
- 1mysql8.0.18相关配置_mysql8.0.18配置文件
- 2STM32 相关RTOS_stm32与rtxrots
- 3TypeError: argument of type ‘int‘ is not iterable_typeerror: argument of type 'int' is not iterable
- 4安全防御:防火墙基本模块
- 5Java在字符串中查找匹配的子字符串_java string匹配子串
- 6用故事绘就生活:探索星火绘镜Typemovie的艺术魅力
- 7什么是真正的敏捷开发?敏捷开发与瀑布开发有何不同_敏捷开发 ccb
- 8子查询(嵌套查询)——MySQL_mysql子查询执行顺序
- 9Android移动应用开发课程设计(基于Android Studio的音视频播放系统设计与实现)_android studio课设
- 10都快2023年了,入行软件测试是不是晚了?_白驹自动化测试平台
目标检测算法之RT-DETR_rt-detr代码
赞
踩
Background
Real-time Detection Transformer(RT-DETR)是一个基于tranformer的实时推理目标检测模型。RT-DETR是2023年百度发布的一个新目标检测模型,它兼顾了速度和精度俩个特性,在速度上超越yolo,同时仍保持不低于yolo模型的精度。其分别从encoder部分、query选择俩个方面进行改进,保持了模型的精度,同时提高了模型的推理速度。
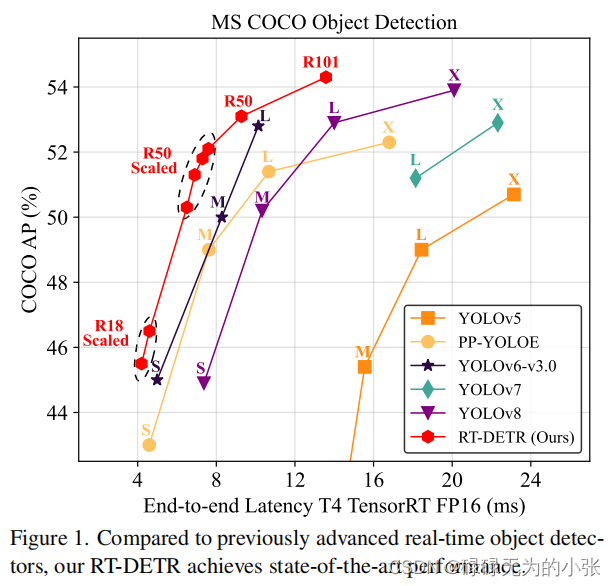
论文地址:https://arxiv.org/pdf/2304.08069
代码地址:https://github.com/lyuwenyu/RT-DETR
Model Architecture
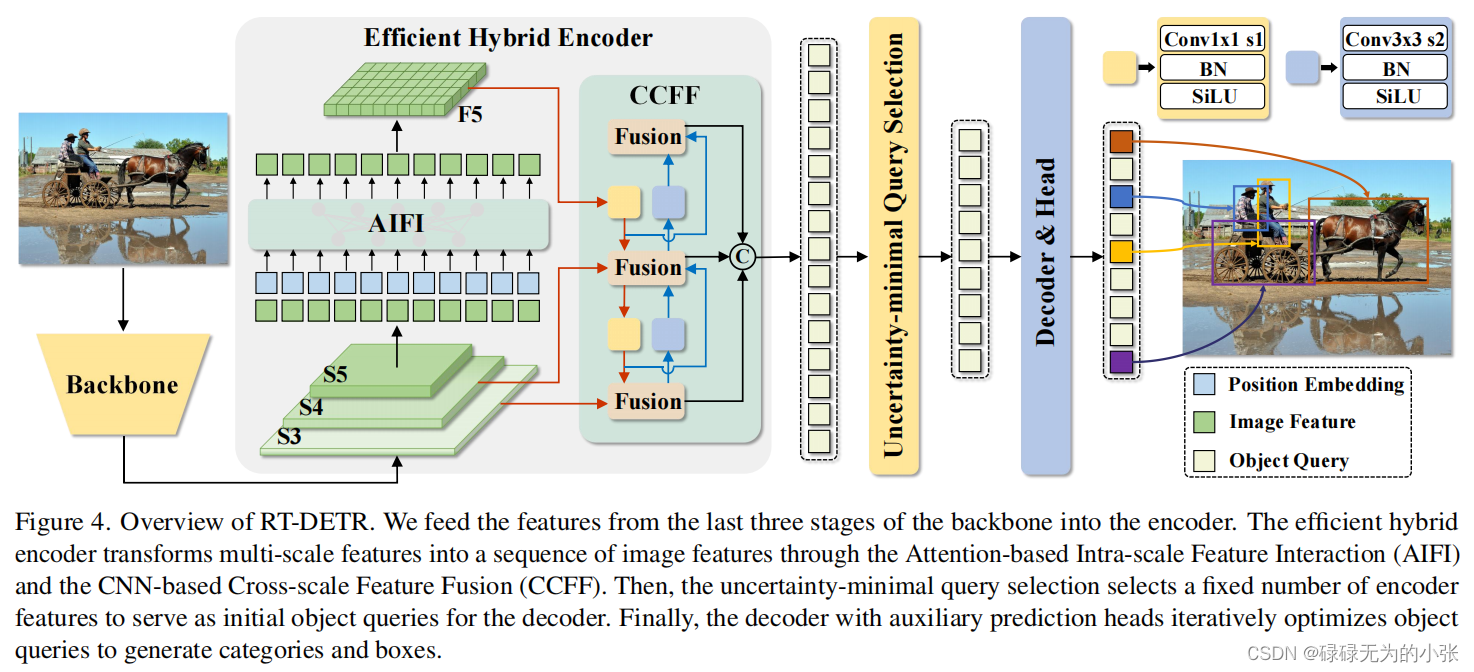
模型的结构如上图所示,输出图片经过Backbone进行特征提取,获取三个特征图
S
3
、
S
4
、
S
5
S_3、S_4、S_5
S3、S4、S5。然后将它们输入Efficient Hybrid Encoder层。Efficient Hybrid Encoder层对特征图
S
5
S_5
S5做AIFI获得特征图
F
5
F_5
F5,然后通过CCFF结合
S
3
、
S
4
、
F
5
S_3、S_4、F_5
S3、S4、F5输出。然后用Uncertainty-minimal Query Selection选取query,再和Encoder的输出一起输入decoder中,最后输出检测结果。
Efficient Hybrid Encoder
作者分析了特征图自交互的情况,认为低级特征具备丰富的图像语义,交互的需求不大。同时通过实验验证了这一观点。这里的出发点是从缩短输入的AIFI的长度出发,由于计算复杂度与长度的平方成正比,由于高级特征的长度较小,所以计算量较少,同时能够验证低级特征交互是不必要,那么就可以较少这一部分的计算。
整个Efficient Hybrid Encoder模块可以用公式表达出来,即
Q
=
K
=
V
=
F
l
a
t
t
e
n
(
C
5
)
F
5
=
R
e
s
h
a
p
e
(
A
I
F
I
(
Q
,
K
,
V
)
)
O
=
C
C
F
F
(
{
S
3
,
S
4
,
F
5
}
)

CCFF模块其实就是类似于yolo neck中的FPN+PAN,用于融合不同尺度的特征图。这里主要了解一下Fusion的结构,论文中给出了fusion的结构图,具体如下
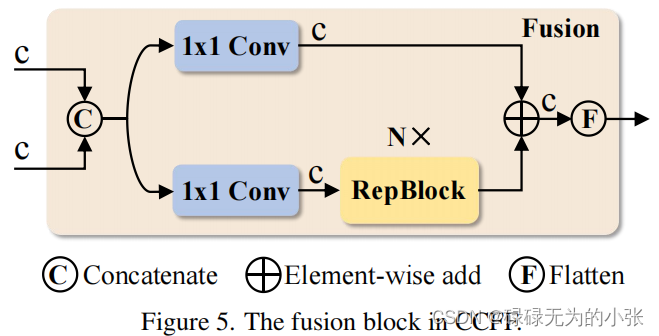
Fusion的结构采用了CSP的方法,将输入的特征concat后用1x1的卷积分成了俩份,然后一边经过RepBlock,另一边直接与RepBlock输出直接concat,然后经过flatten层输出。
接下来结合一下源码分析一下CCFF的结构,下面的代码来自hybrid_encoder.py
inner_outs = [proj_feats[-1]] #获取特征图F5 for idx in range(len(self.in_channels) - 1, 0, -1): #总共俩层,即idx为2,1 feat_high = inner_outs[0] #第一次遍历为F5 feat_low = proj_feats[idx - 1] #第一次遍历为S4 feat_high = self.lateral_convs[len(self.in_channels) - 1 - idx](feat_high)#这一部分就是图中的黄色模块,由1x1的卷积+BN层+SiLU组成,第一次遍历时处理F5 inner_outs[0] = feat_high upsample_feat = F.interpolate(feat_high, scale_factor=2., mode='nearest') #第一次遍历对经过lateral_conv的F5做上采样 inner_out = self.fpn_blocks[len(self.in_channels)-1-idx](torch.concat([upsample_feat, feat_low], dim=1)) #这里就是论文中的fusion模块 inner_outs.insert(0, inner_out) #相信集合图形可以很好地理解,第二次的遍历对着图就可以了 outs = [inner_outs[0]] for idx in range(len(self.in_channels) - 1): #这里也是遍历俩次 feat_low = outs[-1] #获得FPN的最后一层输出 feat_high = inner_outs[idx + 1] #第二次lateral_conv的输出 downsample_feat = self.downsample_convs[idx](feat_low) #上采样 out = self.pan_blocks[idx](torch.concat([downsample_feat, feat_high], dim=1)) #经过fusion模块 outs.append(out) #这里也是分析了第一次遍历,第二次也是类似的

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
Uncertainty-minimal Query Selection
作者分析认为,以往选择query时未同时考虑分类和回归的结果,所以导致模型的预测结果中,并不是分类和回归都是最优。所以它为了降低这种不确定性,在query的选择中加入整个因素,即衡量不确定性定义为
U
(
x
^
)
U(\hat{x})
U(x^),其中
U
(
x
^
)
=
∣
∣
P
(
x
^
)
−
C
(
x
^
)
∣
∣
U(\hat{x}) = ||P(\hat{x})-C(\hat{x})||
U(x^)=∣∣P(x^)−C(x^)∣∣其中
x
^
\hat{x}
x^为encoder的输出,
P
P
P位置预测,
C
C
C指分类预测。
然后在最后的损失中加上
U
U
U,即
L
(
x
^
,
y
^
,
y
)
=
L
b
o
x
(
b
^
,
b
)
+
L
c
l
s
(
U
(
x
^
)
,
c
^
,
c
)
\mathcal{L}(\hat{x},\hat{y},y) = \mathcal{L} _{box}(\hat{b},b)+ \mathcal{L} _{cls}(U(\hat{x}),\hat{c},c)
L(x^,y^,y)=Lbox(b^,b)+Lcls(U(x^),c^,c)这里的思想其实就是做了一个分类和回归的对齐,核心上就是分类分数高回归结果也要准。在源码的具体实现中,采用了VFL的方法,VFL公式具体如下
V
F
L
(
p
,
q
)
=
{
−
q
(
q
log
(
p
)
+
(
1
−
q
)
log
(
1
−
p
)
)
q
>
0
−
α
p
γ
log
(
1
−
p
)
q
=
0
VFL(p,q)=\left\{
源码中的实现如下
def loss_labels_vfl(self, outputs, targets, indices, num_boxes, log=True): assert 'pred_boxes' in outputs idx = self._get_src_permutation_idx(indices) src_boxes = outputs['pred_boxes'][idx] target_boxes = torch.cat([t['boxes'][i] for t, (_, i) in zip(targets, indices)], dim=0) ious, _ = box_iou(box_cxcywh_to_xyxy(src_boxes), box_cxcywh_to_xyxy(target_boxes)) ious = torch.diag(ious).detach() src_logits = outputs['pred_logits'] target_classes_o = torch.cat([t["labels"][J] for t, (_, J) in zip(targets, indices)]) target_classes = torch.full(src_logits.shape[:2], self.num_classes, dtype=torch.int64, device=src_logits.device) target_classes[idx] = target_classes_o target = F.one_hot(target_classes, num_classes=self.num_classes + 1)[..., :-1] target_score_o = torch.zeros_like(target_classes, dtype=src_logits.dtype) target_score_o[idx] = ious.to(target_score_o.dtype) target_score = target_score_o.unsqueeze(-1) * target pred_score = F.sigmoid(src_logits).detach() weight = self.alpha * pred_score.pow(self.gamma) * (1 - target) + target_score loss = F.binary_cross_entropy_with_logits(src_logits, target_score, weight=weight, reduction='none') loss = loss.mean(1).sum() * src_logits.shape[1] / num_boxes return {'loss_vfl': loss}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
总结
对RT-DETR的encoder部分,整体看下来像是yolo的backbone+neck。RT-DETR的核心还是在增速上,所以这里它的优化思想是值得借鉴的,但是yolo结构跟DETR结构之间的界限越来越模糊了。对query的优化上,只是做了对齐,使其选择的query更加精确。整体而言模型的创新不大。虽然DETR提倡的是NMS-Free,但是对于某些对精装度要求较高的任务中,如果阈值设置过低,导致最后得出的框过多,仍然需要借助NMS的方法去改进。设置过高则存在丢框的问题。

