
- 1Python机器学习/数据挖掘项目实战 波士顿房价预测 回归分析_波士顿房价分析python中机器学习部分
- 2【故事编程:Lambda表达式】之最甜的巧克力(二)
- 3android rtsp 播放器的论述_android exoplayer2 rtsp报错
- 4AI人工智能 Agent:对生活的影响_agent 大模型能对我们的生活有哪些影响
- 5微信小程序入门三request请求_wx.request 官方文档
- 6SpringCloud全家桶— — 【1】eureka、ribbon、nacos、feign、gateway_将eurekaapplication启动类配置到configurations中
- 7mysql-8.0.27-winx64 zip版 安装_mysql8.0.27安装包
- 8用Coze打造你的AI微信公众号_微秘书对接coze
- 9【路径规划】基于A星算法实现考虑车辆运动和外形约束的路径规划附matlab代码_车辆路径问题车辆类型约束代码
- 10推荐大模型书籍|《从ChatGPT到AIGC:智能创作与应用赋能》_大模型学习推荐书籍
GPT3, llama2, InternLM2技术报告对比_llama的结构与gpt3的区别
赞
踩
GPT3(September 22, 2020)是大语言应用的一个milestone级别的作品,Llama2(February 2023)则是目前开源大模型中最有影响力的作品,InternLM2(2023.09.20)则是中文比较有影响力的作品。
今天结合三篇技术汇报,尝试对比一下这三个方案的效果。
参考GPT3,关于模型(Model and Architectures)的介绍分为了几个部分,包括Training Dataset, Training Process,而InternLM2包括了Pretrain和Alignment,LLama包括预训练,微调和安全。针对这个大致的划分,我们可以对比模型的具体细节效果。
1. 预训练
2. 微调,对齐
2. 模型结构及大小
模型大小
GPT3是175B参数,此外也提供了一些小版本。模型结构与GPT2一致。是一个纯decoder的transformer架构(没有深究了)。
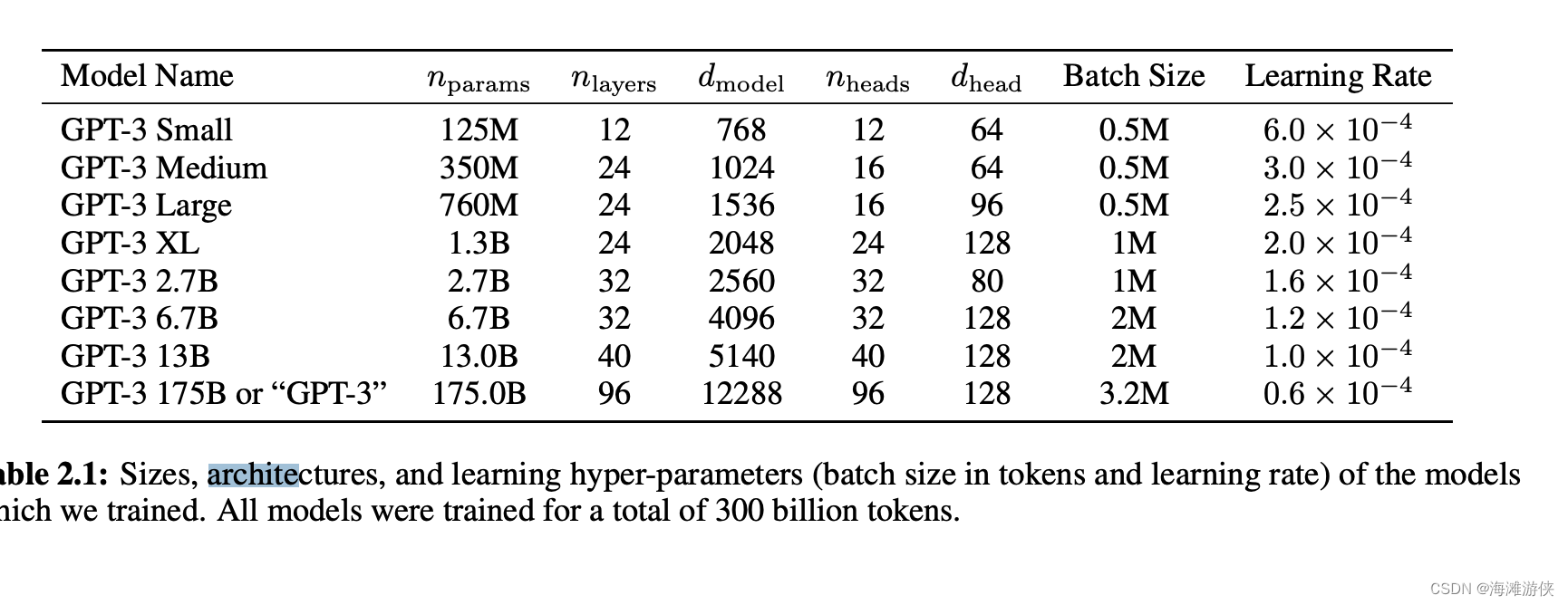
LLama2则是70--700B参数

InternLM2则是1.8B到20B的参数量。

模型结构
GPT-3和GPT-2模型结构一致,都是采用了decoder形式的transformer架构。
LLama2则是基于LLama,增加了Context Length(from 2048 tokens to 4096 token),将Grouped-Query Attention替代MHA(multi-head attention)。
而LLama的架构则是基于Transformer,然后采用了其他方案的改进:RMSNorm(gpt3),Relu -> SwiGLU activation function(PaLM), absolute positional embeddings ->Rotary Embeddings (GPTNeo]),
而 InternLM2技术报告中,强调了它们很大参考了 LLama,但是还做了如下调整。
to better support diverse tensor parallelism (tp) transformations, we have reconfigured the matrix layout. Rather than stacking the Wk , Wq, and Wv matrices in a straightforward manner, we adopt an interleaving approach for each head’s Wk , Wq, and Wv, as depicted in Figure 2.
按我的理解,就是基于qkv三个权重矩阵的合并实现加速。

预训练
GPT-3论文对于训练策略的介绍比较简单,具体可以参考【5】,但是,它强调了pretrain,one-shot,zero-shot这几种任务的难度截然不同,
而关于数据集,主要介绍了Common Crawl dataset,而关于训练策略,不管是正文,还是附录,都没有多余的介绍了。
LLama,它使用English CommonCrawl以及github,wiki等大量数据进行训练。
相比于前两者,InternLM2则详细介绍了数据的准备过程,但是有趣的点,似乎没有。
Tokenize
GPT3使用的tokenize方式为reversible tokenization, 和GPT2一致。·
LLama2的tokenize的方式采用bytepair encoding (BPE) algorithm。训练集包含了1.4T个Token。
InternLM的Tokenize则采用了GPT-4所使用的tokenize方式。
finetune
在GPT-3的论文中强调了finetuning可以增加LLM针对特定任务的表现,但是也会影响模型的泛化性,并且,夸大了它的实际效果。作者把finetune和few shot,one-shot,zero-shot这几种方式对比,fine-tune显然是相对笨拙的方式。即使这样,他依然可以优化在各个场景中llm的效果。在GPT-3中,特定任务的使用都提到了finetune,但是finetune的细节并没有提及,在llama中,finetune也没有看到细节的介绍。而在InternLM中,则有alignment一大个章节来讲述finetune。
其中提到,为了对齐,他使用了 supervised fine-tuning (SFT) 和 reinforcement learning from human feedback (RLHF) 。针对RLHF,具体提出了coolRLHF,值得注意的是,在TR中,有大量篇幅用于介绍coolRLHF这一方案。
参考文档
[1] https://arxiv.org/pdf/2403.17297.pdf
[2] https://arxiv.org/pdf/2005.14165.pdf


