- 1unity入门教程(非常详细)从零基础入门到精通,看完这一篇就够了_unity完全自学教程
- 2IDEA教程_config your intellisence settings to help主要是干什么的
- 32024年最全Windows下MySQL的详细安装教程_mysql windows安装教程csdn,太厉害了_windows安装mysql
- 4Intel FPGA高速设计代码原则总结
- 5基于bert的中文语义匹配模型,判断两句话是不是同一个意思
- 6算法沉淀——BFS 解决最短路问题(leetcode真题剖析)_leetcode bfs题
- 7com.fasterxml.jackson.databind.JsonMappingException: (was java.lang.NullPointExcepti 单属性VO在序列化时空指针异常
- 8华为OD机试C卷-- 贪吃的猴子(Java & JS & Python & C)
- 9动手学深度学习 - 3.11. 模型选择、欠拟合和过拟合_动手学深度学习 3.11
- 10MySQL的视图(介绍、创建、修改、更新、重命名和删除)MySQL的存储过程(入门、变量定义、参数传递和流程控制)_mysql 修改视图
MYSQL 查找单个字段或者多个字段重复数据,清除重复数据,保留一条_mysql查询重复数据保留一条
赞
踩
前文
重复数据的情况分为两种:
单个字段 数据重复
多个字段 数据重复
所以该篇的内容就是包括
单个字段的重复数据查找 与 去重
多个字段的重复数据查找 与 去重
正文
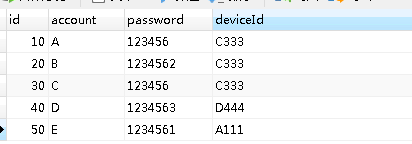
示例 accountinfo 表数据如下:
场景一 单个字段重复数据查找 & 去重
我们要把上面这个表中 单个字段 account字段相同的数据找出来。
思路 分三步 简述:
第一步
要找出重复数据,我们首先想到的就是,既然是重复,那么 数量就是大于 1 就算是重复。 那就是 count 函数 。
因为我们要排查的是 单个 字段account ,那么就是需要按照 account 字段 维度 去分组。 那就是 group by 函数。
那么我们第一步写出来的mysql 语句是:
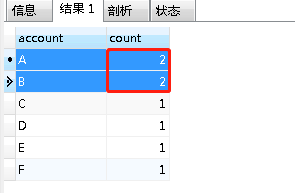
SELECT account ,COUNT(account) as count FROM accountinfo GROUP BY account;查询结果如下:
第二步
没错,如我们所想,count大于1的即是 account为 A 和 B 的数据。
那么我们稍作筛选,只把count大于1的数据的account 找出来。
第二步,利用having 拼接筛选条件,写出来的mysql 语句是:
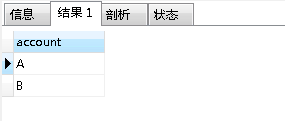
SELECT account FROM accountinfo GROUP BY account HAVING COUNT(account) > 1;查询结果如下:
第三步
重复的account数据 A B 都找出来了,接下来我们只需要把account为A 和 B 的其他数据都一起查询出来。
那就是利用第二步查出来的数据做为子查询条件,使用 IN 函数。
第三步写出来的mysql 语句是:
- SELECT * FROM accountinfo WHERE account IN
- (
- SELECT account FROM accountinfo GROUP BY account HAVING COUNT(account) > 1
- );
查询结果如下:
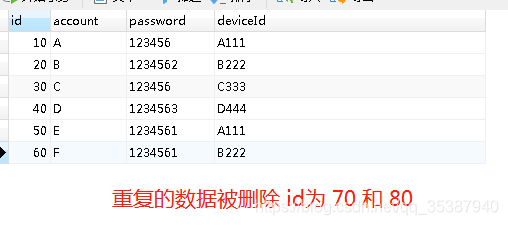
可以看到重复的数据都被我们筛选出来了。
那么怎么去重呢? 也就是说,把重复的数据删掉。
不,准确点应该说是,重复的数据都只留下一条即可,这才是去重。
紧接着上面,毕竟去重的前提肯定是找重,上面我们已经实现找重了,所以紧接着进行去重。
按照我们步骤三得到的图,就是我们需要删掉一条account为A的数据, 一条account为B的数据,去重结果图应该如下:
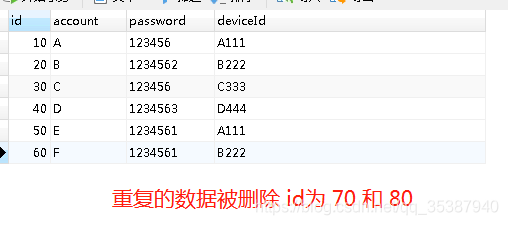
思路也分三步简述:
第一步
删掉数据,我们一般选择接住主键来删除,所以我们考虑从id入手。
再来看我们的重复数据:
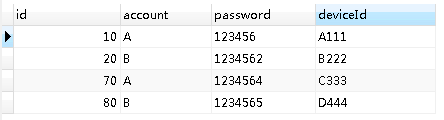
如果我们想在这些重复数据里面,每个都保留一条,如 account 为 A 中 id=10 的数据, account 为B 中 id=20 的数据 ,那么第一步我们就得把这两条数据从上面的
最终得到的数据 筛选出来,也就是按照 account分组,保留里面id最小的数据。使用 group by 和 min 函数。
所以去重我们第一步写出来的mysql 语句是:
- SELECT min(id) as id from (
-
-
- SELECT * FROM accountinfo WHERE account IN
- (
- SELECT account FROM accountinfo GROUP BY account HAVING COUNT(account) > 1
- )
-
-
- ) a GROUP BY a.account
查询结果如下:
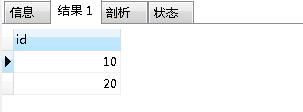
第二步
想要保留的数据已经找出来了,那么接下来就是从所有的重复数据里面 删掉 不为 我们保留的数据 即可 。
那么就是找出我们需要删除的id, 使用 not in 函数。
所以去重我们第二步写出来的mysql 语句是:
- SELECT t1.id FROM (
-
- SELECT id FROM accountinfo WHERE account IN ( SELECT account FROM accountinfo GROUP BY account HAVING COUNT(account) > 1) ) t1
-
- WHERE t1.id NOT IN (
-
-
- SELECT min(id) AS id FROM (
-
-
- SELECT * FROM accountinfo WHERE account IN
- (
- SELECT account FROM accountinfo GROUP BY account HAVING COUNT(account) > 1
- )
-
-
- ) a GROUP BY a.account
-
- )
查询的结果为:
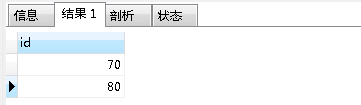
对这个sql语句稍作文字说明:
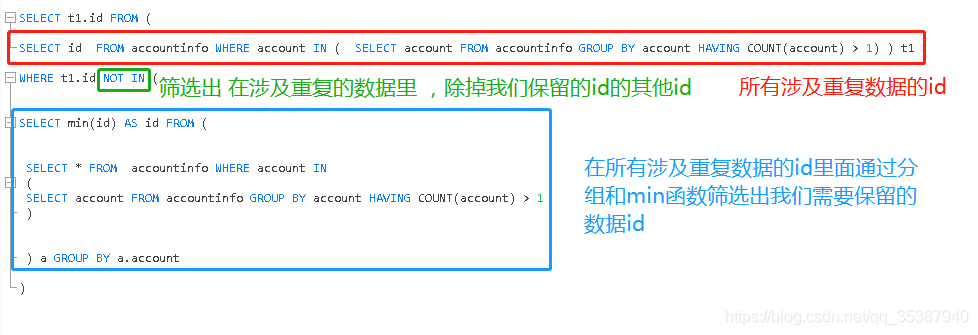
第三步,删掉第二步找出来的数据即可,根据id删除。
所以第三步写出来的mysql语句是:
- DELETE FROM accountinfo WHERE id IN (
-
- SELECT t1.id FROM (
-
- SELECT id FROM accountinfo WHERE account IN ( SELECT account FROM accountinfo GROUP BY account HAVING COUNT(account) > 1) ) t1
-
- WHERE t1.id NOT IN (
-
-
- SELECT min(id) AS id FROM (
-
-
- SELECT * FROM accountinfo WHERE account IN
- (
- SELECT account FROM accountinfo GROUP BY account HAVING COUNT(account) > 1
- )
-
-
- ) a GROUP BY a.account
-
- )
-
- )
执行结果如下图:
场景二 多个字段重复数据查找 & 去重
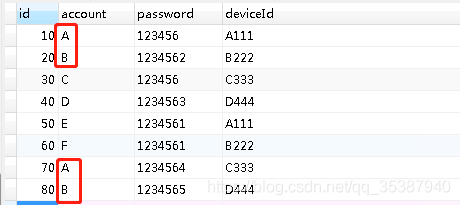
示例 accountinfo 表数据如下:
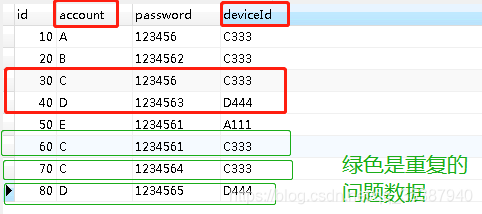
想要去重,我们的首要想到的也是先把 重复数据 找出来。
现在的重复定义是, account 和 deviceId 都相同的 时候,这种数据就是重复数据(也就是上图绿色框出来的就是同时多个字段都存在重复的数据)。
思路简述:
第一步
因为有了文章上半部讲到的单个字段重复的数据查找思路,所以到这边应该更好理解了。
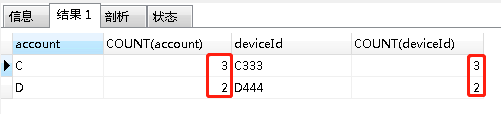
同样, account 和 deviceId 都相同的重复数据就是指, 这种数据存在的数量 大于 2,那么就是存在重复了。
我们还是使用到了 group by 函数 和 count 函数 和 having and 函数(因为需要同时满足两个字段条件,使用and)。
第一步写出来的mysql语句是:
- SELECT account, COUNT(account), deviceId, COUNT(deviceId)
- FROM accountinfo
- GROUP BY account, deviceId
- HAVING (COUNT(account) > 1) AND (COUNT(deviceId) > 1)
查询出来的结果如下图:
第二步
一样 也是把第一步里的到的关键信息 account 和 deviceId做为子查询条件,从原表里把 account 和 deviceId 同时相同的数据都查找出来。
第二步写出来的mysql语句是:
- SELECT t.* FROM accountinfo t, (
-
- SELECT account, COUNT(account), deviceId, COUNT(deviceId)
- FROM accountinfo
- GROUP BY account, deviceId
- HAVING (COUNT(account) > 1) AND (COUNT(deviceId) > 1)
- ) a
-
- WHERE t.account=a.account AND t.deviceId=a.deviceId
查询结果如下图:
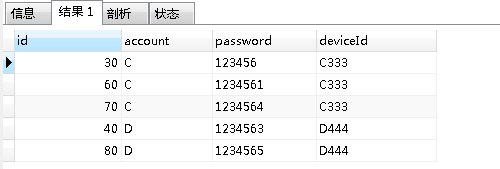
可以看到重复的数据都被我们筛选出来了,这些数据里面就是包含 account 和 deviceId 同时都相同的数据!
去重
第一步
思路一样,我们对于重复的数据每个只保留一条,那就是把这些涉及重复的数据每个都找出一条,也是根据id入手。
也就是在account为 C 且 deviceId 为 C333 三条重复数据里面,保留 id最小的 等于30 这一条;
account为D 且 deviceId 为 D444 二条重复数据里面,保留 id最小的 等于40 这一条.
所以第一步我们先写出来的mysql语句为:
- SELECT min(id) as id FROM (
-
- SELECT t.* FROM accountinfo t, (
-
- SELECT account, COUNT(account), deviceId, COUNT(deviceId)
- FROM accountinfo
- GROUP BY account, deviceId
- HAVING (COUNT(account) > 1) AND (COUNT(deviceId) > 1)
- ) a
-
- WHERE t.account=a.account AND t.deviceId=a.deviceId
-
- )a GROUP BY a.account,a.deviceId
查询结果如下图:
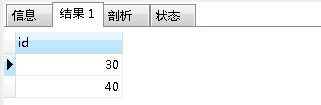
第二步
就是从涉及重复数据里面,找出除了我们需要保留的id之外的那批id, 那就是需要我们执行删除的数据id。
所以第二步我们先写出来的mysql语句为:
- SELECT t.* FROM accountinfo t, (
-
- SELECT account, COUNT(account), deviceId, COUNT(deviceId)
- FROM accountinfo
- GROUP BY account, deviceId
- HAVING (COUNT(account) > 1) AND (COUNT(deviceId) > 1)
- ) a
-
- WHERE t.account=a.account AND t.deviceId=a.deviceId
-
- ) b WHERE b.id
-
- NOT IN (
-
-
- SELECT min(id) as id FROM (
-
- SELECT t.* FROM accountinfo t, (
-
- SELECT account, COUNT(account), deviceId, COUNT(deviceId)
- FROM accountinfo
- GROUP BY account, deviceId
- HAVING (COUNT(account) > 1) AND (COUNT(deviceId) > 1)
- ) a
-
- WHERE t.account=a.account AND t.deviceId=a.deviceId
-
- )a GROUP BY a.account,a.deviceId
-
- )
查询出来的结果为:
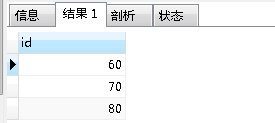
那么最后删掉这些id的数据即可:
- DELETE FROM accountinfo WHERE id in (
-
- SELECT b.id FROM (
-
- SELECT t.* FROM accountinfo t, (
-
- SELECT account, COUNT(account), deviceId, COUNT(deviceId)
- FROM accountinfo
- GROUP BY account, deviceId
- HAVING (COUNT(account) > 1) AND (COUNT(deviceId) > 1)
- ) a
-
- WHERE t.account=a.account AND t.deviceId=a.deviceId
-
- ) b WHERE b.id
-
- NOT IN (
-
-
- SELECT min(id) as id FROM (
-
- SELECT t.* FROM accountinfo t, (
-
- SELECT account, COUNT(account), deviceId, COUNT(deviceId)
- FROM accountinfo
- GROUP BY account, deviceId
- HAVING (COUNT(account) > 1) AND (COUNT(deviceId) > 1)
- ) a
-
- WHERE t.account=a.account AND t.deviceId=a.deviceId
-
- )a GROUP BY a.account,a.deviceId
-
- )
-
- )
去重后结果为: