
- 1Python编程实例-Tkinter GUI编程-Treeview_python tkinter treeview
- 2springboot 整合 邮件发送_oxxsw
- 3Linux添加用户及用户权限管理_用linux命令给用户加权限_linux操作系统添加核管理用户
- 4pyqt5基本使用操作_pyqt5怎么使用
- 5hive里如何快速查看表中有多少记录数_hive获取数据量
- 6JavaScript实现打印指定区域的内容(附完整源码)_js打印指定区域内容
- 7【Linux系统进阶】Linux命令日志审计方法、企业中动态密码方案、加密算法md5与随机数8种方法(二)_linux audit日志审计命令
- 8利用AI大模型实现自然语言到SQL的转换及其优化_ai sql
- 9SQLAlchemy 连接 MySQL 数据库(一)_sqlalchemy 链接mysql
- 10mysql中授权(grant)和撤销授权(revoke)等命令的用法详解
初学者必备,StableDiffusion基础知识(附工具资料)
赞
踩
下方扫码可获取AI工具安装包,AI全套教程资料,AI变现教程

初学者必备,StableDiffusion基础知识(附工具资料)
目前文生图的主流 AI 绘画平台主要有三种:Midjourney、Stable Diffusion、DALL·E。如果要在实际工作场景中应用,我更推荐 Stable Diffusion。
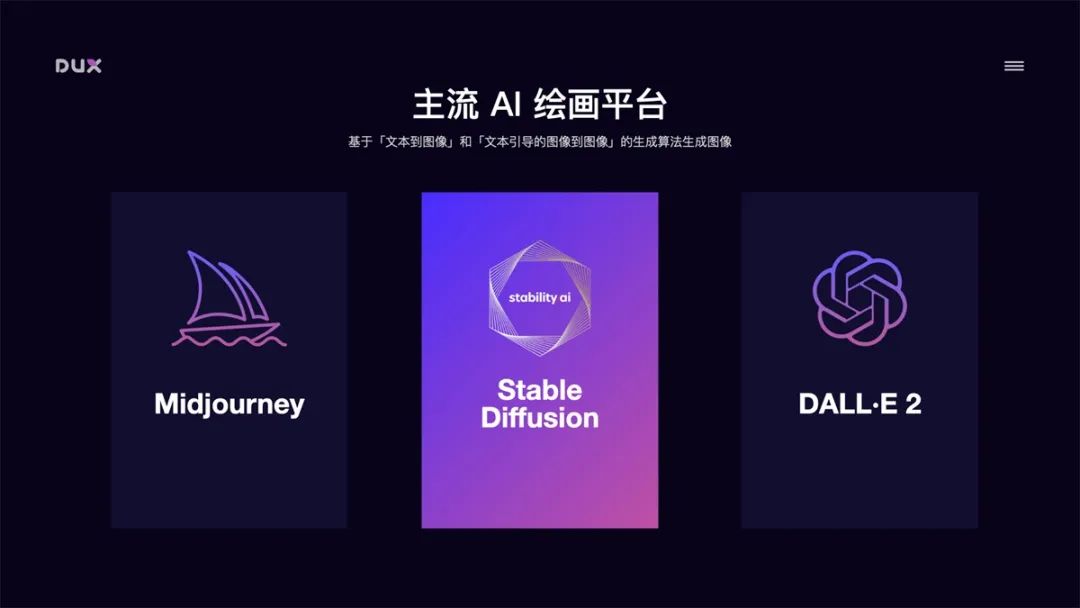
通过对比,Stable Diffusion 在数据安全性(可本地部署)、可扩展性(成熟插件多)、风格丰富度(众多模型可供下载,也可以训练自有风格模型)、费用版权(开源免费、可商用)等方面更适合我们的工作场景。

那么如何在实际工作中应用 Stable Diffusion 进行 AI 绘画?
要在实际工作中应用 AI 绘画,需要解决两个关键问题,分别是:图像的精准控制和图像的风格控制。

Science Technology
Stable Diffusion 基础操作
RECRUIT
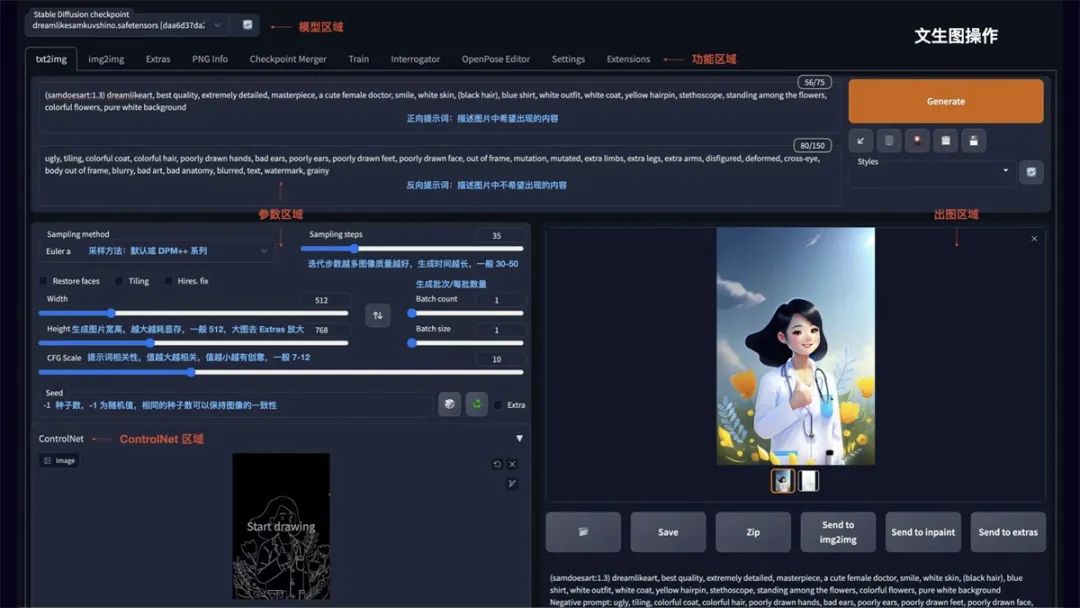
文生图
如图所示 Stable Diffusion WebUI 的操作界面主要分为:模型区域、功能区域、参数区域、出图区域。
txt2img 为文生图功能,重点参数介绍:
正向提示词:描述图片中希望出现的内容
反向提示词:描述图片中不希望出现的内容
Sampling method:采样方法,推荐选择 Euler a 或 DPM++ 系列,采样速度快
Sampling steps:迭代步数,数值越大图像质量越好,生成时间也越长,一般控制在 30-50 就能出效果
Restore faces:可以优化脸部生成
Width/Height:生成图片的宽高,越大越消耗显存,生成时间也越长,一般方图 512x512,竖图 512x768,需要更大尺寸,可以到 Extras 功能里进行等比高清放大
CFG:提示词相关性,数值越大越相关,数值越小越不相关,一般建议 7-12 区间
Batch count/Batch size:生成批次和每批数量,如果需要多图,可以调整下每批数量
Seed:种子数,-1 表示随机,相同的种子数可以保持图像的一致性,如果觉得一张图的结构不错,但对风格不满意,可以将种子数固定,再调整 prompt 生成
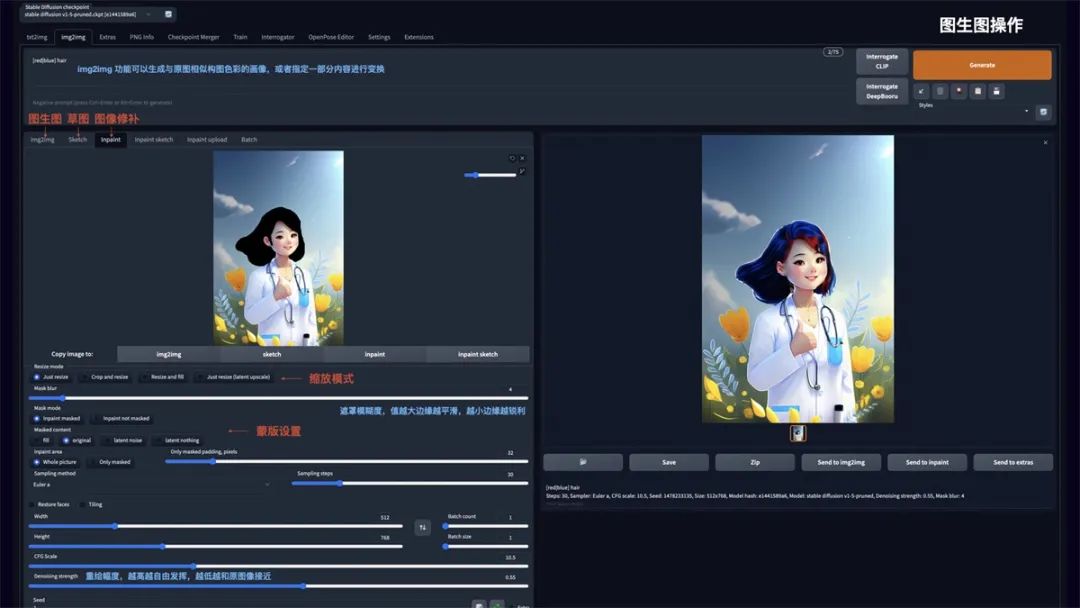
图生图
img2img 功能可以生成与原图相似构图色彩的画像,或者指定一部分内容进行变换。可以重点使用 Inpaint 图像修补这个功能:
Resize mode:缩放模式,Just resize 只调整图片大小,如果输入与输出长宽比例不同,图片会被拉伸。Crop and resize 裁剪与调整大小,如果输入与输出长宽比例不同,会以图片中心向四周,将比例外的部分进行裁剪。Resize and fill 调整大小与填充,如果输入与输出分辨率不同,会以图片中心向四周,将比例内多余的部分进行填充
Mask blur:蒙版模糊度,值越大与原图边缘的过度越平滑,越小则边缘越锐利
Mask mode:蒙版模式,Inpaint masked 只重绘涂色部分,Inpaint not masked 重绘除了涂色的部分
Masked Content:蒙版内容,fill 用其他内容填充,original 在原来的基础上重绘
Inpaint area:重绘区域,Whole picture 整个图像区域,Only masked 只在蒙版区域
Denoising strength:重绘幅度,值越大越自由发挥,越小越和原图接近
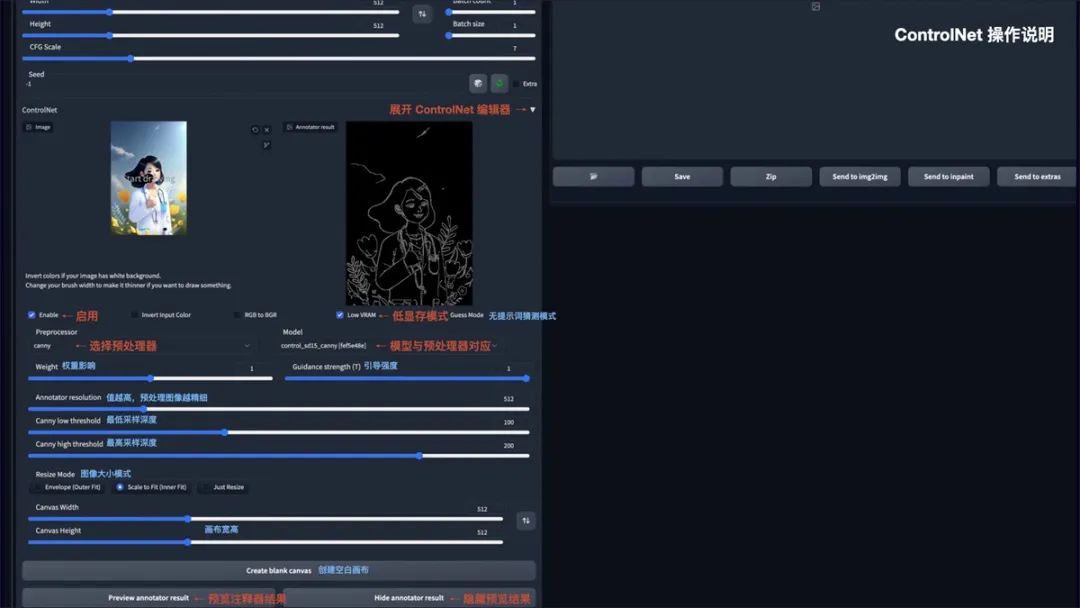
ControlNet
安装完 ControlNet 后,在 txt2img 和 img2img 参数面板中均可以调用 ControlNet。操作说明:
Enable:启用 ControlNet
Low VRAM:低显存模式优化,建议 8G 显存以下开启
Guess mode:猜测模式,可以不设置提示词,自动生成图片
Preprocessor:选择预处理器,主要有 OpenPose、Canny、HED、Scribble、Mlsd、Seg、Normal Map、Depth
Model:ControlNet 模型,模型选择要与预处理器对应
Weight:权重影响,使用 ControlNet 生成图片的权重占比影响
Guidance strength(T):引导强度,值为 1 时,代表每迭代 1 步就会被 ControlNet 引导 1 次
Annotator resolution:数值越高,预处理图像越精细
Canny low/high threshold:控制最低和最高采样深度
Resize mode:图像大小模式,默认选择缩放至合适
Canvas width/height:画布宽高
Create blank canvas:创建空白画布
Preview annotator result:预览注释器结果,得到一张 ControlNet 模型提取的特征图片
Hide annotator result:隐藏预览图像窗口
LoRA 模型训练说明
前面提到 LoRA 模型具有训练速度快,模型大小适中(100MB 左右),配置要求低(8G 显存),能用少量图片训练出风格效果的优势。
以下简要介绍该模型的训练方法:
第 1 步:数据预处理
在 Stable Diffusion WebUI 功能面板中,选择 Train 训练功能,点选 Preprocess images 预处理图像功能。在 Source directory 栏填入你要训练的图片存放目录,在 Destination directory 栏填入预处理文件输出目录。width 和 height 为预处理图片的宽高,默认为 512x512,建议把要训练的图片大小统一改成这个尺寸,提升处理速度。勾选 Auto focal point crop 自动焦点裁剪,勾选 Use deepbooru for caption 自动识别图中的元素并打上标签。点击 Preprocess 进行图片预处理。
第 2 步:配置模型训练参数
在这里可以将模型训练放到 Google Colab 上进行,调用 Colab 的免费 15G GPU 将大大提升模型训练速度。LoRA 微调模型训练工具我推荐使用 Kohya,运行
配置训练参数:
先在 content 目录建立 training_dir/training_data 目录,将步骤 1 中的预处理文件上传至该数据训练目录。然后配置微调模型命名和数据训练目录,在 Download Pretrained Model 栏配置需要参考的预训练模型文件。其余的参数可以根据需要调整设置。
第 3 步:训练模型
参数配置完成后,运行程序即可进行模型训练。训练完的模型将被放到 training_dir/output 目录,我们下载 safetensors 文件格式的模型,存放到 stable-diffusion-webui/models/Lora 目录中即可调用该模型。由于直接从 Colab 下载速度较慢,另外断开 Colab 连接后也将清空模型文件,这里建议在 Extras 中配置 huggingface 的 Write Token,将模型文件上传到 huggingface 中,再从 huggingface File 中下载,下载速度大大提升,文件也可进行备份。

2. Prompt 语法技巧
文生图模型的精髓在于 Prompt 提示词,如何写好 Prompt 将直接影响图像的生成质量。
提示词结构化
Prompt 提示词可以分为 4 段式结构:画质画风 + 画面主体 + 画面细节 + 风格参考
画面画风:主要是大模型或 LoRA 模型的 Tag、正向画质词、画作类型等
画面主体:画面核心内容、主体人/事/物/景、主体特征/动作等
画面细节:场景细节、人物细节、环境灯光、画面构图等
风格参考:艺术风格、渲染器、Embedding Tag 等

提示词语法
提示词排序:越前面的词汇越受 AI 重视,重要事物的提示词放前面
增强/减弱:(提示词:权重数值),默认 1,大于 1 加强,低于 1 减弱。如 (doctor:1.3)
混合:提示词 | 提示词,实现多个要素混合,如 [red|blue] hair 红蓝色头发混合
+ 和 AND:用于连接短提示词,AND 两端要加空格
分步渲染:[提示词 A:提示词 B:数值],先按提示词 A 生成,在设定的数值后朝提示词 B 变化。如[dog
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

