
- 1大模型管理工具Ollama搭建及整合springboot
- 2基于springboot的婚纱摄影服务软件毕业设计源码_springboot婚纱租赁
- 3最全什么是软件测试?_what is software testing(1),征服软件测试面试官
- 4Unity VR 开发教程: Meta Quest 一体机开发 (一) 环境配置(基于 Oculus Integration v46)_unity quest
- 5webSocket使用教程_websocket is not supported by this browser.
- 6Linux系统管理基础-RHEL软件包管理03-yum指令的man手册_yum multiple matches
- 7七天入门大模型 :LLM和多模态模型高效推理实践_llm模型推理 实践
- 8MVVM框架与VUE的认识_前端开发主流技术mvvm和开发框架vue谁先出现
- 9Android7.0修改时间服务器_android7.0 如何配置ntp服务
- 10大厂面试官问我:布隆过滤器有不能扩容和删除的缺陷,有没有可以替代的数据结构呢?【后端八股文二:布隆过滤器八股文合集】
第十四周:机器学习周报_transformer 手推
赞
踩
目录
Seq2aeq for Text-to-Speech (TTS) Synthesis (语音合成)
Seq2seq for Syntactic Parsing (文法剖析)
Seq2seq for Multi-label Classification
摘要
Transform是在神经网络之后又发展的一个比较流行的深度模型,通过学习了解到Transformer不同与以往其他神经网络,由且仅由self-Attenion和Feed Forward Neural Network组成。Transform类似seq2seq模型,首先了解了seq2seq模型,以及在各方面的应用。Transform模型分为编码(Encode)和解码(Decoder)两个模块。通过假想翻译任务对Transform模型进行手动推导,运作机制先将句子输入到Encoder模型中不断计算,直到计算到最后一层,再映射到Decoder模型中进行解码最后输出结果。
Abstract
Transform is a popular deep model developed after neural networks. Through learning, we know that Transformer is different from other neural networks in the past and consists only of self attention and Feed Forward Neural Network. Transform is similar to the seq2seq model. Firstly, we learned about the seq2seq model and its applications in various aspects. The Transform model is divided into two modules: Encoder and Decoder. By manually deriving the Transform model through hypothetical translation tasks, the operating mechanism first inputs sentences into the Encoder model and continuously calculates them until they reach the final layer, then maps them to the Decoder model for decoding and finally outputs the results.
Sequence-to-sequence(Seq2aeq)
今天要学习的Transformer就是一个Sequence-to-sequence的模型,首先讲一下什么是Sequence-to-sequence model。
在第九周学习self-attention的时候讲到了输入一个sequence,输出有几种可能,其中Sequence-to-sequence model即输入一个sequence,输出一个sequence,其中输出的长度由模型自己决定
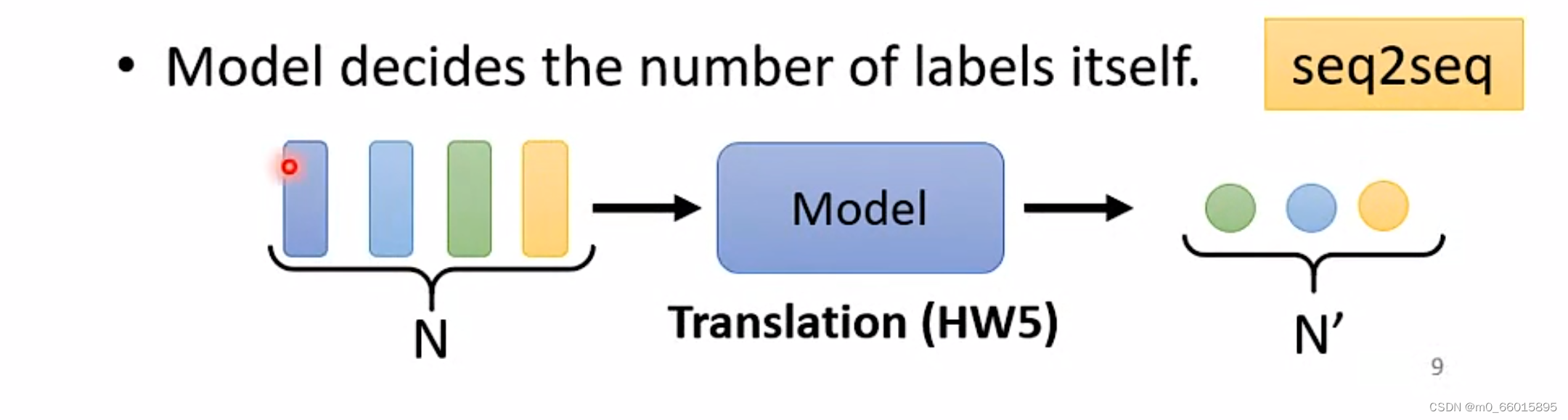
Sequence-to-sequence model有很多实际应用例子,例如语音辨识、机器翻译、语音翻译、语音合成、聊天机器人等。
Speech Recognition(语音识别):输入一段声音讯号,输出这段声音讯号所对应的文字。输入跟输出的长度没有绝对的关系,由机器决定。

Machine Translation(机器翻译):输入一个语言的句子,输出另外一种语音的句子,输入跟输出的长度没有绝对的关系,由机器决定。

Speech Translation(语音翻译):输入一段声音讯号,输出对应的中文句子。类似于Speech Recognition+Machine Translation,但是很多种语言是没有对应的文字的,因此要做语音辩识,可能根本就没有办法,因为他没有文字,但我们可能可以对这些语言做语音翻译,把它翻译成我们有办法阅读的文字。

Seq2aeq for Text-to-Speech (TTS) Synthesis (语音合成)
如果有一个模型,它的输入是台语声音 输出中文的文字,那这就是语音辨识,反过来输入文字输出声音讯号,就是语音合成。
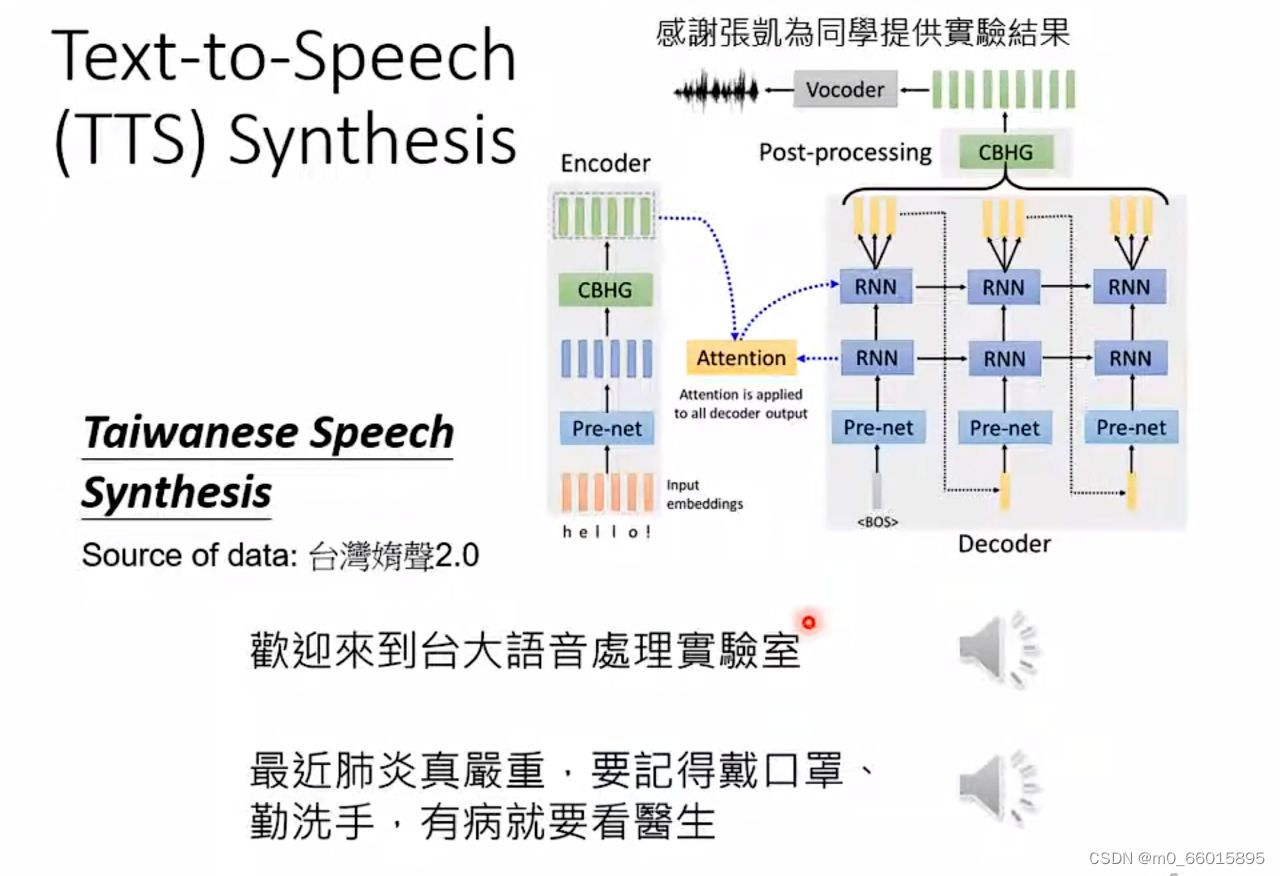 这边模型还是分成两阶,先把中文的文字转成台语的台罗拼音,就像是台语的KK音标,在把台语的KK音标转成声音讯号。从台语的KK音标转成声音讯号这一段,就是一个像是Transformer的network,其实是一个叫做echotron的model,其本质上就是一个Seq2Seq model,大概长的是这个样子 (右上角图)。
这边模型还是分成两阶,先把中文的文字转成台语的台罗拼音,就像是台语的KK音标,在把台语的KK音标转成声音讯号。从台语的KK音标转成声音讯号这一段,就是一个像是Transformer的network,其实是一个叫做echotron的model,其本质上就是一个Seq2Seq model,大概长的是这个样子 (右上角图)。
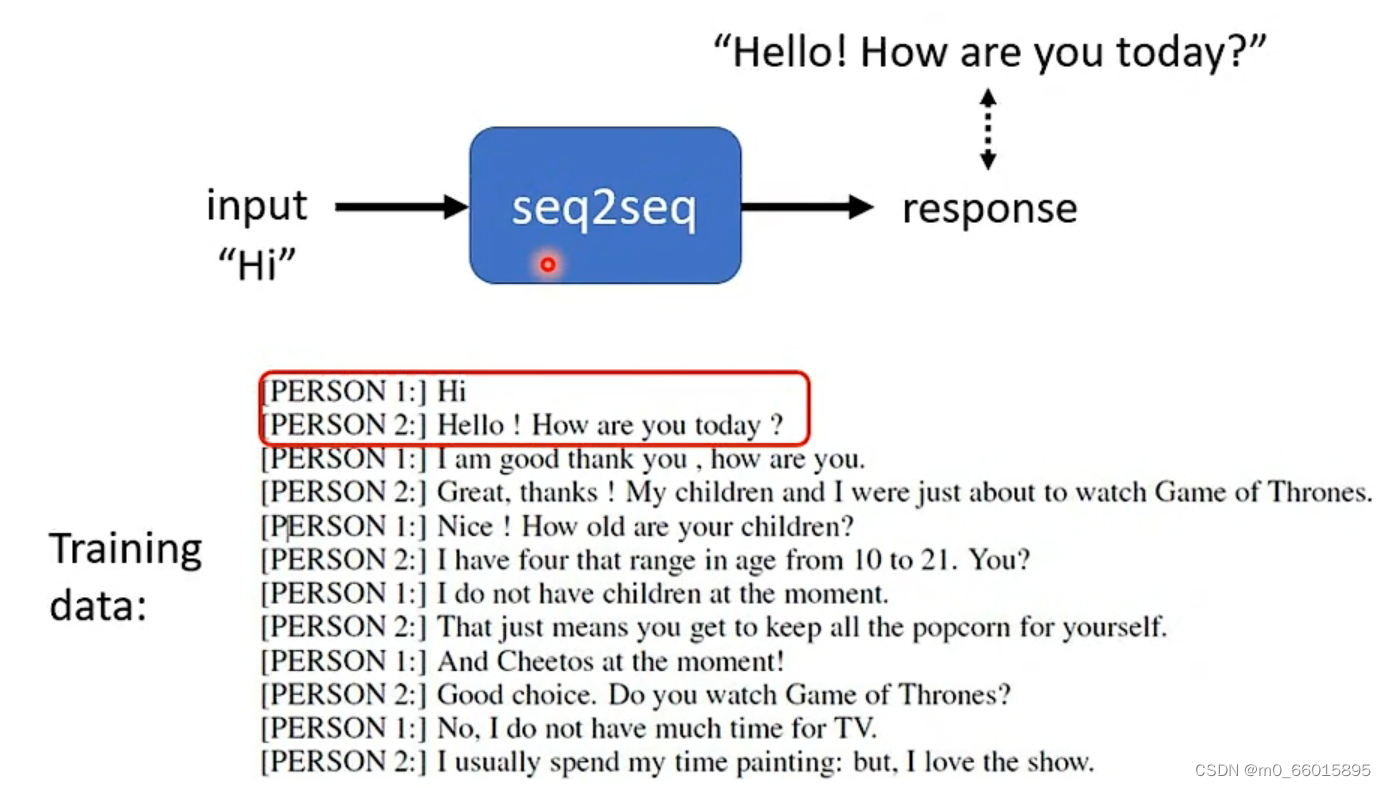
Seq2aeq for Chatbot(聊天机器人)
Seq2aeq模型在文字上也广泛使用,例如可以使用Seq2aeq模型训练一个聊天机器人。聊天机器人即逆对他说一句话,它可以根据输入给出回应,输入输出都是文字也就是vector sequence。而训练一个聊天机器人需要给它喂入大量人的对话作为训练资料让它学习。
Question Answering (QA)
Seq2Seq的模型在NLP领域上的任务都可以想象成是Question Answering (QA) 的任务,而QA就是一问一答,你给机器输入一段文字,希望机器读入你的文字然后给出你一个正确的答案。因此各式各样的NLP问题都可以看作QA问题,而QA问题可以用Seq2Seq model解决。Seq2Seq model只要是输入一段文字,输出一段文字,只要是输入一个Sequence,输出一个Sequence就可以解。所以Seq2Seq model可以解决大量NLP的问题。
Seq2seq for Syntactic Parsing (文法剖析)
Seq2seq for Syntactic Parsing 文法剖析
很多NLP领域的任务,可能觉得它不是Seq2Seq model的问题,但都可以硬用Seq2Seq model的问题硬解。举例来说文法剖析,给机器一段文字,机器要做的事情是产生一个文法的剖析树 。
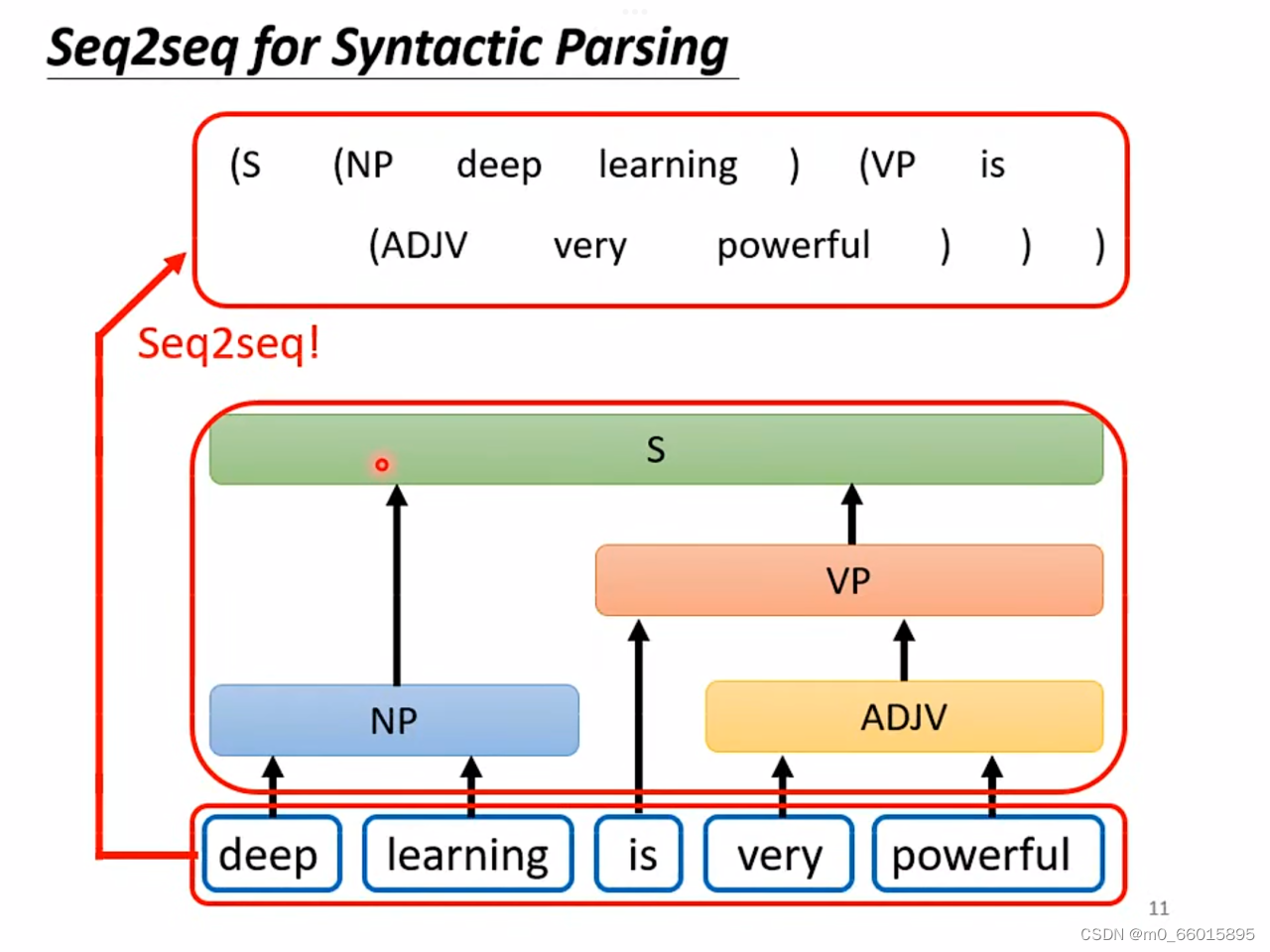
但从输出来看并不是一个sequence,而是一个但事实上一个树状的结构,可以硬是把他看作是一个Sequence,这个树状结构可以对应到如下这样的Sequence,然后就可以用Seq2Seq的方法去解决,这个方法听上去不切实际,但是还是可以实现的。
Seq2seq for Multi-label Classification
multi-class classification与multi-label classification的区别就是:multi-class classification意思是在做分类的时候并不只一个class,机器要做的事情,是从数个class里面,选择某一个class出来。multi-label classification意思是说同一个东西,它可以属于多个class,例如做文章分类的时候,一片文章可以既属于生物学又属于分子化学。
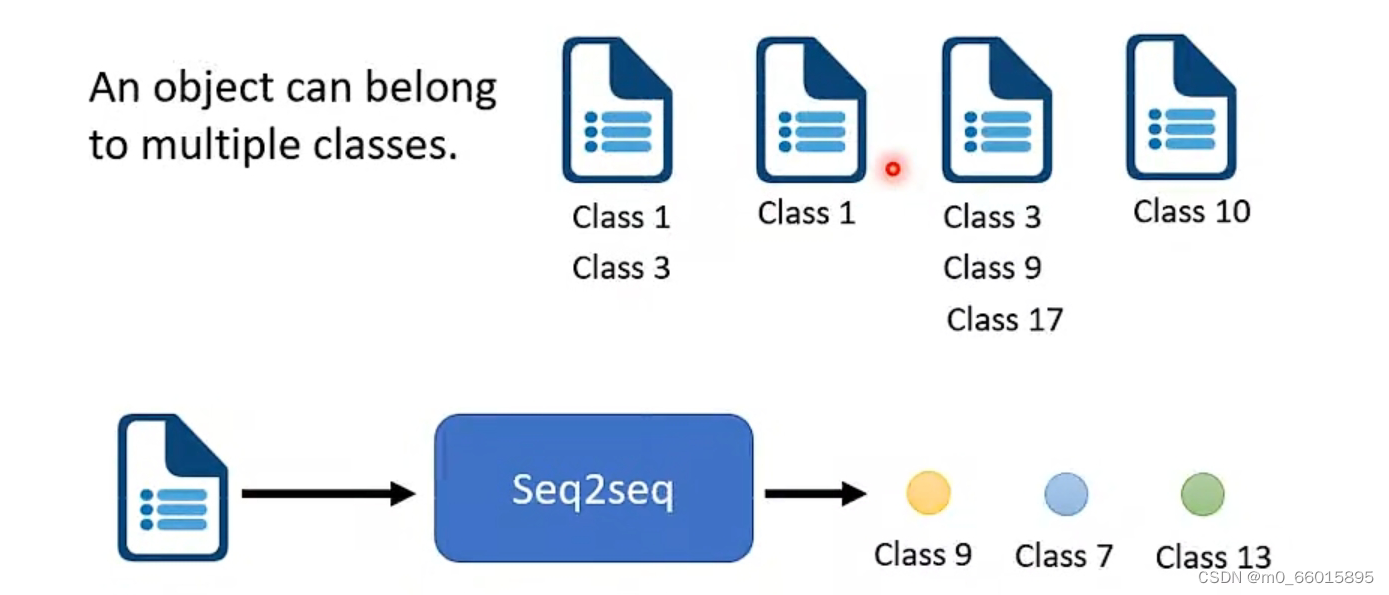
如果用multi-class的方法解决multi-label classification是不可行的,因為每一篇文章对应的class的数目,根本不一样,因此可以用seq2seq硬做,输入一篇文章输出就是class,由机器自己决定输出几个class。既然没有办法决定class的数目,那就让机器帮你决定, 他自己决定每篇文章要属于多少个class。
Seq2seq for Object Detection
Object Detection就是给机器一张图片,让它把图片里的物件框出来, 例如框出图中的所有斑马,但这种问题可以用seq2seq model硬做,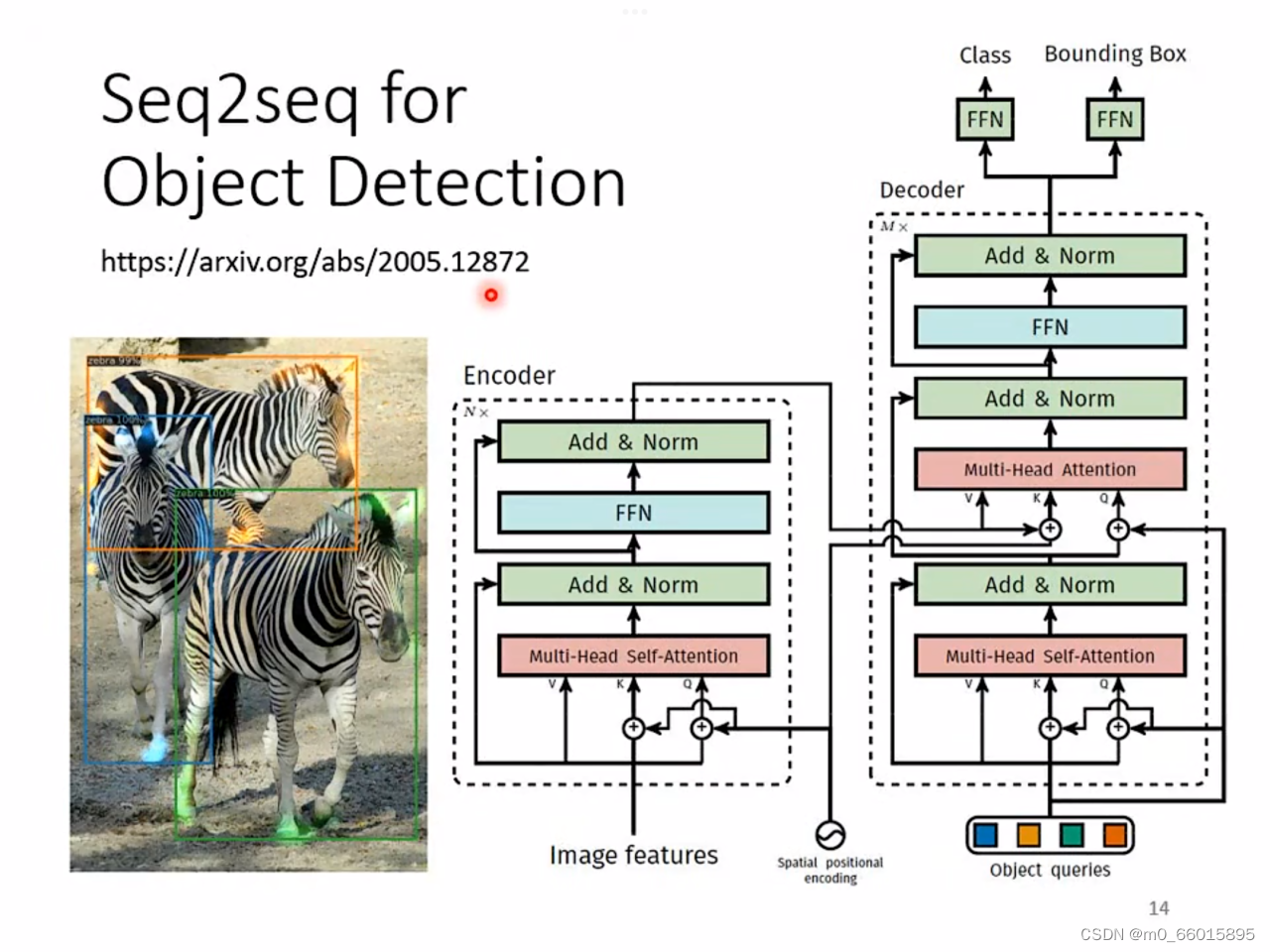
通过这么多例子就是为了说明seq2seq model 它是一个很powerful的model,它是一个很有用的model。
seq2seq model内部分成两大块,一块是Encoder,另外一块是Decoder,当向模型输入一个sequence,则由Encoder负责处理这个sequence,再把处理好的结果丢给Decoder,由Decoder决定,它要输出什么样的sequence。
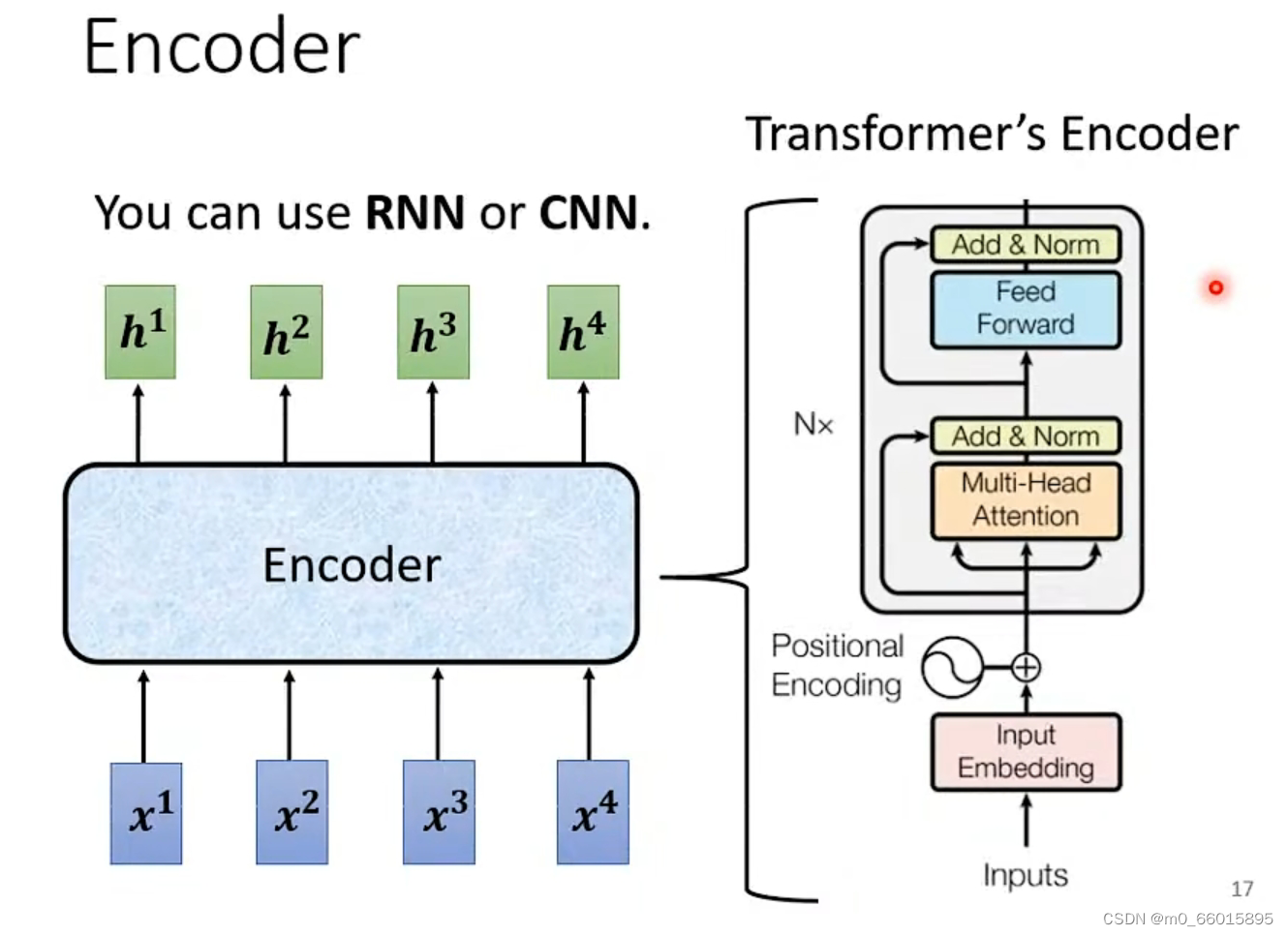
Encoder
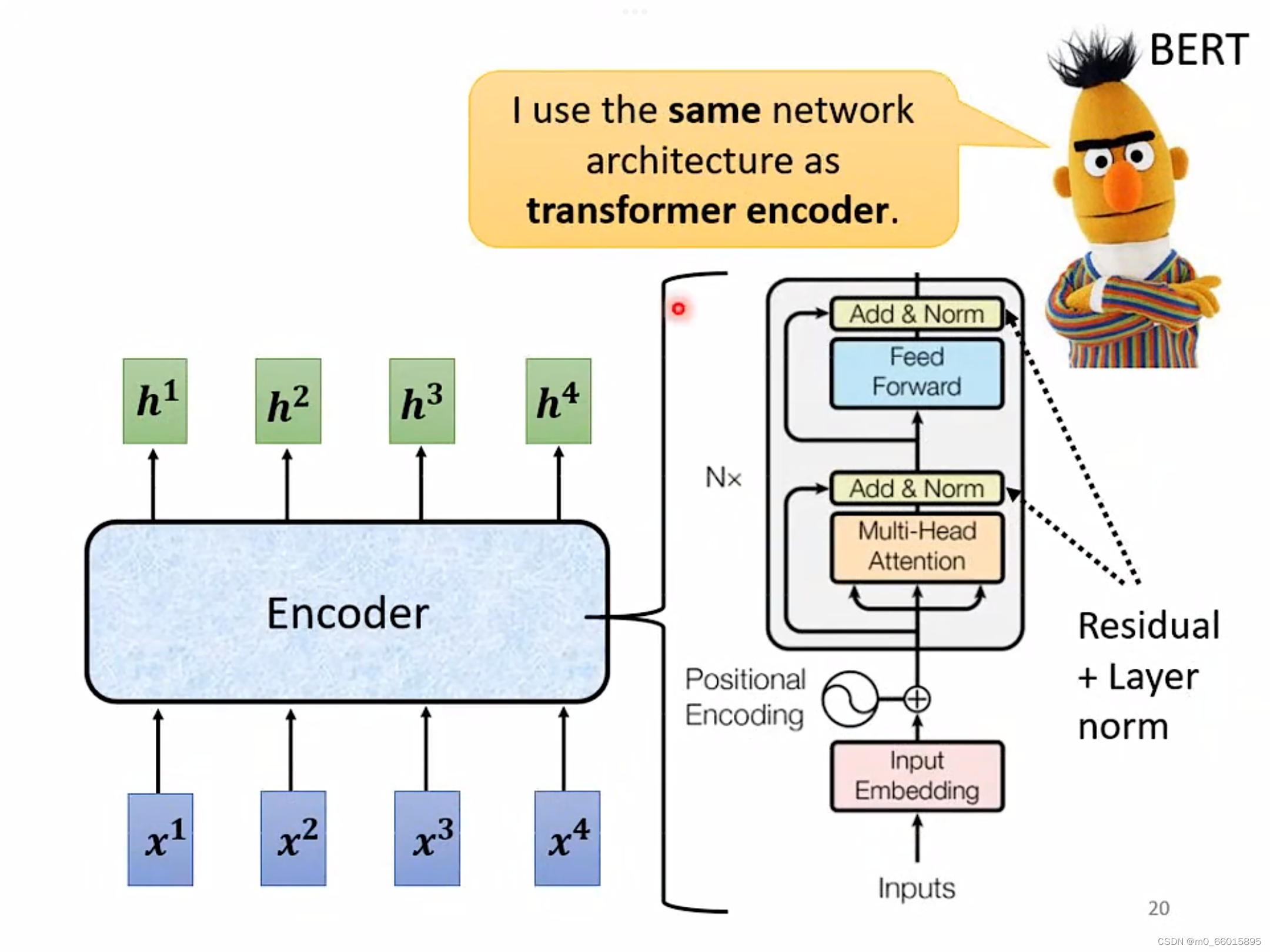
Encoder要做的事情就是,输入一排向量,输出另外一排向量。输入一排向量、输出一排向量这件事情,很多模型都可以做到,例如self-attention,RNN CNN,input一排向量,output另外一个同样长度的向量。在transformer里面的Encoder,用的就是self-attention。
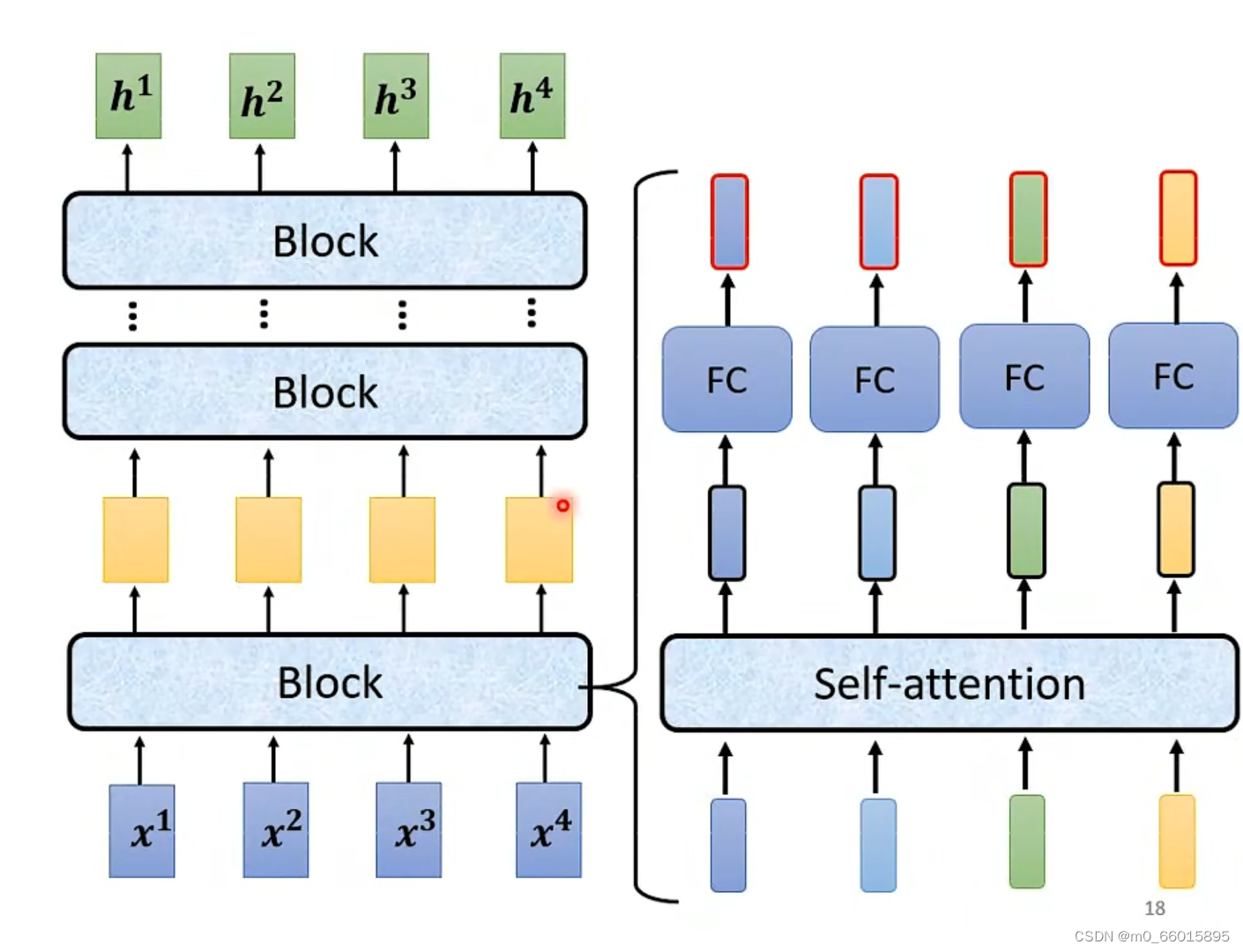
每一个block ,其实并不是neural network的一层。每一个block里面包含了好几个layer,每个block里面做的事情就是:
- 将输入的一排vector sequence先做一个self-attention,考虑整个sequence的资讯,Output另外一排vector。
- 接下来这一排vector,会再丢到fully connected的feed forward network裡面,再output另外一排vector,这一排vector就是block的输出。
事实上在原来的transformer里面的Encode做的事情是更复杂的,在上面Encode里面做self-attention的时候, 输入一排vector,就输出一排vector,得到的每个vector都是考虑了所有的input以后所得到的结果。而在原来的transformer里面,它加入了一个设计,不只是输出得到这个vector,而是还要把这个vector加上它的input,当作新的output。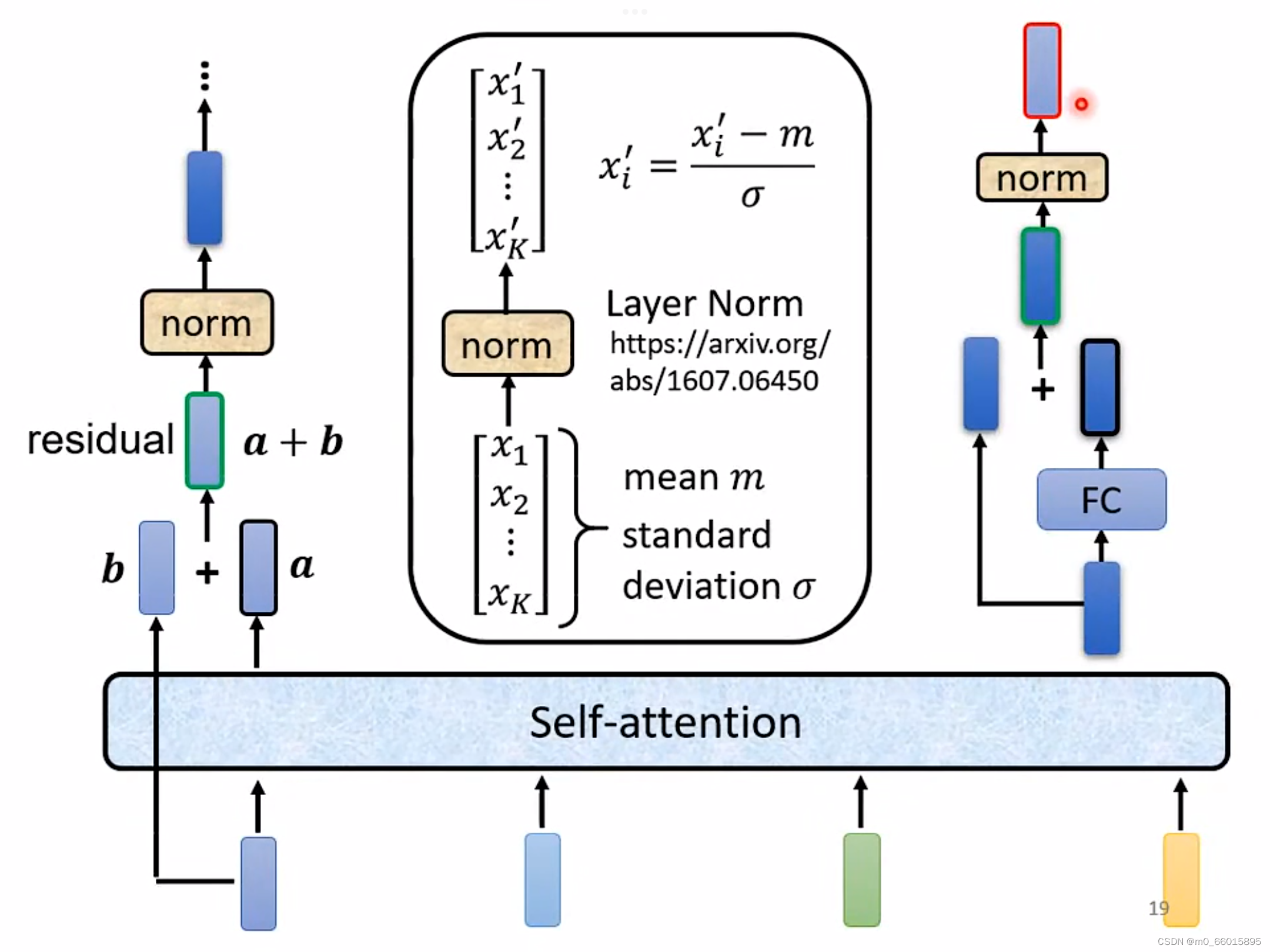
由输入和self-attention的结果相加得到residual的结果以后,再把它做一件事情叫做normalization,用的叫做layer normalization,它做的事情就是输入一个向量 输出另外一个向量,不需要考虑batch,它会把输入的这个向量,计算它的mean跟standard deviation,就可以做一个normalize,把input的这个vector里面每一个dimension减掉mean,再除以standard deviation以后得到layer normalization的输出x',输出x'才是FC network的输入。
而FC network这里同样也有一个residual的架构, 经过相加得到residual的结果之后,再做一次layer normalization得到的结果,才是Encoder里面一个block的输出。
- 首先做一个self-attention的时候,在input的地方加上positional encoding(位置编码),如果只用self-attention,没有末知的资讯。
- positional的information是通过Multi-Head Attention,这个就是self- attention的block是Multi-Head的self-attention。
- Add&norm,就是residual加layer normalization
- Add&norm的结果过feed forward network,fc的feed forward network以后再做一次Add&norm,再做一次residual加layer norm,才是一个block的输出。
Decoder
Autoregressive Decoder(AT)
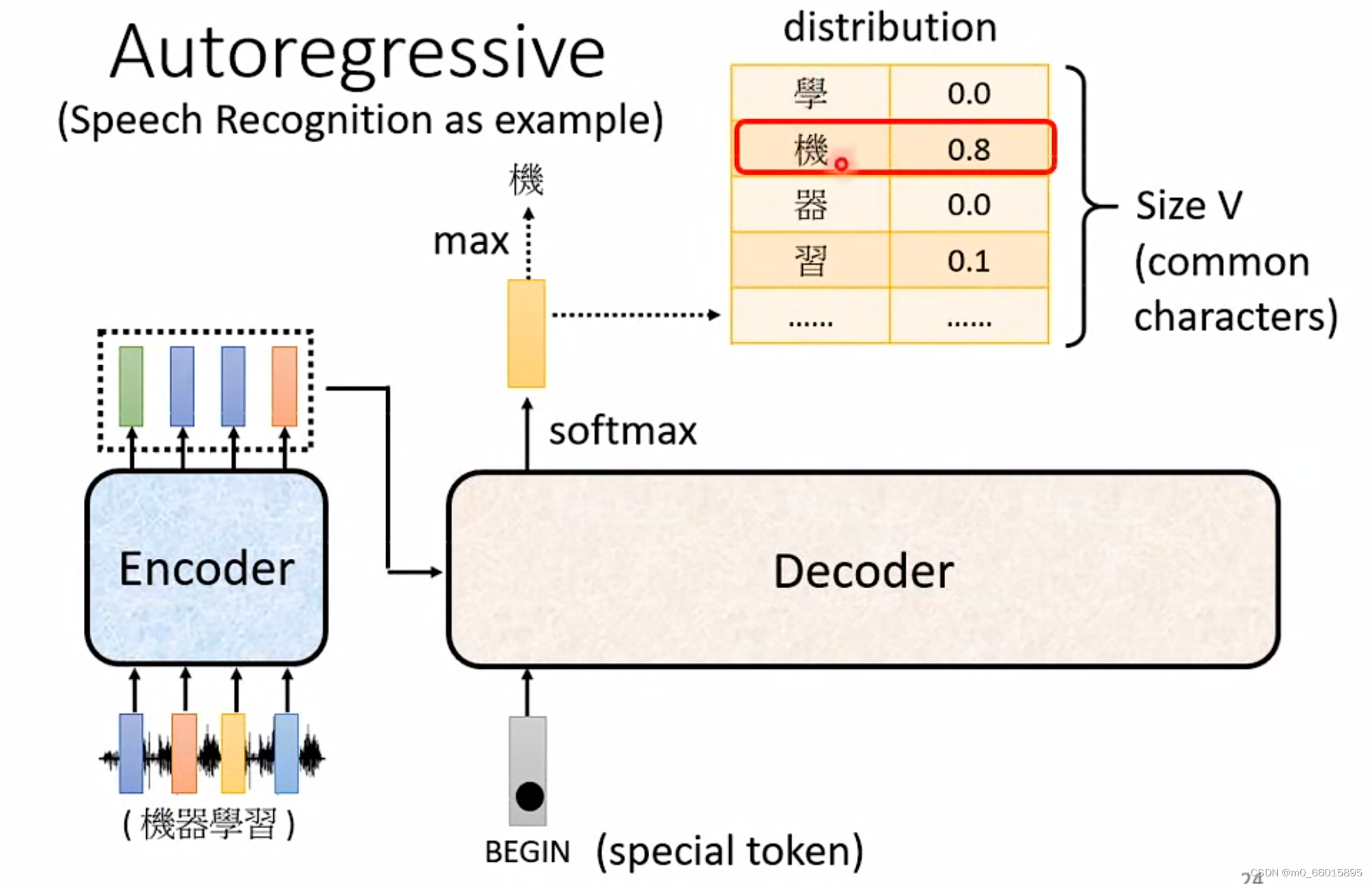
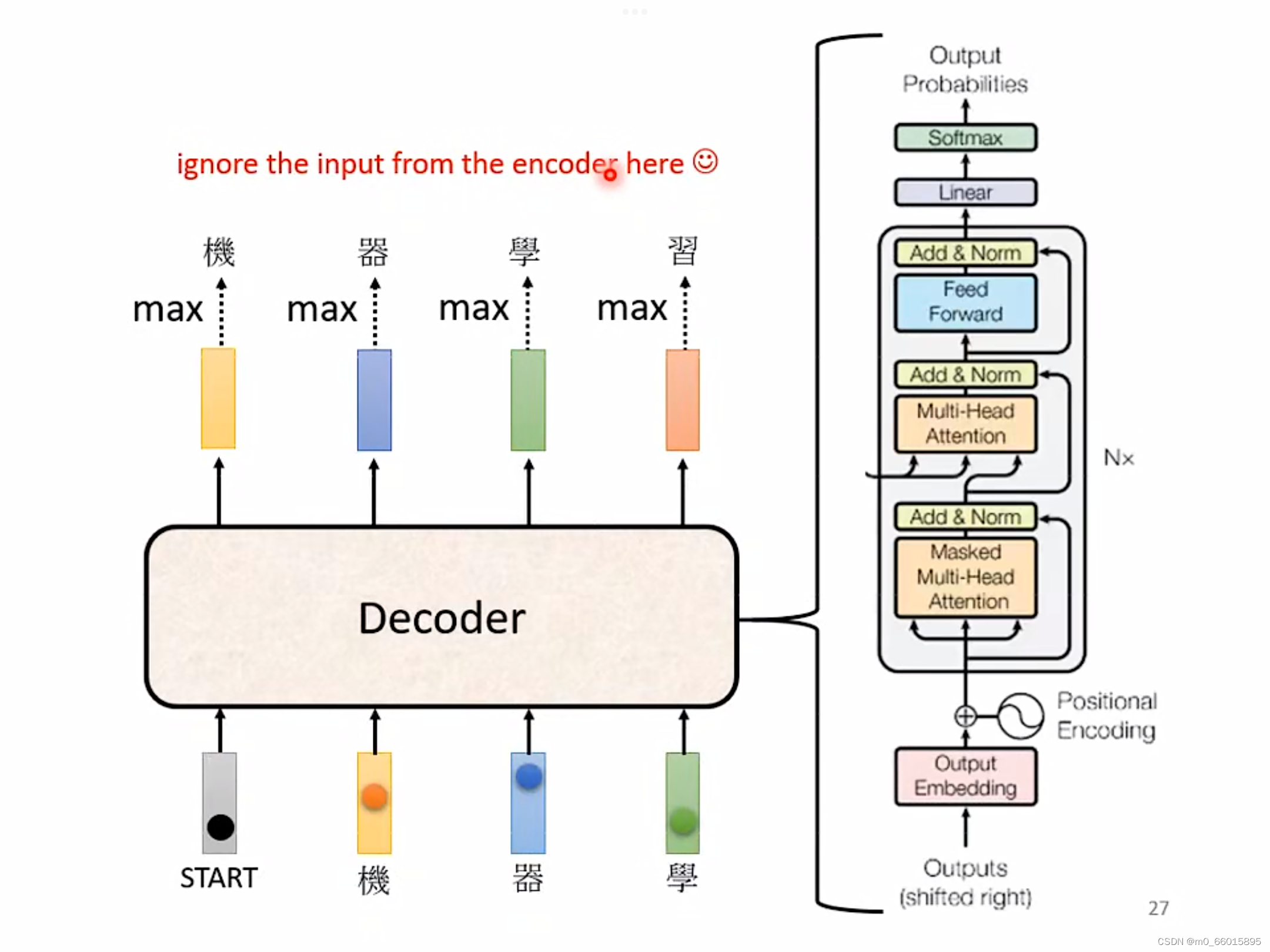
Decoder中比较常见的就是Autoregressive Decoder, Autoregressive 的 Decoder是怎么运作的呢?采用语音辨识作为例子进行说明,语音辨识就是输入一段声音,输出一串文字,把一段声音输入给 Encoder,输出一排Vector Sequence,接下来就轮到 Decoder 运作了,Decoder 要做的事情就是产生输出,即语音辨识的结果。
Decoder是怎么可以根据语音得到一段文字?
首先要给Decoder一个特殊的符号,Begin Of Sentence,缩写是 BOS,标志着“开始”,这个特殊字符是一个 Special 的 Token,相当于就在你本来 Decoder可能产生的文字里面多加一个特殊的字。在机器学习里面,假设你要处理 NLP 的问题每一个 Token,你都可以把它用一个 One-Hot 的 Vector 来表示,One-Hot Vector 就其中一维是 1,其他都是 0,所以 BEGIN 也是用 One-Hot Vector 来表示
Decoder在读入BEGIN之后会吐出一个Vector,这个 Vector 的长度很长,与模型的Vocabulary的Size 是一样长,如果我们要输出的文字是中文,那么Vocabulary size就是需要用到的常用中文数量,大概三四千个。每一个中文的方块字都会对应到一个数值,在得到这个数值之前都会先经过一个 Softmax,就如同做分类一样,所以输出的这个一个向量的数值其实是一个 Distribution,也就向量里面的值全部加起来总和是1,值最高的一个中文字,它就是最终的输出。在这个例子里面,机的分数最高,所以“机”就是这个 Decoder的第一个输出。
第二步:把“机”当做是Decoder新的 Input,,在第一步的时候Decoder的输入只有 BEGIN这个特别的符号,现在Decoder有两个输入:一个是BEGIN 这个符号,一个是“机”,根据这两个输入,同样输出一个Vocabulary size的向量,给每一个中文的字概率值,决定第二个输出什么。
之后重复第二步,Decoder 看到 Encoder这边的输入,看到“机”、“器”、“学”之后决定接下来输出一个向量,从图中可以看出这个向量里面“习”这个中文字的概率值最高,所以输出“习”。
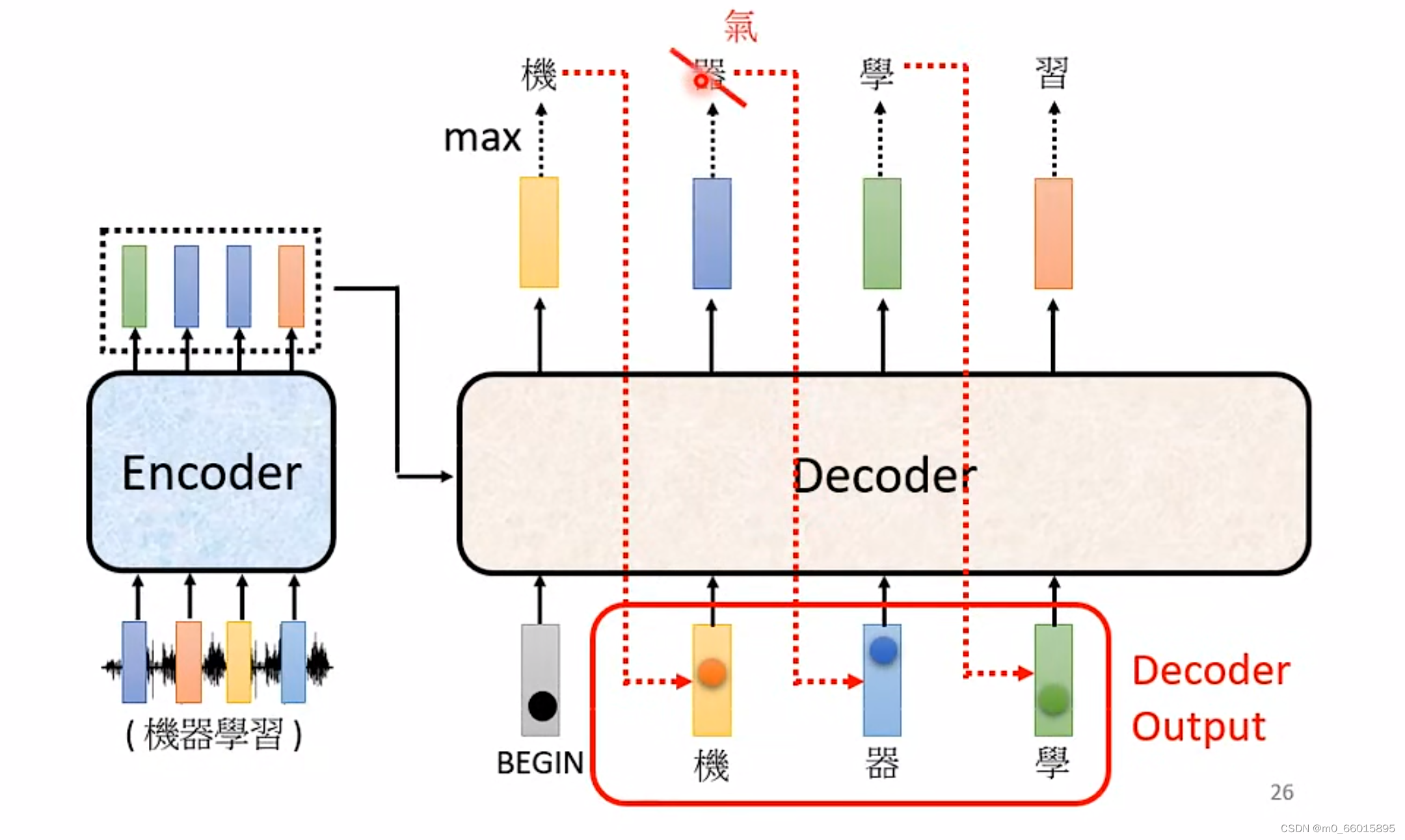 红色的虚线标出来的意思,也就是说 Decoder的输入其实是它在前一个时间点自己的输出,所以当Decoder在产生一个句子的时候,他其实有可能看到错误的东西,他还是要想办法根据错误的辨识结果产生正确的输出,不会一步错步步错造成Error Propagation 的问题。
红色的虚线标出来的意思,也就是说 Decoder的输入其实是它在前一个时间点自己的输出,所以当Decoder在产生一个句子的时候,他其实有可能看到错误的东西,他还是要想办法根据错误的辨识结果产生正确的输出,不会一步错步步错造成Error Propagation 的问题。
Decoder内部的结构如下
在 Transformer里面,Decoder 的结看起来比Encoder还稍微复杂一点,如果我们把 Decoder 中间这一块盖起来,其实 Encoder 跟 Decoder并没有很大的差别。在最后的时候,可能会再做一个 Softmax,使得它的输出变成一个机率。
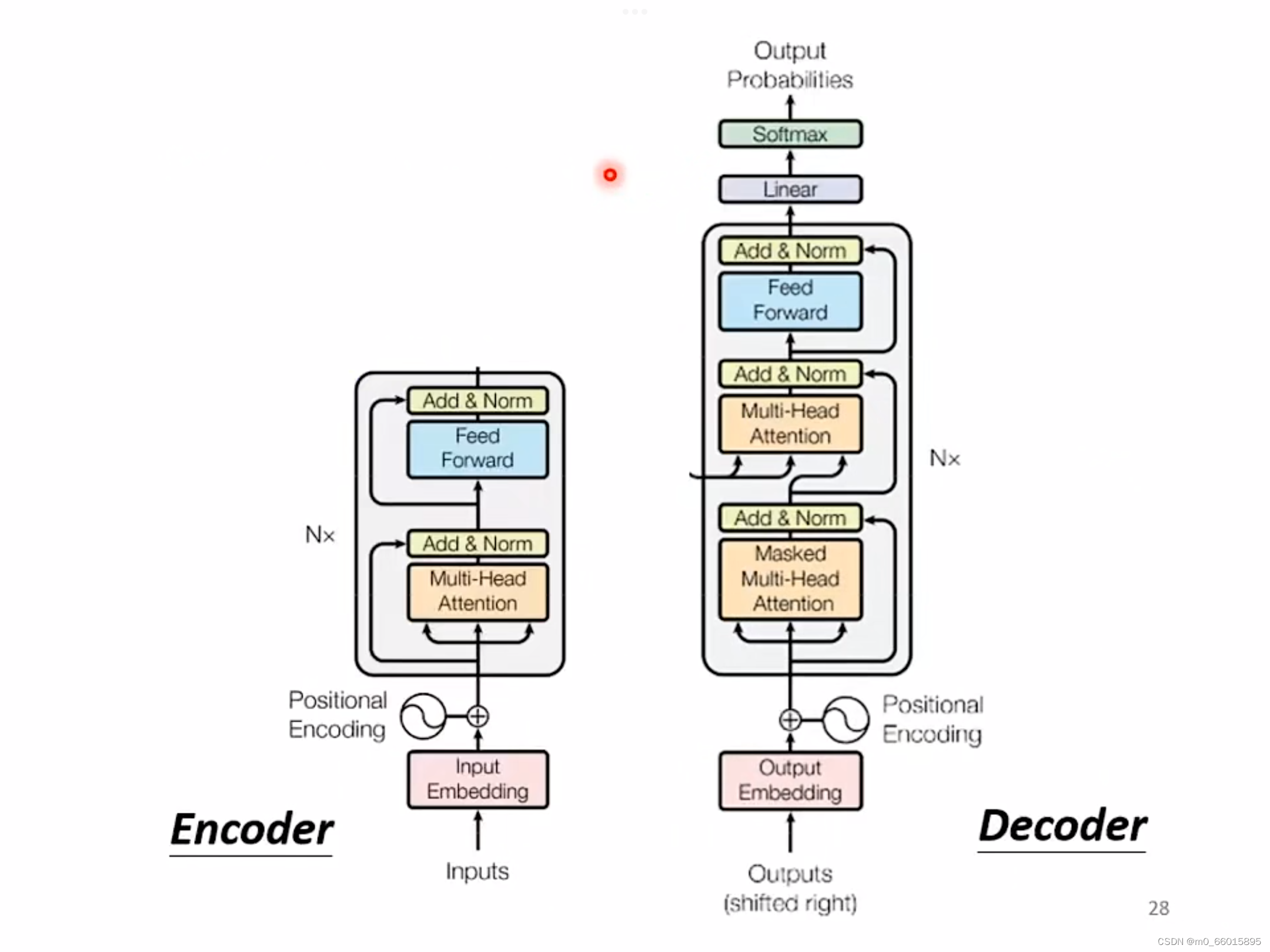 稍微不一样的地方是,在 Decoder里面的Multi-Head Attention 这一个Block上面,用的是Masked self-attention,那这个Masked self-attention与一般的self-attention有什么区别呢?
稍微不一样的地方是,在 Decoder里面的Multi-Head Attention 这一个Block上面,用的是Masked self-attention,那这个Masked self-attention与一般的self-attention有什么区别呢?
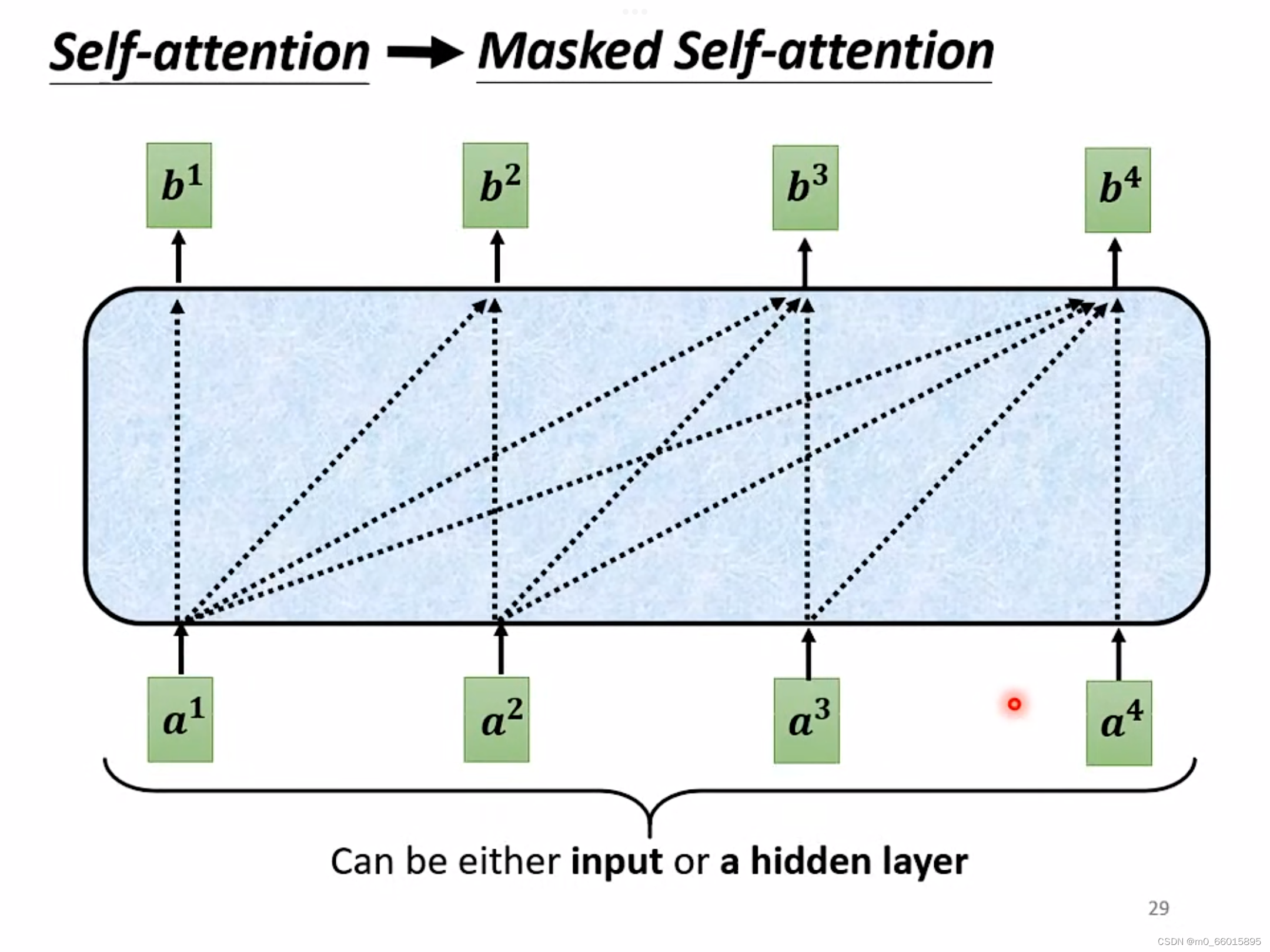
原来的 Self-Attention,Input 一排 Vector,Output 另外一排 Vector,输出的这一排 Vector都是考虑全部Input 得到的结果,即考虑了所有的资讯得到这个Vector。而Masked Attention与self-attention不同点是它某个时间点的结果只考虑前面的输入,而不考虑后面的输入。
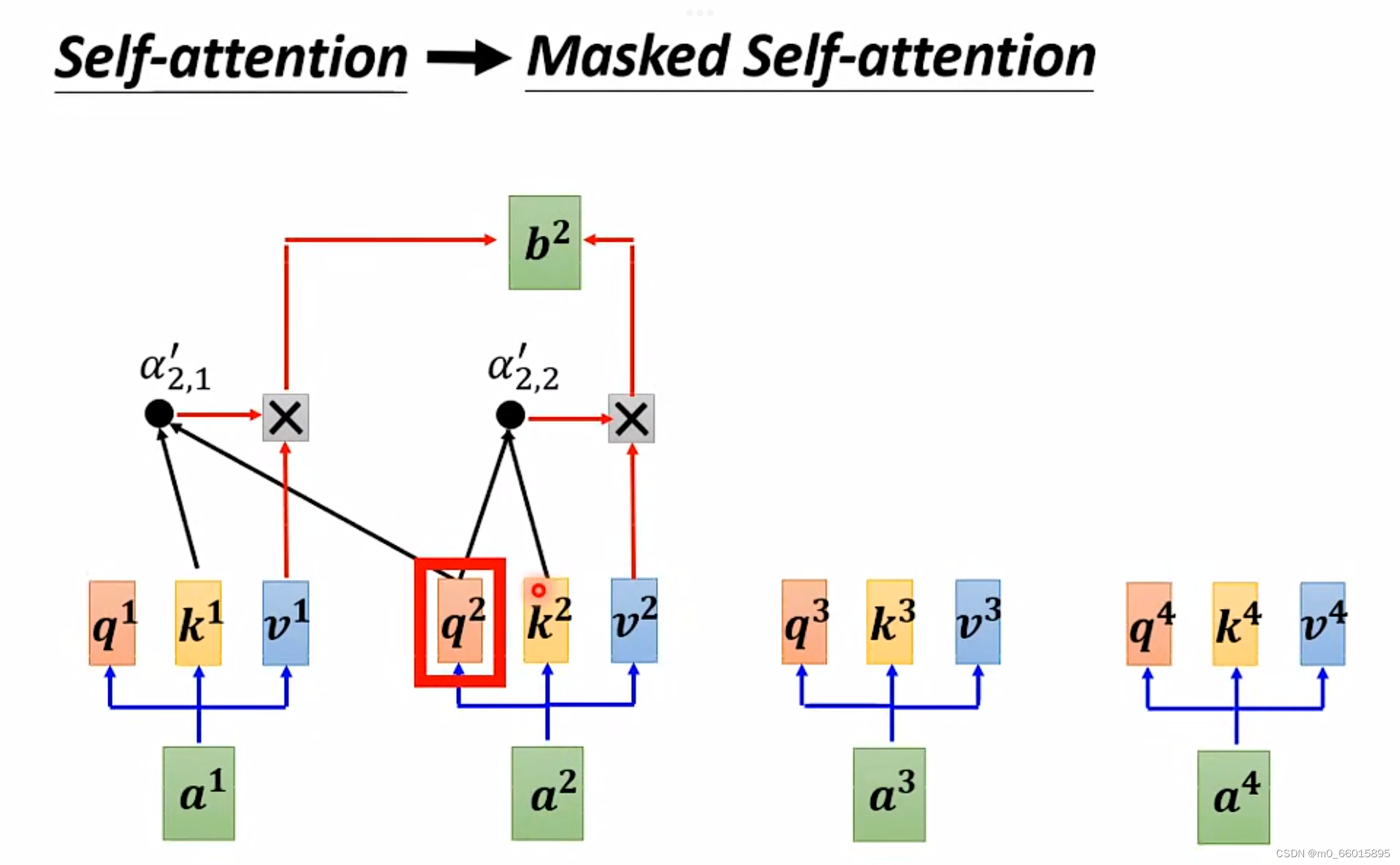
如上图举例来说,产生的时候,我们只拿第二个位置的Query,去跟第一个位置的 Key和第二个位置的 Key去计算Attention,而第三个位置跟第四个位置的Key就不管了,不去计算 Attention。
Q:为什么Decoder要用Masked Attention呢?
A:原来的self-attention是一次性输入全部的向量a,同时产生所有的输出Decoder运作过程是先有 a1, 再有a2 ,再有a3,再有a4,并且输出是一个一个产生的。Decoder 的Tokent输出的东西是一个一个产生的,所以它只能考虑它左边的东西,它没有办法考虑它右边的东西。
了解完Decoder的运作之后,对于Decoder最关键的一点是,Decoder必须自己决定输出的Sequence 的长度
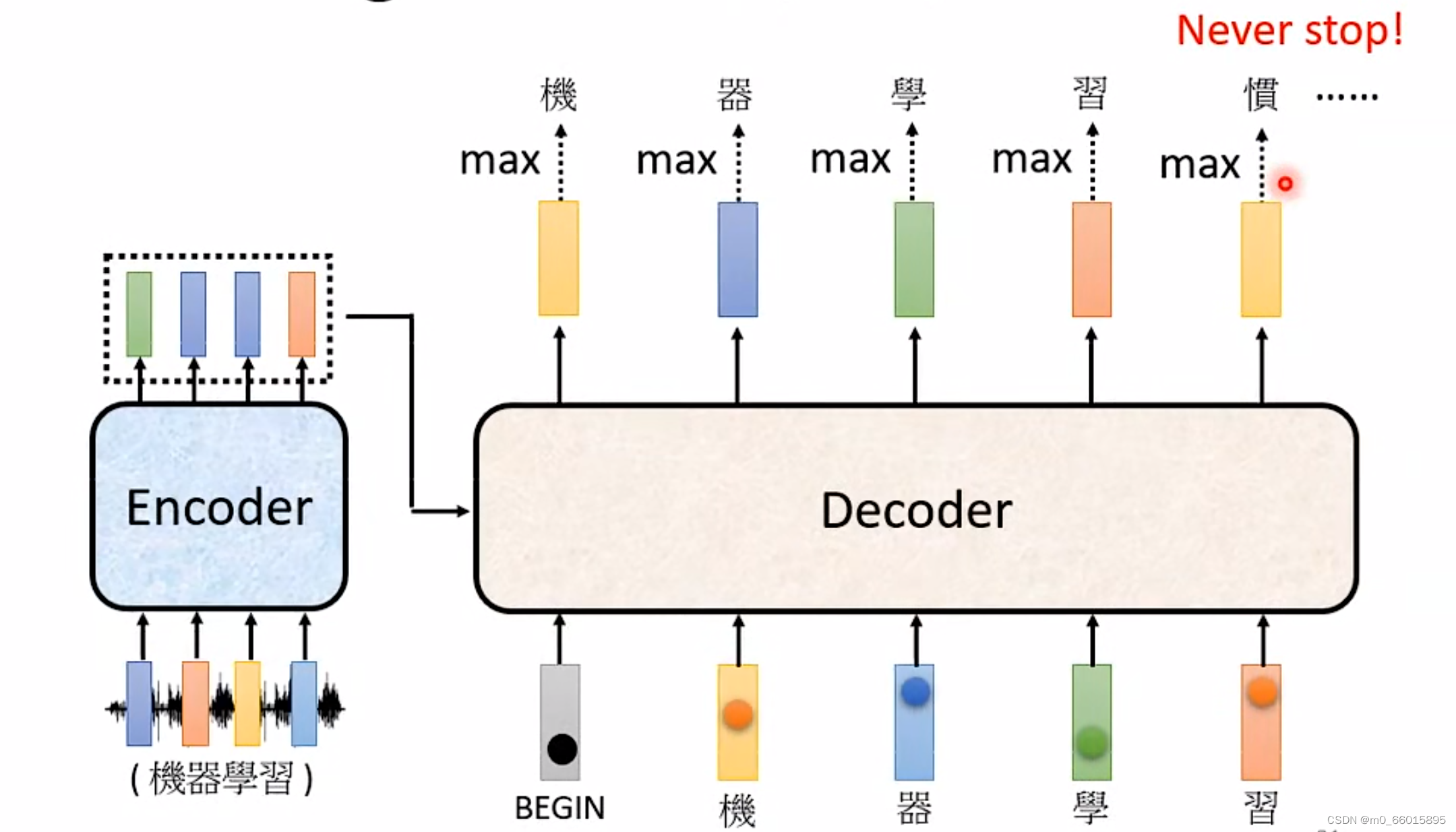
从上图来看的话,在Decoder的运作机制里,他会一直重复一模一样的 Process,就想文字接龙一样,一直输出下去永远不会暂停,因此需要在vocabulary里面设置一个特别的符号,如同BEGIN一样,添加一个”Stop Token”。
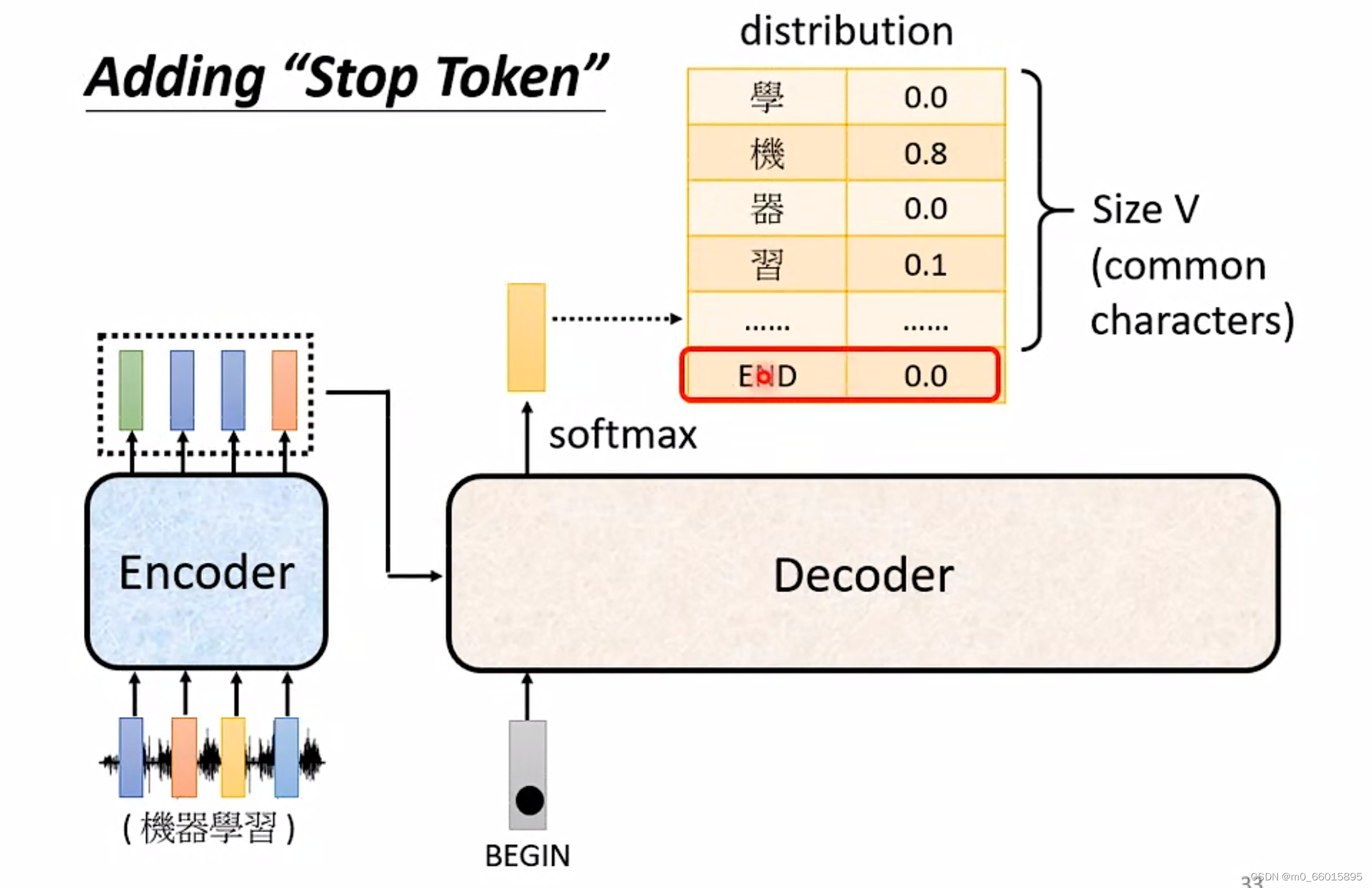 希望在输出“习”以后,Decoder就要能输出”断“,也就是当把"习"当作输入以后, Decoder 看到 Encoder 输出的这个Embedding以及前面输入的 "BEGIN","机" "器" "学" "习"以后,可以判断并输出“断”结束整个Decoder的进程,这就是 Autoregressive Decoder运作的方式。
希望在输出“习”以后,Decoder就要能输出”断“,也就是当把"习"当作输入以后, Decoder 看到 Encoder 输出的这个Embedding以及前面输入的 "BEGIN","机" "器" "学" "习"以后,可以判断并输出“断”结束整个Decoder的进程,这就是 Autoregressive Decoder运作的方式。
Non-Autoregressive (NAT)
前面学习了Autoregressive Decoder,Decoder的另一个模型就是Non-Autoregressive模型,Non-Autoregressive通常缩写成 NAT,Autoregressive也缩写成 AT。
Non-Autoregressive与Autoregressive有什么区别呢?
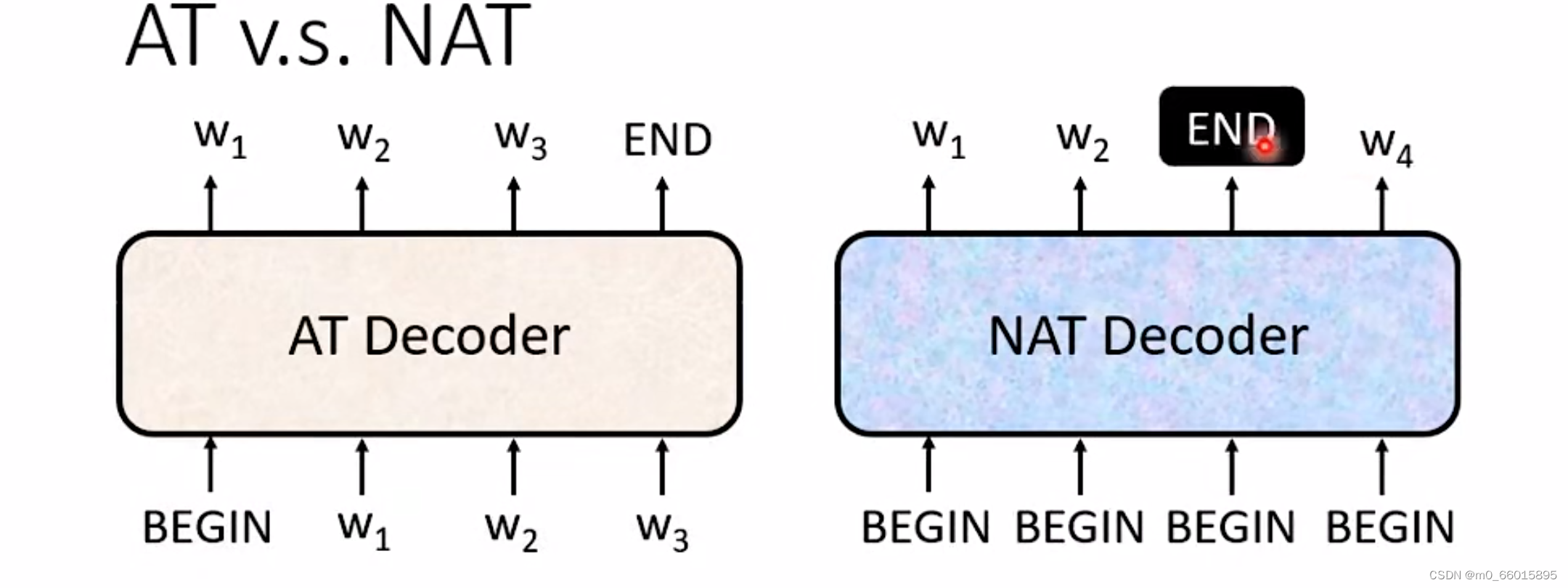
Autoregressive的Model是:先输入 BEGIN,然后得到输出w1,然后再把 w1当做输入,输出 w2,然后再将w2当作输入得到w3,一直到输出 END 为止。
Not Autoregressive的Model是:一次性同时输入BEGIN,然后同时运作,同时产生得到所有的输出。
例如丢给它 4 个 BEGIN 的 Token,它就产生 4 个中文的字然后结束,所以它只要一个步骤就可以完成句子的生成。那机器怎么知道要输入多少个BEGIN?
①另外学习一个 Classifier,可以将Encoder的Input输入到这个Classifier可以得到一个数值,这个数值就代表 Decoder 应该要输出的长度。②给它一堆很长(假设不超过300)BEGIN 的 Token,因此可以得到输出 300 个字,可以看在这三个百个输出里面,在第几个输出的结果是END,那么END后面的输出就当作是没有的,最终的输出长度就是就是END前面的输出个数。
NAT的好处
一、可以并行处理,可以一次性得到输出,一个步骤得到一个句子。相比较AT的Decoder而言,会跑的很快,
二、能够控制它输出的长度,从上面可知可以通过一个 Classifier决定 NAT 的 Decoder应该输出的长度,例如做语音合成的时候如果想要说话的速度快一点,就可以通过把Classifier的Output除以二,这样讲话速度就可以快两倍。
Encoder-Decoder
前面分别学习了Encoder和Decoder,那么这两者之间是怎么通信的呢?连接的这块叫做 Cross Attention,它就是连接 Encoder 跟 Decoder 之间的桥梁,其中Cross Attention一共有三个输入,有两个输入来自 Encoder,一个来自于Encoder,因此从左边这两个箭头,Decoder可以读到 Encoder 的输出 。
里面的具体计算方法如下图,这个步骤中的q来自于Decoder,k跟v来自于Encoder,这个步骤就叫做 Cross Attention。所以Decoder就是凭借一个q,可以从Encoder读取到输入的资讯,并把从Encoder读取的信息当做接下来的 Decoder 里面的FC的输入。
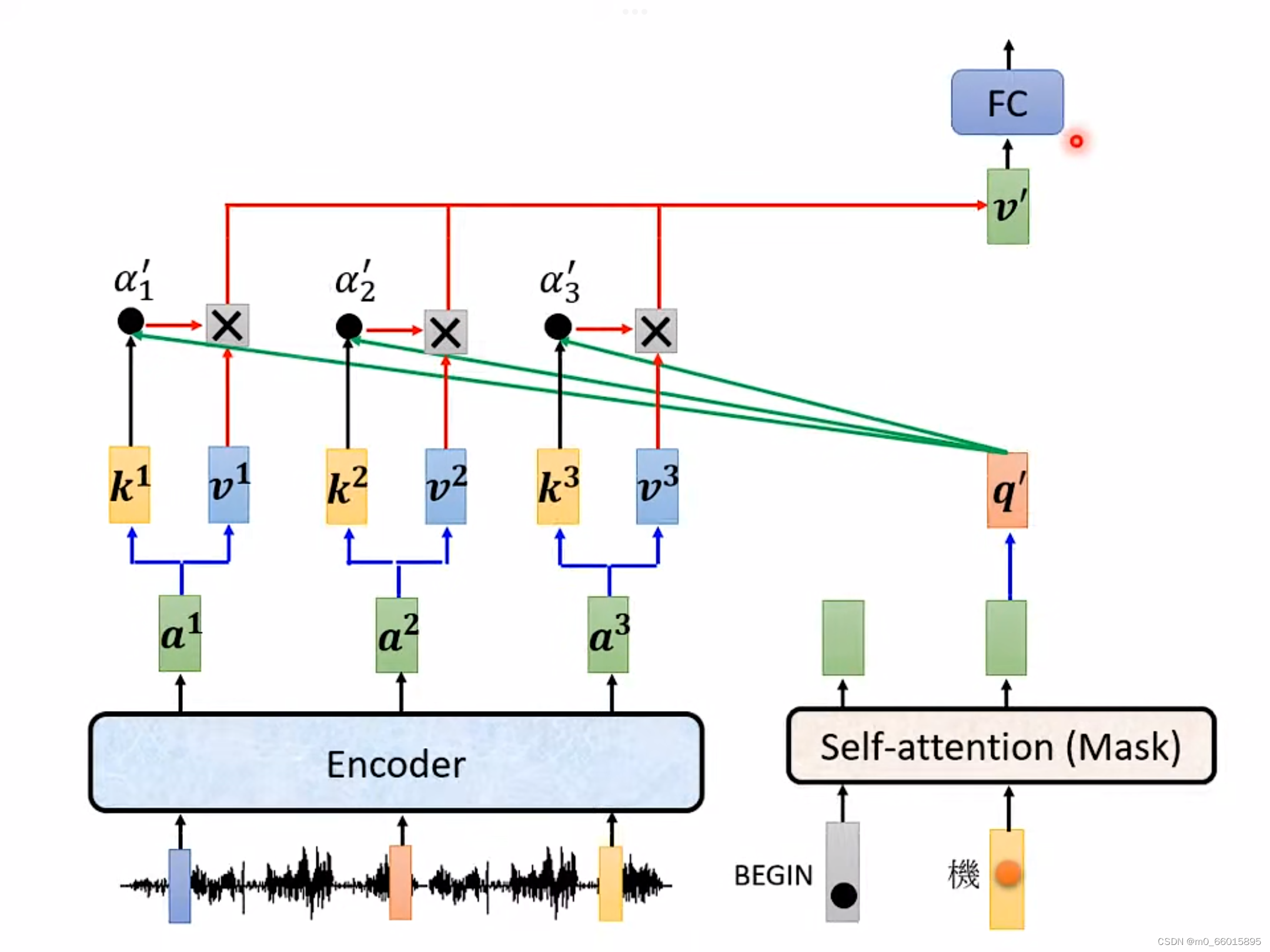
- 首先Encoder中接受了输入之后产生了对应的输出向量
、
、
,而Decoder中最开始的自注意力机制(带Mask)中也接受了BEGIN这个输入,产生对应的向量,并将该向量乘以一个矩阵得到向量
。
- Encoder中的输出向量分别乘以矩阵K得到各个向量
,然后再将向量
。
- 将Encoder中的输出向量分别乘以矩阵V得到各个向量
,然后再其与对应的
相乘,并进行相加得到向量
。
- 得到的向量
另外一个值得注意的问题是Encoder有很多层,Decoder也有很多层,而在原始的论文中Decoder中的每一层的Cross attention都是用Encoder最后一层的输出,但是也存在众多对此的研究,尝试各种方式,因此方法并不是唯一的。
手推Transformer例子——假象机翻任务
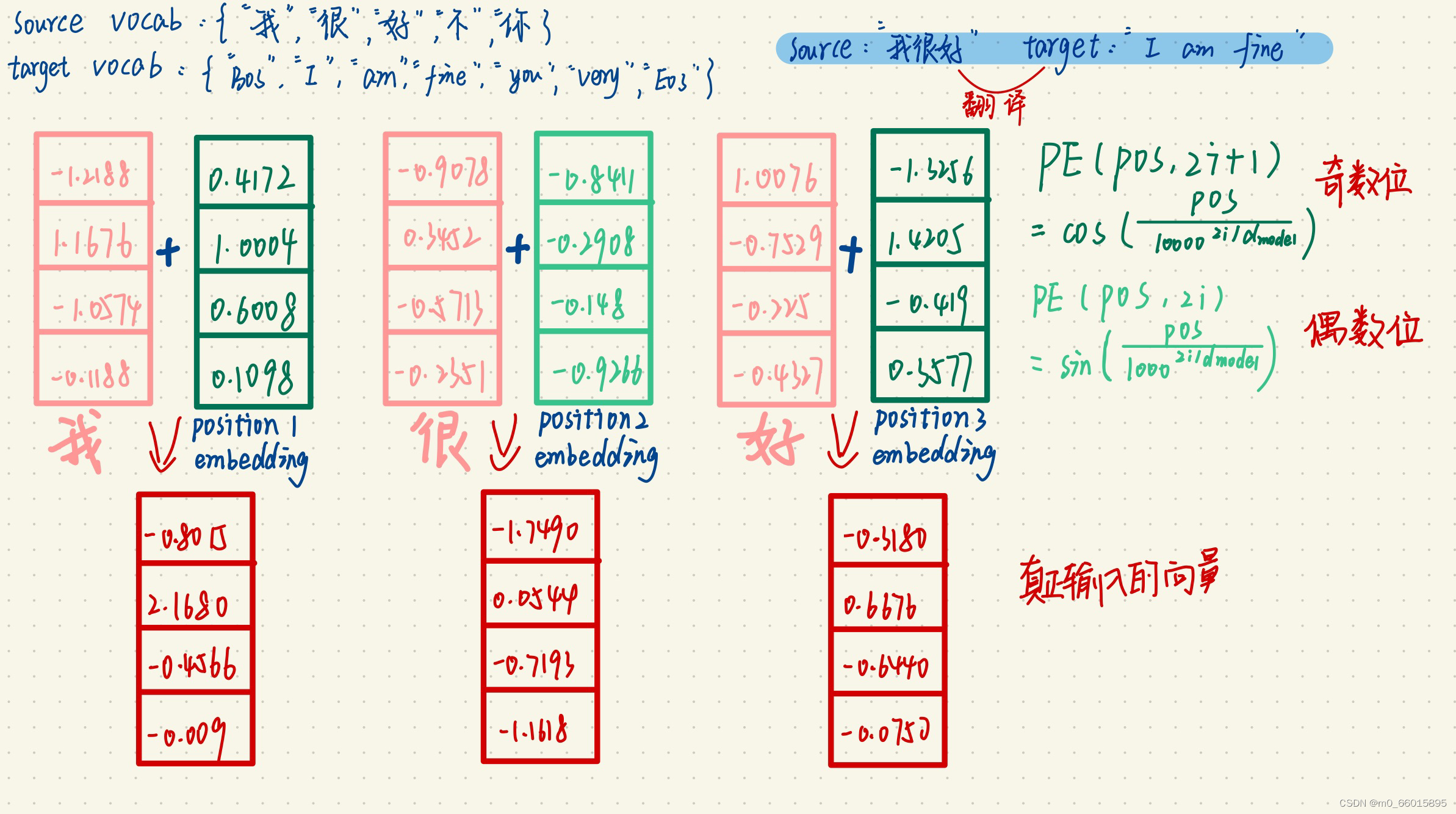
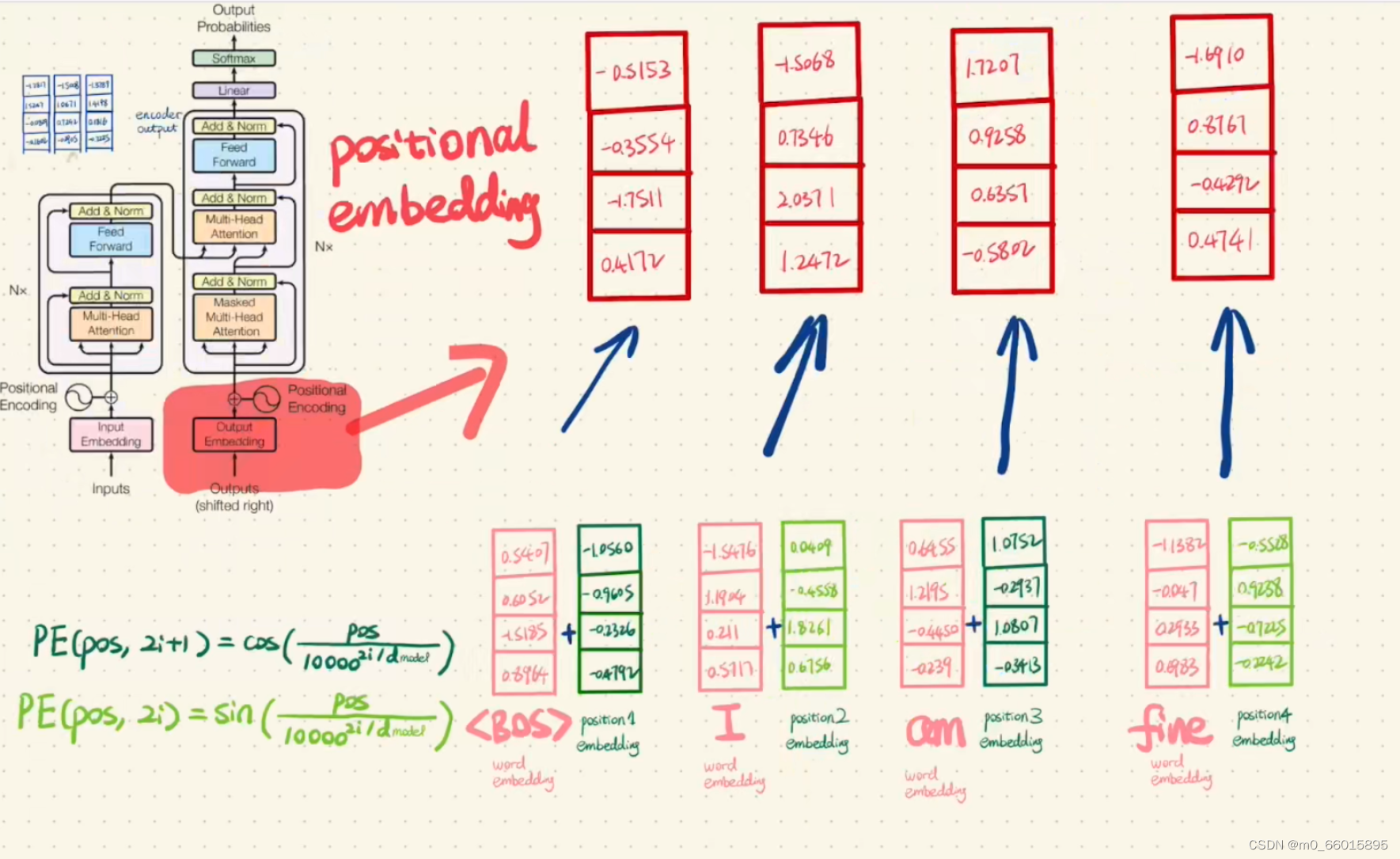
第一步:将sorce“我很好”的每个字词表示向量作为Encoder的输入,并加上positional embedding最为Encoder的最终输入。
Transformer中没有考虑顺序信息,可以给每个词向量加上一个有顺序特征的向量,也就是position embedding,其中sin和cos函数能够很好的表达这种特征。
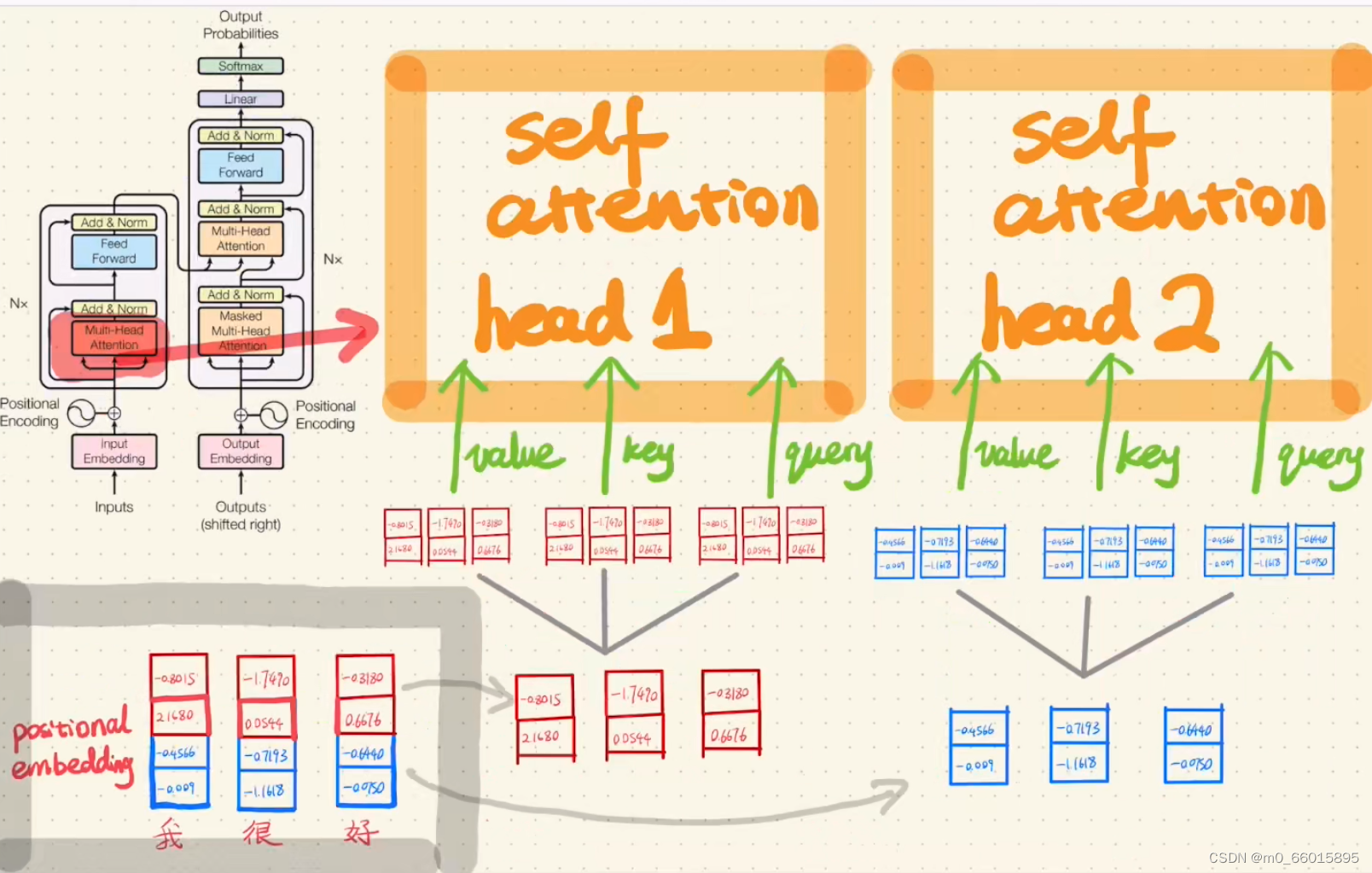
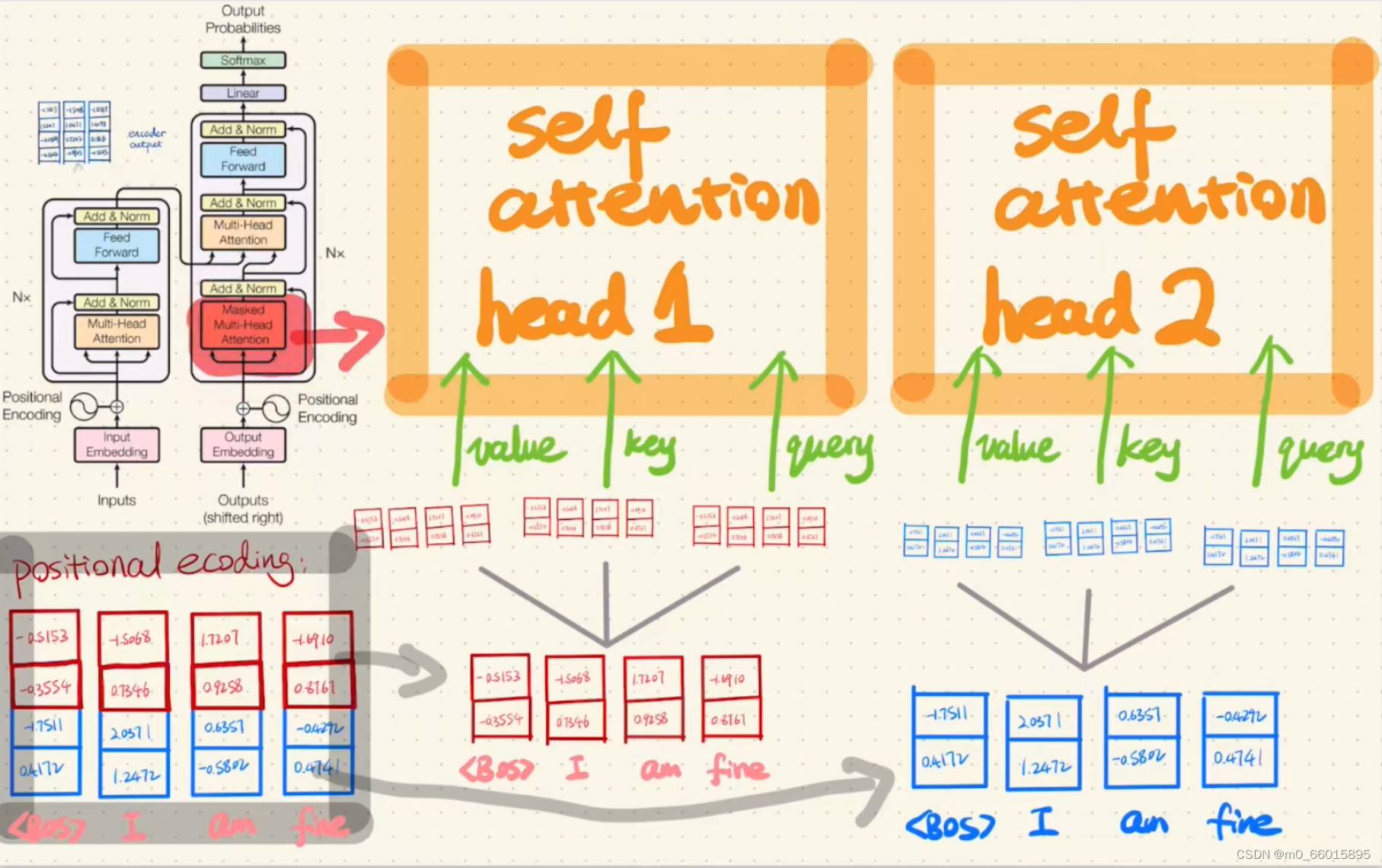
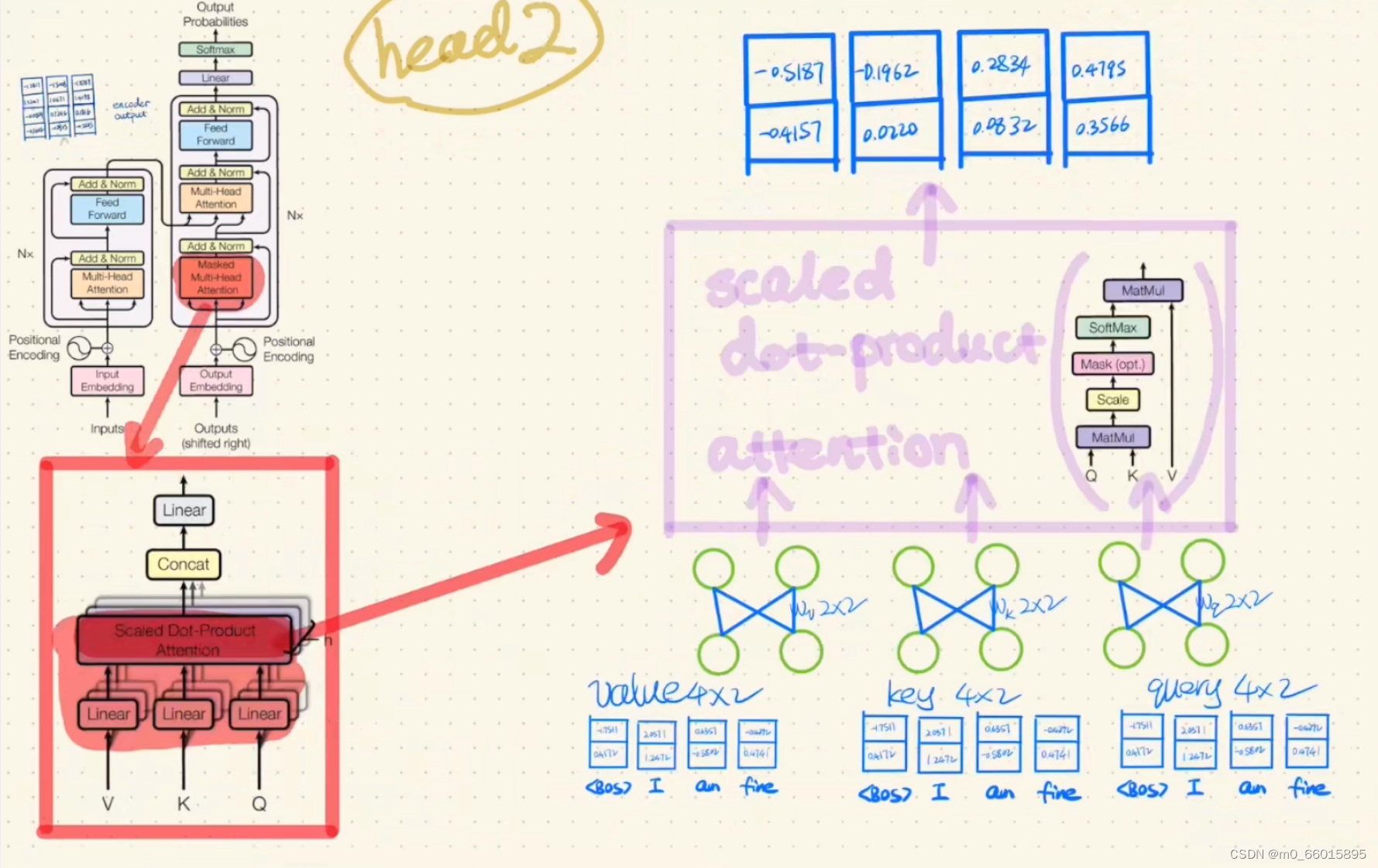
第二步:Encoder的Multi-Head Attention
所谓多头注意力机制,也就是多次进行自注意力机制编码。将词向量分为两份,每份分别复制三份,分别作为value、key、query输入两个head。有两种输入self-attention head的 方式,一种是输入前分开词向量,另一种是输入head以后再分开的。在实际训练时两者的结果相差不大,但第一种方式的参数更少,训练速度更快。
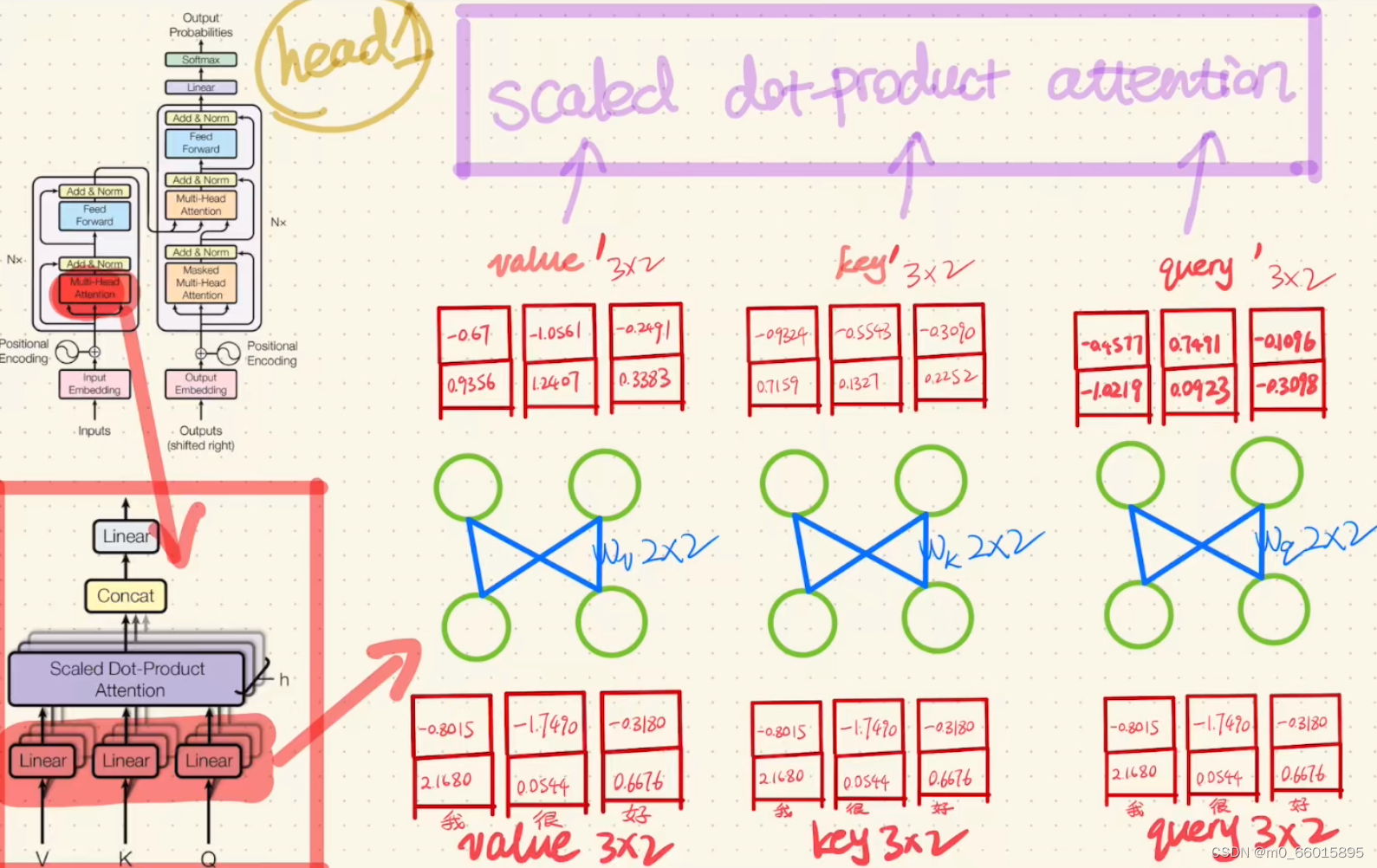
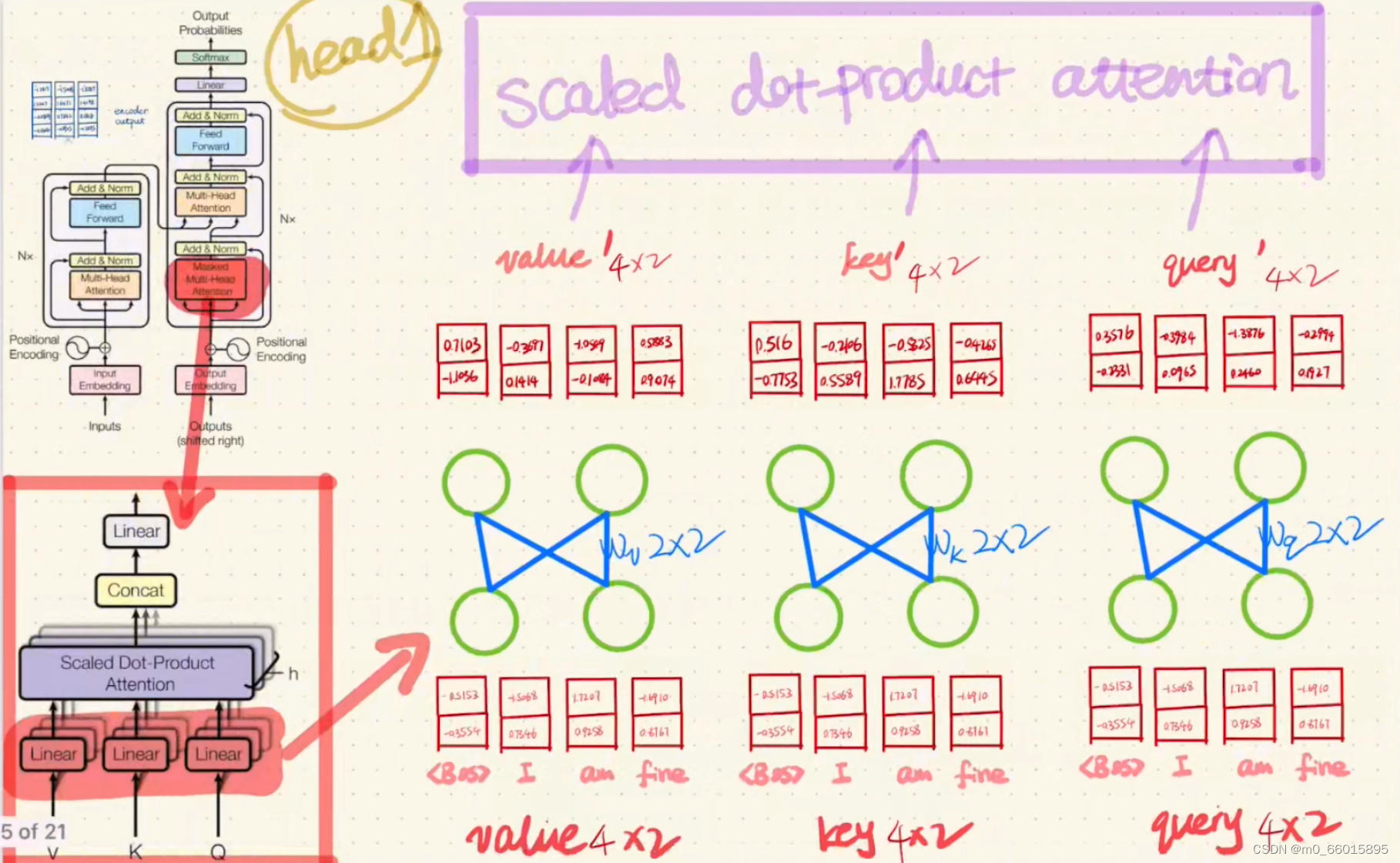
第三步:Encoder的Multi-Head Attention里面的计算
分别将输入head的value、key、query通过一个Linear,然后将Linear得到的结果value'、key'、query'经过一个Scaled dot-product Attention。
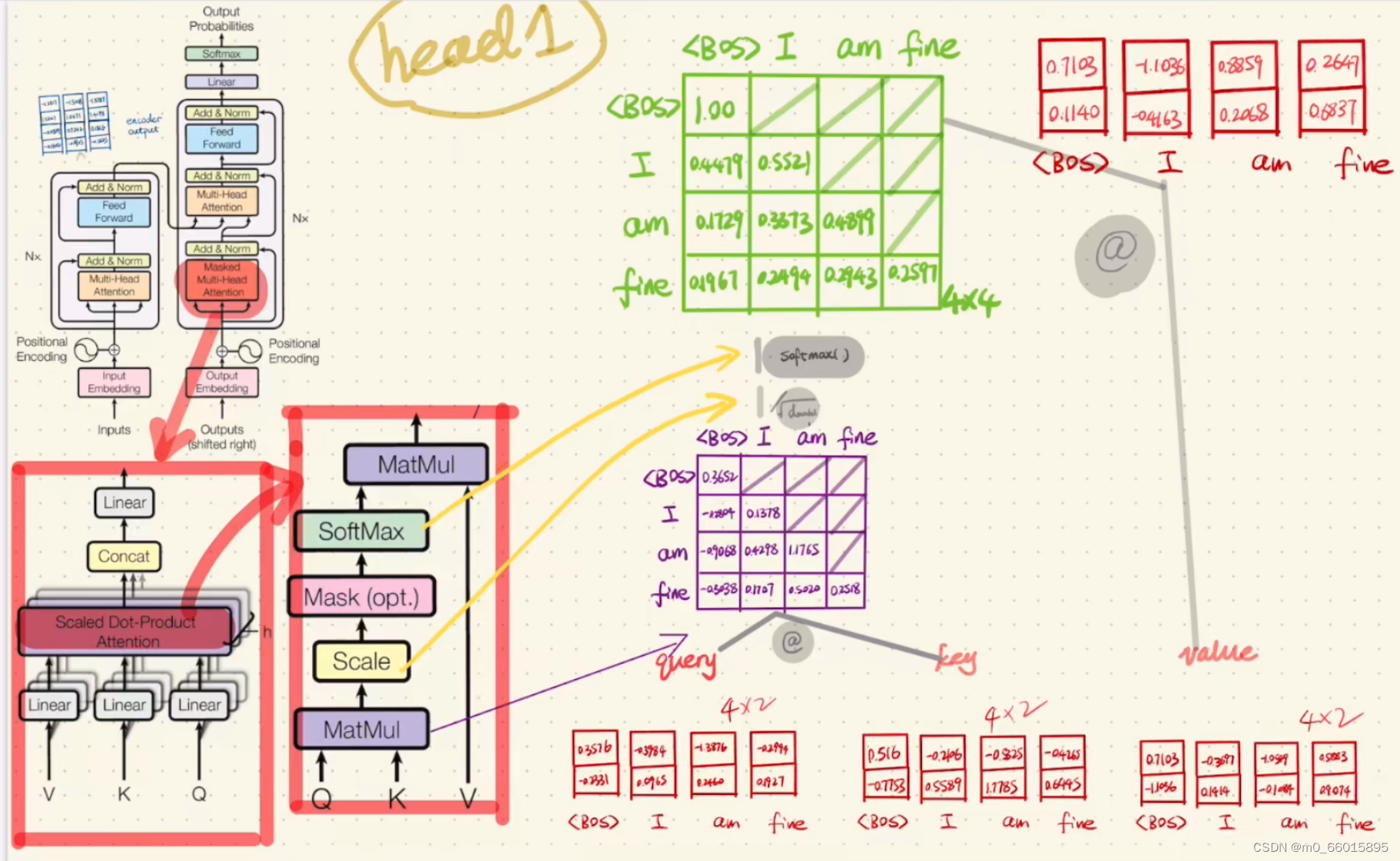
第四步:Scaled dot-product Attention里面的计算
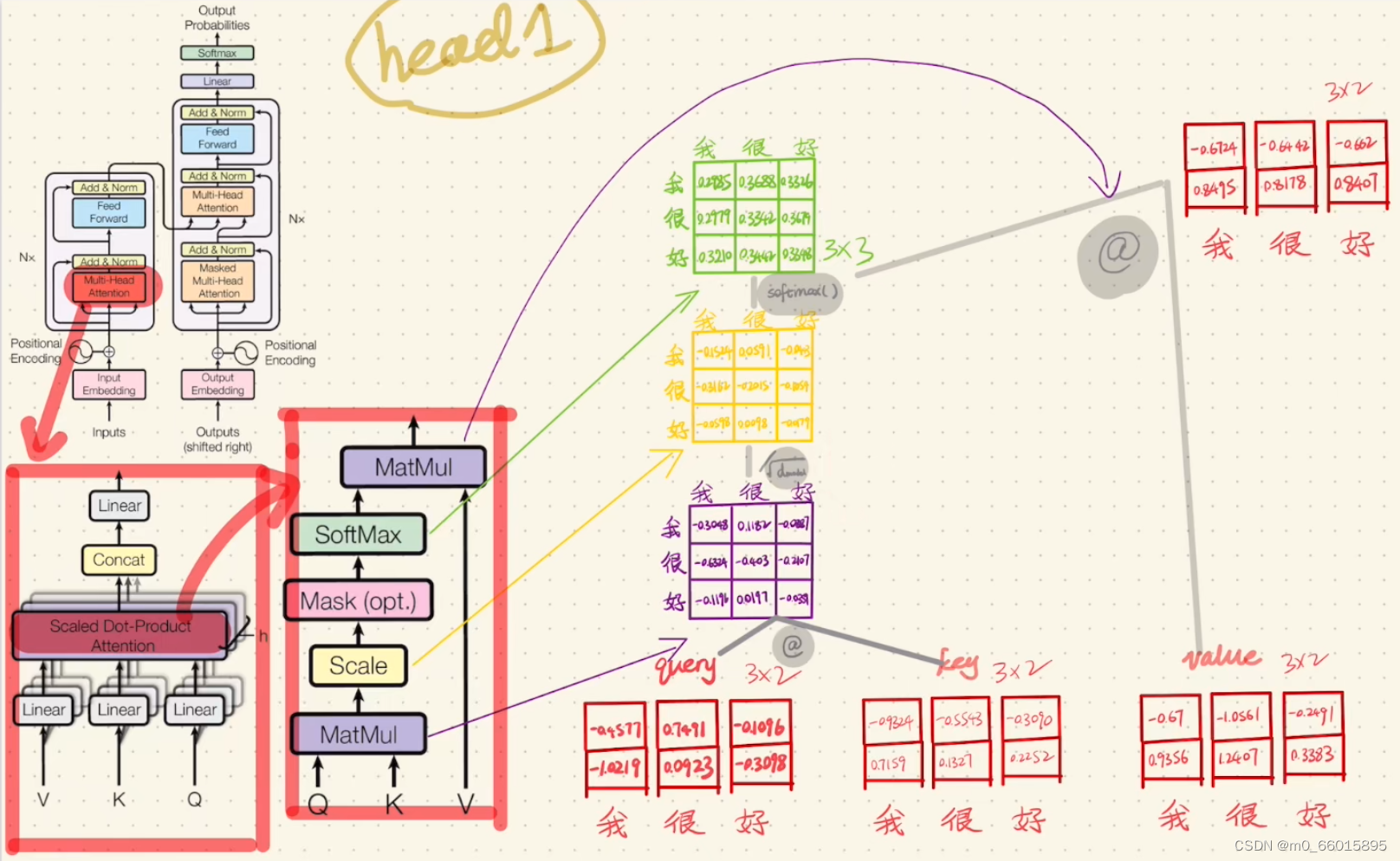
然后对head2分别做同样的操作
不同的head是为了从不同维度提取特征
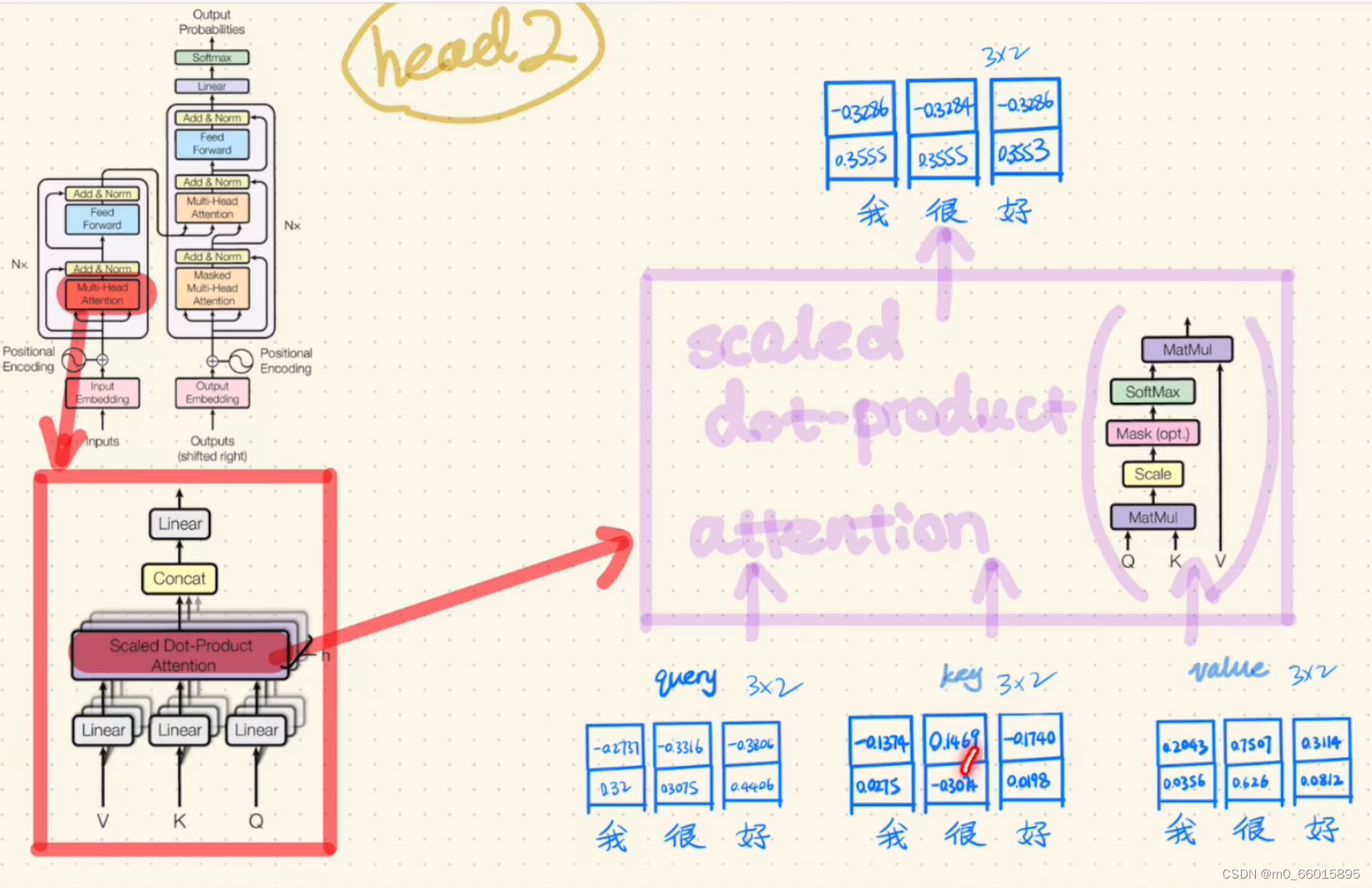
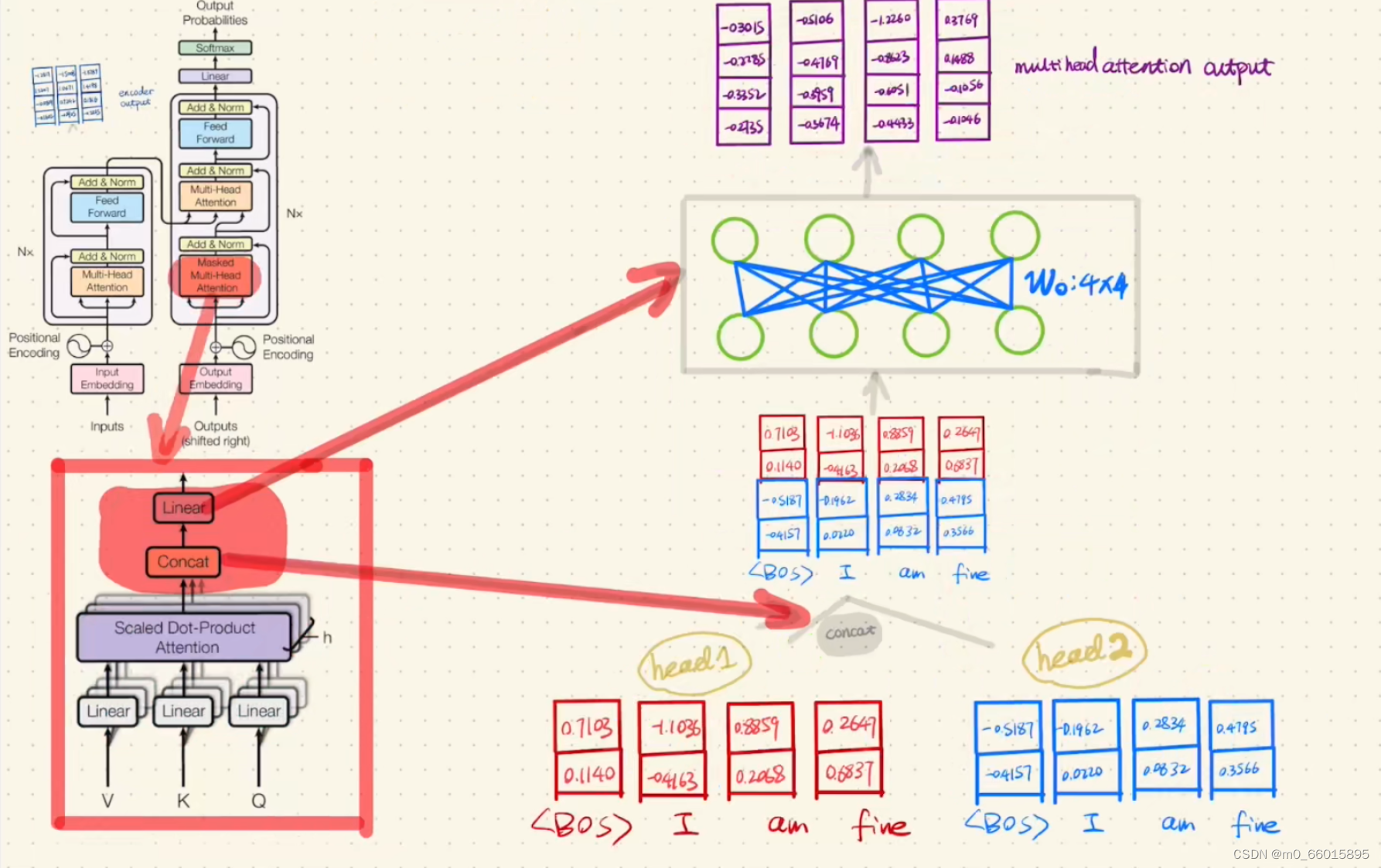
第五步:对Scaled dot-product Attention后的结果进行concat,并通过一个Linear函数(全连接),然后得到Multi-Head Attention的输出。
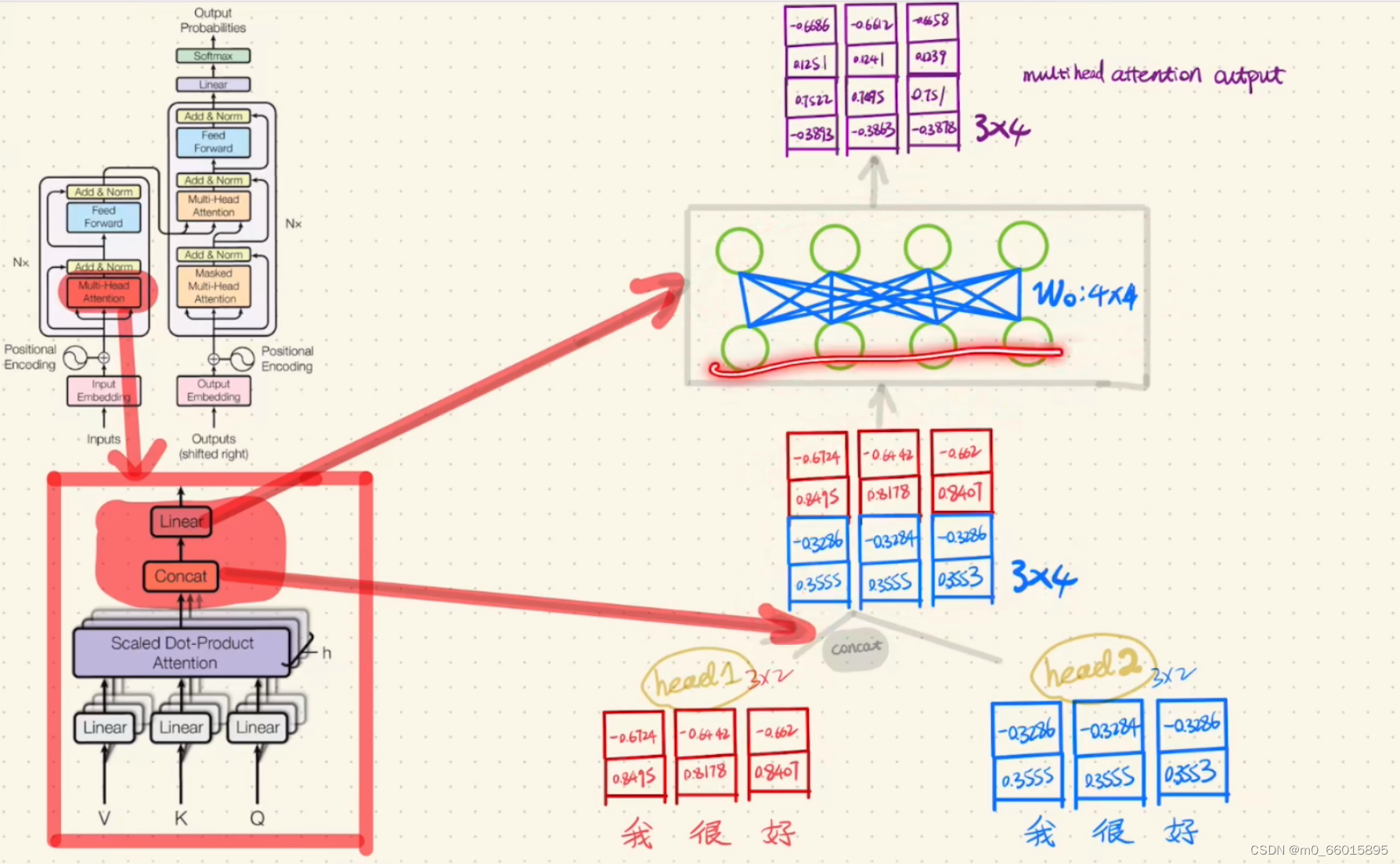
第六步:Encoder的Add&Norm
首先将Multi-Head Attention的输出与Encoder的输入进行相加,然后将相加的结果做一次layer normolization。
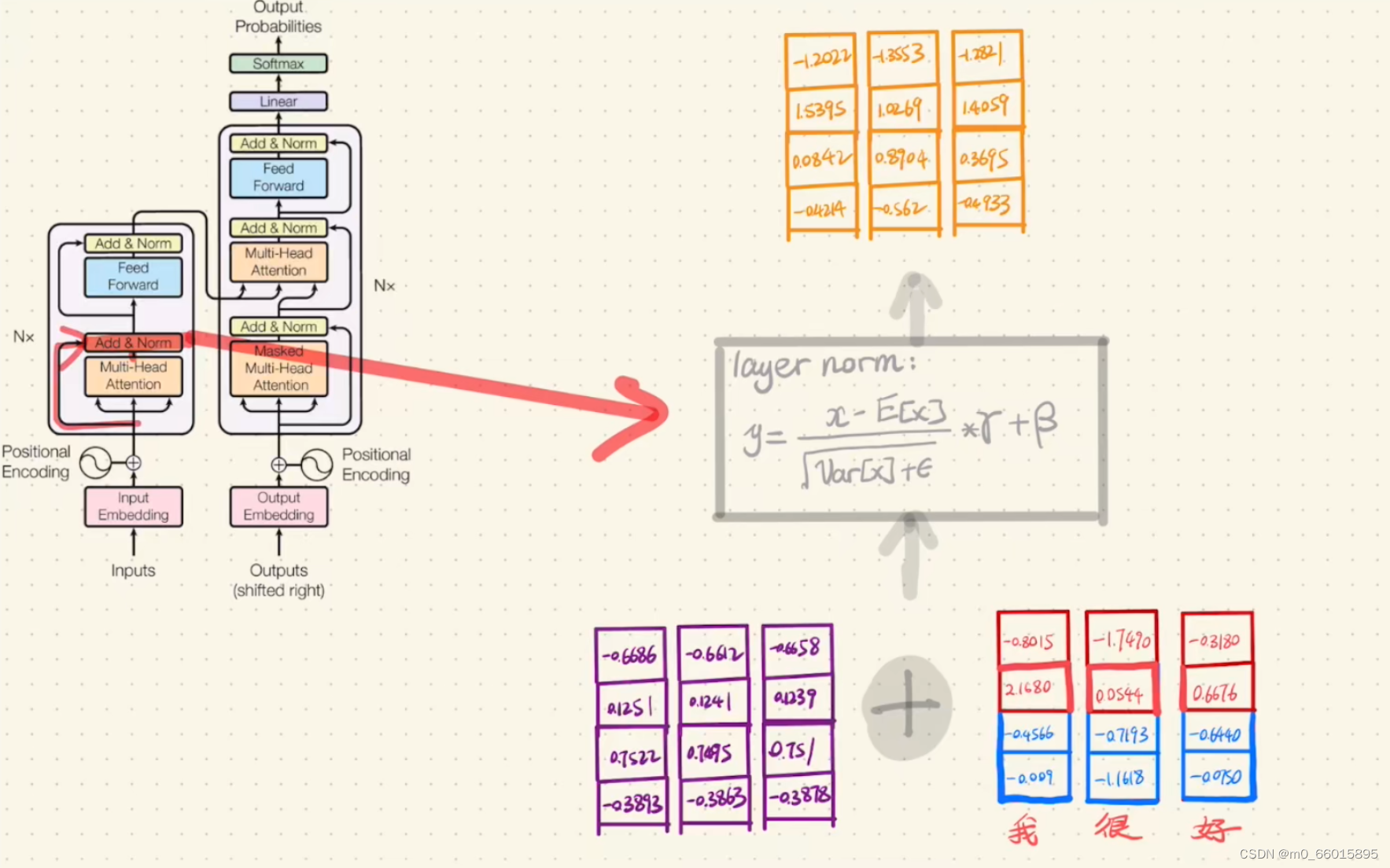
第七步:将Add&Norm结果经过一次Feed Forward Network,然后再做一次Add&Norm,就得到了Encoder最终的输出。
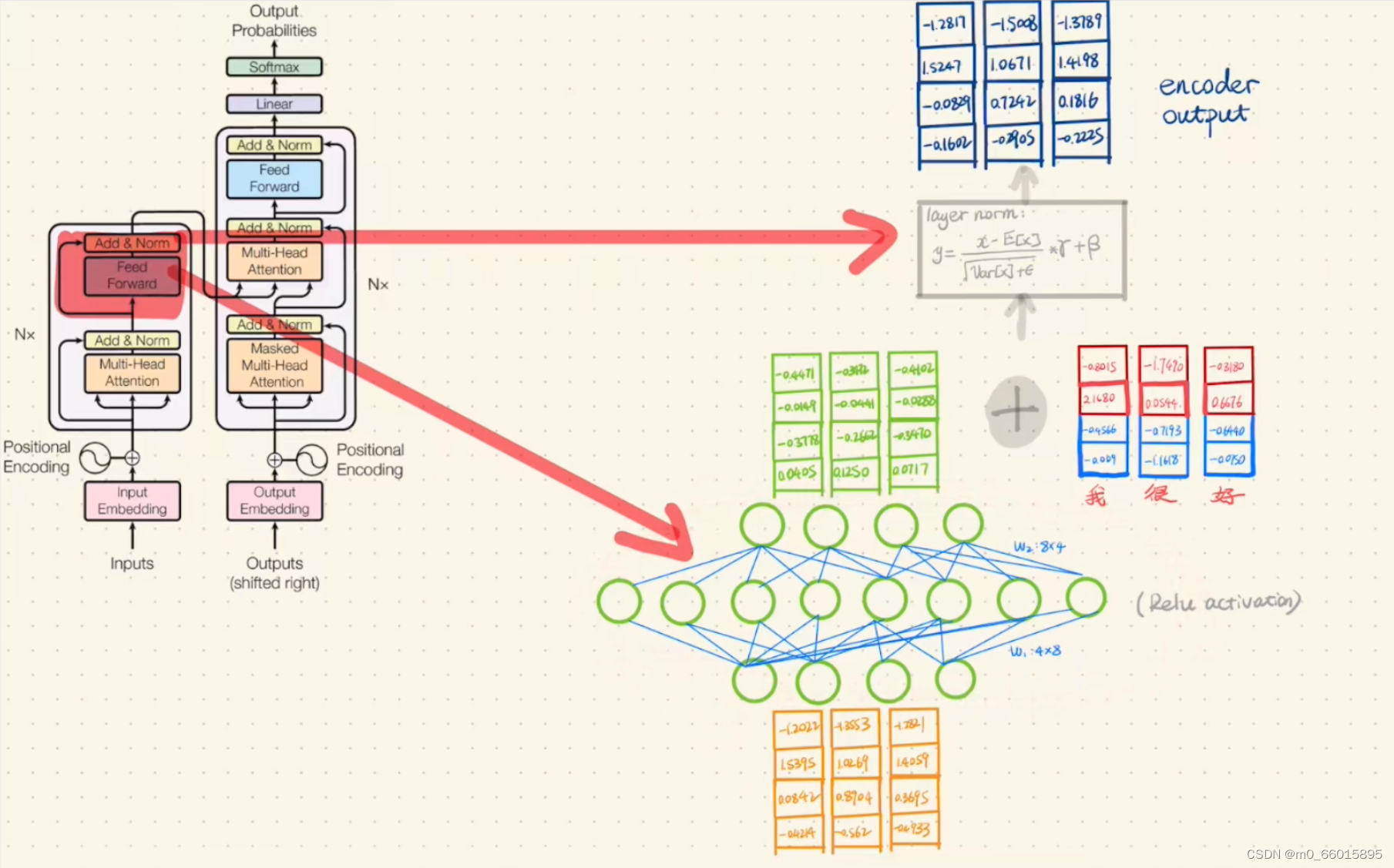
第八步:将targe source作为Encoder的输入,并将输入加上positional embedding
第九步:Decoder的Multi-Head Attention(带Masked)
与Encoder的Multi-Head Attention不同在于带了Masked,Masked 的意思即为在产生第n个编码的时候只能考虑第n个和第n个之前的信息,不能考虑之后的信息。
与Encoder的计算方法一样
为了使得 Decoder不能看见未来的信息。也就是对于一个序列,在时间为 t 的时刻,我们的解码输出应该只能依赖于 t 时刻之前的输出,而不能依赖 t 之后的输出。因此我们需要想一个办法,把 t 之后的信息给隐藏起来。具体做法:产生一个上三角矩阵,上三角的值全为0。把这个矩阵作用在每一个序列上。
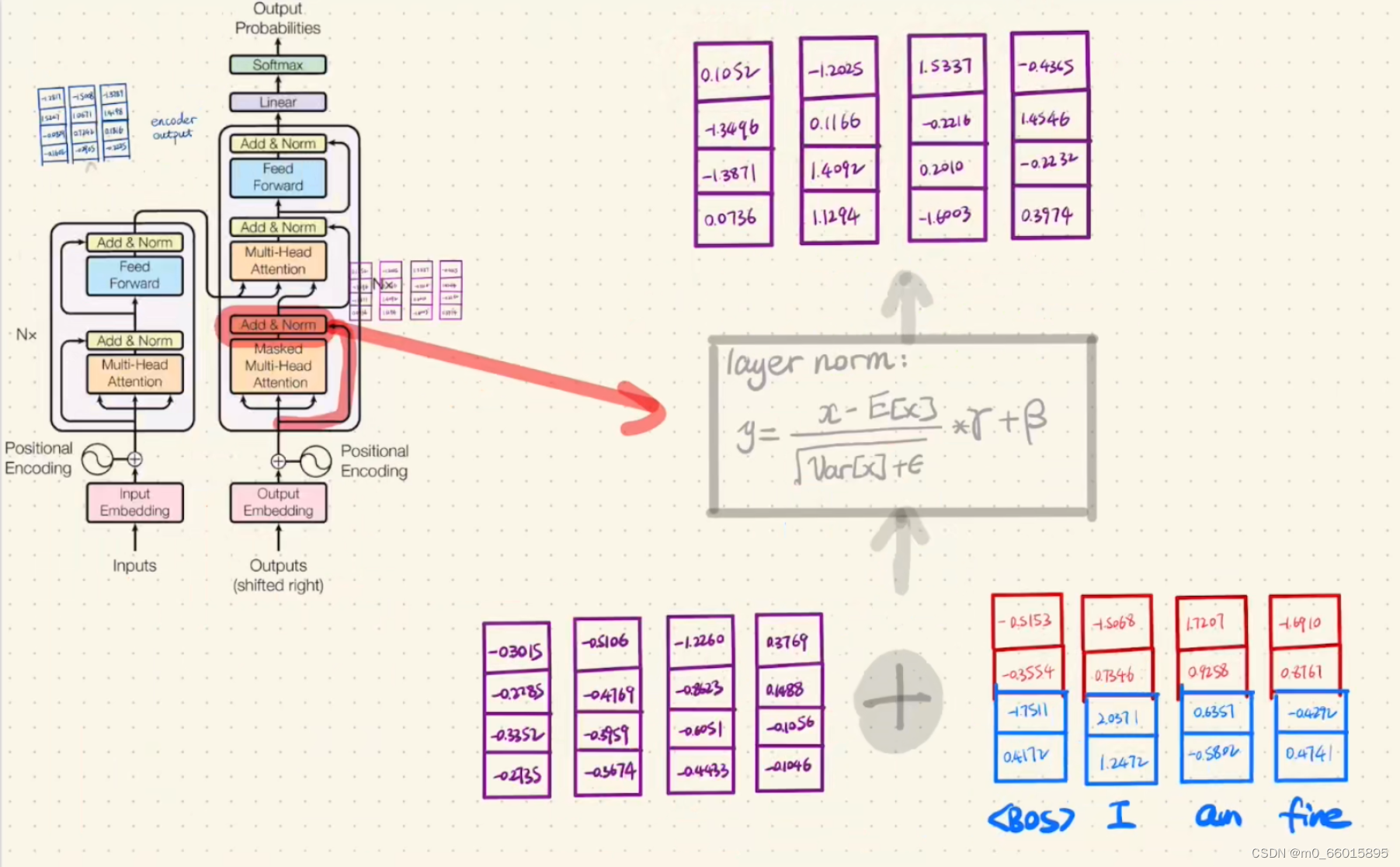
第十步:Decoder的第一次Add&Norm(与Encoder一致)
第十一步:Decoder的第二次Multi-Head Attention+Add&Norm
这里Multi-Head Attention的有三个输入,其中两个来自Encoder的输出(分别作为value和key),一个来自Decoder第一次Add&Norm得到的结果(作为query)。
Normalization有很多种,但是它们都有一个共同的目的,那就是把输入转化成均值为0方差为1的数据。我们在把数据送入激活函数之前进行normalization(归一化),因为我们不希望输入数据落在激活函数的饱和区。Layer normalization它也是归一化数据的一种方式,不过 LN 是在每一个样本上计算均值和方差,而每一个特征维度上进行归一化。
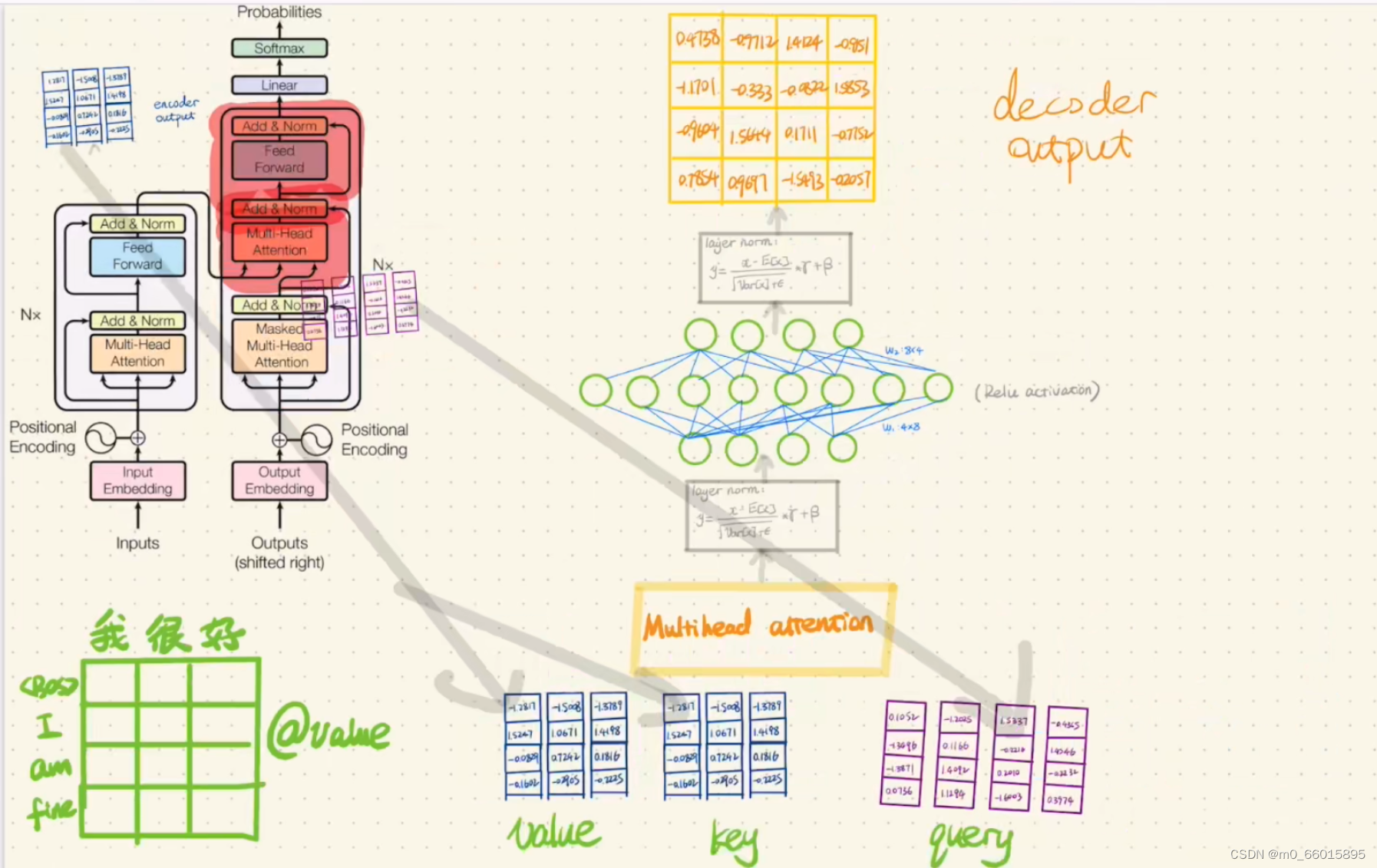
第十二步:将第二次Add&Norm的结果通过一个Feed Forward Network,将结果与上一次Add&Norm的结果作相加,将相加结果通过一个全连接的Linear,最后将结果做一次Softmax,则得到了Decoder的最终输出,也就是得到翻译结果。
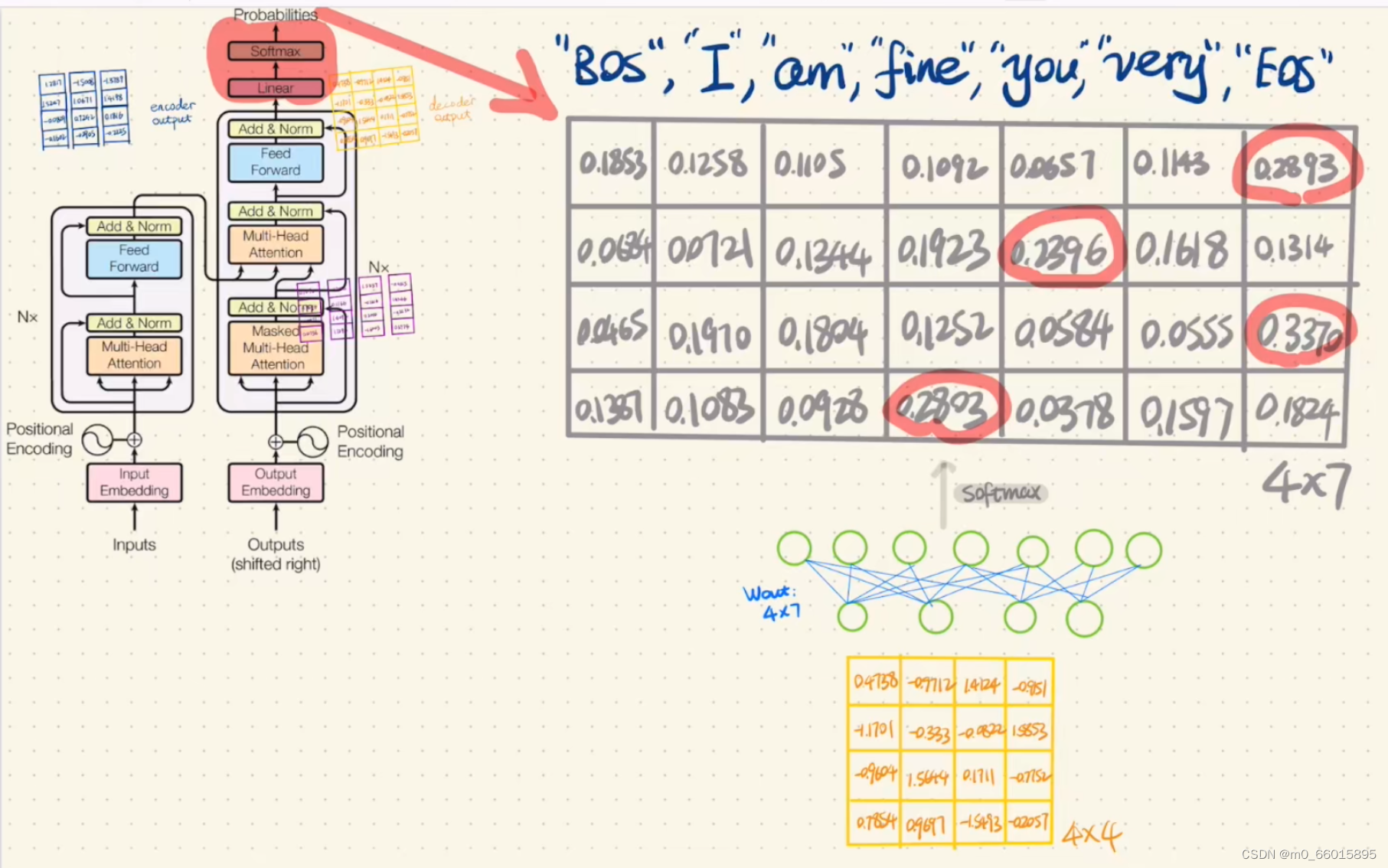
总结
Transformer 在机器翻译任务上的表现超过了 RNN,CNN,只用 encoder-decoder 和 attention 机制就能达到很好的效果,最大的优点是可以高效地并行化。Transformer模型整体看上去看上去很复杂,其实这就是一个Seq2Seq的encoder-decoder,左边一个encoder把输入读进去,右边一个decoder得到输出。为了更好的学习运作机制,之后会通过实例分析代码。

