
- 1短视频剪辑的10个常用技巧!附短视频素材网站!新手也能轻松学会_短视频剪辑的步骤和技巧
- 239、PHP 实现二叉树的下一个结点(含源码)
- 3ElasticSearch新增字段_elasticsearch 新增字段
- 4传统目标检测算法综述_传统的目标检测算法综述
- 5chatgpt赋能Python-pythontotur_pythontutor
- 6SSRF—服务器请求伪造 漏洞详解_ssrf服务端请求伪造
- 7华为CANN要替代英伟达CUDA,比鸿蒙替代安卓还难么?
- 8链栈(栈的链式储存结构)
- 9Java数据结构-栈的实现_java栈的实现
- 10easyadmin layui js监听返回结果,进行token验证防止连点
上手步骤解析,快速实现 Hive 数据库表的读写分离!
赞
踩

背景
为了在 Hive 数据库中实现对数据表操作的细粒度控制,我们在创建 Amazon EMR 集群的时候,需要启用 Kerberos 和 Apache Ranger 等安全组件。默认情况下,集群本身并不会具备细粒度的控制,例如对数据表的增删改查操作等。但是,引入 Kerberos 和 Apache Ranger 会让系统变的更复杂,管理和运维难道也增加。
有时候我们可能并不需要对数据表中的内容进行非常细粒度的控制,例如某个字段的读写控制,而只是希望让数据表本身能够实现读写分离。例如,我们希望产生数据的应用系统能够对数据表进行增删改查操作;而对于分析团队,只需要提供只读操作。
本文将详细描述如何在 EMR 集群里对 Hive 下的某个数据库中的表实现读写分离。
客户实际场景和架构说明
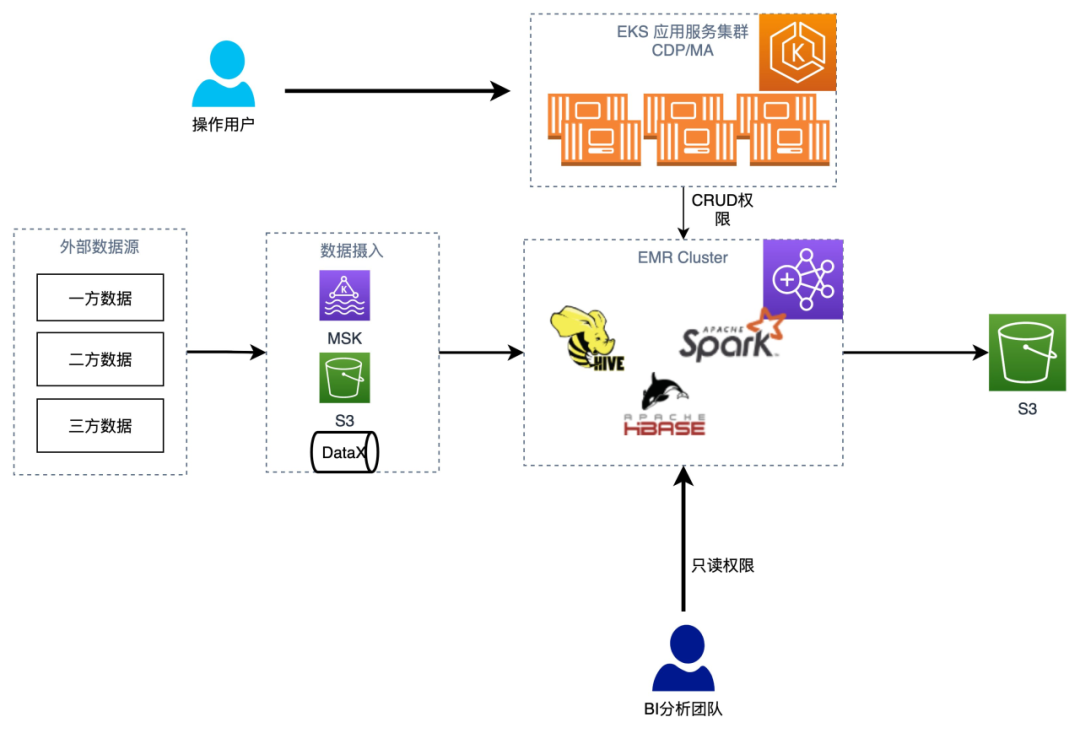
1.初始状态:整个数仓系统采用 Hive,构建在 Amazon EMR 上,数仓的访问权限只能通过其 CDP/MA 应用进行访问,不对外开放其它用户。
2.经过一段时间运行后,系统积累了大量的数据。企业的 BI 分析团队,也希望能够通过 BI 工具访问数仓系统。系统提供方不希望 BI 团队能够修改和删除数仓中的表,避免因为误操作导致系统崩溃。
3.在运行的EMR 集群上无法 Enable Kerbose和 Ranger。
现状的 EMR 集群的配置信息
EMR 版本号 :6.10.0
组件:Hive 3.1.3
Master(1 台):xlarge,Core(3 台):m5.2xlarge
具体实现步骤
修改 EMR 集群 hive-site 参数
在 EMR 控制台配置如下 hive-site 参数:
- < property>
- < name>hive.security.authorization.enabled< /name>
- < value>true< /value>
- < description>enable or disable the hive client authorization< /description>
- < /property>< property>
- < name>hive.security.authorization.createtable.owner.grants< /name>
- < value>ALL< /value>
- < description>the privileges automatically granted to the owner whenever a table gets created. An example like "select,drop" will grant select and drop privilege to the owner of the table< /description>
- < /property>
左右滑动查看更多
1、进入 EMR 集群

2、进入配置页面

3、对集群节点的 Instance group configurations 进行配置

选择实例组,点击右上角的 Reconfigure,添加上面说的两项内容,然后保存
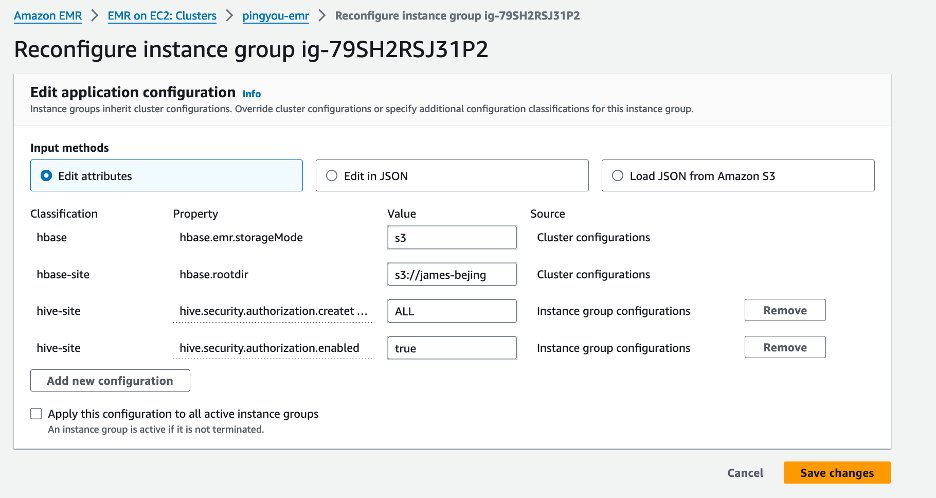
对其它实例组做同样的配置。
在 master 节点上创建 linux 的只读用户
1、先进入集群
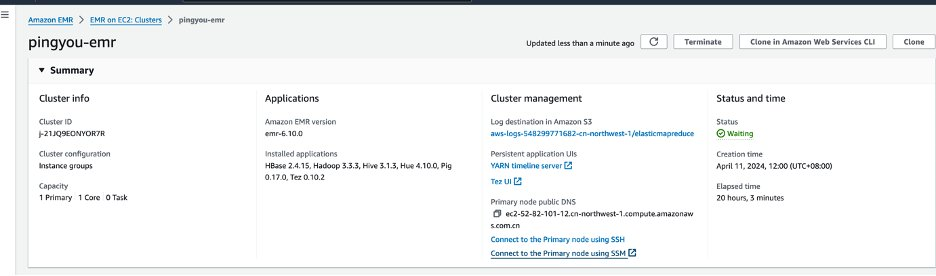
2、打开 Master 节点的控制 console

依次执行如下命令:
1)创建一个 linux 用户:adduser pingyou
2)切换到 hadoop 用户:sudo su – hadoop
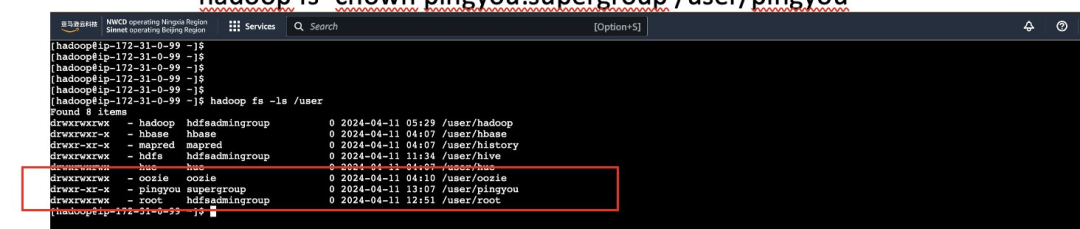
3)通过 hadoop 创建一个 pingyou 的用户目录,让 pingyou 这个用户有权限访问hdfs
执行如下命令:hadoop fs -mkdir /user/pingyou
然后给 pingyou 这个用户相应的权限:hadoop fs -chown pingyou:supergroup /user/pingyou
4)进入 hive (进入 hive 的一定是创建数据库和表的这个用户,我这边用的是 hadoop 这个用户)
执行 grant 权限,将相应的表的 select 权限赋予 pingyou 这个用户
进入自己的数据库,然后给权限:GRANT SELECT ON TABLE my_table TO USER pingyou;
如下图所示:

测试验证
1、用上一步创建的用户 pingyou 登陆
退出 hive,退出当前 hadoop 用户,然后进入到刚才创建的 pingyou 这个用户

2、测试增删改操作
进入 hive,进入数据库:use test_db;
执行 truncate,drop,create,insert 操作,测试验证

3、测试 select 操作

本篇作者

黄海波
亚马逊云科技高级架构师。负责亚马逊云科技合作伙伴相关解决方案的建设以及合作伙伴生态合作。与合作伙伴一起,根据客户需求,分析其在技术架构层面所遇到的挑战和未来的方向,设计和落地基于亚马逊云科技平台和合作伙伴产品的架构方案。有丰富的系统设计和研发经验。

叶骏
亚马逊云科技资深解决方案架构师。拥有超过 18 年的零售行业、制造行业以及数字营销领域的技术产品研发和解决方案架构经验。目前专注于将亚马逊云科技的技术应用于实际解决方案,为客户实现技术创新和成功的技术落地。


星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
点击阅读原文查看博客,获得更详细内容
听说,点完下面4个按钮
就不会碰到bug了!


