
- 12024年计算机网络与互联网技术国际会议(ICCNIT 2024)_iccnit官网
- 2Mybatis的特性详解——四大操作标签_mybatis insert select
- 3【RK3568】编译error记录_rk3568 error:no found parameter!
- 4Python桌面应用程序的布局和设计_python桌面系统
- 5docker拉取镜像的时候超时_docker拉取镜像超时
- 6Python 安装 Selenium 报错解决方案:全方位排错指南_安装selenium报错
- 7python每日一题——16除自身以外数组的乘积_python 除自身以外数组的乘积
- 8rsa加密算法详解_rsa加密算法详细步骤
- 9能把进程和线程讲的这么透彻的,没有20年功夫还真不行【0基础也能看懂】
- 10软件测试工程师面试——接口测试话术_测试工程师常用话术
图像生成系列(三)——Diffusion_diffusion unet
赞
踩
知识准备
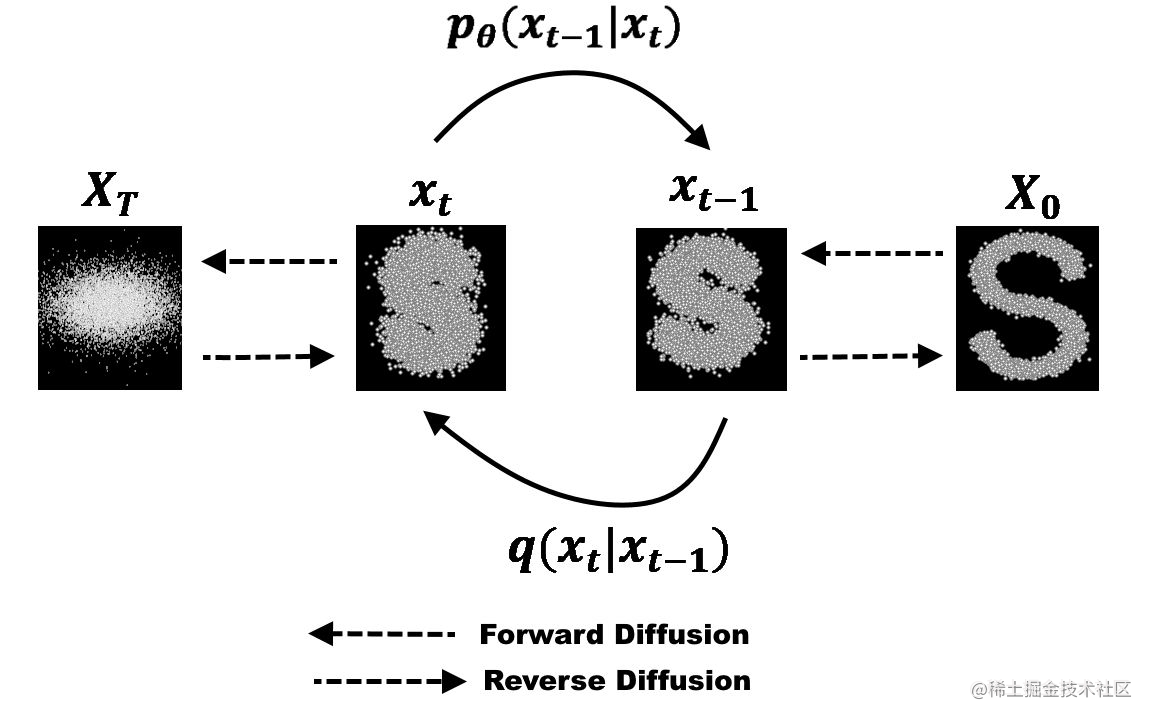
扩散模型是一种用于图像生成的模型,其主要特点是通过逐渐扩散和迭代生成图像。有两个过程:前向扩散和反向扩散。
扩散模型的前向过程,核心部分是训练 U-Net 模型,也就是在原图的基础上加噪声,以噪声为标签,给 U-Net 输入一张带噪图片和时间步,让其预测噪声,通过不断学习,降低预测噪声和实际噪声的损失值,最后可以得到训练好的能认识噪声的 U-Net 模型。
扩散模型的反向过程,也就是还原过程,在我们训练好了上面的模型之后,给模型输入一张带噪图片,不断根据当前带噪图片和时间步迭代去掉 U-Net 预测的噪声,就可以尽力还原图片。
数据处理
这部分主要是对数据的加载、处理、以及工具的定义。
get_data 函数
get_data 函数的主要功能是获取数据集,并对数据集进行预处理,以便后续的算法或模型使用。具体步骤如下:
-
使用
load_dataset函数从名为lansinuote/gen.1.celeba的数据集中加载数据,这里只用到了’train’数据集中的最多 3000 张图片作为训练集。 -
对数据集进行洗牌以确保随机性,并且对每一张进行了尺寸调整和图像值归一化,将图像的维度顺序从 (H, W, C) 转换为 (C, H, W) 。
-
创建一个空的 NumPy 数组
data,形状为 (N, 3, 64, 64),数据类型为np.float32。遍历处理后的数据集,将处理后的图像存储在data数组中,返回处理后的数据data作为结果。
getLoader 函数
getLoader 函数的功能是创建一个数据加载器(DataLoader),用于在训练过程中加载数据批次。
show 函数
show 函数的功能是展示一组图像数据。具体步骤如下:
-
将图像数据转移到 CPU 上,并将其从计算图中分离,并转换为 NumPy 数组。
-
从图像列表中选择前 5 个图像。
-
展示这些图像 1 秒之后自动关闭,并且将照片存到本地然后关闭图像。
这里展示了部分的真实人像数据。

import time
from datasets import load_dataset
import numpy as np
import torch
from matplotlib import pyplot as plt
def get_data():
dataset = load_dataset('lansinuote/gen.1.celeba', split='train')
N = min(dataset.shape[0], 3000)
dataset = dataset.shuffle(0).select(range(N))
def f(data):
images = data['image']
data = []
for i in images:
i = i.resize((64, 64))
i = np.array(i)
i = i / 255
i = i.transpose(2, 0, 1)
data.append(i)
return {'image': data}
dataset = dataset.map(function=f, batched=True, batch_size=1000, remove_columns=list(dataset.features)[1:])
data = np.empty((N, 3, 64, 64), dtype=np.float32)
for i in range(len(dataset)):
data[i] = dataset[i]['image']
return data
def getLoader():
return torch.utils.data.DataLoader( dataset=get_data(), batch_size=64, shuffle=True, drop_last=True,)
def show(images):
if type(images) == torch.Tensor:
images = images.to('cpu').detach().numpy()
images = images[:5]
plt.figure(figsize=(5, 1))
for i in range(len(images)):
image = images[i]
image = image.transpose(1, 2, 0)
plt.subplot(1, 5, i + 1)
plt.imshow(image)
plt.axis('off')
plt.pause(1)
plt.savefig(f"../datas/diffusion_result_{time.time()}.png")
plt.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
模型搭建
schedule 函数
这个函数的目的是根据时间步 time 的变化,生成噪声比例和图像比例,用于扩散模型中的噪声和图像处理过程和计算。
Combine 类
Combine 类用于将图像和时间步组合起来。以下是主要函数功能:
get_var 函数方法起到了将时间步信息映射到特征空间,并为扩散模型提供了时间感知的特征表示的作用。参数 var 是指扩散模型中的时间步,输入的 var 表示时间步信息,它与预定义的张量 t 相乘,得到一个新的张量 var。这样做的目的是将时间步信息映射到一个更大的空间,以便在扩散过程中引入更多的变化和多样性。通过对 var 进行正弦和余弦函数的计算,并将结果按列拼接起来,可以增加对时间步的灵活性和表达能力。最后,通过维度扩展和上采样操作,将 var 转换为与图像相同大小的特征张量,后续用于与图像特征进行融合。
get_image 方法的作用是通过卷积操作对输入图像进行特征提取,得到一个新的特征图。这个特征图可以用于后续的图像处理和特征融合操作。
forward 方法其实就是把上面两个的特征进行融合拼接操作,形成一个新的特征表示。特征融合的过程可以使得模型能够同时考虑到图像特征和时间步的变化情况。这有助于提升模型对噪声的适应能力和对时间步的感知能力,从而更好地处理带噪图片的生成。
Residual 类
Residual 类定义了一个残差块(Residual Block)。残差块是深度学习中常用的构建块之一,核心思想就是将原始输入与学习到的特征相加,可以帮助网络更好地进行特征学习和信息传递。残差块的设计可以有效地缓解梯度消失和梯度爆炸问题,提升模型的训练效果和表示能力。
Unet 类
Unet 类就是扩散模型的核心部分,它是一个经典的图像分割网络结构,常用于图像分割任务,在这里我们主要是用于噪声图的预测。UNet 模型由对称的编码器(downsampling)和解码器(upsampling)组成,中间部分是一个跳跃连接(skip connection),用于融合低级和高级特征以提高分割精度。
在初始化函数中,定义了编码器(self.down)、中间部分(self.middle)和解码器(self.up),以及输出层(self.out)。编码器和解码器都由一系列的残差块(Residual)组成,其中编码器通过下采样操作(torch.nn.AvgPool2d)逐渐减小特征图的尺寸,解码器通过上采样操作(torch.nn.UpsamplingBilinear2d)逐渐恢复特征图的尺寸。中间部分是一些额外的残差块。
Diffusion 类
Diffusion 类它包含了一个图像归一化层(self.norm),一个 UNet 模型(self.unet),和一个特征融合模块(self.combine)。其中 self.norm 是一个批归一化层,用于归一化输入图像。self.unet 是一个 UNet 模型,用于噪声预测。self.combine 是一个特征融合模块,用于将图像特征和时间特征进行融合。
在前向传播方法中,首先对输入图像应用归一化操作。接下来,生成一个与输入图像大小相同的噪声。通过调用 schedule 函数生成系数(noise_r 和 image_r),用于对图像和噪声进行调整。然后将噪声和图像进行线性叠加,得到带噪图像。接着,将调整后的图像和时间特征传入特征融合模块 self.combine,得到融合后的特征 combine。最后,将融合后的特征传入 UNet 模型 self.unet,得到预测的噪声 pred_noise。
import torch
from transformers import PreTrainedModel, PretrainedConfig
def schedule(time):
t = 0.3175604292915215 + time * 1.2332345639299847
return t.sin(), t.cos()
class Combine(torch.nn.Module):
def __init__(self):
super().__init__()
t = torch.linspace(0.0, 6.907755278982137, 16).exp()
t *= 2
t *= 3.141592653589793
self.register_buffer('t', t)
self.upsample = torch.nn.UpsamplingNearest2d(size=(64, 64))
self.cnn = torch.nn.Conv2d(3, 32, kernel_size=1, stride=1, padding=0)
def get_var(self, var):
var = self.t * var
var = torch.cat((var.sin(), var.cos()), dim=1)
var = var.unsqueeze(dim=-1).unsqueeze(dim=-1)
var = self.upsample(var)
return var
def get_image(self, image):
image = self.cnn(image)
return image
def forward(self, image, var):
var = var.squeeze(dim=-1).squeeze(dim=-1)
var = self.get_var(var)
image = self.get_image(image)
combine = torch.cat((image, var), dim=1)
return combine
class Residual(torch.nn.Module):
def __init__(self, channel_in, channel_out):
super().__init__()
self.cnn = torch.nn.Conv2d(channel_in, channel_out, kernel_size=1, stride=1, padding=0)
self.s = torch.nn.Sequential(
torch.nn.BatchNorm2d(channel_in),
torch.nn.Conv2d(channel_in, channel_out, kernel_size=3, stride=1, padding=1),
torch.nn.SiLU(),
torch.nn.Conv2d(channel_out, channel_out, kernel_size=3, stride=1, padding=1),
)
def forward(self, x):
return self.cnn(x) + self.s(x)
class UNet(torch.nn.Module):
def __init__(self):
super().__init__()
self.down = torch.nn.ModuleList([
Residual(64, 32),
Residual(32, 32),
torch.nn.AvgPool2d(2),
Residual(32, 64),
Residual(64, 64),
torch.nn.AvgPool2d(2),
Residual(64, 96),
Residual(96, 96),
torch.nn.AvgPool2d(2),
])
self.middle = torch.nn.ModuleList([
Residual(96, 128),
Residual(128, 128),
])
self.up = torch.nn.ModuleList([
torch.nn.UpsamplingBilinear2d(scale_factor=2),
Residual(224, 96),
Residual(192, 96),
torch.nn.UpsamplingBilinear2d(scale_factor=2),
Residual(160, 64),
Residual(128, 64),
torch.nn.UpsamplingBilinear2d(scale_factor=2),
Residual(96, 32),
Residual(64, 32),
])
self.out = torch.nn.Conv2d(32, 3, kernel_size=1, stride=1, padding=0)
def forward(self, image):
out = []
for i in self.down:
image = i(image)
if type(i) == Residual:
out.append(image)
for i in self.middle:
image = i(image)
for i in self.up:
if type(i) == Residual:
p = out.pop()
image = torch.cat((image, p), dim=1)
image = i(image)
image = self.out(image)
return image
class Diffusion(PreTrainedModel):
config_class = PretrainedConfig
def __init__(self, config):
super().__init__(config)
self.norm = torch.nn.BatchNorm2d(3, affine=False)
self.unet = UNet()
self.combine = Combine()
def forward(self, image):
b = image.shape[0]
image = self.norm(image)
noise = torch.randn(b, 3, 64, 64, device=image.device)
noise_r, image_r = schedule(torch.rand(b, 1, 1, 1, device=image.device))
image = image * image_r + noise * noise_r
combine = self.combine(image, noise_r ** 2)
pred_noise = self.unet(combine)
return noise, pred_noise
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
模型训练
generate 函数
这是一个生成函数,用于扩散模型的反向生成图像。初始化输入图像 image,它是一个大小为 (B, 3, 64, 64) 的随机张量表示的是纯噪声。下面要进行 20 轮迭代,每轮迭代都按照时间步 i 逐渐生成图像:
time是一个大小为 (B, 1, 1, 1) 的张量,里面的值是随着 i 增大而逐渐减小的。然后调用schedule函数计算噪声系数noise_r和图像系数image_r。- 通过调用
diffusion.combine函数,将输入图像和噪声系数的平方进行(其实就是方差)组合,得到合成图像combine。然后通过diffusion.unet函数对combine进行处理,得到预测的噪声图像pred_noise。然后通过对image减去噪声系数乘以预测的噪声图像,再除以图像系数,得到还原后的预测图像pred_image。 - 将当前
time减去 (1 / 20),再次调用schedule函数,计算新的噪声系数、图像系数、下一轮迭代的输入图像,为下一轮迭代计算做准备。 - 重复上面的过程,直到完成所有的迭代。
最后的代码涉及归一化的数学原理。在生成过程中,预测图像 pred_image 是在经过归一化处理的噪声图像的基础上生成的。为了还原生成的图像,需要对预测图像进行反归一化。根据扩散模型中的归一化统计信息,对预测图像进行还原操作。也就是将归一化的均值和标准差重新应用到预测图像上,得到最终的预测图像。mean 的形状为 (1, 3, 1, 1),表示在每个颜色通道上都有一个均值。std 的形状为 (1, 3, 1, 1),表示在每个颜色通道上都有一个标准差。这个过程保证了生成的图像在与原始数据集相似的数据分布下,并保持了原始数据的颜色和结构特征。最后,为了确保像素值处于合理的范围内,使用 clip 函数将像素值限制在 0 到 1 之间。
train 函数
train 函数用于训练扩散模型。下面是代码的主要逻辑和步骤:
- 定义损失函数和优化器:使用 L1 损失函数
torch.nn.L1Loss()来计算噪声和预测噪声之间的差异,并使用 AdamW 优化器torch.optim.AdamW进行参数优化。通过 2000 次的 epoch 循环不断更新 diffusion 模型的参数。 - 每训练 100 个 epoch,打印当前的损失值
loss.item(),并且使用generate函数展示 5 张生成的效果图。并且将训练好的模型保存到 huggingface 上,这里需要个人的账号 token 。
import torch
from transformers import PretrainedConfig
from diffusion.data import show, getLoader
from diffusion.model import Diffusion, schedule
diffusion = Diffusion(PretrainedConfig())
loader = getLoader()
def generate(n, device):
image = torch.randn(n, 3, 64, 64, device=device)
for i in range(20):
time = torch.full(size=(n, 1, 1, 1), fill_value=(20 - i) / 20, dtype=torch.float32, device=device)
noise_r, image_r = schedule(time)
combine = diffusion.combine(image, noise_r**2)
pred_noise = diffusion.unet(combine)
pred_image = (image - noise_r * pred_noise) / image_r
time = time - (1 / 20)
noise_r, image_r = schedule(time)
image = image_r * pred_image + noise_r * pred_noise
mean = diffusion.norm.running_mean.reshape(1, 3, 1, 1)
std = (diffusion.norm.running_var**0.5).reshape(1, 3, 1, 1)
pred_image = mean + pred_image * std
pred_image = pred_image.clip(0.0, 1.0)
return pred_image
def train():
criterion = torch.nn.L1Loss()
optimizer = torch.optim.AdamW(diffusion.parameters(), lr=2e-4, weight_decay=1e-4)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
diffusion.to(device)
diffusion.train()
for epoch in range(2000):
for i, data in enumerate(loader):
noise, pred_noise = diffusion(data.to(device))
loss = criterion(noise, pred_noise)
loss.backward()
optimizer.step()
optimizer.zero_grad()
if epoch % 100 == 0:
print(epoch, loss.item())
diffusion.eval()
gen = generate(5, device)
# torch.save(gen, "data_%d.txt" % epoch) # 保存生成的图像
show(gen)
# torch.save(diffusion, "diffusion_%d.pt" % epoch) # 保存训练好的模型
diffusion.push_to_hub( repo_id='wangdayaya/my_diffusion_from_pikachu', use_auth_token=open('tokens.txt').read().strip())
train()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
测试
因为我已经将生成好的模型上传到了 huggingface ,所以直接使用即可,调用模型生成 5 张人像,我们可以看到基本上随机生成的图片还是有模有样的。当然如果模型结构更大,训练数据更多,训练 epoch 更多,效果应该会更好,但是我的 4090 只能做到这个程度了,再大就崩了。
import torch
from diffusion.data import show
from diffusion.model import Diffusion, schedule
def generate(n, device, diffusion):
image = torch.randn(n, 3, 64, 64, device=device)
N = 20
for i in range(N):
time = torch.full(size=(n, 1, 1, 1), fill_value=(N - i) / N, dtype=torch.float32, device=device)
noise_r, image_r = schedule(time)
combine = diffusion.combine(image, noise_r**2)
pred_noise = diffusion.unet(combine)
pred_image = (image - noise_r * pred_noise) / image_r
time = time - (1 / N)
noise_r, image_r = schedule(time)
image = image_r * pred_image + noise_r * pred_noise
mean = diffusion.norm.running_mean.reshape(1, 3, 1, 1)
std = (diffusion.norm.running_var**0.5).reshape(1, 3, 1, 1)
pred_image = mean + pred_image * std
pred_image = pred_image.clip(0.0, 1.0)
return pred_image
diffusion = Diffusion.from_pretrained('wangdayaya/my_diffusion_from_celeba')
device = 'cuda' if torch.cuda.is_available() else 'cpu'
diffusion.to(device)
with torch.no_grad():
show(generate(5, device, diffusion))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27

扩散模型的特点
扩散模型具有以下特点:
- 生成高质量图像:扩散模型能够逐步生成高质量、逼真的图像。
- 可控的生成过程:扩散模型通过时间步骤的迭代控制图像生成过程,可以根据需要逐步调整图像的细节和特征,这使得用户能够控制生成图像的具体过程。
- 随机性和多样性:扩散模型在生成过程中引入噪声和随机性,这为生成多样化的图像提供了可能。
- 灵活的架构:扩散模型的架构具有灵活性,可以根据任务的需要进行调整和扩展。模型中包含的组件如 Combine 模块和 UNet 模块可以根据具体情况进行定制和修改,以适应不同的生成任务和数据特征。
扩散模型、VAE 、AE 的区别
扩散模型(Diffusion Model)、变分自编码器(Variational Autoencoder,VAE)和自编码器(Autoencoder,AE)是三种不同的生成模型,它们在结构和工作原理上有所区别。
-
扩散模型(Diffusion Model):
- 结构:扩散模型使用了逐步迭代的方法生成图像,核心部分是 Unet 用来预测噪声。
- 工作原理:训练一个可以在不同时间步和带噪图片输入的情况下预测出噪声的扩散模型,通过迭代,在纯噪声图片情况下,不断预测并剔除每个时间步的噪声,最后可以得到真实图像。
- 特点:扩散模型具有可控的生成过程、生成随机性和生成多样性、可逆的操作以及灵活的架构等特点。
- 优势:(1)高质量图像生成:扩散模型通过逐步迭代的方式生成图像,可以产生高质量的合成图像。(2)可控的生成过程:通过调整噪声和时间步等隐变量,可以对生成过程进行精细的控制。(3)无需显式潜在空间:扩散模型不依赖于显式的潜在空间表示,因此在数据的分布结构复杂或不明确时也能进行有效的生成。
-
变分自编码器(Variational Autoencoder,VAE):
- 结构:VAE 由编码器和解码器组成,其中编码器将输入数据映射到潜在空间(latent space),解码器则从潜在空间重建输入数据。
- 工作原理:VAE 的目标是学习数据的潜在分布,并生成新的样本。它通过引入潜在变量(latent variable)和对数据的隐变量分布进行建模来实现这一点。VAE 使用了编码器将输入数据映射到潜在空间的均值和方差参数,然后通过从潜在空间中采样来生成样本,并使用解码器将样本重构为原始数据。
- 特点:VAE 具有学习潜在分布、生成新样本的能力,并可以通过调整潜在变量来控制生成样本的属性。它还可以用于无监督学习、数据压缩和特征提取等任务。
- 优势:(1)学习潜在表示:VAE 能够学习数据的潜在分布,并通过潜在变量进行采样和生成。这种潜在表示可以提取数据的抽象特征,有助于生成多样化且具有连续性的样本。(2)可解释性:VAE 的潜在变量通常具有一定的可解释性,可以通过操纵潜在空间中的变量来控制生成样本的特征,例如改变数字的字体、旋转物体等。(3)广泛应用:由于 VAE 具有良好的潜在表示学习能力,它在无监督学习、数据压缩、特征提取等任务中具有广泛的应用。
-
自编码器(Autoencoder,AE):
- 结构:AE 由编码器和解码器组成,其中编码器将输入数据压缩为低维表示,解码器则将低维表示恢复为重构数据。
- 工作原理:AE 的目标是尽可能准确地重构输入数据。编码器将输入数据压缩为低维表示,捕捉输入数据的关键特征。解码器将低维表示解码为与原始输入尽可能接近的重构数据。AE 通过最小化重构误差来学习有效的数据表示。
- 特点:AE 主要用于数据重构和特征提取。它可以自动学习数据中的重要特征,并生成与输入数据相似的重构数据。
综上所述,扩散模型、变分自编码器(VAE)和自编码器(AE)是三种不同的生成模型,它们在结构、工作原理和应用领域上有所区别。扩散模型强调生成高质量图像和可控的生成过程,VAE 关注学习潜在分布和生成新样本,而 AE 主要用于数据重构和特征提取。
感谢
https://huggingface.co/datasets/lansinuote/gen.1.celeba
https://github.com/lansinuote/Simple_Generative_in_PyTorch/blob/main/10.diffusion.ipynb

