
热门标签
热门文章
- 1太香了!推荐6个Python数据分析神器!!_python 数据分析脚本
- 2检索增强生成(RAG)技术_检索、增强、生成(rag)三个阶段
- 3嵌入式学习路线_嵌入式软件学习路线
- 4iOS开发网络篇—文件下载 通过block回调_ios 多个文件下载
- 5微信小程序onShareAppMessage的promise用法_onshareappmessage promise
- 6三种命名规则之-----骆驼命名法_camel命名法
- 7【南洋理工大学、新加坡机器人学专业协会主办|SPIE出版,往届已见刊检索】 第三届物联网与机器学习国际学术会议(IoTML 2023)_spie 出版社
- 8Spark(29)-Spark Shell及编写Spark独立应用程序_虚拟机spark独立应用程序编程
- 9spark内核解析和调优指南_spark的内核比如何设置
- 10Hive 常用函数总结_hive contract
当前位置: article > 正文
Prompt-Free Diffusion: Taking “Text” out of Text-to-Image Diffusion Models
作者:运维做开发 | 2024-07-12 09:38:13
赞
踩
Prompt-Free Diffusion: Taking “Text” out of Text-to-Image Diffusion Models
- 问题引入
- 在SD模型的基础之上,去掉text prompt,使用reference image作为生成图片语义的指导,optional structure image作为生成图片structure的指导来进行生成;
- 使用SeeCoder来提取参考图片的embedding作为生成条件,且SeeCoder是可以重复使用的,可以直接集成到另外的T2I模型中;
- methods
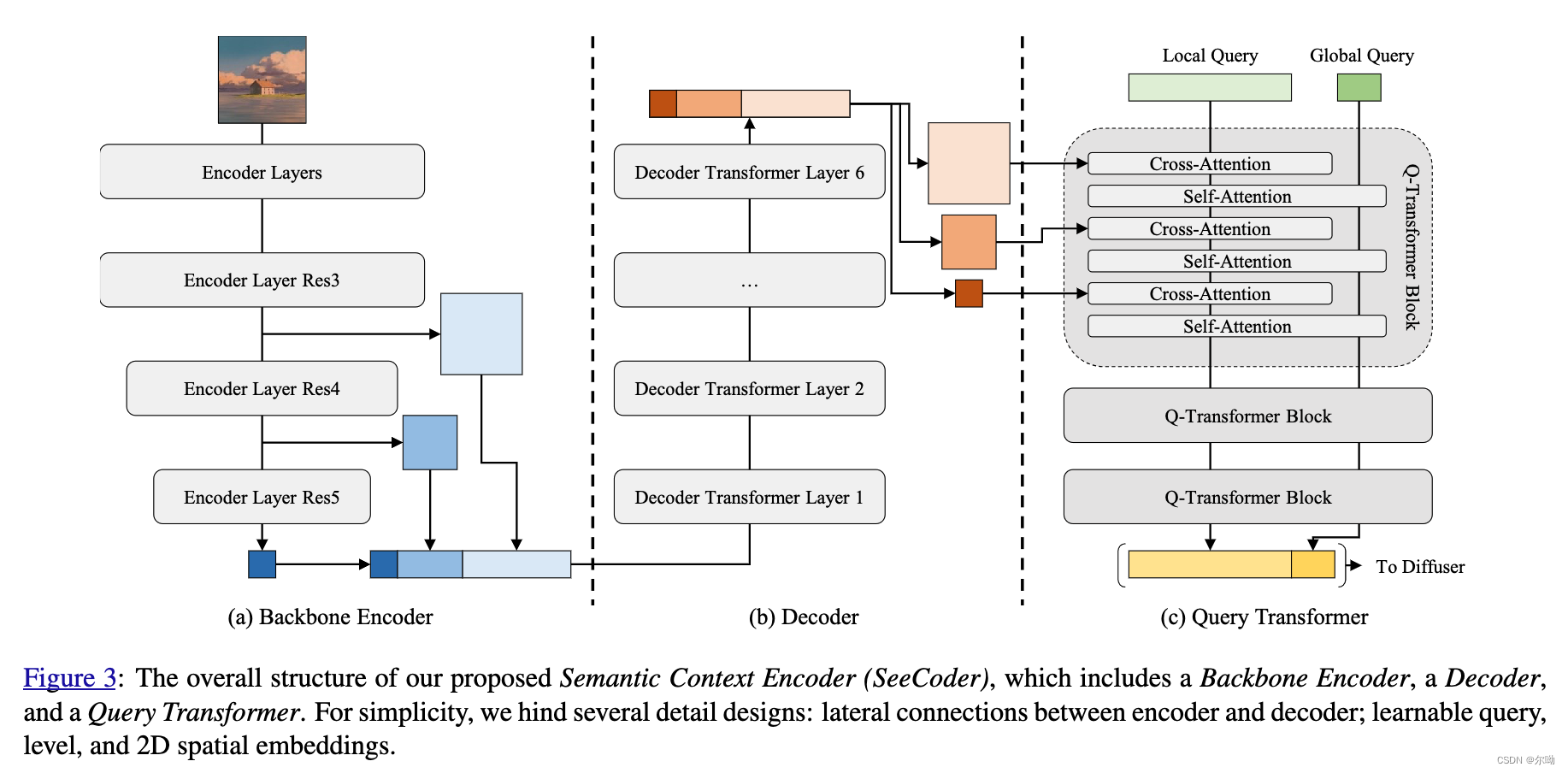
- 使用SeeCoder代替CLIP text embedding;
- SeeCoder包含三个部分,Backbone Encoder, Decoder, and Query Transformer,其中Backbone Encoder使用SWIN-L提取多尺度特征,该部分参数是冻结的;之后decoder使用卷积来使得多尺度特征通道数相同,然后进行flatten+concat,得到的结果通过self attn + ffn;之后Query Transformer输出视觉embedding;
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/运维做开发/article/detail/813374?site
推荐阅读
相关标签

