- 1什么是RPC?有哪些RPC框架?
- 2R9000P2021版拯救者 装ubuntu系统相关问题(WiFi、蓝牙、亮度调节,驱动安装)记录总结_r9000p重装蓝牙
- 3解决Spring Boot应用中的内存优化问题
- 4搭建hadoop+spark完全分布式集群环境
- 5软件测试除了做好功能测试自动化测试之外,如何在职位上获得提升?_测试工程师除了功能测试还能做什么
- 6BERT参数计算,RBT3模型结构
- 7Android Studio运行项目_android studio怎么运行当前项目csdn
- 8量化机器人能否实现多资产交易?
- 9深度学习环境配置_ubuntu18及以上_nvcc fatal : failed to preprocess host compiler pr
- 10数据库逻辑设计 完全函数依赖、部分函数依赖、传递函数依赖、码、候选码、主码、范式_数据库部分函数依赖
使用Yolov4训练自己的数据集
赞
踩
一、什么是Yolov4?
YOLOV4是一种目标检测算法,是YOLO(You Only Look Once)系列的最新版本。YOLO算法通过将目标检测任务转化为一个回归问题来实现实时目标检测,它将图像划分为网格并在每个网格中预测边界框及其相关的类别概率。YOLOV4相比之前的版本具有更高的检测精度和更快的检测速度,它采用了一系列的改进和优化,包括网络结构的改进、损失函数的优化、数据增强的策略等。YOLOV4在计算机视觉领域得到了广泛的应用,在实时目标检测、视频分析、自动驾驶等领域具有重要的意义。
二、数据准备
数据准备是指在进行机器学习或深度学习任务之前,对数据进行收集、清洗、标注、划分等处理的过程。以下是数据准备的一般步骤:
水果分类目标检测VOC数据集_数据集-飞桨AI Studio星河社区
1.划分数据集
我们选用的水果数据集是已经标注好的,所以后续不用再对数据进行标注,可直接划分数据集。
我们是一个Annotations文件夹放标签,一个ImageSets文件夹放图片
2.处理数据集
训练自己的数据集时xml标签文件放入VOCdevkit文件夹下的VOC2007文件夹下的Annotation文件夹中
jpg图片文件放在VOCdevkit文件夹下的VOC2007文件夹下的JPEGImages文件夹中
我们都是png格式的图片,转换成jpg格式,这里我们借鉴了csdn上的博客冰万森的代码,感谢冰万森的支持,代码如下:
from PIL import Image
import os
# 设置源文件夹和目标文件夹
source_folder = '这里是需要转换的文件夹路径'
target_folder = '这里是转换输出的文件夹路径'
# 检查目标文件夹是否存在,如果不存在则创建
if not os.path.exists(target_folder):
os.makedirs(target_folder)
# 遍历源文件夹中的所有文件
for file_name in os.listdir(source_folder):
if file_name.endswith('.png'):
# 读取PNG图片
img_path = os.path.join(source_folder, file_name)
img = Image.open(img_path)
# 转换为JPEG
rgb_im = img.convert('RGB')
# 保存JPEG图片
target_file_name = file_name[:-4] + '.jpg'
target_img_path = os.path.join(target_folder, target_file_name)
rgb_im.save(target_img_path, 'JPEG')
# 删除原始PNG图片
os.remove(img_path)
print("转换并删除原始PNG图片完成!")
三、环境准备
1.环境内容
电脑硬件配置
-
处理器:通常搭载英特尔(Intel)或者 AMD 的处理器,如英特尔第十代酷睿i5 或 i7 处理器,或者 AMD Ryzen 5 或 Ryzen 7 处理器。
-
内存(RAM):通常具有 8GB 或 16GB DDR4 内存,但也可能有更高容量的配置选项。
-
存储:通常提供 256GB 或 512GB 的固态硬盘(SSD)作为主要存储设备,但也可能有不同容量的选项。
-
显卡:一般集成显卡,如英特尔集成显卡或者 AMD Radeon 集成显卡。某些配置可能会搭载独立显卡,如 NVIDIA GeForce MX350。
-
屏幕:14 英寸全高清(1920x1080)IPS 显示屏,具有窄边框设计,提供良好的视觉体验。
-
连接接口:通常具有多个连接接口,如 USB 3.0/3.1 接口、USB-C 接口、HDMI 接口、耳机/麦克风组合接口等。
-
无线连接:支持 Wi-Fi 和蓝牙连接。
-
电池:通常具有 3 或 4 芯电池,提供较长的续航时间。
-
操作系统:预装 Windows 10 操作系统,但也可能有 Linux 或其他操作系统的选项。
2.环境配置
我们用的环境是python 3.9
四、训练数据
1.运行voc_annotation.py
voc_annotation.py 是一个用于创建VOC格式(PASCAL VOC格式)标注文件的 Python 脚本。PASCAL VOC格式是一种常用的图像数据集标注格式,通常用于对象检测和图像分割任务。这个脚本的作用是帮助用户将图像数据集的标注信息整理成符合VOC格式的 XML 文件。
通常,voc_annotation.py 的功能包括:
-
读取标注文件:该脚本可以读取已有的标注文件,比如包含对象类别和位置信息的文本文件或者数据库文件。
-
解析标注信息:解析图像数据集中每张图像的标注信息,包括对象的类别、位置(边界框的坐标)等。
-
生成XML文件:将解析得到的标注信息按照VOC格式的要求,生成对应的XML文件。这些XML文件包含了图像的文件名、宽高信息以及每个对象的类别和位置信息。
-
标注数据集准备:通过生成符合VOC格式的XML文件,为后续的模型训练提供了方便。许多深度学习框架(如TensorFlow、PyTorch等)都支持使用PASCAL VOC格式的数据集进行模型训练,因此这个脚本有助于准备训练所需的数据集。
如果你有一个图像数据集,希望用于对象检测或者其他视觉任务的训练,可以使用这个脚本来整理数据集并生成相应的标注文件,以便后续的模型训练和评估。要使用该脚本,通常需要提供图像文件路径、标注文件路径以及输出XML文件的保存路径等参数。
2.运行train.py
要运行 train.py 脚本,通常需要知道这个脚本是做什么的,以及它所需的输入参数或配置文件。在运行 train.py 脚本之前,你需要确保你已经安装了脚本所依赖的库和框架,并且已经准备好了训练所需的数据集、模型配置文件等。
-
确定任务和模型:首先要确定你要进行的任务,比如图像分类、对象检测、语义分割等,以及你要使用的模型架构,比如ResNet、YOLO、Mask R-CNN等。
-
准备数据集:确保你已经准备好了用于训练的数据集,包括训练集、验证集和测试集,并且数据集的格式符合模型的要求。
-
配置训练参数:通常需要配置训练所需的参数,比如学习率、批量大小、训练轮数等。
-
运行脚本:根据脚本的要求,提供正确的输入参数或配置文件,并运行
train.py脚本。
在train.py中修改路径运行
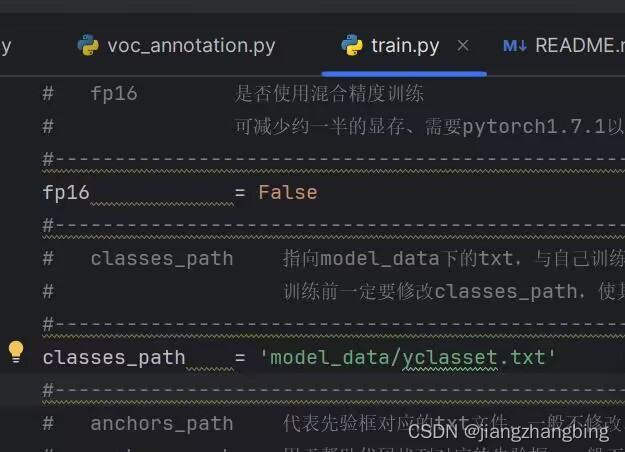
然后在yolo.py中修改相关函数

运行结果如下
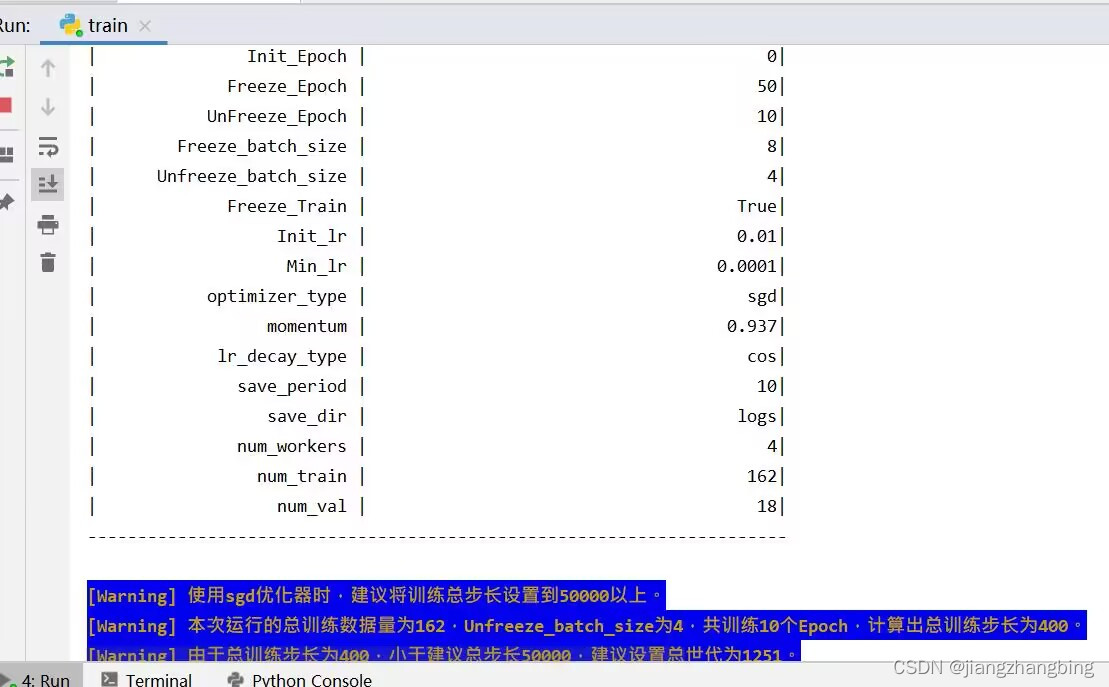
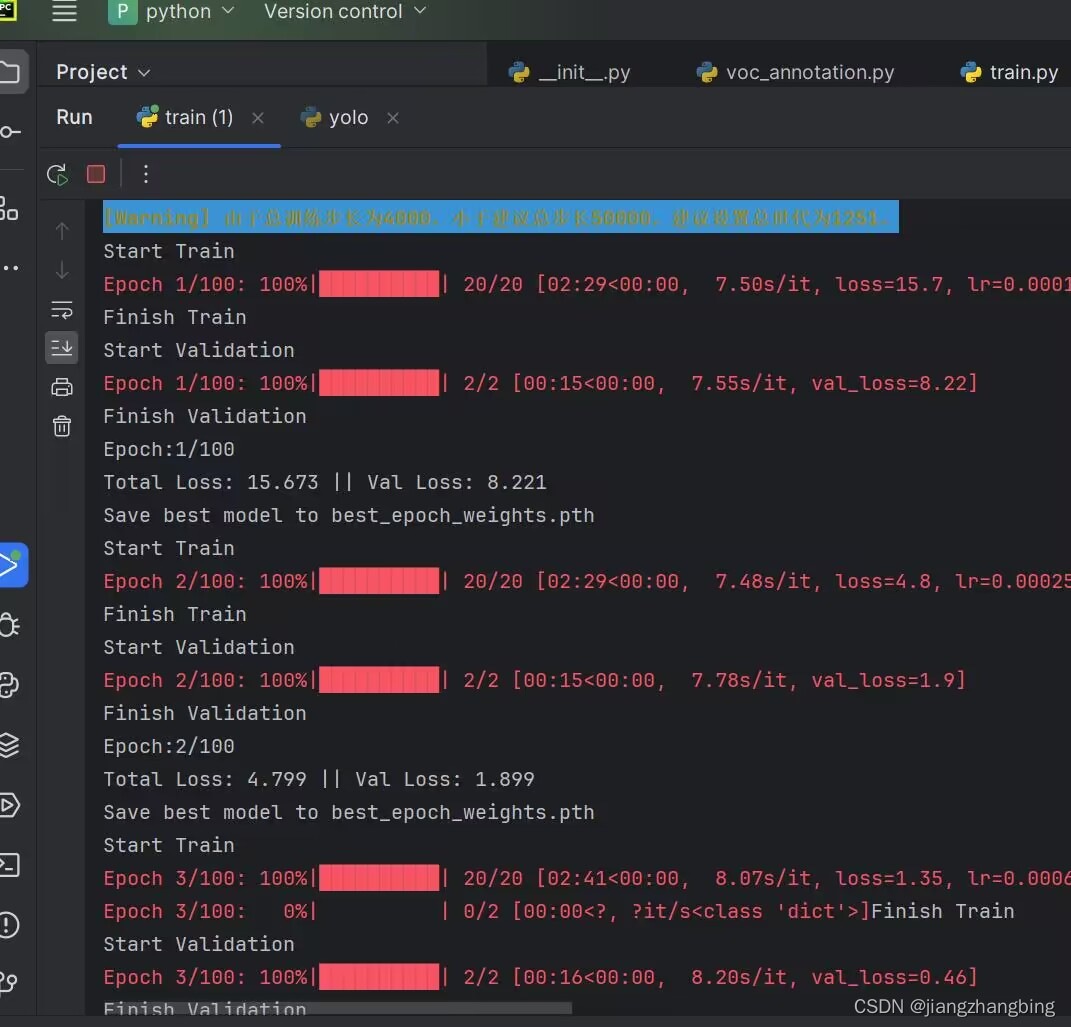
运行 train.py 的作用通常是训练机器学习或深度学习模型。具体来说,它可以用于以下用途之一或多个:
-
模型训练:通过提供训练数据集,
train.py可以使用所选择的机器学习或深度学习算法来训练模型。这可能涉及调整模型的参数以最小化损失函数,以便模型能够更好地拟合数据并提高性能。 -
参数调优:通过尝试不同的参数组合或超参数值,
train.py可以进行参数调优,以获得最佳模型性能。这可能包括调整学习率、优化器、正则化参数等。 -
模型评估:在训练过程中,
train.py可以定期评估模型的性能,并在必要时进行调整。这可能包括在验证集或测试集上计算准确率、精确率、召回率、F1分数等指标。 -
保存模型:一旦训练完成,
train.py可以保存训练好的模型,以便将来进行推断或部署。 -
迁移学习:在某些情况下,
train.py可能还支持迁移学习,即使用预训练的模型权重作为起点,然后在新的数据集上进行微调以适应特定任务。
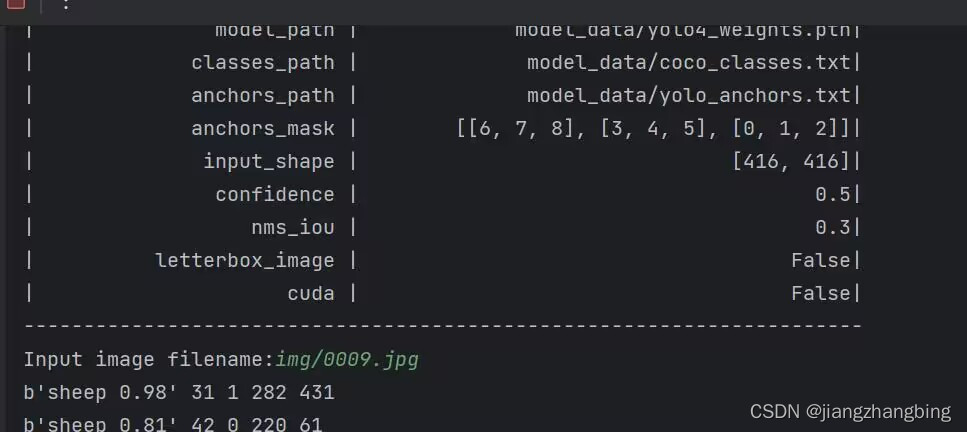
3.运行predict.py
修改predict.py里的图片输入路径
五、成果展示
训练结果