
- 1git——github篇_github draft a new release
- 2node爬虫、前端爬虫_node crawler 获取网页后传给前端
- 3java实现单链表上的插入、删除、查找、修改、计数、输出等基本操作_单链表重复字符的统计
- 4进入AI领域做产品 —— 我的自学之路(CV-人脸识别)_粗略人脸识别需要多少算力
- 5IDEA中Git的提交、更新、还原_idea git更新代码到本地
- 6javaagent学习_java agent学习
- 7基于LLM+TTS+Lip-Sync的流式数字人的问答系统框架_llm tts
- 8修改元素内容改值,表单改值, 获取/失去焦点,鼠标移动离开不会冒泡的方式,通过样式让滚动条丝滑滚动_失去焦点修改标签属性
- 9DNS域名解析服务— — —DNS分离解析_windowsdns分离解析
- 10BASE64Encoder_base64encoder.encode(
HTTP请求协议格式详解_请求头格式
赞
踩
请求协议格式
HTTP请求协议由首行、请求头(header)、空行、正文(body)组成。通过空行来区别header和body,body可有可无,若body存在,则在header中会定义一个content-length属性来标识body的长度。

1. 首行
首行 = 方法 + URL + 版本号
1.1 URL
一个完整的URL包括:
协议://主机名(域名):端口号/路径/查询字符串query string
以一个比较复杂的URL做例:
https://www.example.com:80/path/to/myfile.html?key1=value1&key2=value2#anchor
https://协议名www.example.域名,等价于IP地址,能够表示一个网络上的主机com:80端口号为80,一般情况下端口号都会省略。当端口号省略时,浏览器会根据协议类型自动决定使用哪个端口。默认情况下HTTP协议使用80端口,HTTPS协议使用443端口。- /path/to/myfile.html 带层次的文件路径,用于定位到程序管理的资源。
- key1=value1&key2=value2#anchor
❓后面的都是查询字符串query string,其本质是一个键值对结构,用于在请求中带上一些参数信息,传递给服务器。 - 片段标识,该URL中省略了片段标识,其主要用于页面内跳转。
以上URL中的各部分,皆可以省略。
1.2 方法
HTTP首行的方法种类较多,但常用的只有前两个,下面也只详细介绍GET和POST方法。
如下的表格列举了各方法以及其功能,但是直到今天为止,程序员对于各种方法已经用的随心所欲,而不考虑其功能了,所以具体这个方法起到了什么作用,还是要根据程序员的代码进行分析~毕竟大家都这么用也不能算是错误用法,只能说目前都习惯这么随便用吧。
| 方法 | 说明 |
|---|---|
| GET | 获取资源 |
| POST | 传输实体主体 |
| PUT | 传输文件 |
| HEAD | 获得报文首部 |
| DELETE | 删除文件 |
| OPTIONS | 询问支持的方法 |
| TRACE | 追踪路径 |
| CONNECT | 要求用隧道协议链接代理 |
| LINK | 建立和资源之间的联系 |
| UNLINE | 断开连接关系 |
1.2.1 GET方法
GET方法是最常见的HTTP请求,一般有以下几种情况可能触发GET方法的请求。
- 浏览器中输入URL回车 ( 浏览器收藏夹中的链接也是同样的效果)

- HTML中含有地址的一些标签
- img标签中的src属性就可以写一个URL,浏览器会根据img中的src构造出一个HTTP GET请求;
- a标签中的href属性,也可以通过出点击网页中的a标签,构造出对应的HTTP GET请求;
- 使用JS,直接在浏览器前端构造出HTTP GET 请求(ajax);
<script src="https://code.jquery.com/jquery-3.6.0.min.js"></script>
<script>
$.ajax({ //异步
url:'http://42.192.83.143:8089/AjaxMockServer/info',
method:'GET',
//回调函数
success:function(data,status){
console.log(data);
console.log(status);
}
});
</script>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 其实只要是能够访问网络的编程语言,都能构造出HTTP GET请求;
GET 方法的特点
- 首行中第一个是GET;
- URL中的query string 可以为空,也可以不为空;
- GET请求中有若干组header这样的键值对;
- GET请求一般body都为空;
1.2.2 POST方法
一般登录页面中会触发POST请求,输入了用户名以及密码后,点击登录,就会产生POST请求。

如上图例子所示,我们可以观察总结出POST请求的特点。
POST方法的特定
- 首行中第一个是PST;
- URL中的query string一般是没有的;
- GET请求中有若干组header这样的键值对;
- GET请求一般body都不为空。其中,body的具体长度由header中的Content-Length来描述,body的具体数据格式由header中的Content-Type来描述;
[经典面试题] GET方法与POST方法的区别?
两者没有本质区别~使用GET的场景,完全可以使用POST替代,使用POST的场景也一样可以使用GET替代。
- 语义不同。GET习惯上用于从服务器上获取数据,POST是向服务器传送数据。
- 格式不同。由于body一般是空的,所以GET习惯上通过query string 来传输数据;而POST方法的query string 一般为空,所以POST习惯上使用 body 来传递数据。
- . 幂等性。一般情况下,程序员会把GET请求的处理实现成幂等,而POST请求的处理,不要求实现幂等。
幂等:一次和多次请求某一个资源对于资源本身应该具有同样的结果(网络超时等问题除外)。也就是说,其任意多次执行对资源本身所产生的影响均与一次执行的影响相同。例如我通过网上银行支付一笔订单,但由于该时间段在线人数过多或网络不好,我支付了以后就卡在这个页面没有成功,此时若我重复提交支付操作,也只扣了一次费用,没有产生额外的负面效果,则说明该网页设计具有幂等性。
- 缓存。GET请求可以被缓存,可以被浏览器把偶才能到收藏夹中,而POST请求不可。
1.2.3 其他方法
其他方法就是上述表中列举的一些,仅作了解即可,常用的还是GET和POST。
2. 请求头
请求头是由若干个键值对的结构组成的,每个键值对独占一行,使用冒号分割键与值,遇到空行表示header部分结束。
2.1 Host
Host表示该请求所对应的服务器的地址,地址可以是域名,可以是IP地址,也可以手动指定端口号。
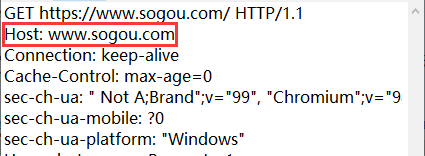
2.2 Content-Length
Content-Length表示body的长度,单位是字节。GET中一般没有body,所以抓包POST请求才能看到该header。
2.3 Content-Type
Content-Type表示body的格式。同上,只有该请求是POST时,才会带上Content-Length和Content-Type这来给你个header。
Content-Type 常见取值:
- application/x-www-form-urlencoded;
form 表单提交的数据格式. 此时 body 就是用类似于query string这样的格式来进行组织。 - multipart/form-data;
使用HTML时提交图片/文件时,会出现种格式。 - application/json;
数据为 json 格式,body格式形如下方的键值对形式。键值对之间使用 逗号 分割,键与值之间使用 冒号 分割。
{"title":"test","sub":"测试"}
- 1
2.4 User-Agent / UA
UA表示浏览器 / 操作系统的属性。形如
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36
- 1
其中,Windows NT 10.0; Win64; x64 表示操作系统是Windows 10,64位系统;
Chrome/91.0.4472.77 Safari/537.36说明了当前的浏览器以及浏览器版本。
2.5 Referer
Referer表示该页面是从哪个页面跳转过来的。如果直接在网址中输入URL回车抓到的包是没有Referer的。
2.6 Cookie
下面是抓到一个报文格式中的Cookie细节。不难发现,Cookie中也是由若干的键值对结构组成的,每个键值对之间使用;分割,键与值之间之用= 分割。至于键值对所表示的含义,是由网站开发的程序员自定义的。
Cookie: runoob-uuid=a07ab814-1920-4f66-9a2d-e00074f33900; _ga=GA1.2.2125547423.1646032953; _gid=GA1.2.65496705.1646032953; __gads=ID=3b377f2a9b5979bd-224586d1c5d00004:T=1646032953:RT=1646032953:S=ALNI_MYYASEYH9bJmBounu7Wpcb9tMqm4A; _gat_gtag_UA_84264393_2=1; Hm_lvt_3eec0b7da6548cf07db3bc477ea905ee=1646032953,1646043712,1646043717; Hm_lpvt_3eec0b7da6548cf07db3bc477ea905ee=1646043717
- 1
Cookie的作用
首先我们需要明确的是,浏览器为了保证安全性,是允许网页中的代码读写浏览器所在的主机的硬盘的。但是有些时候我们又确实需要存储一些必要的数据,比如网页的登陆页面,现在绝大多数网站都可以做到首次登录,后面会记住登录状态无需次次登录,那么用户的账户信息是如何存储的呢?
Cookie的作用就是给程序员提供了一种能在本地存储数据的能力。
虽然浏览器不允许程序员读写客户端的文件,但是提供了Cookie这样的机制,按照键值对存储,来代替直接访问文件。而Cookie中存储的内容是由浏览器管理的,会持久化存在~除非手动清楚。
清楚历史Cookie中存储的数据
按照下图中的方式,点击浏览器网址栏左边的小锁会打开Cookie,按照域名分文件存储。若是把相关的Cookie存储的数据全部删除,那么这个网址就会和首次访问是一样的状态,用户信息等等全部清空。

如何向Cookie中存储数据?
下面的例子中浏览器清楚了Cookie存储的数据后重新访问搜狗主页,可以看到请求中的Cookie对应的就是网页中的相应的数据。

Cookie工作原理?
Cookie会在后续的请求中,将存储在浏览器本地的数据发送给服务器~具体工作流程如下:


