- 1Unity Canvas的三种模式_unity canvas render mode
- 2当当分库分表中间件-sharding-jdbc_sharding分表 多个分表键
- 3Java——JAVE(音视频格式转换)_java video audio encoder
- 4AGV机器人的调度开发分析(2)- 内核中的调度
- 5常用的排序算法的时间复杂度和空间复杂度_常用排序算法的时间复杂度和空间复杂度
- 6【chainlit】使用chainlit部署chatgpt
- 7多模态大模型:技术原理与实战 大模型在软件研发领域的实战案例与前沿探索
- 8brew upgrade php,mac home-brew 安装 php 失败
- 9MYSQL _数据库_EXPLAIN(查询性能优化)_mysql explain
- 10python正则表达式爬取网页数据_常用正则表达式爬取网页信息及HTML分析总结
Semantic-NeRF: Semantic Neural Radiance Fields(Semantic-NeRF:语义神经辐射场)_语义nerf
赞
踩
摘要
1. 介绍
2. 相关工作
2.1. 基于代码的表示法
2.2. 隐式三维表示法
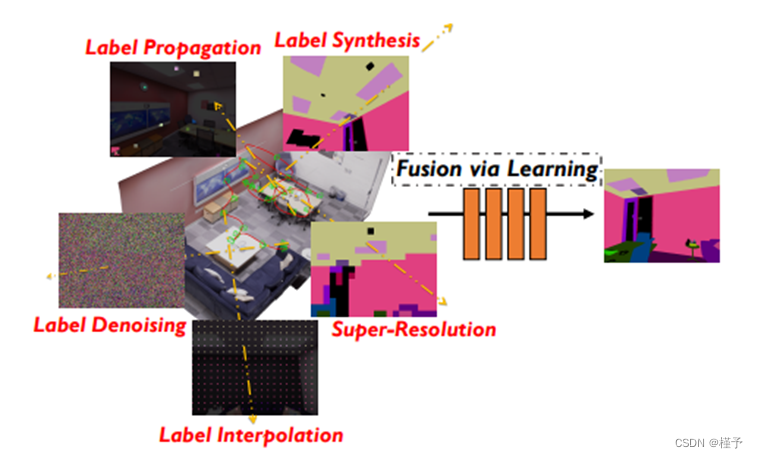
3. 方法
3.1. 前言
NeRF [16] 利用 MLPs 将连续三维场景密度 σ 和颜色 c = (r, g, b) 隐式表示为空间坐标 x = (x, y, z) 和观察方向 d = (θ, φ) 的连续 5D 输入向量的函数。具体来说,σ(x) 仅是三维位置的函数,而辐射度 c(x, d) 则是三维位置和观察方向的函数。 为了计算单个像素的颜色,NeRF[16] 采用分层分层采样的数值正交法来近似体积渲染。在一个分层中,如果 r(t) = o + td是从摄像机空间投影中心发出的射线,穿过一个给定的像素点,并穿过近界和远界(tn 和 tf),那么对于在 tn 和 tf 之间选取的 K 个随机正交点 {tk} K k=1 ,其近似期望颜色为:
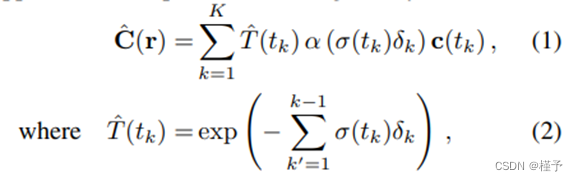
其中,α (x) = 1 - exp(-x),δk = tk+1 - tk 是相邻两个正交采样点之间的距离。 给定观测场景的多视角训练图像后,NeRF 使用随机梯度下降法 (SGD) 通过最小化光度差异来优化 σ 和 c。
3.2. 语义-NeRF
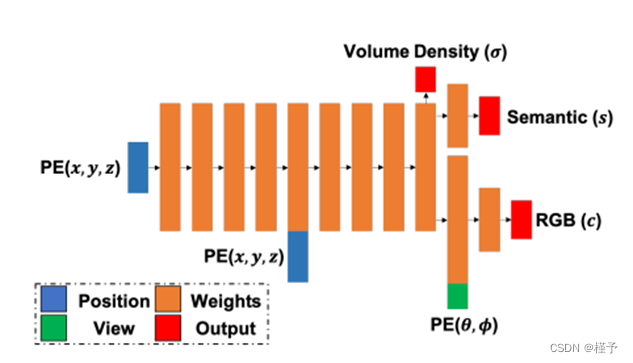
图 2:语义-NeRF 网络架构。三维位置(x、y、z)和观察方向(θ、φ)在位置编码(PE)后输入网络。体积密度 σ 和语义对数 s 是三维位置的函数,而颜色 c 则取决于观察方向。
![]()
其中,FΘ 代表学习到的 MLP。
图像平面中给定像素的近似预期语义对数 Sˆ(r)可写成:
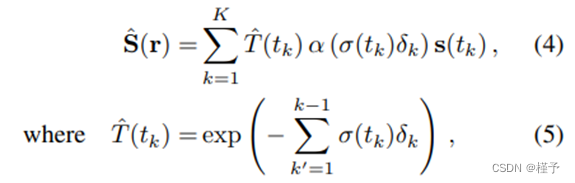
α (x) = 1 - exp(-x),δk = tk+1 - tk 是相邻样本点之间的距离。然后,语义对数可通过软最大归一化层转化为多类概率。
3.3. 网络训练
在光度损失 Lp 和语义损失 Ls 的条件下,我们从头开始训练整个网络。
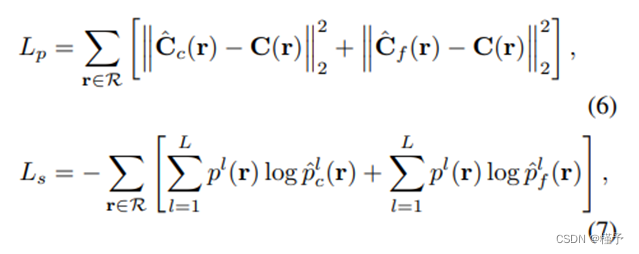
其中,R 是训练批次中的采样射线,C(r)、Cˆ c(r) 和 Cˆ f (r) 分别是射线 r 的地面实况图、粗体预测图和细体预测图的 RGB 颜色。同样,p l、pˆ l c 和 pˆ l f 分别是光线 r 的地面实况图、粗体预测图和精细体预测图中 l 类的多类语义概率。 Ls 被选为多类交叉熵损失,以鼓励渲染的语义标签与所提供的标签保持一致,无论这些标签是地面实况、噪声还是部分观测数据。因此,总训练损失 L 为:
![]()
其中,λ 是语义损失的权重,设置为 0.04 以平衡两种损失的大小[8]。在实践中,我们发现实际性能对 λ 值并不敏感,将 λ 设为 1 可获得相似的性能。这些光度和语义损失自然会促使网络从底层联合表示生成多视角一致的二维渲染。
3.4. 实施
4. 实验和应用
在对彩色图像和带有相关姿势的语义标签进行训练后,我们获得了特定场景的隐式三维语义表征。我们通过将三维表征投射回二维图像空间来定量评估其有效性,在二维图像空间中,我们可以直接获取明确的地面实况数据。我们旨在展示高效学习这种用于语义标注和理解的联合三维表示法的益处和应用前景。我们恳请读者在项目网页 In-Place Scene Labelling and Understanding with Implicit Scene Representation 上查看更多定性结果。
4.1. 室内场景数据集和数据准备
Replica: Replica [28] 是一个基于重构的三维数据集,包含 18 个高保真场景,其中有密集的几何图形、HDR 纹理和语义注释。我们使用 Habitat 模拟器[23],从随机生成的类似手持摄像机运动的 6-DOF 轨迹中渲染 RGB 彩色图像、深度图和语义标签。我们沿用 SceneNet RGB-D [14] 的程序,并锁定滚动角度,使摄像机的向上矢量沿 Y 轴指向。 在特定场景实验中,我们使用 Replica 提供的 88 个语义类别,并在第 4.4 节中按照 ScanNet [3] 的映射约定,将这些标签手动映射到流行的 NYUv2-13 定义 [24, 4],以进行多视角标签融合。对于每个由房间和办公室组成的复制场景,我们使用水平视场角为 90 度的默认针孔摄像机模型,以 640x480 的分辨率渲染了 900 幅图像。我们从序列中每隔 5 个帧取样,组成训练集,并对中间帧取样,组成测试集。
ScanNet:ScanNet[3]是一个大规模的真实世界室内RGB-D视频数据集,包含1513个场景中的250万个视图,具有丰富的注释,包括语义分割、摄像机姿势和表面重构。我们仅使用提供的彩色图像、摄像机姿势和二维语义标签在 ScanNet 场景上训练 SemanticNeRF。每个场景中的序列都是均匀采样的,因此训练数据的总量大约为 300 帧。在实验过程中,我们选择了几个室内房间规模的场景,并使用来自 NYUv2-40 定义的姿势图像和语义标签对每个场景训练一个 Semantic-NeRF。
4.2. 语义神经辐射场
需要注意的是,我们可能会认为大量高质量的语义标注信息可以提高重建质量,但在本文中,我们关注的是在语义标注稀少或嘈杂的相反情况下,几何如何帮助语义学。
4.3. 使用稀疏标签的语义视图合成
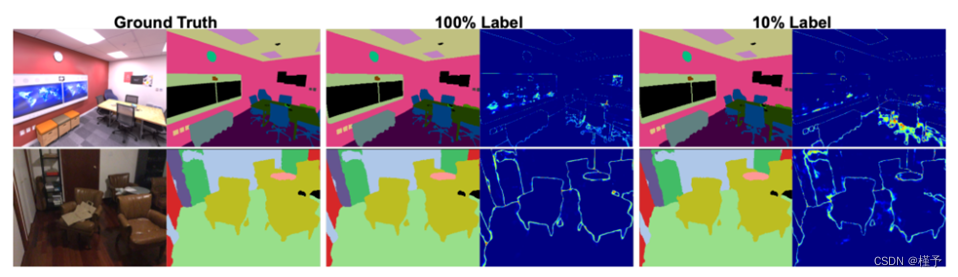
4.3.1. 语义标签去噪
具有像素噪声的标签我们通过添加独立的像素噪声来破坏真实的训练语义标签。具体来说,我们在每个训练帧中随机选择固定的一部分像素,并将其标签随机翻转为任意标签(包括无效类别)。在仅使用这些噪声标签进行训练后,我们通过渲染回相同的训练姿势来获得去噪语义标签。
虽然像素去噪的破坏程度如此严重并非现实应用,但这仍然是一项极具挑战性的任务,更重要的是,它凸显了我们的主要观点,即训练本身就是一个融合过程,通过隐式联合表征的内部一致性,可以获得连贯的渲染效果。

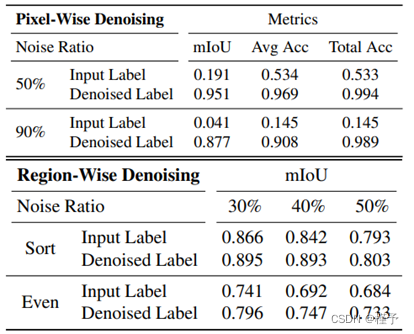
表 1: 对 Replica 标签去噪的定量评估。mIoU 用于区域去噪,因为它对场景中椅子类别的错误预测更为敏感。两个表格都是根据干净的训练标签计算的。
具有区域噪声的标签我们通过在标签图中随机翻转某些整体实例(而不是像素)的类别标签,进一步验证了语义一致性的有效性。这可以更好地模拟真实的单视角 CNN 的行为,因为从受阻或模糊的视角看,整个物体很容易被标记为相似但不正确的类别。 我们选择包含 8 个椅子实例的复制房间 2 作为测试场景。对于每个椅子实例,我们计算占用面积比(即属于该实例的像素数与图像中每个地面实况标签帧的像素总数之比),然后根据占用面积比对序列中的标签图进行排序。有两个标准用于选择其中的帧随机扰动每个实例: (1) 排序: 选择占用面积比最小的标签图。这样做的直觉是,由于上下文模糊不清,有部分观察结果的帧更容易被语义标签预测网络误标。(2) 均匀: 从排序序列中均匀选择标签图,引入更多的大面积不一致。将帐篷区域纳入训练过程。

图 6:当我们随机改变椅子实例的训练语义类别标签(蓝色)时,呈现标签的定性结果。从左至右:带有区域性噪声的训练标签;从相同姿势渲染的恢复语义标签;以及信息熵,突出显示带有噪声预测的区域。
4.3.2. 超分辨率
(1) 将所有地面实况标签从 320×240 缩放到 40 × 30,然后再缩放回原始尺寸;使用近邻插值法确定像素大小。
(2) 除了来自低分辨率标签图(行和列除以 8)的像素外,所有像素都被无效类屏蔽,从而不会造成训练损失。

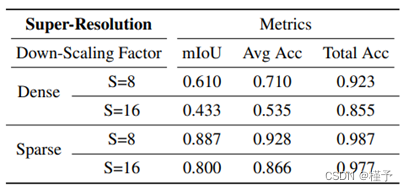
表 2: 标签超分辨率的定量评估,无论是采样标签还是插值低分辨率标签,都有良好的表现。mIoU 指标表明,稀疏但几何精度高的标签对高分辨率下的精细结构更有帮助。
4.3.3. 标签传播

图 8:分别使用帧内每个类别的单像素、1% 或 5%像素的部分注释进行标签传播的结果。出于可视化目的,即使是放大 9 倍的单击也能获得准确的标签。
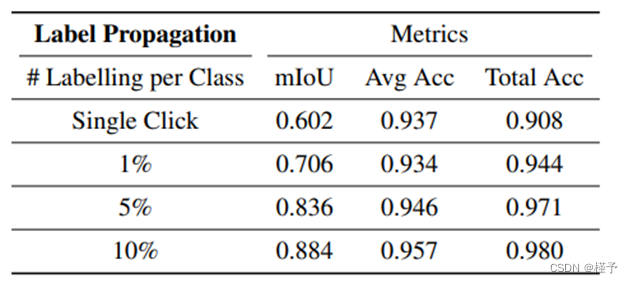
表 3:使用测试姿势对复制场景的标签插值和传播进行评估。即使是单像素监督也能在准确度指标上取得有竞争力的表现,这突出表明了该表示法在交互式场景标注方面的有效性。
4.3.4. 多视图语义融合
为了准备 Replica 数据集的训练数据,我们为每个 Replica 场景渲染了两个不同的序列,以覆盖场景的各个部分。每个序列包括从 900 个大小为 640×480 的渲染中均匀采样的 90 个帧,并将语义标签重新映射为 NYUv2-13 类别惯例。 我们选择以 ResNet-101 为骨干的 DeepLabV3+ [2] 作为单目标签预测的 CNN 模型。 为了生成合适的单目 CNN 预测并避免过度拟合,我们在 SUN-RGBD [26] 上训练 DeepLab,然后使用所有 Replica 场景的数据对其进行微调,但用于训练 Semantic-NeRF 和标签融合评估的场景除外。我们重复这一微调过程,为每个测试场景训练一个单独的 DeepLab CNN 模型。 测试场景的单目 CNN 预测用于两个目的:(1)我们特定场景 Semantic-NeRF 模型的训练监督;(2)基线多视图语义融合方法的单目预测(每像素密集软最大概率)。我们使用摆好姿势的彩色图像和 CNN 预测的标签对 Semantic-NeRF 进行 200,000 步的训练,然后将融合后的语义标签重新渲染回训练姿势,作为融合结果。 值得注意的是,两种基线融合技术都需要深度信息来计算帧间的密集对应关系,而我们的技术只需要图像。我们在表 4 中报告了所有测试场景的平均性能,其中两种基线方法都使用了地面实况深度图来代表 "最佳情况"。我们的方法在所有指标上都取得了最高的改进,这表明了我们的联合表示法在标签融合中的有效性。
5. 结论和未来工作
6. 致谢
利用内隐场景表示法进行现场场景标注和理解的补充材料
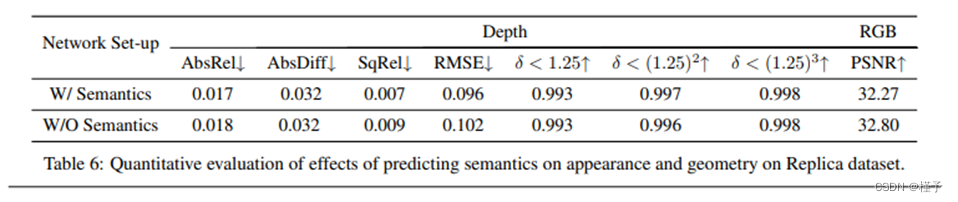
A.学习语义对辐射和几何的影响

表 5:深度指标的定义:n 为有效深度像素的数量,d 和 dgt 分别为测试姿态下的渲染深度和地面实况深度。
B. 从摆拍图像进行语义三维重建

图 9:使用 Semantic-NeRF 获得的语义三维重建。请注意,我们学习到的特定场景三维表示法可以预测隐蔽区域的几何形状和语义,并在一定程度上填补了未观察区域造成的漏洞。
C. 网络架构
D. 更多定性结果
图 10、图 11 和图 12 分别展示了语义视图合成、标签去噪和超分辨率的定性结果。 我们恳请读者观看我们在项目页面 Shuaifeng Zhi Semantic-NeRF 上的补充视频,该视频重点介绍了在各种情况和应用中语义渲染的准确性和一致性。