
- 1滴水石穿_机会留给有准备的人 英文
- 2特洛伊木马 (计算机木马程序)
- 3网络虚拟化
- 4安装Selenium库的方法最终解答!_Python库
- 5【数字图像】数字图像直方图规定化处理的奇妙之旅_数字图像处理直方图规定化实验报告
- 6安装了nltk但仍报错:Resource punkt not found._oserror: `nltk` resource `punkt` is not available
- 7江苏工程职业技术学院软件工程计算机方向毕业设计选题课题参考目录
- 8深度学习中为什么要使用多于一个epoch?_深度学习为什么要多个epoch
- 9【漏洞复现】Hadoop 未授权访问到RCE
- 10Python的pip换源
Elasticsearch 与 OpenSearch:解开向量搜索性能差距_elasticsearch向量检索 速度
赞
踩
作者:来自 Elastic Ugo Sangiorgi
Elasticsearch 的开箱即用的向量搜索速度比 OpenSearch 快 2 到 12 倍。

向量搜索正在彻底改变我们进行相似性搜索的方式,尤其是在人工智能和机器学习等领域。随着向量嵌入模型的日益普及,高效搜索数百万个高维向量的能力变得至关重要。
Elastic 收到了来自社区的大量请求,要求我们澄清 Elasticsearch 和 OpenSearch 之间的性能差异,尤其是在语义搜索/向量搜索领域。鉴于这个主题的重要性,我们进行了性能测试,以提供清晰的、数据驱动的比较 —— 没有歧义,只有直截了当的事实和见解来告知我们的用户。
在为向量数据库提供支持方面,Elastic 和 OpenSearch 采取了明显不同的方法。Elastic 投入巨资优化 Apache Lucene 和 Elasticsearch,以将它们提升为向量搜索应用程序的顶级选择。相比之下,OpenSearch 扩大了其关注范围,集成了其他向量搜索实现并探索 Lucene 的范围之外。我们对 Lucene 的关注是战略性的,这使我们能够在我们的 Elasticsearch 版本中提供高度集成的支持,从而形成一个增强的功能集,其中每个组件都相互补充并增强了其他组件的功能。
本博客详细比较了 Elasticsearch 8.14 和 OpenSearch 2.14 的不同配置和向量引擎。在这次性能分析中,Elasticsearch 被证明是向量搜索操作的卓越平台,即将推出的功能将进一步扩大差异。与 OpenSearch 相比,它在每个基准测试中都表现出色 —— 平均性能提高了 2 倍到 12 倍。这是在使用不同向量数量和维度的场景中得出的,包括 so_vector(2M 向量,768D)、openai_vector(2.5M 向量,1536D)和 density_vector(10M 向量,96D),所有这些都在此存储库中提供,以及用于在 Google Cloud 上配置所有必需基础设施的 Terraform 脚本和用于运行测试的 Kubernetes 清单。
本博客中详述的结果补充了之前发布的第三方验证研究的结果,该研究显示,在最常见的搜索分析操作(文本查询、排序、范围、日期直方图和术语过滤)中,Elasticsearch 比 OpenSearch 快 40%-140%。现在我们可以添加另一个差异化因素:向量搜索。
总结:速度最高提升 12 倍
我们对四个向量数据集进行了重点基准测试,涉及近似 KNN 和精确 KNN 搜索,考虑了不同的大小、维度和配置,总共 40,189,820 个未缓存的搜索请求。结果:Elasticsearch 的向量搜索速度最高比 OpenSearch 快 12 倍,因此需要的计算资源更少。
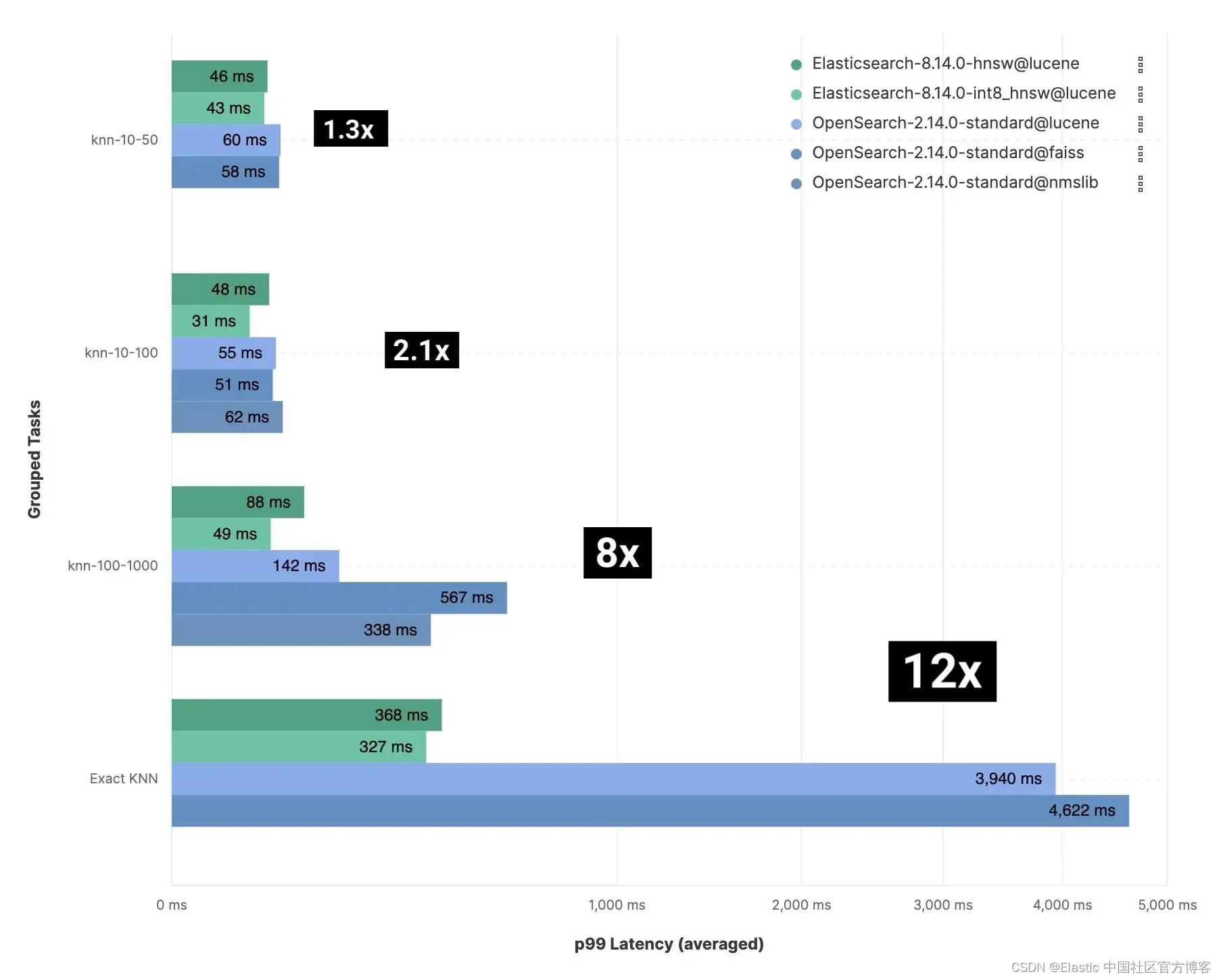
像 knn-10-100 这样的组表示 KNN 搜索,其中 k:10 及 n: 100,。在 HNSW 向量搜索中,k 确定要检索查询向量的最近邻居的数量。它指定要找到多少个相似的向量。n 设置在每个段中要检索的候选向量的数量。更多的候选可以提高准确性,但需要更多的计算资源。
我们还测试了不同的量化技术并利用了特定于引擎的优化,每个轨道、任务和向量引擎的详细结果如下。
精确 KNN 和近似 KNN
在处理不同的数据集和用例时,向量搜索的正确方法会有所不同。在此博客中,所有以 knn-* 表示的任务(如 knn-10-100)都使用近似 KNN,而 script-score-* 则指的是精确 KNN,但它们之间有什么区别,为什么它们很重要?
本质上,如果你处理的是更大的数据集,则首选方法是近似 K-最近邻 (ANN),因为它具有出色的可扩展性。对于可能需要过滤过程的较适中的数据集,精确 KNN 方法是理想的选择。
精确 KNN 使用强力方法,计算一个向量与数据集中每个其他向量之间的距离。然后,它对这些距离进行排序以找到 k 个最近邻居。虽然这种方法可以确保精确匹配,但对于大型高维数据集,它面临着可扩展性挑战。但是,在很多情况下都需要精确 KNN:
- 重新评分:在涉及词汇或语义搜索,然后进行基于向量的重新评分的场景中,精确 KNN 必不可少。例如,在产品搜索引擎中,可以根据文本查询(例如关键字、类别)过滤初始搜索结果,然后使用与过滤项目相关的向量进行更准确的相似度评估。
- 个性化:当处理大量用户时,每个用户都由相对较少数量(例如 100 万)的不同向量表示,按用户特定的元数据(例如 user_id)对索引进行排序并使用向量进行强力评分变得非常有效。这种方法允许根据针对个人用户偏好的精确向量比较进行个性化推荐或内容传递。
因此,精确 KNN 可确保基于向量相似度的最终排名和推荐是精确的,并根据用户偏好进行量身定制。
另一方面,近似 KNN(或 ANN)采用的方法使数据搜索比精确 KNN 更快、更高效,尤其是在大型高维数据集中。ANN 不使用蛮力(brute-force)方法(测量查询与所有点之间的精确最近距离,从而带来计算和扩展挑战),而是使用某些技术有效地重构数据集中可搜索向量的索引和维度。虽然这可能会导致轻微的不准确性,但它显著提高了搜索过程的速度,使其成为处理大型数据集的有效替代方案。
在此博客中,所有以 knn-* 表示的任务(如 knn-10-100)都使用近似 KNN,而 script-score-* 则指的是精确 KNN。
测试方法
虽然 Elasticsearch 和 OpenSearch 在 BM25 搜索操作的 API 方面相似,因为后者是前者的分支,但 Vector Search 并非如此,它是在分支之后引入的。OpenSearch 在算法方面采取了与 Elasticsearch 不同的方法,除了 Lucene 之外,还引入了另外两个引擎 —— nmslib 和 faiss,每个引擎都有特定的配置和限制(例如,OpenSearch 中的 nmslib 不允许使用过滤器,而过滤器是许多用例的必备功能)。
这三个引擎都使用分层可导航小世界 (HNSW) 算法,该算法对于近似最近邻搜索非常有效,在处理高维数据时尤其强大。值得注意的是,faiss 还支持第二种算法 ivf,但由于它需要对数据集进行预训练,因此我们将只关注 HNSW。HNSW 的核心思想是将数据组织成多层连通图,每层代表数据集的不同粒度。搜索从最粗略的顶层开始,然后逐渐向下到越来越精细的层,直到达到基础层。
两个搜索引擎都在受控环境中以相同的条件进行测试,以确保公平的测试环境。所采用的方法类似于之前发布的性能比较,其中 Elasticsearch、OpenSearch 和 Rally 具有专用的节点池。terraform 脚本(与所有来源一起)可用于配置具有以下配置的 Kubernetes 集群:
- 1 个 Elasticsearch 节点池,带有 3 台 e2-standard-32 机器(128GB RAM 和 32 个 CPU)
- 1 个 OpenSearch 节点池,带有 3 台 e2-standard-32 机器(128GB RAM 和 32 个 CPU)
- 1 个 Rally 节点池,带有 2 台 t2a-standard-16 机器(64GB RAM 和 16 个 CPU)
每个 “track - 轨道”(或测试)针对每个配置运行 10 次,其中包括不同的引擎、不同的配置和不同的向量类型。根据 track 的不同,Track 的任务重复次数在 1000 到 10000 次之间。如果 track 中的某个任务由于网络超时而失败,则所有任务都将被丢弃,因此所有结果都代表 track 的开始和结束都没有问题。所有测试结果都经过统计验证,确保改进不是巧合。
详细发现
为什么使用第 99 个百分位而不是平均延迟进行比较?假设某个社区的平均房价。平均价格可能表明该地区房价昂贵,但仔细观察后可能会发现,大多数房屋的价值要低得多,只有少数豪宅抬高了平均价格。这说明平均价格无法准确代表该地区房屋价值的全部范围。这类似于检查响应时间,平均值可能会隐藏关键问题。
任务
- 使用 k:10 n:50 进行近似 KNN
- 使用 k:10 n:100 进行近似 KNN
- 使用 k:100 n:1000 进行近似 KNN
- 使用 k:10 n:50 和关键字过滤器进行近似 KNN
- 使用 k:10 n:100 和关键字过滤器进行近似 KNN
- 使用 k:100 n:1000 和关键字过滤器进行近似 KNN
- 使用 k:10 n:1000 和关键字过滤器进行近似 KNN 与索引结合使用
- 精确 KNN(脚本分数)
向量引擎
- Elasticsearch 和 OpenSearch 中的 Lucene,均采用 9.10 版本
- OpenSearch 中的 faiss
- OpenSearch 中的 nmslib
向量类型
- Elasticsearch 和 OpenSearch 中的 hnsw
- Elasticsearch 中的 int8_hnsw(具有自动 8 位量化的 HNSW:链接)
- OpenSearch 中的 sq_fp16 hnsw(具有自动 16 位量化的 HNSW:链接)
开箱即用和并发分段搜索
你可能知道,Lucene 是一个用 Java 编写的高性能文本搜索引擎库,是 Elasticsearch、OpenSearch 和 Solr 等许多搜索平台的骨干。Lucene 的核心是将数据组织成分段,这些分段本质上是自包含索引,允许 Lucene 更有效地执行搜索。因此,当你向任何基于 Lucene 的搜索引擎发出搜索时,你的搜索最终将在这些分段中按顺序或并行执行。
OpenSearch 引入了并发分段搜索作为可选标志,默认情况下不使用它,你必须使用特殊索引设置 index.search.concurrent_segment_search.enabled 启用它,详情请见此处,但有一些限制。
另一方面,Elasticsearch 可以开箱即用地同时搜索片段,因此我们在本博客中进行的比较除了考虑不同的向量引擎和向量类型外,还将考虑不同的配置:
- Elasticsearch ootb:开箱即用的 Elasticsearch,具有并发片段搜索;
- OpenSearch ootb:未启用并发片段搜索;
- OpenSearch css:启用并发片段搜索
现在,让我们深入了解每个测试的向量数据集的一些详细结果:
250 万个向量,1536 个维度(openai_vector)
从最简单的 track 开始,但也是维度最大的 track,openai_vector - 它使用 NQ 数据集,该数据集丰富了使用 OpenAI 的 text-embedding-ada-002 模型生成的嵌入。它是最简单的,因为它只测试近似 KNN 并且只有 5 个任务。它在独立(无索引)和索引的同时进行测试,并使用单个客户端和 8 个同时客户端。
任务
- standalone-search-knn-10-100-multiple-clients:使用 8 个客户端同时搜索 250 万个向量,k:10 和 n:100
- standalone-search-knn-100-1000-multiple-clients:使用 8 个客户端同时搜索 250 万个向量,k:100 和 n:1000
- standalone-search-knn-10-100-single-client:使用单个客户端搜索 250 万个向量,k:10 和 n:100
- standalone-search-knn-100-1000-single-client:使用单个客户端搜索 250 万个向量,k:100 和 n:1000
- parallel-documents-indexing-search-knn-10-100:搜索 250 万个向量,同时索引其他向量100000 份文档,k:10 和 n:100
平均 p99 性能概述如下:
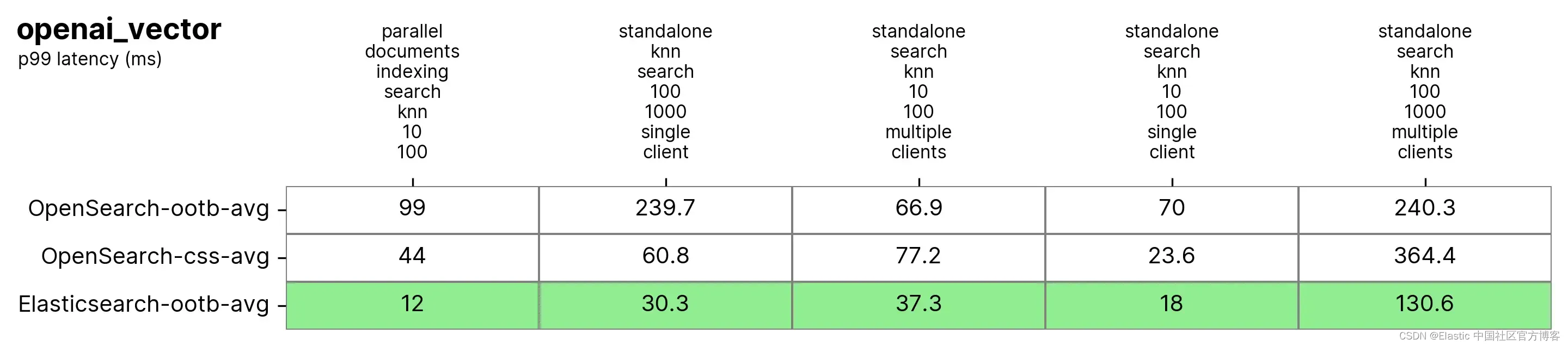
在这里,我们观察到,当使用 k:10 和 n:100 执行向量搜索和索引(即读取+写入)时,Elasticsearch 比 OpenSearch 快 3 到 8 倍,而当不使用相同的 k 和 n 时,Elasticsearch 比 OpenSearch 快 2 到 3 倍。对于 k:100 和 n:1000(standalone-search-knn-100-1000-single-client 和 standalone-search-knn-100-1000-multiple-clients),Elasticsearch 平均比 OpenSearch 快 2 到 7 倍。
详细结果显示了比较的具体案例和向量引擎:
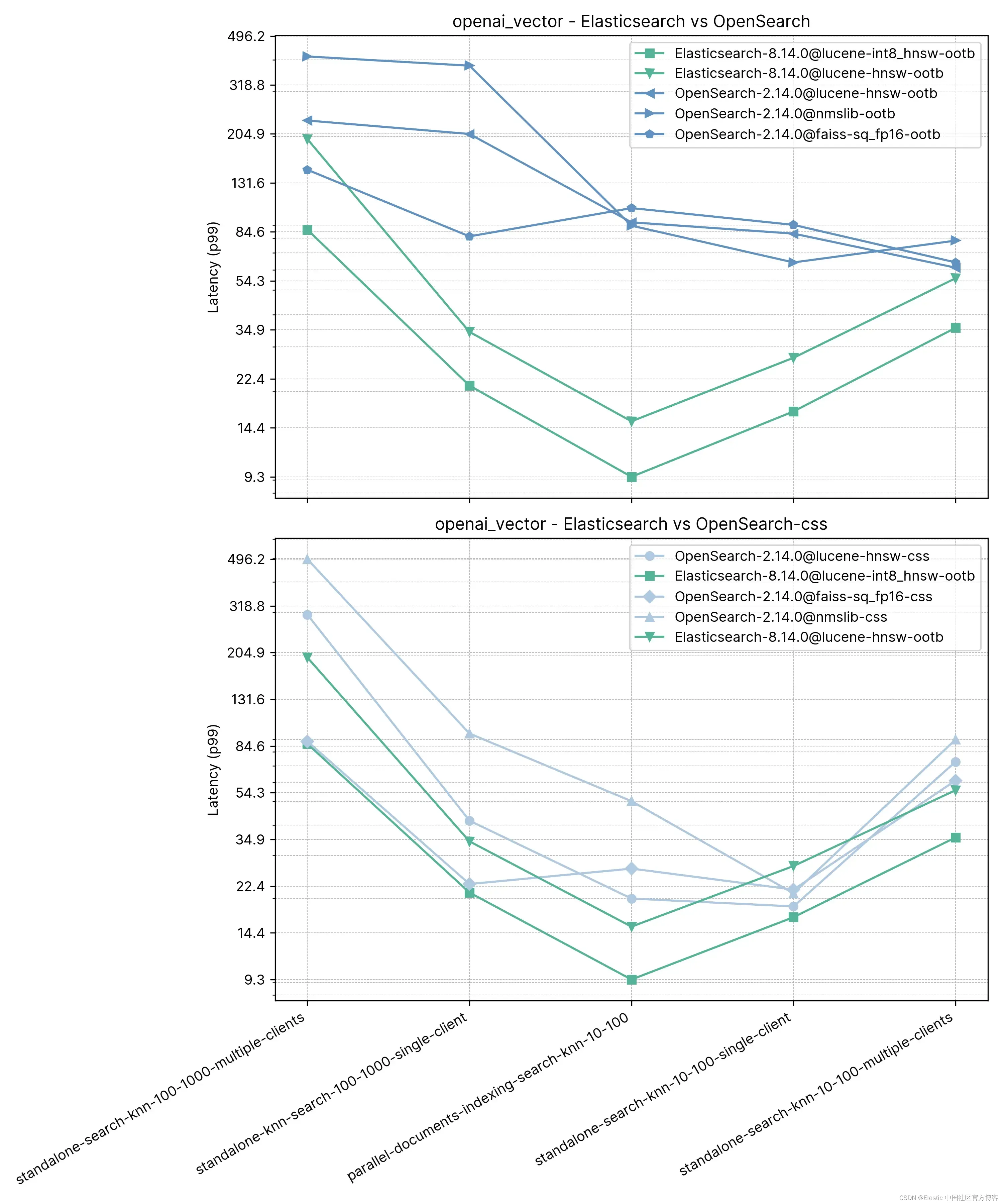
召回率
| knn-recall-10-100 | knn-recall-100-1000 | |
|---|---|---|
| Elasticsearch-8.14.0@lucene-hnsw | 0.969485 | 0.995138 |
| Elasticsearch-8.14.0@lucene-int8_hnsw | 0.781445 | 0.784817 |
| OpenSearch-2.14.0@lucene-hnsw | 0.96519 | 0.995422 |
| OpenSearch-2.14.0@faiss | 0.984154 | 0.98049 |
| OpenSearch-2.14.0@faiss-sq_fp16 | 0.980012 | 0.97721 |
| OpenSearch-2.14.0@nmslib | 0.982532 | 0.99832 |
1000 万个向量,96 个维度 (dense_vector)
dense_vector 中有 1000 万个向量和 96 个维度。它基于 Yandex DEEP1B 图像数据集。该数据集由名为 learn.350M.fbin 的 “样本数据” 文件的前 1000 万个向量创建。搜索操作使用来自 “查询数据” 文件 query.public.10K.fbin 的向量。
Elasticsearch 和 OpenSearch 在该数据集上的表现都非常好,尤其是在强制合并之后,这通常在只读索引上完成,它类似于对索引进行碎片整理以拥有一个可以搜索的 “表”。
任务
每个任务预热 100 个请求,然后测量 1000 个请求
- knn-search-10-100:搜索 1000 万个向量,k:10 和 n:100
- knn-search-100-1000:搜索 1000 万个向量,k:100 和 n:1000
- knn-search-10-100-force-merge:强制合并后搜索 1000 万个向量,k:10 和 n:100
- knn-search-100-1000-force-merge:强制合并后搜索 1000 万个向量,k:100 和 n:1000
- knn-search-100-1000-concurrent-with-indexing:搜索 1000 万个向量,同时更新 5% 的数据集,k:100 和n:1000
- script-score-query:对 2000 个特定向量进行精确 KNN 搜索。
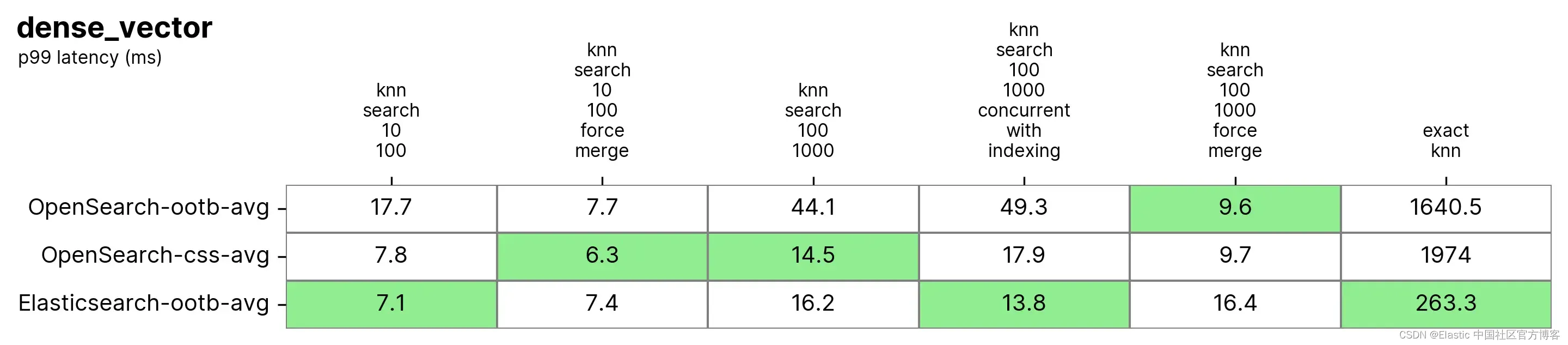
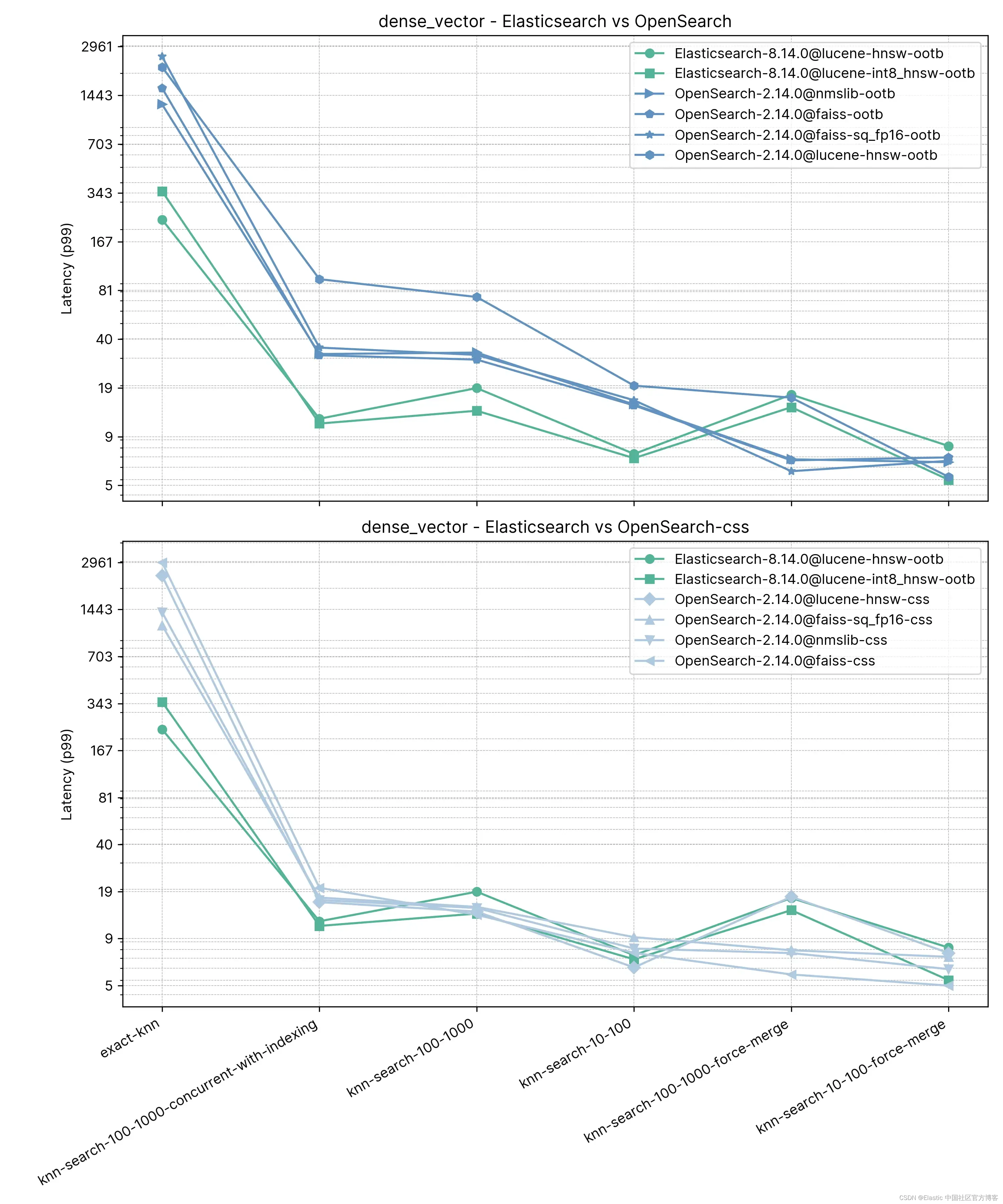
Elasticsearch 和 OpenSearch 在近似 KNN 方面均表现良好。在 knn-search-100-1000-force-merge 和 knn-search-10-100-force-merge 中,当索引合并(即只有一个段)时,使用 nmslib 和 faiss 时,OpenSearch 的表现优于其他引擎,尽管它们都在 15ms 左右,而且非常接近。
但是,当 knn-search-10-100 和 knn-search-100-1000 中的索引有多个段(索引接收其文档更新的典型情况)时,Elasticsearch 将延迟保持在约 ~7ms 和 ~16ms 之间,而所有其他 OpenSearch 引擎都较慢。
此外,当同时搜索和写入索引(knn-search-100-1000-concurrent-with-indexing)时,Elasticsearch 将延迟保持在 15 毫秒以下(13.8 毫秒),几乎比开箱即用的 OpenSearch(49.3 毫秒)快 4 倍,启用并发段搜索时速度更快(17.9 毫秒),但太接近了,没有太大意义。
至于 Exact KNN,差异要大得多:Elasticsearch 比 OpenSearch 快 6 倍(~260 毫秒 vs ~1600 毫秒)。
召回率
| knn-recall-10-100 | knn-recall-100-1000 | |
|---|---|---|
| Elasticsearch-8.14.0@lucene-hnsw | 0.969843 | 0.996577 |
| Elasticsearch-8.14.0@lucene-int8_hnsw | 0.775458 | 0.840254 |
| OpenSearch-2.14.0@lucene-hnsw | 0.971333 | 0.996747 |
| OpenSearch-2.14.0@faiss | 0.9704 | 0.914755 |
| OpenSearch-2.14.0@faiss-sq_fp16 | 0.968025 | 0.913862 |
| OpenSearch-2.14.0@nmslib | 0.9674 | 0.910303 |
200 万个向量,768 个维度 (so_vector)
此 track so_vector 源自 2022 年 4 月 21 日下载的 StackOverflow 帖子转储。它仅包含问题文档 — 所有代表答案的文档都已被删除。每个问题标题都使用句子转换器模型 multi-qa-mpnet-base-cos-v1 编码为向量。此数据集包含前 200 万个问题。
与上一个 track 不同,这里的每个文档除了向量之外还包含其他字段,以支持测试功能,例如带过滤的近似 KNN 和混合搜索。OpenSearch 的 nmslib 在本测试中明显缺失,因为它不支持过滤器。
任务
每个任务都会预热 100 个请求,然后测量 100 个请求。请注意,为了简单起见,对任务进行了分组,因为测试包含 16 种搜索类型 * 2 种不同的 k 值 * 3 种不同的 n 值。
- knn-10-50:搜索 200 万个不使用过滤器的向量,k:10 和 n:50
- knn-10-50-filtered:搜索 200 万个使用过滤器的向量,k:10 和 n:50
- knn-10-50-after-force-merge:搜索 200 万个使用过滤器并强制合并后的向量,k:10 和 n:50
- knn-10-100:搜索 200 万个不使用过滤器的向量,k:10 和 n:100
- knn-10-100-filtered:搜索 200 万个使用过滤器的向量,k:10 和 n:100
- knn-10-100-after-force-merge:搜索 200 万个使用过滤器并强制合并后的向量,k:10 和 n:100
- knn-100-1000:搜索 200 万个不使用过滤器的向量,k:100 和n:1000
- knn-100-1000-filtered:使用过滤器搜索 200 万个向量,k:100 和 n:1000
- knn-100-1000-after-force-merge:使用过滤器搜索 200 万个向量,并在强制合并后搜索,k:100 和 n:1000
- exact-knn:使用和不使用过滤器的精确 KNN 搜索。
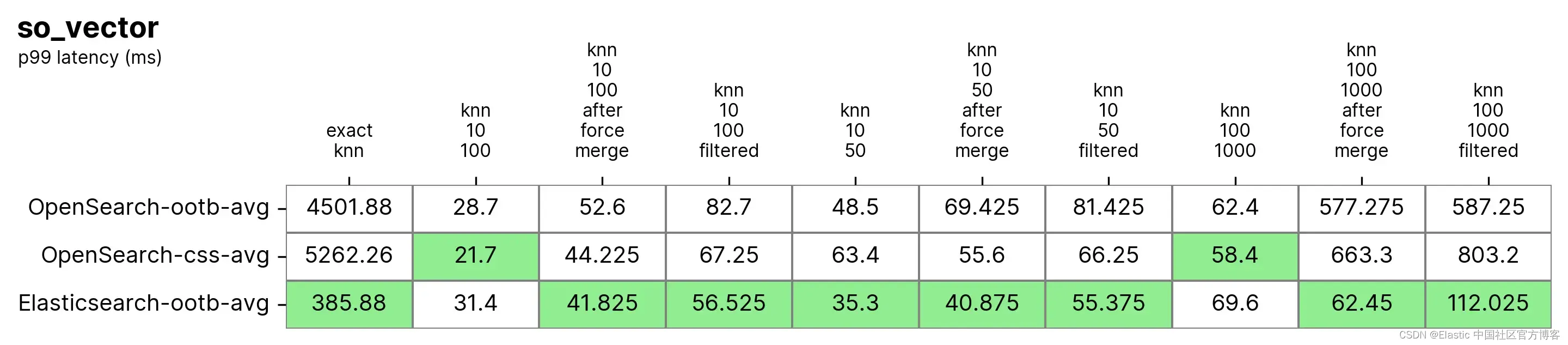
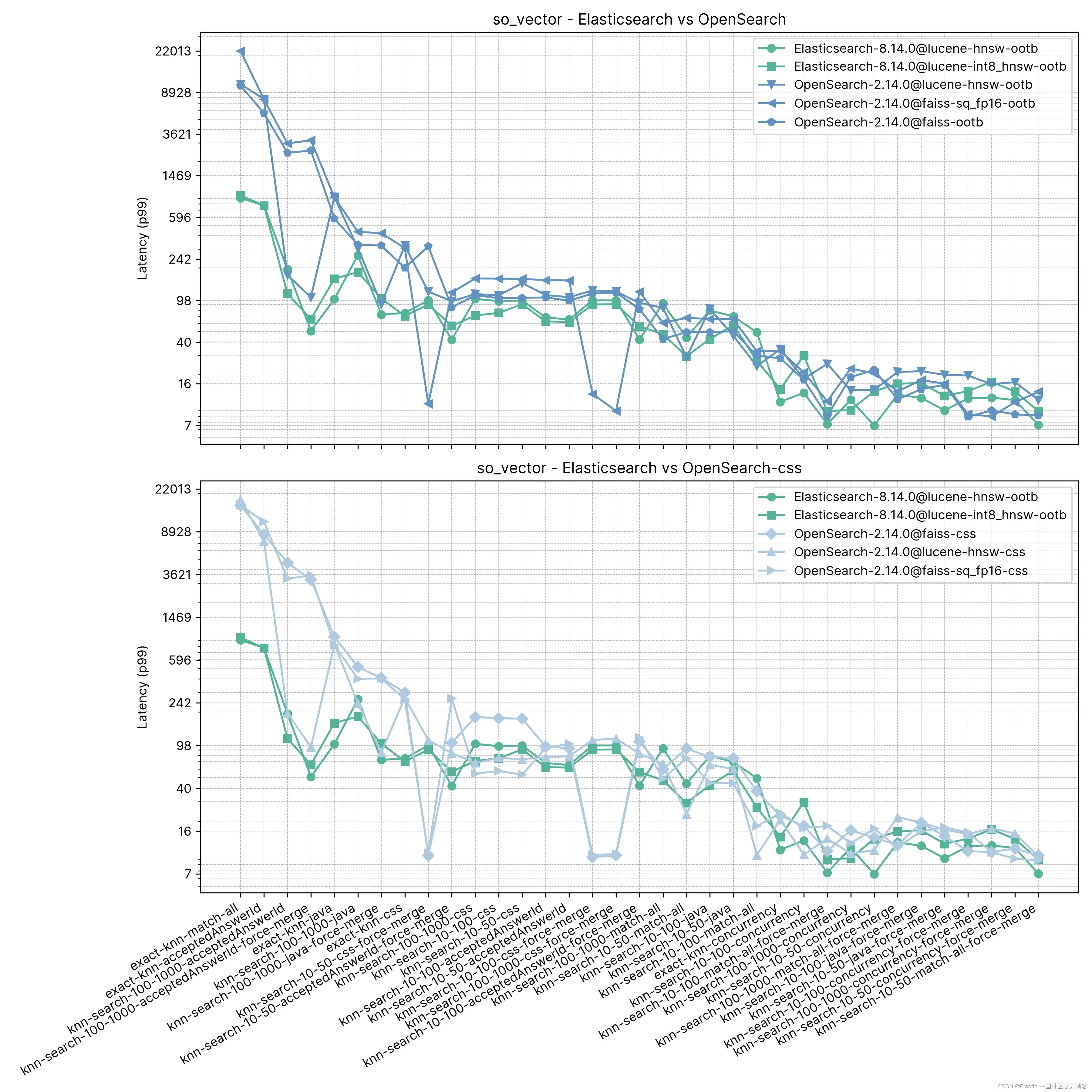
在此测试中,Elasticsearch 始终比 OpenSearch 开箱即用的速度快,只有在两种情况下 OpenSearch 更快,而且快不了多少(knn-10-100 和 knn-100-1000)。涉及 knn-10-50、knn-10-100 和 knn-100-1000 与过滤器结合的任务显示出高达 7 倍的差异(112ms vs 803ms)。
可以理解的是,两种解决方案的性能在 “强制合并 ”后似乎趋于平衡,knn-10-50-after-force-merge、knn-10-100-after-force-merge 和 knn-100-1000-after-force-merge 就是明证。在这些任务上,faiss 更快。
Exact KNN 的性能再次大不相同,Elasticsearch 这次比 OpenSearch 快 13 倍(~385ms vs ~5262ms)。
召回率
| knn-recall-10-100 | knn-recall-100-1000 | knn-recall-10-50 | |
|---|---|---|---|
| Elasticsearch-8.14.0@lucene-hnsw | 1 | 1 | 1 |
| Elasticsearch-8.14.0@lucene-int8_hnsw | 1 | 0.986667 | 1 |
| OpenSearch-2.14.0@lucene-hnsw | 1 | 1 | 1 |
| OpenSearch-2.14.0@faiss | 1 | 1 | 1 |
| OpenSearch-2.14.0@faiss-sq_fp16 | 1 | 1 | 1 |
| OpenSearch-2.14.0@nmslib | 0.9674 | 0.910303 | 0.976394 |
Elasticsearch 和 Lucene 明显胜出
在 Elastic,我们不断创新 Apache Lucene 和 Elasticsearch,以确保我们能够为搜索和检索用例提供一流的向量数据库,包括 RAG(检索增强生成)。我们最近的进步大大提高了性能,使向量搜索比以前更快、更节省空间,这得益于 Lucene 9.10 的优势。本博客介绍了一项研究,该研究表明,在比较最新版本时,Elasticsearch 比 OpenSearch 快 16 倍。
值得一提的是,这两种产品都使用相同版本的 Lucene(Elasticsearch 8.14 发行说明和 OpenSearch 2.14 发行说明)。
Elastic 的创新步伐不仅会为我们的本地和 Elastic Cloud 客户带来更多,还会为使用我们 stateless 平台的客户带来更多。将提供对 int4 标量量化等功能,并进行严格测试,以确保客户能够使用这些技术而不会显著降低召回率,类似于我们对 int8 的测试。
由于人工智能和机器学习应用的激增,向量搜索效率正成为现代搜索引擎中不可或缺的功能。对于寻求能够满足高容量、高复杂度向量数据需求的强大搜索引擎的组织来说,Elasticsearch 是最佳选择。
无论是扩展现有平台还是启动新项目,将 Elasticsearch 集成到向量搜索需求中都是一项战略举措,将带来切实的长期利益。凭借其久经考验的性能优势,Elasticsearch 有望为下一波搜索创新奠定基础。
准备好自己尝试一下了吗?开始免费试用。
Elasticsearch 集成了 LangChain、Cohere 等工具。加入我们的高级语义搜索网络研讨会,构建你的下一个 GenAI 应用程序!
原文:Elasticsearch vs. OpenSearch: Unraveling the Vector Search Performance Gap — Elastic Search Labs

