
- 1Linux内核编译与安装_内核编译依赖工具安装
- 2Weisfeiler-Lehman(WL)算法和WL Test的学习笔记
- 3软考高级 真题 2014年上半年 信息系统项目管理师 综合知识_信息系统2014年上半年l为外资软件公司高级项目经理,负责
- 4每日AIGC最新进展(31):新加坡国立大学提出视频生成人类评估协议、加州大学提出视频生成测试基准TC-Bench、清华大学提出视频编辑新方法COVE
- 5Fiddler的安装和使用,PC和手机端抓包快速入门教程
- 6MAC 安装 protobuf_libprotobuf.28.dylib
- 7M1/M2 通过VM Fusion安装Win11 ARM,解决联网和文件传输
- 8pmp考试是什么?有没有含金量?值得考吗?(附2023 年考试时间、备考资料)
- 9feign.codec.EncodeException: Could not write request: no suitable HttpMessageConverter found【已解决】_caused by: feign.codec.encodeexception: could not
- 10面试必问的41道 SpringBoot 面试题,不看亏大了!_springboot管理系统导师会问什么
【Linux】三、Linux 环境基础及开发工具使用(下篇)_卸载lrzsz
赞
踩
目录
六、Linux 软件包管理器 yum
6.1 前言
思考:
你要下载的软件之前是存在你电脑或手机上的吗?
- 答案:不是
如果不在,你怎么知道你要下载的软件在哪里?
- 答案是通过浏览器搜素或应用商店下载的
那浏览器或应用商店上的软件是谁放的呢?
- 答案是它的内部人员或软件提供者放的,它们都统一放在服务器上,你要下载就通过访问服务器来下载里面的软件
同理,Linux上安装软件也是如此,Linux 上下载软件一般是通过 yum 来下载的,它就类似于应用商店一样。
-------------------我是分割线------------------
6.2 什么是软件包
- 在Linux下安装软件, 一个通常的办法是下载到程序的源代码, 并进行编译, 得到可执行程序.
- 但是这样太麻烦了, 于是有些人把一些常用的软件提前编译好, 做成软件包(可以理解成windows上装程序)放在一个服务器上, 通过包管理器可以很方便的获取到这个编译好的软件包, 直接进行安装.
- 软件包和软件包管理器, 就好比 "App" 和 "应用商店" 这样的关系.
- yum(Yellow dog Updater, Modified)是Linux下非常常用的一种包管理器. 主要应用在Fedora, RedHat,Centos等发行版上
6.3 查看软件包
yum list通过 yum list 命令可以罗列出当前一共有哪些软件包,全部显示

由于包的数目可能非常之多, 这里我们需要使用 grep 命令只筛选出我们关注的包.
yum list | grep [需要查找的软件包名]例如:yum list | grep lrzsz

注意事项:
- 软件包名称: 主版本号.次版本号.源程序发行号-软件包的发行号.主机平台.cpu架构.
- "x86_64" 后缀表示64位系统的安装包, "x86" 后缀表示32位系统安装包,选择包时要和系统匹配.
- "el7" 表示操作系统发行版的版本, "el7" 表示的是 centos7/redhat7. "el6" 表示 centos6/redhat6.
- 最后一列,@os 表示的是 "软件源" 的名称, 类似于 "小米应用商店", "华为应用商店" 这样的概念
6.4 如何安装软件
通过 yum, 我们可以通过很简单的一条命令完成一些软件的安装,比如我们要安装 lrzse,普通用户安装需要 sudo
- sudo yum install [软件包名]
- //假设安装 lrzsz
- sudo yum install lrzsz
敲下这条指令即可安装lrzse,yum 会自动找到都有哪些软件包需要下载, 这时候敲 "y" 确认安装,当出现 "complete" 字样, 说明安装完成。
也可以这样
sudo yum install -y lrzsz-y 表示有关于这次安装的问题不用请求我的同意,出现 “complete" 字样,说明安装完成。
注意
- 安装软件时由于需要向系统目录中写入内容,一般需要 sudo 或者切换到 root 帐户下才能完成
- yum 安装软件只能一个装完了再装另一个,正在 yum 安装一个软件的过程中,如果再尝试 yum 安装另一个软件,yum 会报错
- 如果 yum 报错, 请自行百度
6.5 如何卸载软件
仍然是一条命令,普通用户也是需要 sudo
- sudo yum remove [软件名]
- sudo yum remove -y [软件名]
- //比如卸载 lrzsz
- sudo yum remove lrzsz
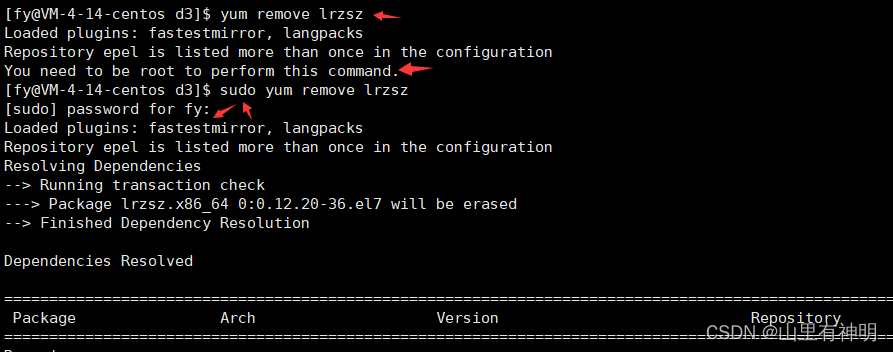
出现 “complete" 字样,说明卸载完成

6.6 yum 源
yum 源就是一个配套文件,说白了就是一堆链接,提供下载途径
查看自己的 yum 源:
ls /etc/yum.repos.d 
随便打开一个 yum源:
vim /etc/yum.repos.d/CentOS-Base.repo
我们会发现里面全是链接,这些链接就是供我们下载软件用的,一般 yum源只有几个,需要自己添加yum源

- 一般原生的Linux 系统,内置的下载链接基本都是配套国外的网址。一些提供服务器的公司,华为腾讯之类的,他们给我们提供云服务的时候,基本上已经把 yum 源换成国内的了。
- 由于国内的防火墙,很多国外的网站已经访问不了了,像腾讯这些大公司就会把国外整个网站里面的东西全部复制过来,把Linux 里面是国外的 yum 源全部替换成国内自己的。
安装 yum扩展源,提供一些非官方的软件
sudo yum install -y epel-release这个我之前就安装有了
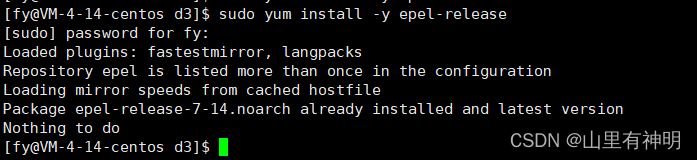
- 如果自己的yum源是国外的,需要自己更新一些yum源,安装替换新的yum源建议自己备份一下原有的yum,再进行覆盖旧的yum源
- 这里就不演示了,(因为我自己的是国内哈哈hh),自己百度一下即可。
6.7 一些好玩的命令
sudo yum install -y sl安装好这个后,输入 sl ,就可以看到小火车跑了

其他好玩的插件,自己百度搜索即可,最好带上自己的 Linux版本
-------------------我是分割线------------------
七、Linux第一个小程序-进度条
7.1 \r&&\n
\n 我们都懂,\n不就是回车换行吗,可是真的是你理解的那样吗,事实上并不是你理解的那样,回车和换行压根就不是一个概念
如图:
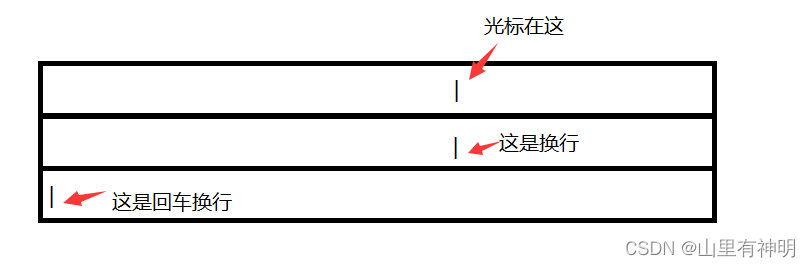
\r 则是换行,\n是回车换行
看一下老式键盘,回车换行的原来的图形是那样子的,而不是现在这样子的

7.2 行缓冲区概念
这段代码运行时的现象是什么?
- #include<stdio.h>
- #include<unistd.h>
- int main()
- {
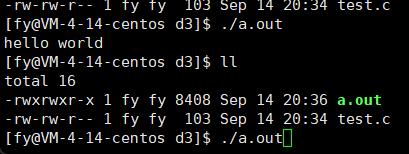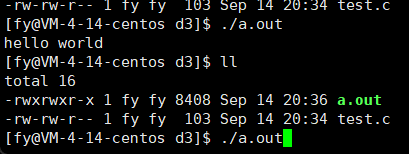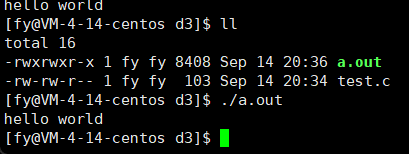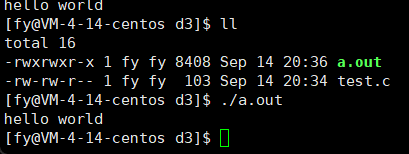
- printf("hello world\n");
- sleep(2);
- return 0;
- }
运行结果如下:
那下面这段代码呢?(去掉了\n)
- #include<stdio.h>
- #include<unistd.h>
- int main()
- {
- printf("hello world");
- sleep(2);
- return 0;
- }
运行结果如下:
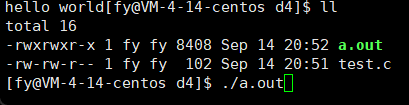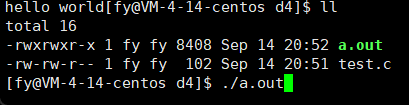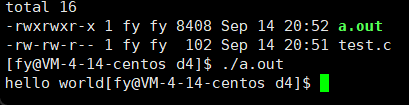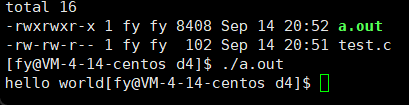
第一个程序我们可以理解,先 printf 后 sleep ,可是第二个呢?为什么先执行的是 sleep 后 printf ?
其实这里执行 sleep 时,printf 已经执行了,也就是说,printf 已经执行了,并不代表信息会被我们看到,这又是为什么呢?
- 这也是之前我们学过的一个概念 —— 缓冲区(在学 C语言文件操作的时候已经接触过了),对于这个概念,我们对它的理解都是浅薄,真正要理解缓冲区,大概会在 Linux系统编程部分,学习基础 IO 后,才会真正理解缓冲区。
- 在此之前我们可以理解为,缓冲区本质上是一段内存空间,它可以暂存临时数据,在合适的时候刷新出去。
- 而 \n 的作用就是把 \n 之前的字符全部刷新出去,也就是显示到显示器上。
再看这个代码:
- #include<stdio.h>
- #include<unistd.h>
- int main()
- {
- printf("hello world");
- fflush(stdout);
- sleep(2);
- return 0;
- }
运行结果:
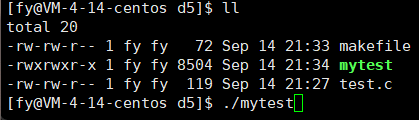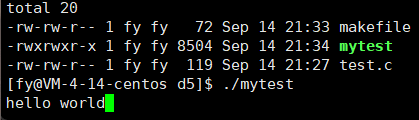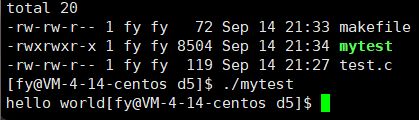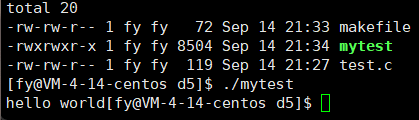
最后再解释下这里的现象,这里是往显示器上显示,默认的刷新方案是行刷新,而如上并没有 \n,所以不会刷新,只能把缓冲区写满或程序结束才能刷新,所以为了让它显示出来,需要强制刷新 fflush(stdout),这个可以帮助我们写进度条小程序
-------------------我是分割线------------------
7.3 进度条代码
先来看一个倒计时代码
原理:回车不换行,依次覆盖,使用 \r,需要注意的是没使用 \n,不能刷新,所以需要 ffush 强制刷新
- #include<stdio.h>
- #include<unistd.h>
-
- int main()
- {
- int cnt = 5;
- while(cnt >= 0)
- {
- printf("倒计时:%d\r", cnt);
- cnt--;
- fflush(stdout);
- sleep(1);
- }
- return 0;
- }
运行结果:
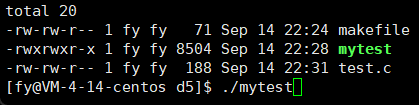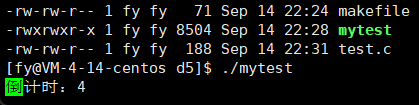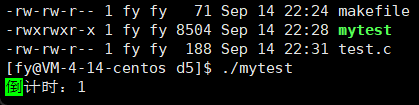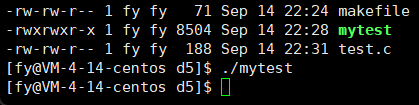
这里有个问题,比如十位数是两个数,当减到个位数它只会覆盖一个数,留下了10 的另一半 0,解决方法就是加上位宽来控制
- #include<stdio.h>
- #include<unistd.h>
-
- int main()
- {
- int cnt = 5;
- while(cnt >= 0)
- {
- printf("倒计时:%d\2r", cnt);
- cnt--;
- fflush(stdout);
- sleep(1);
- }
- return 0;
- }
进度条代码:
usleep 单位是微秒,sleep 单位是秒
- #include<stdio.h>
- #include<unistd.h>
- #include<string.h>
-
- #define NUM 102
-
- int main()
- {
- char bar[NUM];
- memset(bar, 0, sizeof(bar));
- const char *lable = "|/-\\";
- int cnt = 0;
- while(cnt <= 100)
- {
- printf("[%-100s][%d] %c\r", bar, cnt, lable[cnt%4]);
- bar[cnt++] = '#';
- fflush(stdout);
- usleep(20000);
- }
- printf("\n");
- return 0;
- }

运行结果:

有兴趣的话,可以给进度条更好的优化
-------------------我是分割线------------------
八、Linux 使用 git 命令行
8.1 版本控制
版本控制是指对软件开发过程中各种程序代码、配置文件及说明文档等文件变更的管理,是软件配置管理的核心思想之一。
用故事解释:
- 小明用 word 写实验报告,其小明写完了实验报告把第一个版本上传给老师,老师说不合格随后又给小明打回来,让小明修改,小明修改完后又上传给老师,重复修改了n次后老师说,还没第一版写的好,算了,小明你把第一个版本给我吧!对此,小明心里极度不爽,因为小明的第一版本修改来修改去已经不见了。
- 张三看到小明惨痛的经历,于是张三第一个版本写完,交给老师,被打回来后,张三留了个心眼:万一自己改完,老师又要我老的版本呢,所以张三对第一个版本进行了备份,然后进行修改生成第二个版本,随后上传第二个版本,又被打回来了,然后张三又留了个心眼,万一老师要我的第二个版本呢,随后又对第二版进行备份,然后进行修改生成第三个版本,随后上传第三个版本,老师说:算了张三你拿第二个版再修改一下就交给吧。张三继续备份第三个版本,张三拿出第二个版复制并对其修改,生成了2.1版本,提交后老师说:你改的啥啊,算了张三你直接那第一个版本给我吧,不用改了。此时张三心中庆幸:还好我都保存有。
- 其中张三所做的这个工作可以叫做版本管理。不过,张三所做的所有工作都是手动做的,成本较高。张三想了想,学校很多同学遇到这个老师都会遇到这种情况,张三直接叫人写了一个app,专门用于储存旧版本,每修改一次就自动保存就版本,想要哪个版本就拿哪个版本。
- 这个app 的作用就相当于 git,基于 git 搭建的一些网站叫 github 或 gitee,张三对各个版本的保存和拿出就叫版本控制。
-------------------我是分割线------------------
8.2 git 的历史
Linux 内核开源项目有着为数众广的参与者。绝大多数的 Linux 内核维护工作都花在了提交补丁和保存归档的繁琐事务上(1991-2002年间)。 到 2002 年,整个项目组开始启用一个专有的分布式版本控制系统 BitKeeper 来管理和维护代码。
事实上,在 2002 年以前,世界各地的志愿者把源代码文件通过邮件的方式发给作者,然后由作者本人通过手工方式合并代码,随着代码量的增多,成本也越来越高了,所以 Linus Torvalds 就在市面上找了很多版本管理的工具,当时市面上比较成熟的工具都是需要付费的,倒也不是人家掏不起钱,主要是和 Linux 的开源精神不符,其实当时 Linus Torvalds 选择了一个商业的版本控制系统 BitKeeper,因为这个公司的老板比较敬佩 Linus Torvalds ,直接免费给 LInux 社区提供服务。但是 Linux 社区中存在很多的大佬,进行破解研究 BitKeeper !人家老板当然不干了:我免费给你用,你却想砸我的饭碗。
到了 2005 年,开发 BitKeeper 的商业公司同 Linux 内核开源社区的合作关系结束,他们收回了 Linux 内核社区免费使用 BitKeeper 的权力。这就迫使 Linux 开源社区(特别是 Linux 的缔造者 Linus Torvalds)基于使用 BitKeeper 时的经验教训,开发出自己的版本系统。(2周左右!) 也就是后来的 Git!
- github 由于国内的防火墙的原因,现在访问速度极慢,给人体验极其不好,所以目前推荐用国内的 gitee,gitee 就相当于 github 的中文版。
-------------------我是分割线------------------
8.3 git 安装
gitee 链接:点这,进去创建账号并创建好仓库。
不懂的看着,gitee教程:gitee(码云)的注册和代码提交【手把手】
sudo yum install git
8.4 克隆远程仓库到本地
git clone [url]这里的 url 就是刚刚建立好的 仓库项目 的链接,等待同步完成即可,不是开源的要输入自己的账号和密码
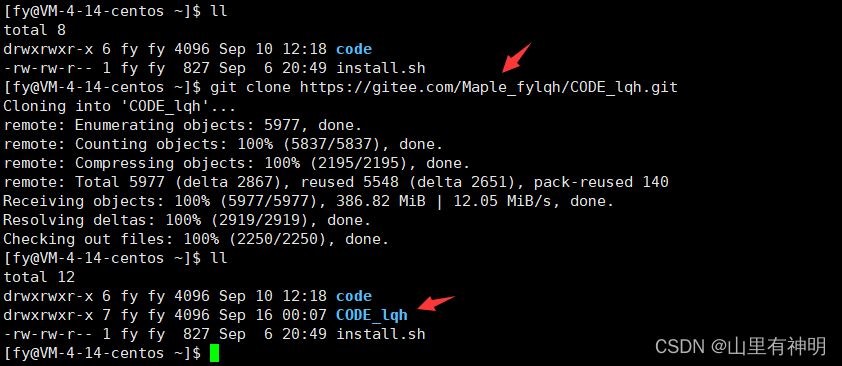
-------------------我是分割线------------------
8.5 git 三板斧
8.51 三板斧第一招: git add
git add [文件或目录名]:将当前文件或目录下的所有文件添加到本地仓库
git add 必须在本地仓库下进行,否则无法进行 add,ps:

可以拷贝或移动文件到本地仓库目录下,再或者文件直接在仓库内创建

到仓库目录下再 add,[git add .]是 add 当前目录下所有文件
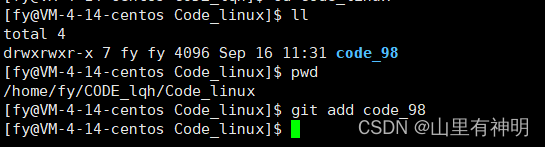
8.52 三板斧第二招: git commit
git commit -m “提交日志说明” 提交代码到本地仓库中,注意引号里的东西不要胡写,提交的时候应该注明提交日志, 描述改动的详细内容。因为 git log 就可以查看到你所有的提交信息。
第一次提交可能会让你完善信息,按照提升操作即可

按照提示添加:

再次 git commit
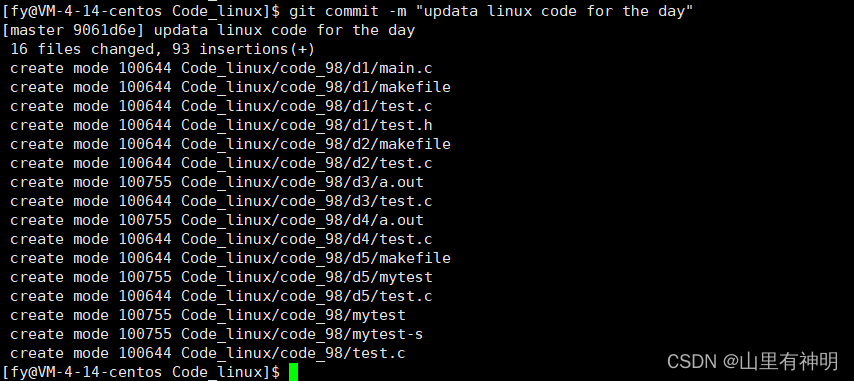
注意这里的提交并不是把内容上传至远端,而是把内容提交到你的本地仓库,远端仓库并没有进行同步
-------------------我是分割线------------------
8.53 三板斧第三招: git push
提交代码到远端仓库
git push提交如下:

按照提示输入账号和密码即可,等待提交成功即可

再去 gitee 上看,已经同步到远端仓库了

注:
- 有时候会出现无法提交,直接无脑 git pull
- .gitignore //不想提交某些后缀的文件同步到 git 远端仓库,把需要添加的后缀添加到 .gitignore 文件里。
-------------------我是分割线------------------
九、Linux调试器 - gdb使用
9.1 背景
- 程序的发布方式有两种,debug模式和release模式(C语言已经学习过了,这里就不解释了)
- Linux gcc/g++出来的二进制程序,默认是release模式,要在 debug 版本下调试
- 程序出错肯定是要调试的,毕竟做项目代码量太大,肉眼看就是受罪
- 要使用gdb调试,必须在源代码生成二进制程序的时候, 加上 -g 选项
测试使用代码:
- #include<stdio.h>
-
- int AddTop(int top)
- {
- int ret = 0;
- int i = 0;
- for(i = 0; i <= top; i++)
- {
- ret += i;
- }
- return ret;
- }
-
- int main()
- {
- int top = 100;
-
- int result = AddTop(top);
-
- printf("%d\n", result);
- return 0;
- }
debug 和 release 大小比较,debug 比 release 所用空间大就是插入了调试信息,可用于调试
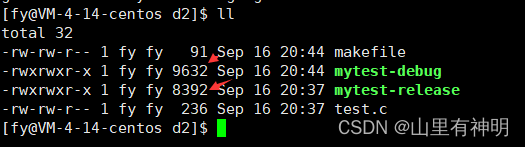
9.2 gdb 开始使用
gdb [binFile]
gdb 退出: ctrl + d 或 quit
调试命令:
(每个命令基本都可简写,建议使用简写)
- list/l 行号:显示binFile源代码,接着上次的位置往下列,每次列10行。
- list/l 函数名:列出某个函数的源代码。
- r 或 run:运行程序,没有断点程序直接运行结束。
- n 或 next:单条执行。
- s 或 step:进入函数调用
- break / b 行号:在某一行设置断点
- break [函数名]:在某个函数开头设置断点
- info b/ break :查看断点信息。
- finish:执行到当前函数返回,然后挺下来等待命令
- print / p:打印表达式的值,通过表达式可以修改变量的值或者调用函数
- p [变量]:打印变量值。
- set var:修改变量的值
- continue 或 c:从当前位置开始连续而非单步执行程序,运行至下一个断点
- delete breakpoints:删除所有断点
- d n / delete breakpoints n:删除序号为n的断点
- disable breakpoints:禁用断点
- enable breakpoints:启用断点
- info(或i) breakpoints:参看当前设置了哪些断点
- display 变量名:跟踪查看一个变量,每次停下来都显示它的值
- undisplay:取消对先前设置的那些变量的跟踪
- until X行号:跳至X行
- breaktrace(或bt):查看各级函数调用及参数
- info(i) locals:查看当前栈帧局部变量的值
- quit:退出gdb
9.3 gdb 调试例子
测试代码依旧是上面的,release 版本无法调试

使用gdb调试,必须在源代码生成二进制程序的时候, 加上 -g 选项
gcc test.c -o mytest -g 可以进行调试

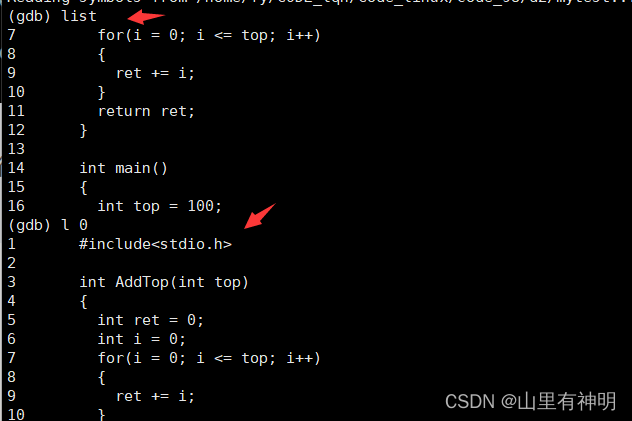
list/l [行号]:显示binFile源代码,接着上次的位置往下列,每次列10行
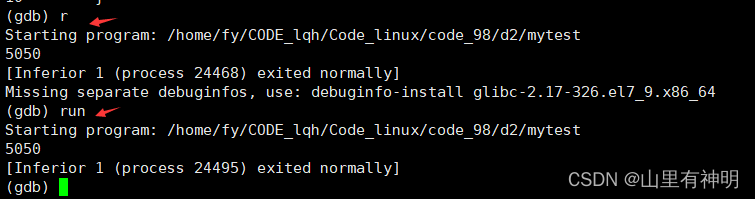
r 或 run:运行程序,没有断点程序直接运行结束
接下来全用简写,写完太麻烦了
break / b 行号:在某一行设置断点

info break/b :查看断点信息

d n / delete breakpoints n:删除序号为n的断点,序号为 num 的一列

disable breakpoints/ n:禁用断点,enable breakpoints/ n:启用断点
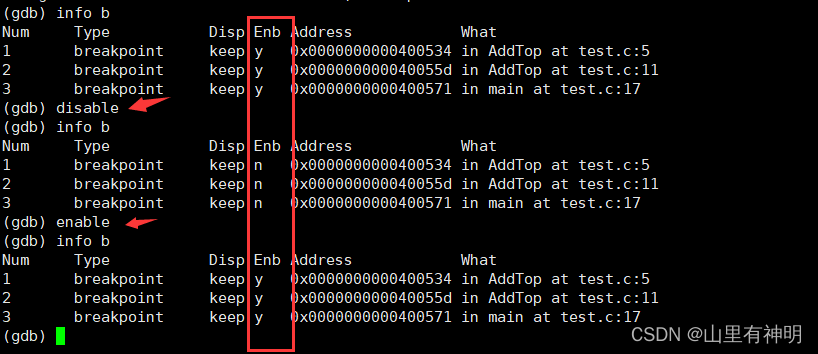

演示到这,后面不演示了...
这两篇文章仅仅是对这些开发工具作一个了解,还需要自己投入大量时间进行练习使用这些工具,这些工具的知识扩展还得靠自己一步一个脚印,毕竟学习的道路漫长且艰,文章到这就结束了。
-------------------我是分割线------------------
文章就到这里,下篇即将更新

