
- 1Unity3D 游戏数据本地化存储与管理详解
- 2生成对抗网络(GAN)_对抗网络 共享特征
- 3python+jieba+wordcloud实现超酷的词云_jieba分词后如何使用jupyter输出
- 4go + uniapp 通过 微信 code 获取 appid 等信息 无废话_uniapp获取微信code
- 5go语言有没有简单的流程引擎_go 流程引擎
- 6Mysql---C#在cmd中使用mysqldump导出sql文件
- 7论文阅读【时间序列分析1】Reconstructing Nonlinear Dynamical Systems from Multi-Modal Time Series_多模态时间序列
- 8yolov5调试common.py出现importerror: cannot import name ‘tryexcept‘ from ‘utils‘_cannot import name 'tryexcept' from 'utils
- 9Android:漫画APP开发笔记之ListView中图片按屏幕宽度缩放_android listview可缩放
- 10基于 Nginx Ingress + 云效 AppStack 实现灰度发布
[深度学习-NPL]ELMO、BERT、GPT学习与总结_npl gpt
赞
踩
系列文章目录
深度学习NLP(一)之Attention Model;
深度学习NLP(二)之Self-attention, Muti-attention和Transformer;
深度学习NLP(三)之ELMO、BERT、GPT
深度学习NLP(四) 之IMDB影评情感分析之BERT实战
1, word2vec, glove的应用以及不足之处
1.1 one-hot 编码
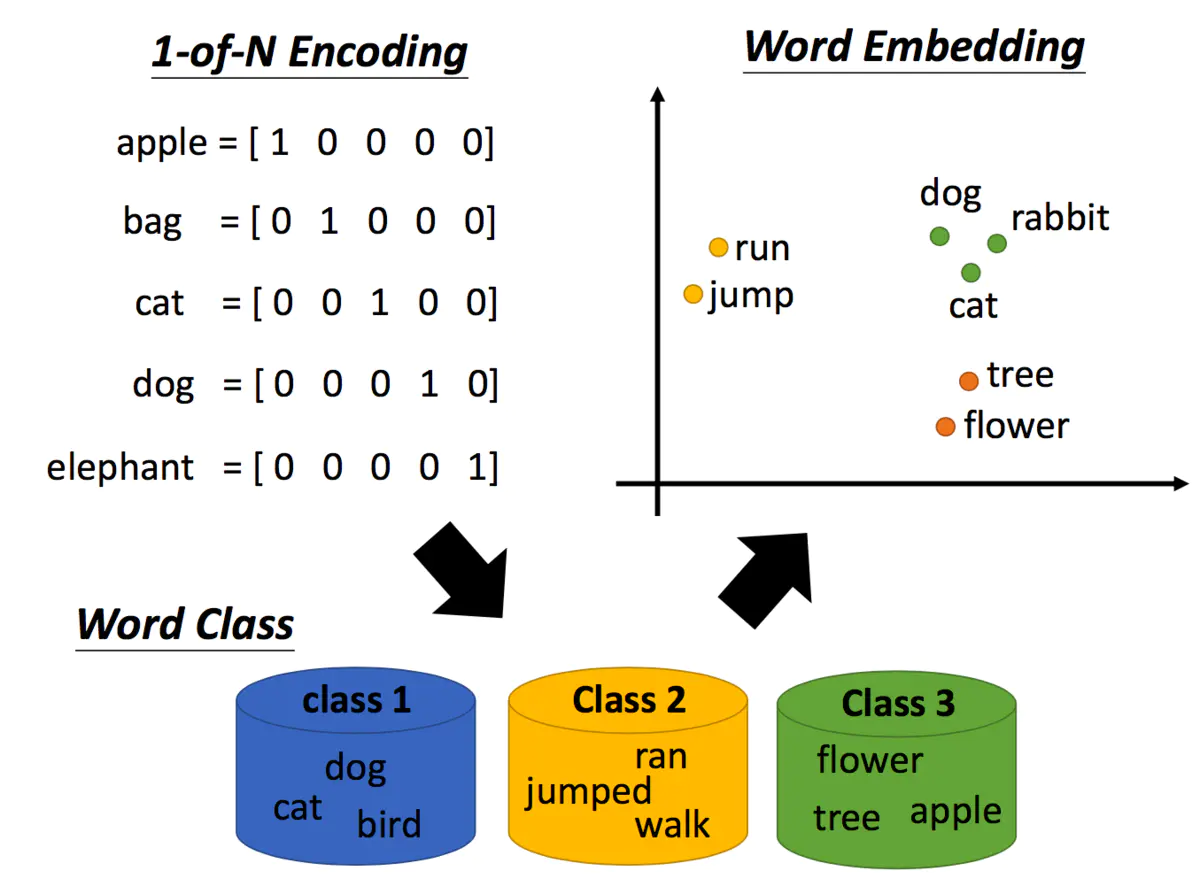
机器是如何理解我们的文字的呢?最早的技术是1-of-N encoding,把每一个词汇表示成一个向量,每一个向量都只有一个地方为1,其他地方为0。但是这么做词汇之间的关联没有考虑,因为不同词之间的距离都是一样的。
所以,接下来有了word class的概念,举例说dog、cat和bird都是动物,它们应该是同类。但是动物之间也是有区别的,如dog和cat是哺乳类动物,和鸟类还是有些区别的。
1.2 word2vec
后来有了更进阶的想法,称作word embedding,我们用一个向量来表示一个单词,相近的词汇距离较近,如cat和dog。那word embedding怎么训练呢?比较熟知的就是word2vec方法。
但是呢,同一个词是可能有不同的意思的,如下图中的bank,前两个指银行,后两个指河堤:

尽管有不同的意思,但使用传统的word embedding的方法,相同的单词都会对应同样的embedding。但我们希望针对不同意思的bank,可以给出不同的embedding表示。
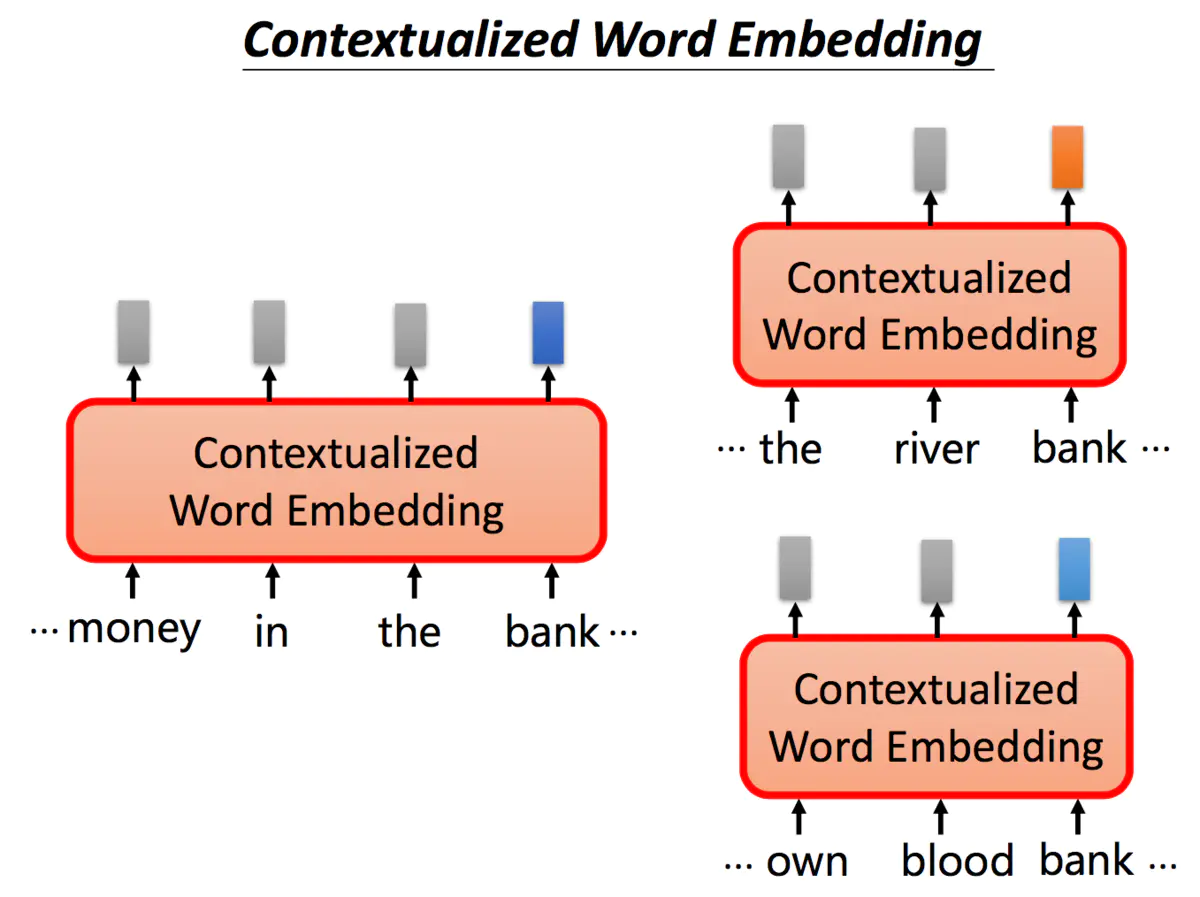
根据上下文语境的不同,同一个单词bank我们希望能够得到不同的embedding,如果bank的意思是银行,我们期望它们之间的embedding能够相近,同时能够与河堤意思的bank相距较远。
1.3 word2vec与glove的缺点
没有考虑上下文语境
2,ELMO的应用
ELMO是Embeddings from Language Model的简称,ELMO是《芝麻街》中的一个角色。它是一个RNN-based的语言模型,其任务是学习句子中的下一个单词或者前一个单词是什么。
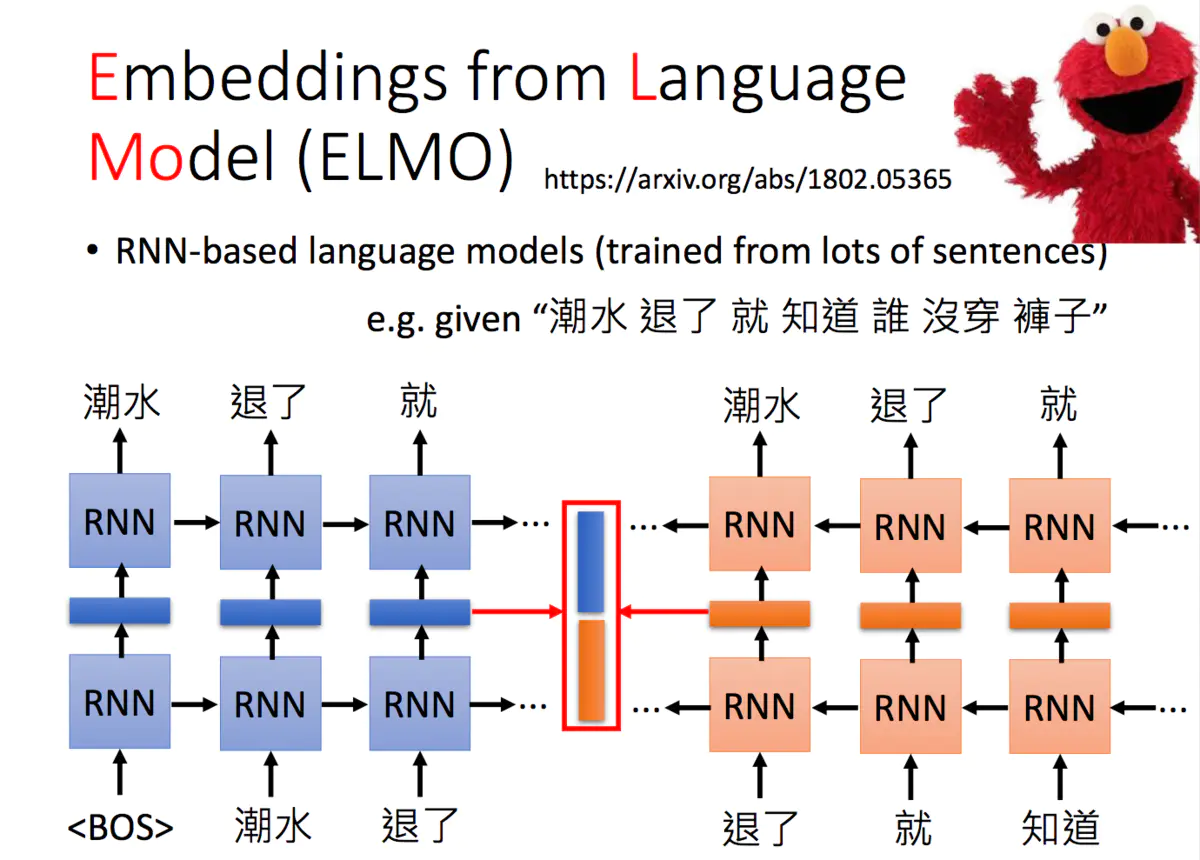
它是一个双向的RNN网络,这样每一个单词都对应两个hidden state,进行拼接便可以得到单词的Embedding表示。当同一个单词上下文不一样,得到的embedding就不同。
当然,我们也可以搞更多层:
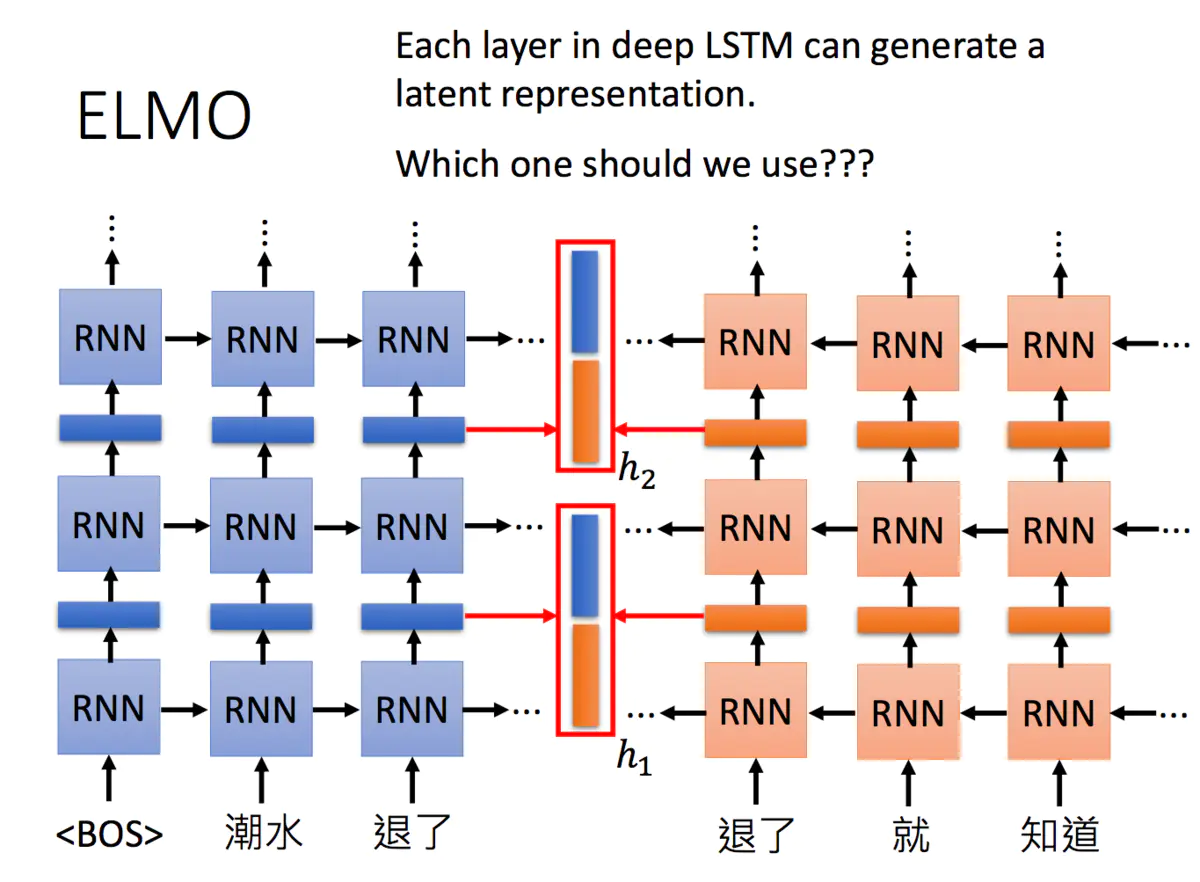
这么多层的RNN,内部每一层输出都是单词的一个表示,那我们取哪一层的输出来代表单词的embedding呢?ELMO的做法就是我全都要:

在ELMO中,一个单词会得到多个embedding,对不同的embedding进行加权求和,可以得到最后的embedding用于下游任务。要说明一个这里的embedding个数,下图中只画了两层RNN输出的hidden state,其实输入到RNN的原始embedding也是需要的,所以你会看到说右下角的图片中,包含了三个embedding。
a1 与 a2 是一起跟下游任务结合训练出来的
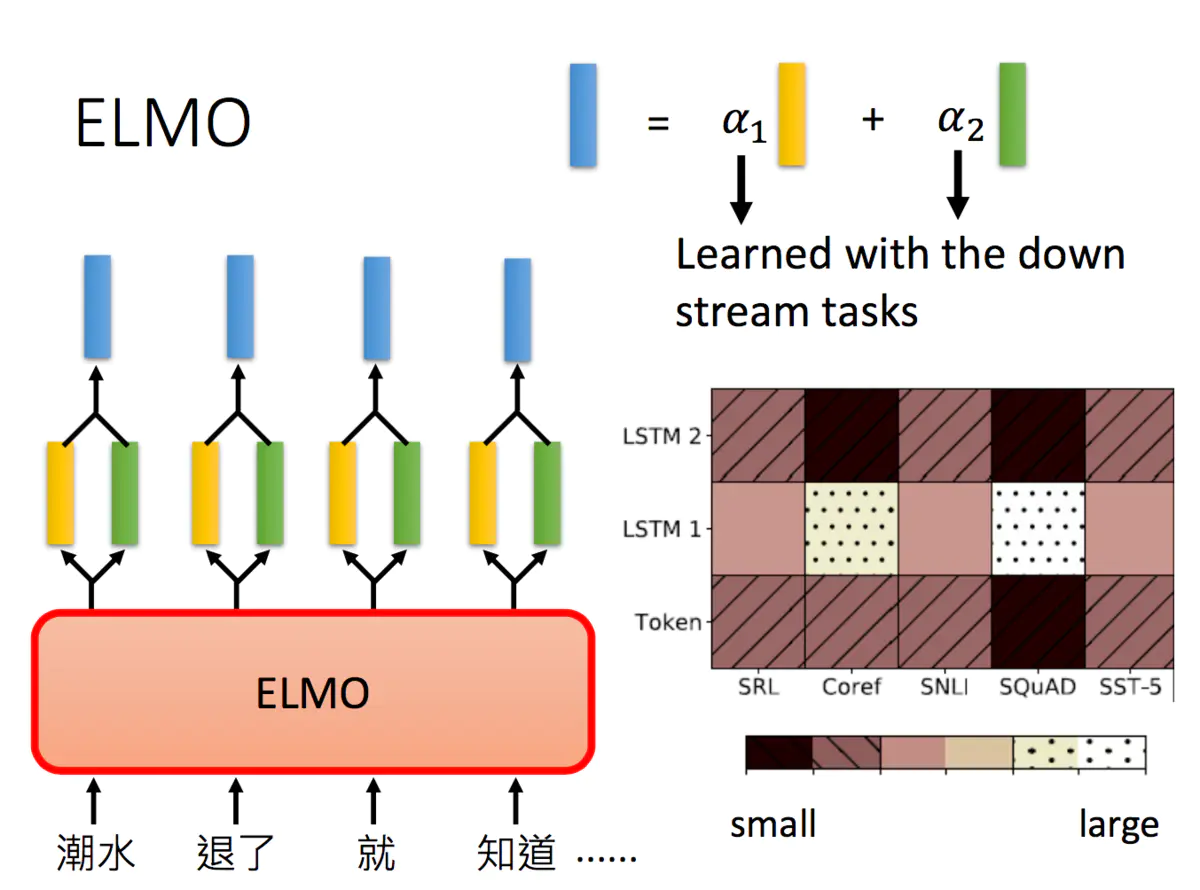
但不同的权重是基于下游任务学习出来的,上图中右下角给了5个不同的任务,其得到的embedding权重各不相同。
代码
import tensorflow_hub as hub
import tensorflow as tf
from keras import backend as K
elmo = hub.load(r"D:\train_data\3")
x = ["the cat is on the mat", "dogs are in the fog"]
x = tf.convert_to_tensor(x)
t = elmo.signatures['default']( x)
#t = dict
print(t.keys())
print(t['elmo'].numpy().shape)
print(t['default'].numpy().shape)
print(t['sequence_len'].numpy().shape)
print(t['word_emb'].numpy().shape)
print(t['lstm_outputs1'].numpy().shape)
print(t['lstm_outputs2'].numpy().shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
dict_keys(['word_emb', 'lstm_outputs2', 'sequence_len', 'elmo', 'default', 'lstm_outputs1'])
(2, 6, 1024)
(2, 1024)
(2,)
(2, 6, 512)
(2, 6, 1024)
(2, 6, 1024)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
Elmo 优点:
1、加入上下文信息,不在像之前固定的窗口大小,这样可以保证得到的向量是有上下文信息的;
2、增加模型的神深度,并且保证将每一层得到的向量都用于预测。
Elmo 缺点
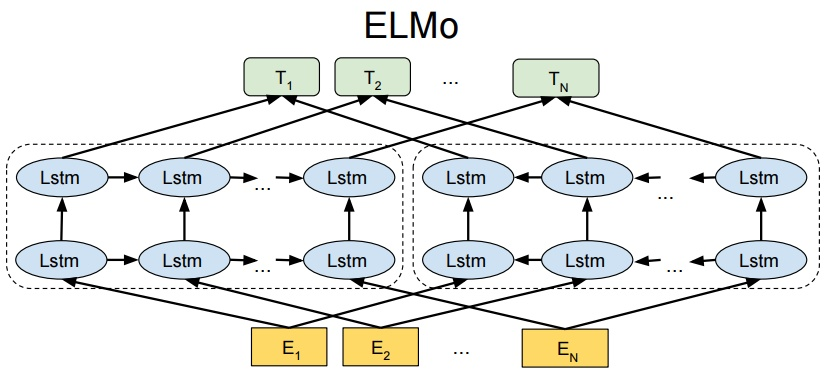
1 执行时串行的,不管时训练还时预测
2 不完全双向
是指模型的前向和后向 LSTM两个模型是分别训练的,从图中也可以看出,对于一个序列,前向遍历一遍获得左边的 LSTM,后向遍历一遍获得右边的LSTM,最后得到的隐层向量直接通过拼接 (concat) 得到结果向量,并且在最后的Loss Function 直接相加,并非完全同时的双向计算。
3 自己看见自己
是指要预测的下一个词在给定的序列中已经出现的情况。传统语言模型的数学原理决定了它的单向性。从公式
p
(
s
)
=
p
(
w
0
)
⋅
p
(
w
1
∣
w
0
)
⋅
p
(
w
2
∣
w
1
,
w
0
)
⋯
p
(
w
n
∣
c
o
n
t
e
x
t
)
p
(
s
)
p(s)=p(w0)⋅p(w1∣w0)⋅p(w2∣w1,w0)⋯p(wn∣context)p(s)
p(s)=p(w0)⋅p(w1∣w0)⋅p(w2∣w1,w0)⋯p(wn∣context)p(s) 可以看出,传统语言模型的目标是获得在给定序列从头到尾条件概率相乘后概率最大的下一词,而加深网络的层数会导致预测的下一词已经在给定序列中出现了的问题,这就是“自己看见自己”。
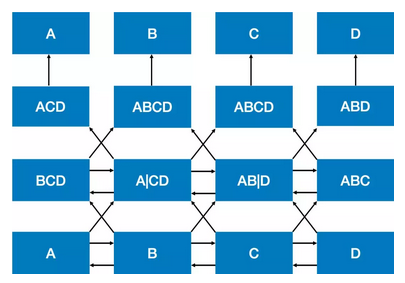
如上图所示(从下往上看),最下行是训练数据ABCD,经过两个Bi-LSTM操作,需要预测某个词位置的内容。比如第二行第二列A∣C∣C这个结果是第一层Bi-LSTM在BB位置输出的内容,包括正向A 和反向 CD,直接拼接成A∣CD。比如第三行第二列ABCD这个结果是前向 BCD和反向AB∣DAB∣D拼接结果,而当前位置需要预测的是 BB,已经在 ABCD中出现了,这就会有问题。因而对于 Bi-LSTM,只要层数增加,就是会存在“自己看见自己”的问题。
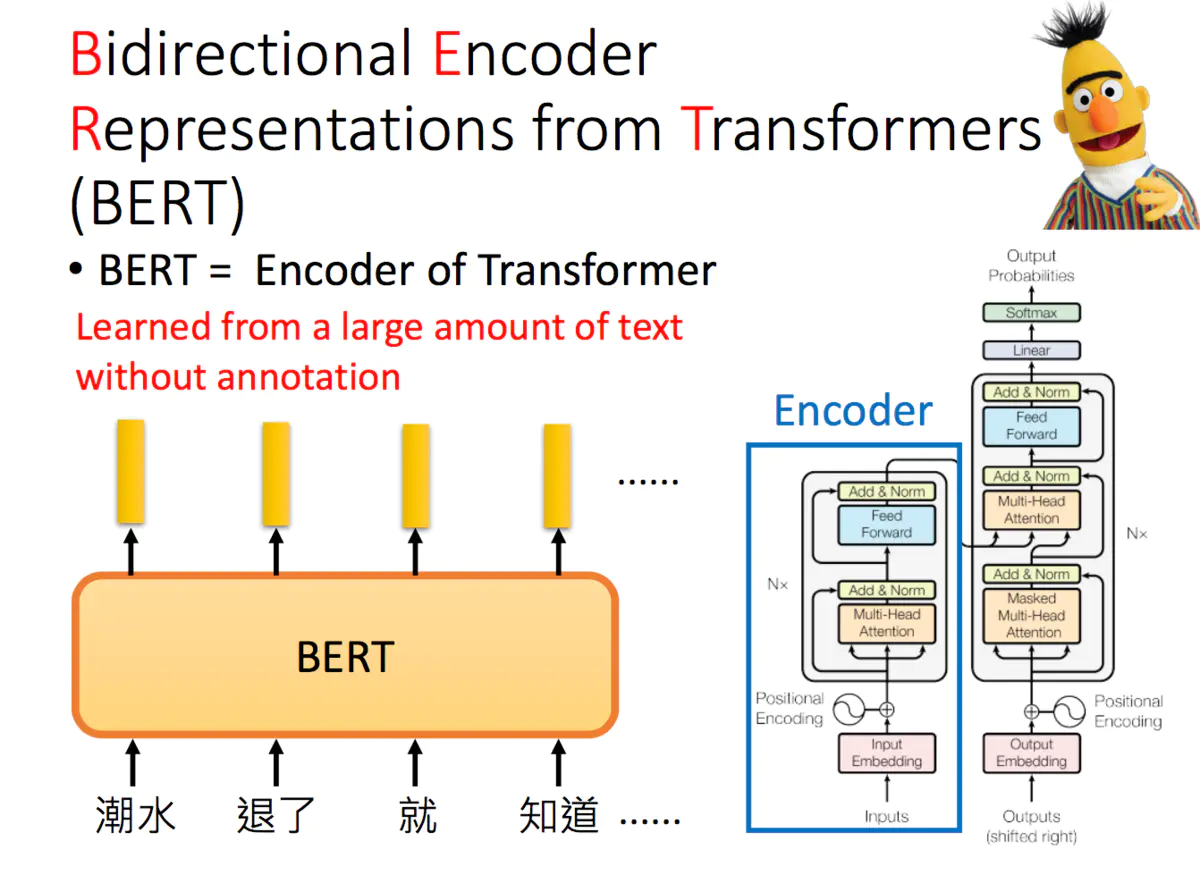
3、Bert的应用
Bert是Bidirectional Encoder Representations from Transformers的缩写,它也是芝麻街的人物之一。Transformer中的Encoder就是Bert预训练的架构。
如果是中文的话,可以把字作为单位,而不是词。因为中文的词太多,但是中文的字想多少点
3.1 Bert怎么训练
只是Transformer中的Encoder,那Bert怎么训练呢?文献中给出了两种训练的方法,
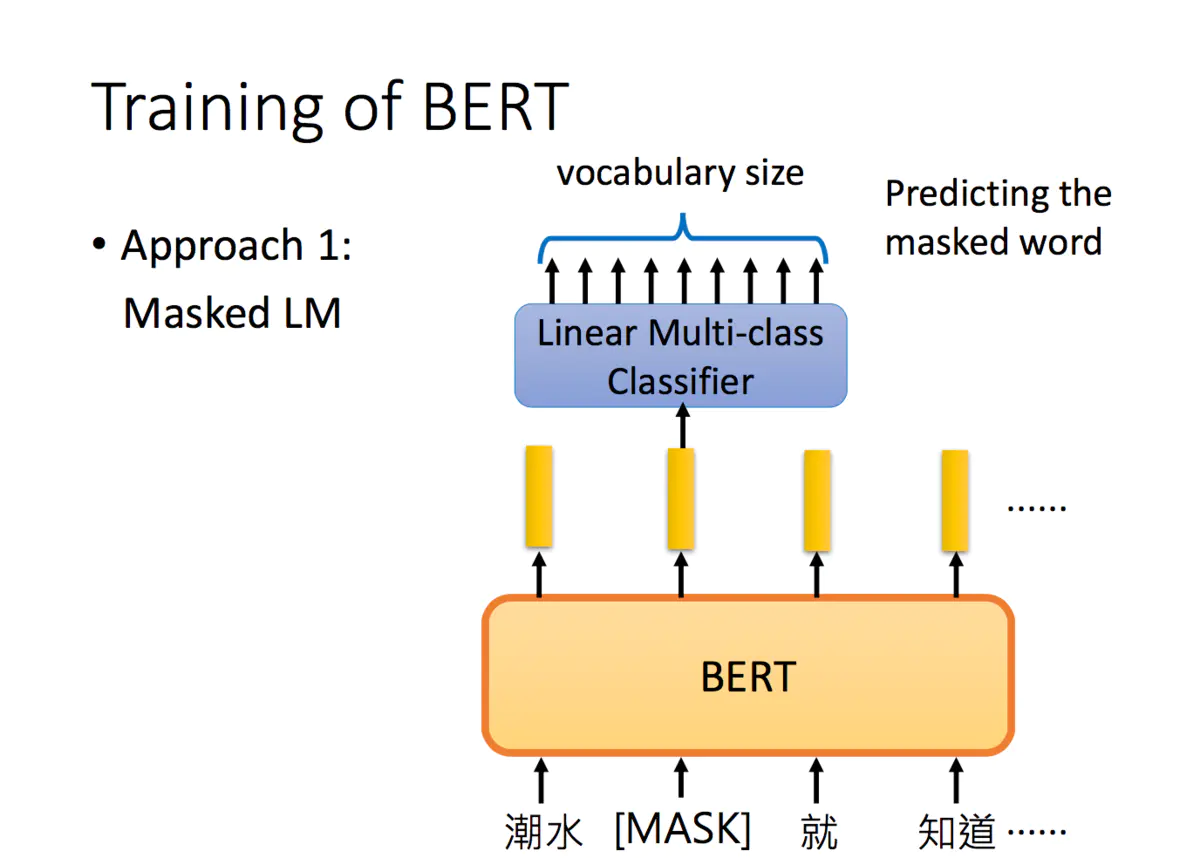
3.1.1 第一个称为Masked LM,
做法是随机把一些单词变为Mask,让模型去猜测盖住的地方是什么单词。假设输入里面的第二个词汇是被盖住的,把其对应的embedding输入到一个多分类模型中,来预测被盖住的单词。
3.1.2 两个句子是不是连接在一起的
另一种方法是预测下一个句子, 这里,先把两句话连起来,中间加一个[SEP]作为两个句子的分隔符。而在两个句子的开头,放一个[CLS]标志符(要做分类的事情),将其得到的embedding输入到二分类的模型,输出两个句子是不是接在一起的。
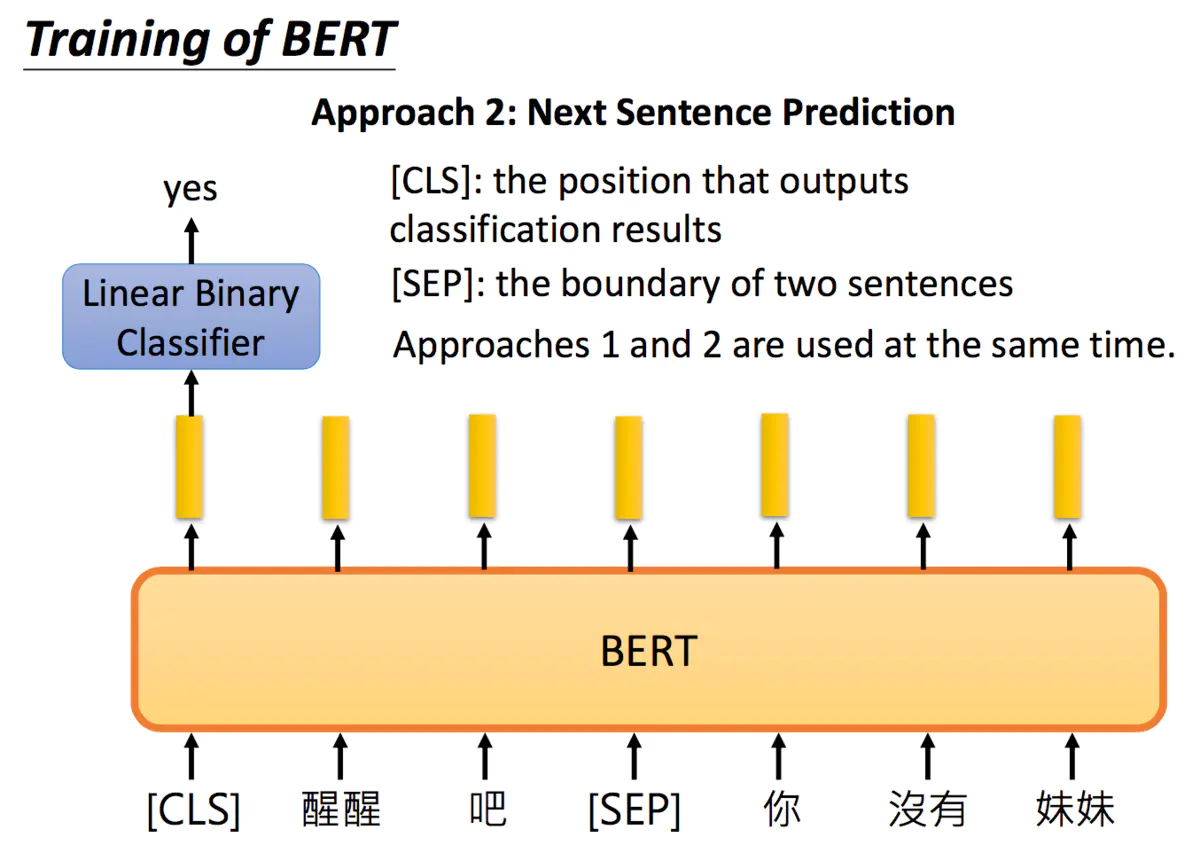
实际中,同时使用两种方法往往得到的结果最好。
在ELMO中,训练好的embedding是不会参与下游训练的,下游任务会训练不同embedding对应的权重,但在Bert中,Bert是和下游任务一起训练的:
如果是分类任务,在句子前面加一个标志,将其经过Bert得到的embedding输出到二分类模型中,得到分类结果。二分类模型从头开始学,而Bert在预训练的基础上进行微调(fine-tuning)。
3.2 bert 的四种应用
bert paper 里说 bert model 和你要做的任务一起做训练
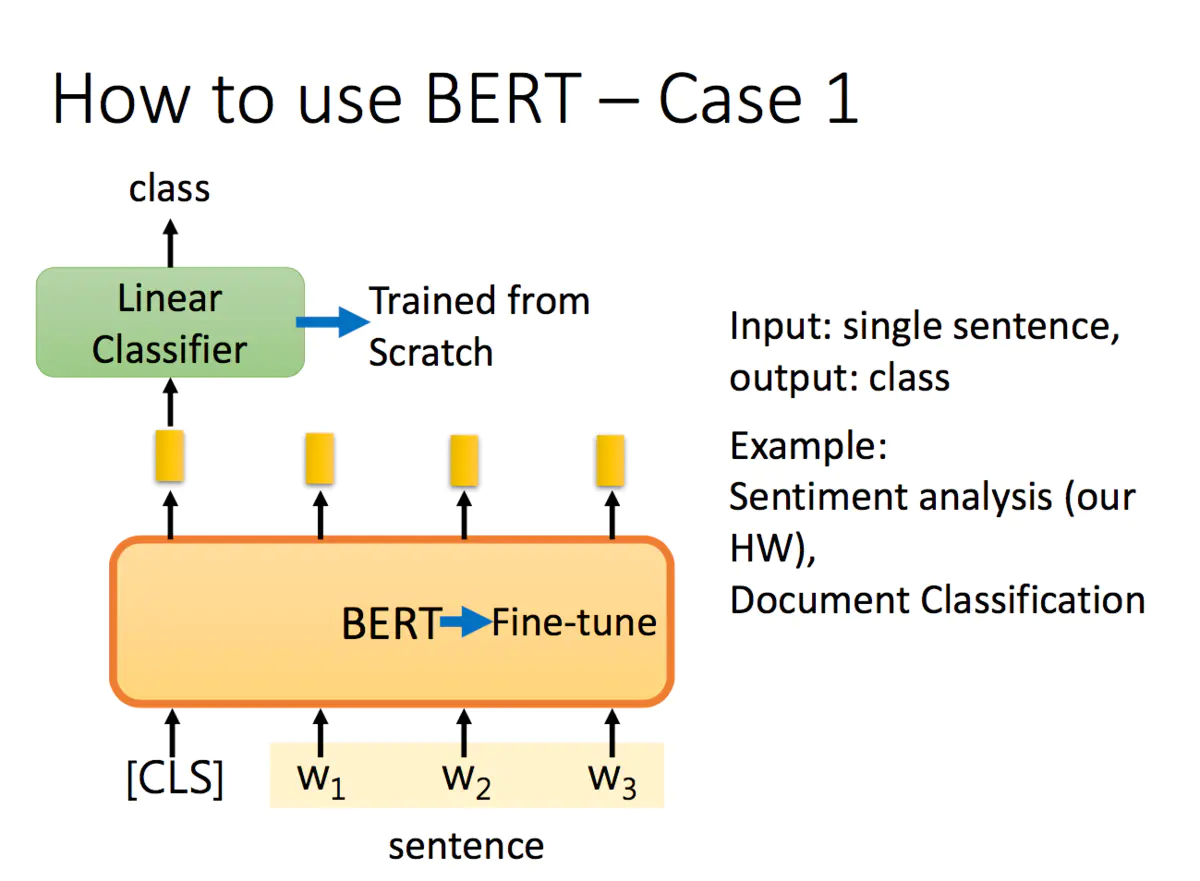
3.2.1 情感分类或文本分类
Linear Classifier 是从头开始学,但是Bert只要做Fine-tune
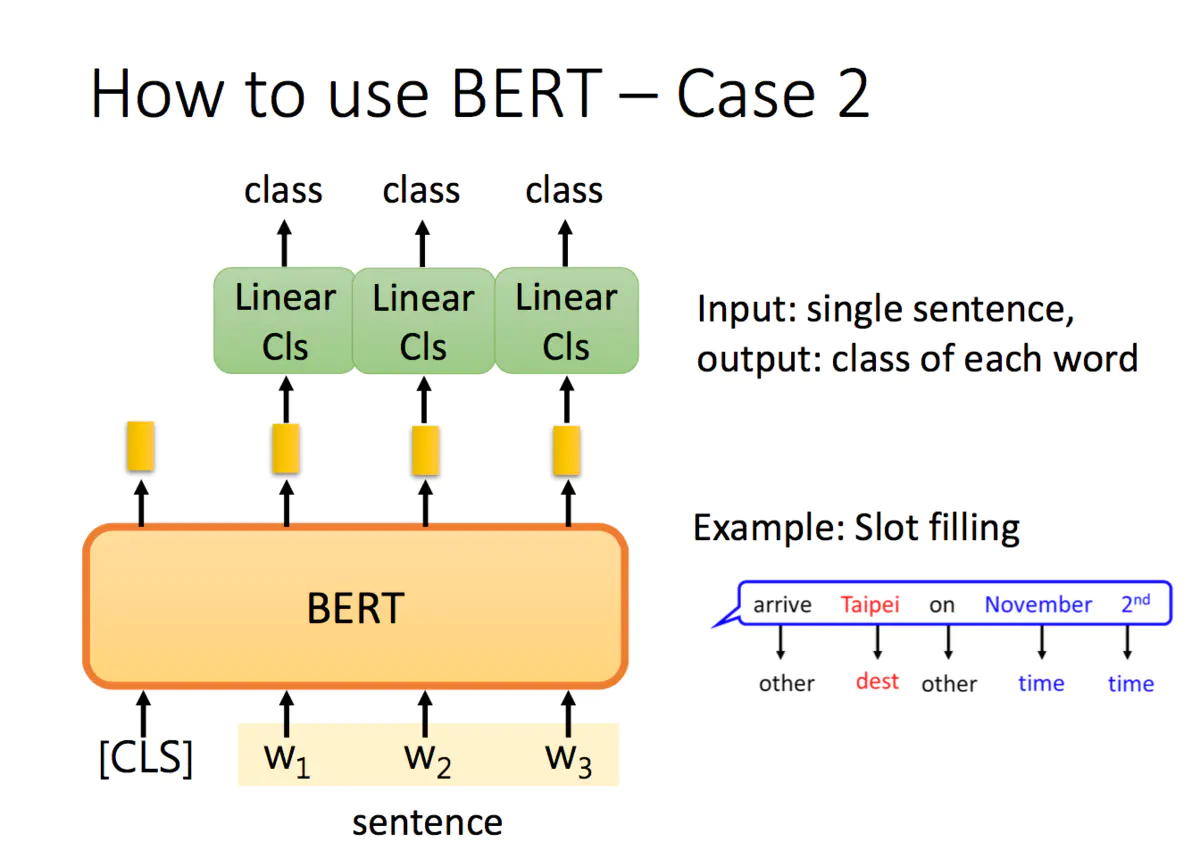
3.2.2 单词分类 – input词是哪个的Slot(other, dest, time)
什么是Slot Filling
比如在一个订票系统上,我们的输入 “Arrive Taipei on November 2nd” 这样一个序列,
我们设置几个槽位(Slot),希望算法能够将关键词’Taipei’放入目的地(Destination)槽位,
将November和2nd放入到达时间(Time of Arrival)槽位,将Arrive和on放入其他(Other)
槽位,实现对输入序列的一个归类,以便后续提取相应信息。
3.2.3 推理是否正确
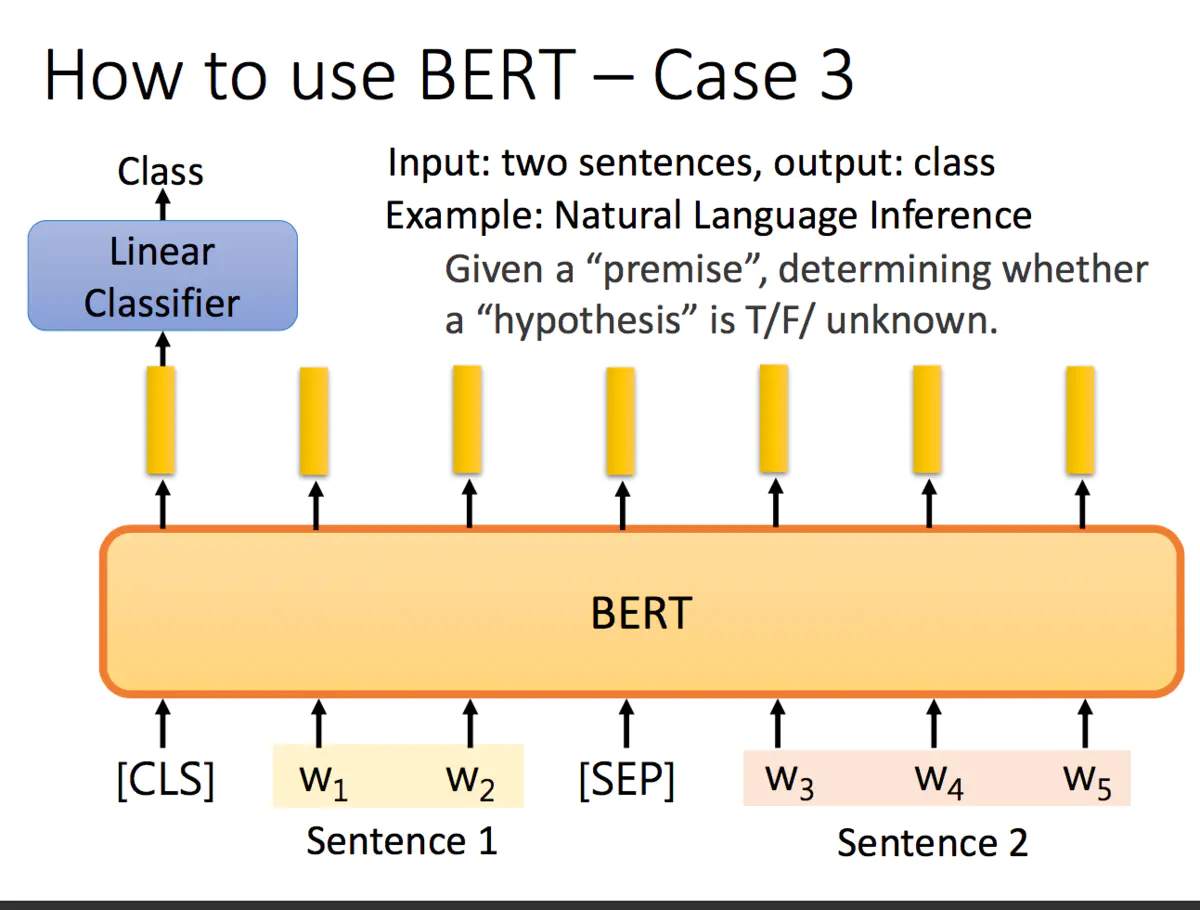
input 两个句子,output 一个Classifier
如自然语言推理任务,给定一个前提/假设,得到推论是否正确 (T/F/unknown):
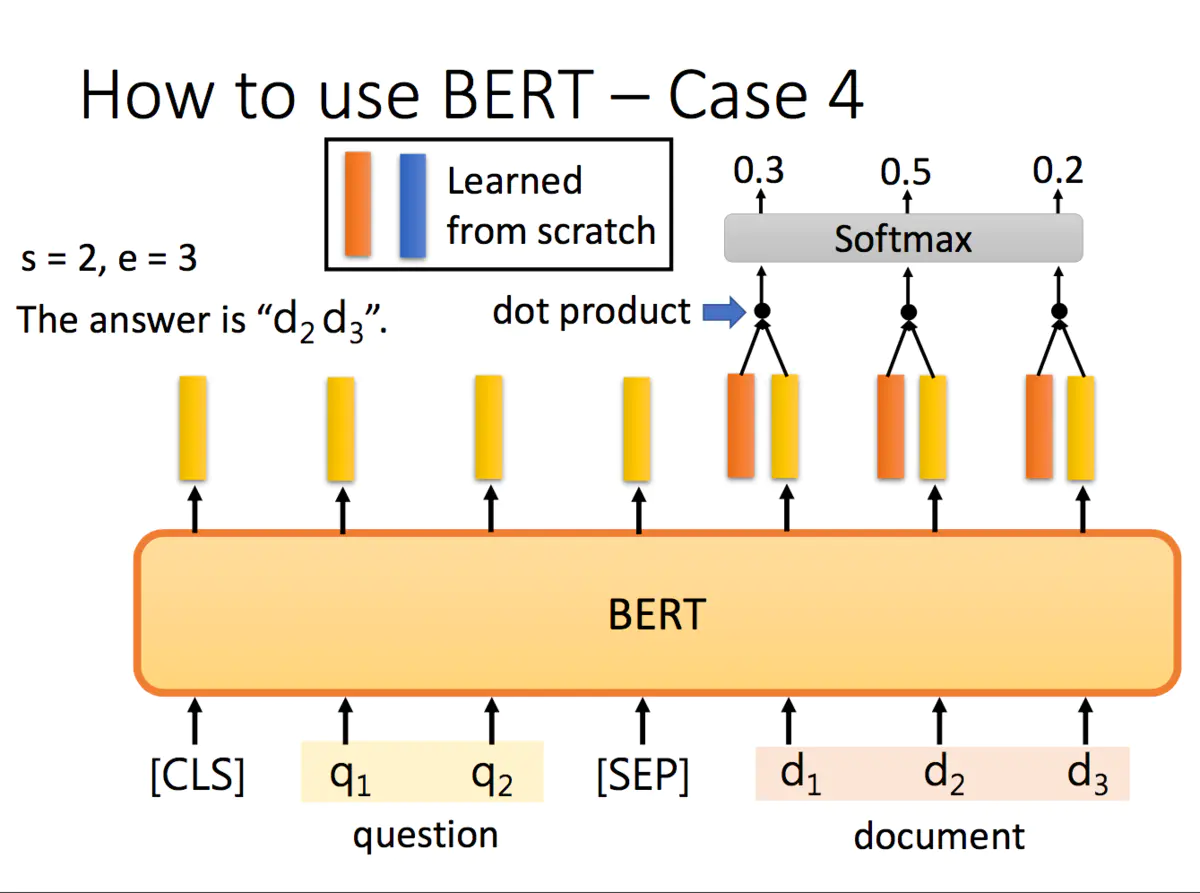
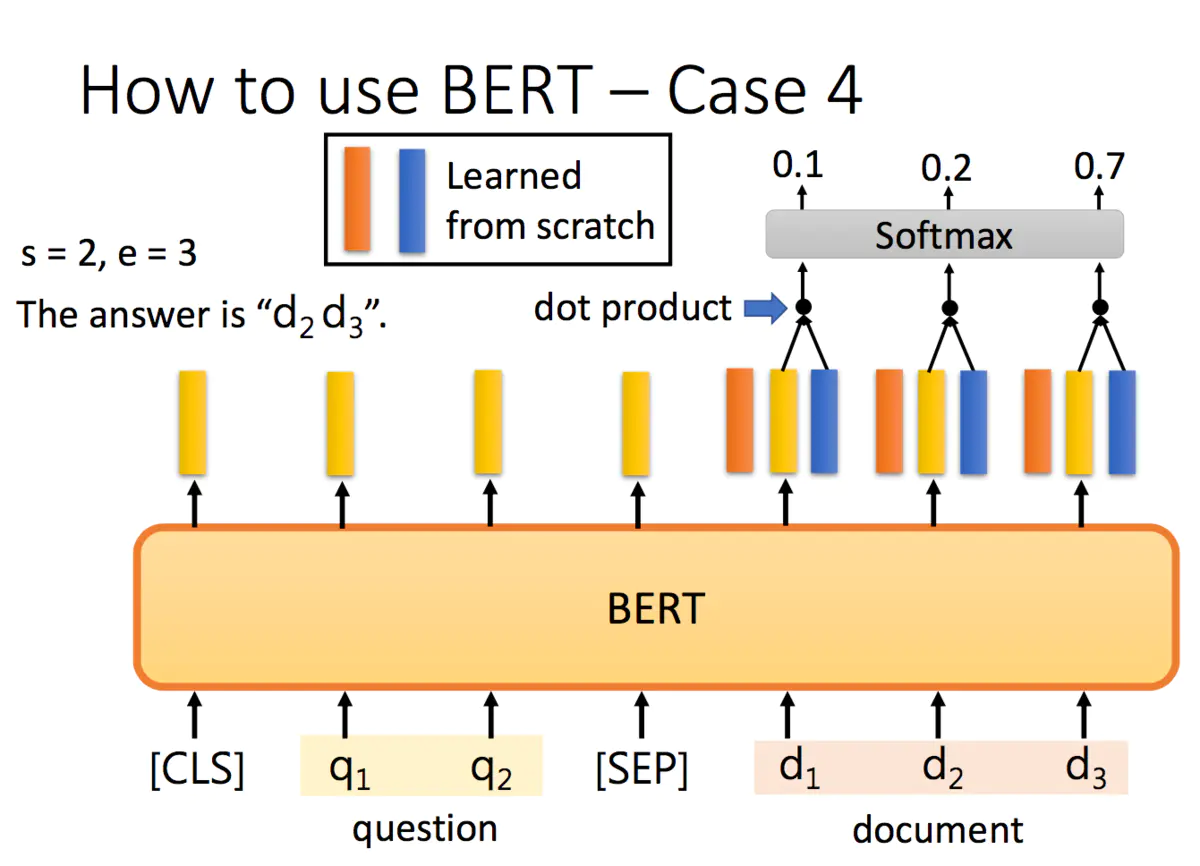
3.2.4 Extraction-based Question Answering(QA) 问答
答案一定在文章里的
input 是Document 文章 和 Query 问题
output: 是 S(Start)和E (End)
最后一个例子是抽取式QA,抽取式的意思是输入一个原文和问题,输出两个整数start和end,代表答案在原文中的起始位置和结束位置,两个位置中间的结果就是答案。

具体怎么解决刚才的QA问题呢?把问题 - 分隔符 - 原文输入到BERT中,每一个单词输出一个黄颜色的embedding,这里还需要学习两个(一个橙色一个蓝色)的向量,这两个向量分别与原文中每个单词对应的embedding进行点乘,经过softmax之后得到输出最高的位置。
正常情况下start <= end,但如果start > end的话,说明是矛盾的case,此题无解。
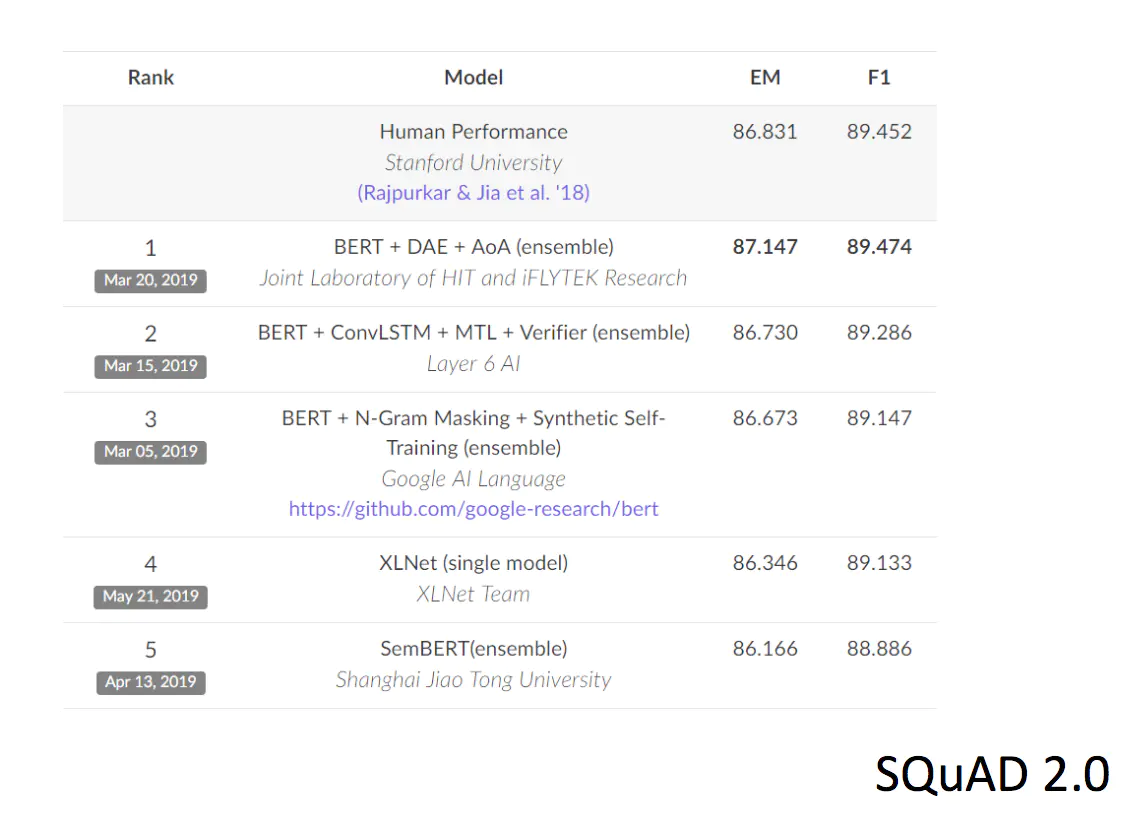
Bert一出来就开始在各项比赛中崭露头角:
这里李宏毅老师还举例了百度提出的ERNIE,ERNIE也是芝麻街的人物,而且还是Bert的好朋友,这里没有细讲,感兴趣的话大家可以看下原文。
ERNIE是百度专门为中文写的
解决的问题,如果是训练中文训练Bert的话,一次盖住一个字,其实是不好,在中文里还是一次盖住一个词比较好

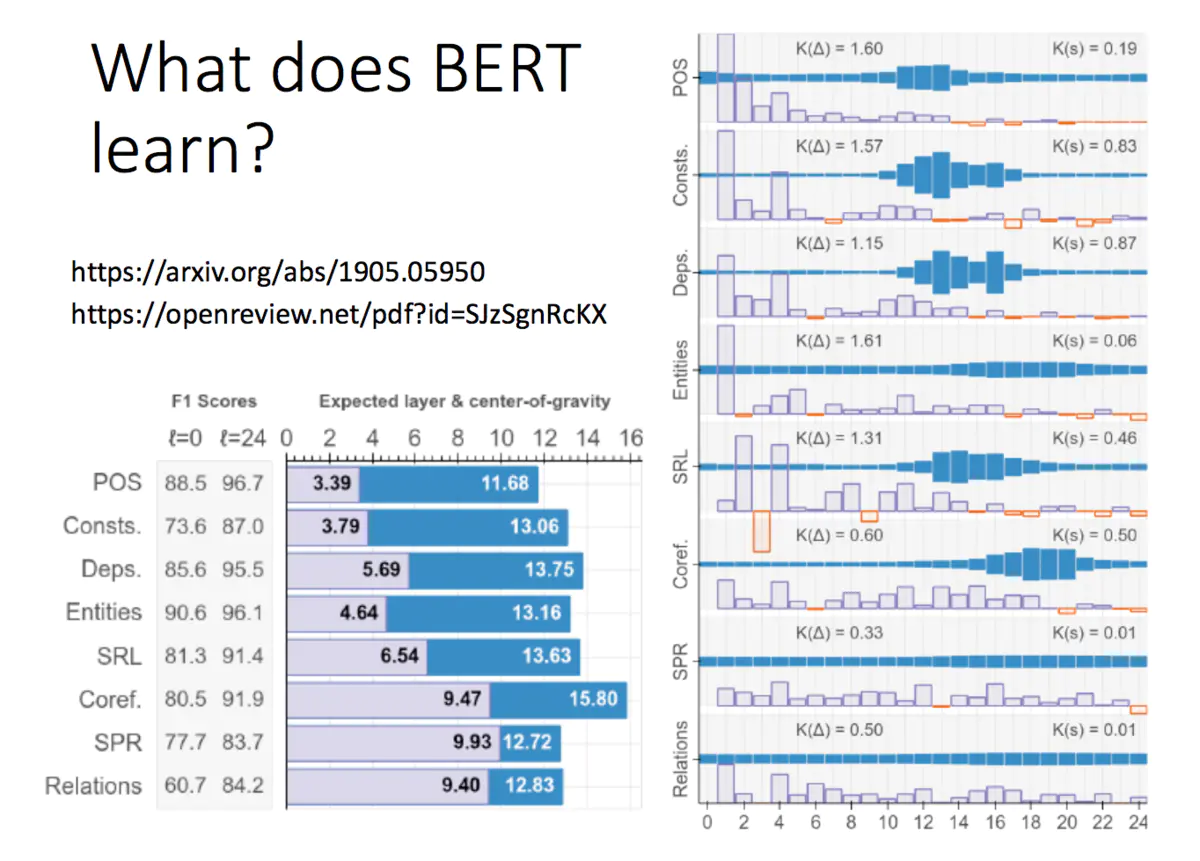
Bert学到了什么呢?可以看下下面两个文献(给大伙贴出来:https://arxiv.org/abs/1905.05950 和https://openreview.net/pdf?id=SJzSgnRcKX):
Bert 有24层, 每一层做了什么呢,
每一层是NPL 里的一个任务
方框多的,那么把它这几层抽出来做这个任务的比较好
4、GPT-2
GPT是Generative Pre-Training 的简称,但GPT不是芝麻街的人物。GPT-2的模型非常巨大,它其实是Transformer的Decoder。

GPT-2是Transformer的Decoder部分,输入一个句子中的上一个词,我们希望模型可以得到句子中的下一个词。
BOS = begin of sentence
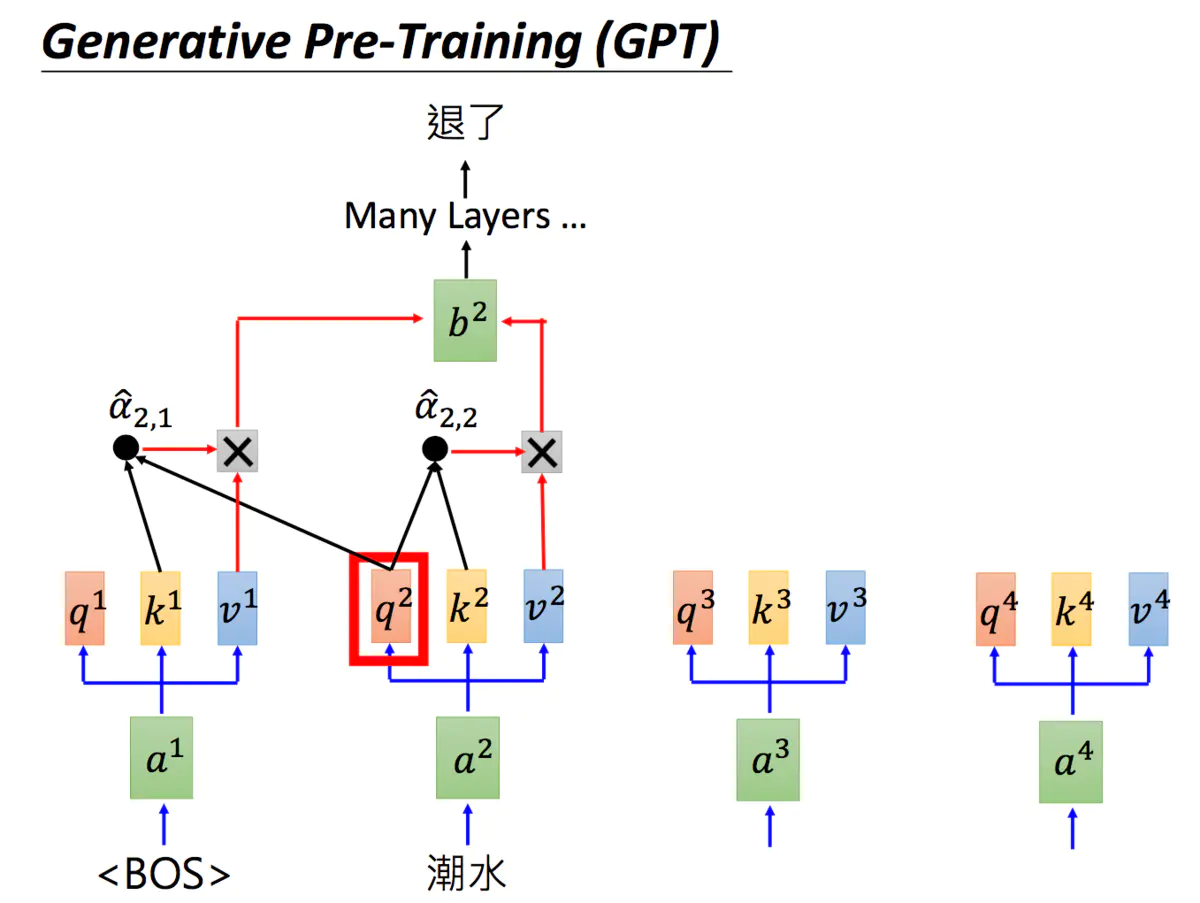
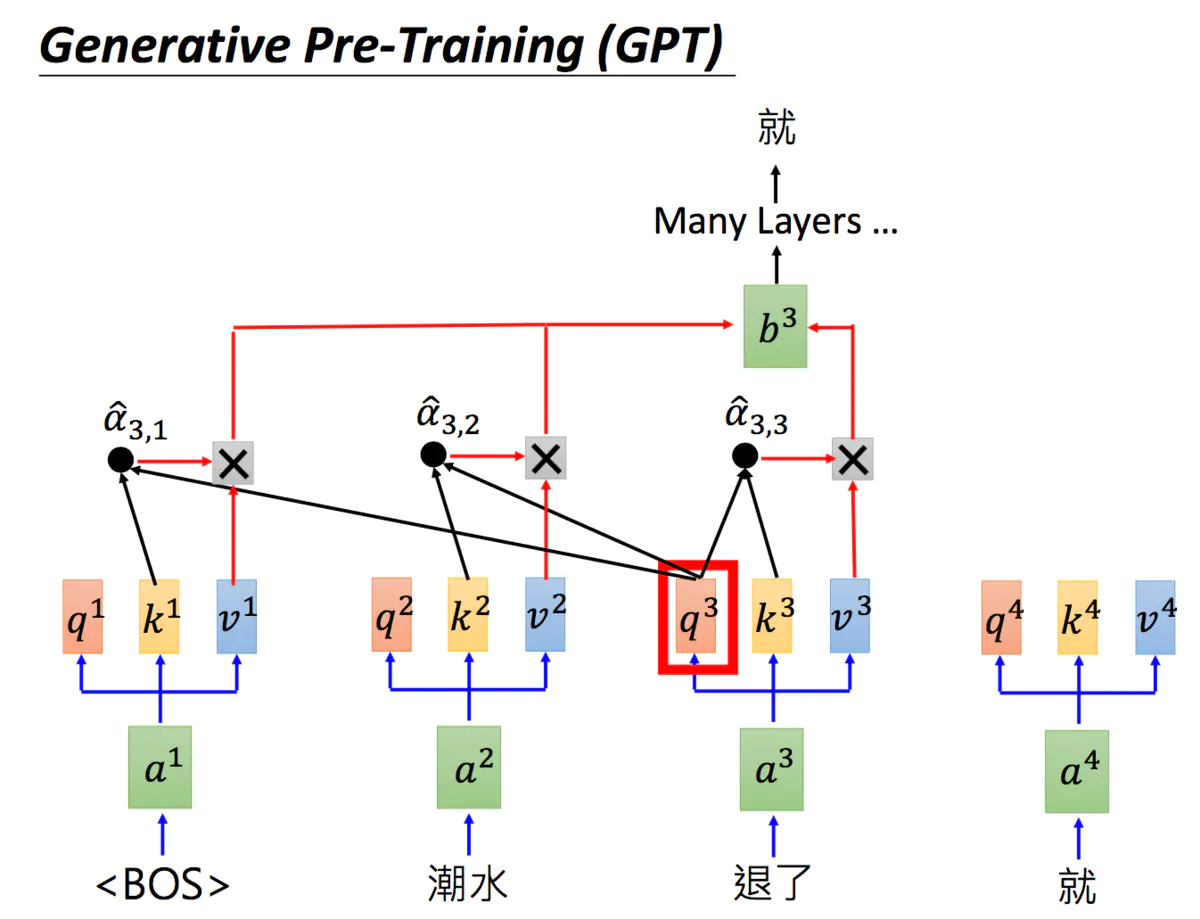
由于GPT-2的模型非常巨大,它在很多任务上都达到了惊人的结果,甚至可以做到zero-shot learning(简单来说就是模型的迁移能力非常好),如阅读理解任务,不需要任何阅读理解的训练集,就可以得到很好的结果。

GPT-2可以自己进行写作,写得还是不错的!

参考资料
https://www.jianshu.com/p/f4ed3a7bec7c
https://github.com/google-research/bert
https://blog.csdn.net/tkkzc3E6s4Ou4/article/details/83629271
https://www.cnblogs.com/zongfa/p/10149483.html
https://www.cnblogs.com/jiangxinyang/p/11114993.html
本文根据李宏毅老师2019最新的机器学习视频整理。
视频地址:https://www.bilibili.com/video/av46561029/?p=61
ppt下载地址:http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML19.html

