
- 1ARM Trusted Firmware User Guide_linux-firmware20220411
- 2MySQL8版本升级(RPM包)8.0.11升级到8.0.25_mysql 8.0.11 升级
- 3mysql主从同步恢复数据_如何恢復MySQL主从数据一致性
- 4疯了、Spring 惊奇大漏洞。。。_spring反序列化 漏洞
- 5工业镜头与普通镜头有什么区别?
- 6prometheus变量_Prometheus配置文件说明
- 7esxi硬盘卸载_esxi 删除硬盘
- 8Word2Vec导学第二部分 - 负采样_word2vec负采样例子
- 9ChatGLM2-6B部署_chatglm2-6b 部署
- 10自己做的一个用于生成DICOM文件的服务器
LangChain实践-Data Connection(数据连接)之Vector Store(向量数据库)_langchain怎么加载向量数据库
赞
踩
一、向量数据库概述
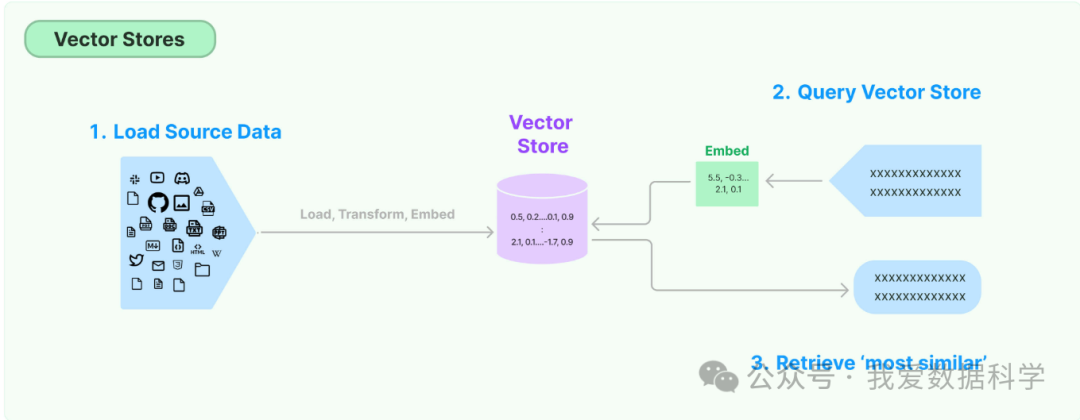
存储和搜索非结构化数据的最常见方法之一是将其嵌入并存储生成的嵌入向量,然后在查询时嵌入非结构化查询并检索与嵌入查询“最相似”的嵌入向量。向量存储负责为您存储嵌入数据并执行向量搜索。
向量数据库是一种将数据存储为高维向量的数据库,高维向量是特征或属性的数学表示。每个向量都有一定数量的维度,根据数据的复杂性和粒度,可以从数十到数千不等。
向量通常是通过对原始数据(如文本、图像、音频、视频等)应用某种转换或嵌入函数来生成的。嵌入函数可以基于各种方法,如机器学习模型、词嵌入和特征提取算法。
向量数据库的主要优点是,它允许基于数据的向量距离或相似性进行快速和准确的相似性搜索和检索。
这意味着不用使用基于精确匹配或预定义标准查询数据库的传统方法,而是可以使用向量数据库根据语义或上下文含义查找最相似或最相关的数据。
为什么需要向量数据库
可以通过将向量嵌入到向量数据库中来索引它们,通过搜索周围向量来定位相关的信息。
在传统领域,开发人员可以使用不同类型的机器学习模型来自动从扫描文档和照片等数据中提取元数据。然后用向量索引信息,通过关键字和向量的混合搜索改善搜索结果,还可以将语义理解与相关性排名结合起来。
最新的生成式人工智能(GenAI)的创新带来了大模型,它可以生成文本并处理复杂的人机交互。例如,一些模型允许用户描述风景,然后创建与描述相匹配的图片。但是生成模型在提供不正确的信息时容易产生幻觉。向量数据库正好可以帮助解决这个问题。通过向量数据库补充生成人工智能模型和外部知识库,以确保它们提供可靠的信息。
主流的向量数据库
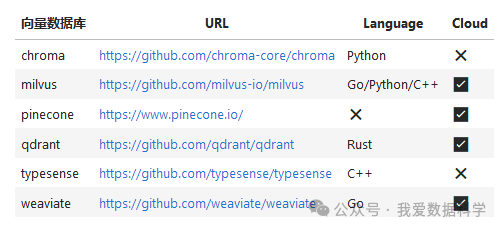
二、Chroma数据库
向量数据库 Chroma 是一种专门设计用来高效管理和查询向量数据的数据库系统。Chroma 通过其高效的数据结构和算法优化,能够快速处理和检索大量的向量数据。
Chroma是一款开源的向量数据库,它使用向量相似度搜索技术,可以快速有效地存储和检索大规模高维向量数据。它的应用场景包括推荐系统、图像和视频搜索、自然语言处理等领域,可以帮助用户快速地找到相似的数据和信息。
Chroma是一款应用嵌入式数据库,以包的形式嵌入到我们的代码,Chroma的优点就是简单,如果你在开发LLM应用需要一个向量数据库实现LLM记忆功能,需要支持文本相似语言搜索,又不想安装独立的向量数据库,Chroma是不错的选择。
以下是 Chroma 向量数据库的一些主要特点:
-
高效的向量索引:Chroma 使用高效的索引结构,如倒排索引、KD-树或基于图的索引,以加快向量搜索速度;
-
支持多种相似度度量:它支持多种向量相似度度量标准,包括欧氏距离、余弦相似度等,使其可以广泛应用于不同的应用场景;
-
可扩展性和弹性:Chroma 能够支持水平扩展,适应大规模数据集的需要。同时,它也能有效处理数据的动态变化,适应快速发展的存储需求;
-
易于集成和使用:Chroma 设计有易于使用的API接口,支持多种编程语言接入,便于开发者在不同的系统和应用中集成使用;
-
实时性能优化:Chroma 优化了查询处理过程,支持实时的数据查询和更新,满足实时分析和决策的需求。
三、Chroma快速上手
Chroma的目标是帮助用户更加便捷地构建大模型应用,更加轻松的将知识(knowledge)、事实(facts)和技能(skills)等我们现实世界中的文档整合进大模型中。
Chroma提供的工具:
-
存储文档数据和它们的元数据
-
嵌入
-
搜索
Chroma的设计优先考虑:
-
足够简单并且提升开发者效率
-
搜索之上再分析
-
追求快(性能)
安装
pip install chromadb -i https://pypi.tuna.tsinghua.edu.cn/simple
- 1
初始化
import chromadb``chroma_client = chromadb.Client()
- 1
创建一个合集
合集(collection)在chroma数据库中的作用就类似表,存储向量数据(包括文档和其他源数据)的地方,下面创建一个集合:
# 创建集合``collection = chroma_client.create_collection(name="test")
- 1
添加数据
Chroma会存储我们的数据,并根据文本数据的向量创建专门的向量索引方便后面查询。
使用内置的嵌入模型计算向量
-
documents参数就是需要写入的文本数据数组,支持一次插入多条数据
-
metadatas是每条写入的数据关联的一些属性
-
ids 是每条写入数据的id
# 假设这里是需要存储的文本``text1 = "This is a document"``text2 = "This is another document"`` ``# 使用内置的嵌入模型计算向量``collection.add(` `documents=[text1,text2],` `metadatas=[{"source": "my_source"}, {"source": "my_source"}],` `ids=["id1", "id2"]``)
- 1

Chroma 支持使用 id .delete 从集合中删除项目。与每个项目关联的嵌入、文档和元数据将被删除。⚠️ 当然,这是一个破坏性的行动,无法撤销。
collection.delete(` `ids=["id1","id2"],``)
- 1
查询数据
results = collection.query(` `query_texts=["This is a query document about hawaii"], # Chroma will embed this for you` `n_results=2 # how many results to return``)``print(results)
- 1
{'ids': [['id1', 'id2']], 'distances': [[1.0404009819030762, 1.2430799007415771]], 'metadatas': [[None, None]], 'embeddings': None, 'documents': [['This is a document about pineapple', 'This is a document about oranges']], 'uris': None, 'data': None}
- 1
其中n为n个最相似的结果。默认情况下,Chroma中的数据是存储在内存中,重启程序数据就丢了,当然你可以设置Chroma的数据持久化到硬盘,这样程序启动的时候会去加载磁盘中的数据。
持久化数据
client = chromadb.PersistentClient(path="test")
- 1
这样在运行代码后,在你指定的位置会新建一个chroma.sqlite3文件。
四、Chroma Embeddings算法
hroma默认使用的是all-MiniLM-L6-v2模型来进行embeddings
魔搭平台ModelScope里的通用中文embeddings算法(damo/nlp_corom_sentence-embedding_chinese-base),他有768维的向量。
https://modelscope.cn/models/iic/nlp_corom_sentence-embedding_chinese-base/summary
coROM中文通用文本表示模型
文本表示是自然语言处理(NLP)领域的核心问题, 其在很多NLP、信息检索的下游任务中发挥着非常重要的作用。近几年, 随着深度学习的发展,尤其是预训练语言模型的出现极大的推动了文本表示技术的效果, 基于预训练语言模型的文本表示模型在学术研究数据、工业实际应用中都明显优于传统的基于统计模型或者浅层神经网络的文本表示模型。这里, 我们主要关注基于预训练语言模型的文本表示。
文本表示示例, 输入一个句子, 输入一个固定维度的连续向量:
-
输入: 吃完海鲜可以喝牛奶吗?
-
输出: [0.27162,-0.66159,0.33031,0.24121,0.46122,…]
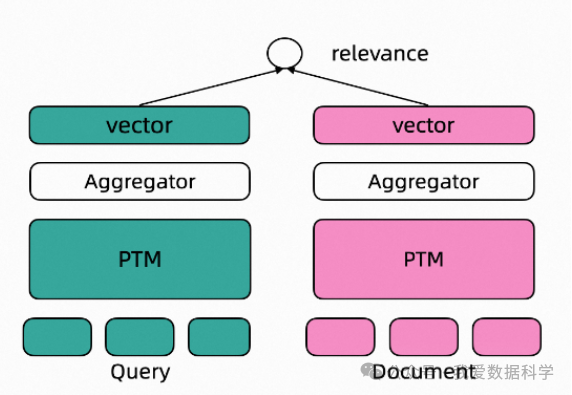
Dual Encoder文本表示模型
基于监督数据训练的文本表示模型通常采用Dual Encoder框架, 如下图所示。在Dual Encoder框架中, Query和Document文本通过预训练语言模型编码后, 通常采用预训练语言模型[CLS]位置的向量作为最终的文本向量表示。基于标注数据的标签, 通过计算query-document之间的cosine距离度量两者之间的相关性。
使用方式和范围
使用方式:
- 直接推理, 对给定文本计算其对应的文本向量表示,向量维度768
使用范围:
- 本模型可以使用在通用领域的文本向量表示及其下游应用场景, 包括双句文本相似度计算、query&多doc候选的相似度排序
如何使用
在ModelScope框架上,提供输入文本(默认最长文本长度为128),即可以通过简单的Pipeline调用来使用coROM文本向量表示模型。ModelScope封装了统一的接口对外提供单句向量表示、双句文本相似度、多候选相似度计算功能
代码示例
安装
pip install modelscope -i https://pypi.tuna.tsinghua.edu.cn/simple``pip install addict -i https://pypi.tuna.tsinghua.edu.cn/simple``pip install datasets==2.16.0 -i https://pypi.tuna.tsinghua.edu.cn/simple``pip install oss2 -i https://pypi.tuna.tsinghua.edu.cn/simple``pip install sortedcontainers -i https://pypi.tuna.tsinghua.edu.cn/simple
- 1
from modelscope.models import Model``from modelscope.pipelines import pipeline``from modelscope.utils.constant import Tasks``model_id = "damo/nlp_corom_sentence-embedding_chinese-base"``pipeline_se = pipeline(Tasks.sentence_embedding,` `model=model_id)``inputs = {` `"source_sentence": ["吃完海鲜可以喝牛奶吗?"],` `"sentences_to_compare": [` `"不可以,早晨喝牛奶不科学",` `"吃了海鲜后是不能再喝牛奶的,因为牛奶中含得有维生素C,如果海鲜喝牛奶一起服用会对人体造成一定的伤害",` `"吃海鲜是不能同时喝牛奶吃水果,这个至少间隔6小时以上才可以。",` `"吃海鲜是不可以吃柠檬的因为其中的维生素C会和海鲜中的矿物质形成砷"` `]` `}`` ``result = pipeline_se(input=inputs)``print (result)
- 1
{'text_embedding': array([[ 0.05729477, 0.20573795, 0.17653942, ..., 0.24166013,` `-0.08281942, 0.01529923],` `[-0.058939 , -0.06724129, 0.21177901, ..., 0.09431249,` `0.0062068 , -0.10968875],` `[ 0.15444988, 0.2245397 , 0.05703048, ..., 0.21452697,` `-0.05757068, 0.36385244],` `[-0.04844466, 0.290426 , 0.08930054, ..., -0.10127009,` `-0.04289719, 0.47542858],` `[ 0.40530455, 0.10854281, 0.2716445 , ..., -0.19292738,` `-0.10013288, 0.15214866]], dtype=float32), 'scores': [55.69992446899414, 75.31268310546875, 71.80325317382812, 54.557762145996094]}
- 1

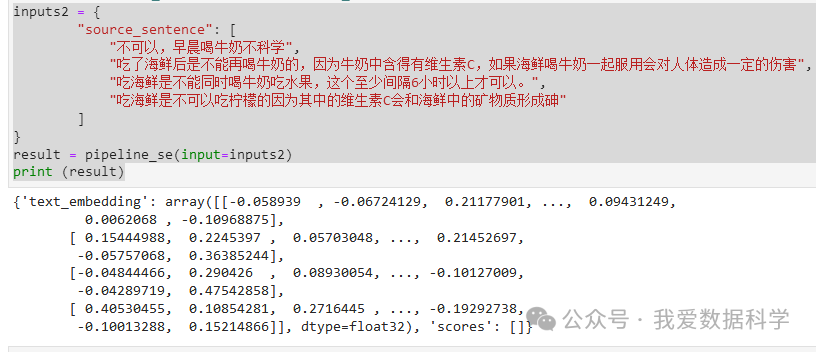
inputs2 = {` `"source_sentence": [` `"不可以,早晨喝牛奶不科学",` `"吃了海鲜后是不能再喝牛奶的,因为牛奶中含得有维生素C,如果海鲜喝牛奶一起服用会对人体造成一定的伤害",` `"吃海鲜是不能同时喝牛奶吃水果,这个至少间隔6小时以上才可以。",` `"吃海鲜是不可以吃柠檬的因为其中的维生素C会和海鲜中的矿物质形成砷"` `]``}``result = pipeline_se(input=inputs2)``print (result)
- 1
{'text_embedding': array([[-0.058939 , -0.06724129, 0.21177901, ..., 0.09431249,` `0.0062068 , -0.10968875],` `[ 0.15444988, 0.2245397 , 0.05703048, ..., 0.21452697,` `-0.05757068, 0.36385244],` `[-0.04844466, 0.290426 , 0.08930054, ..., -0.10127009,` `-0.04289719, 0.47542858],` `[ 0.40530455, 0.10854281, 0.2716445 , ..., -0.19292738,` `-0.10013288, 0.15214866]], dtype=float32), 'scores': []}
- 1
五、Chroma对象存储
Chroma对象为用户提供了两种不同的数据存储方法:from_texts和from_documents。如果用户持有的数据是以字符串列表形式存在的,那么用户可以选择使用from_texts方法加载和存储字符串类型的数据。如果用户的数据是由Document对象组成的,那么应该选择from_documents方法。
尽管这两种方法在参数上基本相似,但其背后的操作有所不同。事实上,from_documents方法会从Document对象列表中提取page_content和metadata的内容,将其转换为两个列表,之后再调用from_texts方法处理。
无论选择from_texts还是from_documents,在使用时都需要注意一个非常关键的参数-persist_directory。该参数用于指定数据存储的目标路径。
Chroma提供了多种相关性检索方法:
-
similarity_search:通过文本进行相关性检索,并返回检索到的Document列表。
-
similarity_search_by_vector:使用嵌入处理过的向量进行检索,并返回检索到的Document列表。
-
similarity_search_with_relevance_scores:通过文本进行相关性检索,并返回检索到的Document对象和相关性分数组成的元组列表。
-
max_marginal_relevance_search:使用文本进行最大边际相关性(MMR)检索,并返回检索到的Document列表。
-
max_marginal_relevance_search_by_vector:使用经过向量化计算后的向量进行最大边际相关性检索,并返回检索到的Document列表
上面集中检索方法返回的条数和它们共有的参数k有关,默认为4。当然,上面的检索方法也提供了移动的方法。
第1个示例
from langchain.vectorstores import Chroma``from langchain.embeddings import ModelScopeEmbeddings`` ``texts = [` `'在这里!',` `'你好啊!',` `'你叫什么名字?',` `'我的朋友们都称呼我为小明',` `'哦,那太棒了!'``]`` ``model_id = "damo/nlp_corom_sentence-embedding_chinese-base"``embeddings = ModelScopeEmbeddings(model_id=model_id)`` ``# 存储数据``db = Chroma.from_texts(` `texts, embeddings,` `persist_directory='./chroma_test/'``)`` ``# 相关性搜索``query = '谈话中和名字相关的有哪些?'``docs = db.similarity_search(query, k=2)``for doc in docs:` `print(doc.page_content)
- 1
你叫什么名字?``你好啊!
- 1
第2个示例
from langchain_community.document_loaders import TextLoader``from langchain.embeddings import ModelScopeEmbeddings``from langchain.text_splitter import CharacterTextSplitter``from langchain_community.vectorstores import Chroma``model_id = "damo/nlp_corom_sentence-embedding_chinese-base"``embeddings = ModelScopeEmbeddings(model_id=model_id)``# 加载文档,将其拆分为块,嵌入每个块并将其加载到向量存储中。``raw_documents = TextLoader('example_data/三体.txt',encoding='utf-8').load()``text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)``documents = text_splitter.split_documents(raw_documents)``db = Chroma.from_documents(documents, embeddings)
- 1
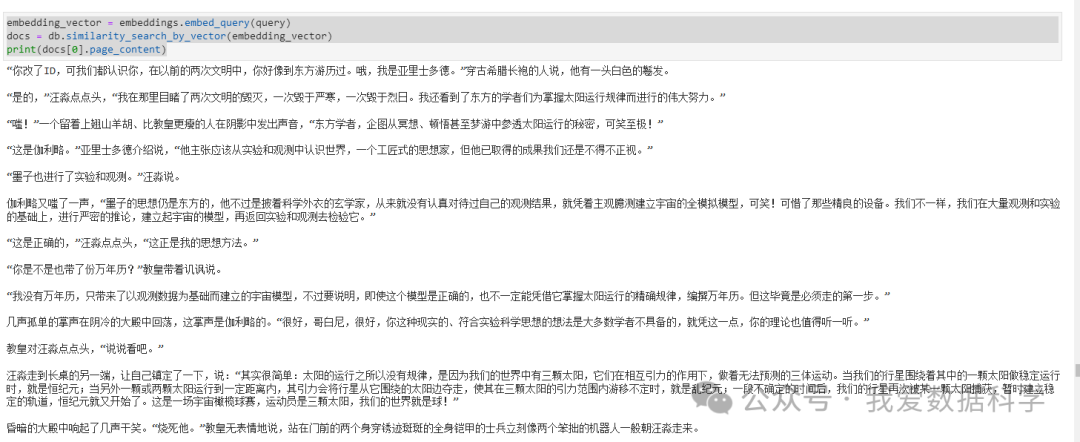
Similarity search(通过文本进行相关性搜索)
query ="汪淼"``docs = db.similarity_search(query)``print(docs[0].page_content)
- 1
“你改了ID,可我们都认识你,在以前的两次文明中,你好像到东方游历过。哦,我是亚里士多德。”穿古希腊长袍的人说,他有一头白色的鬈发。`` ``“是的,”汪淼点点头,“我在那里目睹了两次文明的毁灭,一次毁于严寒,一次毁于烈日。我还看到了东方的学者们为掌握太阳运行规律而进行的伟大努力。”`` ``“嗤!”一个留着上翘山羊胡、比教皇更瘦的人在阴影中发出声音,“东方学者,企图从冥想、顿悟甚至梦游中参透太阳运行的秘密,可笑至极!”`` ``“这是伽利略。”亚里士多德介绍说,“他主张应该从实验和观测中认识世界,一个工匠式的思想家,但他已取得的成果我们还是不得不正视。”`` ``“墨子也进行了实验和观测。”汪淼说。`` ``伽利略又嗤了一声,“墨子的思想仍是东方的,他不过是披着科学外衣的玄学家,从来就没有认真对待过自己的观测结果,就凭着主观臆测建立宇宙的全模拟模型,可笑!可惜了那些精良的设备。我们不一样,我们在大量观测和实验的基础上,进行严密的推论,建立起宇宙的模型,再返回实验和观测去检验它。”`` ``“这是正确的,”汪淼点点头,“这正是我的思想方法。”`` ``“你是不是也带了份万年历?”教皇带着讥讽说。`` ``“我没有万年历,只带来了以观测数据为基础而建立的宇宙模型,不过要说明,即使这个模型是正确的,也不一定能凭借它掌握太阳运行的精确规律,编撰万年历。但这毕竟是必须走的第一步。”`` ``几声孤单的掌声在阴冷的大殿中回荡,这掌声是伽利略的。“很好,哥白尼,很好,你这种现实的、符合实验科学思想的想法是大多数学者不具备的,就凭这一点,你的理论也值得听一听。”`` ``教皇对汪淼点点头,“说说看吧。”`` ``汪淼走到长桌的另一端,让自己镇定了一下,说:“其实很简单:太阳的运行之所以没有规律,是因为我们的世界中有三颗太阳,它们在相互引力的作用下,做着无法预测的三体运动。当我们的行星围绕着其中的一颗太阳做稳定运行时,就是恒纪元;当另外一颗或两颗太阳运行到一定距离内,其引力会将行星从它围绕的太阳边夺走,使其在三颗太阳的引力范围内游移不定时,就是乱纪元;一段不确定的时间后,我们的行星再次被某一颗太阳捕获,暂时建立稳定的轨道,恒纪元就又开始了。这是一场宇宙橄榄球赛,运动员是三颗太阳,我们的世界就是球!”`` ``昏暗的大殿中响起了几声干笑。“烧死他。”教皇无表情地说,站在门前的两个身穿锈迹斑斑的全身铠甲的士兵立刻像两个笨拙的机器人一般朝汪淼走来。
- 1

Similarity search by vector
可以使用similarity_search_by_vector对给定的嵌入向量进行文档相似性搜索,它接受一个嵌入向量作为参数,而不是字符串。
查询相同,结果也相同。
embedding_vector = embeddings.embed_query(query)``docs = db.similarity_search_by_vector(embedding_vector)``print(docs[0].page_content)
- 1
“你改了ID,可我们都认识你,在以前的两次文明中,你好像到东方游历过。哦,我是亚里士多德。”穿古希腊长袍的人说,他有一头白色的鬈发。`` ``“是的,”汪淼点点头,“我在那里目睹了两次文明的毁灭,一次毁于严寒,一次毁于烈日。我还看到了东方的学者们为掌握太阳运行规律而进行的伟大努力。”`` ``“嗤!”一个留着上翘山羊胡、比教皇更瘦的人在阴影中发出声音,“东方学者,企图从冥想、顿悟甚至梦游中参透太阳运行的秘密,可笑至极!”`` ``“这是伽利略。”亚里士多德介绍说,“他主张应该从实验和观测中认识世界,一个工匠式的思想家,但他已取得的成果我们还是不得不正视。”`` ``“墨子也进行了实验和观测。”汪淼说。`` ``伽利略又嗤了一声,“墨子的思想仍是东方的,他不过是披着科学外衣的玄学家,从来就没有认真对待过自己的观测结果,就凭着主观臆测建立宇宙的全模拟模型,可笑!可惜了那些精良的设备。我们不一样,我们在大量观测和实验的基础上,进行严密的推论,建立起宇宙的模型,再返回实验和观测去检验它。”`` ``“这是正确的,”汪淼点点头,“这正是我的思想方法。”`` ``“你是不是也带了份万年历?”教皇带着讥讽说。`` ``“我没有万年历,只带来了以观测数据为基础而建立的宇宙模型,不过要说明,即使这个模型是正确的,也不一定能凭借它掌握太阳运行的精确规律,编撰万年历。但这毕竟是必须走的第一步。”`` ``几声孤单的掌声在阴冷的大殿中回荡,这掌声是伽利略的。“很好,哥白尼,很好,你这种现实的、符合实验科学思想的想法是大多数学者不具备的,就凭这一点,你的理论也值得听一听。”`` ``教皇对汪淼点点头,“说说看吧。”`` ``汪淼走到长桌的另一端,让自己镇定了一下,说:“其实很简单:太阳的运行之所以没有规律,是因为我们的世界中有三颗太阳,它们在相互引力的作用下,做着无法预测的三体运动。当我们的行星围绕着其中的一颗太阳做稳定运行时,就是恒纪元;当另外一颗或两颗太阳运行到一定距离内,其引力会将行星从它围绕的太阳边夺走,使其在三颗太阳的引力范围内游移不定时,就是乱纪元;一段不确定的时间后,我们的行星再次被某一颗太阳捕获,暂时建立稳定的轨道,恒纪元就又开始了。这是一场宇宙橄榄球赛,运动员是三颗太阳,我们的世界就是球!”`` ``昏暗的大殿中响起了几声干笑。“烧死他。”教皇无表情地说,站在门前的两个身穿锈迹斑斑的全身铠甲的士兵立刻像两个笨拙的机器人一般朝汪淼走来。
- 1
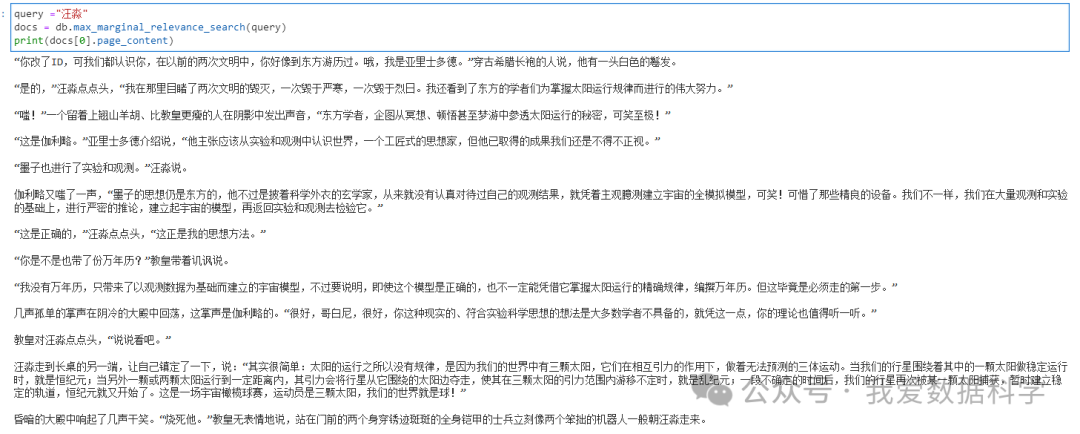
max_marginal_relevance_search(最大边际相关性 ,MMR)
query ="汪淼"``docs = db.max_marginal_relevance_search(query)``print(docs[0].page_content)
- 1
“你改了ID,可我们都认识你,在以前的两次文明中,你好像到东方游历过。哦,我是亚里士多德。”穿古希腊长袍的人说,他有一头白色的鬈发。`` ``“是的,”汪淼点点头,“我在那里目睹了两次文明的毁灭,一次毁于严寒,一次毁于烈日。我还看到了东方的学者们为掌握太阳运行规律而进行的伟大努力。”`` ``“嗤!”一个留着上翘山羊胡、比教皇更瘦的人在阴影中发出声音,“东方学者,企图从冥想、顿悟甚至梦游中参透太阳运行的秘密,可笑至极!”`` ``“这是伽利略。”亚里士多德介绍说,“他主张应该从实验和观测中认识世界,一个工匠式的思想家,但他已取得的成果我们还是不得不正视。”`` ``“墨子也进行了实验和观测。”汪淼说。`` ``伽利略又嗤了一声,“墨子的思想仍是东方的,他不过是披着科学外衣的玄学家,从来就没有认真对待过自己的观测结果,就凭着主观臆测建立宇宙的全模拟模型,可笑!可惜了那些精良的设备。我们不一样,我们在大量观测和实验的基础上,进行严密的推论,建立起宇宙的模型,再返回实验和观测去检验它。”`` ``“这是正确的,”汪淼点点头,“这正是我的思想方法。”`` ``“你是不是也带了份万年历?”教皇带着讥讽说。`` ``“我没有万年历,只带来了以观测数据为基础而建立的宇宙模型,不过要说明,即使这个模型是正确的,也不一定能凭借它掌握太阳运行的精确规律,编撰万年历。但这毕竟是必须走的第一步。”`` ``几声孤单的掌声在阴冷的大殿中回荡,这掌声是伽利略的。“很好,哥白尼,很好,你这种现实的、符合实验科学思想的想法是大多数学者不具备的,就凭这一点,你的理论也值得听一听。”`` ``教皇对汪淼点点头,“说说看吧。”`` ``汪淼走到长桌的另一端,让自己镇定了一下,说:“其实很简单:太阳的运行之所以没有规律,是因为我们的世界中有三颗太阳,它们在相互引力的作用下,做着无法预测的三体运动。当我们的行星围绕着其中的一颗太阳做稳定运行时,就是恒纪元;当另外一颗或两颗太阳运行到一定距离内,其引力会将行星从它围绕的太阳边夺走,使其在三颗太阳的引力范围内游移不定时,就是乱纪元;一段不确定的时间后,我们的行星再次被某一颗太阳捕获,暂时建立稳定的轨道,恒纪元就又开始了。这是一场宇宙橄榄球赛,运动员是三颗太阳,我们的世界就是球!”`` ``昏暗的大殿中响起了几声干笑。“烧死他。”教皇无表情地说,站在门前的两个身穿锈迹斑斑的全身铠甲的士兵立刻像两个笨拙的机器人一般朝汪淼走来。
- 1
那么,如何系统的去学习大模型LLM?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~

篇幅有限,部分资料如下:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/酷酷是懒虫/article/detail/1001152
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

