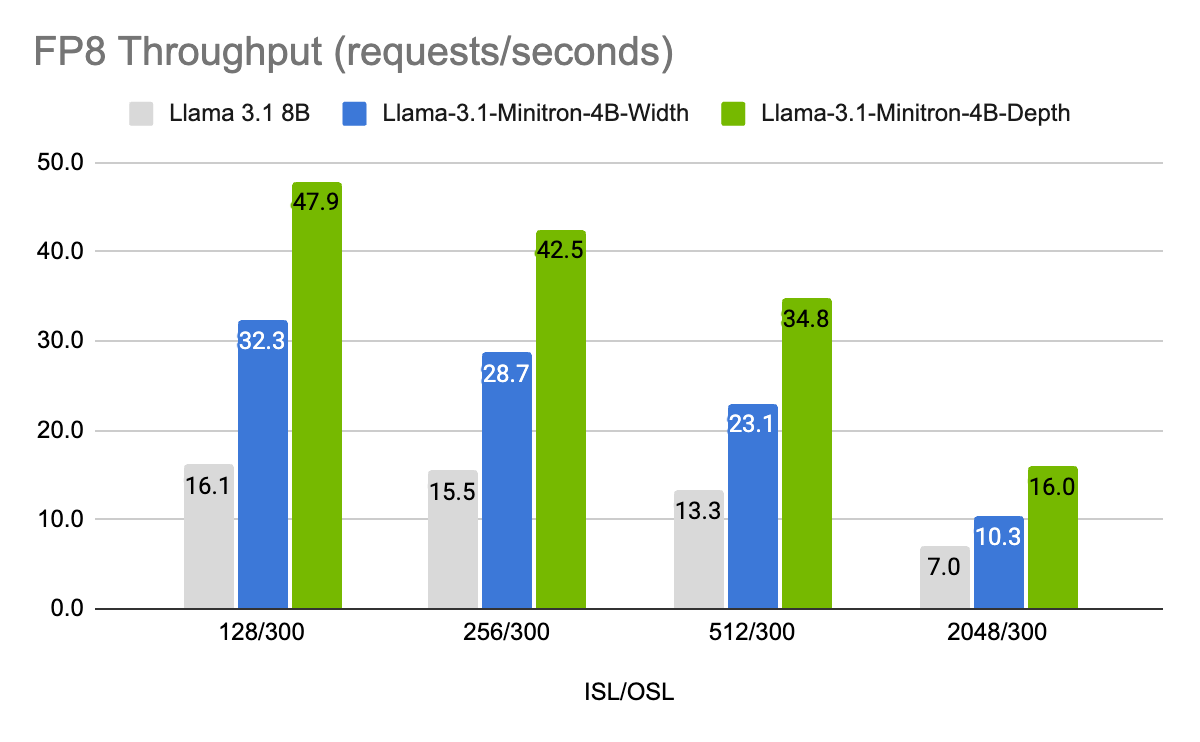
图 8. 不同输入/输出长度组合下请求 FP8 吞吐量的性能基准
组合:Llama 3.1 8B 的 BS=32 和 Llama-3.1-Minitron 4B 模型的 BS=64。1x H100 80GB GPU。
5、结束语
修剪和经典知识提炼是一种非常经济高效的方法,可以逐步获得更小尺寸的 LLM,与在所有领域从头开始训练相比,可实现更高的准确性。与合成数据式微调或从头开始预训练相比,它是一种更有效、数据效率更高的方法。
Llama-3.1-Minitron 4B 是我们首次使用最先进的开源 Llama 3.1 系列进行的工作。要在 NVIDIA NeMo 中使用 Llama-3.1 的 SDG 微调,请参阅 GitHub 上的 /sdg-law-title-generation 笔记本。

