
详解数仓的向量化执行引擎_数据仓库 向量计算
赞
踩
前言
-
适用版本:【基线功能】
传统的行执行引擎大多采用一次一元组的执行模式,这样在执行过程中CPU大部分时间并没有用来处理数据,更多的是在遍历执行树,就会导致CPU的有效利用率较低。而在面对OLAP场景巨量的函数调用次数,需要巨大的开销。为了解决这一问题,GaussDB(DWS)中增加了向量化引擎。向量化引擎使用了一次一批元组的执行模式,能够大大减少遍历执行节点的开销。同时向量化引擎还天然对接列存储,能够较为方便地在底层扫描节点装填向量化的列数据。列存 + 向量化执行引擎,是打开OLAP性能之门的金钥匙之一!
关于行存、列存表
行存表按行存储tuple到Page页面。多用于TP场景,这些场景数据频繁更新,增删改操作多,查询结果涉及表的多列。

列存表按列存储,每列数据存储到一个文件。多用于AP场景。
-
表列数多,访问列数少,减少IO操作次数
-
列数据具有同质性,提高数据压缩比
-
基于列批量数据的运算,CPU的cache命中率高

执行框架
执行器是优化器与存储引擎的交互枢纽。以优化器生成的执行计划树为输入,从存储引擎访问数据,并按照计划,操作各种执行算子,从而实现数据的处理。采用Pipeline模式, 行执行器一次一tuple,列执行器一次一batch。上层驱动下层,使得数据在执行树上流动。提供各种数据处理的执行算子。下图展示了自上而下的控制流和自下而上的数据流。
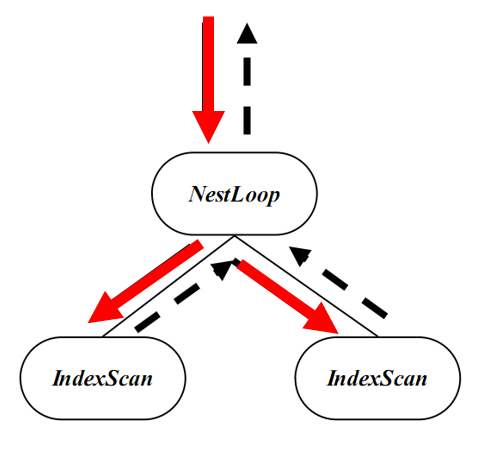
执行器的执行过程可分为这三个步骤:
-
执行器初始化:构造执行器全局状态信息estate、递归遍历计划树各节点,初始化其执行状态信息planstate
-
执行器的执行:行引擎和向量化引擎入口独立开,从计划树根节点开始,递归遍历到叶节点获取一个tuple/batch,经过逐层节点算子的处理,返回一个结果tuple/batch,直到再无tuple/batch。
-
执行器的清理:回收执行器全局状态信息,清理各plan node的执行状态。
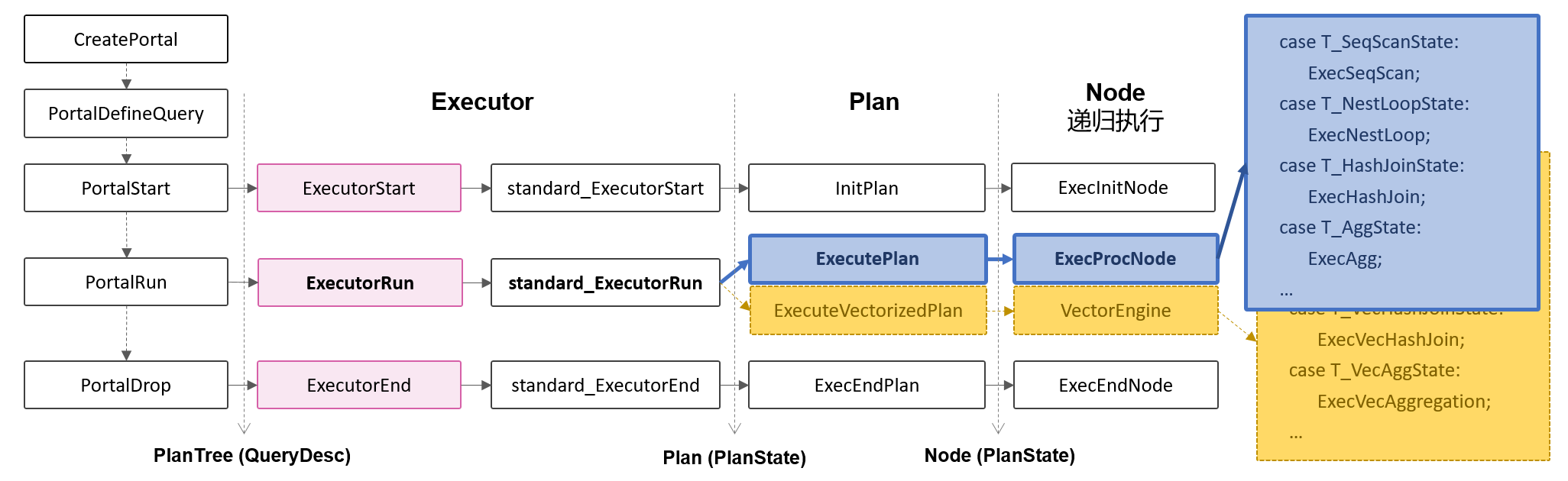
列执行器
行执行器的问题是:CPU大部分处理在遍历Plan Tree过程,而不是真正处理数据,CPU有效利用率低。列存表独有的应用场景,需要配套的向量化引擎,才能真正发挥其在OLAP场景下提升性能的优势。因此,列执行器的改造基本思路为:一次处理一列数据。
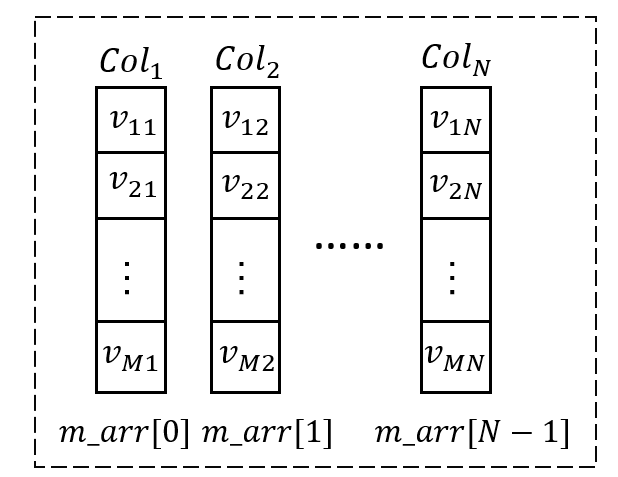
和行执行器一样,向量化执行引擎调度器,遵循Pipeline模式,但每次处理及在算子间传递数据为一次一个Batch(即1000行数据),CPU命中率提高,IO读操作减少。列执行器的数据流结构VectorBatch如下图所示。
行列混合:Adapter算子
列存表的某些场景不支持向量化执行引擎,譬如:string_to_array、listagg、string_agg等。GaussDB具有将两套行列引擎自动切换的能力。
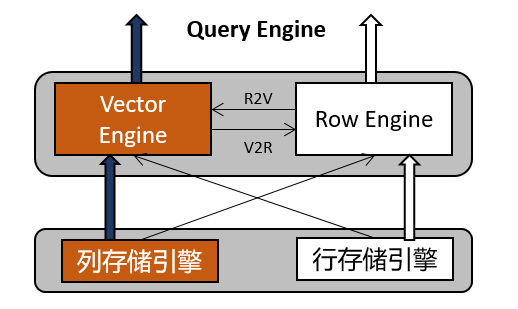
针对列存数据,如果只有行引擎,通常需要将列数据重构成元组tuple给执行引擎逐行处理。Tuple deform过程影响列存数据查询处理的性能。
向量化执行引擎的性能
对比行列存引擎对同一表达式x*(1-y)计算的性能,可以看到列存引擎的Cstore Scan算子相比行存引擎的Seq Scan算子,耗时减少了85%。
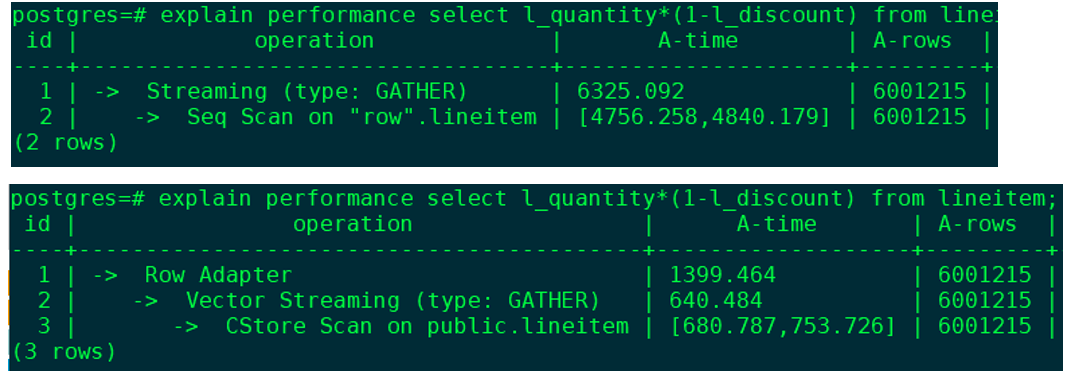
向量计算的特点是:一次计算多个值,减少函数调用和上下文切换,尽量利用CPU的缓存以及向量化执行指令提高性能。
向量化执行引擎的性能优势:
-
一次一Batch,读取更多数据,减少IO读次数
-
由于Batch中记录数多,相应的CPU的cache命中率提升
-
Pipeline模式执行过程中的函数调用次数减少
-
与列存表配套,减少tuple deform,即列存数据重构tuple的时间开销
行/列执行器各算子对照
向量化引擎的执行算子类似于行执行引擎,包含控制算子、扫描算子、物化算子和连接算子。同样会使用节点表示,继承于行执行节点,执行流程采用递归方式。主要包含的节点有:CStoreScan(顺序扫描),CStoreIndexScan(索引扫描),CStoreIndexHeapScan(利用Bitmap获取元组),VecMaterial(物化),VecSort(排序),VecHashJoin(向量化哈希连接)等,下面将逐一介绍这些执行算子。
扫描算子
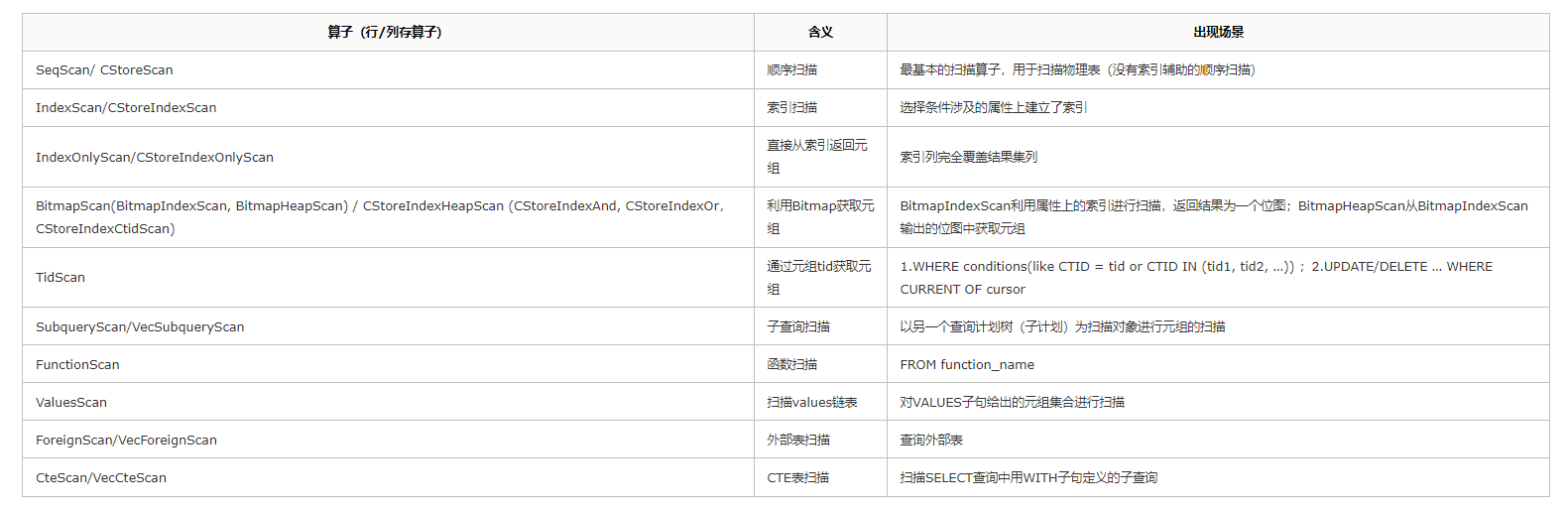
扫描算子用来扫描表中的数据,每次获取一条元组作为上层节点的输入, 存在于查询计划树的叶子节点,它不仅可以扫描表,还可以扫描函数的结果集、链表结构、子查询结果集。一些比较常见的扫描算子如表所示。
连接算子
连接算子对应了关系代数中的连接操作,以表 t1 join t2 为例,主要的集中连接类型如下:inner join、left join、right join、full join、semi join、 anti join,其实现方式包括Nestloop、HashJoin、MergeJoin;

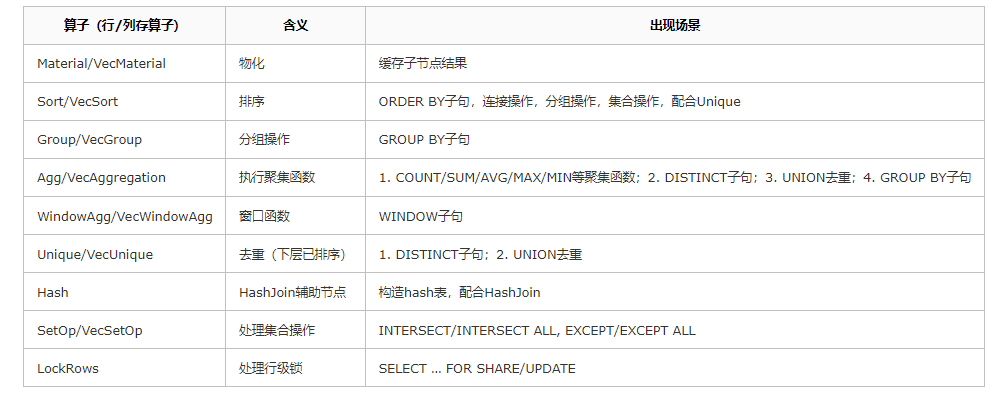
物化算子
物化算子是一类可缓存元组的节点。在执行过程中,很多扩展的物理操作符需要首先获取所有的元组才能进行操作(例如聚集函数操作、没有索引辅助的排序等),这是要用物化算子将元组缓存起来;
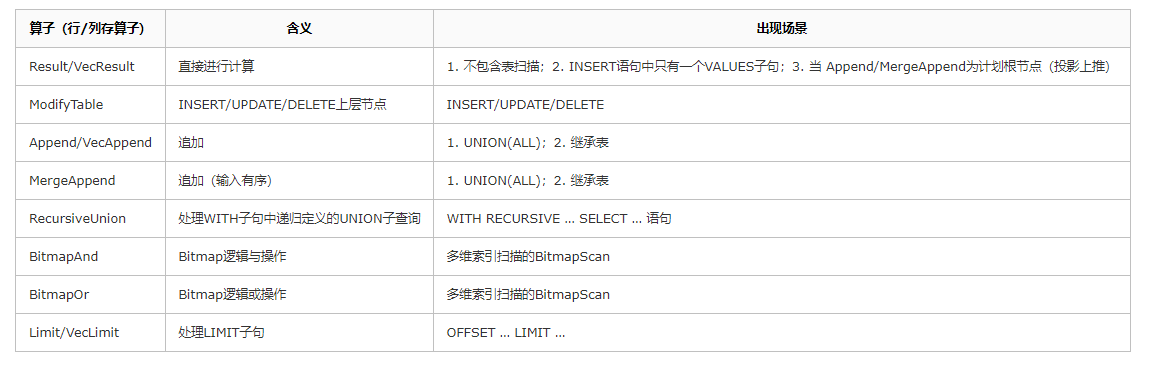
控制算子
控制算子是一类用于处理特殊情况的节点,用于实现特殊的执行流程。
其他算子
其他算子包括Stream算子,以及RemoteQuery等算子

Gaussdb向量化的演进
在第一代向量化引擎之后,GaussDB演化出具有更高性能的向量化引擎:Sonic向量化引擎和Turbo向量化引擎。GaussDB为了OLAP执行性能提升,在列存 + 向量化执行引擎、批量计算的路上不断演进:
-
Stream算子 + 分布式执行框架,支持数据在多节点间流动
-
SMP,节点内多线程并行,充分利用空闲硬件资源
-
LLVM技术,全新的代码生成框架,JIT(just in time)编译器,消除tuple deform瓶颈
-
Sonic向量化引擎,对HashAgg、HashJoin算子进一步向量化,根据每列不同类型实现不同Array来对数据做计算
-
新一代Turbo向量化引擎,对大部分算子做进一步向量化,在Sonic引擎的基础上,新增了Null优化、大整数优化、Stream优化、Sort优化等,进一步提升了性能
总结
本文介绍了GaussDB向量化执行引擎,对其框架、原理、各算子概况、性能提升等做了详细阐述。
文章转载自:华为云开发者联盟

