- 1c语言文件(万字)(超详细)_c语言文档
- 2git 大文件上传以及下载_gitbash 下载大文件
- 3小程序开发---uniapp---商城项目002---分类_uniapp实现商品分类展示组件
- 4ARP协议及抓包详解_arp抓包
- 5解决obsidian无法加载第三方插件(社区插件)的问题_obsidian无法加载社区插件
- 6UI管理面板_panal name
- 7前端实现sql格式化,Mybatis语法_sqlformatter.js+paramtypes
- 8机器学习原理之 -- XGboost原理详解
- 9数据库课设(图书管理系统)_数据库设置管理图书馆保管和借还的数据库
- 10Oracle数据库ORA-报错大全
大数据毕业设计hadoop+pyspark图书推荐系统_python hadoop spark 毕业设计
赞
踩
本部分主要考察:1.复杂软件系统的分析与建模能力;2.系统架构和功能结构设计能力;3.数据结构和算法分析和设计能力。
本部分是中期检查报告的主要内容,要重点论述复杂软件系统的需求分析、概要设计和详细设计工作(包括用例设计、架构设计、功能结构设计、数据库设计、算法流程设计等),既要有文字描述,又要有图表等。
具体要求:
能够应用软件系统开发全生命周期的基本设计开发方法和技术,进行系统设计目标和技术方案的可行性分析。
能够应用软件工程的基本原理,识别、描述、分析软件系统的需求,并能够应用软件工程的基本原理,建立软件系统模型。
能够对软件系统的系统架构和功能结构进行设计,并对软件系统的数据结构和算法流程进行设计。
能够在分析和评价软件工程实践与复杂软件工程问题解决方案对社会、健康、安全、法律以及文化的影响,以及这些制约因素对软件项目实施、软件服务的影响,并理解应承担的责任。
毕业设计任务有一定原创性,能够理解职业道德的含义及其影响,并能够在毕业设计过程中遵守软件工程师职业道德和规范,自觉履行完成毕业设计相关任务。
能够理解毕业设计软件系统的全生命周期及主要环节的成本构成,能够在多学科环境下,设计复杂软件工程问题的解决方案过程中,运用项目管理原理和经济决策方法进行预测分析。
要求报告正文用小四号中文宋体、英文新罗马字体,单倍行距。
请在最终报告中删除以上红色字体说明内容(包括本句话)!
基于Spark的个性化书籍推荐系统是一种基于大数据技术的智能推荐系统,它可以根据用户的历史行为和偏好,为用户提供个性化的书籍推荐。该系统采用Spark技术,可以实现大数据的实时处理,从而提高推荐系统的准确性和可靠性。此外,该系统还可以根据用户的习惯和偏好,提供更加个性化的书籍推荐,从而满足用户的需求。
本系统的实现功能包括:
1、数据采集模块:采集用户的历史行为和偏好数据;2、数据处理模块:使用Spark技术对数据进行实时处理;3、推荐算法模块:根据用户的历史行为和偏好,提供个性化的书籍推荐;4、用户界面模块:提供友好的用户界面,方便用户查看推荐结果;5、管理员管理模块:提供书籍管理、用户管理、分类管理以及推荐管理功能。
技术方案可行性分析:
1、技术可行性:本系统采用Spark技术,可以实现实时处理大量数据,提高推荐系统的准确性和可靠性,同时也可以支持多种推荐算法,如基于内容的推荐、基于协同过滤的推荐等,从而实现个性化的书籍推荐。 2、系统可行性:本系统采用Mysql数据库存储用户数据,使用SQL语句进行调用和分析,可以有效地提高系统的运行效率,同时也可以满足用户的需求。 3、经济可行性:本系统采用开源技术,可以有效地降低系统的开发成本,同时也可以提高系统的可靠性和稳定性。 4、社会可行性:本系统可以满足用户对书籍的需求,提供个性化的书籍推荐,从而提高用户的阅读体验,同时也可以提高用户的阅读兴趣,促进社会文化的发展。
综上所述,本系统的技术方案具有较高的可行性,可以有效地满足用户的需求,促进社会文化的发展。
实现步骤如下:
1、数据采集:采用爬虫技术,从网络上抓取书籍的相关信息,包括书籍的名称、作者、出版社、出版时间、价格等; 2、数据处理:将抓取的数据进行清洗和预处理,去除无效数据,并将数据转换为Spark可以处理的格式; 3、推荐算法:采用基于内容的推荐算法和基于协同过滤的推荐算法,根据用户的历史行为和书籍的相关信息,计算出用户的推荐列表; 4、用户界面:设计用户界面,使用户可以轻松地查看推荐列表,并可以根据自己的喜好进行选择; 5、管理员管理:设计管理员管理模块,使管理员可以对系统进行管理和维护。
数据库的详细设计方案如下:
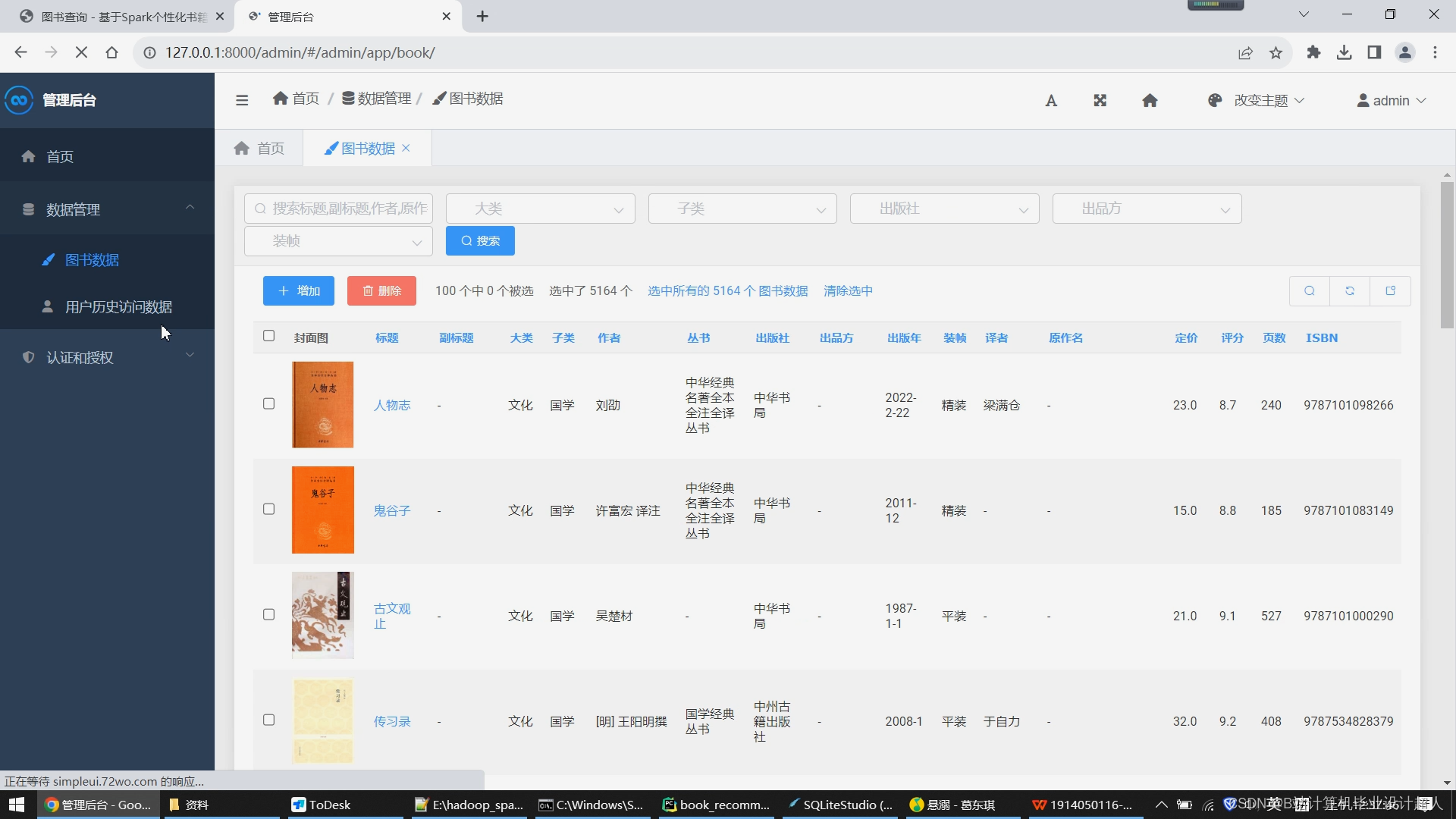
1、用户表:用户表用于存储用户的信息,包括用户ID、用户名、密码、性别、年龄等,字段类型为int、varchar等; 2、书籍表:书籍表用于存储书籍的信息,包括书籍ID、书籍名称、作者、出版社、出版时间、价格等,字段类型为int、varchar等; 3、分类表:分类表用于存储书籍的分类信息,包括分类ID、分类名称、书籍ID等,字段类型为int、varchar等; 4、用户行为表:用户行为表用于存储用户的行为信息,包括用户ID、书籍ID、行为类型(浏览、购买等)、行为时间等,字段类型为int、varchar等。
二、毕业设计工作存在的问题及解决方案(不少于1000字)
重点论述在软件系统的需求分析、概要设计和详细设计过程中遇到的问题以及解决方案。
开发过程中存在的问题及解决方案如下: 1、数据采集问题:由于网络上的数据量庞大,采集数据时可能会遇到网络不稳定、数据量过大等问题,可以采用分布式爬虫技术,将爬虫任务分发到多台服务器上,提高采集效率; 2、数据处理问题:由于网络上的数据结构不统一,处理数据时可能会遇到数据格式不一致、数据缺失等问题,可以采用数据清洗技术,将数据格式统一,并填补缺失的数据; 3、推荐算法问题:由于推荐算法的复杂性,可能会遇到推荐结果不准确、推荐效率低等问题,可以采用基于机器学习的推荐算法,根据用户的历史行为和书籍的相关信息,提高推荐结果的准确性和推荐效率; 4、用户界面问题:由于用户界面的复杂性,可能会遇到界面不友好、操作不便等问题,可以采用简洁的界面设计,使用户可以轻松地查看推荐列表,并可以根据自己的喜好进行选择; 5、管理员管理问题:由于管理员管理模块的复杂性,可能会遇到管理不方便、维护不及时等问题,可以采用可视化的管理界面,使管理员可以对系统进行管理和维护。
三、下一步工作预测及可能存在的问题(不少于500字)
为了优化基于Spark个性化书籍推荐系统,可以采用以下措施: 1、改进推荐算法:采用深度学习技术,改进推荐算法,提高推荐结果的准确性和推荐效率; 2、改进用户界面:采用可视化的用户界面,使用户可以轻松地查看推荐列表,并可以根据自己的喜好进行选择; 3、改进管理员管理:采用自动化的管理模式,使管理员可以对系统进行管理和维护; 4、改进数据采集:采用大数据技术,改进数据采集,提高采集效率; 5、改进数据处理:采用数据挖掘技术,改进数据处理,提高数据处理效率。 可能存在的问题包括:推荐结果不准确、推荐效率低、界面不友好、操作不便、管理不方便、维护不及时、数据采集效率低、数据处理效率低等。 下一步应该采用以上措施,改进推荐算法、用户界面、管理员管理、数据采集和数据处理,以提高系统的性能和用户体验。