
热门标签
热门文章
- 1通用大模型VS垂直大模型
- 2[大模型]Qwen2-7B-Instruct Lora 微调_qwen2 微调训练
- 3Python基础入门自学——10_def init(self, output: callable = print) -> bool:
- 4git解决合并冲突_git pull合并冲突
- 5python编写小游戏详细教程,用python做简单的小游戏_怎么编程小游戏
- 6反无人机技术详解
- 7vscode 无法导入自己写的模块文件(.py)问题_vscode中import无法导入
- 8类ChatGPT人工智能技术嵌入数字政府治理:价值、风险及其防控
- 92023年Android社招找工作需要掌握到什么程度?_2023android 简历 相关技能
- 10深度学习之Softmax回归_softmax回归 matlab csdn
当前位置: article > 正文
【论文阅读】dreambooth_dreambooth论文
作者:酷酷是懒虫 | 2024-06-24 03:49:30
赞
踩
dreambooth论文
简介
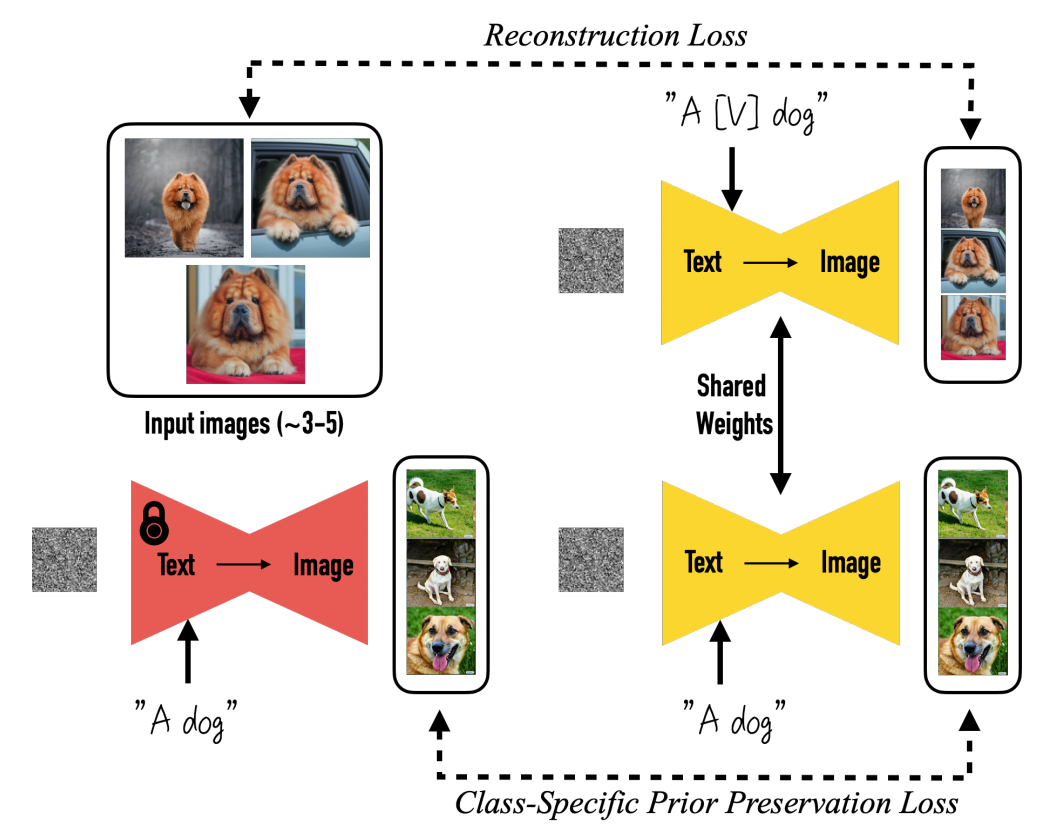
- 目标:subject-driven generation,针对特定物体的图像生成,仅使用少量目标主体图像,dreambooth可以在prompt的指导下生成大量目标主体在不同场景下的图像。例如下图中小狗,我们给定的set就是左侧的input images,需要生成小狗在不同背景/场景下的图像

- 做法:微调预训练文生图模型将input images绑定到特定的identifier上。并通过添加类别特定保留损失class- specific preservation loss鼓励生成多样的(set中没有出现的)场景姿势视角等
- 之前的模型无法实现这种目标驱动的生成的原因是模型的表达能力有限,模型的output domain没有见过指定目标在不同场景下的生成。现有模型无法保留/识别/理解物体最核心的特征。解决方案:通过训练一个特定的embedding来绑定特定物体的特征(bind identifier with specific subjects)
- 模型输入
- input images
- text prompt。将类别实例绑定到identifier上以使用类别上的先验知识。eg:a [V] dog
- 为了防止language drift导致原始的dog的emb向特定的输入偏移),这里使用到class-specific preservation loss 鼓励生成的多样性。这块不太能理解
方法
- 用少量数据fine-tune容易导致过拟合(生成的图像与输入很像)。模型可能会走捷径,并没有学会特定物体的真实分布使得生成的图像多样性不足
prompts
- a [identifier] [class none]
- 将class none绑定到identifier上以利用类别先验知识。实验发现添加错误的class none或者不添加会导致训练时间长,language drift以及模型性能下降。(有点“继承”和“多态”对感觉)
identifier
- 选择要求:rare。在语言模型和扩散模型中都具有较弱的先验。
- 最好不要选择常见词汇。如果选择常见的词汇,则identifier需要先与原始meaning解绑然后再绑定到新的meaning中,选择较为rare的词汇可以较为容易地学习新知识,不受源词汇的干扰
- 不要选择乱码:因为文本预处理的时候会分割词根词缀,乱码会导致最终分割的情况是所有字符都分割开,而模型对字符有很强的先验,也会干扰identifier的学习
模型训练
fine tune模型的所有层,包括text embedding
-
存在问题
- language drift:当使用很少的图像文本对去fine tune大模型时,使用的文本词汇的meaning会慢慢偏移到输入的特定图像特征上去
- 多样性降低:主要可能是过拟合,例如训练时间过长。模型的输出局限于输入的图像
-
解决:class-specific preservation loss
- 去掉identifier的文本作为prompt分别输入fine tune之前和之后的模型中生成的图像要越接近越好。
- 对于克服language drift和鼓励输出多样性是很有效的
-
最终损失
- 重构损失:输出与输入之间的相似度
- 先验损失:先验类别在微调前后的相似度
注意
- 对于简单的图像例如小猫小狗,3-5张图像可以有较好的效果。但是要生成更加复杂的图像,可能需要更多的输入
- application很强大,具体见论文

- 也有一些局限
- 无法生成太奇怪的场景,因为可能这种场景class也没有在预训练模型中见过。例如书包在国际空间站上
- prompt改变了原始输入的一些特征
- prompt与输入图像高度相似

- 对于比较罕见的目标,难以学习,可能难以支持目标的多种变体。
- 可能会出现“幻想”对目标特征,取决于模型的先验强度以及语义修改的复杂度
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/酷酷是懒虫/article/detail/751578
推荐阅读
相关标签

