
- 1大数据·小算法-实用的用户行为研究方法_大数据算法 用户行为数据
- 2计算机毕业设计之基于hadoop的外卖数据分析系统设计与实现_基于hadoop的外卖订单数据分析系统的设计与实现
- 3APPnium 自动化实践 :第一步adb 连接手机
- 4使用RawInputDevices实现快捷键
- 5论文阅读_用字典提升基于BERT的中文标注效果_使用 bert classifier torch 中文 打标签
- 6Spring MVC学习笔记之Spring MVC组件HandlerAdapter_handlerfunctionadapter类是做什么
- 7虚拟机怎样使用代理服务器上网,VMware虚拟机使用NAT模式上网的方法
- 8总结新老的Python程序员常犯的一些错误(满满的干货)_代码只有第一次使用有效
- 9Hadoop Pipes “Server failed to authenticate”错误及解决_failed to authenticate with server: spnegoerror (1
- 10开发必备的100个 Flutter 开源精品项目
HDFS分布式文件系统详解(Hadoop)
赞
踩
HDFS详解(Hadoop)
Hadoop 分布式文件系统(Hadoop Distributed File System,HDFS)是 Apache Hadoop 生态系统的核心组件之一,它是设计用于存储大规模数据集并运行在廉价硬件上的分布式文件系统。

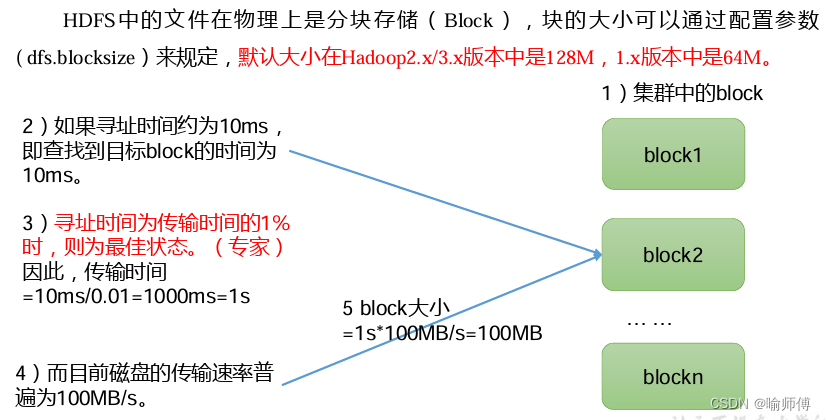
1. 分布式存储:
- HDFS 将文件分割成若干块(
Block),并将这些块分布式地存储在集群中的多个节点上。默认情况下,每个块的大小为 128 MB(可配置),并且每个块都会被复制到多个节点上以实现容错性。

- 分布式存储的优势在于可以有效地利用集群中的所有节点存储空间,并且通过数据的复制和容错机制,提高了数据的可靠性和可用性。

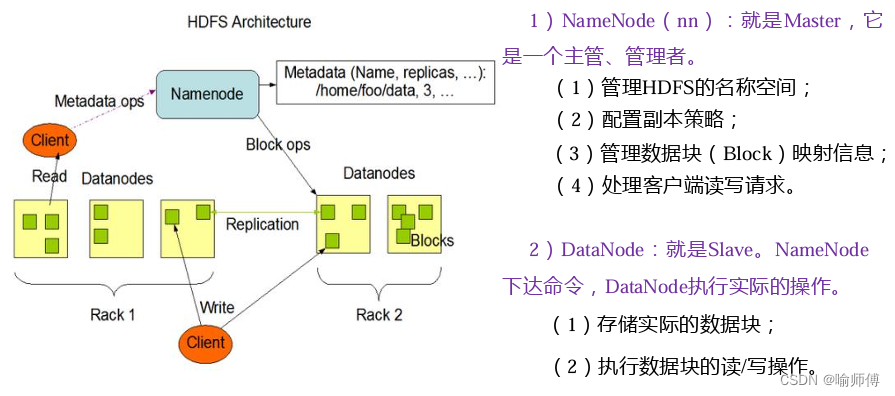
2. 主从架构:
- HDFS 采用主从架构,包括一个
NameNode和多个DataNode组成。

- NameNode 负责管理文件系统的命名空间和存储元数据信息,而 DataNode 负责存储实际的数据块。
NameNode记录了文件的目录结构、文件与数据块的映射关系以及数据块的复制情况等元数据信息。DataNode负责存储数据块,并向 NameNode 定期汇报数据块的状态。
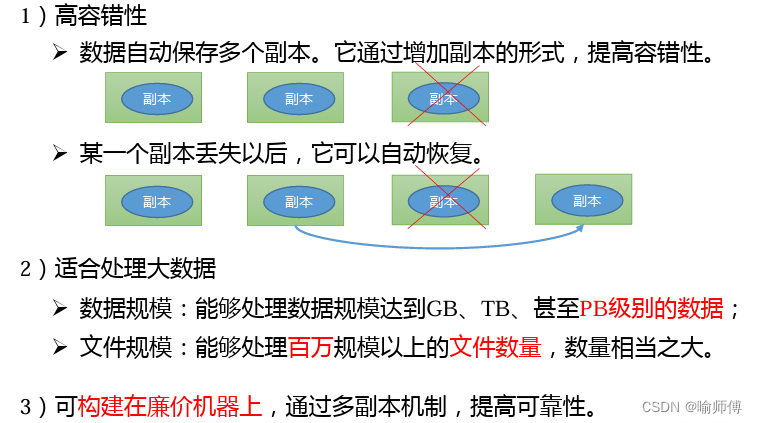
3. 容错性和可靠性:
-
HDFS 提供了多种容错机制来确保数据的可靠性和一致性。其中,数据的复制是最重要的机制之一,每个数据块默认会被复制到集群中的多个节点上。

-
当某个节点发生故障或数据损坏时,HDFS 可以通过复制的数据块在其他节点上恢复数据,从而保证数据的完整性和可靠性。
4. 高吞吐量:
- HDFS 的设计目标之一是实现高吞吐量的数据访问。为了实现这一目标,HDFS 采用了批量读写和数据本地化等策略,尽可能地减少了网络传输的开销。
- 此外,HDFS 还支持数据流式处理和数据并行处理等特性,可以满足大规模数据处理和分析的需求。
5. 数据一致性:
- HDFS 采用了一致性模型,确保了数据的一致性和正确性。在数据写入和读取过程中,HDFS 会维护一致性语义,确保用户能够看到最新的数据内容。

- 此外,HDFS 还支持一些一致性保证,例如数据块的写入顺序保证等,以确保数据的一致性和可靠性。
6.使用场景

6.1适宜场景
-
大数据分析:HDFS 为存储大规模数据提供了可靠的基础,适用于各种大数据分析任务,如数据挖掘、机器学习、统计分析等。通过 Hadoop MapReduce 或其他大数据处理框架,可以对存储在 HDFS 上的数据进行高效的分布式计算和分析。
-
日志处理:许多互联网和移动应用生成大量的日志数据,HDFS 可以作为存储这些日志数据的平台。通过将日志数据写入 HDFS,可以轻松地进行日志分析、用户行为分析、系统性能监控等任务。
-
数据仓库:HDFS 可以作为数据仓库的底层存储系统,用于存储结构化和非结构化的数据。结合数据仓库解决方案,如 Apache Hive、Apache HBase 等,可以实现数据的高效查询、数据仓库建模和数据集成等功能。
-
实时数据处理:尽管 HDFS 本身不适合存储实时数据,但可以与其他实时数据处理系统集成,如 Apache Kafka、Apache Spark Streaming 等。通过将实时数据写入 HDFS,并结合实时处理系统进行流式处理,可以实现实时数据分析和实时报告生成等应用。
-
备份和归档:由于 HDFS 提供了数据的可靠性和容错性,因此可以将其用作备份和归档的存储解决方案。通过将数据备份到 HDFS,并定期进行数据归档,可以确保数据的安全性和可用性。
-
数据湖:HDFS 可以作为数据湖(Data Lake)的核心存储,用于存储各种类型和格式的数据。结合数据湖解决方案,如 Apache Atlas、Apache Ranger 等,可以实现数据的统一管理、数据治理和数据安全等功能。
6.2不适宜场景
-
小型数据集:HDFS 设计用于存储大规模数据集,如果数据规模相对较小,使用 HDFS 可能会带来不必要的复杂性和开销。对于小型数据集,传统的文件系统或云存储服务可能更为合适。
-
低延迟要求:HDFS 优化了数据写入和读取的吞吐量,但并不适合对低延迟有极高要求的应用场景。因为 HDFS 不支持像传统文件系统那样的低延迟数据访问。
-
频繁的小文件操作:HDFS 的设计是为了存储大型数据文件,而不是大量小文件。如果应用需要频繁地处理大量小文件,那么 HDFS 的元数据操作和数据复制可能会成为性能瓶颈。
-
高度动态的数据访问模式:HDFS 更适合于批处理和长期存储,对于频繁变化的数据或需要快速更新的数据集,HDFS 可能不是最佳选择。因为 HDFS 的设计目标是高可靠性和一致性,而不是频繁变化的数据更新。
-
需要原子性操作和事务支持:HDFS 不支持原子性操作和事务处理,因此不适合需要强一致性和事务支持的应用场景。对于此类需求,应该选择支持事务处理的分布式数据库或存储系统。
-
不需要容错性和数据复制的场景:如果应用对数据的容错性和复制没有特别要求,或者数据可以通过其他手段进行备份和保护,那么使用 HDFS 可能会带来不必要的复杂性和成本。


